
Se você quiser aprender mais em Python, faça o curso gratuito de Introdução ao DataCamp em Python para Ciência dos Dados.
Todos vocês já viram conjuntos de dados. Algumas vezes eles são pequenos, mas muitas vezes, eles são tremendamente grandes em tamanho. Torna-se muito difícil processar os conjuntos de dados que são muito grandes, pelo menos significativos o suficiente para causar um gargalo de processamento.
Então, o que faz com que esses conjuntos de dados sejam tão grandes? Bem, são características. Quanto maior for o número de características, maiores serão os conjuntos de dados. Bem, nem sempre. Você vai encontrar conjuntos de dados onde o número de características é muito grande, mas eles não contêm tantas instâncias. Mas esse não é o ponto de discussão aqui. Então, você pode se perguntar com um computador de mercadorias em mãos como processar esses tipos de conjuntos de dados sem bater o bush.
Muitas vezes, em um conjunto de dados de alta dimensão, permanecem algumas características totalmente irrelevantes, insignificantes e sem importância. Tem-se visto que a contribuição destes tipos de características é muitas vezes menos para a modelagem preditiva do que para as características críticas. Eles também podem ter contribuição zero. Estas características causam uma série de problemas que, por sua vez, impedem o processo de modelagem preditiva eficiente –
- Alocação desnecessária de recursos para estas características.
- Estas características atuam como um ruído para o qual o modelo de aprendizagem da máquina pode funcionar terrivelmente mal.
- O modelo da máquina leva mais tempo para ser treinado.
Então, qual é a solução aqui? A solução mais económica é Feature Selection.
Feature Selection é o processo de selecção das características mais significativas de um dado conjunto de dados. Em muitos dos casos, Feature Selection pode melhorar o desempenho de um modelo de aprendizagem de máquina também.
Sons interessantes direito?
Você tem uma introdução informal a Feature Selection e sua importância no mundo da Ciência de Dados e Aprendizagem de Máquina. Neste post você vai cobrir:
>
- Introdução à selecção de características e compreensão da sua importância
- Diferença entre selecção de características e redução de dimensão
- Diferentes tipos de métodos de selecção de características
- Aplicação de diferentes métodos de selecção de características com o scikit-learn
Introduction to feature selection
Selecção de características também é conhecida como Selecção de Variável ou Selecção de Atributos.
Essencialmente, é o processo de selecção do mais importante/relevante. Características de um conjunto de dados.
Entendendo a importância da seleção de características
A importância da seleção de características pode ser melhor reconhecida quando você está lidando com um conjunto de dados que contém um vasto número de características. Este tipo de conjunto de dados é frequentemente referido como um conjunto de dados de alta dimensão. Agora, com esta alta dimensionalidade, surgem muitos problemas, tais como – esta alta dimensionalidade irá aumentar significativamente o tempo de treino do seu modelo de aprendizagem da máquina, pode tornar o seu modelo muito complicado o que, por sua vez, pode levar a um Overfitting.
A maior parte das vezes, num conjunto de características de alta dimensão, permanecem várias características que são redundantes, o que significa que estas características não são mais do que extensões das outras características essenciais. Estes recursos redundantes não contribuem efetivamente para o treinamento do modelo também. Portanto, claramente, há uma necessidade de extrair as características mais importantes e mais relevantes para um conjunto de dados, a fim de obter o desempenho mais eficaz da modelagem preditiva.
“O objetivo da seleção de variáveis é triplo: melhorar o desempenho da previsão dos preditores, fornecendo preditores mais rápidos e com melhor custo-benefício, e fornecer uma melhor compreensão do processo subjacente que gerou os dados.”
-An Introdução à Seleção de Variável e Característica
Agora vamos entender a diferença entre redução de dimensionalidade e seleção de característica.
Algumas vezes, a seleção de característica é confundida com redução de dimensionalidade. Mas elas são diferentes. A selecção de características é diferente da redução de dimensionalidade. Ambos os métodos tendem a reduzir o número de atributos no conjunto de dados, mas um método de redução de dimensionalidade faz isso criando novas combinações de atributos (às vezes conhecidas como transformação de característica), enquanto os métodos de seleção de característica incluem e excluem atributos presentes nos dados sem alterá-los.
Alguns exemplos de métodos de redução de dimensionalidade são a Análise de Componentes Principais, Decomposição de Valor Singular, Análise Linear Discriminatória, etc.
