Última atualização em 18 de agosto de 2020
Dadosets podem ter valores em falta, e isso pode causar problemas para muitos algoritmos de aprendizagem de máquinas.
Assim, é uma boa prática identificar e substituir valores em falta para cada coluna nos dados de entrada antes de modelar a sua tarefa de previsão. Isto é chamado de imputação de dados ausentes, ou imputação para abreviar.
Uma abordagem popular para a imputação de dados é calcular um valor estatístico para cada coluna (como uma média) e substituir todos os valores ausentes para aquela coluna com a estatística. É uma abordagem popular porque a estatística é fácil de calcular usando o conjunto de dados de treinamento e porque muitas vezes resulta em bom desempenho.
Neste tutorial, você descobrirá como usar estratégias de imputação estatística para dados ausentes na aprendizagem de máquinas.
Após completar este tutorial, você saberá:
- Valores ausentes devem ser marcados com valores NaN e podem ser substituídos por medidas estatísticas para calcular a coluna de valores.
- Como carregar um valor CSV com valores ausentes e marcar os valores ausentes com valores NaN e informar o número e percentagem de valores ausentes para cada coluna.
- Como imputar valores ausentes com estatísticas como método de preparação de dados ao avaliar modelos e ao encaixar um modelo final para fazer previsões sobre novos dados.
Primeiro arranque do seu projecto com o meu novo livro Data Preparation for Machine Learning, incluindo tutoriais passo-a-passo e os ficheiros de código fonte Python para todos os exemplos.
Vamos começar.
- Actualizado Jun/2020: Alterada a coluna utilizada para previsão em exemplos.

Imputação Estatística para Valores Faltantes no Aprendizado de Máquinas
Foto por Bernal Saborio, alguns direitos reservados.
Visão geral do tutorial
Este tutorial está dividido em três partes; elas são:
- Imputação Estática
- Dados de Cólicas de Cavalo
- Imputação Estática Com SimpleImputer
- Transformação de Dados SimpleImputer
- SimpleImputer e Avaliação de Modelos
- Comparando Diferentes Estatísticas Imputadas
- SimplesImputer Transform When Making a Prediction
Imputação Estatística
Um conjunto de dados pode ter valores em falta.
>
Estas são linhas de dados onde um ou mais valores ou colunas naquela linha não estão presentes. Os valores podem estar faltando completamente ou podem estar marcados com um caracter ou valor especial, como um ponto de interrogação “?”.
Estes valores podem ser expressos de várias maneiras. Já os vi aparecerem como nada , uma string vazia , a string explícita NULL ou indefinida ou N/A ou NaN, e o número 0, entre outros. Não importa como eles aparecem em seu conjunto de dados, sabendo o que esperar e verificando para ter certeza de que os dados correspondem a essa expectativa irá reduzir problemas à medida que você começar a usar os dados.
– Página 10, Bad Data Handbook, 2012.
Valores podem estar faltando por muitas razões, muitas vezes específicas para o domínio do problema, e podem incluir razões como medições corruptas ou indisponibilidade de dados.
Podem ocorrer por uma série de razões, tais como mau funcionamento do equipamento de medição, alterações no projeto experimental durante a coleta de dados e compilação de vários conjuntos de dados semelhantes, mas não idênticos.
– Página 63, Data Mining: Ferramentas e Técnicas Práticas de Aprendizagem de Máquinas, 2016.
Mais avançados algoritmos de aprendizagem de máquinas requerem valores de entrada numéricos, e um valor para estar presente em cada linha e coluna de um conjunto de dados. Como tal, valores ausentes podem causar problemas para algoritmos de aprendizagem de máquinas.
Como tal, é comum identificar valores ausentes num conjunto de dados e substituí-los por um valor numérico. Isto é chamado imputação de dados, ou imputação de dados ausentes.
Uma abordagem simples e popular à imputação de dados envolve o uso de métodos estatísticos para estimar um valor para uma coluna a partir daqueles valores que estão presentes, em seguida, substituir todos os valores ausentes na coluna com a estatística calculada.
