Introdução
Se você está analisando seus dados usando regressão múltipla e qualquer uma de suas variáveis independentes foi medida em uma escala nominal ou ordinal, você precisa saber como criar variáveis dummy e interpretar seus resultados. Isso porque variáveis independentes nominais e ordinais, mais amplamente conhecidas como variáveis independentes categóricas, não podem ser inseridas diretamente em uma análise de regressão múltipla. Ao invés disso, elas precisam ser convertidas em variáveis fictícias. A exceção são as variáveis ordinais independentes que são inseridas em uma regressão múltipla como variáveis independentes contínuas, que não precisam ser convertidas em variáveis fictícias. Portanto, neste guia mostramos como criar variáveis dummy quando você tem variáveis independentes categóricas.
Primeiro, apresentamos o exemplo que usamos para mostrar como criar variáveis dummy nas Estatísticas SPSS, antes de explicar como configurar seus dados nas janelas Visualização de Variáveis e Visualização de Dados das Estatísticas SPSS, para que você possa criar variáveis dummy. Se você não está familiarizado com o uso de variáveis fictícias, recomendamos que você leia sobre alguns dos princípios básicos de variáveis fictícias e codificação fictícia, inclusive: (a) o número de variáveis dummy que você precisa criar na sua análise; e (b) como criar variáveis dummy e codificação dummy. Na seção Procedimento que se segue, definimos o procedimento simples de 3 etapas Criar Variáveis Dummy nas Estatísticas SPSS que podem ser usadas para criar variáveis dummy. Finalmente, explicamos a saída de Estatísticas SPSS após executar o procedimento Criar Variáveis Dummy, incluindo como suas variáveis dummy serão agora configuradas nas janelas Variable View e Data View das Estatísticas SPSS.
Note: Se você achar que os procedimentos neste guia não cobrem o tipo de variáveis dummy que você deseja criar, por favor entre em contato conosco. Talvez possamos adicionar outro guia ao site para ajudar.
SPSS Statistics
Exemplo usado neste guia
Neste guia estaremos usando o exemplo de 10 triatletas que foram solicitadas a selecionar seu esporte favorito entre os três esportes que realizam ao fazer um triatlo: natação, ciclismo e corrida. As suas respostas foram registadas na variável nominal independente, desporto_preferido, que tem três categorias: “natação”, “ciclismo” e “corrida”. Esta variável nominal independente, favorito_desportivo, devia ser incluída numa análise de regressão múltipla que também tinha um número de variáveis independentes contínuas. Como esta variável independente era categórica (ou seja, variáveis nominais e variáveis ordinais podem ser amplamente classificadas como variáveis categóricas), variáveis dummy tiveram que ser criadas antes que ela pudesse ser inserida na análise de regressão múltipla.
Importante: Note que o desporto_favorito é uma variável nominal, mas você também pode criar variáveis dummy para uma variável ordinal. Além disso, o processo para criar variáveis dummy é o mesmo independentemente de você ter uma variável ordinal ou nominal, com a exceção de uma pequena mudança que você tem que fazer ao configurar seus dados, que é explicado abaixo.
Note 1: As “categorias” de uma variável independente de categoria também são referidas como “grupos” ou “níveis”, mas o termo “níveis” é geralmente reservado para categorias que têm uma ordem (por exemplo, a variável independente ordinal, “nível de aptidão”, poderia ter três níveis: “baixo”, “moderado” e “alto”). Entretanto, esses três termos – “categorias”, “grupos” e “níveis” – podem ser usados de forma intercambiável. Neste guia, nós nos referiremos a eles como categorias, mas você poderia se referir a eles como grupos ou níveis se preferir.
Nota 2: O termo “fatores” é às vezes usado em vez de “variáveis independentes categóricas” (ou seja, variáveis independentes que são “ordinais” ou “nominais”). Entretanto, estes dois termos – “variáveis categóricas independentes” e “fatores” – podem ser usados de forma intercambiável. Neste guia, nos referiremos a elas como variáveis independentes categóricas e você também verá as Estatísticas SPSS se referirem a elas como variáveis independentes ao invés de fatores em seu procedimento de regressão múltipla. Entretanto, você pode se referir a elas como fatores se preferir.
SPSS Statistics
Configurando seus dados nas Estatísticas SPSS
Ao criar variáveis dummy, você começará com uma única variável independente categórica (por exemplo, favorito_desportivo). Para configurar esta variável categórica independente, as Estatísticas SPSS têm uma Visão de Variável onde você define os tipos de variável que está analisando e uma Visão de Dados onde você insere seus dados para esta variável. Nesta seção, mostramos primeiro como configurar uma variável independente de categoria na janela Visão de Variável das Estatísticas SPSS, antes de mostrar como entrar seus dados na janela Visão de Dados. Fazemos isso usando a nossa variável independente de categoria, favorita_sport, que tem três categorias: “swimming”, “cycling” e “running”.
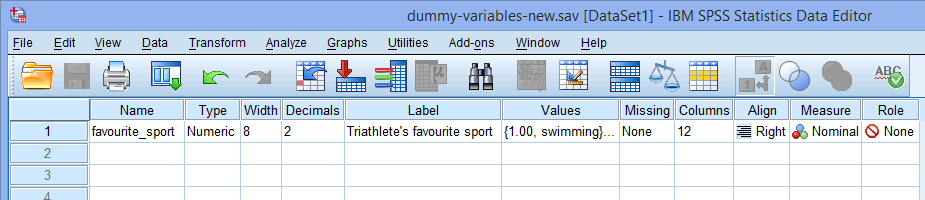
The Variable View in SPSS Statistics
Para uma única variável independente de categoria (por exemplo, favorita_sport), a sua janela de Vista de Variáveis será parecida com a abaixo:
Note: Pode aceder à janela de Vista de Variáveis nas Estatísticas SPSS clicando na aba ![]() no canto inferior esquerdo do software Estatísticas SPSS.
no canto inferior esquerdo do software Estatísticas SPSS.
Publicado com permissão por escrito da SPSS Statistics, IBM Corporation.
O nome da sua variável independente de categoria deve ser inserido na célula sob a coluna ![]() (por exemplo, “desporto_preferido” na linha
(por exemplo, “desporto_preferido” na linha ![]() para representar a nossa variável independente de categoria, desporto_preferido. Existem certos caracteres “ilegais” que não podem ser inseridos na célula
para representar a nossa variável independente de categoria, desporto_preferido. Existem certos caracteres “ilegais” que não podem ser inseridos na célula ![]() . Portanto, se você receber uma mensagem de erro e quiser que adicionemos um guia de estatísticas SPSS para explicar o que são esses caracteres ilegais, entre em contato conosco.
. Portanto, se você receber uma mensagem de erro e quiser que adicionemos um guia de estatísticas SPSS para explicar o que são esses caracteres ilegais, entre em contato conosco.
