Proteínas com GPI são o homem estranho. Na biologia celular introdutória, eles nos ensinaram que existiam cinco tipos de proteínas de membrana, nomeadas como se segue: Tipo I, Tipo II, Tipo III, Tipo IV, e GPI-anchored. Porque é que temos esta estranha classe de proteínas fundidas a uma cadeia de açúcar e gordura? O que é que elas fazem? Podemos obter alguma informação sobre as minhas proteínas de interesse – PrP – aprendendo mais sobre esta classe de proteínas de que é membro?
Sonia e eu e o nosso colega de equipa Andrew e temos feito algumas leituras sobre este assunto e estou a escrever este post no blog para partilhar um pouco do que aprendemos.
reading
Começamos por ler algumas críticas . Estas cobriram principalmente a estrutura e biogênese da âncora GPI em si, sobre a qual se conhece um espantoso sobre.
Esta âncora, cujo nome completo é glicosilfosfatidilinositol, não é um monólito: é uma descrição geral de uma molécula cujos detalhes podem variar. Em geral, a partir do ω (último resíduo pós-traducional presente) da proteína, tem-se etanolamina, depois um fosfato, depois alguns açúcares, depois um fosfolipídeo. O núcleo da espinha dorsal do açúcar é conservado, mas as cadeias laterais que se ramificam dele podem variar, e o grupo da cabeça do fosfolípido e os ácidos gordos também podem variar. A âncora GPI da PrP foi caracterizada em , mas mesmo assim não é um monólito – eles identificaram pelo menos seis estruturas diferentes na composição da cadeia lateral do açúcar.
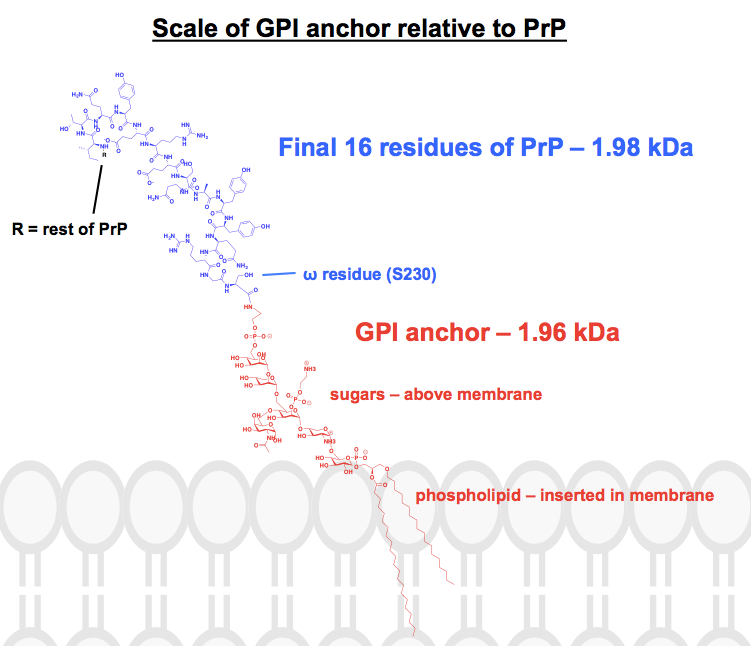
Tudo a estrutura química que encontrei das âncoras GPI tem pelo menos algumas partes abreviadas ou resumidas, e a proteína é geralmente mostrada apenas como uma imagem. Eu queria ter uma idéia de como essas âncoras realmente se parecem quimicamente, no contexto das proteínas anexas, então eu comecei a desenhar uma estrutura completa no ChemDraw. Trabalhando a partir da Figura 1 da – a coisa mais próxima de uma estrutura esquelética completa que pude encontrar – eu adicionei os detalhes de uma das âncoras GPI da PrP do painel superior da Figura 6. O peso molecular chegou a 1.958 Da, então para o contexto desenhei os 16 resíduos finais de HuPrP23-230, que pesam em comparação, a 1.979 Da. Isto é cerca de 8% da sequência pós-tradução da PrP modificada. Não tenho a certeza de ter acertado em todas as ligações, mas eis o que eu descobri:
Em muitos casos, um gene tem múltiplas isoformas, com um produto emendado dando origem a uma proteína ancorada em GPI enquanto outros dão origem a formas segregadas ou transmembranas. Exemplos incluem NCAM1, que tem três isoformas principais, uma das quais é ancorada em GPI e as outras duas são transmembranas, e ACHE (codificando acetilcolinesterase), cuja forma ancorada em GPI é aparentemente encontrada apenas nos glóbulos vermelhos (NCBI Genes). A história mais fascinante aqui é a do gene do rato Ly6a que, graças a um polimorfismo genético, está ancorado em algumas estirpes de rato e não em outras. Somente em sua forma ancorada em GPI, ele atua como receptor do vetor viral AAV PHP.eB . (Este vetor consegue uma absorção surpreendentemente eficiente em neurônios cerebrais para terapia gênica , mas infelizmente, é um gene de camundongo somente – nós humanos não temos nem mesmo o Ly6a).