É simples porque as estatísticas são rápidas de calcular e é popular porque muitas vezes se mostra muito eficaz.
As estatísticas comuns calculadas incluem:
- O valor médio da coluna.
- O valor médio da coluna.
- O valor do modo coluna.
- Um valor constante.
Agora estamos familiarizados com métodos estatísticos para imputação de valores ausentes, vamos dar uma olhada em um conjunto de dados com valores ausentes.
Quer começar com a preparação de dados?
Tomar meu curso crash de 7 dias grátis por e-mail agora (com código de amostra).
Clique para se inscrever e também obter uma versão PDF Ebook grátis do curso.
Download Your FREE Mini-Course
Horse Colic Dataset
O conjunto de dados de cólicas em cavalos descreve as características médicas dos cavalos com cólicas e se eles viveram ou morreram.
Existem 300 linhas e 26 variáveis de entrada com uma variável de saída. É uma tarefa de previsão de classificação binária que envolve prever 1 se o cavalo viveu e 2 se ele morreu.
Existem muitos campos que poderíamos selecionar para prever neste conjunto de dados. Neste caso, vamos prever se o problema foi cirúrgico ou não (índice da coluna 23), tornando-o um problema de classificação binária.
O conjunto de dados tem inúmeros valores em falta para muitas das colunas onde cada valor em falta é marcado com um ponto de interrogação (“?”).
Below fornece um exemplo de linhas do conjunto de dados com valores em falta marcados.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Você pode aprender mais sobre o conjunto de dados aqui:
- Dataset de Cólicas de Cavalo
- Dataset de Cólicas de Cavalo Descrição
Não é necessário fazer o download do conjunto de dados, pois nós o faremos automaticamente nos exemplos trabalhados.
Marcar valores ausentes com um valor NaN (não um número) em um conjunto de dados carregado usando Python é uma melhor prática.
Podemos carregar o conjunto de dados usando a função read_csv() Pandas e especificar os “na_values” para carregar valores de ‘?como faltando, marcado com um valor naN.
|
1
2
3
4
|
…
# carregar conjunto de dados
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
|
Once loaded, podemos rever os dados carregados para confirmar que “?” são marcados como NaN.
|
1
2
3
|
…
# resumir as primeiras linhas
print(dataframe.head())
|
Podemos então enumerar cada coluna e reportar o número de linhas com valores em falta para a coluna.
|
1
2
3
4
5
6
7
|
…
# resume o número de linhas com valores em falta para cada coluna
para i no intervalo(dataframe.shape):
# contar número de linhas com valores em falta
n_miss = dataframe].isull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Desaparecido: %d (%.1f%%)’ % (i, n_miss, perc))
|
Aplicando isto, o exemplo completo de carregamento e resumo do conjunto de dados está listado abaixo.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# resumir o conjunto de dados de cólicas de cavalo
da importação de pandas read_csv
# carregar conjunto de dados
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# resume as primeiras linhas
print(dataframe.head())
# resume o número de linhas com valores em falta para cada coluna
para i no intervalo(dataframe.shape):
# contar número de linhas com valores em falta
n_miss = dataframe].isull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Missing: %d (%.1f%%)’ % (i, n_miss, perc))
|
Executar o exemplo primeiro carrega o conjunto de dados e resume as primeiras cinco linhas.
Vemos que os valores em falta que estavam marcados com um caractere “?” foram substituídos por valores NaN.
Próximo, podemos ver a lista de todas as colunas do conjunto de dados e o número e percentagem de valores em falta.