Note: Para sua própria clareza, você também pode fornecer uma etiqueta para suas variáveis na coluna ![]() . Por exemplo, a etiqueta que introduzimos para “favorite_sport” era “Triathlete’s favorite sport”.
. Por exemplo, a etiqueta que introduzimos para “favorite_sport” era “Triathlete’s favorite sport”.
A célula sob a coluna ![]() deve conter a informação sobre as categorias da sua variável independente de categoria (por exemplo, “swimming”, “cycling” e “running” para “favorite_sport”). Para introduzir esta informação, clique na célula sob a coluna
deve conter a informação sobre as categorias da sua variável independente de categoria (por exemplo, “swimming”, “cycling” e “running” para “favorite_sport”). Para introduzir esta informação, clique na célula sob a coluna ![]() para a sua variável independente. O botão
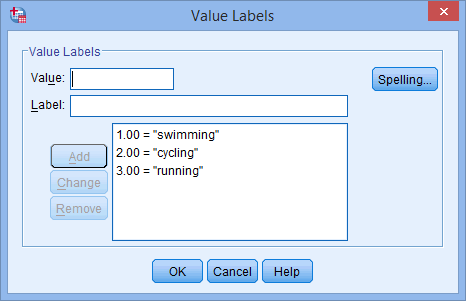
para a sua variável independente. O botão ![]() irá aparecer na célula. Clique neste botão e aparecerá a caixa de diálogo Rótulos de Valor. Agora precisa de dar a cada categoria da sua variável independente um “valor”, o qual deverá introduzir na caixa Valor: (e.g., “1”), assim como uma “etiqueta”, a qual deverá introduzir na caixa Etiqueta: (e.g., “swimming”). Ao clicar no botão
irá aparecer na célula. Clique neste botão e aparecerá a caixa de diálogo Rótulos de Valor. Agora precisa de dar a cada categoria da sua variável independente um “valor”, o qual deverá introduzir na caixa Valor: (e.g., “1”), assim como uma “etiqueta”, a qual deverá introduzir na caixa Etiqueta: (e.g., “swimming”). Ao clicar no botão ![]() a codificação aparecerá na caixa principal (por exemplo, “1.00=”swimming” para o desporto_preferido). A configuração da nossa variável independente categórica é mostrada na caixa de diálogo Rótulos de Valores abaixo:
a codificação aparecerá na caixa principal (por exemplo, “1.00=”swimming” para o desporto_preferido). A configuração da nossa variável independente categórica é mostrada na caixa de diálogo Rótulos de Valores abaixo:
Publicada com permissão escrita da SPSS Statistics, IBM Corporation.
A célula sob a coluna ![]() deve mostrar
deve mostrar ![]() se você tiver uma variável independente nominal (por exemplo, favorito_sport, como no nosso exemplo) ou
se você tiver uma variável independente nominal (por exemplo, favorito_sport, como no nosso exemplo) ou ![]() se tiver uma variável ordinal independente (por exemplo, imagine uma variável ordinal como “Índice de Massa Corporal” (IMC), IMC), que tem quatro níveis: “Peso Baixo”, “Peso Saudável/Normal”, “Sobrepeso”, e “Obeso”). Finalmente, a célula sob a coluna
se tiver uma variável ordinal independente (por exemplo, imagine uma variável ordinal como “Índice de Massa Corporal” (IMC), IMC), que tem quatro níveis: “Peso Baixo”, “Peso Saudável/Normal”, “Sobrepeso”, e “Obeso”). Finalmente, a célula sob a coluna ![]() deve mostrar
deve mostrar ![]() .
.
Nota: Sugerimos mudar a célula sob a coluna ![]() de
de ![]() para
para ![]() , mas você não precisa fazer esta mudança. Sugerimos que você faça porque existem certas análises nas Estatísticas SPSS onde a configuração
, mas você não precisa fazer esta mudança. Sugerimos que você faça porque existem certas análises nas Estatísticas SPSS onde a configuração ![]() resulta na transferência automática de suas variáveis para certos campos das caixas de diálogo que você está usando. Como você pode não querer transferir essas variáveis, sugerimos que você altere a configuração
resulta na transferência automática de suas variáveis para certos campos das caixas de diálogo que você está usando. Como você pode não querer transferir essas variáveis, sugerimos que você altere a configuração ![]() para
para ![]() para que isso não aconteça automaticamente.
para que isso não aconteça automaticamente.
Você agora digitou com sucesso todas as informações que as Estatísticas do SPSS precisam saber sobre sua variável categórica independente na janela Visão de Variável. Na próxima seção, nós mostramos como inserir seus dados na janela Visão de Dados.
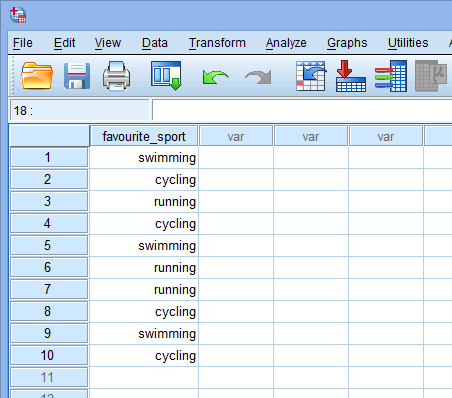
A Visão de Dados em Estatísticas SPSS
Baseado na configuração do arquivo para sua variável independente de categoria na janela Visão de Variável acima, a janela Visão de Dados mostra a seguinte aparência:
Note: Você pode acessar a janela Visão de Dados em Estatísticas SPSS clicando na aba ![]() no canto inferior esquerdo do software Estatísticas SPSS.
no canto inferior esquerdo do software Estatísticas SPSS.
Publicado com permissão por escrito da SPSS Statistics, IBM Corporation.
Sua variável independente de categoria será exibida na primeira coluna, já que esta foi a ordem em que inserimos a variável na janela View Variable View. No nosso exemplo, as respostas dos 10 triatletas são apresentadas sob a coluna ![]() . Agora, você simplesmente tem que inserir seus dados nas células sob esta primeira coluna. Lembre-se de que cada linha representa um caso (por exemplo, um caso pode ser um único participante). Portanto, na linha
. Agora, você simplesmente tem que inserir seus dados nas células sob esta primeira coluna. Lembre-se de que cada linha representa um caso (por exemplo, um caso pode ser um único participante). Portanto, na linha ![]() do nosso exemplo, o primeiro caso representava um triatleta cujo esporte favorito era “natação”. Como estas células estarão inicialmente vazias, você precisa clicar nas células para inserir seus dados. Você notará que quando você clicar nas células sob a coluna
do nosso exemplo, o primeiro caso representava um triatleta cujo esporte favorito era “natação”. Como estas células estarão inicialmente vazias, você precisa clicar nas células para inserir seus dados. Você notará que quando você clicar nas células sob a coluna ![]() , as Estatísticas do SPSS lhe dará uma opção drop-down com suas categorias já preenchidas.
