Overview
- Aprenda a interpretar Bias and Variance num determinado modelo.
- Qual é a diferença entre Viés e Variância?
- Como conseguir Viés e Variância Tradicional usando o fluxo de trabalho de Machine Learning
Introdução
Deixe-nos falar sobre o tempo. Só chove se estiver um pouco úmido e não chove se estiver ventando, quente ou congelando. Neste caso, como você treinaria um modelo de previsão e garantiria que não haja erros na previsão do tempo? Você pode dizer que há muitos algoritmos de aprendizagem para escolher. Eles são distintos em muitos aspectos, mas há uma grande diferença no que esperamos e no que o modelo prevê. Esse é o conceito de Bias e Variance Tradeoff.
Usually, Bias e Variance Tradeoff é ensinado através de fórmulas matemáticas densas. Mas neste artigo, eu tentei explicar Bias e Variance da forma mais simples possível!
>
O meu foco será fazer você girar através do processo de entender a declaração do problema e garantir que você escolha o melhor modelo onde os erros de Bias e Variance são mínimos.
Para isso, eu tenho retomado o popular conjunto de dados dos Índios Pima Diabetes. O conjunto de dados consiste em medições diagnósticas de pacientes adultas do sexo feminino de índios Pima Heritage nativos. Para este conjunto de dados, vamos nos concentrar na variável “Outcome” – que indica se o paciente tem ou não diabetes. Evidentemente, este é um problema de classificação binária e nós vamos mergulhar e aprender como fazê-lo.
Se você estiver interessado nisto e nos conceitos de ciência de dados e quiser aprender praticamente, consulte nosso curso – Introdução à Ciência de Dados
Conteúdo
- Avaliação de um modelo de aprendizagem de máquina
- Declaração de Problemas e Passos Primários
- O que é o Bias?
- O que é Desvio?
- Bias-Variância Tradeoff
Avaliar o seu Modelo de Aprendizagem Máquina
O objectivo principal do modelo de Aprendizagem Máquina é aprender com os dados fornecidos e gerar previsões com base no padrão observado durante o processo de aprendizagem. No entanto, a nossa tarefa não termina aí. Precisamos melhorar continuamente os modelos, com base no tipo de resultados que eles geram. Também quantificamos o desempenho do modelo utilizando métricas como Precisão, Erro Quadrático Médio (MSE), F1-Score, etc. e tentamos melhorar essas métricas. Isto pode ficar complicado quando temos que manter a flexibilidade do modelo sem comprometer a sua correção.
Um modelo supervisionado de Machine Learning tem como objetivo treinar a si mesmo nas variáveis de entrada(X) de tal forma que os valores previstos(Y) estejam o mais próximo possível dos valores reais. Esta diferença entre os valores reais e os valores previstos é o erro e é usada para avaliar o modelo. O erro para qualquer algoritmo de Machine Learning supervisionado é composto por 3 partes:
- Bias error
- Variance error
- O ruído
Apesar de o ruído ser o erro irredutível que não podemos eliminar, os outros dois i.e. Viés e Variância são erros redutíveis que podemos tentar minimizar ao máximo.
Nas seções seguintes, vamos cobrir o erro de Viés, erro de Variância, e o tradeoff de Viés-Variância que nos ajudará na melhor seleção do modelo. E o que é excitante é que vamos cobrir algumas técnicas para lidar com esses erros usando um conjunto de dados de exemplo.
Problem Statement and Primary Steps
Como explicado anteriormente, nós pegamos o conjunto de dados dos Índios Pima Diabetes e formamos um problema de classificação sobre ele. Vamos começar por medir o conjunto de dados e observar o tipo de dados com os quais estamos lidando. Vamos fazer isso importando as bibliotecas necessárias:
Agora, vamos carregar os dados em um quadro de dados e observar algumas linhas para obter insights sobre os dados.
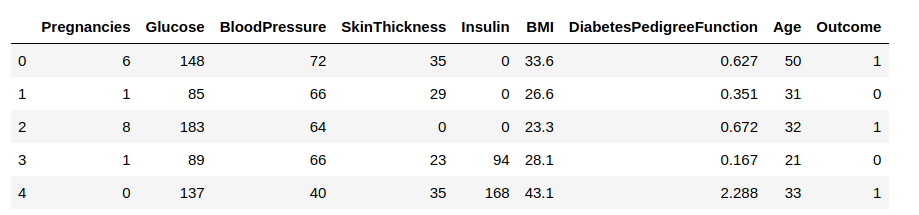
Precisamos prever a coluna ‘Outcome’ (Resultados). Vamos separá-la e atribuí-la a uma variável de destino ‘y’. O resto do quadro de dados será o conjunto de variáveis de entrada X.