Podemos ver que algumas colunas (por exemplo, índices de coluna 1 e 2) não têm valores em falta e outras colunas (por exemplo, índices de coluna 15 e 21) têm muitos ou mesmo a maioria dos valores em falta.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Missing: 1 (0,3%)
> 1, Em falta: 0 (0,0%)
> 2, Falta: 0 (0,0%)
> 3, Falta: 60 (20,0%)
> 4, Falta: 58 (19,3%)
> 6, Faltam: 56 (18,7%)
> 7, Faltam: 69 (23,0%)
> 8, Faltam: 47 (15,7%)
> 9, Faltam: 32 (10,7%)
> 10, Faltam: 55 (18,3%)
> 11, Faltam: 44 (14,7%)
> 12, Faltam: 56 (18,7%)
> 13, Faltam: 104 (34,7%)
> 14, Faltam: 106 (35,3%)
> 15, Faltam: 247 (82,3%)
> 16, Faltam: 102 (34,0%)
> 17, Faltam: 118 (39,3%)
> 18, Faltam: 29 (9,7%)
> 19, Faltam: 33 (11,0%)
> 20, Faltam: 198 (66,0%)
> 22, Faltam: 1 (0,3%)
> 23, Faltam: 0 (0,0%)
> 24, Faltam: 0 (0,0%)
|
Agora estamos familiarizados com o conjunto de dados de cólicas de cavalos que tem valores em falta, vamos ver como podemos usar a imputação estatística.
Imputação estatística com o SimpleImputer
A biblioteca de aprendizagem da máquina Scikit-learn fornece a classe SimpleImputer que suporta a imputação estatística.
Nesta seção, vamos explorar como usar efetivamente a classe SimpleImputer.
Transformação de Dados do SimpleImputer
O SimpleImputer é uma transformação de dados que é configurada primeiro com base no tipo de estatística a ser calculada para cada coluna, e.g. média.
|
1
2
3
|
…
# definir imputador
imputador = SimpleImputer(strategy=’mean’)
|
Então o imputador é ajustado em um conjunto de dados para calcular a estatística para cada coluna.
|
1
2
3
|
…
# cabe no conjunto de dados
imputer.fit(X)
|
O imputer.fit é então aplicado a um conjunto de dados para criar uma cópia do conjunto de dados com todos os valores em falta para cada coluna substituída por um valor estatístico.
|
1
2
3
|
…
# transformar o conjunto de dados
Xtrans = imputer.transform(X)
|
Podemos demonstrar o seu uso no conjunto de dados de cólicas do cavalo e confirmar que funciona resumindo o número total de valores em falta no conjunto de dados antes e depois da transform.
O exemplo completo está listado abaixo.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# imputação estatística transform for the horse colic dataet
from numpy import isan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# carregar conjunto de dados
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# dividir em elementos de entrada e saída
data = dataframe.values
ix = ) if i != 23]
X, y = dados, dados
# impressão total em falta
impressão(‘Em falta: %d’ % soma(isan(X).flatten()))
# definir imputer
imputer = SimpleImputer(strategy=’mean’)
# caber no conjunto de dados
imputer.fit(X)
# transformar o conjunto de dados
Xtrans = imputer.transform(X)
# imprimir total em falta
imprimir(‘Em falta: %d’ % soma(isan(Xtrans).achatar()))
|
Executar o exemplo primeiro carrega o conjunto de dados e reporta o número total de valores em falta no conjunto de dados como 1.605,
A transformação é configurada, ajustada e realizada e o novo conjunto de dados resultante não tem valores em falta, confirmando que foi realizada como esperávamos.
Cada valor em falta foi substituído pelo valor médio da sua coluna.
|
1
2
|
Missing: 1605
Sissing: 0
|
SimpleImputer and Model Evaluation
É uma boa prática avaliar modelos de aprendizagem de máquinas num conjunto de dados usando a validação cruzada k-fold.
Para aplicar correctamente a imputação de dados estatísticos em falta e evitar fugas de dados, é necessário que as estatísticas calculadas para cada coluna sejam calculadas apenas no conjunto de dados de formação, depois aplicadas ao comboio e aos conjuntos de teste para cada dobra no conjunto de dados.
Se estamos usando a resampling para selecionar valores de parâmetros de ajuste ou para estimar o desempenho, a imputação deve ser incorporada dentro da resampling.
– Página 42, Applied Predictive Modeling, 2013.
Isto pode ser alcançado criando um pipeline de modelagem onde o primeiro passo é a imputação estatística, depois o segundo passo é o modelo. Isto pode ser alcançado usando a classe Pipeline.