, as Estatísticas do SPSS lhe dará uma opção drop-down com suas categorias já preenchidas.
Agora que você configurou seus dados nas janelas Visualização de Variáveis e Visualização de Dados das Estatísticas do SPSS, nós recomendamos a leitura da próxima seção: Entendendo variáveis fictícias e codificação fictícia, onde explicamos os princípios básicos de variáveis fictícias e codificação fictícia. Entretanto, se você já estiver familiarizado com os fundamentos das variáveis e codificação fictícia, você pode pular esta seção e ir direto para a seção Procedimento, onde definimos o procedimento Criar variáveis fictícias nas Estatísticas do SPSS, que é usado para criar variáveis fictícias.
SPSS Statistics
Entendendo variáveis fictícias e codificação fictícia
Como mencionamos na Introdução, se você está analisando seus dados usando regressão múltipla e qualquer uma de suas variáveis independentes foi medida em uma escala nominal ou ordinal, você precisa saber como criar variáveis fictícias e interpretar seus resultados. Isto porque variáveis categóricas independentes (ou seja, variáveis nominais e ordinais independentes) não podem ser diretamente inseridas em uma regressão múltipla. Ao invés disso, elas precisam ser convertidas em variáveis fictícias. A exceção são as variáveis ordinais independentes que são inseridas em uma regressão múltipla como variáveis independentes contínuas, que não precisam ser convertidas em variáveis fictícias. Nas seções abaixo, nós explicamos: (a) o número de variáveis dummy que você precisa criar; e (b) como criar variáveis dummy e codificação dummy.
O número de variáveis dummy que você precisa criar
O número de variáveis dummy que você precisa criar dependerá de quantas categorias a sua variável independente categórica possui. Como regra geral, você criará menos uma variável dummy do que o número de categorias na sua variável independente categórica. Por exemplo, se você tiver uma variável independente de categoria com três categorias (por exemplo, favorite_sport, com as três categorias a seguir): “swimming”, “cycling” e “running”), você criará duas variáveis dummy e selecionará uma categoria para atuar como categoria de referência (por exemplo, “swimming” e “cycling” tornam-se variáveis dummy e “running” torna-se a categoria de referência). Explicamos mais sobre categorias de referência após a tabela seguinte, que fornece alguns exemplos de variáveis categóricas independentes e o número de variáveis dummy que precisam de ser criadas:
| Nome da variável independente categórica | Tipo de variável | Número de categorias | Número de variáveis fictícias | ||||
|---|---|---|---|---|---|---|---|
| 1 | Principal | Nominal | Duas (Machos &Fêmeas) |
Uma=Homens “Fêmeas”. é a categoria de referência |
|||
| 2 | Altura | Ordinal | Dois (Inferior a 180cm & 180cm e superior) |
Um=Acima 180cm “180cm e mais” é a categoria de referência |
|||
| 3 | Ethnicity | Nominal | Três (Afro-americano, Caucasiano & Hispânico) |
Dois=Americano africano & Caucasiano “Hispânico” é a categoria de referência |
|||
| 4 | Nível de atividade física | Ordinal | Três (Baixo, Moderado &Alto) |
Dois=Baixo & Moderado “Alto” é a categoria de referência |
|||
| 5 | Profissão | Nominal | Quatro (Cirurgião, Doutor, Enfermeira &Terapeuta) |
Três=Esurgião, Doutor & Enfermeira “Terapeuta” é a categoria de referência |
|||
| 6 | Nível de concordância | Ordinal | Quatro (Concordo plenamente, Concordo, Discordo, Discordo fortemente) |
Três= Concordam fortemente, Concordo & Discordo “Discordo fortemente” é a categoria de referência |
|||
| 7 | Área do subjeito | Nominal | Cinco (Estudos de negócios, Psicologia, Ciências Biológicas, Engenharia & Direito) |
Quatro=Estudos de negócios, Psicologia, Ciências Biológicas & Engenharia “Direito” é a categoria de referência |
|||
| 8 | Age | Ordinal | Cinco (Menos de 18 anos, 19-30, 31-40, 41-50, 51-60) |
Quatro=Acima de 18, 19-30, 31-40 & 41-50 “51-60” é a categoria de referência |
|||
| Tabela: Exemplos de variáveis categóricas independentes e suas respectivas variáveis dummy | |||||||
Como mostrado na tabela acima, você só precisa criar menos uma variável dummy do que o número de categorias em sua variável categórica independente. Isso porque você só precisa (e deve) transferir esse número de variáveis dummy para uma regressão múltipla quando você tem uma variável independente de categoria. Entretanto, há boas razões para criar uma variável dummy para cada categoria da variável categórica independente: (a) é mais flexível e (b) permite fazer comparações múltiplas (ver a nota abaixo). Em outras palavras, se sua variável independente de categoria tiver três categorias, você criaria três variáveis dummy, não apenas duas.
Felizmente, o procedimento Criar Variáveis dummy no SPSS Statistics versão 22 e superior cria automaticamente uma variável dummy para cada categoria da sua variável independente de categoria. Contudo, este não é o caso do procedimento Recodificar em Variáveis Diferentes nas Estatísticas do SPSS versão 21 ou anterior. Portanto, em circunstâncias normais, você terá criado a seguinte configuração no SPSS Statistics, dependendo se você tem a versão 21 ou anterior ou a versão 22 e superior:
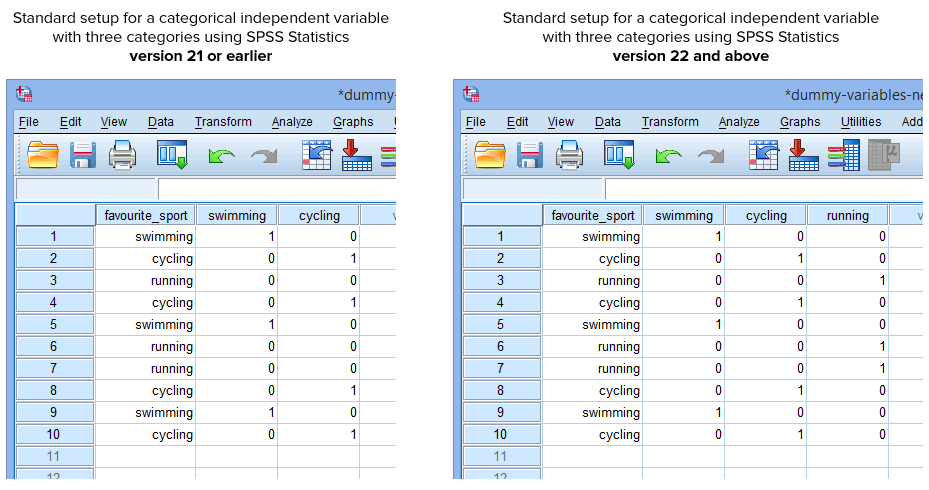
Publicado com permissão escrita da SPSS Statistics, IBM Corporation.