Sabe-se muito sobre como as âncoras GPI são sintetizadas e fixadas às proteínas , com >20 proteínas envolvidas no caminho, a maioria das quais começam com o prefixo “PIG” e são codificadas por genes como PIGA, PIGK, e assim por diante – veja a Figura 2 para um diagrama. A maior parte da biossíntese ocorre com a âncora inserida na membrana no ER mas não presa a nenhuma proteína. De facto, os primeiros passos ocorrem no folheto citosólico da membrana, e só mais tarde é que a âncora se desloca para o lado lumenal (dentro do RE). A etapa final é quando a transamidase GPI, um complexo composto de pelo menos cinco proteínas, cliva o sinal GPI do terminal C da proteína e prende a âncora GPI ao chamado resíduo da proteína ω (o último resíduo na seqüência pós-tradução modificada). Existe então uma maturação adicional da âncora GPI à medida que a proteína migra para fora da ER em direção à superfície celular.
Existe um número de pequenos inibidores de biossíntese de moléculas GPI em fungos, alguns dos quais pessoas tentaram desenvolver como antifúngicos, mas até onde pude dizer, o único inibidor conhecido de biossíntese GPI em células de mamíferos é a mannosamina, um análogo de manose quimicamente incompatível com a incorporação na GPI .
Procurei e procurei um logotipo da seqüência de aminoácidos que o motivo da transamidase GPI reconhece, mas não encontrei nenhum. Aparentemente o motivo da sequência é bastante solto , e aparentemente os sinais GPI não são sequer homólogos , o que significa que não evoluíram a partir de uma sequência ancestral comum, mas sim que evoluíram de forma convergente, na medida em que existe mesmo alguma convergência. A melhor descrição que consegui encontrar é que (lendo N-to-C-terminal até o final da proteína) você precisa 1) cerca de 11 resíduos de um ligador não estruturado, 2) alguns resíduos com pequenas cadeias laterais incluindo um resíduo ω que pode ser S, N, D, G, A, ou C, 3) um espaçador de 5-10 aminoácidos polares, e finalmente 4) 15-20 aminoácidos hidrofóbicos . O PrP segue livremente este motivo. De acordo com estruturas publicadas , a hélice alfa 3 termina no resíduo Q223, que deixa o ‘linker não estruturado’ como apenas AYYQR (um pouco mais curto do que os 11 resíduos prescritos). A região ‘pequena cadeia lateral’ seria GS|SM (com o tubo denotando o local de corte da transamidase), a região polar seria VLFSSPP, e o terminal hidrofóbico C como VILLISFLIFLIVG.
Salgumas das proteínas da biossíntese GPI e da via de fixação são muito importantes, e foram descritas várias doenças graves e síndromes de deficiência da âncora GPI, devido à perda de função bialleica ou a mutações de falta de sentido aparentemente hipomórfica em genes como PIGO, PIGV, PIGW, PGAP2, e PGAP3 .
