A encriptação de dados em repouso é uma necessidade para qualquer empresa moderna de Internet. Muitas empresas, no entanto, não criptografam seus discos, porque temem a potencial penalidade de desempenho causada pela sobrecarga de criptografia.
Criptografar dados em repouso é vital para o Cloudflare com mais de 200 centros de dados em todo o mundo. Neste post, vamos investigar o desempenho da criptografia de disco no Linux e explicar como fizemos isso pelo menos duas vezes mais rápido para nós mesmos e nossos clientes!
Criptografar dados em repouso
Quando se trata de criptografar dados em repouso, há várias maneiras de implementá-los em um sistema operacional (SO) moderno. As técnicas disponíveis estão firmemente acopladas com uma típica pilha de armazenamento de SO. Uma versão simplificada da pilha de armazenamento e soluções de criptografia pode ser encontrada no diagrama abaixo:
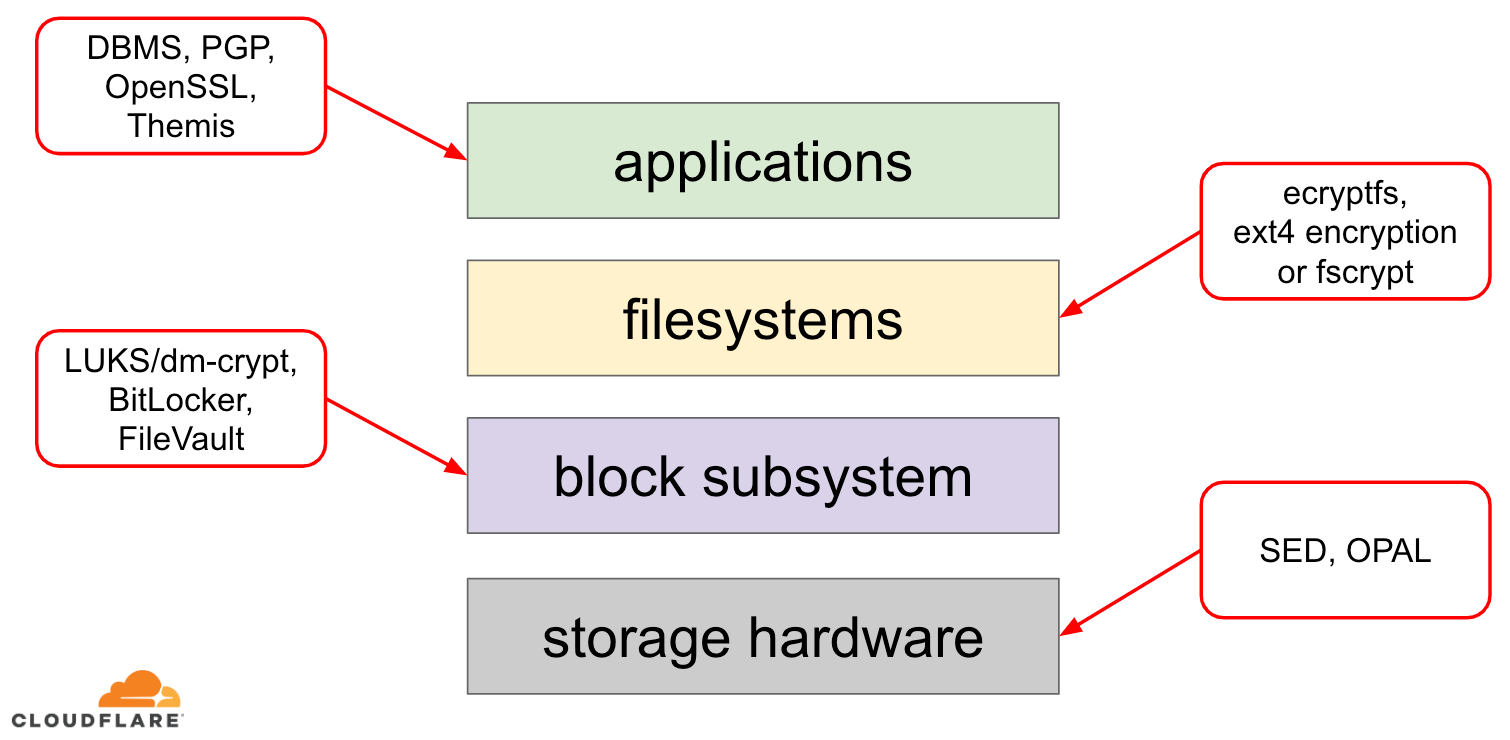
No topo da pilha estão aplicações, que lêem e escrevem dados em arquivos (ou fluxos). O sistema de arquivos no kernel do SO mantém um registro de quais blocos do dispositivo de bloco subjacente pertencem a quais arquivos e traduz esses arquivos lidos e gravados em blocos lidos e gravados, entretanto as especificações de hardware do dispositivo de armazenamento subjacente são abstraídas para longe do sistema de arquivos. Finalmente, o subsistema de blocos realmente passa o bloco lido e escrito para o hardware subjacente usando drivers de dispositivo apropriados.
O conceito da pilha de armazenamento é na verdade similar ao conhecido modelo OSI de rede, onde cada camada tem uma visão mais alta da informação e os detalhes de implementação das camadas inferiores são abstraídos para longe das camadas superiores. E, similar ao modelo OSI, pode-se aplicar criptografia em diferentes camadas (pense em TLS vs IPsec ou uma VPN).
