Existem muitas grandes vantagens que são oferecidas pela virtualização de sua infraestrutura e pela execução de recursos virtuais para atender a cargas de trabalho críticas para os negócios. No caso do VMware vSphere, ele oferece muitos recursos e recursos notáveis que oferecem alta disponibilidade no ambiente, bem como agendamento automático de carga de trabalho para garantir o uso mais eficiente de hardware e recursos em seu ambiente vSphere.
Neste post, falaremos sobre dois dos principais recursos em nível de cluster do vSphere na empresa – vSphere HA e DRS. Você provavelmente já viu ambos referenciados juntamente com a execução do vSphere na empresa.
O que é vSphere HA e DRS? O que é que eles fazem?
Como você se beneficia ao rodar ambos em seu ambiente vSphere?
Vamos dar uma olhada em uma introdução básica ao HA e DRS no VMware vSphere e ver como eles se comparam e os benefícios de usá-los.
VMware vSphere Clusters
Uma das vantagens óbvias e melhores práticas ao utilizar o VMware vSphere para executar cargas de trabalho críticas para os negócios é executar um vSphere Cluster.
O que é um vSphere Cluster?
Um cluster vSphere é uma configuração de mais de um servidor VMware ESXi agregada como um pool de recursos que contribuem para o cluster vSphere. Recursos como computação de CPU, memória e, no caso de armazenamento definido por software como vSAN, armazenamento, são contribuídos por cada host ESXi.
Por que é importante rodar suas cargas de trabalho críticas para o seu negócio em cima de um vSphere Cluster?
Quando você pensa nas vantagens proporcionadas pela execução de um hypervisor, ele permite que mais de um servidor seja executado em cima de um único conjunto de hardware físico. Virtualizar cargas de trabalho desta forma fornece muitos benefícios de eficiência em ordens de magnitude quando comparado a rodar um único servidor em um único conjunto de hardware físico.
No entanto, isto também pode se tornar o calcanhar de Aquiles de uma solução virtualizada, uma vez que o impacto de uma falha de hardware pode afetar muito mais serviços e aplicativos críticos para os negócios. Você pode imaginar que se você tiver apenas um único host VMware ESXi rodando muitas VMs, o impacto da perda desse único host ESXi seria imenso.
Aqui é onde executar várias máquinas VMware ESXi em um vSphere Cluster realmente brilha.
No entanto, você pode se perguntar, como simplesmente executar várias máquinas em um cluster melhora sua alta disponibilidade? Como uma máquina no vSphere Cluster “sabe” se outra máquina falhou? Existe algum mecanismo especial que é usado para cuidar do gerenciamento da alta disponibilidade de cargas de trabalho rodando em um vSphere Cluster? Sim, existe. Vamos ver.
O que é HA no VMware?
VMware percebeu a necessidade de ter um mecanismo para ser capaz de fornecer proteção contra uma máquina ESXi com falha no vSphere Cluster. Com essa necessidade, nasceu o VMware High-Availability (HA).
VMware vSphere HA oferece os seguintes benefícios:
VMware vSphere HA é econômico e permite reinicializações automáticas de VMs e hosts vSphere quando há uma falha no servidor ou uma falha no sistema operacional detectada no ambiente vSphere
Monitoriza todos os hosts VMware vSphere & VMs no vSphere Cluster
Distribui alta disponibilidade à maioria dos aplicativos executados em máquinas virtuais, independentemente do sistema operacional e dos aplicativos.
A beleza da solução VMware vSphere HA que é implementada através do VMware Cluster é a simplicidade para a qual ela pode ser configurada. Com alguns cliques através de uma interface orientada por um assistente, a alta disponibilidade pode ser configurada. Como isso se compara com as tecnologias tradicionais de “clustering”?
Windows Server Failover Clustering Comparison
Windows Server Failover Clustering (WSFC) se tornou a tecnologia de clustering que a maioria pensa quando tem a tecnologia de clustering em mente. O problema visto com o WSFC é que ele requer muita experiência especializada para executar os serviços WSFC corretamente, especialmente quando se trata de atualizações, correções e tarefas operacionais em geral.