Note: Como mencionado acima, criar uma variável dummy para cada categoria da variável independente categórica é benéfico por duas razões: (a) ela é mais flexível e (b) permite múltiplas comparações. Abordamos brevemente estes benefícios abaixo:
É mais flexível:
Quando você criou uma variável dummy para cada categoria da sua variável independente de categoria, você pode então considerar qualquer categoria como uma categoria de referência. No nosso exemplo, consideramos a categoria “corrida” como a categoria de referência, o que significa que teríamos transferido “natação” e “ciclismo” para a equação de regressão múltipla. Entretanto, se mais tarde mudássemos de idéia sobre a nossa escolha da categoria de referência, teríamos que executar o procedimento da variável dummy novamente (a menos que você tenha SPSS Statistics versão 22 ou superior). Por exemplo, vamos assumir que agora queríamos considerar a categoria “ciclismo” como a categoria de referência. Poderíamos agora transferir as variáveis dummy “swimming” e “running” para a equação de regressão múltipla porque também temos a variável dummy “running”.
Permite fazer comparações múltiplas:
O coeficiente de uma variável dummy representa a diferença entre a categoria que a variável dummy representa e a categoria de referência. Por exemplo, com “running” como categoria de referência, o coeficiente da variável dummy “swimming” representa a diferença na variável dependente entre a categoria “swimming” e a categoria “running”. Usando este método, nem todas as combinações de categorias serão possíveis. Este problema pode ser resolvido com a utilização de diferentes categorias de referência. Isto é possível se todas as categorias da variável categórica tiverem uma variável dummy.
Como criar variáveis dummy e codificação dummy
Existem dois passos para configurar variáveis dummy com sucesso em uma regressão múltipla: (1) criar variáveis dummy que representam as categorias da sua variável independente categórica; e (2) inserir valores nestas variáveis dummy – conhecidas como codificação dummy – para representar as categorias da variável independente categórica. Explicamos este processo abaixo usando o exemplo que apresentamos acima.
Explicação: Variáveis dummy são simplesmente variáveis novas que atuam como “placeholders” para um esquema de codificação particular. Elas não contêm nenhum dado, por si só. Ao invés disso, dados/valores precisam ser adicionados a essas variáveis fictícias para que elas possam cumprir seu propósito de representar as categorias de sua variável independente categórica. Existem muitos tipos diferentes de esquema de codificação que irão ditar os valores que são inseridos em variáveis dummy, mas usamos um esquema de codificação muito comum chamado codificação dummy ou, alternativamente, codificação de indicador (N.B., não se confunda porque variáveis dummy e codificação dummy não são a mesma coisa). A codificação dummy funciona usando cada variável dummy para identificar uma categoria específica de uma variável independente categórica, com a exceção de uma categoria de referência, que explicamos abaixo.
Vamos começar considerando nosso exemplo de variável independente categórica, favorita_desportiva, que tem três categorias: “natação”, “ciclismo” e “corrida”. Como existem três categorias, são necessárias duas variáveis dummy representando duas das categorias, e uma categoria de referência representando a terceira categoria.
Nota: Lembre-se da discussão acima que uma regressão múltipla requer que você transfira menos uma variável dummy do que o número de categorias na sua variável independente de categoria (ou seja, duas no nosso exemplo). Entretanto, você pode criar uma variável dummy para cada categoria da variável independente categórica para fins de maior flexibilidade e a capacidade de fazer múltiplas comparações. No entanto, na discussão abaixo apenas destacamos o que é necessário para uma regressão múltipla; ou seja, a criação de menos uma variável dummy do que o número de categorias na sua variável independente de categoria com a categoria que não é diretamente representada tornando-se a “categoria de referência”.
Por exemplo, deixe a variável dummy #1 representar a categoria “swimming” e a variável dummy #2 representar a categoria “cycling”. Isto não deixa nenhuma variável dummy para a categoria “corrida”. Esta categoria “missing” (em falta) é a categoria de referência e não é necessária. Além disso, é inteiramente sua decisão qual categoria você quer usar como categoria de referência. Poderíamos ter escolhido tão facilmente a categoria “natação” como a categoria de referência, em vez da categoria “corrida”. A única razão pela qual não o fizemos é que, por padrão, a SPSS Statistics usa a última categoria que você codificou na Visão de Variável para sua variável independente de categoria como a categoria de referência (veja a nota abaixo).
Note: Como explicado na seção de Configuração de Dados anteriormente e como mostrado abaixo na caixa de diálogo Value Labels, a terceira e última categoria de nossa variável independente de categoria foi “running” (ou seja, “correndo”), 3=”running”).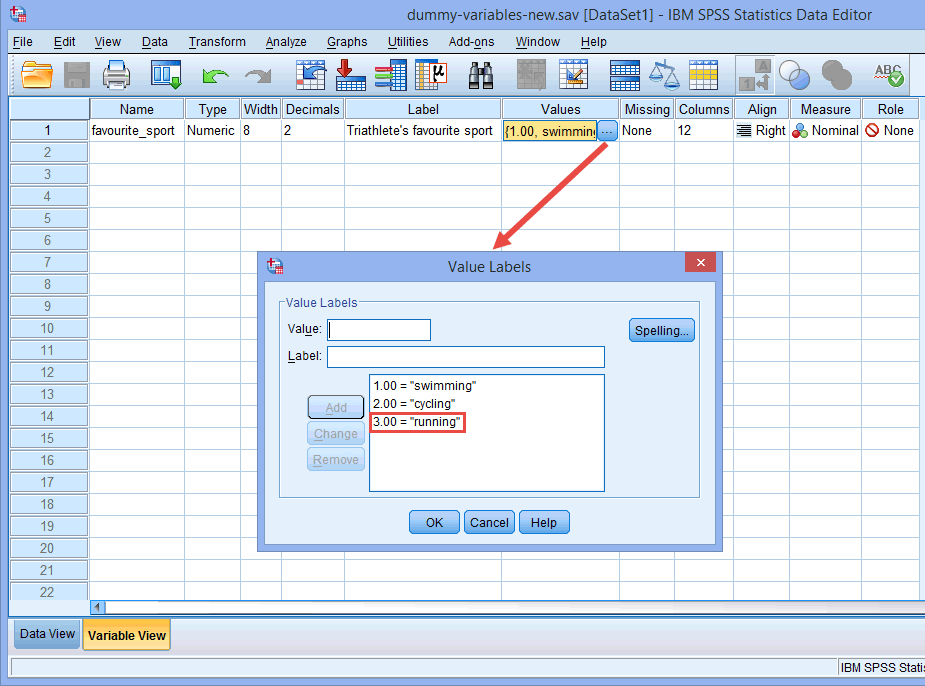
Não houve nenhuma razão teórica ou estatística para fazermos da categoria “running” a terceira e última categoria, o que a tornou a categoria de referência nas Estatísticas SPSS por padrão. Fizemos isso simplesmente porque quando os triatletas participam de um triatlo, eles primeiro nadam, depois fazem um ciclo, antes de finalmente correrem para a linha de chegada. Portanto, pareceu lógico codificar a nossa variável independente categórica desta forma. Entretanto, poderíamos tê-la codificado como 1=ciclismo, 2=ciclismo e 3= natação; não teria feito diferença, exceto pelo fato de que como terceira e última categoria, “nadar” teria se tornado nossa categoria de referência por padrão nas Estatísticas SPSS.
