
Antes de começar esta jornada de tentar aprender informática, havia certos termos e frases que me faziam querer correr na outra direcção.
Mas em vez de correr, fingi saber, acenando com a cabeça em conversas, fingindo que sabia o que alguém estava a referir, embora a verdade fosse que eu não fazia ideia e tinha parado de ouvir por completo quando ouvi Aquele Super Assustador Informático Term™. Ao longo do curso desta série, consegui cobrir muito terreno e muitos desses termos tornaram-se na verdade muito menos assustadores!
Mas há um grande, que tenho evitado por um tempo. Até agora, sempre que tinha ouvido este termo, sentia-me paralisado. Surgiu em conversas casuais em reuniões e, às vezes, em conversas de conferência. Todas as vezes, penso em máquinas girando e computadores cuspindo fios de código que são indecifráveis, exceto que todos à minha volta podem realmente decifrá-los, então na verdade sou só eu que não sei o que está acontecendo (whoops como isso aconteceu?!).
Talvez eu não seja o único que tem se sentido assim. Mas, suponho que devo dizer-lhe qual é realmente este termo, certo? Bem, prepare-se, porque eu estou me referindo a uma árvore de sintaxe abstrata sempre e aparentemente confusa, ou AST para abreviar. Após muitos anos de intimidação, estou entusiasmado por finalmente parar de ter medo deste termo e compreender verdadeiramente o que é na terra.
Está na hora de enfrentar a raiz da árvore de sintaxe abstracta de frente – e nivelar o nosso jogo de análise!
Muita boa busca começa com uma base sólida, e nossa missão de desmistificar esta estrutura deve começar exatamente da mesma forma: com uma definição, é claro!
Uma árvore de sintaxe abstrata (geralmente chamada apenas de AST) não é nada mais que uma versão simplificada e condensada de uma árvore parse. No contexto do design do compilador, o termo “AST” é usado de forma intercambiável com a árvore sintáctica.

Pensamos muitas vezes em árvores de sintaxe (e como elas são construídas) em comparação com as suas contrapartes de árvore parse, com as quais já estamos bastante familiarizados. Sabemos que árvores parse são estruturas de dados de árvores que contêm a estrutura gramatical do nosso código; em outras palavras, elas contêm toda a informação sintática que aparece em uma “frase” de código, e é derivada diretamente da gramática da própria linguagem de programação.
Uma árvore de sintaxe abstrata, por outro lado, ignora uma quantidade significativa da informação sintática que uma árvore parse conteria de outra forma.
Por contraste, um AST contém apenas a informação relacionada à análise do texto fonte, e salta qualquer outro conteúdo extra que é usado durante a análise do texto.
Esta distinção começa a fazer muito mais sentido se nos concentrarmos na “abstrato” de um AST.
Lembraremos que uma árvore parse é uma versão ilustrada, pictórica, da estrutura gramatical de uma frase. Em outras palavras, podemos dizer que uma árvore de parse representa exatamente como uma expressão, frase ou texto se parece. É basicamente uma tradução direta do texto em si; pegamos a frase e transformamos cada pedacinho dela – da pontuação às expressões às fichas – em uma estrutura de dados em árvore. Ela revela a sintaxe concreta de um texto, por isso também é referida como uma árvore de sintaxe concreta, ou CST. Usamos o termo concreto para descrever essa estrutura porque é uma cópia gramatical do nosso código, ficha por ficha, em formato de árvore.
Mas o que faz algo concreto versus abstrato? Bem, uma árvore de sintaxe abstrata não nos mostra exatamente como uma expressão se parece, como uma árvore parse faz.
Reta, uma árvore de sintaxe abstrata nos mostra as partes “importantes” – as coisas com as quais realmente nos importamos, que dão sentido à nossa própria “frase” de código. Árvores de sintaxe nos mostram as partes significativas de uma expressão, ou a sintaxe abstraída do nosso texto fonte. Assim, em comparação com a sintaxe concreta, essas estruturas são representações abstratas do nosso código (e de certa forma, menos exatas), que é exatamente como elas receberam seu nome.
Agora que entendemos a distinção entre essas duas estruturas de dados e as diferentes maneiras que elas podem representar nosso código, vale a pena fazer a pergunta: onde uma árvore de sintaxe abstrata cabe no compilador? Primeiro, vamos nos lembrar de tudo que sabemos sobre o processo de compilação como o conhecemos até agora.