Para dados em repouso, podemos aplicar criptografia tanto nas camadas de bloco (seja em hardware ou em software) ou no nível de arquivo (seja diretamente nas aplicações ou no sistema de arquivos).
Bloquear vs criptografia de arquivo
Generalmente, quanto mais alto na pilha aplicarmos a criptografia, maior flexibilidade teremos. Com a encriptação a nível de aplicação, os mantenedores da aplicação podem aplicar qualquer código de encriptação que quiserem a qualquer dado em particular que precisem. A desvantagem desta abordagem é que eles próprios têm de implementá-la e a encriptação em geral não é muito amigável para o desenvolvedor: é preciso conhecer as entradas e saídas de um algoritmo criptográfico específico, gerar apropriadamente chaves, nonces, IVs, etc. Além disso, a criptografia em nível de aplicação não alavanca o cache em nível de SO e cache de páginas Linux em particular: cada vez que a aplicação precisa usar os dados, ela tem que descriptografá-los novamente, desperdiçando ciclos de CPU, ou implementar seu próprio “cache” descriptografado, o que introduz mais complexidade ao código.
Cache em nível de sistema de arquivos torna a criptografia de dados transparente para as aplicações, porque o próprio sistema de arquivos criptografa os dados antes de passá-los para o subsistema de blocos, de modo que os arquivos são criptografados independentemente se a aplicação tem ou não suporte a criptografia. Além disso, os sistemas de arquivos podem ser configurados para criptografar apenas um determinado diretório ou ter chaves diferentes para arquivos diferentes. Esta flexibilidade, no entanto, vem com um custo de uma configuração mais complexa. A criptografia de sistemas de arquivos também é considerada menos segura do que a criptografia de dispositivos de bloqueio, pois apenas o conteúdo dos arquivos é criptografado. Os arquivos também têm metadados associados, como o tamanho do arquivo, o número de arquivos, o layout da árvore de diretórios, etc., que ainda são visíveis para um potencial adversário.
Criptografia na camada de bloco (muitas vezes referida como criptografia de disco ou criptografia de disco completo) também torna a criptografia de dados transparente para aplicativos e até mesmo para sistemas de arquivos inteiros. Ao contrário da encriptação a nível de sistema de ficheiros, encripta todos os dados no disco, incluindo metadados de ficheiros e até mesmo espaço livre. No entanto, é menos flexível – só se pode criptografar todo o disco com uma única chave, portanto não há configuração por diretórios, por arquivo ou por usuário. Da perspectiva da criptografia, nem todos os algoritmos criptográficos podem ser usados, pois a camada de bloco não tem mais uma visão geral de alto nível dos dados, portanto precisa processar cada bloco de forma independente. A maioria dos algoritmos comuns requer algum tipo de encadeamento de blocos para ser seguro, portanto não são aplicáveis à criptografia de disco. Em vez disso, modos especiais foram desenvolvidos apenas para este caso de uso específico.
Então qual camada escolher? Como sempre, depende… A encriptação ao nível da aplicação e do sistema de ficheiros é normalmente a escolha preferida para os sistemas clientes devido à flexibilidade. Por exemplo, cada usuário em um desktop multiusuário pode querer criptografar seu diretório home com uma chave que possui e deixar alguns diretórios compartilhados não criptografados. Pelo contrário, em sistemas de servidor, geridos por empresas SaaS/PaaS/IaaaS (incluindo Cloudflare) a escolha preferida é a simplicidade de configuração e segurança – com a encriptação total do disco activada, quaisquer dados de qualquer aplicação são automaticamente encriptados, sem excepções ou sobreposições. Acreditamos que todos os dados precisam ser protegidos sem ordená-los em baldes “importantes” vs “não importantes”, portanto a flexibilidade seletiva que as camadas superiores fornecem não é necessária.
Criptografia de disco de hardware vs software
Quando criptografamos dados na camada de bloco é possível fazê-lo diretamente no hardware de armazenamento, se o hardware o suportar. Fazendo isso geralmente dá melhor desempenho de leitura/gravação e consome menos recursos do host. No entanto, como a maioria do firmware do hardware é proprietário, ele não recebe tanta atenção e revisão por parte da comunidade de segurança. No passado isso levou a falhas em algumas implementações de criptografia de disco de hardware, o que torna todo o modelo de segurança inútil. A Microsoft, por exemplo, começou a preferir a encriptação de disco baseada em software desde então.
Não queríamos colocar os nossos dados e os dados dos nossos clientes ao risco de usar soluções potencialmente inseguras e acreditamos fortemente no código aberto. É por isso que confiamos apenas na criptografia de disco de software no kernel Linux, que é aberto e tem sido auditado por muitos profissionais de segurança em todo o mundo.
Desempenho da criptografia de disco Linux
A nossa meta não é apenas economizar custos de largura de banda para nossos clientes, mas fornecer conteúdo aos usuários da Internet o mais rápido possível.
A certa altura percebemos que nossos discos não eram tão rápidos quanto gostaríamos que fossem. Alguns perfis, assim como um rápido teste A/B, apontaram para a criptografia do disco Linux. Porque não encriptar os dados (mesmo que seja suposto ser um cache público da Internet) não é uma opção sustentável, decidimos dar uma olhada mais de perto no desempenho da encriptação de discos Linux.