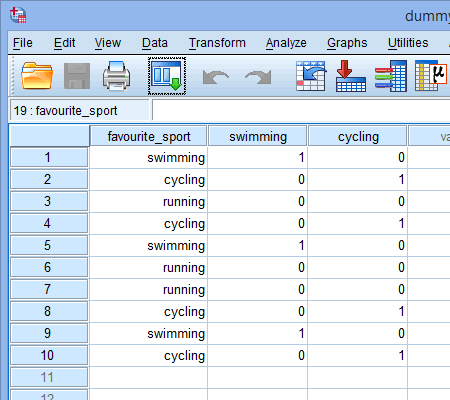
Quando você cria variáveis fictícias você deve dar a elas um nome significativo. Como cada uma das nossas variáveis dummy representa uma categoria da nossa variável independente de categoria, é costume referir-se a cada variável dummy pelo nome da categoria que ela representa. Portanto, nós chamamos a variável dummy #1 de “natação”, pois ela representa a categoria da natação. Da mesma forma, chamamos a variável dummy #2 de “ciclismo”, pois ela representa a categoria de ciclismo. Ao criar estas duas variáveis dummy, teremos duas novas colunas em nosso conjunto de dados em SPSS Statistics, como mostrado abaixo:
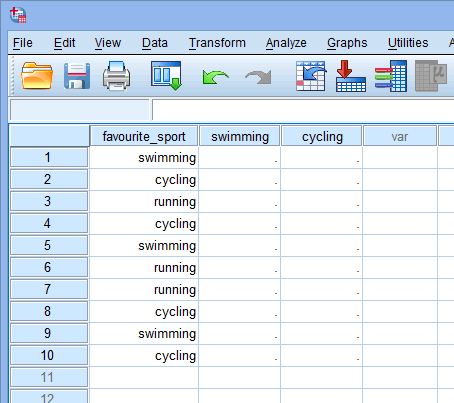
Publicado com permissão escrita da SPSS Statistics, IBM Corporation.
Agora que criamos duas variáveis dummy e lhes demos nomes apropriados, precisamos inserir valores nestas variáveis para que cada variável dummy realmente represente sua categoria da variável independente categórica. Com a codificação dummy isto é muito simples. Você entra um “1” para representar qualquer caso (por exemplo, um participante no seu conjunto de dados) que tenha a categoria e entra um “0” (zero) se eles não tiverem a categoria. Primeiro, considere a variável dummy “swimming”, como mostrado abaixo:
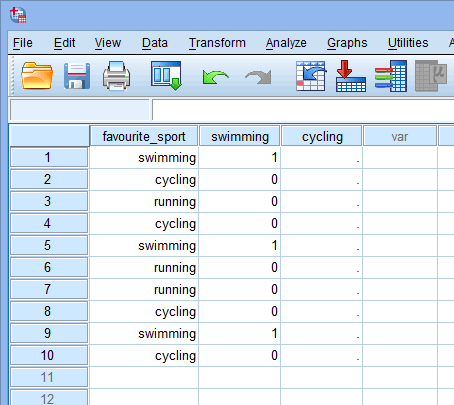
Publicado com permissão escrita da SPSS Statistics, IBM Corporation.
Se um dos triatletas afirmasse que “swimming” era o seu desporto “favorito”, entraríamos um “1” na célula sob a coluna da variável dummy swimming (![]() ) para aquele triatleta que afirmou que a natação era o seu desporto “favorito”. Alternativamente, se um dos triatletas declarasse que “ciclismo” ou “corrida” era o seu desporto “favorito”, introduziríamos um “0” na célula por baixo da coluna da variável dummy de natação (
) para aquele triatleta que afirmou que a natação era o seu desporto “favorito”. Alternativamente, se um dos triatletas declarasse que “ciclismo” ou “corrida” era o seu desporto “favorito”, introduziríamos um “0” na célula por baixo da coluna da variável dummy de natação (![]() ) para aquele triatleta que declarasse que a natação era “não” o seu desporto favorito (isto significa que ou “ciclismo” ou “corrida” era o desporto favorito daquele triatleta). Isto é destacado abaixo para todos os 10 triatletas:
) para aquele triatleta que declarasse que a natação era “não” o seu desporto favorito (isto significa que ou “ciclismo” ou “corrida” era o desporto favorito daquele triatleta). Isto é destacado abaixo para todos os 10 triatletas:
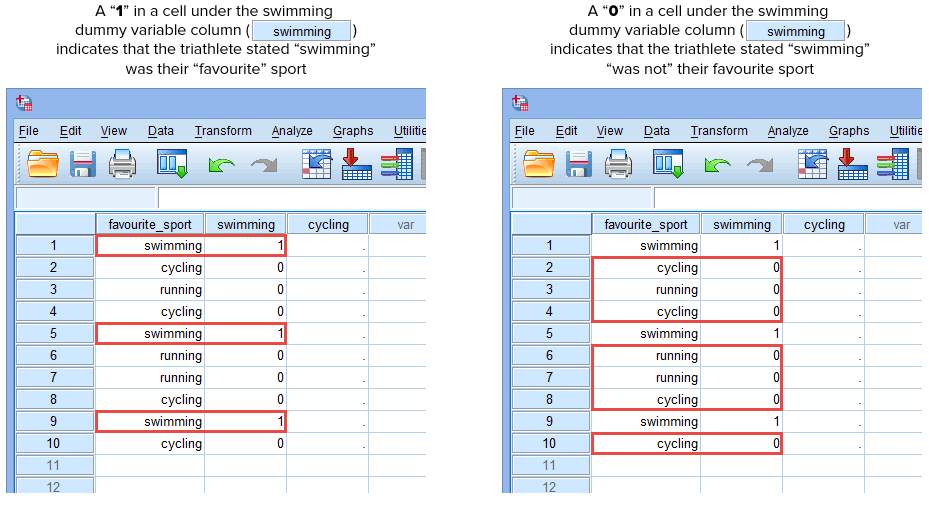
Publicado com permissão por escrito da SPSS Statistics, IBM Corporation.