Contrasting vSphere HA com WSFC, a sobrecarga operacional é mínima em comparação com o WSFC. Há poucas chances de que o HA possa ser configurado incorretamente, uma vez que está habilitado em um cluster ou não. Com o WSFC, há muitas considerações que precisam ser feitas ao configurar o WSFC para evitar tanto erros de configuração quanto de implementação. Pense sobre o seguinte:
- Failover clustering requer aplicações que suportem clustering (SQL, etc)
- Failover clustering requer quorum é configurado corretamente
- Não é suportado por muitos sistemas operacionais e aplicações legadas
- Requer complexidade de nomes de rede, recursos e rede de clusters
Windows Server Failover Clustering é anunciado para fornecer quase zero de tempo de inatividade no nível da aplicação. No entanto, quando você adiciona a experiência necessária para uma solução HA que funcione corretamente, juntamente com a implementação adequada do WSFC, os riscos podem começar a superar os benefícios do uso do WSFC para alta disponibilidade de aplicações e serviços. Isto é especialmente verdade quando para a maioria das organizações que podem não precisar verdadeiramente de uma solução “zero downtime”. Além disso, sua aplicação deve ser projetada para aproveitar o WSFC e funcionar corretamente com a tecnologia WSFC.
Embora o vSphere HA requeira um reinício das máquinas virtuais em um host saudável quando ocorre um failover, ele não requer instalação de software adicional dentro das máquinas virtuais convidadas, nenhuma configuração complexa de tecnologias de clustering adicionais e as aplicações ou SO’s não precisam ser projetadas para funcionar com uma tecnologia de clustering específica.
Sistemas operacionais e aplicativos legados geralmente têm habilidades limitadas quando se trata de tecnologias suportadas para fornecer alta disponibilidade. Portanto, pode não haver literalmente opções nativas para fornecer funcionalidade de failover no caso de falhas de hardware.
O mecanismo de alta disponibilidade do vSphere HA funciona e é simples de implementar, configurar e gerenciar. Além disso, esta é uma tecnologia bem testada em milhares de ambientes de clientes VMware, por isso tem um histórico estável e longo de implantações bem-sucedidas.
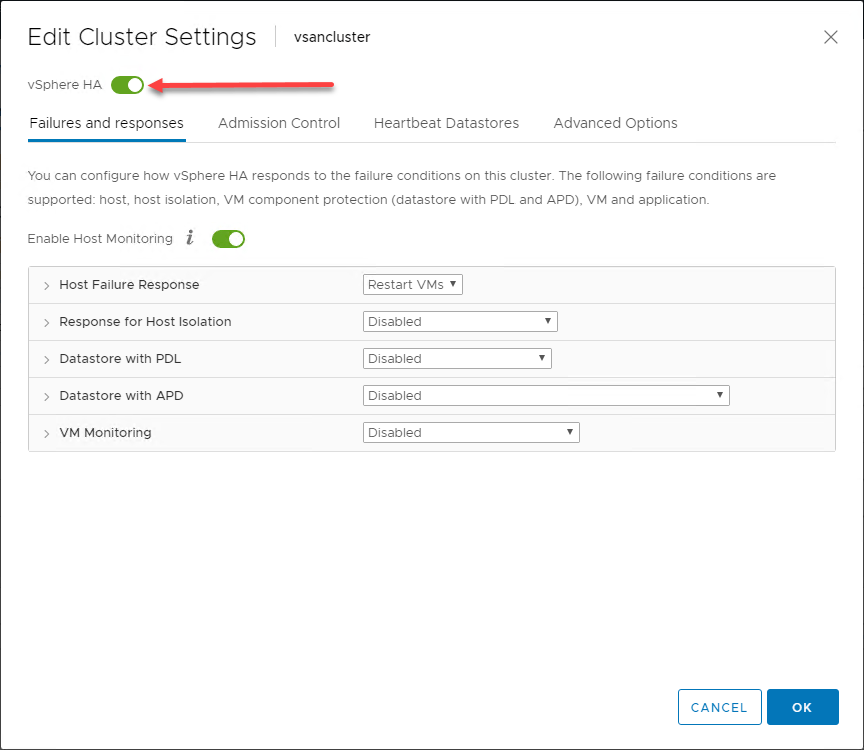
General Overview of vSphere HA Behavior
Ao utilizar os benefícios fornecidos aos hosts ESXi em um vSphere Cluster, em sua forma mais básica, o vSphere HA implementa um mecanismo de monitoramento entre os hosts no vSphere Cluster. O mecanismo de monitorização fornece uma forma de determinar se algum hospedeiro no vSphere Cluster falhou.
