Wprowadzenie
Jeśli analizujesz swoje dane przy użyciu regresji wielokrotnej i którakolwiek ze zmiennych niezależnych została zmierzona na skali nominalnej lub porządkowej, musisz wiedzieć, jak tworzyć zmienne dummy i interpretować ich wyniki. Dzieje się tak dlatego, że nominalne i porządkowe zmienne niezależne, szerzej znane jako kategoryczne zmienne niezależne, nie mogą być bezpośrednio wprowadzone do analizy regresji wielorakiej. Zamiast tego muszą one zostać przekształcone w zmienne dummy. Wyjątkiem są rzędowe zmienne niezależne, które są wprowadzane do regresji wielorakiej jako ciągłe zmienne niezależne, które nie muszą być przekształcane w zmienne dummy. Dlatego w tym przewodniku pokażemy, jak tworzyć zmienne dummy, gdy mamy kategoryczne zmienne niezależne.
Najpierw przedstawimy przykład, którego używamy, aby pokazać, jak tworzyć zmienne dummy w SPSS Statistics, a następnie wyjaśnimy, jak skonfigurować dane w oknach Widok zmiennej i Widok danych SPSS Statistics, aby można było tworzyć zmienne dummy. Jeśli nie jesteś zaznajomiony z użyciem zmiennych dummy, zalecamy, abyś przeczytał o niektórych podstawowych zasadach zmiennych dummy i kodowania dummy, w tym: (a) liczbą zmiennych dummy, które musisz utworzyć w swojej analizie; oraz (b) sposobem tworzenia zmiennych dummy i kodowania dummy. W sekcji Procedura, która następuje, przedstawiamy prostą, 3-etapową procedurę Utwórz zmienne dummy w SPSS Statistics, która może być użyta do utworzenia zmiennych dummy. Na koniec wyjaśniamy, jak wygląda wyjście SPSS Statistics po uruchomieniu procedury Utwórz zmienne dummy, w tym jak Twoje zmienne dummy będą teraz ustawione w oknach Widok zmiennych i Widok danych w SPSS Statistics.
Uwaga: Jeśli stwierdzisz, że procedury w tym przewodniku nie obejmują typu zmiennych dummy, które chcesz utworzyć, skontaktuj się z nami. Być może będziemy w stanie dodać do witryny inny przewodnik, aby pomóc.
SPSS Statistics
Przykład wykorzystany w tym przewodniku
W tym przewodniku posłużymy się przykładem 10 triathlonistów, którzy zostali poproszeni o wybranie ulubionego sportu spośród trzech dyscyplin, które uprawiają podczas uprawiania triathlonu: pływanie, jazda na rowerze i bieganie. Ich odpowiedzi zostały zapisane w nominalnej zmiennej niezależnej, favourite_sport, która ma trzy kategorie: „pływanie”, „jazda na rowerze” i „bieganie”. Ta nominalna zmienna niezależna, ulubiony_sport, miała być włączona do analizy regresji wielokrotnej, która miała również szereg ciągłych zmiennych niezależnych. Ponieważ ta zmienna niezależna była kategoryczna (tj. zmienne nominalne i zmienne porządkowe mogą być szeroko klasyfikowane jako zmienne kategoryczne), zmienne dummy musiały być utworzone przed wprowadzeniem do analizy regresji wielokrotnej.
Ważne: Zauważ, że favourite_sport jest zmienną nominalną, ale można również tworzyć zmienne dummy dla zmiennej porządkowej. Co więcej, proces tworzenia zmiennych dummy jest taki sam niezależnie od tego, czy masz zmienną porządkową czy nominalną, z wyjątkiem jednej małej zmiany, którą musisz wprowadzić podczas konfigurowania danych, co jest wyjaśnione poniżej.
Uwaga 1: „Kategorie” kategorycznej zmiennej niezależnej są również określane jako „grupy” lub „poziomy”, ale termin „poziomy” jest zwykle zarezerwowany dla kategorii, które mają porządek (np. porządkowa zmienna niezależna, „poziom sprawności fizycznej”, może mieć trzy poziomy: „niski”, „umiarkowany” i „wysoki”). Jednakże te trzy terminy – „kategorie”, „grupy” i „poziomy” – mogą być używane zamiennie. W tym przewodniku będziemy odnosić się do nich jako do kategorii, ale możesz odnosić się do nich jako do grup lub poziomów, jeśli wolisz.
Uwaga 2: Termin „czynniki” jest czasami używany zamiast „kategorycznych zmiennych niezależnych” (tj. zmiennych niezależnych, które są „porządkowe” lub „nominalne”). Jednak te dwa terminy – „kategoryczne zmienne niezależne” i „czynniki” – mogą być używane zamiennie. W tym przewodniku będziemy się do nich odnosić jako do kategorycznych zmiennych niezależnych, a SPSS Statistics w swojej procedurze regresji wielorakiej będzie się do nich odnosił raczej jako do zmiennych niezależnych niż czynników. Jednakże, możesz odnosić się do nich jako do czynników, jeśli wolisz.