Deixe-me resumir a importância da selecção de características para si:
- Permite que o algoritmo de aprendizagem da máquina treine mais rapidamente.
- Reduz a complexidade de um modelo e facilita a interpretação.
- Melhora a precisão de um modelo se for escolhido o subconjunto certo.
- Reduz o Sobre-equipamento.
Na próxima seção, você estudará os diferentes tipos de métodos de seleção de características gerais – métodos de filtragem, métodos Wrapper e métodos Embutidos.
Métodos de filtragem
A imagem a seguir descreve melhor os métodos de seleção de características baseadas em filtragem:

Image Source: Analytics Vidhya
O método do filtro depende da singularidade geral dos dados a serem avaliados e do subconjunto de características a serem escolhidas, não incluindo qualquer amálgama de mineração. O método de filtro utiliza o critério exato de avaliação que inclui distância, informação, dependência e consistência. O método de filtro usa os principais critérios da técnica de classificação e usa o método de ordenação de classificação para a seleção de variáveis. A razão para utilizar o método de classificação é a simplicidade, produzir características excelentes e relevantes. O método de classificação filtrará características irrelevantes antes do início do processo de classificação.
Os métodos de filtragem são geralmente usados como uma etapa de pré-processamento de dados. A seleção das características é independente de qualquer algoritmo de aprendizagem da máquina. As características dão classificação com base em resultados estatísticos que tendem a determinar a correlação das características com a variável de resultado. A correlação é um termo fortemente contextual, e varia de trabalho para trabalho. Você pode consultar a seguinte tabela para definir coeficientes de correlação para diferentes tipos de dados (neste caso contínuo e categórico).

Image Source: Analytics Vidhya
Alguns exemplos de alguns métodos de filtragem incluem o teste Qui-quadrado, ganho de informação e pontuação dos coeficientes de correlação.
Próximo, você verá os métodos Wrapper.
Métodos Wrapper
Métodos de filtragem, deixe-me dar-lhe um mesmo tipo de info-gráfico que o ajudará a compreender melhor os métodos Wrapper:
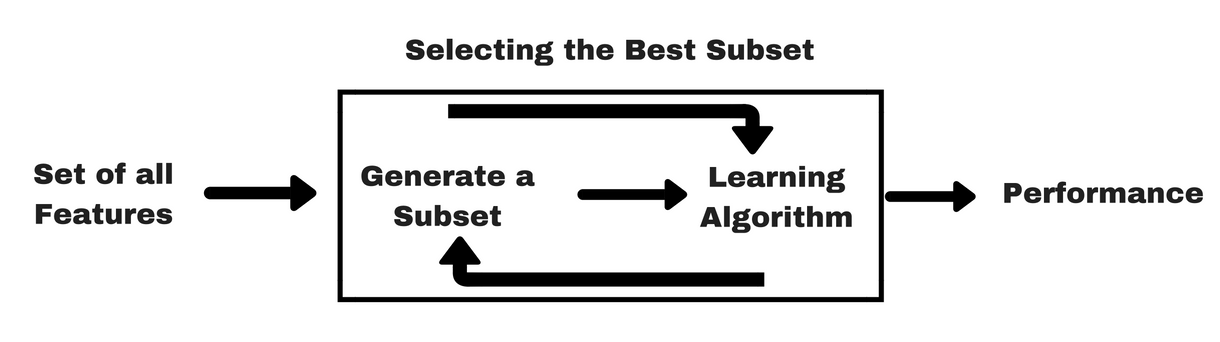
Fonte de Imagem: Analytics Vidhya
Como você pode ver na imagem acima, um método de wrapper precisa de um algoritmo de aprendizagem de máquina e usa seu desempenho como critério de avaliação. Este método procura uma característica que seja mais adequada para o algoritmo de aprendizagem da máquina e visa melhorar o desempenho da mineração. Para avaliar as características, a precisão preditiva usada para tarefas de classificação e a bondade do cluster é avaliada usando o clustering.
Alguns exemplos típicos de métodos de empacotamento são a seleção de características para frente, eliminação de características para trás, eliminação de características recursivas, etc.
- Seleção para frente: O procedimento começa com um conjunto vazio de características . O melhor das características originais é determinado e adicionado ao conjunto reduzido. Em cada iteração subsequente, o melhor dos atributos originais restantes é adicionado ao conjunto.