Repetimos este processo para a outra variável dummy, “ciclismo”, como mostrado abaixo:
Publicado com permissão por escrito da SPSS Statistics, IBM Corporation.
Se um dos triatletas afirmasse que o “ciclismo” era o seu desporto “favorito”, entraríamos com um “1” na célula debaixo da coluna da variável dummy do ciclismo (![]() ) para aquele triatleta que afirmou que o ciclismo era o seu desporto “favorito”. Alternativamente, se um dos triatletas declarasse que “nadar” ou “correr” era o seu desporto “favorito”, introduziríamos um “0” na célula debaixo da coluna da variável dummy de ciclismo (
) para aquele triatleta que afirmou que o ciclismo era o seu desporto “favorito”. Alternativamente, se um dos triatletas declarasse que “nadar” ou “correr” era o seu desporto “favorito”, introduziríamos um “0” na célula debaixo da coluna da variável dummy de ciclismo (![]() ) para aquele triatleta que declarasse que o ciclismo era “não” o seu desporto favorito (isto significa que ou “nadar” ou “correr” era o desporto favorito daquele triatleta). Isto é destacado abaixo para todos os 10 triatletas:
) para aquele triatleta que declarasse que o ciclismo era “não” o seu desporto favorito (isto significa que ou “nadar” ou “correr” era o desporto favorito daquele triatleta). Isto é destacado abaixo para todos os 10 triatletas:
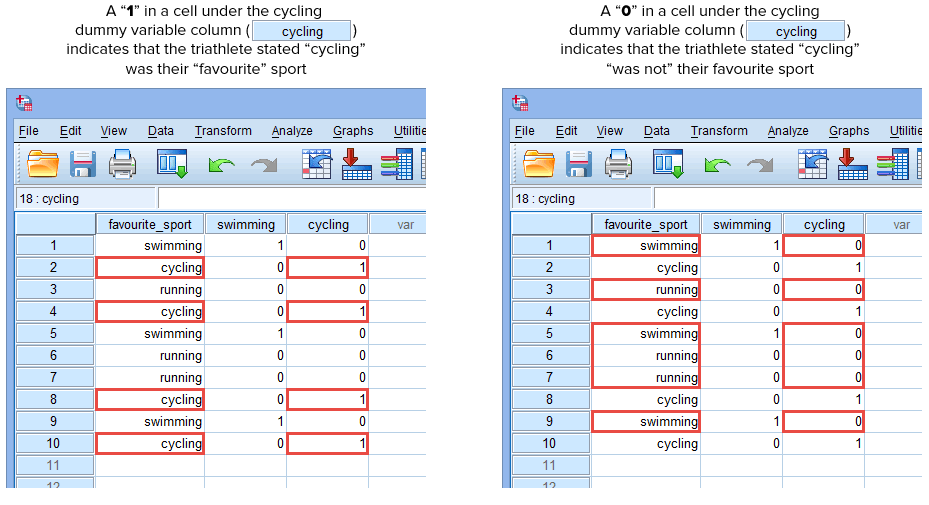
Publicado com permissão por escrito da SPSS Statistics, IBM Corporation.
Ao inserir “1 “s e “0 “s em suas variáveis dummy desta forma, você terá criado um conjunto de variáveis dummy que você pode inserir em uma análise de regressão múltipla. Na seção Procedimento a seguir, mostramos como criar essas variáveis dummy usando o procedimento Create Dummy Variables.
SPSS Statistics
Procedimento nas Estatísticas SPSS para criar variáveis dummy
Existem dois procedimentos nas Estatísticas SPSS para criar variáveis dummy: o procedimento Create Dummy Variables e o procedimento Recode into Different Variables. Neste guia, mostramos como usar o procedimento Create Dummy Variables, que é um procedimento simples de 3 passos. No entanto, ele só está disponível se você tiver SPSS Statistics versão 22 ou posterior, com a versão 26 (e a versão de assinatura do SPSS Statistics) sendo a última versão do SPSS Statistics. Se você não tem certeza de qual versão do SPSS Statistics você está usando, veja nosso guia: Identificando a sua versão do SPSS Statistics. Se você tem SPSS Statistics versão 21 ou anterior ou está interessado em fazer múltiplas comparações ao realizar sua análise de regressão múltipla, veja a Nota abaixo:
Note: Se você tem SPSS Statistics versão 21 ou anterior, você não pode usar o procedimento Create Dummy Variables. Portanto, o procedimento Recodificar em Variáveis Diferentes pelo menos permite que você crie variáveis fictícias nas Estatísticas do SPSS. Embora você também possa usar o procedimento Recodificar em Variáveis Diferentes para criar variáveis fictícias se você tiver Estatísticas SPSS versão 22 ou posterior, definimos o procedimento Criar variáveis fictícias neste guia porque ele é dedicado à criação de variáveis fictícias e é muito mais fácil e rápido de usar. Por exemplo, são necessários apenas 3 passos para criar variáveis fictícias para o exemplo usado neste guia em comparação com os 28 passos para o mesmo exemplo usando o procedimento Recodificar em Variáveis Diferentes.
Por isso, se você tem SPSS Statistics versão 21 ou anterior, nosso guia melhorado em Criar variáveis fictícias na seção de membros no Laerd Statistics inclui uma página dedicada a mostrar como realizar este procedimento Recodificar em Variáveis Diferentes em 28 passos. Você pode acessar este guia melhorado assinando as Estatísticas de Laerd. Alternativamente, você pode simplesmente usar o procedimento Create Dummy Variables abaixo.
Para criar variáveis dummy quando você tem SPSS Statistics versão 22 ou posterior, siga o procedimento Create Dummy Variables abaixo:
- Click Transform > Create Dummy Variables no menu principal, como mostrado abaixo:

Publicado com permissão por escrito da SPSS Statistics, IBM Corporation.