SPSS Statistics
Ustawianie danych w SPSS Statistics
Przy tworzeniu zmiennych dummy, zaczniesz od pojedynczej kategorycznej zmiennej niezależnej (np., ulubiony_sport). Aby skonfigurować tę kategoryczną zmienną niezależną, SPSS Statistics posiada Widok zmiennej, w którym definiuje się typy analizowanych zmiennych oraz Widok danych, w którym wprowadza się dane dla tej zmiennej. W tej sekcji najpierw pokażemy, jak skonfigurować kategoryczną zmienną niezależną w oknie Widok zmiennej SPSS Statistics, a następnie pokażemy, jak wprowadzić dane do okna Widok danych. Zrobimy to przy użyciu naszej kategorycznej zmiennej niezależnej, ulubiony_sport, która ma trzy kategorie: „pływanie”, „jazda na rowerze” i „bieganie”.
The Variable View in SPSS Statistics
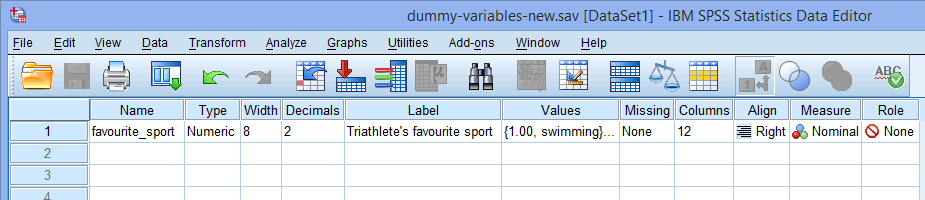
Dla pojedynczej kategorycznej zmiennej niezależnej (np., favourite_sport), Twoje okno Variable View będzie wyglądało jak poniżej:
Uwaga: Możesz uzyskać dostęp do okna Variable Viewwindow w SPSS Statistics klikając na zakładkę ![]() w lewym dolnym rogu programu SPSS Statistics.
w lewym dolnym rogu programu SPSS Statistics.
Published with written permission from SPSS Statistics, IBM Corporation.
Nazwa Twojej kategorycznej zmiennej niezależnej powinna być wpisana w komórce pod kolumną ![]() (np, „ulubiony_sport” w wierszu
(np, „ulubiony_sport” w wierszu ![]() , aby reprezentować naszą kategoryczną zmienną niezależną, ulubiony_sport. Istnieją pewne „nielegalne” znaki, które nie mogą być wprowadzone do komórki
, aby reprezentować naszą kategoryczną zmienną niezależną, ulubiony_sport. Istnieją pewne „nielegalne” znaki, które nie mogą być wprowadzone do komórki ![]() . Dlatego, jeśli otrzymasz komunikat o błędzie i chciałbyś, abyśmy dodali przewodnik SPSS Statistics wyjaśniający, czym są te nielegalne znaki, skontaktuj się z nami.
. Dlatego, jeśli otrzymasz komunikat o błędzie i chciałbyś, abyśmy dodali przewodnik SPSS Statistics wyjaśniający, czym są te nielegalne znaki, skontaktuj się z nami.
Uwaga: Dla własnej przejrzystości możesz również podać etykietę dla swoich zmiennych w kolumnie ![]() . Na przykład etykieta, którą wpisaliśmy dla zmiennej „ulubiony_sport” to „Ulubiony sport triathlonisty”.
. Na przykład etykieta, którą wpisaliśmy dla zmiennej „ulubiony_sport” to „Ulubiony sport triathlonisty”.