No infográfico abaixo, um Cluster vSphere de dois nós do vSphere Cluster sofreu uma falha de um dos hospedeiros do ESXi no vSphere Cluster. O vSphere Cluster tem o vSphere HA habilitado no nível do cluster.
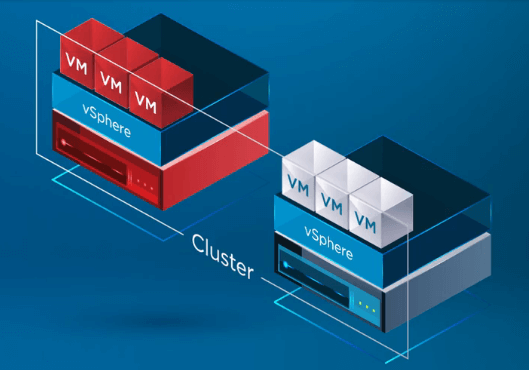
Após o vSphere HA reconhecer que um hospedeiro no vSphere Cluster falhou, o processo HA move o registro de VMs do hospedeiro falho para um hospedeiro saudável.
Após as VMs serem registradas em um hospedeiro saudável, o vSphere HA reinicia todas as VMs do hospedeiro falhado em um hospedeiro ESXi saudável no cluster onde as VMs foram re-inscriçadas. O único downtime incorrido é com o reinício das VMs em um hospedeiro saudável no vSphere Cluster.
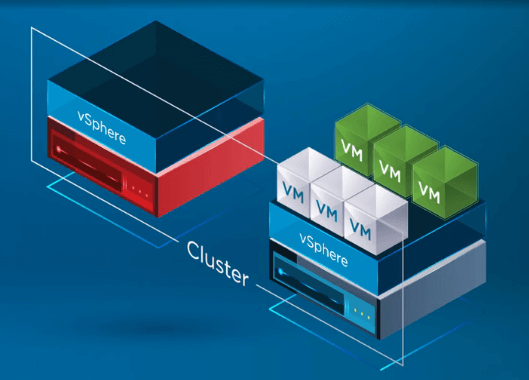
VSphere HA Technical Overview
Prerequisites for vSphere HA
Você pode se perguntar quais pré-requisitos subjacentes podem ser necessários para que o vSphere HA funcione. Para você simplesmente precisa de um VMware Cluster para habilitar o HA? Ao contrário do Windows Server Failover Clustering, existem apenas alguns requisitos que precisam estar em vigor para que o HA funcione.
Requisitos:
>
- Em pelo menos dois hosts ESXi
- Em pelo menos 4 GB de memória configurada em cada host
- vCenter Server
- vSphere Standard License
- Armazenamento compartilhado para VMs
- Gateway configurável ou outro nó de rede confiável
Se você notar, não é necessário nenhum componente de quorum, nenhum nome de rede complexo envolvido, e nenhum outro recurso especial de cluster que precise estar instalado.
Ler mais: Como configurar um vSphere High Availability Cluster
VMware vSphere HA Master vs Subordinate Hosts
Quando você ativa o vSphere HA em um cluster, um determinado host no vSphere Cluster é designado como o mestre do vSphere HA. As restantes hospedeiras ESXi no vSphere Cluster são configuradas como subordinadas na configuração do vSphere HA.
Que papel desempenha a máquina vSphere HA ESXi que é designada como a máquina mestre? O nó mestre vSphere HA:
- Monitoriza o estado das host subordinadas escravas – Se a host subordinada falhar ou for inalcançável, a host mestre identifica quais VMs precisam ser reiniciadas
- Monitoriza o estado de potência de todas as VMs que são protegidas. Se uma VM falhar, o nó master vSphere HA garante que a VM seja reiniciada. O master vSphere HA decide onde a VM reinicia (qual host ESXi).