- Eliminação para trás: O procedimento começa com o conjunto completo de atributos. A cada passo, ele remove o pior atributo remanescente no conjunto.
- Combinação de seleção avançada e eliminação regressiva: Os métodos de seleção progressiva e de eliminação regressiva podem ser combinados para que, em cada etapa, o procedimento selecione o melhor atributo e remova o pior de entre os atributos restantes.
- Eliminação recursiva de característica: Eliminação de característica recursiva realiza uma busca gananciosa para encontrar o subconjunto de característica com melhor desempenho. Cria iterativamente modelos e determina o melhor ou o pior desempenho em cada iteração. Constrói os modelos subsequentes com as características esquerdas até que todas as características sejam exploradas. Em seguida, classifica as funcionalidades com base na ordem da sua eliminação. No pior caso, se um conjunto de dados contiver N número de características RFE fará uma busca gananciosa por combinações de características 2N.
Bom o suficiente!
Agora vamos estudar métodos embutidos.
Métodos embutidos
Métodos embutidos são iterativos num sentido que cuida de cada iteração do processo de treinamento do modelo e extrai cuidadosamente aquelas características que mais contribuem para o treinamento de uma determinada iteração. Métodos de regularização são os métodos embutidos mais comumente usados que penalizam uma característica dado um limite de coeficiente.
É por isso que métodos de regularização também são chamados de métodos de penalização que introduzem restrições adicionais na otimização de um algoritmo preditivo (como um algoritmo de regressão) que enviesam o modelo para uma complexidade mais baixa (menos coeficientes).
Exemplos de algoritmos de regularização são o LASSO, Elastic Net, Ridge Regression, etc.
Diferença entre métodos de filtragem e de wrapper
Bem, às vezes pode ficar confuso diferenciar entre métodos de filtragem e métodos de wrapper em termos de suas funcionalidades. Vamos ver em que pontos eles diferem uns dos outros.
- Os métodos de filtragem não incorporam um modelo de aprendizagem de máquina a fim de determinar se uma funcionalidade é boa ou má, enquanto os métodos de embalamento usam um modelo de aprendizagem de máquina e treinam a funcionalidade para decidir se ela é essencial ou não.
- Os métodos de filtragem são muito mais rápidos em comparação com os métodos de embalamento, pois não envolvem o treino dos modelos. Por outro lado, os métodos de wrapper são computacionalmente caros, e no caso de conjuntos de dados massivos, os métodos de wrapper não são o método de selecção de características mais eficaz a considerar.
- Os métodos de wrapper podem não encontrar o melhor subconjunto de características em situações em que não há dados suficientes para modelar a correlação estatística das características, mas os métodos de wrapper podem sempre fornecer o melhor subconjunto de características devido à sua natureza exaustiva.
- Usar características dos métodos de embalamento no seu modelo final de aprendizagem da máquina pode levar ao sobreajustamento, uma vez que os métodos de embalamento já treinam modelos de aprendizagem da máquina com as características e afecta o verdadeiro poder da aprendizagem. Mas as características dos métodos de filtragem não conduzirão ao sobreajuste na maioria dos casos
Até agora você estudou a importância da seleção de características, compreendeu a sua diferença com a redução da dimensionalidade. Você também cobriu vários tipos de métodos de seleção de características. Até agora, tudo bem!
Agora, vamos ver algumas armadilhas em que você pode se meter enquanto executa a seleção de recursos:
Ponderações importantes
Você já deve ter entendido o valor da seleção de recursos em um pipeline de aprendizagem de máquina e o tipo de serviços que ela fornece se integrada. Mas é muito importante entender exatamente onde você deve integrar a seleção de características no seu pipeline de aprendizagem da máquina.
Simplesmente falando, você deve incluir a etapa de seleção de características antes de alimentar o modelo com os dados para treinamento, especialmente quando você estiver usando métodos de estimativa de precisão, como a validação cruzada. Isto assegura que a selecção de características seja efectuada na dobra de dados mesmo antes de o modelo ser treinado. Mas se você executar a seleção de recurso primeiro para preparar seus dados, então executar a seleção e o treinamento do modelo nos recursos selecionados, então seria um erro.
Se você executar a seleção de recurso em todos os dados e depois a validação cruzada, então os dados de teste em cada dobra do procedimento de validação cruzada também foram usados para escolher os recursos, e isso tende a enviesar o desempenho do modelo de aprendizagem da sua máquina.