Agora vamos escalar as variáveis preditoras e então separar os dados de treinamento e os dados de teste.
Desde que os resultados sejam classificados de forma binária, usaremos o classificador vizinho mais simples K-nearest(Knn) para classificar se o paciente tem diabetes ou não.
No entanto, como decidimos o valor de ‘k’?
- Talvez devamos usar k = 1 para que obtenhamos resultados muito bons nos nossos dados de treinamento? Isso pode funcionar, mas não podemos garantir que o modelo terá o mesmo desempenho nos nossos dados de teste, uma vez que pode ser muito específico
- Que tal usar um valor alto de k, digamos como k = 100 para que possamos considerar um grande número de pontos mais próximos para contabilizar os pontos distantes também? No entanto, este tipo de modelo será demasiado genérico e não podemos ter a certeza de que tenha considerado correctamente todas as possíveis características contributivas.
Deixe-nos pegar em alguns valores possíveis de k e encaixar o modelo nos dados de treino para todos esses valores. Também vamos calcular a pontuação do treinamento e a pontuação do teste para todos esses valores.
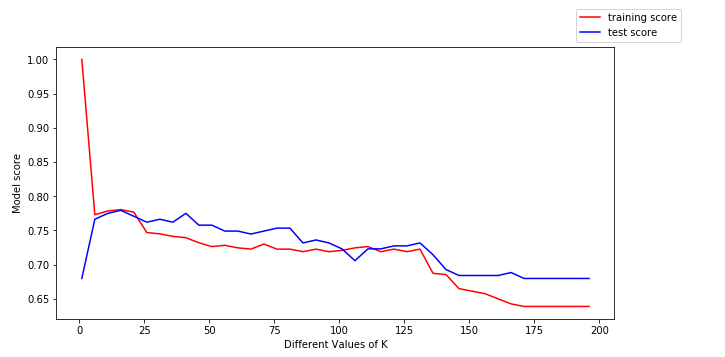
Para obter mais informações, vamos traçar os dados de treinamento (em vermelho) e os dados de teste (em azul).
Para calcular as pontuações para um determinado valor de k,
![]()
Podemos tirar as seguintes conclusões do gráfico acima:
- Para valores baixos de k, a pontuação do treinamento é alta, enquanto a pontuação do teste é baixa
- Quando o valor de k aumenta, a pontuação do teste começa a aumentar e a pontuação do treinamento começa a diminuir.
- No entanto, com algum valor de k, tanto a pontuação do treino como a pontuação do teste estão próximas uma da outra.
É aqui que entra o Viés e a Variância.
O que é Viés?
Em termos mais simples, Viés é a diferença entre o Valor Previsto e o Valor Esperado. Para explicar melhor, o modelo faz certas suposições quando treina sobre os dados fornecidos. Quando é introduzido aos dados de teste/validação, essas suposições podem não estar sempre corretas.
No nosso modelo, se utilizarmos um grande número de vizinhos mais próximos, o modelo pode decidir totalmente que alguns parâmetros não são nada importantes. Por exemplo, ele pode apenas considerar que o nível de Glusoce e a Pressão Arterial decidem se o paciente tem diabetes. Este modelo faria suposições muito fortes sobre os outros parâmetros que não afectam o resultado. Você também pode pensar nele como um modelo prevendo uma relação simples quando os dados indicam claramente uma relação mais complexa:
Matematicamente, deixe as variáveis de entrada serem X e uma variável alvo Y. Mapeamos a relação entre os dois usando uma função f.
Então,
Y = f(X) + e
Aqui ‘e’ é o erro que normalmente é distribuído. O objectivo do nosso modelo f'(x) é prever valores tão próximos de f(x) quanto possível. Aqui, o viés do modelo é:
Bias = E
Como expliquei acima, quando o modelo faz as generalizações, ou seja, quando há um erro de viés elevado, resulta num modelo muito simplista que não considera as variações muito bem. Como ele não aprende os dados de treinamento muito bem, é chamado de Underfitting.
What is a Variance?
Contrary to bias, o Variance é quando o modelo leva em conta as flutuações nos dados, ou seja, o ruído também. Então, o que acontece quando nosso modelo tem uma variância alta?
O modelo ainda considerará a variância como algo a se aprender. Ou seja, o modelo aprende muito com os dados de treinamento, tanto que quando confrontado com novos dados (testes), ele é incapaz de prever com precisão com base nele.
