Posted on August 27, 2015
Redes Neurais Atuais
Humans não começam a pensar do zero a cada segundo. Ao ler este ensaio, você entende cada palavra com base na sua compreensão das palavras anteriores. Você não joga tudo fora e começa a pensar a partir do zero novamente. Seus pensamentos têm persistência.
As redes neurais tradicionais não podem fazer isso, e parece ser uma grande falha. Por exemplo, imagine que você quer classificar que tipo de evento está acontecendo em cada ponto de um filme. Não está claro como uma rede neural tradicional poderia usar seu raciocínio sobre eventos anteriores no filme para informar eventos posteriores.
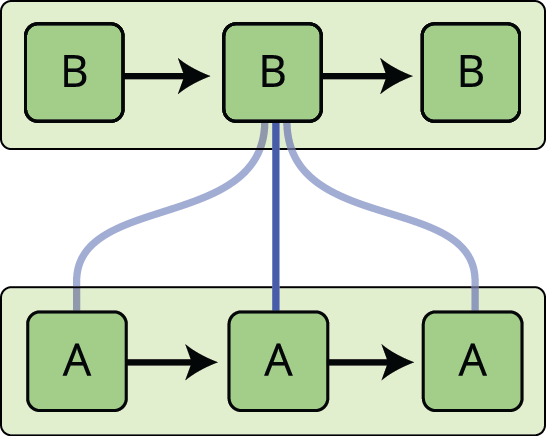
Rede neural atual aborda este problema. São redes com loops nelas, permitindo que a informação persista.

No diagrama acima, um pedaço da rede neural, \(A\), olha para alguma entrada \(x_t\) e sai um valor \(h_t\). Um loop permite que informações sejam passadas de um passo da rede para o próximo.
Esses loops fazem as redes neurais recorrentes parecerem um pouco misteriosas. Entretanto, se você pensar um pouco mais, acontece que eles não são tão diferentes de uma rede neural normal. Uma rede neural recorrente pode ser considerada como várias cópias da mesma rede, cada uma passando uma mensagem para um sucessor. Considere o que acontece se desenrolarmos o loop:

Esta natureza em cadeia revela que as redes neurais recorrentes estão intimamente relacionadas a sequências e listas. Elas são a arquitetura natural da rede neural a ser usada para tais dados.
E elas certamente são usadas! Nos últimos anos, tem havido um sucesso incrível aplicando RNNs a uma variedade de problemas: reconhecimento de fala, modelagem de linguagem, tradução, legendagem de imagens… A lista continua. Vou deixar a discussão sobre os feitos incríveis que se pode conseguir com os RNNs para o excelente post do blog de Andrej Karpathy, The Unreasonable Effectiveness of Recurrent Neural Networks (A Eficácia Irrazoável das Redes Neurais Recorrentes). Mas eles são realmente incríveis.
Essencial para estes sucessos é o uso de “LSTMs”, um tipo muito especial de rede neural recorrente que funciona, para muitas tarefas, muito melhor do que a versão padrão. Quase todos os resultados interessantes baseados em redes neurais recorrentes são alcançados com elas. São esses LSTMs que este ensaio explorará.
O problema das dependências de longo prazo
Um dos apelos dos RNNs é a idéia de que eles podem ser capazes de conectar informações anteriores à tarefa presente, como o uso de quadros de vídeo anteriores pode informar o entendimento do quadro presente. Se os RNNs pudessem fazer isso, eles seriam extremamente úteis. Mas eles podem? Depende.
Por vezes, só precisamos de olhar para informações recentes para executar a tarefa presente. Por exemplo, considere um modelo de linguagem tentando prever a próxima palavra com base nas anteriores. Se estamos tentando prever a última palavra em “as nuvens estão no céu”, não precisamos de nenhum contexto adicional – é bastante óbvio que a próxima palavra será céu. Nesses casos, onde o espaço entre a informação relevante e o lugar que é necessário é pequeno, os RNNs podem aprender a usar a informação passada.

Mas também há casos em que precisamos de mais contexto. Considere tentar prever a última palavra no texto “Eu cresci na França… Eu falo francês fluente”. Informações recentes sugerem que a próxima palavra é provavelmente o nome de uma língua, mas se quisermos restringir qual língua, precisamos do contexto da França, a partir de mais atrás. É inteiramente possível que a lacuna entre a informação relevante e o ponto onde ela é necessária para se tornar muito grande.
Felizmente, à medida que essa lacuna cresce, os RNNs tornam-se incapazes de aprender a conectar a informação.