- Realiza o rastreamento de todos os hosts de cluster e VMs que são protegidos pelo vSphere HA
- É designado como o mediador entre o vSphere Cluster e o vCenter Server. O master HA relata a saúde do cluster ao vCenter e fornece a interface de gerenciamento para o cluster do vCenter Server
- Pode executar as próprias VMs e monitorar o status das VMs
- Lojas protegidas em datastores de cluster
vSphere HA Subordinate Hosts:
- Executar máquinas virtuais localmente
- Monitorar os estados de tempo de execução das VMs no vSphere Cluster
- Relatar as actualizações dos estados do vSphere HA master
Eleição e Falha do Master Host
Como é seleccionado o master host do vSphere HA? Quando o vSphere HA é ativado para um cluster, todos os hosts ativos (sem modo de manutenção, etc.) participam da eleição do host mestre. Se o host mestre eleito falhar, uma nova eleição ocorre onde um novo host HA mestre é eleito para cumprir essa função.
VMware vSphere HA Cluster Failure Types
Em um cluster vSphere HA habilitado, há três tipos de falhas que podem acontecer para acionar um evento de failover do vSphere HA. Esses tipos de falha do host são:
- Falha – Uma falha é intuitivamente o que você pensa. Um host parou de funcionar de alguma forma ou maneira devido a hardware ou outros problemas.
- Isolamento – O isolamento de um host geralmente acontece devido a um evento de rede que isola um host em particular dos outros hosts do cluster vSphere HA.
- Partição – Um evento de partição é caracterizado por uma máquina subordinada perdendo conectividade de rede para a máquina principal do cluster HA vSphere.
Batendo, Detecção de Falhas e Ações de Falha
Como o nó principal determina se há uma falha de uma máquina em particular?
Existem vários mecanismos diferentes que o nó mestre usa para determinar se um host falhou:
- O nó mestre troca batimentos cardíacos da rede com os outros hosts no cluster a cada segundo.
- Após o batimento cardíaco da rede ter falhado, o host mestre verifica a vivacidade do host.
- A verificação da vivacidade do host determina se o host subordinado está trocando batimentos cardíacos com um dos datastores. Então ele envia pings ICMP para seus endereços IP de gerenciamento
- Se a comunicação direta com o agente HA de um host subordinado do host mestre não for possível e os pings ICMP para o endereço de gerenciamento falharem, o host é visto como falho e as VMs são reiniciadas em um host diferente.
- Se for descoberto que o host subordinado está trocando batimentos cardíacos com o datastore, o host mestre assume que o host está em uma partição de rede ou está isolado da rede. Neste caso, o mestre simplesmente monitora o host e as VMs
- O isolamento da rede é o evento onde um host subordinado está rodando, mas não pode mais ser visto da perspectiva de um agente de gerenciamento HA na rede de gerenciamento. Se um host deixa de ver esse tráfego, ele tenta pingar os endereços de isolamento do cluster. Se este ping falhar, o host declara que está isolado da rede
- Neste caso, o nó mestre monitora as VMs que estão rodando no host isolado. Se as VMs desligarem no host isolado, o nó mestre reinicia as VMs em outro host
Datastore Heartbeating
Como mencionado acima, uma das métricas usadas para determinar a detecção de falhas é datastore heartbeating. O que é isto exactamente? O VMware vCenter seleciona um conjunto preferido de datastores para o batimento cardíaco. Em seguida, o vSphere HA cria um diretório na raiz de cada datastore que é usado tanto para o batimento cardíaco do datastore quanto para se manter atualizado com a lista de VMs protegidas. Este diretório é chamado .vSphere-HA.
Há uma nota importante a lembrar sobre as datastores vSAN. Uma datastore vSAN não pode ser usada para datastore heartbeating. Se você só tem uma datastore vSAN disponível, não pode haver datastores de batimento cardíaco usados.