Matematicamente, o erro de variância no modelo é:
Variância-E^2
Desde que no caso de alta variância, o modelo aprende muito com os dados de treinamento, ele é chamado de sobreajuste.
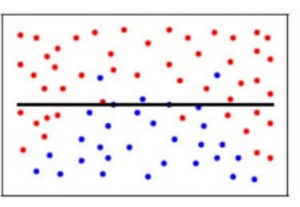
No contexto dos nossos dados, se usamos muito poucos vizinhos mais próximos, é como dizer que se o número de gestações é superior a 3, o nível de glicose é superior a 78, a PA diastólica é inferior a 98, a espessura da pele é inferior a 23 mm e assim por diante para cada característica….. decide que a paciente tem diabetes. Todos os outros pacientes que não atendem aos critérios acima não são diabéticos. Embora isso possa ser verdade para um determinado paciente no conjunto de treinamento, e se esses parâmetros são os outliers ou foram mesmo registrados incorretamente? Claramente, tal modelo poderia ser muito caro!
Adicionalmente, este modelo teria um erro de variação elevado porque as previsões do paciente ser diabético ou não variam muito com o tipo de dados de treino que estamos a fornecer. Assim, mesmo mudando o Nível de Glicose para 75 resultaria no modelo prever que o paciente não tem diabetes.
Para simplificar, o modelo prevê relações muito complexas entre o resultado e as características de entrada quando uma equação quadrática teria sido suficiente. É assim que um modelo de classificação se pareceria quando houvesse um erro de variância elevado/quando houvesse sobreajustamento:
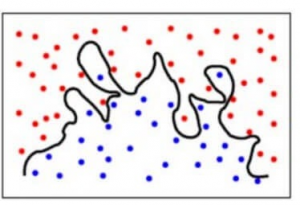
Para resumir,
- Um modelo com um erro de viés elevado ajusta-se aos dados e faz suposições muito simplistas sobre ele
- Um modelo com um erro de variância elevado ajusta-se aos dados e aprende demasiado com ele
- Um bom modelo é onde tanto os erros de viés como os erros de variância são equilibrados
Bias-Variance Tradeoff
Como relacionamos os conceitos acima com o nosso modelo Knn de antes? Vamos descobrir!
No nosso modelo, digamos, para, k = 1, o ponto mais próximo do datapoint em questão será considerado. Aqui, a previsão pode ser precisa para esse ponto de dados em particular, então o erro de desvio será menor.
No entanto, o erro de desvio será alto, já que apenas o ponto mais próximo é considerado e isso não leva em conta os outros pontos possíveis. A que cenário você acha que isto corresponde? Sim, você está pensando certo, isto significa que o nosso modelo está sobreajustando.
Por outro lado, para valores mais altos de k, muito mais pontos mais próximos do ponto de referência em questão serão considerados. Isto resultaria em maior erro de viés e subajuste, já que muitos pontos mais próximos do datapoint são considerados e, portanto, não pode aprender as especificidades do conjunto de treinamento. No entanto, podemos contabilizar um erro de desvio menor para o conjunto de teste que tem valores desconhecidos.
Para alcançar um equilíbrio entre o erro de Polarização e o erro de Variância, precisamos de um valor de k tal que o modelo não aprenda com o ruído (sobreajuste de dados) nem faça suposições de varredura sobre os dados (subajuste de dados). Para mantê-lo mais simples, um modelo equilibrado pareceria assim:
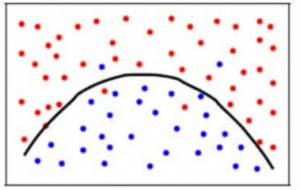
Embora alguns pontos sejam classificados incorretamente, o modelo geralmente se encaixa na maioria dos pontos de dados com precisão. O equilíbrio entre o erro de Bias e o erro de Variância é o Bias-Variance Tradeoff.