Em teoria, os RNNs são absolutamente capazes de lidar com tais “dependências de longo prazo”. Um humano poderia escolher cuidadosamente parâmetros para eles resolverem problemas de brinquedo desta forma. Infelizmente, na prática, os RNNs não parecem ser capazes de aprendê-los. O problema foi explorado em profundidade por Hochreiter (1991) e Bengio, et al. (1994), que encontraram algumas razões bastante fundamentais pelas quais poderia ser difícil.
Felizmente, os LSTMs não têm este problema!
LSTM Networks
Long Short Term Memory networks – geralmente chamados apenas de “LSTMs” – são um tipo especial de RNN, capazes de aprender dependências de longo prazo. Elas foram introduzidas por Hochreiter & Schmidhuber (1997), e foram refinadas e popularizadas por muitas pessoas no trabalho seguinte.1 Elas funcionam tremendamente bem em uma grande variedade de problemas, e agora são amplamente utilizadas.
LSTMs são explicitamente projetadas para evitar o problema de dependência de longo prazo. Lembrar informações por longos períodos de tempo é praticamente o comportamento padrão deles, não algo que eles lutam para aprender!
Todas as redes neurais recorrentes têm a forma de uma cadeia de módulos repetidos de redes neurais. Em RNNs padrão, este módulo de repetição terá uma estrutura muito simples, como uma única camada tanh.

LSTMs também têm esta estrutura em cadeia, mas o módulo de repetição tem uma estrutura diferente. Ao invés de ter uma única camada de rede neural, existem quatro, interagindo de uma forma muito especial.

Não se preocupe com os detalhes do que está acontecendo. Vamos caminhar através do diagrama LSTM passo a passo mais tarde. Por enquanto, vamos tentar ficar confortáveis com a notação que vamos usar.

No diagrama acima, cada linha carrega um vetor inteiro, desde a saída de um nó até as entradas de outros. Os círculos cor-de-rosa representam operações pontuais, como adição vetorial, enquanto as caixas amarelas são camadas de redes neurais aprendidas. Linhas fundindo denotam concatenação, enquanto uma forquilha de linha denotando seu conteúdo sendo copiado e as cópias indo para locais diferentes.
A idéia central atrás de LSTMs
A chave para LSTMs é o estado da célula, a linha horizontal correndo através do topo do diagrama.
O estado da célula é como uma correia transportadora. Ela percorre a corrente inteira, com apenas algumas pequenas interações lineares. É muito fácil para a informação simplesmente fluir ao longo dela inalterada.

O LSTM tem a capacidade de remover ou adicionar informação ao estado da célula, cuidadosamente regulada por estruturas chamadas gates.
Gates são uma forma opcional de deixar passar a informação. Eles são compostos por uma camada de rede neural sigmóide e uma operação de multiplicação pontual.

Os números de saída da camada sigmóide entre zero e um, descrevendo quanto de cada componente deve ser deixado passar. Um valor de zero significa “não deixar nada passar”, enquanto um valor de um significa “deixar tudo passar!”
Um LSTM tem três destas portas, para proteger e controlar o estado da célula.
Passo a passo do LSTM Walk Through
O primeiro passo do nosso LSTM é decidir que informação vamos jogar fora do estado da célula. Esta decisão é feita por uma camada sigmóide chamada de “esquece a camada do portão”. Ela olha para o estado da célula (h_t-1) e (x_t), e produz um número entre 0 e 1 para cada número no estado da célula (C_t-1). Um {\i1}(1\i} representa “manter isto completamente” enquanto um {\i} representa “livrar-se completamente disto”
Vamos voltar ao nosso exemplo de um modelo de linguagem que tenta prever a próxima palavra com base em todas as anteriores. Em tal problema, o estado celular pode incluir o gênero do sujeito atual, para que os pronomes corretos possam ser usados. Quando vemos um novo assunto, queremos esquecer o gênero do assunto antigo.

O próximo passo é decidir que nova informação vamos armazenar no estado celular. Isto tem duas partes. Primeiro, uma camada sigmóide chamada “input gate layer” decide quais os valores que vamos atualizar. Em seguida, uma camada tanh cria um vetor de novos valores candidatos, que poderiam ser adicionados ao estado. No próximo passo, vamos combinar estes dois para criar uma atualização para o estado.
No exemplo do nosso modelo de linguagem, queremos adicionar o gênero do novo sujeito ao estado da célula, para substituir o antigo que estamos esquecendo.

Agora é hora de atualizar o estado da célula antiga, { C_{t-1}}, para o novo estado da célula { C_t}. Os passos anteriores já decidiram o que fazer, só precisamos realmente fazê-lo.
Multiplicamos o estado antigo por \\(f_t), esquecendo as coisas que decidimos esquecer antes. Depois acrescentamos {\i1}(i_t**) até{C_t*). Estes são os novos valores dos candidatos, escalados pelo quanto decidimos atualizar cada valor de estado.
No caso do modelo de linguagem, é aqui que na verdade deixaríamos cair a informação sobre o sexo do sujeito antigo e adicionaríamos a nova informação, como decidimos nos passos anteriores.

Finalmente, precisamos decidir o que vamos sair. Esta saída será baseada no nosso estado celular, mas será uma versão filtrada. Primeiro, rodamos uma camada sigmóide que decide que partes do estado da célula vamos sair. Depois, colocamos o estado da célula através do {\tanh} (para empurrar os valores entre o {\tanh} e o {\tanh}) e o multiplicamos pela saída da porta sigmóide, de modo que só saímos as partes que decidimos.
Para o exemplo do modelo de linguagem, já que ele acabou de ver um assunto, ele pode querer sair informações relevantes a um verbo, caso seja isso o que está vindo a seguir. Por exemplo, ele pode sair se o assunto é singular ou plural, para que saibamos em que forma um verbo deve ser conjugado se é isso que vem a seguir.