Komórka pod kolumną ![]() powinna zawierać informacje o kategoriach Twojej kategorycznej zmiennej niezależnej (np. „pływanie”, „jazda na rowerze” i „bieganie” dla ulubionego_sportu. Aby wprowadzić te informacje, kliknij w komórkę pod kolumną
powinna zawierać informacje o kategoriach Twojej kategorycznej zmiennej niezależnej (np. „pływanie”, „jazda na rowerze” i „bieganie” dla ulubionego_sportu. Aby wprowadzić te informacje, kliknij w komórkę pod kolumną ![]() dla twojej zmiennej niezależnej. W komórce pojawi się przycisk
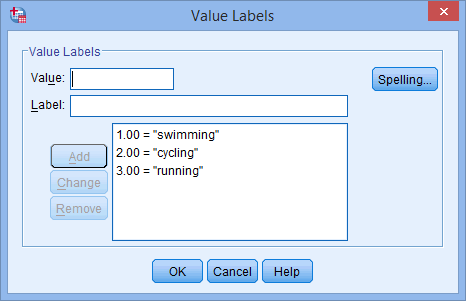
dla twojej zmiennej niezależnej. W komórce pojawi się przycisk ![]() . Kliknij ten przycisk, a pojawi się okno dialogowe Etykiety wartości. Teraz musisz nadać każdej kategorii swojej zmiennej niezależnej „wartość”, którą wpisujesz w polu Wartość: (np. „1”), oraz „etykietę”, którą wpisujesz w polu Etykieta: (np. „pływanie”). Po kliknięciu przycisku
. Kliknij ten przycisk, a pojawi się okno dialogowe Etykiety wartości. Teraz musisz nadać każdej kategorii swojej zmiennej niezależnej „wartość”, którą wpisujesz w polu Wartość: (np. „1”), oraz „etykietę”, którą wpisujesz w polu Etykieta: (np. „pływanie”). Po kliknięciu przycisku ![]() kodowanie pojawi się w głównym polu (np. „1.00=”pływanie” dla ulubionego_sportu). Ustawienie dla naszej kategorycznej zmiennej niezależnej jest pokazane w oknie dialogowym Etykiety wartości poniżej:
kodowanie pojawi się w głównym polu (np. „1.00=”pływanie” dla ulubionego_sportu). Ustawienie dla naszej kategorycznej zmiennej niezależnej jest pokazane w oknie dialogowym Etykiety wartości poniżej:
Published with written permission from SPSS Statistics, IBM Corporation.
Komórka pod kolumną ![]() powinna pokazywać
powinna pokazywać ![]() , jeśli masz nominalną zmienną niezależną (np, ulubiony_sport, jak w naszym przykładzie) lub
, jeśli masz nominalną zmienną niezależną (np, ulubiony_sport, jak w naszym przykładzie) lub ![]() , jeśli masz zmienną niezależną porządkową (np. wyobraź sobie zmienną porządkową, taką jak „wskaźnik masy ciała” (BMI), BMI), która ma cztery poziomy: „Niedowaga”, „Zdrowa/Normalna waga”, „Nadwaga” i „Otyłość”). Wreszcie w komórce pod kolumną
, jeśli masz zmienną niezależną porządkową (np. wyobraź sobie zmienną porządkową, taką jak „wskaźnik masy ciała” (BMI), BMI), która ma cztery poziomy: „Niedowaga”, „Zdrowa/Normalna waga”, „Nadwaga” i „Otyłość”). Wreszcie w komórce pod kolumną ![]() powinno być
powinno być ![]() .
.
Uwaga: Sugerujemy zmianę komórki pod kolumną ![]() z
z ![]() na
na ![]() , ale nie musisz dokonywać tej zmiany. Sugerujemy to zrobić, ponieważ istnieją pewne analizy w SPSS Statistics, w których ustawienie
, ale nie musisz dokonywać tej zmiany. Sugerujemy to zrobić, ponieważ istnieją pewne analizy w SPSS Statistics, w których ustawienie ![]() powoduje, że zmienne są automatycznie przenoszone do pewnych pól używanych okien dialogowych. Ponieważ możesz nie chcieć przenosić tych zmiennych, sugerujemy zmianę ustawienia
powoduje, że zmienne są automatycznie przenoszone do pewnych pól używanych okien dialogowych. Ponieważ możesz nie chcieć przenosić tych zmiennych, sugerujemy zmianę ustawienia ![]() na
na ![]() , aby nie odbywało się to automatycznie.
, aby nie odbywało się to automatycznie.
Udało Ci się wprowadzić wszystkie informacje, które SPSS Statistics musi znać na temat Twojej kategorycznej zmiennej niezależnej do okna Variable View. W następnej sekcji pokażemy, jak wprowadzić dane do okna Data View.
Widok danych w SPSS Statistics
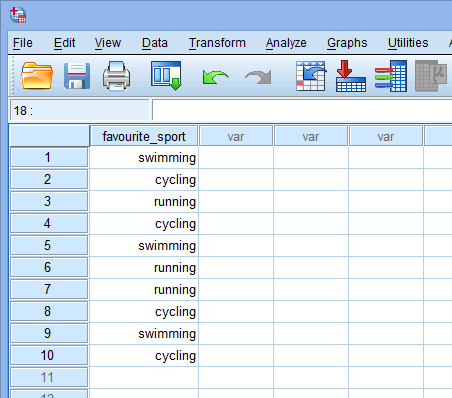
W oparciu o konfigurację pliku dla twojej kategorycznej zmiennej niezależnej w oknie Variable View powyżej, okno Data View wygląda następująco:
Uwaga: Możesz uzyskać dostęp do okna Data Viewwindow w SPSS Statistics klikając na zakładkę ![]() w lewym dolnym rogu programu SPSS Statistics.
w lewym dolnym rogu programu SPSS Statistics.
