By: Derek Colley | Actualizado: 2014-01-29 | Comentários (5) | Relacionado: Mais > Funções – Sistema
Problema
Você está procurando recuperar uma amostra aleatória de um conjunto de resultados de uma consulta do SQL Server. Talvez você esteja procurando uma amostra representativa de dados de um grande banco de dados de clientes; talvez você esteja procurando algumas médias, ou uma idéia do tipo de dados que você está segurando. O SELECT TOP N nem sempre é o ideal, uma vez que os outliers de dados aparecem frequentemente no início e no fim dos conjuntos de dados, especialmente quando ordenados alfabeticamente ou por algum valor escalar. Da mesma forma, você pode ter usado TABLESAMPLE, mas ele tem limitações especialmente com conjuntos de dados pequenos ou enviesados. Talvez o seu chefe lhe tenha pedido uma selecção aleatória de 100 nomes e localizações de clientes; ou está a participar numa auditoria e precisa de recuperar uma amostra aleatória de dados para análise. Como você realizaria essa tarefa? Verifique esta dica para saber mais.
Solução
Esta dica lhe mostrará como usar TABLESAMPLE em T-SQL para recuperar amostras de dados pseudo-aleatórios, e falar através dos internos de TABLESAMPLE e onde não é apropriado. Também lhe mostrará um método alternativo – um método matemático usando NEWID() acoplado ao CHECKSUM e um operador bitwise, notado pela Microsoft no artigo TABLESAMPLE TechNet. Vamos falar um pouco sobre amostragem estatística em geral (as diferenças entre aleatório, sistemático e estratificado) com exemplos, e vamos dar uma olhada em como as estatísticas SQL são amostradas como um caso em ponto, e as opções que podemos usar para sobrepor esta amostragem. Após ler esta dica, você deve ter uma apreciação dos benefícios da amostragem sobre o uso de métodos como o TOP N e saber como aplicar pelo menos um método para conseguir isso no SQL Server.
Setup
Para esta dica, eu estarei usando um conjunto de dados contendo uma coluna INT de identidade (para estabelecer o grau de aleatoriedade ao selecionar linhas) e outras colunas preenchidas com dados pseudo-aleatórios de diferentes tipos de dados, para (vagamente) simular dados reais em uma tabela. Você pode usar o código T-SQL abaixo para configurar isso. Deve levar apenas alguns minutos para ser executado e é testado no SQL Server 2012 Developer Edition.
Selecting the top 10 rows of data yields this result (just to give you an idea of the shape of the data).Como um aparte, este é um código geral que criei para gerar dados aleatórios sempre que precisasse – sinta-se à vontade para levá-los e aumentá-los/publimentá-los para o conteúdo do seu coração!
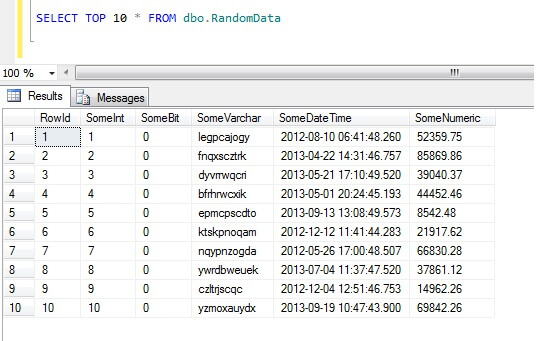
Como não amostrar dados no SQL Server
Agora temos as nossas amostras de dados, vamos pensar nas piores formas de obter uma amostra. Na base de dados AdventureWorks, existe uma tabela chamada Person.Address. Vamos amostrar pegando os 10 melhores resultados, sem ordem particular:
SELECT TOP 10 * FROM Person.Address
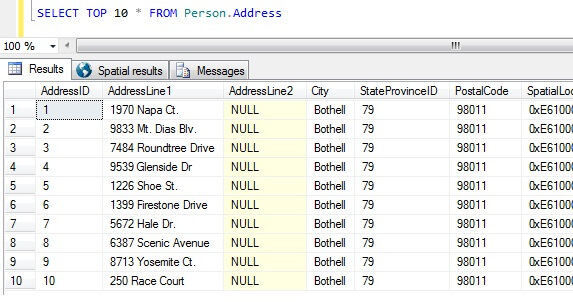
Vindo somente desta amostra, podemos ver que todas as pessoas retornaram ao vivo em Bothell, e compartilham o código postal 98011. Isto porque os resultados foram especificados para serem devolvidos em nenhuma ordem em particular, mas na verdade foram devolvidos na ordem da coluna AddressID. Note que isto NÃO é comportamento garantido para os dados da pilha em particular – veja esta citação de BOL:
“Normalmente os dados são armazenados inicialmente na ordem em que as linhas são inseridas na tabela, mas o Motor de Base de Dados pode mover os dados na pilha para armazenar as linhas eficientemente; assim a ordem dos dados não pode ser prevista. Para garantir a ordem das linhas retornadas de uma pilha, você deve usar a cláusula ORDER BY”
http://technet.microsoft.com/en-us/library/hh213609.aspx
A partir deste conjunto de resultados, uma pessoa desinformada sobre a natureza da tabela pode concluir que todos os seus clientes vivem em Bothell.