Vamos dizer que temos um texto fonte super curto e doce, que se parece com isto: 5 + (1 x 12).
Lembraremos que a primeira coisa que acontece no processo de compilação é a digitalização do texto, um trabalho realizado pelo scanner, que resulta na divisão do texto em suas menores partes possíveis, que são chamadas de lexemas. Esta parte será agnóstica da linguagem, e acabaremos com a versão descascada do nosso texto fonte.
Next, estes mesmos lexemas são passados para o lexer/tokenizer, o que transforma aquelas pequenas representações do nosso texto fonte em fichas, que serão específicas para a nossa linguagem. Os nossos tokens terão um aspecto semelhante a este: . O esforço conjunto do scanner e do tokenizer compõem a análise léxica da compilação.
Então, uma vez que nossa entrada tenha sido tokenizada, seus tokens resultantes são passados ao nosso analisador, que então pega o texto fonte e constrói uma árvore de parse para fora dele. A ilustração abaixo exemplifica como é o nosso código tokenizado, em formato de árvore parse.
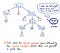
O trabalho de transformar os tokens em árvore parse também é chamado de parse, e é conhecido como fase de análise de sintaxe. A fase de análise de sintaxe depende diretamente da fase de análise léxica; assim, a análise léxica deve sempre vir em primeiro lugar no processo de compilação, pois o analisador do nosso compilador só pode fazer o seu trabalho uma vez que o tokenizer faz o seu trabalho!
Podemos pensar nas partes do compilador como bons amigos, que dependem uns dos outros para garantir que nosso código seja corretamente transformado de um texto ou arquivo em uma árvore parse.
Mas voltando à nossa pergunta original: onde a árvore de sintaxe abstrata se encaixa neste grupo de amigos? Bem, para responder a essa pergunta, ajuda a entender a necessidade de um AST em primeiro lugar.
Condensar uma árvore em outra
Okay, então agora temos duas árvores para manter em linha reta em nossas cabeças. Nós já tínhamos uma árvore parse, e como há ainda outra estrutura de dados para aprender! E aparentemente, esta estrutura de dados AST é apenas uma árvore de dados parse simplificada. Então, porque é que precisamos dela? Qual é mesmo a razão disso?
Bem, vamos dar uma olhada na nossa árvore de análise, vamos?
Já sabemos que as árvores de análise representam o nosso programa nas suas partes mais distintas; de facto, é por isso que o scanner e o tokenizer têm trabalhos tão importantes de decompor a nossa expressão nas suas partes mais pequenas!
O que significa realmente representar um programa pelas suas partes mais distintas?
Como se vê, às vezes todas as partes distintas de um programa não são tão úteis para nós o tempo todo.
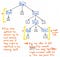
Vejamos a ilustração aqui apresentada, que representa a nossa expressão original, 5 + (1 x 12), em formato de árvore parse. Se olharmos de perto esta árvore com um olhar crítico, veremos que há alguns casos em que um nó tem exatamente um filho, que também são referidos como nós únicos sucessores, pois eles têm apenas um nó filho proveniente deles (ou um “sucessor”).
No caso do nosso exemplo de árvore parse, os nós de um único sucessor têm um nó pai de um Expression, ou Exp, que têm um único sucessor de algum valor, como 5, 1, ou 12. No entanto, os nós Exp superiores aqui não estão realmente acrescentando nada de valor para nós, estão eles? Podemos ver que eles contêm nós criança token/terminal, mas nós realmente não nos importamos com o nó pai “expressão”; tudo que realmente queremos saber é qual é a expressão?
O nó pai não nos dá nenhuma informação adicional depois de termos analisado a nossa árvore. Em vez disso, o que realmente nos preocupa é o nó filho único, o nó sucessor único. Na verdade, esse é o nó que nos dá a informação importante, a parte que é significativa para nós: o número e o valor em si! Considerando o fato de que estes nós pais são meio desnecessários para nós, torna-se óbvio que esta árvore parse é uma espécie de verbo.
Todos estes nós únicos sucessores são bastante supérfluos para nós, e não nos ajudam em nada. Então, vamos nos livrar deles!
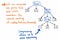
Se comprimirmos os nós monossuccessores em nossa árvore parse, acabaremos com uma versão mais comprimida da mesma estrutura exata. Olhando a ilustração acima, veremos que ainda estamos mantendo exatamente o mesmo ninho de antes, e os nossos nós/tokens/terminais ainda estão aparecendo no lugar correto dentro da árvore. Mas, nós conseguimos diminuir um pouco.
E podemos aparar mais um pouco da nossa árvore, também. Por exemplo, se olharmos para a nossa árvore parse como ela está no momento, veremos que há uma estrutura espelhada dentro dela. A subexpressão de (1 x 12) está aninhada dentro de parênteses (), que são símbolos por direito próprio.
No entanto, estes parênteses não nos ajudam realmente uma vez que tenhamos a nossa árvore no lugar. Já sabemos que 1 e 12 são argumentos que serão passados para a multiplicação x operação, por isso os parênteses não nos dizem muito neste ponto. Na verdade, poderíamos comprimir ainda mais nossa árvore parse e nos livrarmos desses nós supérfluos de folhas.
Após comprimirmos e simplificarmos nossa árvore parse e nos livrarmos do “pó” sintático externo, acabamos com uma estrutura que parece visivelmente diferente neste ponto. Essa estrutura é, de fato, nossa nova e muito esperada amiga: a árvore de sintaxe abstrata.