Published with written permission from SPSS Statistics, IBM Corporation.
Twoja kategoryczna zmienna niezależna będzie wyświetlana w pierwszej kolumnie, ponieważ w takiej kolejności wprowadziliśmy zmienną do okna Widok zmiennej. W naszym przykładzie, odpowiedzi 10 triathlonistów są prezentowane w kolumnie ![]() . Teraz musisz po prostu wprowadzić swoje dane do komórek pod pierwszą kolumną. Pamiętaj, że każdy wiersz reprezentuje jeden przypadek (np. przypadek może być pojedynczym uczestnikiem). Dlatego w wierszu
. Teraz musisz po prostu wprowadzić swoje dane do komórek pod pierwszą kolumną. Pamiętaj, że każdy wiersz reprezentuje jeden przypadek (np. przypadek może być pojedynczym uczestnikiem). Dlatego w wierszu ![]() naszego przykładu pierwszy przypadek reprezentował triatlonistę, którego ulubionym sportem było „pływanie”. Ponieważ komórki te będą początkowo puste, musisz kliknąć w nie, aby wprowadzić swoje dane. Zauważysz, że kiedy klikniesz w komórki pod kolumną
naszego przykładu pierwszy przypadek reprezentował triatlonistę, którego ulubionym sportem było „pływanie”. Ponieważ komórki te będą początkowo puste, musisz kliknąć w nie, aby wprowadzić swoje dane. Zauważysz, że kiedy klikniesz w komórki pod kolumną ![]() , SPSS Statistics da Ci opcję rozwijania z już wypełnionymi kategoriami.
, SPSS Statistics da Ci opcję rozwijania z już wypełnionymi kategoriami.
Teraz, kiedy już ustawiłeś swoje dane w oknach Widoku Zmiennych i Widoku Danych SPSS Statistics, zalecamy przeczytanie następnej sekcji: Understanding dummy variables and dummy coding, gdzie wyjaśniamy podstawowe zasady działania zmiennych dummy i kodowania dummy. Jednakże, jeśli jesteś już zaznajomiony z podstawami zmiennych dummy i kodowania dummy, możesz pominąć tę sekcję i przejść bezpośrednio do sekcji Procedura, gdzie przedstawimy procedurę Create Dummy Variables w SPSS Statistics, która jest używana do tworzenia zmiennych dummy.
SPSS Statistics
Zrozumienie zmiennych dummy i kodowania dummy
Jak wspomnieliśmy we Wprowadzeniu, jeśli analizujesz swoje dane przy użyciu regresji wielorakiej i którakolwiek ze zmiennych niezależnych była mierzona na skali nominalnej lub porządkowej, musisz wiedzieć, jak tworzyć zmienne dummy i interpretować ich wyniki. Dzieje się tak dlatego, że kategoryczne zmienne niezależne (tj. nominalne i porządkowe zmienne niezależne) nie mogą być bezpośrednio wprowadzone do regresji wielorakiej. Zamiast tego muszą one zostać przekształcone w zmienne dummy. Wyjątkiem są rzędowe zmienne niezależne, które wprowadza się do regresji wielorakiej jako ciągłe zmienne niezależne, które nie muszą być przekształcane w zmienne dummy. W poniższych sekcjach wyjaśniamy: (a) liczbę zmiennych dummy, które musisz utworzyć; oraz (b) jak tworzyć zmienne dummy i kodowanie dummy.