Tipos de Amostragem de Dados no SQL Server
O acima é claramente falso, então precisamos de uma forma melhor de amostragem. Que tal pegar uma amostra em intervalos regulares ao longo da tabela?
Isso deve retornar 47 linhas:
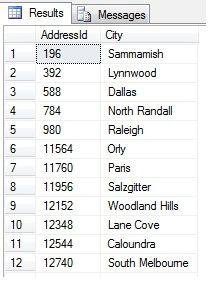
Até agora, tudo bem. Nós pegamos uma linha em intervalos regulares ao longo do nosso conjunto de dados e retornamos uma seção transversal estatística – ou nós temos? Não necessariamente. Não se esqueça, o pedido não é garantido. Podemos fazer uma ou duas conclusões sobre estes dados. Vamos agregá-los para ilustrar. Execute novamente o trecho de código acima, mas mude o bloco final do SELECT como tal:
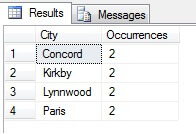
Você pode ver no meu exemplo que de uma contagem total de mais de 19.000 linhas na tabela Person.Address, eu experimentei cerca de 1/4% das linhas e, portanto, posso concluir que (no meu exemplo), Concord, Kirkby, Lynnwood e Paris têm o maior número de residentes e, além disso, são igualmente povoados. Preciso? Absurdo, claro:
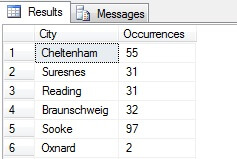
Como você pode ver, nenhum dos meus quatro estavam realmente nos quatro primeiros lugares para se viver, como julgado por esta tabela. Não só os dados da amostra eram muito pequenos, mas eu agreguei esta pequena amostra e tentei chegar a uma conclusão a partir dela. Isto significa que o meu conjunto de resultados é estatisticamente insignificante -avisamente, provar a significância estatística é um dos maiores ônus da prova ao apresentar resumos estatísticos (ou deveria ser) e uma grande queda de muitos infográficos populares e datagramas liderados pelo mercado.
Então, a amostragem desta forma (chamada amostragem sistemática) é eficaz, mas apenas para uma população estatisticamente significativa. Há fatores como periodicidade e proporção que podem arruinar uma amostra – vejamos a proporção em ação retirando uma amostra de 10 cidades da tabela Person.Address, usando o seguinte código, que obtém uma lista distinta de cidades da tabela Person.Address, então seleciona 10 cidades dessa lista usando amostragem sistemática:
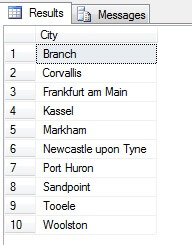
Parece uma boa amostra, certo? Agora vamos compará-la com uma amostra de cidades NÃO-distintas listadas em ordem ascendente, ou seja, cada enésima cidade, onde n é a contagem total de linhas dividida por 10. Esta medida leva em conta a população da amostra:
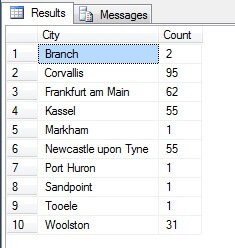
Os dados retornados são completamente diferentes – não por acaso, mas pela apresentação de uma amostra representativa. Note esta lista, na qual eu incluí as contagens de cada cidade na tabela de origem para delinear o quanto a população desempenha um papel na seleção dos dados, inclui as quatro cidades mais populosas da amostra, que (se você considerar uma lista não-distinta ordenada) é a representação mais justa. Não é necessariamente a melhor representação para as suas necessidades, portanto tenha cuidado ao escolher seu método de amostragem estatística.