A imagem acima ilustra exatamente a mesma expressão da nossa árvore de parse: 5 + (1 x 12). A diferença é que ela abstraiu a expressão da sintaxe concreta. Não vemos mais nenhum dos parênteses () nesta árvore, porque eles não são necessários. Da mesma forma, não vemos os não-terminais como Exp, pois já descobrimos o que é a “expressão”, e somos capazes de extrair o valor que realmente nos interessa – por exemplo, o número 5.
Este é exatamente o fator distintivo entre um AST e um CST. Sabemos que uma árvore de sintaxe abstrata ignora uma quantidade significativa da informação sintática que uma árvore parse contém, e salta o “conteúdo extra” que é usado no parsing. Mas agora podemos ver exatamente como isso acontece!

Agora que tenhamos condensado uma árvore parse própria, seremos muito melhores em pegar alguns dos padrões que distinguem um AST de um CST.
Existirão algumas maneiras de uma árvore de sintaxe abstrata que se diferenciará visualmente de uma árvore de parse:
- Um AST nunca conterá detalhes sintáticos, tais como vírgulas, parênteses e ponto e vírgula (dependendo, é claro, da linguagem).
- Um AST terá uma versão colapsada do que de outra forma apareceria como nós de um único sucessor; ele nunca conterá “cadeias” de nós com um único filho.
- Finalmente, quaisquer fichas de operador (como
+,-,x, e/) se tornarão nós internos (pai) na árvore, ao invés das folhas que terminam em uma árvore parse.
Visualmente, um AST sempre aparecerá mais compacto que uma árvore parse, uma vez que é, por definição, uma versão comprimida de uma árvore parse, com menos detalhes sintáticos.
É lógico, então, que se um AST é uma versão compactada de uma árvore parse, só podemos realmente criar uma árvore de sintaxe abstrata se tivermos as coisas para construir uma árvore parse para começar!
É, de fato, assim que a árvore de sintaxe abstrata se encaixa no processo de compilação maior. Um AST tem uma conexão direta com as árvores parse que já aprendemos, enquanto simultaneamente confiamos no lexer para fazer seu trabalho antes que um AST possa ser criado.

A árvore de sintaxe abstrata é criada como o resultado final da fase de análise de sintaxe. O parser, que é frente e centro como o “caractere” principal durante a análise de sintaxe, pode ou não gerar sempre uma árvore de parser, ou CST. Dependendo do compilador em si, e como ele foi projetado, o analisador pode ir diretamente para a construção de uma árvore de sintaxe, ou AST. Mas o analisador irá sempre gerar um AST como sua saída, não importa se ele cria uma árvore de análise no meio, ou quantas passagens ele pode precisar fazer para fazê-lo.
Anatomia de um AST
Agora que sabemos que a árvore de sintaxe abstrata é importante (mas não necessariamente intimidante!), podemos começar a dissecá-la um pouquinho mais. Um aspecto interessante sobre como o AST é construído tem a ver com os nós desta árvore.
A imagem abaixo exemplifica a anatomia de um único nó dentro de uma árvore de sintaxe abstrata.
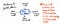
Notemos que este nó é semelhante a outros que já vimos antes, pois contém alguns dados (um token e o seu value). No entanto, ele também contém alguns indicadores muito específicos. Cada nó de um AST contém referências ao seu próximo nó irmão, bem como ao seu primeiro nó filho.
Por exemplo, nossa simples expressão de 5 + (1 x 12) poderia ser construída em uma ilustração visualizada de um AST, como a abaixo.