Sonia encontrou um excelente trabalho de alguns anos atrás onde eles fizeram uma tela de mutagênese em células humanas haplóides para identificar genes necessários para a biogênese de duas proteínas ancoradas em GPI: PrP e CD59 . Eles usaram a classificação repetida de células FACS baseada na superfície celular PrP e CD59 a fim de identificar células com níveis de superfície dramaticamente reduzidos dessas proteínas, e então fizeram seqüenciamento para ver quais nocaute de genes foram enriquecidos nessas células em relação à população mãe. Como seria de esperar, a maioria dos genes PIG surgiram para ambas as proteínas (Figura 4), mas nem todos os hits se sobrepuseram, o que é um pouco surpreendente, especialmente porque ao nível do RNA, pelo menos, PrP e CD59 são duas das proteínas com perfis de expressão mais semelhantes nos tecidos (ver mapa de calor na parte inferior deste post). Um monte de enzimas envolvidas na modificação da cadeia lateral da âncora GPI apareceu apenas para CD59, sugerindo que a CD59, mas não a PrP, precisa dessas cadeias laterais complexas para amadurecer e alcançar a superfície celular. Enquanto isso, Sec62 e Sec63 apareceram apenas para PrP – estas são proteínas de alguma forma envolvidas na translocação co-tradicional para o ER, mas aparentemente, elas são necessárias para PrP mas não para CD59, nem para CD55 ou CD109, duas outras proteínas de controle que eles observaram. Este é um novo capítulo fascinante na resposta à minha pergunta, “há algo de especial na expressão da PrP?”, onde eu estava procurando por algo único sobre a biogênese da PrP que pudesse ser potencialmente recarregável com uma pequena molécula. Claro, só porque estas proteínas não eram importantes para três outras proteínas de controle não significa que não sejam importantes – um estudo descobriu que o Sec62 era necessário para a secreção de muitas proteínas pequenas, e o gene SEC62 está totalmente esgotado para variantes de perda de função na população humana, o suficiente para sugerir haploinsuficiência. O SEC63 parece menos limitado, embora isso só poderia significar que ele age de forma recessiva.
Nenhum dos itens acima responde à questão de por que existem proteínas com âncora de GPI. A propósito, minha antiga classe de biologia celular omitiu um detalhe: existe na verdade uma sexta classe de proteínas de membrana, chamadas de proteínas ancoradas na cauda (TA) , que têm apenas um termo C hidrofóbico que se fixa na membrana mas não se projeta para fora do outro lado. Por que todas essas proteínas GPI ancoradas não poderiam ser apenas proteínas TA? Por que as células desenvolveram um caminho tão complicado para sintetizar uma âncora de gordura de açúcar, e por que elas a desenvolveram tão cedo no jogo – âncoras GPI estão presentes em todos os eucariotas, incluindo em muitos patógenos unicelulares que infectam humanos.
A maior parte das revisões não gastou muito tempo nesta questão, provavelmente porque é a coisa mais difícil de responder. As próprias proteínas ancoradas em GPI, na medida em que suas funções nativas são conhecidas, têm uma gama enorme de funções – há enzimas (como AChE), moléculas de adesão celular (como NCAM1), proteínas que regulam o complemento no sistema imunológico (CD59), e assim por diante. Aparentemente, existe pelo menos uma proteína GPI envolvida na manutenção da mielina nos nervos periféricos. Mas o que é que as proteínas com GPI podem fazer exactamente que as outras proteínas não podem? Uma revisão cita algumas idéias que foram propostas. Uma delas é que as proteínas com âncora GPI são boas em dimerizar transitoriamente . Alguns estudos exploraram a idéia de que a homodimerização desempenha algum papel na biologia do prião, embora a relevância dos sistemas modelo ali utilizados para a situação in vivo ainda não esteja clara. Outra idéia é que, como as proteínas ancoradas em GPI podem ser eliminadas da superfície celular, por exemplo, pela enzima conversora de angiotensina (ACE), sua localização pode ser regulada de alguma forma dinâmica. Aqui também, sabemos que a PrP pode ser eliminada, aparentemente pela enzima ADAM10 , embora qualquer papel na função nativa da PrP ainda não esteja claro. Uma terceira idéia, e talvez a que eu mais tenha ouvido falar, é que as proteínas ancoradas em GPI se reúnem seletivamente em “jangadas lipídicas” . Esta é talvez a explicação mais sedutora, porque você poderia imaginar todos os tipos de efeitos de arrastamento, onde o aumento da concentração local efetiva dessas proteínas permite mais interações, e assim por diante. Mas uma revisão apontou que uma ressalva é que as jangadas lipídicas ainda são mais uma idéia abstrata do que uma coisa concreta – enquanto são funcionalmente definidas pela insolubilidade do detergente e a maioria das pessoas as descreve como sendo ricas em esfingomielina e colesterol, não há uma definição universalmente aceita do que é e não é uma jangada lipídica, e as evidências empíricas sugerem que elas podem ser muito menores e mais transitórias do que a maioria das pessoas pensa.