Outros métodos de amostragem
Amostragem de cluster – é aqui que a população a ser amostrada é dividida em clusters, ou subconjuntos, então cada um desses subconjuntos é determinado aleatoriamente para ser incluído ou não no conjunto de resultados de saída. Se incluído, cada membro desse subconjunto é retornado no conjunto de resultados. Veja abaixo um exemplo disto.
Amostragem desproporcional – isto é como uma amostragem estratificada, onde membros de grupos de subconjuntos são selecionados a fim de representar todo o grupo, mas ao invés de ser proporcional, pode haver diferentes números de membros de cada grupo selecionado para igualar a representação de cada grupo. Ou seja, dadas as cidades em Person.Address no exemplo da seção acima, o primeiro conjunto de resultados foi desproporcional, pois não levou em conta a população, mas o segundo conjunto de resultados foi proporcional, pois representou o número de entradas da cidade na tabela Person.Address. Este tipo de amostragem é de fato útil se uma determinada categoria estiver sub-representada no conjunto de dados, e a proporção não é importante (por exemplo, 100 clientes aleatórios de 100 cidades aleatórias estratificadas por cidade – as cidades no subconjunto precisariam de normalização – amostragem desproporcional pode ser usada).
SQL Server Random Data with TABLESAMPLE
SQL Server helpfully vem com um método de amostragem de dados. Vamos vê-lo em ação. Use o seguinte código para retornar aproximadamente 100 linhas (se ele retorna 0 linhas, execute novamente – explicarei em um momento) de dados do dbo.RandomData que definimos anteriormente.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
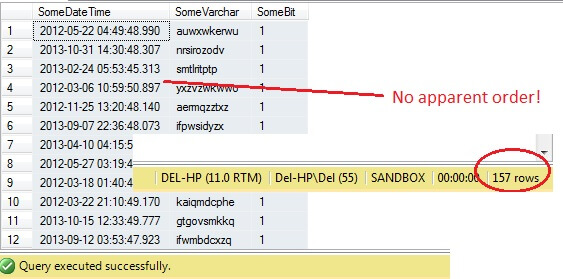
Até agora, tudo bem, certo? Espera aí – não conseguimos ver a coluna Id. Vamos incluir isto e repetir:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
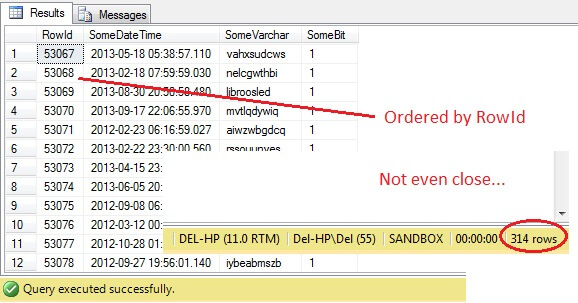
Oh querido – a TABLESAMPLE seleccionou uma fatia de dados, mas não é aleatória – a RowId mostra uma fatia claramente delineada com um valor mínimo e máximo. Além disso, também não retornou exatamente 100 linhas. O que está acontecendo?
TABLESAMPLE usa o modificador de SISTEMA implícito. Este modificador, por padrão e uma especificação ANSI-SQL, ou seja, não opcional, pegará cada página de 8KB em que a tabela reside e decidirá se inclui ou não todas as linhas dessa página na amostra produzida, com base na porcentagem ou N ROWS passada. Portanto, uma tabela que resida em muitas páginas, ou seja, com grandes linhas de dados, deve retornar uma amostra morerandomizada, uma vez que haverá mais páginas na amostra. Ela falha para um exemplo como o nosso, onde os dados são escalares e pequenos e residem em apenas algumas páginas – se qualquer número de páginas não conseguir fazer o corte, isso pode distorcer significativamente a amostra de saída. Esta é a queda do TABLESAMPLE – não funciona bem para dados ‘pequenos’ e não leva em conta a distribuição dos dados nas páginas. Então a disposição dos dados nas páginas é, em última análise, responsável pela amostra retornada por este método.
