Învățarea prin întărire (RL) este unul dintre cele mai fierbinți subiecte de cercetare în domeniul inteligenței artificiale moderne și popularitatea sa este în creștere. Să ne uităm la 5 lucruri utile pe care cineva trebuie să le știe pentru a începe cu RL.
Învățarea prin întărire(RL) este un tip de tehnică de învățare automată care permite unui agent să învețe într-un mediu interactiv prin încercare și eroare, folosind feedback-ul din propriile acțiuni și experiențe.
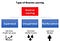
Deși atât învățarea supravegheată cât și învățarea prin întărire utilizează cartografierea între intrare și ieșire, spre deosebire de învățarea supravegheată în care feedback-ul furnizat agentului este un set de acțiuni corecte pentru îndeplinirea unei sarcini, învățarea prin întărire utilizează recompense și pedepse ca semnale pentru comportament pozitiv și negativ.
În comparație cu învățarea nesupravegheată, învățarea prin întărire este diferită în ceea ce privește obiectivele. În timp ce în cazul învățării nesupravegheate scopul este de a găsi asemănări și diferențe între punctele de date, în cazul învățării prin întărire scopul este de a găsi un model de acțiune adecvat care să maximizeze recompensa totală cumulată a agentului. Figura de mai jos ilustrează bucla de feedback acțiune-recompensă a unui model RL generic.

Cum se formulează o problemă de bază de învățare prin întărire?
Câțiva termeni cheie care descriu elementele de bază ale unei probleme de RL sunt:
- Mediu – Lumea fizică în care operează agentul
- Stare – Situația curentă a agentului
- Recompensă – Feedback-ul din partea mediului
- Politică – Metoda de cartografiere a stării agentului pentru acțiuni
- Valoare – Recompensa viitoare pe care un agent ar primi-o dacă ar întreprinde o acțiune într-o anumită stare
O problemă de RL poate fi cel mai bine explicată prin intermediul jocurilor. Să luăm jocul PacMan în care scopul agentului (PacMan) este de a mânca mâncarea din grilă evitând în același timp fantomele din calea sa. În acest caz, lumea grilei este mediul interactiv pentru agent în care acesta acționează. Agentul primește o recompensă pentru că mănâncă mâncare și o pedeapsă dacă este ucis de fantome (pierde jocul). Stările reprezintă locația agentului în lumea grilă, iar recompensa totală cumulată reprezintă câștigarea jocului de către agent.

Pentru a construi o politică optimă, agentul se confruntă cu dilema explorării de noi stări și, în același timp, cu maximizarea recompensei sale globale. Aceasta se numește compromisul explorare vs. exploatare. Pentru a le echilibra pe ambele, cea mai bună strategie globală poate implica sacrificii pe termen scurt. Prin urmare, agentul ar trebui să colecteze suficiente informații pentru a lua cea mai bună decizie globală în viitor.
Procesele de decizie Markov (MDP) sunt cadre matematice pentru a descrie un mediu în RL și aproape toate problemele RL pot fi formulate folosind MDP. Un MDP constă dintr-un set de stări finite ale mediului S, un set de acțiuni posibile A(s) în fiecare stare, o funcție de recompensă cu valoare reală R(s) și un model de tranziție P(s’, s | a). Cu toate acestea, în mediile din lumea reală este mai probabil să lipsească orice cunoaștere prealabilă a dinamicii mediului. Metodele RL fără model sunt utile în astfel de cazuri.
Învățarea Q este o abordare fără model utilizată în mod obișnuit, care poate fi folosită pentru construirea unui agent PacMan care se joacă singur. Aceasta se învârte în jurul noțiunii de actualizare a valorilor Q care denotă valoarea efectuării acțiunii a în starea s. Următoarea regulă de actualizare a valorilor este nucleul algoritmului Q-learning.