Com essa leitura em mãos, eu me propus a obter uma lista dessas proteínas e fazer algumas análises sobre elas para ver se eu poderia ter uma melhor noção de como elas são.
análises
Uniprot tem uma lista de 173 proteínas humanas ancoradas em GPI. Estes mapeados para 140 símbolos genéticos, que caíram para 135 depois de executar este script para atualizar para os símbolos genéticos de codificação de proteínas atualmente aprovados pelo HGNC. A lista final de 135 símbolos de genes está aqui.
Uniprot não oferece nenhuma informação sobre como as suas anotações foram geradas, embora deva haver um grau significativo de cura manual. Para comparação, Andrew também desenterrou uma série de artigos que usaram PI-PLD ou PI-PLC, duas enzimas que clivam âncoras GPI, para isolar empiricamente proteínas GPI-anchored das células . A combinação de listas desses trabalhos e o mapeamento dos símbolos genéticos atuais produziu 107 genes. Nós verificamos vários destes ao acaso. Entre eles estavam proteínas GPI-anchored bem conhecidas, tais como glicopican-1 (GPC1) e molécula de adesão de células neurais (NCAM1), ambas relatadas como tendo interações com PrP . Mas também estavam presentes vários genes pelos quais nenhuma ancoragem GPI parecia ser conhecida na literatura, como o VDAC3, alguns dos quais podem ser simplesmente proteínas muito abundantes ou falsos positivos por outros motivos. Entretanto, existem fontes óbvias de falsos negativos: genes que simplesmente não foram expressos na linha celular estudada, ou não foram abundantes o suficiente para serem captados por espectros de massa, e os parálogos PrP SPRN e PRND não estavam nas listas. No total, 51 genes estavam em ambas as listas, um enriquecimento altamente significativo (OR = 217, P < 1 × 10-84), o que me ajuda a assegurar que as anotações da Uniprot são consistentes com os dados empíricos. Mas para mais análises, decidimos ir com a lista Uniprot, pois parece mais sensível e específica.
Armado com esta lista, eu queria ver como as proteínas ancoradas em GPI se acumulam. PrP é um exon único, curto (208 aminoácidos na sua forma madura), não essencial, proteína amplamente expressa. Estas características são típicas ou atípicas para uma proteína ancorada em GPI?
Acontece que as proteínas ancoradas em GPI estão em todo o mapa, tão variáveis em cada dimensão que eu olhei como qualquer outro conjunto de proteínas.