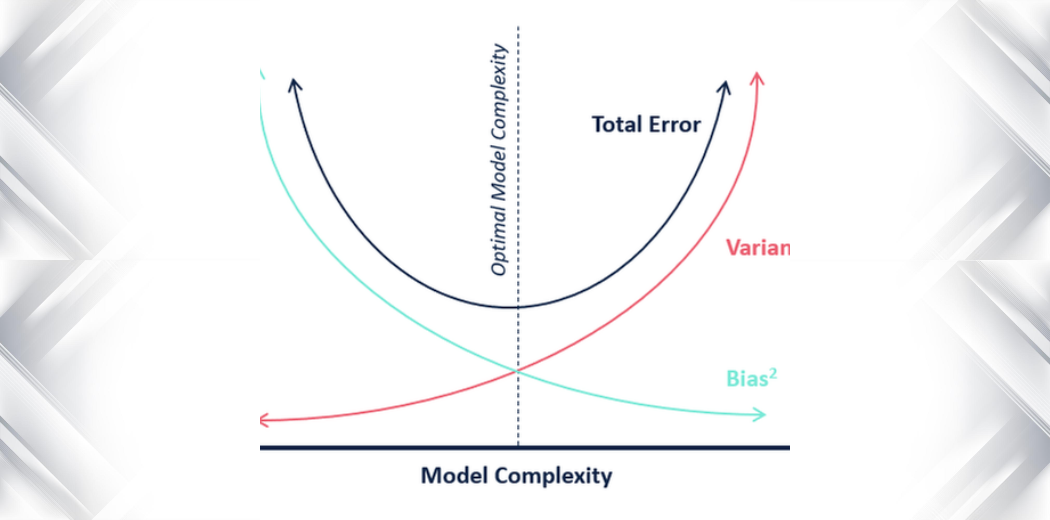
O seguinte diagrama de Bias-eye explica melhor o tradeoff:
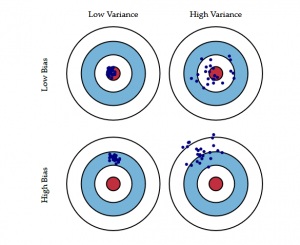
O centro, ou seja, o olho do touro é o resultado do modelo que queremos alcançar e que prevê perfeitamente todos os valores correctamente. Conforme nos afastamos do olho do touro, nosso modelo começa a fazer mais e mais previsões erradas.
Um modelo com baixa polarização e alta variância prevê pontos que estão em torno do centro em geral, mas muito longe um do outro. Um modelo com viés alto e baixa variância está bastante longe do olho do touro, mas como a variância é baixa, os pontos previstos estão mais próximos uns dos outros.
Em termos de complexidade do modelo, podemos usar o diagrama a seguir para decidir sobre a complexidade ótima do nosso modelo.
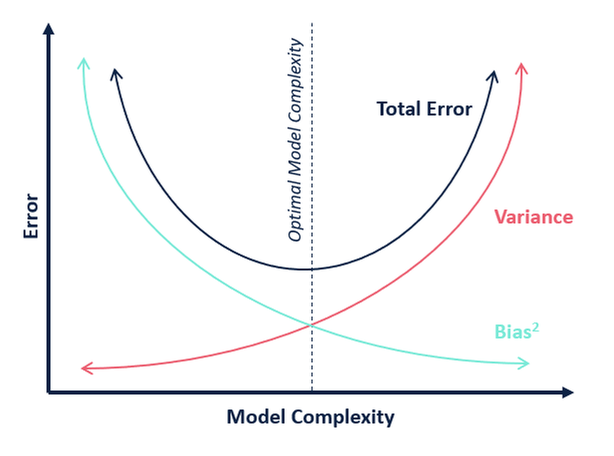
Então, o que você acha que é o valor ótimo para k?
Da explicação acima, podemos concluir que o k para o qual
- a pontuação do teste é o maior, e
- tanto a pontuação do teste quanto a pontuação do treinamento são próximas uma da outra
é o valor ótimo de k. Assim, apesar de estarmos comprometendo uma pontuação mais baixa no treinamento, ainda assim obtemos uma pontuação alta para nossos dados de teste, o que é mais crucial – os dados do teste são, afinal, dados desconhecidos.
Deixe-nos fazer uma tabela para diferentes valores de k para provar isto:
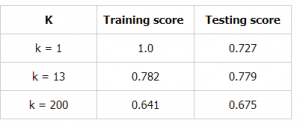
Conclusão
Para resumir, neste artigo, aprendemos que um modelo ideal seria aquele onde tanto o erro de viés quanto o erro de variância são baixos. Entretanto, devemos sempre apontar para um modelo em que a pontuação do modelo para os dados de treinamento seja a mais próxima possível da pontuação do modelo para os dados de teste.
Foi aí que descobrimos como escolher um modelo que não seja muito complexo (Alta variância e baixo viés) o que levaria ao sobreajuste e nem muito simples (Alta viés e baixa variância) o que levaria ao subajuste.
Bias e Variância tem um papel importante na decisão de qual modelo preditivo usar. Espero que este artigo tenha explicado bem o conceito.