Device mapper e dm-crypt
Linux implementa a encriptação de discos transparentes através de um módulo dm-crypt e dm-crypt faz parte da estrutura do kernel do device mapper. Em poucas palavras, o device mapper permite pedidos de IO pré/pós-processo enquanto eles viajam entre o sistema de arquivos e o dispositivo de bloco subjacente.
dm-crypt em particular encripta pedidos de IO “write” antes de enviá-los mais abaixo na pilha para o dispositivo de bloco real e decripta pedidos de IO “read” antes de enviá-los para o driver do sistema de arquivos. Simples e fácil! Ou será?
Configuração de benchmarking
Para o registro, os números neste post foram obtidos executando comandos especificados em um servidor G9 de Cloudflare ocioso fora de produção. No entanto, a configuração deve ser facilmente reproduzível em qualquer laptop x86 moderno.
Geralmente, o benchmarking de qualquer coisa em torno de uma pilha de armazenamento é difícil por causa do ruído introduzido pelo próprio hardware de armazenamento. Nem todos os discos são criados iguais, então para o propósito deste post vamos usar os discos mais rápidos disponíveis lá fora – isto é, sem discos.
Intead Linux tem uma opção para emular um disco diretamente na RAM. Como a RAM é muito mais rápida do que qualquer armazenamento persistente, ela deve introduzir pouco viés em nossos resultados.
O seguinte comando cria um ramdisk de 4GB:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Agora podemos configurar uma instância dm-crypt em cima dela habilitando assim a criptografia para o disco. Primeiro, precisamos gerar a chave de encriptação do disco, “formatar” o disco e especificar uma senha para desbloquear a chave recém gerada.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:Aqueles que estão familiarizados com LUKS/dm-crypt podem ter notado que usamos um cabeçalho destacado do LUKS aqui. Normalmente, o LUKS armazena a chave de encriptação do disco encriptado com senha no mesmo disco que os dados, mas como queremos comparar o desempenho de leitura/escrita entre dispositivos encriptados e não encriptados, podemos acidentalmente sobrescrever a chave encriptada durante o nosso benchmarking mais tarde. Manter a chave criptografada em um arquivo separado evita este problema para os propósitos deste post.
Agora, nós podemos realmente “desbloquear” o dispositivo criptografado para nosso teste:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0Neste ponto nós podemos agora comparar o desempenho do ramdisk criptografado vs. não criptografado: se nós lemos/escrevemos dados para /dev/ram0, eles serão armazenados em texto plano. Da mesma forma, se lermos/escrevermos os dados para /dev/mapper/encrypted-ram0, eles serão desencriptados/encriptados no caminho por dm-crypt e armazenados em ciphertext.
Vale a pena notar que não estamos a criar nenhum sistema de ficheiros em cima dos nossos dispositivos de bloco para evitar resultados enviesados com uma sobrecarga do sistema de ficheiros.
Medida de rendimento
Quando se trata de testes de armazenamento/benchmarking O testador de E/S flexível é a solução go-to usual. Vamos simular carga sequencial simples de leitura/gravação com 4K de tamanho de bloco no ramdisk sem criptografia:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%O comando acima será executado por um longo tempo, então nós apenas o paramos depois de um tempo. Como podemos ver pelas estatísticas, somos capazes de ler e escrever aproximadamente com a mesma taxa de transferência em torno de 1126 MB/s. Vamos repetir o teste com o ramdisk encriptado:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecWhoa, isso é uma gota! Nós só temos ~147 MB/s agora, o que é mais de 7 vezes mais lento! E isto é numa máquina totalmente ociosa!
Talvez, a criptografia é apenas lenta
A primeira coisa que consideramos é garantir que usamos a criptografia mais rápida. cryptsetup permite-nos comparar todas as implementações de criptografia disponíveis no sistema para seleccionar a melhor:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/A Parece que aes-xts com uma chave de encriptação de dados de 256-bit é a mais rápida aqui. Mas qual deles estamos realmente usando para o nosso ramdisk criptografado?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 Usamos aes-xts com uma chave de criptografia de dados de 256 bits (conte todos os zeros convenientemente mascarados pela ferramenta dmsetup – se você quiser ver os bytes reais, adicione a opção --showkeys ao comando acima). Os números, no entanto, não somam: cryptsetup benchmark diz-nos acima para não confiarmos nos resultados, pois “Os testes são aproximados usando apenas memória (sem IO de armazenamento)”, mas é exactamente assim que preparamos a nossa experiência usando o ramdisk. Num caso um pouco pior (assumindo que estamos lendo todos os dados e depois encriptando-os/descriptografando-os sequencialmente sem paralelismo), fazendo o cálculo do back of theenvelope, deveríamos estar a chegar a (1126 * 1823) / (1126 + 1823) =~696 MB/s, o que ainda está bastante longe do real 147 * 2 = 294 MB/s (total para leituras e escritas).
dm-crypt performance flags
Apesar de ler a página do homem criptométrico notamos que ela tem duas opções prefixadas com --perf-, que provavelmente estão relacionadas com a afinação da performance. A primeira é --perf-same_cpu_crypt com uma descrição bastante críptica:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Então ativamos a opção
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Note: de acordo com a última página de manual há também um comando cryptsetup refresh, que pode ser usado para ativar essas opções ao vivo sem ter que “fechar” e “reabrir” o dispositivo criptografado. Nosso cryptsetup contudo ainda não o suportava.