Liczba zmiennych dummy, które musisz utworzyć
Liczba zmiennych dummy, które musisz utworzyć, będzie zależała od tego, ile kategorii ma Twoja kategoryczna zmienna niezależna. Zgodnie z ogólną zasadą, utworzysz jedną zmienną dummy mniej niż liczba kategorii w twojej kategorycznej zmiennej niezależnej. Na przykład, jeśli masz kategoryczną zmienną niezależną z trzema kategoriami (np. ulubiony_sport, z następującymi trzema kategoriami: „pływanie”, „jazda na rowerze” i „bieganie”), utworzysz dwie zmienne dummy i wybierzesz jedną kategorię, która będzie działać jako kategoria referencyjna (np. „pływanie” i „jazda na rowerze” stają się zmiennymi dummy, a „bieganie” staje się kategorią referencyjną). Więcej na temat kategorii referencyjnych wyjaśniamy po poniższej tabeli, która zawiera kilka przykładów kategorycznych zmiennych niezależnych oraz liczbę zmiennych dummy, które należy utworzyć:
| Nazwa kategorycznej zmiennej niezależnej | Typ zmiennej | Liczba kategorii | Liczba zmiennych dummy | ||||
|---|---|---|---|---|---|---|---|
| 1 | Gender | Nominal | Two (Males & Females) |
One=Males „Females” jest kategorią odniesienia |
|||
| 2 | Wzrost | Ordinal | Two (Poniżej 180cm & 180cm i więcej) |
One=Poniżej 180cm „180cm i powyżej” jest kategorią odniesienia |
|||
| 3 | Ethnicity | Nominal | Three (African American, Caucasian & Hispanic) |
Two=African American & Caucasian „Hispanic” is the reference category |
|||
| 4 | Physical activity level | Ordinal | Three (Low, Moderate & High) |
Two=Low & Moderate „High” is the reference category |
|||
| 5 | Profession | Nominal | Four (Surgeon, Lekarz, Pielęgniarka & Terapeuta) |
Trzy=Chirurg, Lekarz & Pielęgniarka „Terapeuta” jest kategorią odniesienia |
|||
| 6 | Poziom porozumienia | Ordinal | Cztery (Zdecydowanie się zgadzam, Zgadzam się, Nie zgadzam się, Zdecydowanie się nie zgadzam) |
Trzy=Bardzo się zgadzam, Zgadzam się &Nie zgadzam się „Zdecydowanie się nie zgadzam” jest kategorią odniesienia |
|||
| 7 | Subject area | Nominal | Pięć (Business studies, Psychologia, Nauki biologiczne, Inżynieria & Prawo) |
Cztery=Biznes, Psychologia, Nauki biologiczne &Inżynieria „Prawo” jest kategorią odniesienia |
|||
| 8 | Wiek | Ordinal | Pięć (Poniżej 18, 19-30, 31-40, 41-50, 51-60) |
Cztery=Poniżej 18, 19-30, 31-40 & 41-50 „51-60” jest kategorią referencyjną |
|||
| Tabela: Przykłady kategorycznych zmiennych niezależnych i odpowiadających im zmiennych dummy | |||||||
Jak widać w powyższej tabeli, musisz utworzyć tylko jedną zmienną dummy mniej niż liczba kategorii w twojej kategorycznej zmiennej niezależnej. Dzieje się tak dlatego, że musisz (i powinieneś) przenieść tę liczbę zmiennych dummy do regresji wielokrotnej tylko wtedy, gdy masz kategoryczną zmienną niezależną. Istnieją jednak dobre powody, aby utworzyć zmienną dummy dla każdej kategorii kategorycznej zmiennej niezależnej: (a) jest to bardziej elastyczne i (b) pozwala na dokonywanie wielokrotnych porównań (patrz uwaga poniżej). Innymi słowy, jeśli twoja kategoryczna zmienna niezależna ma trzy kategorie, utworzyłbyś trzy zmienne dummy, a nie tylko dwie.
Na szczęście procedura Create Dummy Variables w SPSS Statistics w wersji 22 i wyższej automatycznie tworzy zmienną dummy dla każdej kategorii twojej kategorycznej zmiennej niezależnej. Nie dotyczy to jednak procedury Przekoduj na różne zmienne w SPSS Statistics w wersji 21 lub wcześniejszej. Dlatego w normalnych okolicznościach utworzysz w SPSS Statistics następującą konfigurację, w zależności od tego, czy masz wersję 21 lub wcześniejszą, czy wersję 22 i wyższą:
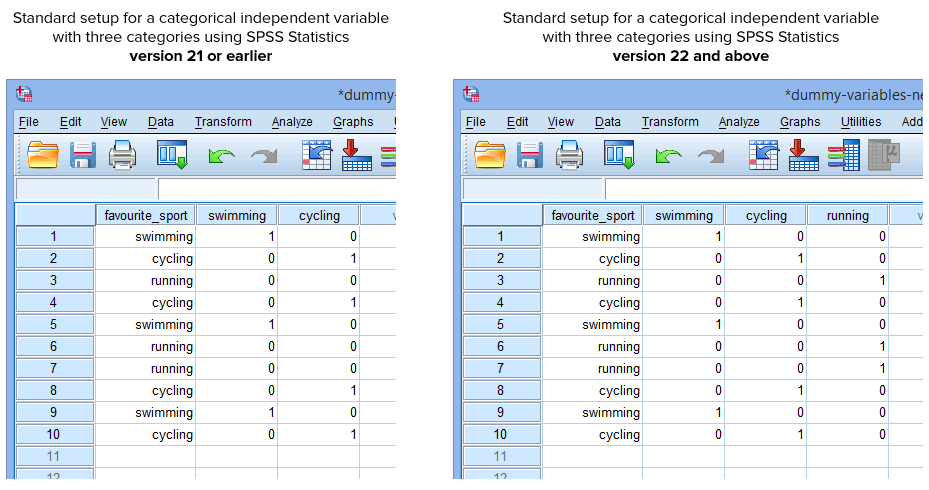
Published with written permission from SPSS Statistics, IBM Corporation.