Isto soa familiar? É essencialmente uma amostragem de cluster, onde todos os membros (linhas) nos grupos selecionados (clusters) são representados no conjunto de resultados.
Vamos testá-lo em uma grande tabela para enfatizar o ponto de não escalabilidade inversa. Vamos primeiro identificar a maior tabela da base de dados da AdventureWorks. Vamos usar um relatório padrão para isso – usando SSMS, clique com o botão direito do mouse na base de dados AdventureWorks2012, vá para Relatórios -> Relatórios Padrão -> Uso do Disco por Tabelas Top. Ordenar por Dados(KB), clicando no cabeçalho da coluna (você pode querer fazer isso duas vezes para ordem decrescente). Você verá o relatório abaixo.
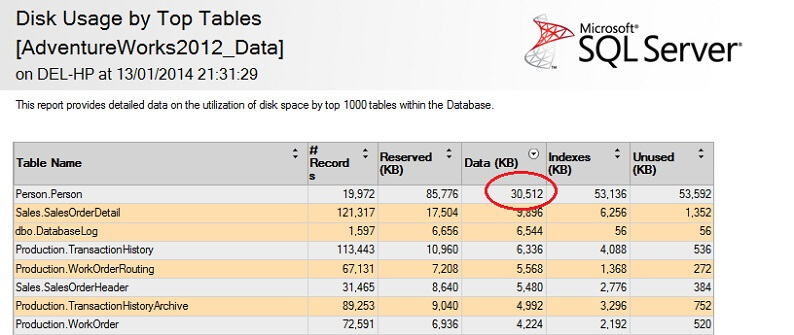
Eu circulei a figura interessante – a Pessoa. A tabela Pessoa consome 30,5MB de dados e é a maior (por dados, não contagem de registros) tabela. Então vamos tentar tirar uma amostra desta tabela em vez disso:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
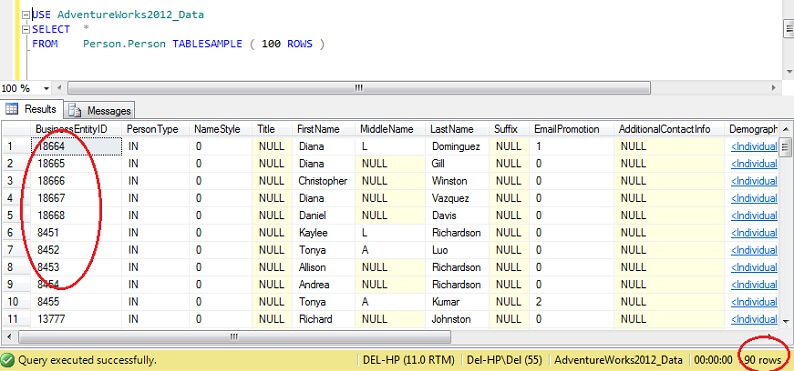
Vemos que estamos muito mais perto de 100 linhas, mas, crucialmente, não parece haver muito agrupamento na chave primária (embora haja alguns, pois há mais de 1 linha por página).
Consequentemente, TABLESAMPLE é bom para grandes dados, e fica catastroficamente pior quanto menor o conjunto de dados. Isto não é bom para nós ao amostrarmos a partir de dados estratificados ou dados agrupados, onde estamos coletando muitas amostras de pequenos grupos ou subconjuntos de dados e depois agregando esses dados. Vamos olhar para um método alternativo, então.
Dados aleatórios do SQL Server com ORDEM POR NEWID()
Aqui está uma citação do BOL sobre como obter uma amostra verdadeiramente aleatória:
“Se você realmente quer uma amostra aleatória de linhas individuais, modifique sua consulta para filtrar linhas aleatoriamente, em vez de usar TABLESAMPLE. Por exemplo, a seguinte consulta usa a função NEWID para retornar aproximadamente um por cento das linhas da tabela Sales.SalesOrderDetail:
Como isso funciona? Vamos dividir a cláusula WHERE e explicá-la.