Verificando se a opção foi realmente ativada:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptSim, agora podemos ver same_cpu_crypt na saída, que é o que queríamos. Vamos reexecutar o benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, agora é ~136 MB/s o que é ligeiramente pior do que antes, por isso não é bom. E a segunda opção --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Talvez, estamos na “alguma situação” aqui, por isso vamos experimentar:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusE agora o benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, que é um pouco melhor, mas ainda não é bom…
Passando a comunidade
Desesperados decidimos buscar apoio da Internet e postamos nossos resultados na lista de discussão dm-crypt, mas a resposta que obtivemos não foi muito encorajadora:
Se os números o incomodam, então isto é por falta de compreensão do seu lado. Você provavelmente não sabe que a criptografia é uma operação pesada…
Decidimos fazer uma pesquisa científica sobre este tópico digitando “é criptografia cara” no Google Search e um dos principais resultados, que realmente contém medidas significativas, é… nosso próprio post sobre o custo da criptografia, mas no contexto do TLS! Esta é uma leitura fascinante por si só, mas a essência é: a criptografia moderna em hardware moderno é muito barata mesmo na escala Cloudflare (fazendo milhões de pedidos HTTP criptografados por segundo). Na verdade, é tão barato que o Cloudflare foi o primeiro provedor a oferecer SSL/TLS grátis para todos.
Digging into the source code
Quando tentamos usar as opções personalizadas dm-crypt descritas acima, ficamos curiosos porque elas existem em primeiro lugar e do que se trata esse “offloading”. Originalmente esperávamos que dm-crypt fosse um simples “proxy”, que apenas encripta/descripta os dados à medida que eles fluem através da pilha. Acontece que dm-crypt faz mais do que encriptar buffers de memória e um diagrama de caminho de IO (simplificado) é apresentado abaixo:

Quando o sistema de ficheiros emite um pedido de escrita, dm-crypt não o processa imediatamente – em vez disso coloca-o numa fila de trabalho chamada “kcryptd”. Em poucas palavras, uma fila de trabalho do kernel apenas agenda algum trabalho (criptografia neste caso) para ser executado em algum momento posterior, quando for mais conveniente. Quando “a hora” chegar, dm-crypt envia o pedido para o Linux Crypto API para encriptação real. Entretanto, a moderna Linux Crypto API também é assíncrona, então dependendo de qual implementação em particular seu sistema irá usar, muito provavelmente não será processada imediatamente, mas enfileirada novamente para “tempo posterior”. Quando o Linux Crypto API finalmente fizer a encriptação, dm-crypt poderá tentar ordenar os pedidos de escrita pendentes, colocando cada pedido numa árvore negra-vermelha. Então uma thread do kernel separada novamente em “algum tempo depois” realmente pega todas as requisições IO na árvore e as envia para a pilha.
Agora para requisições de leitura: desta vez precisamos obter os dados criptografados primeiro do hardware, mas dm-crypt não pede apenas o driver para os dados, mas enfileira a requisição em uma fila de trabalho diferente chamada “kcryptd_io”. Em algum momento mais tarde, quando realmente tivermos os dados criptografados, nós os programamos para descriptografia usando a agora familiar fila de trabalho “kcryptd”. O “kcryptd” enviará a requisição para a API Crypto do Linux, que pode decifrar os dados assincronamente também.
Para ser justo, a requisição nem sempre atravessa todas essas filas, mas a parte importante aqui é que as requisições de escrita podem ser enfileiradas até 4 vezes em dm-crypt e ler requisições até 3 vezes. Nesta altura, estávamos a pensar se toda esta fila extra pode causar algum problema de desempenho. Por exemplo, há uma boa apresentação do Google sobre a relação entre fila e a latência da cauda. Uma das chaves da apresentação é:
Uma quantidade significativa de latência de cauda é devida a efeitos de enfileiramento
Então, porque é que todas estas filas estão lá e podemos removê-las?
Arqueologia de cauda
Ninguém escreve código mais complexo apenas por diversão, especialmente para o kernel do SO. Então todas estas filas devem ter sido colocadas lá por uma razão. Felizmente, o fonte do kernel Linux é gerenciado pelo git, então podemos tentar rastrear as mudanças e as decisões em torno delas.
A fila de trabalho “kcryptd” estava no fonte desde o início da história disponível com o seguinte comentário:
Needed porque seria muito insensato fazer decriptografia em um contexto de interrupção, então bios retornando de pedidos lidos são enfileirados aqui.
Então era apenas para leitura, mas mesmo assim – por que nos importamos se é contexto de interrupção ou não, se a API Crypto do Linux provavelmente usará um thread/queue dedicado para criptografia de qualquer forma? Bem, em 2005 a API Crypto não era assíncrona, então isso fazia todo o sentido.
Em 2006 dm-crypt começou a usar a fila de trabalho “kcryptd” não apenas para criptografia, mas para submeter pedidos IO:
Este patch foi projetado para ajudar o dm-crypt a cumprir com as novas restrições impostas pelo seguinte patch em -mm: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Parece que o objectivo aqui não era adicionar mais simultaneidade, mas sim reduzir o uso da pilha do kernel, o que faz sentido novamente uma vez que o kernel tem uma pilha comum em todo o código, por isso é um recurso bastante limitado. Vale notar, no entanto, que a pilha do kernel Linux foi expandida em 2014 para plataformas x86, portanto isto pode não ser mais um problema.