- Monitoramento de VM e aplicativos
Outro recurso extremamente poderoso do vSphere HA é a capacidade de monitorar máquinas virtuais individuais através do VMware Tools e reiniciar qualquer máquina virtual que não responda aos batimentos cardíacos do VMware Tools. O Monitoramento de aplicativos pode reiniciar uma VM se os batimentos cardíacos de um aplicativo que está em execução não forem recebidos.
Monitoramento de aplicativos – A função de monitoramento de aplicativos é ativada pela obtenção do SDK apropriado de um fornecedor de software de terceiros que permite configurar batimentos cardíacos personalizados para os aplicativos a serem monitorados pelo processo vSphere HA. Assim como o processo de monitoramento de VM, se os batimentos cardíacos dos aplicativos pararem de ser recebidos, a VM é reinicializada.
Algumas destas funções de monitorização podem ser configuradas com sensibilidade de monitorização e também o máximo de reinicializações por VM para ajudar a evitar a reinicialização de VMs repetidamente para software ou erros falsos positivos.
VMware vSphere HA é uma excelente forma de garantir que o seu vSphere Cluster fornece uma alta disponibilidade muito resistente para proteger contra falhas gerais de anfitriões ESXi no seu vSphere Cluster.
E que tal garantir o uso eficiente dos recursos no seu vSphere Cluster? Vamos dar uma olhada na próxima provisão do vSphere Cluster para ajudar a garantir o uso eficiente dos recursos e capacidade do seu vSphere Cluster.
O que é DRS no VMware?
VMware Distributed Resource Scheduler (DRS) é um recurso realmente poderoso ao executar o vSphere Clusters. Ele fornece agendamento e balanceamento de carga através de um vSphere Cluster. O VMware DRS é o recurso encontrado no vSphere Clusters que garante que as máquinas virtuais em execução no seu ambiente vSphere sejam fornecidas com os recursos necessários para serem executadas de forma eficaz e eficiente.
VMs estão geralmente sujeitos ao DRS desde a primeira inicialização em um cluster habilitado para DRS, o DRS coloca as VMs no melhor host configurado para fornecer os recursos necessários para a VM assim que são ativadas. Além disso, a DRS se esforça para manter os clusters vSphere equilibrados a partir de uma perspectiva de uso de recursos.
Even se um vSphere Cluster estiver equilibrado em um determinado momento, as VMs podem ser movidas ou alteradas de tal forma que um desequilíbrio de recursos de cluster possa rastejar de volta para o ambiente. Quando os clusters se tornam desequilibrados, isso pode ser prejudicial para o desempenho geral das máquinas virtuais rodando em um vSphere Cluster.
Por padrão, DRS roda automaticamente em um cluster vSphere a cada cinco minutos para determinar o equilíbrio de um vSphere Cluster e ver se alguma mudança precisa ser feita para fazer um uso mais eficaz dos recursos.
Requisitos do DRS do VMware
Para aproveitar o DRS do VMware, há vários requisitos que precisam ser atendidos para garantir o aproveitamento da funcionalidade do Agendador de recursos distribuído. Estes incluem:
- Um cluster de hosts ESXi
- vCenter Server
- Enterprise Plus License
- vMotion é necessário para o balanceamento automático de carga
Ler mais: Como configurar um vSphere DRS Cluster
VMware DRS Actions
Quando o VMware DRS roda em um vSphere Cluster a cada cinco minutos, ele determina se há algum desequilíbrio que existe no cluster. Se assim for, um vMotion será executado para mover as VMs designadas de um host ESXi para outro.
Como exatamente o DRS determina se máquinas virtuais são mais adequadas em um host ESXi ou outro?
DRS executa um algoritmo especial para determinar o host ESXi correto que deve abrigar uma VM em particular. Quando uma VM é ligada, este algoritmo leva em consideração a distribuição de recursos através do vSphere Cluster após garantir que não haja violações de restrições se uma VM em particular for colocada em uma máquina ESXi em particular.
Adicionalmente, a demanda da própria VM é levada em consideração para que a VM nunca fique faminta por recursos quando ela for ligada. O que está incluído na demanda da VM? A demanda de uma VM inclui a quantidade de recursos necessários para rodar.