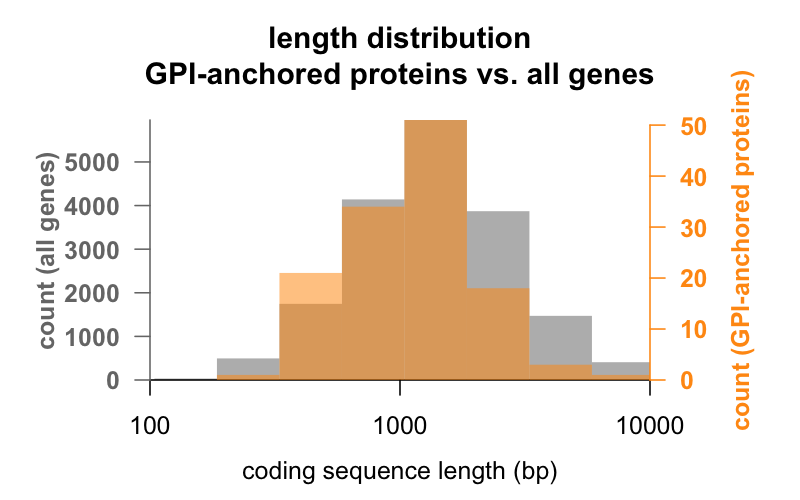
Primeiro, comprimento. Abaixo estão histogramas sobrepostos do comprimento da seqüência de codificação em pares de base para todos os genes, versus genes que codificam as proteínas ancoradas em GPI. A distribuição das proteínas ancoradas por GPI é apenas deslocada para a esquerda. A média do gene de proteínas ancoradas em GPI tem 1.301 bp de sequência de codificação, enquanto o gene médio tem 1.729, mas esta diferença de médias é pequena em comparação com a variação dentro de cada grupo. O PrP, com apenas 762 bp de sequência de codificação, está definitivamente no lado pequeno, embora de forma alguma seja um outlier em ambos os grupos – CD52, com apenas 186 pares de bases de sequência e aparentemente apenas 12 aminoácidos na sua forma madura , é a menor proteína GPI-anchored protein.
E quanto ao número de exons? As proteínas hipercalcinadas GPI têm, em média, um pouco menos exões, em comparação com todos os genes (média 7,8 vs. 10,1), consistente com a leve diferença de distribuição de comprimento observada acima, mas a maioria é multi-exões. Aqui, também, o PrP está no lado pequeno: existem apenas seis proteínas GPI-anchored que têm apenas 1 exon de codificação, e três delas são PrP e seus dois parálogos, Sho e Dpl. (Os outros três genes são GAS1, SPACA4, e o fabulosamente chamado OMG).
Nexterior Eu olhei para a restrição de perda de função. A restrição é uma medida de quão forte é a seleção natural de um gene, baseada no quão depauperado ele está para, digamos, disparate, mudança de estrutura, e variação do local de emenda na população geral, em comparação com a expectativa baseada nas taxas de mutação. Essa métrica não é muito interpretável para genes curtos, tanto por razões estatísticas (o número de mutações esperadas é baixo para genes curtos, então é difícil quantificar o esgotamento) quanto por razões biológicas (genes exon únicos não estão sujeitos à decadência mediada pelo absurdo, então é mais difícil saber se as variantes de truncagem de proteínas são realmente “perda de função” ou não). Mas uma vez que a maioria das proteínas com âncora GPI não são tão pequenas como a PrP, achei que valia a pena dar uma olhada. O resultado: em média, as proteínas ancoradas em GPI são apenas ligeiramente menos condicionadas, o que significa que têm mais da sua quantidade esperada de variação de perda de função, do que o gene médio. O gene médio tem 47% de sua variação de perda de função, e as proteínas ancoradas em GPI têm 56%. Mas como em tudo aqui, há uma ampla distribuição em ambos os campos. Para as proteínas ancoradas em GPI, você tem o ACHE (17 LoFs esperados e nenhum observado) absolutamente restrito em uma ponta e, na outra ponta, vários genes que parecem não estar sob nenhuma seleção contra perda de função – CNTN6, CD109, TREH, e MSLN são alguns exemplos. O PRNP cai neste último campo uma vez que se excluem os resíduos ≥145 onde as variantes de transuncação de proteínas causam um ganho de função .