Você será apresentado com a caixa de diálogo Create Dummy Variables, como mostrado abaixo:
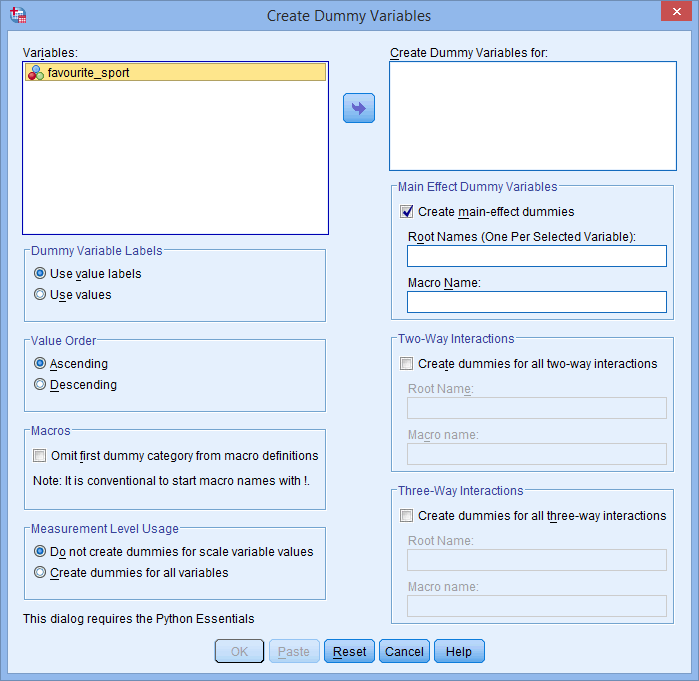
Publicado com permissão escrita da SPSS Statistics, IBM Corporation.
- Transfira a variável independente categórica, favorita_sport, para a caixa Create Dummy Variables for: selecionando-a (clicando nela) e depois clicando no botão
 . Também, insira um nome “root” que possa representar todas as novas variáveis dummy na caixa Root Names (One Per Selected Variable): na área -Main Effect Dummy Variables-. Nós inserimos o nome da raiz “fs” como uma abreviação para nossa variável independente categórica, “favorite_sport”, como mostrado abaixo:
. Também, insira um nome “root” que possa representar todas as novas variáveis dummy na caixa Root Names (One Per Selected Variable): na área -Main Effect Dummy Variables-. Nós inserimos o nome da raiz “fs” como uma abreviação para nossa variável independente categórica, “favorite_sport”, como mostrado abaixo:
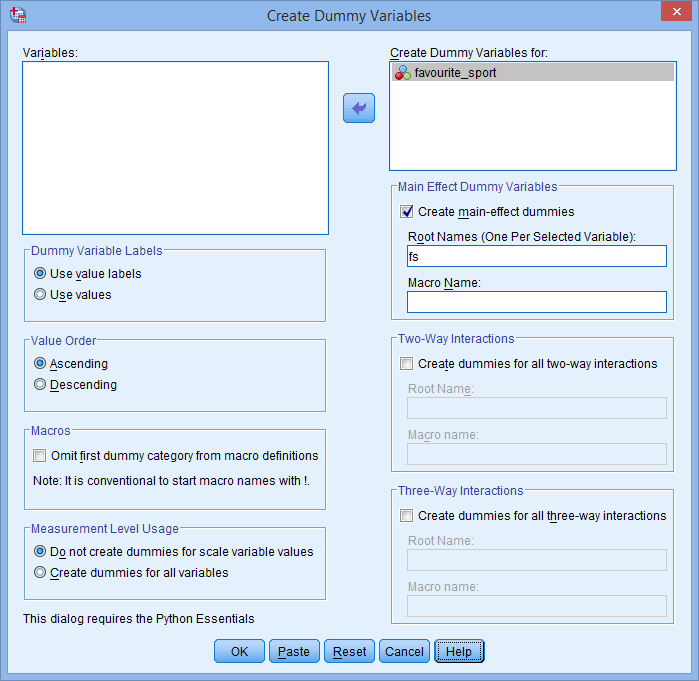
Publicado com permissão escrita da SPSS Statistics, IBM Corporation.
Note: SPSS Statistics adicionará um número seqüencial (ou seja, 1, 2, 3, 4, etc.) no final do nome da raiz que você escolher para representar sua variável independente categórica. Um número sequencial será criado para cada uma das variáveis dummy que você deseja criar (por exemplo, se você tiver duas variáveis dummy, um 1 e 2 serão adicionados ao final do nome da raiz, mas se você tiver seis variáveis dummy, um 1, 2, 3, 4, 5 e 6 serão adicionados ao final do nome da raiz). Isto é mostrado para o nosso exemplo na janela de Variáveis abaixo:
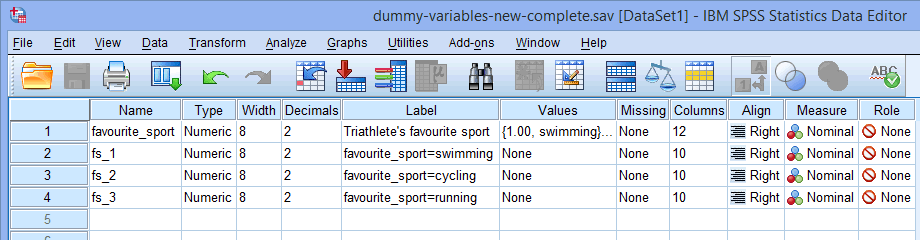
Desde que a nossa variável categórica independente, favorite_sport, tinha três categorias (isto é, natação, ciclismo e corrida), o procedimento Create Dummy Variables cria três variáveis dummy (isto é, uma para natação, uma para ciclismo e uma para corrida). Estas três variáveis dummy estão destacadas na coluna acima: “fs_1” (para natação), “fs_2” (para ciclismo) e “fs_3” (para corrida). Você pode renomeá-las mais tarde para que façam mais sentido. Estamos apenas destacando isto para que você saiba como funciona a caixa acima do Root Names (One Per Selected Variable): caixa acima.
acima: “fs_1” (para natação), “fs_2” (para ciclismo) e “fs_3” (para corrida). Você pode renomeá-las mais tarde para que façam mais sentido. Estamos apenas destacando isto para que você saiba como funciona a caixa acima do Root Names (One Per Selected Variable): caixa acima.
Também, o nome da raiz que você digita no Root Names (One Per Selected Variable): caixa não pode ser o mesmo que o nome da sua variável independente categórica, como mostrado abaixo (ou seja, onde inserimos o nome da raiz, “favorite_sport”, para ilustrar o que não poderíamos chamar de nosso nome raiz):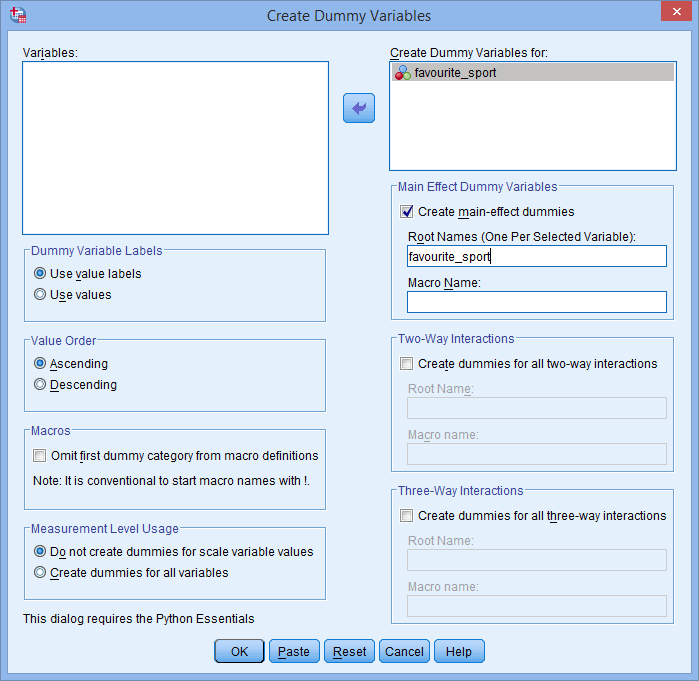
Se o nome da raiz que você inserir é o mesmo que o nome da sua variável independente de categoria, como mostrado acima, quando você clicar no botão , você receberá o seguinte aviso:
, você receberá o seguinte aviso:
- Clique no botão .