Uma primeira versão do “kcryptd_io” workqueue foi adicionada em 2007 com a intenção de evitar:
starvation caused by many requests waiting for memory allocation…
O processamento de requisições estava estrangulando em uma única fila de trabalho aqui, então a solução foi adicionar outra. Faz sentido.
Definitivamente não somos os primeiros a sofrer degradação de desempenho por causa de uma fila extensa: em 2011 foi introduzida uma alteração para reverter condicionalmente parte da fila para pedidos de leitura:
Se houver memória suficiente, o código pode submeter diretamente a bio em vez de enfileirar esta operação em uma thread separada.
Felizmente, naquela época as mensagens de commit do kernel Linux não eram tão verbosas como hoje, então não há dados de performance disponíveis.
Em 2015 o dm-crypt começou a ordenar as escritas em uma thread separada “dmcrypt_write” antes de enviá-las pela pilha:
Em uma máquina com multiprocessadores, os pedidos de encriptação terminam em uma ordem diferente da que foram enviados. Consequentemente, os pedidos de escrita seriam submetidos em uma ordem diferente e isso poderia causar grave degradação de desempenho.
Faz sentido, pois o acesso sequencial ao disco costumava ser muito mais rápido do que o aleatório e dm-crypt estava quebrando o padrão. Mas isto aplica-se principalmente aos discos giratórios, que ainda eram dominantes em 2015. Pode não ser tão importante com SSDs rápidos modernos (incluindo SSDs NVME).
Outra parte da mensagem de commit é digna de menção:
…em particular permite que agendadores de IO como o CFQ classifiquem mais efetivamente…
Menciona os benefícios de desempenho para o agendador de IO CFQ, mas os agendadores Linux melhoraram desde então ao ponto de que o agendador CFQ foi removido do kernel em 2018.
O mesmo patchset substitui a lista de ordenação por uma árvore negra-vermelha:
Em teoria a ordenação deve ser feita pelo agendador de discos subjacente, no entanto, na prática o agendador de discos só aceita e ordena um número finito de pedidos. Para permitir a ordenação de todas as requisições, o dm-crypt precisa implementar sua própria ordenação.
O overhead associado com a ordenação baseada em rbtree- é considerado insignificante, portanto não é usado condicionalmente.
Tudo isso faz sentido, mas seria bom ter alguns dados de suporte.
Interessantemente, no mesmo patchset vemos a introdução da nossa familiar opção “submit_from_crypt_cpus”:
Existem algumas situações em que a descarga de bios de escrita das threads de encriptação para uma única thread degrada significativamente o desempenho
Overall, podemos ver que cada mudança foi razoável e necessária, no entanto as coisas mudaram desde então:
- hardware tornou-se mais rápido e inteligente
- Alocação de recursos do Linux foi revisitada
- Os subsistemas Linux acoplados foram rearquitetados
E muitas das escolhas de design acima podem não ser aplicáveis ao Linux moderno.
A “limpeza”
Baseado na pesquisa acima, decidimos tentar remover todo o comportamento extra de fila e assíncrono e reverter dm-crypt ao seu propósito original: simplesmente encriptar/descriptar pedidos IO à medida que passam. Mas por uma questão de estabilidade e mais benchmarking acabámos por não remover o código actual, mas sim adicionar mais uma opção dm-crypt, que ultrapassa todas as filas/threads, se activada. A bandeira nos permite alternar entre o comportamento atual e novo em tempo de execução sob carga total de produção, para que possamos reverter facilmente nossas mudanças caso vejamos algum efeito colateral. O patch resultante pode ser encontrado no repositório GitHub Linux Cloudflare.
Synchronous Linux Crypto API
Do diagrama acima lembramos que nem todas as filas estão implementadas em dm-crypt. A moderna Linux Crypto API também pode ser assíncrona e para o bem deste experimento queremos eliminar filas lá também. O que significa “pode ser”, no entanto? O sistema operacional pode conter diferentes implementações do mesmo algoritmo (por exemplo, AES-NI acelerado por hardware em plataformas x86 e implementações genéricas de AES com código C). Por padrão, o sistema escolhe o “melhor” com base na prioridade do algoritmo configurado. dm-crypt permite anular este comportamento e solicitar uma determinada implementação de cifra usando o prefixo capi:. No entanto, há um problema. Vamos realmente verificar as implementações AES-XTS disponíveis (esta é nossa cifra de criptografia de disco, lembra-se?) em nosso sistema:
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64 Queremos selecionar explicitamente uma cifra síncrona da lista acima para evitar efeitos de enfileiramento em threads, mas as únicas duas suportadas são xts(ecb(aes-generic)) (a implementação C genérica) e __xts-aes-aesni (a implementação x86 acelerada por hardware). Definitivamente queremos este último, pois é muito mais rápido (estamos visando performance aqui), mas é suspeitamente marcado como interno (veja internal: yes). Se verificarmos o código fonte:
Marcar uma cifra como uma implementação de serviço somente utilizável por outra cifra e nunca por um usuário normal do kernel crypto API
Então esta cifra é para ser usada somente por outro código wrapper na Crypto API e não fora dela. Na prática isto significa, que o chamador da Crypto API precisa especificar explicitamente esta flag, quando requisitando uma implementação de cifra em particular, mas dm-crypt não o faz, porque pelo design não faz parte da API Crypto do Linux, mas sim um usuário “externo”. Nós já corrigimos o módulo dm-crypt, então poderíamos apenas adicionar o flag relevante. Entretanto, há outro problema com AES-NI em particular: FPU x86. “Ponto flutuante”, você diz? Por que precisamos de matemática de ponto flutuante para fazer criptografia simétrica que deve ser apenas sobre mudanças de bit e operações XOR? Não precisamos da matemática, mas as instruções AES-NI utilizam alguns dos registos da CPU, que são dedicados à FPU. Infelizmente o kernel Linux nem sempre preserva esses registros em contexto de interrupção por razões de desempenho (salvar/restaurar a FPU é caro). Mas dm-crypt pode executar código em contexto de interrupção, então corremos o risco de corromper alguns outros dados do processo e voltamos à declaração “seria muito insensato fazer decifração em contexto de interrupção” no código original.