Uwaga: Jak wspomniano powyżej, tworzenie zmiennej dummy dla każdej kategorii kategorycznej zmiennej niezależnej jest korzystne z dwóch powodów: (a) jest bardziej elastyczne i (b) pozwala na dokonywanie wielokrotnych porównań. Krótko omawiamy te korzyści poniżej:
Jest bardziej elastyczny:
Gdy utworzyłeś zmienną dummy dla każdej kategorii swojej kategorycznej zmiennej niezależnej, możesz następnie rozważyć dowolną kategorię jako kategorię odniesienia. W naszym przykładzie uznaliśmy kategorię „bieganie” za kategorię referencyjną, co oznacza, że przenieślibyśmy „pływanie” i „jazdę na rowerze” do równania regresji wielorakiej. Jednakże, jeśli później zmienilibyśmy zdanie na temat naszego wyboru kategorii referencyjnej, musielibyśmy ponownie uruchomić procedurę zmiennej dummy (chyba że posiadasz SPSS Statistics w wersji 22 lub wyższej). Na przykład, załóżmy, że teraz chcemy uznać kategorię „jazda na rowerze” za kategorię referencyjną. Możemy teraz przenieść zmienne dummy „pływanie” i „bieganie” do równania regresji wielokrotnej, ponieważ mamy również zmienną dummy „bieganie”.
Pozwala to na dokonywanie wielokrotnych porównań:
Współczynnik zmiennej dummy reprezentuje różnicę pomiędzy kategorią, którą reprezentuje zmienna dummy, a kategorią odniesienia. Na przykład, z „bieganiem” jako kategorią odniesienia, współczynnik zmiennej dummy „pływanie” reprezentuje różnicę w zmiennej zależnej pomiędzy kategoriami „pływanie” i „bieganie”. Używając tej metody, nie wszystkie kombinacje kategorii będą możliwe. Problem ten można rozwiązać poprzez zastosowanie różnych kategorii referencyjnych. Jest to możliwe, jeśli wszystkie kategorie zmiennej kategorycznej mają zmienną dummy.
Jak tworzyć zmienne dummy i kodowanie dummy
Są dwa kroki, aby z powodzeniem ustawić zmienne dummy w regresji wielorakiej: (1) utwórz zmienne dummy, które reprezentują kategorie twojej kategorycznej zmiennej niezależnej; i (2) wprowadź wartości do tych zmiennych dummy – znane jako kodowanie dummy – aby reprezentować kategorie kategorycznej zmiennej niezależnej. Wyjaśniamy ten proces poniżej, korzystając z przykładu, który przedstawiliśmy powyżej.
Wyjaśnienie: Zmienne dummy to po prostu nowe zmienne, które działają jako „placeholdery” dla konkretnego schematu kodowania. Nie zawierają one żadnych danych, same w sobie. Zamiast tego, dane/wartości muszą być dodane do tych zmiennych dummy, aby mogły one spełnić swój cel reprezentowania kategorii twojej kategorycznej zmiennej niezależnej. Istnieje wiele różnych rodzajów schematów kodowania, które będą dyktować wartości, które są wprowadzane do zmiennych dummy, ale my używamy bardzo powszechnego schematu kodowania zwanego kodowaniem dummy lub, alternatywnie, kodowaniem wskaźnikowym (N.B., nie dajcie się zmylić, ponieważ zmienne dummy i kodowanie dummy to nie to samo). Kodowanie dummy działa poprzez użycie każdej zmiennej dummy do identyfikacji określonej kategorii kategorycznej zmiennej niezależnej z wyjątkiem kategorii referencyjnej, którą wyjaśniamy poniżej.
Zacznijmy od rozważenia naszej przykładowej kategorycznej zmiennej niezależnej, ulubiony_sport, która ma trzy kategorie: „pływanie”, „jazda na rowerze” i „bieganie”. Ponieważ istnieją trzy kategorie, muszą istnieć dwie zmienne dummy reprezentujące dwie z kategorii i kategoria referencyjna reprezentująca trzecią kategorię.
Uwaga: Pamiętaj z dyskusji powyżej, że regresja wielokrotna wymaga przeniesienia jednej mniej zmiennej dummy niż liczba kategorii w twojej kategorycznej zmiennej niezależnej (tj. dwie w naszym przykładzie). Można jednak utworzyć zmienną dummy dla każdej kategorii kategorycznej zmiennej niezależnej w celu uzyskania większej elastyczności i możliwości dokonywania wielokrotnych porównań. Niemniej jednak, w poniższej dyskusji podkreślamy tylko to, co jest wymagane dla regresji wielokrotnej; to jest, tworzenie jednej mniej zmiennej dummy niż liczba kategorii w twojej kategorycznej zmiennej niezależnej z kategorią, która nie jest bezpośrednio reprezentowana staje się „kategorią odniesienia”.