Finalmente, eu me perguntava onde as proteínas com GPI são expressas. O PRNP é mais alto no cérebro, mas é expresso em todos os lugares. Isso é típico? Eu baixei o arquivo de resumo completo do GTEx v7 “gene median tpm” (Jan 15, 2016), onde cada linha é um gene e cada coluna é um tecido e as células são RPKMs – RNA-seq lê por kilobase de exon por milhão de leituras mapeadas. Trabalhar com este conjunto de dados requereu alguns aperfeiçoamentos. Ouvi dizer que alguns bioinformáticos consideram <1 RPKM a ser “não expresso” mas a matriz de expressão é esparsa – a maioria dos genes não são altamente expressos na maioria dos tecidos – por isso o ruído abaixo de 1 RPKM pode dominar se você apenas traçar os RPKMs brutos. Entretanto, a expressão gênica é algo que você precisa pensar em uma escala de log, pois os genes em um tecido podem variar de <1 RPKM a >10,000 RPKM, então se você considerar tudo em uma escala linear, então as poucas combinações genes/tecidos realmente altamente expressos também podem dominar, fazendo a matriz parecer ainda mais sparser do que ela é. Portanto, tomei log10 da matriz e trunquei a distribuição em , assim, a escala roxa que usei corre 1 – 10 – 100 – 1.000 – 10.000 RPKM. Em seguida, sub-conjunto com as proteínas Uniprot ancoradas em GPI. Para visualizar isto, fiz um mapa de calor pela primeira vez na minha vida. Já as vi muitas vezes em jornais e elas normalmente não falam comigo, mas aqui meu objetivo era apenas obter um sentido do padrão de expressão, e depois de brincar um pouco, isto foi o que me deu mais insight. O princípio de um mapa de calor é que as linhas e as colunas estão agrupadas para que coisas semelhantes andem juntas. Assim, por exemplo, todas as colunas de tecido cerebral são alinhadas consecutivamente num remendo no eixo x, e todos os genes altamente expressos pelo cérebro são alinhados consecutivamente num remendo no eixo y, de modo que a sua intersecção forma um denso retângulo roxo que pode ser interpretado como, “existe um aglomerado de genes que são na sua maioria expressos pelo cérebro”.
Os leitores interessados podem ver o PDF da arte vetorial em escala real do mapa térmico, mas para torná-lo mais imediatamente acessível, aqui está uma versão anotada à mão chamando os clusters de interesse:
A resposta, então, é não – a maioria das proteínas com GPI não tem o mesmo padrão de expressão que o PRNP. O PRNP é uma das poucas proteínas de expressão mais elevada e ampla, apresentando perto do topo deste mapa térmico, juntamente com CD59, LY6E, GPC1, e BST2. A maior parte das proteínas com GPI tem expressão mais baixa ou mais restrita aos tecidos, com algumas quase exclusivamente expressas no cérebro e outras quase exclusivamente não expressas no cérebro, e outros grupos menores pertencentes principalmente a tecidos específicos como os testículos, como o PRND paralógico do PrP, cujo nocaute causa esterilidade masculina.
conclusões
proteínas com âncora de GPI podem ser de qualquer tamanho, expressas em praticamente qualquer tecido, e aparentemente ter praticamente qualquer função, na medida em que suas funções são conhecidas. Muitas proteínas ancoradas em GPI têm funções nativas muito claras, mas estas funções são diversas e não é claro porque requerem ancoragem GPI, especialmente porque muitas destas proteínas também existem em isoformas não ancoradas em GPI. Entretanto, para outras proteínas ancoradas em GPI, incluindo PrP, sabemos pouco sobre a função nativa para começar, então é difícil até mesmo especular por que a função nativa requer ancoragem GPI. Nenhuma das análises que fiz ou revisões que li foi capaz de desenhar um princípio unificador sobre a razão pela qual este mecanismo de ancoragem existe ou o que faz com que estas proteínas o exijam. Há uma série de hipóteses para o porquê das proteínas ancoradas em GPI serem únicas, incluindo jangadas lipídicas, homodímeros e desprendimento. Todas estas hipóteses podem conter alguma água. Mas no final das contas, a resposta parece improvável que seja um momento eureka, mas ao invés disso, como tanta da biologia, uma mistura prosaica de coisas diferentes.
R código e arquivos de dados brutos para análises neste post estão aqui.