- Para a demanda de CPU, isto é calculado com base na quantidade de CPU que a VM está consumindo atualmente
- Para a memória, a demanda é calculada com base na fórmula: Demanda de memória VM = Função(memória ativa usada, trocada, compartilhada) + 25% (memória ociosa consumida). Isto mostra que o balanço da memória DRS é baseado principalmente no uso da memória ativa de uma VM enquanto considera uma pequena quantidade de sua memória ociosa consumida como uma almofada para qualquer aumento na carga de trabalho.
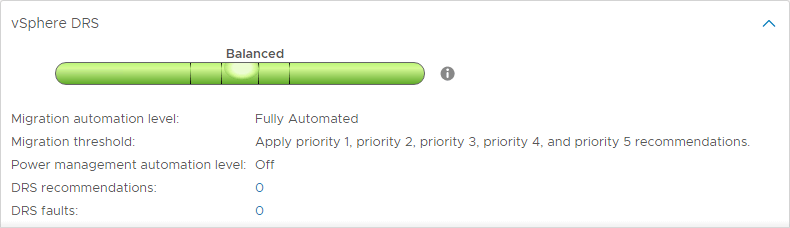
Níveis de automação DRS
Uma das características interessantes do DRS são os níveis de automação DRS. Enquanto o DRS continua a analisar o vSphere Cluster e fornece recomendações a cada 5 minutos, você pode determinar se o DRS é capaz ou não de promulgar suas recomendações automaticamente ou apenas sugerir mudanças que devem ser feitas. O DRS tem três níveis de automação DRS. Estes incluem:
- Totalmente automatizado – Na abordagem totalmente automatizada, DRS aplica automaticamente as recomendações de posicionamento inicial e balanceamento de carga
- Parcialmente automatizado – Com automação parcial, DRS aplica recomendações apenas para posicionamento inicial de VMs
- Manual – Em modo manual, você deve aplicar as recomendações tanto para a colocação inicial quanto para o balanceamento de carga
DRS Migration Thresholds
DRS inclui outra configuração muito útil para controlar a quantidade de desequilíbrio que será tolerada antes que as recomendações DRS sejam feitas. Existem cinco limiares de migração DRS para controlar a quantidade de desequilíbrio tolerada.
O intervalo é de 1 (mais conservador) a 5 (mais agressivo).
Com configurações mais agressivas, DRS tolera menos desequilíbrio em um cluster. Quanto mais conservador, mais DRS tolera o desequilíbrio.

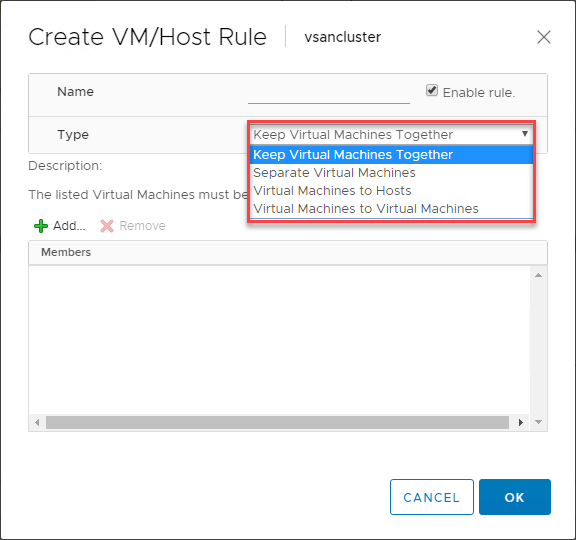
Regras do VMware DRS VM/Hosting DRS
Existe um recurso extremamente útil quando se usa o VMware DRS para controlar a colocação de VMs em seus clusters habilitados para vSphere DRS. As regras do VM/Host permitem que você execute VMs específicas em um host ESXi específico. Você pode pensar nisso como regras de afinidade de certa forma.
As regras da VM/Host permitem que você:
- Junta máquinas virtuais
- Separar máquinas virtuais
- Agregar máquinas virtuais a hosts específicos
- Agregar máquinas virtuais a máquinas virtuais
Mostrado abaixo é um exemplo de criação de uma regra VM/Host para máquinas virtuais e hosts ESXi.