Iată o demonstrație video a unui agent PacMan care utilizează învățarea prin întărire profundă.
Care sunt unii dintre cei mai utilizați algoritmi de învățare prin întărire?
Q-learning și SARSA (State-Action-Reward-State-Action) sunt doi algoritmi de RL fără model frecvent utilizați. Aceștia diferă în ceea ce privește strategiile lor de explorare, în timp ce strategiile de exploatare sunt similare. În timp ce Q-learning este o metodă off-policy în care agentul învață valoarea pe baza acțiunii a* derivată dintr-o altă politică, SARSA este o metodă on-policy în care acesta învață valoarea pe baza acțiunii sale curente a derivată din politica sa curentă. Aceste două metode sunt simplu de implementat, dar le lipsește generalitatea, deoarece nu au capacitatea de a estima valori pentru stări nevăzute.
Acest lucru poate fi depășit prin algoritmi mai avansați, cum ar fi Deep Q-Networks(DQNs), care utilizează rețele neuronale pentru a estima valorile Q. Dar DQN-urile pot gestiona doar spații de acțiune discrete, cu dimensiuni mici.
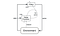
Deep Deterministic Policy Gradient(DDPG) este un algoritm de critică a actorilor, fără model, fără politică, care abordează această problemă prin învățarea politicilor în spații de acțiune continue, cu dimensiuni mari. Figura de mai jos este o reprezentare a arhitecturii actor-critic.
Care sunt aplicațiile practice ale învățării prin întărire?
Din moment ce RL necesită o mulțime de date, prin urmare, se aplică cel mai mult în domenii în care datele simulate sunt disponibile cu ușurință, cum ar fi jocul, robotica.
- RL este destul de mult utilizată în construirea de inteligență artificială pentru jocurile pe calculator. AlphaGo Zero este primul program de calculator care a învins un campion mondial în vechiul joc chinezesc de Go. Altele includ jocurile ATARI, Backgammon ,etc
- În robotică și în automatizarea industrială, RL este utilizată pentru a permite robotului să creeze un sistem de control adaptiv eficient pentru el însuși, care învață din propria experiență și comportament. Activitatea DeepMind privind învățarea prin întărire profundă pentru manipularea robotică cu actualizări asincrone ale politicilor este un bun exemplu în acest sens. Urmăriți acest video demonstrativ interesant.
Alte aplicații ale RL includ motoare de rezumare abstractivă a textului, agenți de dialog (text, vorbire) care pot învăța din interacțiunile utilizatorului și se pot îmbunătăți în timp, învățarea politicilor optime de tratament în domeniul sănătății și agenți bazați pe RL pentru tranzacționarea online a acțiunilor.
Cum pot începe cu învățarea prin întărire?
Pentru a înțelege conceptele de bază ale RL, se pot consulta următoarele resurse.
- Reinforcement Learning-An Introduction, o carte scrisă de părintele învățării prin întărire- Richard Sutton și de consilierul său doctoral Andrew Barto. O versiune online a cărții este disponibilă aici.
- Materialul didactic de la David Silver, inclusiv prelegeri video, este un curs introductiv excelent despre RL.
- Iată un alt tutorial tehnic despre RL de Pieter Abbeel și John Schulman (Open AI/ Berkeley AI Research Lab).
Pentru a începe să construiți și să testați agenți RL, următoarele resurse pot fi utile.
- Acest blog despre cum să antrenați un agent ATARI Pong Neural Network ATARI Pong cu Policy Gradients din pixeli brute de către Andrej Karpathy vă va ajuta să obțineți primul dvs. agent de învățare prin întărire profundă (Deep Reinforcement Learning) și să îl puneți în funcțiune în doar 130 de linii de cod Python.
- DeepMind Lab este o platformă open source asemănătoare jocurilor 3D creată pentru cercetarea AI bazată pe agenți cu medii simulate bogate.
- Project Malmo este o altă platformă de experimentare AI pentru sprijinirea cercetării fundamentale în AI.
- OpenAI gym este un set de instrumente pentru construirea și compararea algoritmilor de învățare prin întărire.