A função CHECKSUM está calculando um checksum sobre os itens da lista. É discutível se SalesOrderID é mesmo necessário, já que NEWID() é uma função que retorna um novo GUID aleatório, então multiplicar um número aleatório por uma constante deve resultar em um aleatório em qualquer caso.De fato, excluindo SalesOrderID parece não fazer diferença. Se você é um keenstatistician e pode justificar a inclusão disto, por favor use a seção de comentários abaixo e me informe porque estou errado!
A função CHECKSUM retorna um VARBINÁRIO. Realizando um bitwise AND operação com 0x7fffff, que é o equivalente a (111111111…) em binário, produz um valor decimal que é efetivamente uma representação de uma string aleatória de 0s e 1s. Dividindo pelo co-eficiente 0x7fffff effectivelynormaliza este valor decimal para um valor entre 0 e 1. Depois, para decidir se cada linha merece ser incluída no conjunto de resultados finais, é usado um limiar de 1/x (neste caso, 0,01) onde x é a percentagem dos dados a recuperar como amostra.
Tenha cuidado para que este método seja uma forma de amostragem aleatória em vez de amostragem sistemática, por isso é provável que você obtenha dados de todas as partes dos seus dados de origem, mas a chave aqui é que você *não pode*. A natureza da amostragem aleatória significa que qualquer amostra que você coletar pode estar enviesada para um segmento dos seus dados, portanto, para se beneficiar da regressão para a média (tendência para um resultado aleatório, neste caso), certifique-se de coletar várias amostras e selecionar de um subconjunto delas, se os seus resultados parecerem enviesados. Alternativamente, tire amostras de subconjuntos dos seus dados, depois agregue estes – este é outro tipo de amostragem, chamado amostragem estratificada.
Como as estatísticas do SQL Server são amostradas?
No SQL Server, a actualização automática das estatísticas de coluna ou definidas pelo utilizador tem lugar sempre que um limite definido de linhas da tabela é alterado para uma dada tabela. Para 2012, este limite é calculado no SQRT(1000 * TR) onde TR é o número de linhas da tabela. Antes de 2005, o trabalho de atualização automática de estatísticas será disparado para cada (500 linhas + 20% de mudança) das linhas da tabela. Uma vez iniciado o processo de atualização automática, a amostragem irá *reduzir o número de linhas amostradas quanto maior a tabela for*, em outras palavras, há uma relação que é semelhante à proporção inversa entre a porcentagem de amostragem da tabela e o tamanho da tabela, mas segue um algoritmo proprietário.
Interessantemente, isto parece ser o oposto da opção TABLESAMPLE (N PERCENT), onde as linhas amostradas estão em proporção normal com o número de linhas na tabela. Podemos desactivar as estatísticas automáticas (tenha cuidado ao fazer isto) e actualizar as estatísticas manualmente – isto é conseguido usando NORECOMPUTA na declaração UPDATE STATISTICS. Com UPDATE STATISTICS podemos substituir algumas das opções – por exemplo, podemos optar por amostrar N linhas, ou N por cento (semelhante a TABLESAMPLE), executar um FULLSCAN, ou simplesmente RESAMPLE usando a última taxa conhecida.
Passos seguintes
Para leitura posterior, Joseph Sack é um Microsoft MVP conhecido pelo seu trabalho na análise estatística do SQL Server – por favor veja abaixo alguns links para o seu trabalho, juntamente com algumas referências a trabalhos usados para este artigo e algumas dicas relacionadas do MSSQLTips.com. Obrigado por ler!
Última Atualização: 2014-01-29


Sobre o autor
 Derek Colley é um desenvolvedor DBA e BI com mais de uma década de experiência trabalhando com SQL Server, Oracle e MySQL.
Derek Colley é um desenvolvedor DBA e BI com mais de uma década de experiência trabalhando com SQL Server, Oracle e MySQL.Ver todas as minhas dicas
- Mais Dicas de Desenvolvedor de Banco de Dados…