Que tipo de caso de uso existe para essas regras VM/Host? Um dos casos de uso clássico que existe é com controladores de domínio. Geralmente falando, se você estiver executando todos os seus controladores de domínio em um ambiente virtualizado como um vSphere Cluster, você quer ter certeza de ter suas máquinas virtuais de controladores de domínio separadas umas das outras dentro do cluster. Desta forma, se você tiver um host ESXi, vá junto com um de seus controladores de domínio, você ainda terá um controlador de domínio que está sujeito a uma regra de Máquinas Virtuais Separadas que está mantendo-o fora do mesmo host que outro DC.
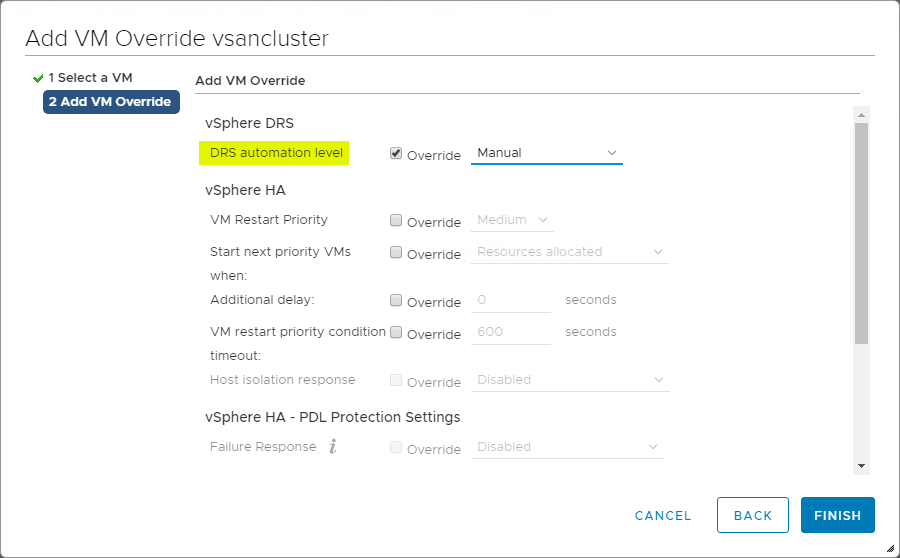
VM Overrides for DRS
O vSphere Cluster fornece grande granularidade para operações que afetam as VMs individuais dentro do vSphere Cluster. Você pode criar VM Overrides para substituir configurações globais definidas no nível de cluster para HA e DRS para definir configurações mais específicas para cada VM individual.
CPU e Resumo da Utilização da Memória
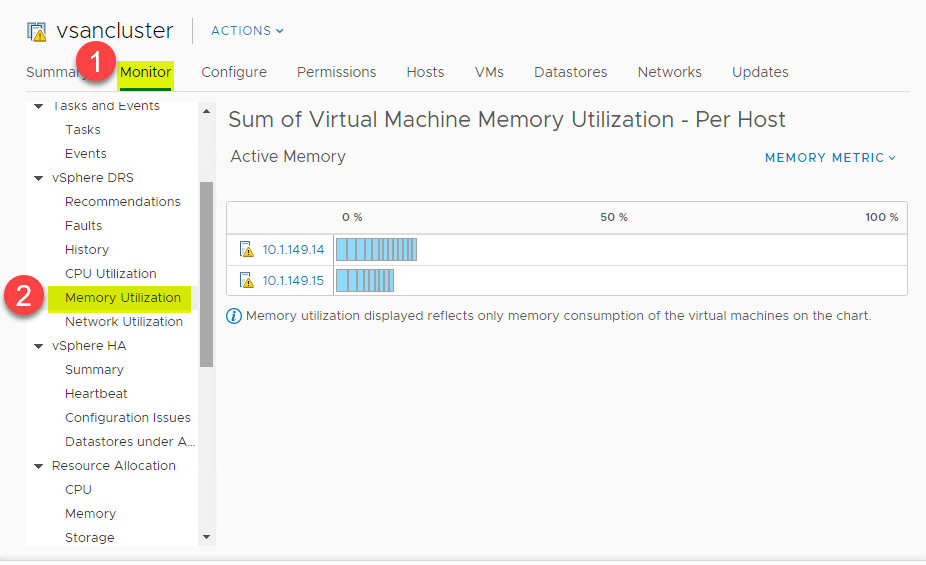
DRS fornece uma excelente visão de alto nível do resumo de utilização da CPU dos recursos da CPU dos hosts ESXi no vSphere Cluster. Navegue até > Configurações > Monitor > vSphere DRS > Utilização da CPU.