Na przykład, niech zmienna dummy #1 reprezentuje kategorię „pływanie” i zmienna dummy #2 reprezentuje kategorię „jazda na rowerze”. To nie pozostawia żadnej zmiennej dummy dla kategorii „bieganie”. Ta „brakująca” kategoria jest kategorią odniesienia i nie jest potrzebna. Co więcej, jest to wyłącznie Twoja decyzja, którą kategorię chcesz wykorzystać jako kategorię odniesienia. Równie dobrze mogliśmy wybrać kategorię „pływanie” jako kategorię referencyjną, a nie kategorię „bieganie”. Jedynym powodem, dla którego tego nie zrobiliśmy, jest to, że domyślnie SPSS Statistics używa ostatniej kategorii, którą zakodowałeś w Widoku Zmiennej dla swojej kategorycznej zmiennej niezależnej jako kategorii odniesienia (patrz uwaga poniżej).
Uwaga: Jak wyjaśniono w sekcji Konfiguracja danych wcześniej i jak pokazano poniżej w oknie dialogowym Etykiety wartości, trzecią i ostatnią kategorią naszej kategorycznej zmiennej niezależnej było „bieganie” (tj.., 3=”bieganie”).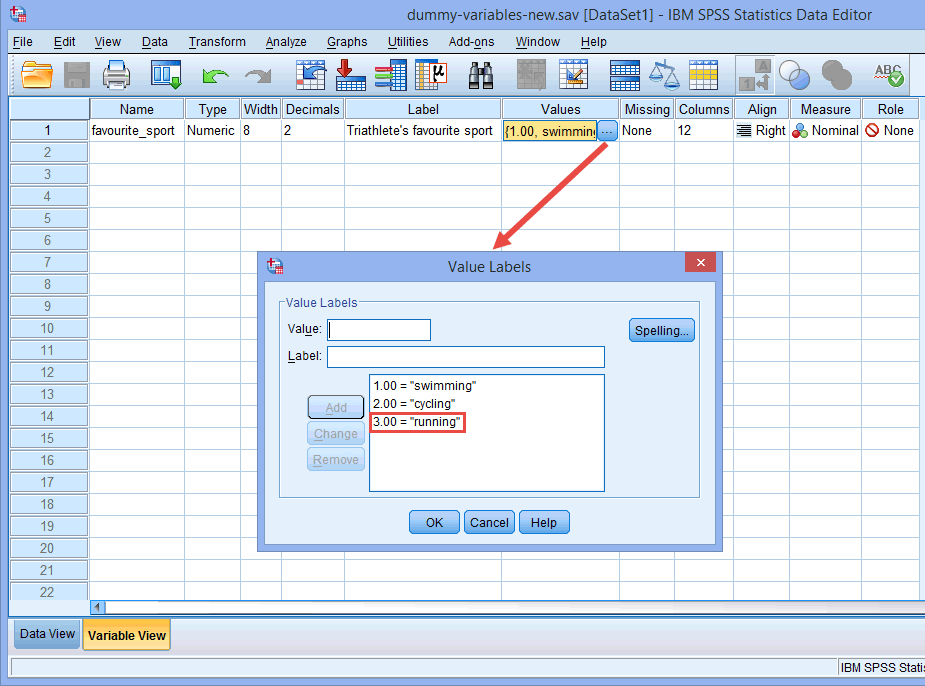
Nie było żadnego teoretycznego ani statystycznego powodu, aby uczynić kategorię „bieganie” trzecią i ostatnią kategorią, co spowodowało, że stała się ona domyślnie kategorią odniesienia w SPSS Statistics. Po prostu zrobiliśmy to w ten sposób, ponieważ kiedy triathloniści biorą udział w triathlonie, najpierw pływają, następnie podejmują cykl, zanim w końcu biegną do mety. Dlatego logiczne wydawało się zakodowanie naszej kategorycznej zmiennej niezależnej w ten sposób. Mogliśmy jednak zakodować ją jako 1=rower, 2=bieg i 3=pływanie; nie zrobiłoby to żadnej różnicy, z wyjątkiem faktu, że jako trzecia i ostatnia kategoria, „pływanie” stałoby się domyślnie naszą kategorią odniesienia w SPSS Statistics.