Por exemplo, o Pipeline abaixo usa um SimpleImputer com uma estratégia ‘média’, seguido por um modelo florestal aleatório.
|
1
2
3
4
5
|
…
# definir modeling pipeline
modelo = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
|
Podemos avaliar a média…conjunto de dados imputados e pipeline de modelagem florestal aleatória para o conjunto de dados sobre cólicas em cavalos com validação cruzada repetida de 10 vezes.
O exemplo completo está listado abaixo.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# avaliar a imputação média e aleatória floresta para o conjunto de dados de cólicas do cavalo
da média de importação numpy
da importação numpy std
da importação pandas read_csv
da sklearn.importação de conjuntos RandomForestClassifier
de sklearn.impute importação SimpleImputer
de sklearn.model_selection importação cross_val_score
de sklearn.model_selection importação RepeatedStratifiedKFold
de sklearn.pipeline import Pipeline
# carregar conjunto de dados
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# dividir em elementos de entrada e saída
data = dataframe.values
ix = ) if i != 23]
X, y = dados, dados
# definir modeling pipeline
modelo = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
# definir model evaluation
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# avaliar modelo
pontuação = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
imprimir(‘Precisão média: %.3f (%.3f)’ % (média(pontuação), std(pontuação)))
|
Executar correctamente o exemplo aplica a imputação de dados a cada dobra do procedimento de validação cruzada.
Nota: Os seus resultados podem variar dada a natureza estocástica do algoritmo ou procedimento de avaliação, ou diferenças na precisão numérica. Considere executar o exemplo algumas vezes e compare o resultado médio.
O pipeline é avaliado usando três repetições de 10 vezes a validação cruzada e reporta a precisão média da classificação no conjunto de dados como cerca de 86.3 por cento, o que é uma boa pontuação.
|
1
|
Exatidão do comportamento: 0,863 (0.054)
|
Comparando Diferentes Estatísticas Imputadas
Como sabemos que a utilização de uma estratégia estatística ‘média’ é boa ou melhor para este conjunto de dados?
A resposta é que não sabemos e que foi escolhida arbitrariamente.
Podemos desenhar um experimento para testar cada estratégia estatística e descobrir o que funciona melhor para este conjunto de dados, comparando a média, mediana, modo (mais freqüente), e estratégias constantes (0). A precisão média de cada abordagem pode então ser comparada.
O exemplo completo está listado abaixo.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# comparar estratégias de imputação estatística para o conjunto de dados de cólicas em cavalos
da média de importação numérica
da média de importação numérica std
da importação de pandas read_csv
da sklearn.importação de conjuntos RandomForestClassifier
de sklearn.impute importação SimpleImputer
de sklearn.model_selection importação cross_val_score
de sklearn.model_selection importação RepeatedStratifiedKFold
de sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataet
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# dividido em elementos de entrada e saída
data = dataframe.values
ix = ) se i != 23]
X, y = dados, dados
# avaliar cada estratégia no conjunto de dados
resultados = lista()
estratégias =
para s em estratégias:
# criar o pipeline de modelagem
pipeline = Pipeline(steps=)
# avaliar o modelo
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
pontuação = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
# armazenar resultados
resultados.append(scores)
print(‘>%s %.3f (%.3f)’ % (s, mean(scores), std(scores)))
# desempenho do modelo de gráfico para comparação
pyplot.boxplot(resultados, rótulos=estratégias, showmeans=verdade)
pyplot.show()
|
Executar o exemplo avalia cada estratégia de imputação estatística no conjunto de dados de cólicas do cavalo usando a validação cruzada repetida.
Nota: Os seus resultados podem variar dada a natureza estocástica do algoritmo ou procedimento de avaliação, ou diferenças na precisão numérica. Considere executar o exemplo algumas vezes e compare o resultado médio.