Suficiente de teorias! Vamos direto para alguma codificação agora.
Um estudo de caso em Python
Para este estudo de caso, você usará o conjunto de dados do Pima Indians Diabetes. A descrição do conjunto de dados pode ser encontrada aqui.
O conjunto de dados corresponde a tarefas de classificação nas quais você precisa prever se uma pessoa tem diabetes com base em 8 características.
Há um total de 768 observações no conjunto de dados. A sua primeira tarefa é carregar o conjunto de dados para que você possa prosseguir. Mas antes disso, vamos importar as dependências necessárias, você vai precisar. Você pode importar as outras à medida que você for avançando.
import pandas as pdimport numpy as npAgora as dependências são importadas vamos carregar o conjunto de dados dos índios Pima em um objeto Dataframe com a ajuda da biblioteca Pandas.
data = pd.read_csv("diabetes.csv")O conjunto de dados é carregado com sucesso nos dados do objeto Dataframe. Agora, vamos dar uma olhada nos dados.
data.head()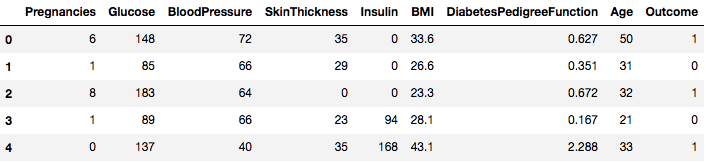
Então você pode ver 8 características diferentes rotuladas nos resultados de 1 e 0 onde 1 significa que a observação tem diabetes, e 0 denota que a observação não tem diabetes. O conjunto de dados é conhecido por ter valores em falta. Especificamente, há observações em falta para algumas colunas que estão marcadas como um valor zero. Você pode deduzir isso pela definição dessas colunas, e é impraticável ter um valor zero é inválido para essas medidas, por exemplo zero para índice de massa corporal ou pressão arterial é inválido.
Mas para este tutorial, você usará diretamente a versão pré-processada do conjunto de dados.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Você carregou os dados em um objeto DataFrame chamado Dataframe agora.
Vamos converter o objeto DataFrame para um array NumPy para obter um cálculo mais rápido. Também, vamos segregar os dados em variáveis separadas para que as características e as etiquetas sejam separadas.
array = dataframe.valuesX = arrayY = arrayMaravilhoso! Você preparou seus dados.
Primeiro, você implementará um teste estatístico Chi-Squared para características não-negativas para selecionar 4 das melhores características do conjunto de dados. Você já viu que o teste Chi-Squared pertence à classe dos métodos de filtragem. Se alguém está curioso em conhecer os internos do Chi-Squared, este vídeo faz um excelente trabalho.
A biblioteca scikit-learn fornece a classe SelectKBest que pode ser usada com um conjunto de diferentes testes estatísticos para selecionar um número específico de características, neste caso, é Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Você importou as bibliotecas para executar os experimentos. Agora, vamos vê-lo em action.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Interpretação:
É possível ver as pontuações para cada atributo e os 4 atributos escolhidos (aqueles com as pontuações mais altas): plas, teste, massa e idade. Esta pontuação irá ajudá-lo ainda mais na determinação das melhores características para o treino do seu modelo.
P.S.: A primeira linha denota os nomes das características. Para pré-processamento do conjunto de dados, os nomes foram codificados numericamente.
P.S.: A primeira linha denota os nomes das características. Para pré-processamento do conjunto de dados, os nomes foram codificados numericamente.
A Eliminação de Característica Recursiva (ou RFE) funciona removendo recursivamente os atributos e construindo um modelo sobre aqueles atributos que permanecem.
Ele usa a precisão do modelo para identificar quais atributos (e combinação de atributos) contribuem mais para prever o atributo alvo.
Você pode aprender mais sobre a classe RFE na documentação scikit-learn.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionVocê usará RFE com o classificador Logistic Regression para selecionar os 3 principais recursos. A escolha do algoritmo não importa muito desde que seja hábil e consistente.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Você pode ver que RFE escolheu os 3 principais recursos como preg, mass, e pedi.
Estes são marcados com True no array de suporte e marcados com uma escolha “1” no array de classificação. Isto, por sua vez, indica a força destas características.
Próximo você usará a regressão de Ridge que é basicamente uma técnica de regularização e uma técnica de seleção de características embutida também.
Este artigo lhe dá uma excelente explicação sobre a regressão de Ridge. Certifique-se de verificar.