Variantes em Memória de Longo Prazo Curto Prazo
O que descrevi até agora é um LSTM bastante normal. Mas nem todas as LSTMs são as mesmas que as anteriores. Na verdade, parece que quase todo papel envolvendo LSTMs usa uma versão ligeiramente diferente. As diferenças são menores, mas vale a pena mencionar algumas delas.
Uma variante popular da LSTM, introduzida por Gers & Schmidhuber (2000), está adicionando “conexões de peephole”. Isto significa que nós deixamos as camadas de gate olhar para o estado da célula.

O diagrama acima adiciona peepholes a todos os portões, mas muitos papéis darão alguns peepholes e não outros.
Uma outra variação é usar os portões de esquecimento e entrada acoplados. Ao invés de decidir separadamente o que esquecer e a que devemos adicionar novas informações, nós tomamos essas decisões juntos. Só nos esquecemos quando vamos inserir algo em seu lugar. Só introduzimos novos valores ao estado quando esquecemos algo mais antigo.

Uma variação um pouco mais dramática no LSTM é a Unidade Corrente Gated, ou GRU, introduzida por Cho, et al. (2014). Ela combina os portões de esquecimento e de entrada em um único “portão de atualização”. Ele também funde o estado da célula e o estado oculto, e faz algumas outras mudanças. O modelo resultante é mais simples do que os modelos LSTM padrão, e tem se tornado cada vez mais popular.

Estas são apenas algumas das variantes mais notáveis do LSTM. Existem muitas outras, como os RNNs com categoria de profundidade por Yao, et al. (2015). Há também algumas abordagens completamente diferentes para lidar com dependências de longo prazo, como RNNs de Clockwork por Koutnik, et al. (2014).
Qual destas variantes é a melhor? As diferenças são importantes? Greff, et al. (2015) fazem uma boa comparação das variantes populares, descobrindo que são todas mais ou menos as mesmas. Jozefowicz, et al. (2015) testaram mais de dez mil arquiteturas RNN, encontrando algumas que funcionavam melhor que as LSTMs em certas tarefas.
Conclusion
Earlier, mencionei os resultados notáveis que as pessoas estão alcançando com as RNNs. Essencialmente todos eles são alcançados usando LSTMs. Eles realmente funcionam muito melhor para a maioria das tarefas!
Escrevidas como um conjunto de equações, as LSTMs parecem bastante intimidadoras. Esperemos que, caminhando através deles passo a passo neste ensaio os tenha tornado um pouco mais acessíveis.
LSTMs foram um grande passo no que podemos alcançar com os RNNs. É natural que nos perguntemos: existe outro grande passo? Uma opinião comum entre os pesquisadores é: “Sim! Há um próximo passo e é a atenção!” A idéia é deixar que cada passo de um RNN escolha informações para ver a partir de uma coleção maior de informações. Por exemplo, se você está usando um RNN para criar uma legenda descrevendo uma imagem, ele pode escolher uma parte da imagem para olhar para cada palavra que sai. De facto, Xu, et al. (2015) fazem exactamente isto – pode ser um ponto de partida divertido se quiseres explorar a atenção! Tem havido uma série de resultados realmente emocionantes usando a atenção, e parece que muito mais estão ao virar da esquina…
Attenção não é a única linha emocionante na pesquisa do RNNN. Por exemplo, Grid LSTMs de Kalchbrenner, et al. (2015) parecem extremamente promissores. O trabalho usando RNNs em modelos generativos – como Gregor, et al. (2015), Chung, et al. (2015), ou Bayer & Osendorfer (2015) – também parece muito interessante. Os últimos anos têm sido uma época emocionante para redes neurais recorrentes, e as próximas prometem ser apenas mais!
Acknowledgments
I’m grateful to a number of people for help me better understand LSTMs, commenting on the visualizations, and providing feedback on this post.
Estou muito grato aos meus colegas no Google pelo seu feedback útil, especialmente Oriol Vinyals, Greg Corrado, Jon Shlens, Luke Vilnis, e Ilya Sutskever. Também estou grato a muitos outros amigos e colegas por me ajudarem, incluindo Dario Amodei, e Jacob Steinhardt. Estou especialmente grato a Kyunghyun Cho pela correspondência extremamente atenciosa sobre meus diagramas.
Antes deste post, eu pratiquei explicando LSTMs durante duas séries de seminários que eu ensinei em redes neurais. Agradeço a todos os que participaram daqueles por sua paciência comigo, e por seu feedback.
-
Além dos autores originais, muitas pessoas contribuíram para a RTB moderna. Uma lista não compreensiva é: Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustino Gomez, Matteo Gagliolo, e Alex Graves.
Outros Posts
Redes Neurais Atualizadas e Aumentadas
Em Destilação
Redes Neurais Atualizadas
Uma Perspectiva Modular
Redes Neurais, Manifolds, and Topology