Após executar os 3 passos do procedimento Criar Variável Dummy acima, você terá criado variáveis dummy para a sua variável independente categórica. Na próxima seção, destaque a saída que é criada na Vista de Variáveis e Vista de Dados das Estatísticas SPSS após executar este procedimento Criar Variáveis Dummy.
SPSS Statistics
SPSS Statistics após criar variáveis dummy
Após criar suas variáveis dummy, a SPSS Statistics produz a seguinte tabela de Criação de Variáveis o seu IBM SPSS Statistics Viewer:
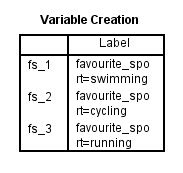
Publicado com permissão por escrito da SPSS Statistics, IBM Corporation.
A tabela Criação de Variáveis confirma que você criou variáveis fictícias com sucesso. Deve haver tantas linhas quantas as novas variáveis dummy. Como criámos três variáveis dummy, existem três linhas na tabela, “fs_1”, “fs_2” e “fs_3”, que reflectem o nome da raiz e a numeração sequencial introduzida no Passo 2 do procedimento Criar Variáveis Dummy na secção anterior. Para cada uma destas variáveis dummy, uma etiqueta é fornecida na tabela para deixar claro qual a categoria da variável categórica independente que cada variável dummy representa. Por exemplo, a etiqueta, “favourite_sport=swimming”, é fornecida para “fs_1”, indicando que “fs_1” é a variável dummy para a categoria “swimming” da variável independente de categoria, favourite_sport.
Next, vá para a janela Vista de Variáveis das Estatísticas SPSS clicando no separador ![]() . As três variáveis dummy terão sido adicionadas, como mostrado abaixo (ou seja, as variáveis dummy, “fs_1”, “fs_2” e “fs_3”, na coluna
. As três variáveis dummy terão sido adicionadas, como mostrado abaixo (ou seja, as variáveis dummy, “fs_1”, “fs_2” e “fs_3”, na coluna ![]() ):
):
Publicadas com permissão escrita da SPSS Statistics, IBM Corporation.
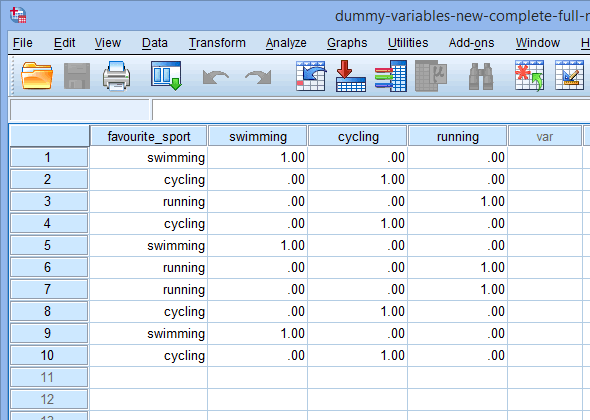
Note: Você pode alterar os nomes das variáveis dummy na coluna ![]() para tornar mais claro o que são. Por exemplo, mudamos “fs_1” para “swimming”, “fs_2” para “cycling” e “fs_3” para “running”, como mostrado abaixo:
para tornar mais claro o que são. Por exemplo, mudamos “fs_1” para “swimming”, “fs_2” para “cycling” e “fs_3” para “running”, como mostrado abaixo:
Finalmente, vá para a janela Data View das Estatísticas do SPSS clicando no separador ![]() . A codificação dummy é mostrada sob cada uma das variáveis dummy que foram criadas. Por exemplo, nas linhas sob a coluna “fs_1”, a categoria, “swimming”, é codificada como “1.00”, enquanto as categorias, “cycling” e “running”, são codificadas como “.00”, como mostrado abaixo. Se você não tem certeza porque estas variáveis dummy são codificadas desta forma, veja a seção: Entendendo variáveis dummy e codificação dummy.
. A codificação dummy é mostrada sob cada uma das variáveis dummy que foram criadas. Por exemplo, nas linhas sob a coluna “fs_1”, a categoria, “swimming”, é codificada como “1.00”, enquanto as categorias, “cycling” e “running”, são codificadas como “.00”, como mostrado abaixo. Se você não tem certeza porque estas variáveis dummy são codificadas desta forma, veja a seção: Entendendo variáveis dummy e codificação dummy.
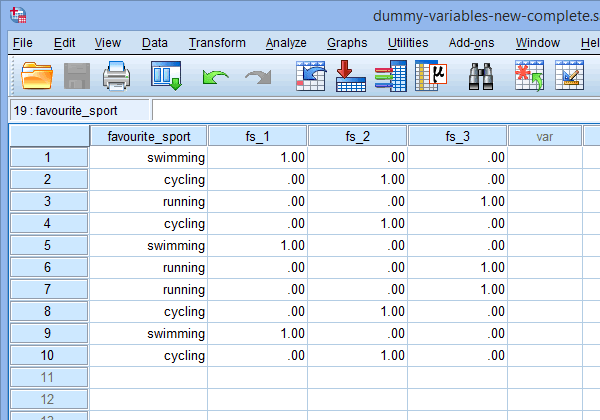
Publicado com permissão escrita da SPSS Statistics, IBM Corporation.
Nota 1: Devido às configurações padrão da SPSS Statistics, suas variáveis dummy serão codificadas como “1.00” ou “.00” ao invés de “1” ou “0”, respectivamente. Elas são idênticas. No entanto, você verá frequentemente a codificação dummy escrita em termos de 1 e 0 em vez de incluir decimais.
Nota 2: Se você alterou os nomes das variáveis dummy na coluna ![]() da janela Visão de Variáveis acima, estas também terão sido alteradas nas colunas da janela Visão de Dados, como mostrado abaixo (por exemplo, o título da coluna
da janela Visão de Variáveis acima, estas também terão sido alteradas nas colunas da janela Visão de Dados, como mostrado abaixo (por exemplo, o título da coluna ![]() tem agora o título
tem agora o título ![]() ):
):