Nossa solução para lidar com o acima foi criar outro módulo API Crypto um pouco “inteligente”. Este módulo é síncrono e não rola seu próprio crypto, mas é apenas um “roteador” de pedidos de criptografia:
- se pudermos usar a FPU (e portanto AES-NI) no contexto de execução atual, nós apenas encaminhamos a requisição de criptografia para a implementação mais rápida, “interna”
__xts-aes-aesni(e podemos usá-la aqui, porque agora nós somos parte do Crypto API) - outros, nós apenas encaminhamos o pedido de criptografia para o mais lento, genérico baseado em C
xts(ecb(aes-generic))implementação
Usando o lote inteiro
Passemos pelo processo de usar tudo junto. O primeiro passo é pegar os patches e recompilar o kernel (ou apenas compilar dm-crypt e os nossos xtsproxy módulos).
Next, vamos reiniciar nossa carga de trabalho IO em um terminal separado, assim podemos ter certeza de que podemos reconfigurar o kernel em tempo de execução sob carga:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...No terminal principal, certifique-se de que nosso novo módulo API Crypto está carregado e disponível:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Reconfigure o disco criptografado para usar nosso módulo recém-carregado e habilite nosso flag corrigido dm-crypt (temos que usar a ferramenta de baixo nível dmsetup pois cryptsetup obviamente não está ciente de nossas modificações):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Acabamos de “carregar” a nova configuração, mas para que ela tenha efeito, precisamos suspender/resumir o dispositivo criptografado:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0E agora observe o resultado. Podemos voltar para o outro terminal rodando o trabalho fio e olhar a saída, mas para tornar as coisas mais agradáveis, aqui está um instantâneo do throughput observado de leitura/escrita no Grafana:
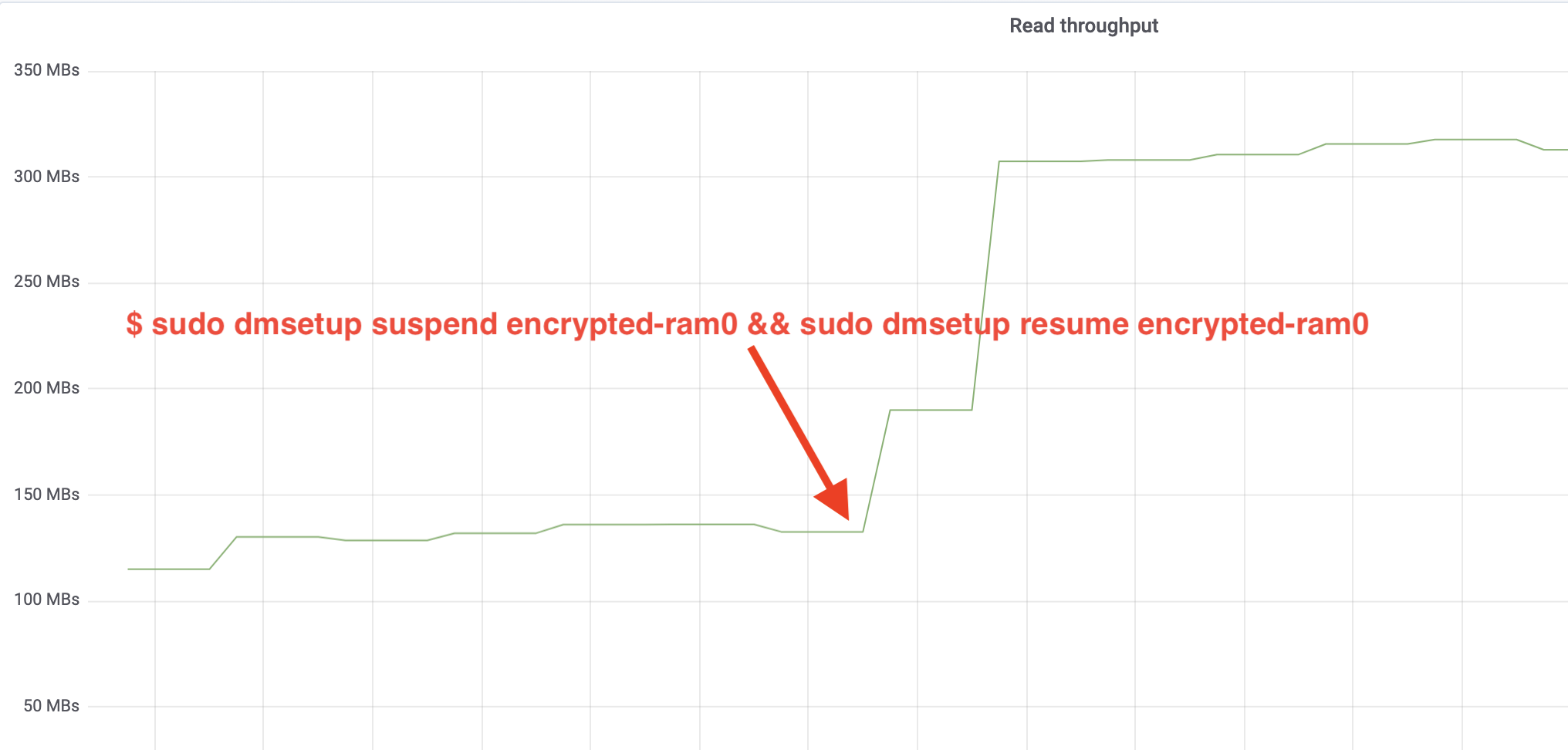
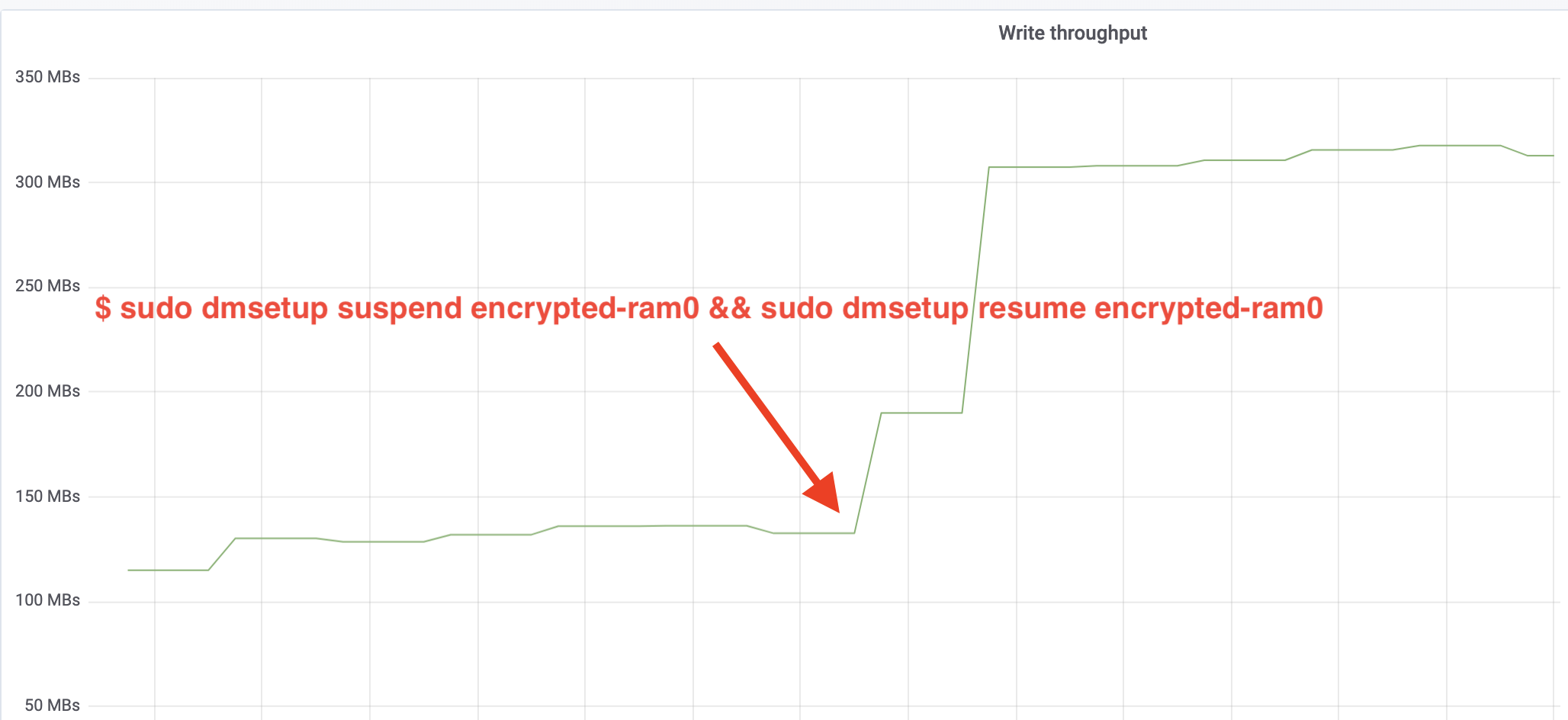
Wow, nós temos mais do que o dobro do throughput! Com a produção total de ~640 MB/s estamos agora muito mais próximos do esperado ~696 MB/s de cima. E quanto à latência IO? (A await estatística da ferramenta de relatório iostat):
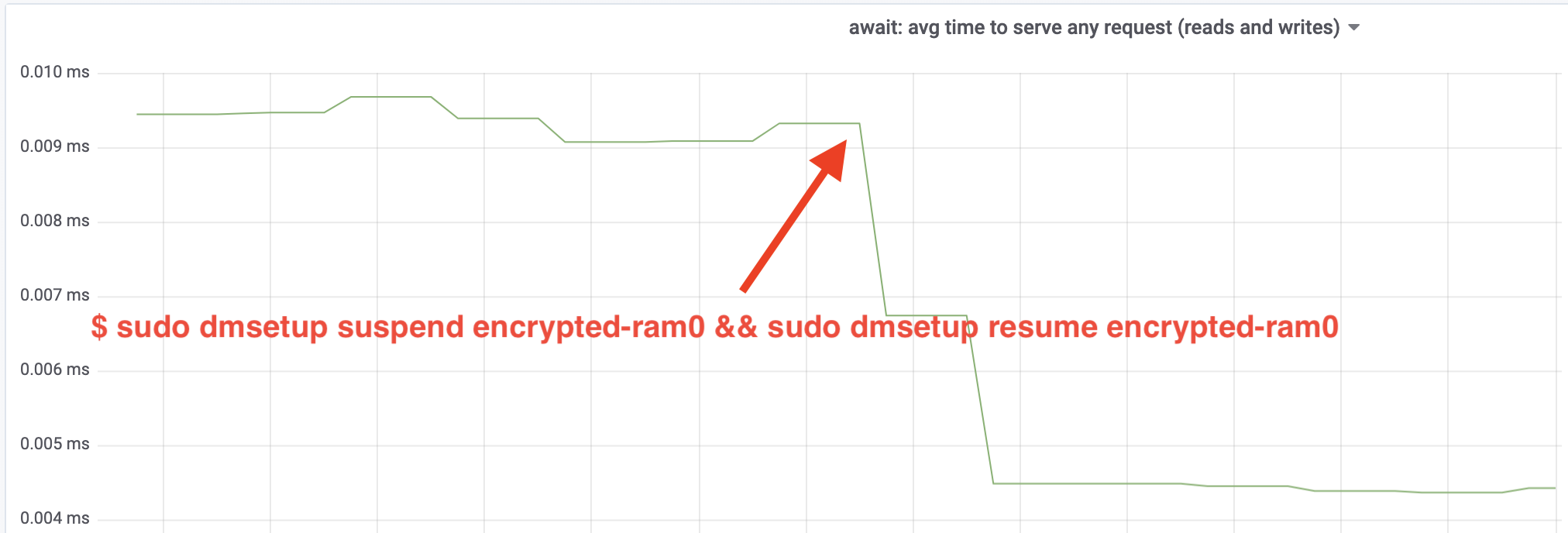
A latência também foi cortada pela metade!
Para produção
Até agora temos usado uma configuração sintética com algumas partes da pilha de produção completa faltando, como sistemas de arquivos, hardware real e, o mais importante, carga de trabalho de produção. Para garantir que não estamos otimizando coisas imaginárias, aqui está um instantâneo do impacto que essas mudanças trazem à parte de cache da nossa pilha:

Este gráfico representa uma comparação de três vias dos piores tempos de resposta (percentil 99) para um hit de cache em um de nossos servidores. A linha verde é de um servidor com discos não criptografados, que nós usaremos como linha de base. A linha vermelha é de um servidor com discos criptografados com a implementação padrão de criptografia de disco Linux e a linha azul é de um servidor com discos criptografados e nossas otimizações ativadas. Como podemos ver, a implementação padrão de criptografia de disco Linux tem um impacto significativo na nossa latência de cache nos piores cenários, enquanto a implementação corrigida é indistinguível de não utilizar criptografia de forma alguma. Por outras palavras, a implementação de encriptação melhorada não tem qualquer impacto na velocidade de resposta do nosso cache, por isso, basicamente, obtemos de graça! Isso é uma vitória!
Estamos apenas começando