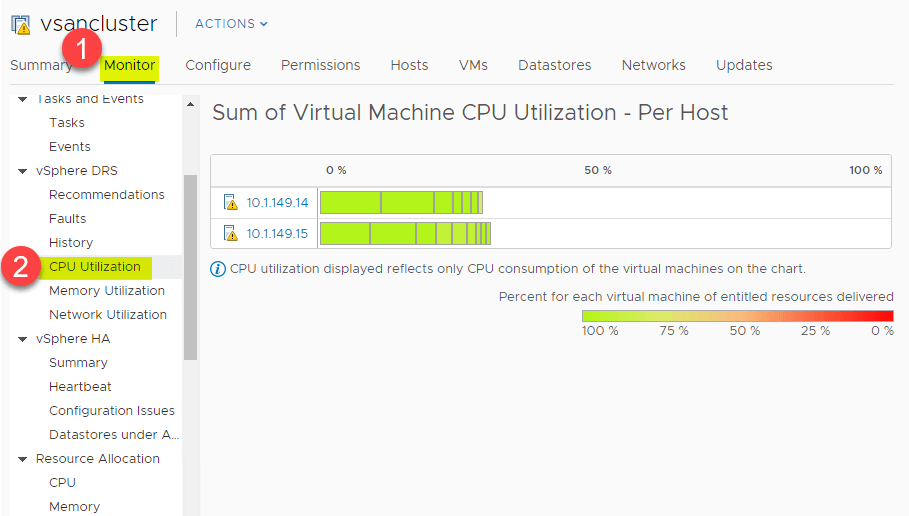
A mesma visão geral de alto nível também pode ser vista para o consumo de memória. Navegue até > Configurações > Monitor > vSphere DRS > Utilização de memória
O melhor de dois mundos
O VMware vSphere HA e VMware DRS são tecnologias concorrentes?
Não, elas não são. Na verdade, é altamente recomendável usar o vSphere HA e o VMware DRS juntos para combinar o failover automático com recursos e funcionalidades de balanceamento de carga. Isso resulta em um ambiente vSphere muito mais resiliente e mais equilibrado.
Se ocorrer falha de um host ESXi, o vSphere HA reiniciará as VMs nos hosts saudáveis restantes em um vSphere Cluster. Portanto, a primeira prioridade, naturalmente, é a disponibilidade de recursos de máquinas virtuais. O VMware DRS será então executado e determinará se existe algum desequilíbrio entre os hosts ESXi rodando as cargas de trabalho e fará recomendações para resolver quaisquer desequilíbrios no cluster com base no limite de migração configurado. Com base no nível de automação, essas recomendações serão automaticamente acionadas ou somente recomendadas se não forem totalmente automatizadas.
Pensamentos finais sobre o VMware vSphere HA e DRS
Executar ambos VMware vSphere HA e DRS são altamente recomendados em um cluster vSphere de produção. O uso de ambas as tecnologias ajuda a tornar suas cargas de trabalho altamente disponíveis e garante que elas tenham continuamente os recursos necessários com base nas demandas de CPU/memória do VM.
A compreensão de como ambos os mecanismos funcionam ajuda você, como administrador do vSphere, a alavancar ambas as tecnologias da melhor maneira possível e de acordo com as melhores práticas. Entre os benefícios que ambas as tecnologias trazem à tabela, cada recurso é extremamente fácil de habilitar e configurar. Com alguns simples cliques nas propriedades de seus vSphere Clusters, você pode rapidamente começar a se beneficiar destas características disponíveis em nível de cluster.
Seguir os nossos feeds do Twitter e Facebook para novos lançamentos, actualizações, posts perspicazes e muito mais.