A precisão média de cada estratégia é relatada ao longo do caminho. Os resultados sugerem que usando um valor constante, por exemplo 0, resulta no melhor desempenho de cerca de 88,1 por cento, o que é um resultado excepcional.
|
1
2
3
4
|
>mean 0.860 (0,054)
>mediante 0,862 (0.065)
>most_frequent 0,872 (0,052)
>constant 0,881 (0,047)
|
No final da execução, é criada uma caixa e um gráfico de whisker para cada conjunto de resultados, permitindo comparar a distribuição dos resultados.
Vemos claramente que a distribuição das pontuações de precisão para a estratégia constante é melhor do que as outras estratégias.
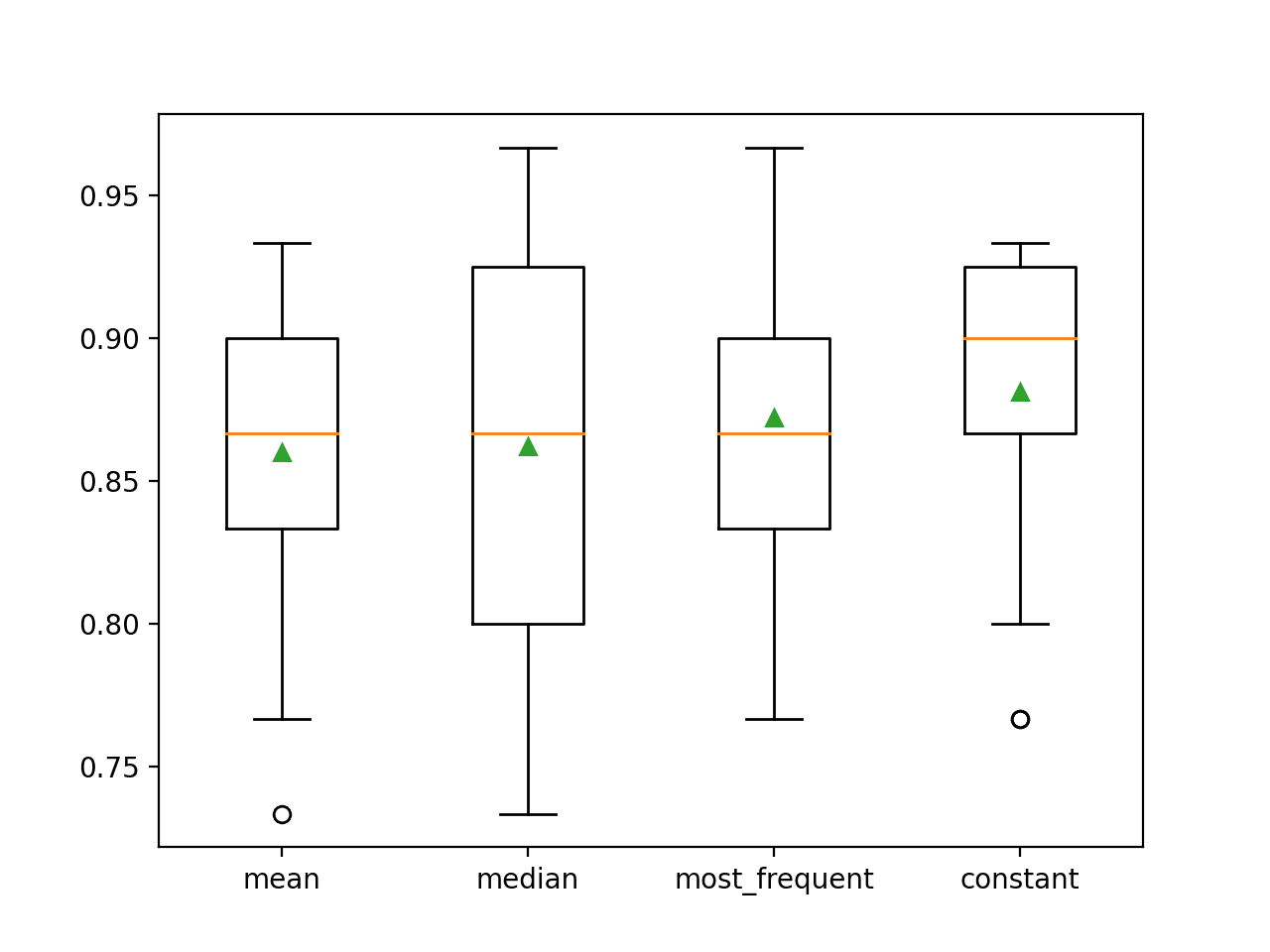
Box and Whisker Plot of Statistical Imputation Strategies Applied to the Horse Colic Dataset
SimpleImputer Transform When Making a Prediction
We may wish to create a final modeling pipeline with the constant imputation strategy and random forest algorithm, then make a prediction for new data.
