Reinforcement Learning(RL) é um dos mais quentes tópicos de pesquisa no campo da Inteligência Artificial moderna e sua popularidade está apenas crescendo. Vamos olhar para 5 coisas úteis que é preciso saber para começar com RL.
Reinforcement Learning(RL) é um tipo de técnica de aprendizagem de máquinas que permite a um agente aprender em um ambiente interativo por tentativa e erro usando o feedback de suas próprias ações e experiências.
A aprendizagem supervisionada e de reforço usa o mapeamento entre entrada e saída, ao contrário da aprendizagem supervisionada onde o feedback fornecido ao agente é o conjunto correto de ações para realizar uma tarefa, a aprendizagem de reforço usa recompensas e punições como sinais de comportamento positivo e negativo.
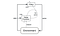
Como comparado ao aprendizado não supervisionado, o aprendizado de reforço é diferente em termos de metas. Enquanto o objectivo na aprendizagem não supervisionada é encontrar semelhanças e diferenças entre os pontos de dados, no caso da aprendizagem de reforço o objectivo é encontrar um modelo de acção adequado que maximize a recompensa total cumulativa do agente. A figura abaixo ilustra o ciclo de feedback action-reward de um modelo genérico RL.

Como formular um problema básico de Aprendizagem de Reforço?
Alguns termos chave que descrevem os elementos básicos de um problema RL são:
- Ambiente – Mundo físico em que o agente opera
- Estado – Situação atual do agente
- Recompensa – Feedback do ambiente
- Política – Método para mapear o estado do agente para ações
- Valor – Recompensa futura que um agente receberia ao tomar uma ação em um determinado estado
Um problema RL pode ser melhor explicado através de jogos. Vamos levar o jogo do PacMan onde o objetivo do agente(PacMan) é comer a comida na grade enquanto evita os fantasmas no seu caminho. Neste caso, o mundo da grelha é o ambiente interactivo para o agente onde ele actua. O agente recebe uma recompensa por comer comida e punição se for morto pelo fantasma (perde o jogo). Os estados são a localização do agente no mundo da grade e a recompensa total acumulada é o agente que vence o jogo.

Para construir uma política ótima, o agente enfrenta o dilema de explorar novos estados enquanto maximiza sua recompensa geral ao mesmo tempo. Isso é chamado de trade-off Exploração vs Exploração. Para equilibrar ambos, a melhor estratégia geral pode envolver sacrifícios de curto prazo. Portanto, o agente deve coletar informações suficientes para tomar a melhor decisão geral no futuro.
Markov Processos de Decisão (MDPs) são estruturas matemáticas para descrever um ambiente em RL e quase todos os problemas de RL podem ser formulados usando MDPs. Um MDP consiste em um conjunto de estados de ambiente finitos S, um conjunto de possíveis ações A(s) em cada estado, uma função de recompensa R(s) real valorizada e um modelo de transição P(s’, s | a). Contudo, é mais provável que os ambientes do mundo real careçam de qualquer conhecimento prévio da dinâmica do ambiente. Métodos RL livres de modelos são úteis em tais casos.
Q-learning é uma abordagem comumente usada livre de modelos que pode ser usada para construir um agente PacMan auto-executável. A seguinte regra de atualização de valores é o núcleo do algoritmo Q-learning.

Aqui está uma demonstração em vídeo de um agente PacMan que usa o Deep Reinforcement Learning.
Quais são alguns dos algoritmos de Reforço de Aprendizagem mais utilizados?
Q-learning e SARSA (State-Action-Reward-State-Action) são dois algoritmos RL livres de modelos comumente utilizados. Eles diferem em termos de suas estratégias de exploração, enquanto suas estratégias de exploração são semelhantes. Enquanto o Q-learning é um método fora da política em que o agente aprende o valor baseado na acção a* derivada da outra política, o SARSA é um método on-policy onde aprende o valor baseado na sua acção actual e derivado da sua política actual. Esses dois métodos são simples de implementar mas carecem de generalidade, pois não têm a capacidade de estimar valores para estados invisíveis.
Isso pode ser superado por algoritmos mais avançados como o Deep Q-Networks(DQNs) que usam Redes Neurais para estimar valores Q. Mas os DQNs só podem lidar com espaços de ação discretos e de baixa dimensão.
Deep Deterministic Policy Gradient(DDPG) é um algoritmo livre de modelos, fora de política, crítico para atores, que ataca este problema aprendendo políticas em espaços de ação contínua e de alta dimensão. A figura abaixo é uma representação da arquitetura ator-crítica.
Quais são as aplicações práticas do Reforço da Aprendizagem?
Desde, RL requer muitos dados, portanto é mais aplicável em domínios onde dados simulados estão prontamente disponíveis como jogabilidade, robótica.
- RL é bastante utilizado na construção de IA para jogar jogos de computador. AlphaGo Zero é o primeiro programa de computador a derrotar um campeão do mundo no antigo jogo chinês de Go. Outros incluem jogos ATARI, Backgammon ,etc
- Em robótica e automação industrial, RL é usado para permitir ao robô criar um sistema de controle adaptável eficiente para si mesmo, que aprende com sua própria experiência e comportamento. O trabalho do DeepMind em Aprendizagem de Reforço Profundo para Manipulação Robótica com Atualizações de Políticas Assíncronas é um bom exemplo do mesmo. Veja este interessante vídeo demonstrativo.
Outras aplicações de RL incluem mecanismos de sumarização de texto abstrato, agentes de diálogo (texto, fala) que podem aprender com as interações do usuário e melhorar com o tempo, aprendendo ótimas políticas de tratamento em saúde e agentes baseados em RL para negociação de ações online.
Como posso começar com Reinforcement Learning?
Para entender os conceitos básicos de RL, pode-se consultar os seguintes recursos.
- Reinforcement Learning-An Introduction, um livro do pai de Reinforcement Learning- Richard Sutton e seu conselheiro doutor Andrew Barto. Um rascunho online do livro está disponível aqui.
- Material didático de David Silver, incluindo palestras em vídeo é um ótimo curso introdutório sobre RL.
- Aqui está outro tutorial técnico sobre RL por Pieter Abbeel e John Schulman (Open AI/ Berkeley AI Research Lab).
Para começar a construir e testar agentes RL, os seguintes recursos podem ser úteis.
- Este blog sobre como treinar um agente ATARI Pong da Rede Neural com Gradientes de Políticas a partir de pixels brutos por Andrej Karpathy ajudará você a colocar seu primeiro agente de Aprendizagem de Reforço Profundo em funcionamento em apenas 130 linhas de código Python.
- DeepMind Lab é uma plataforma de código aberto semelhante a jogos 3D criada para pesquisa de IA baseada em agentes com ambientes simulados ricos.
- Project Malmo é outra plataforma de experimentação de IA para apoiar pesquisas fundamentais em IA.
- OpenAI gym é um kit de ferramentas para construir e comparar algoritmos de aprendizagem de reforço.