Este post mostra como uma revisão de arquitetura pode dobrar a performance de um sistema. Também reconfirmamos que a criptografia moderna não é cara e normalmente não há desculpa para não proteger seus dados.
Vamos submeter este trabalho para inclusão na árvore principal do kernel, mas muito provavelmente não na sua forma atual. Embora os resultados pareçam encorajadores, temos que lembrar que o Linux é um sistema operacional altamente portável: ele roda em servidores poderosos, bem como em pequenos dispositivos IoT restritos a recursos e em muitas outras arquiteturas de CPU também. A versão atual dos patches apenas otimiza a criptografia de disco para uma determinada carga de trabalho em uma determinada arquitetura, mas o Linux precisa de uma solução que roda sem problemas em todos os lugares.
Dito isso, se você acha que seu caso é similar e quer aproveitar as melhorias de desempenho agora, você pode pegar os patches e, com sorte, fornecer feedback. A bandeira de tempo de execução facilita a troca da funcionalidade em tempo real e um simples teste A/B pode ser realizado para ver se beneficia algum caso ou configuração em particular. Estes patches têm sido executados na nossa ampla rede de mais de 200 centros de dados em cinco gerações de hardware, por isso podem ser razoavelmente considerados estáveis. Aproveite o desempenho e a segurança do Cloudflare para todos!

Update (October 11, 2020)
O patch principal deste blog (numa forma ligeiramente actualizada) foi fundido no kernel principal do Linux e está disponível desde a versão 5.9 e seguintes. A principal diferença é que a versão da linha principal expõe duas bandeiras em vez de uma, que fornecem a capacidade de contornar as filas de trabalho dm-crypt para leitura e escrita de forma independente. Para detalhes, veja a documentação oficial do dm-crypt.