# First things firstfrom sklearn.linear_model import RidgeNext, você usará a regressão de Ridge para determinar o coeficiente R2.
Além disso, verifique a documentação oficial do scikit-learn sobre a regressão de Ridge.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)A fim de compreender melhor os resultados da regressão de Ridge, você implementará uma pequena função de ajuda que o ajudará a imprimir os resultados de uma forma melhor para que você possa interpretá-los facilmente.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)Próximo, você vai passar os termos do coeficiente do modelo de Ridge para esta pequena função e ver o que acontece.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Você pode identificar todos os termos do coeficiente anexados com as variáveis de característica. Ele irá ajudá-lo novamente a escolher as características mais essenciais. Abaixo estão alguns pontos que você deve ter em mente ao aplicar a regressão de Ridge:
- É também conhecida como L2-Regularization.
- Para características correlacionadas, significa que elas tendem a obter coeficientes semelhantes.
- As características com coeficientes negativos não contribuem muito. Mas em um cenário mais complexo onde você está lidando com muitas características, então esta pontuação definitivamente o ajudará no processo final de decisão de seleção de características.
Bem, isso conclui a seção de estudo de caso. Os métodos que você implementou na seção acima irão ajudá-lo a entender as características de um conjunto de dados em particular de uma forma abrangente. Deixe-me dar-lhe alguns pontos críticos sobre estas técnicas:
- A selecção de características é essencialmente uma parte do pré-processamento de dados que é considerada como a parte mais demorada de qualquer pipeline de aprendizagem de máquinas.
- Estas técnicas irão ajudá-lo a abordá-lo de uma forma mais sistemática e amigável à aprendizagem de máquinas. Você será capaz de interpretar as características com mais precisão.
Wrap up!
Neste post, você cobriu um dos tópicos estatísticos mais bem estudados e bem pesquisados, ou seja, seleção de características. Você também se familiarizou com suas diferentes variantes e as usou para ver quais características de um conjunto de dados são importantes.
Você pode levar este tutorial mais longe fundindo uma medida de correlação no método de invólucro e ver como ele funciona. No curso da ação, você pode acabar criando seu próprio mecanismo de seleção de características. É assim que você estabelece a base para a sua pequena pesquisa. Os pesquisadores também estão usando vários princípios de soft computing para realizar a seleção. Este é, em si mesmo, um campo completo de estudo e pesquisa. Além disso, você deve experimentar os algoritmos de seleção de recursos existentes em vários conjuntos de dados e desenhar suas próprias inferências.
Por que esses métodos tradicionais de seleção de recursos ainda se mantêm?
Sim, essa questão é óbvia. Porque existem arquiteturas de redes neurais (por exemplo CNNs) que são bastante capazes de extrair os recursos mais significativos dos dados, mas isso também tem uma limitação. Usar uma CNN para um conjunto de dados tabulares regulares que não tem propriedades específicas (as propriedades que uma imagem típica possui como propriedades de transição, bordas, propriedades posicionais, contornos, etc.) não é a decisão mais sábia a tomar. Além disso, quando você tem dados limitados e recursos limitados, o treinamento de uma CNN em conjuntos de dados tabulares regulares pode se transformar em um desperdício completo. Assim, em situações como essa, os métodos que você estudou definitivamente virão à mão.
Os seguintes são alguns recursos se você gostaria de cavar mais sobre este tópico:
- Seleção de Recursos para Descoberta de Conhecimento e Mineração de Dados
- Subespaço, Estrutura Latente e Seleção de Recursos: Workshop de Estatística e Perspectivas de Otimização
- Seleção de Característica: Declaração de problemas e usos
- Usar algoritmos genéticos para seleção de recursos em Análise de dados
Below são as referências que foram usadas para escrever este tutorial.
- Data Mining: Conceitos e Técnicas; Jiawei Han Micheline Kamber Jian Pei.
- Uma introdução à seleção de características
- Analytics Vidhya artigo sobre seleção de características
- Modelo hierárquico e misto – curso DataCamp
- Seleção de características para aprendizado de máquina em Python
- Detecção anterior em fluxo de dados por métodos de aprendizado de máquina e seleção de características
- S. Visalakshi e V. Radha, “Uma revisão da literatura sobre técnicas e aplicações de seleção de recursos”: Revisão de seleção de características em mineração de dados”, 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, pp. 1-6.