Podemos imaginar que a leitura, travessia, ou “interpretação” deste AST pode começar a partir dos níveis inferiores da árvore, trabalhando seu caminho de volta para construir um valor ou um retorno result até o final.
Também pode ajudar a ver uma versão codificada da saída de um parser para ajudar a complementar nossas visualizações. Podemos nos apoiar em várias ferramentas e usar analisadores pré-existentes para ver um exemplo rápido de como nossa expressão pode se parecer quando executada através de um analisador. Abaixo está um exemplo do nosso texto fonte, 5 + (1 * 12), executado através do Esprima, um parser ECMAScript, e sua árvore de sintaxe abstrata resultante, seguida por uma lista de seus símbolos distintos.
Neste formato, podemos ver o agrupamento da árvore se olharmos para os objetos aninhados. Vamos notar que os valores contendo 1 e 12 são os left e right filhos, respectivamente, de uma operação dos pais, *. Veremos também que a operação de multiplicação (*) compõe a sub-árvore certa de toda a expressão em si, razão pela qual ela está aninhada dentro do objeto maior BinaryExpression, sob a chave "right". Da mesma forma, o valor de 5 é o único "left" filho do maior BinaryExpression objeto.

O aspecto mais intrigante da árvore de sintaxe abstrata é, no entanto, o fato de que mesmo sendo tão compacta e limpa, nem sempre é uma estrutura de dados fácil de tentar e construir. Na verdade, construir um AST pode ser bastante complexo, dependendo da linguagem com que o analisador está lidando!
A maioria dos analisadores normalmente ou constrói uma árvore parse (CST) e depois a converte para um formato AST, porque isso às vezes pode ser mais fácil – mesmo que isso signifique mais passos, e geralmente falando, mais passa através do texto fonte. Construir um CST é realmente muito fácil uma vez que o analisador conhece a gramática da língua que está a tentar analisar. Ele não precisa fazer nenhum trabalho complicado de descobrir se um símbolo é “significativo” ou não; em vez disso, ele apenas pega exatamente o que ele vê, na ordem específica que ele vê, e cospe tudo em uma árvore.
Por outro lado, há alguns analisadores que tentarão fazer tudo isso como um processo de um único passo, pulando direto para construir uma árvore de sintaxe abstrata.
Construir um AST diretamente pode ser complicado, já que o analisador não só tem que encontrar as fichas e representá-las corretamente, mas também decidir quais fichas importam para nós, e quais não importam.
No projeto do compilador, o AST acaba sendo super importante por mais de uma razão. Sim, pode ser complicado de construir (e provavelmente fácil de estragar), mas também, é o último e final resultado das fases de análise léxica e de sintaxe combinadas! As fases léxica e de análise de sintaxe são frequentemente chamadas conjuntamente de fase de análise, ou o front-end do compilador.

Podemos pensar na árvore de sintaxe abstrata como o “projeto final” do front-end do compilador. É a parte mais importante, porque é a última coisa que o front-end tem que mostrar para si mesmo. O termo técnico para isso é chamado de representação de código intermediário ou IR, porque ele se torna a estrutura de dados que é finalmente usada pelo compilador para representar um texto fonte.
Uma árvore de sintaxe abstrata é a forma mais comum de IR, mas também, às vezes, a mais mal compreendida. Mas agora que a entendemos um pouco melhor, podemos começar a mudar a nossa percepção desta estrutura assustadora! Esperemos que agora seja um pouco menos intimidante para nós.
Recursos
Existem muitos recursos em ASTs, numa variedade de línguas. Saber por onde começar pode ser complicado, especialmente se você está procurando aprender mais. Abaixo estão alguns poucos recursos para iniciantes que mergulham em muito mais detalhes sem serem muito exagerados. Feliz asbtracting!
- O AST vs a árvore parse, Professor Charles N. Fischer
- Qual é a diferença entre árvores parse e árvores de sintaxe abstrata? StackOverflow
- Árvores de sintaxe abstrata vs. Árvores de sintaxe concreta, Eli Bendersky
- Árvores de sintaxe abstrata, Professor Stephen A. Edwards
- Árvores de sintaxe abstrata & Top-Down Parsing, Professor Konstantinos (Kostis) Sagonas
- Análise Léxica e Sintaxe de Linguagens de Programação, Chris Northwood
- AST Explorer, Felix Kling