Isso pode ser conseguido definindo o pipeline e encaixando-o em todos os dados disponíveis, então chamando a função predict() passando novos dados como um argumento.
Importantemente, a linha de novos dados deve marcar quaisquer valores ausentes usando o valor NaN.
|
1
2
3
|
…
# definir novos dados
linha =
|
O exemplo completo está listado abaixo.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
> |
# imputação constante estratégia e previsão para o conjunto de dados de cólicas da mangueira
da importação numpy nan
da importação pandas read_csv
da sklearn.ensemble import RandomForestClassifier
de sklearn.impute import SimpleImputer
de sklearn.pipeline import Pipeline
# conjunto de dados de carga
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# dividido em elementos de entrada e saída
data = dataframe.values
ix = ) se i != 23]
X, y = dados, dados
# criar o modelo pipeline
pipeline = Pipeline(steps=)
# encaixar no modelo
pipeline.fit(X, y)
# definir novos dados
# linha =
# fazer uma previsão
> yhat = pipeline.prever()
# resumir previsão
imprimir(‘Predicted Class: %d’ % yhat)
|
Executar o exemplo encaixa no pipeline de modelagem em todos os dados disponíveis.
Uma nova linha de dados é definida com valores em falta marcados com NaNs e é feita uma previsão de classificação.
|
>1
|
Classe Prevista: 2
|
Outras Leituras
Esta secção fornece mais recursos sobre o tópico se você estiver procurando ir mais fundo.
Tutoriais relacionados
- Resultados para Datasets de Aprendizagem de Máquinas de Classificação e Regressão Padrão
- Como lidar com dados ausentes com Python
Livros
- Manual de Dados Maus, 2012.
- Mineração de Dados: Ferramentas e Técnicas Práticas de Aprendizagem de Máquina, 2016.
- Modelagem Preditiva Aplicada, 2013.
APIs
- Imputação de valores em falta, Scikit-learn Documentation.
- sklearn.impute.SimpleImputer API.
Dataset
- Dataset de Cólicas de Cavalo
- Dataset de Cólicas de Cavalo
Sumário
Neste tutorial, você descobriu como usar estratégias de imputação estatística para dados faltantes na aprendizagem de máquinas.
Especificamente, você aprendeu:
- Os valores ausentes devem ser marcados com valores de NaN e podem ser substituídos por medidas estatísticas para calcular a coluna de valores.
- Como carregar um valor CSV com valores ausentes e marcar os valores ausentes com valores de NaN e informar o número e a percentagem de valores ausentes para cada coluna.
- Como imputar valores ausentes com estatísticas como um método de preparação de dados ao avaliar modelos e ao ajustar um modelo final para fazer previsões sobre novos dados.
Você tem alguma pergunta?
Ponha as suas questões nos comentários abaixo e farei o meu melhor para responder.
Controle a Preparação de Dados Modernos!

Prepare Your Machine Learning Data in Minutes
…com apenas algumas linhas de código python
Descubra como no meu novo Ebook:
Preparação de Dados para Aprendizagem de Máquina
Fornece tutoriais de auto-estudo com código de trabalho completo em:
Selecção de Características, RFE, Limpeza de Dados, Transformações de Dados, Escalonamento, Redução de Dimensões, e muito mais…
Bring Modern Data Preparation Techniques to
Your Machine Learning Projects
See What’s Inside