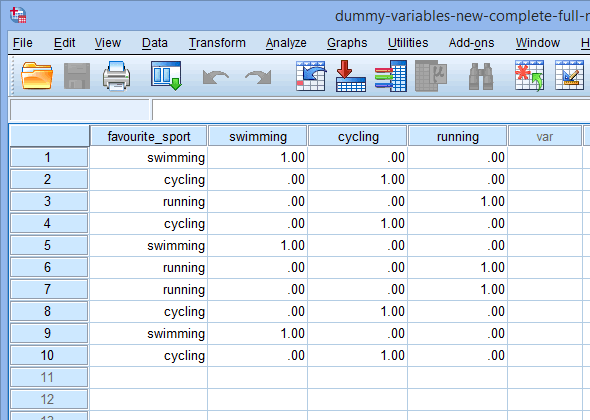
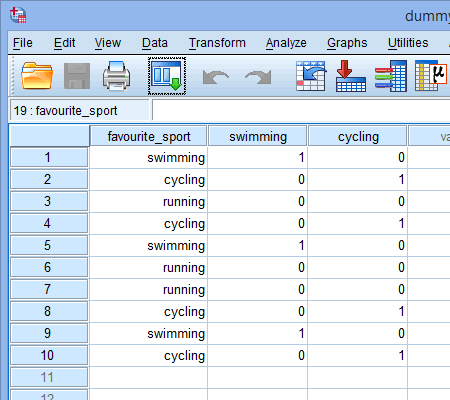
Gdy tworzysz zmienne dummy, powinieneś nadać im znaczącą nazwę. Ponieważ każda z naszych zmiennych dummy reprezentuje kategorię naszej kategorycznej zmiennej niezależnej, zwyczajowo odnosimy się do każdej zmiennej dummy poprzez nazwę kategorii, którą reprezentuje. Dlatego nazwaliśmy zmienną dummy #1 „pływanie”, ponieważ reprezentuje ona kategorię pływania. Podobnie, nazwaliśmy zmienną dummy #2 „jazda na rowerze”, ponieważ reprezentuje ona kategorię jazda na rowerze. Tworząc te dwie zmienne dummy, będziemy mieli dwie nowe kolumny w naszym zestawie danych w SPSS Statistics, jak pokazano poniżej:
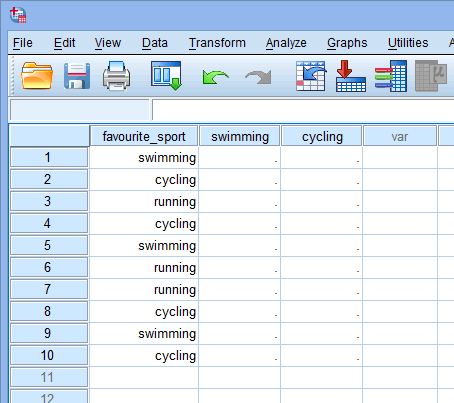
Published with written permission from SPSS Statistics, IBM Corporation.
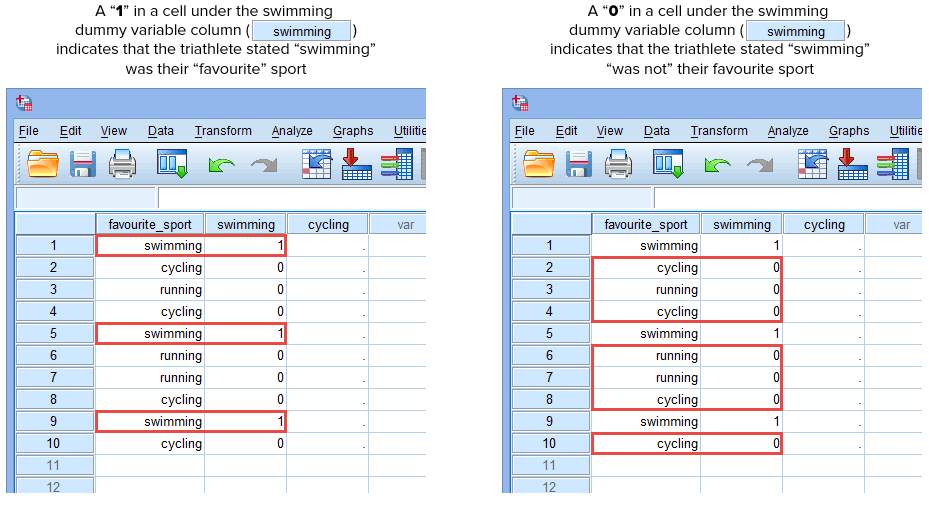
Teraz, gdy stworzyliśmy dwie zmienne dummy i nadaliśmy im odpowiednie nazwy, musimy wprowadzić wartości do tych zmiennych, tak aby każda zmienna dummy rzeczywiście reprezentowała swoją kategorię kategorycznej zmiennej niezależnej. Z kodowaniem dummy jest to bardzo proste. Wprowadzamy „1”, aby reprezentować każdy przypadek (np. uczestnika w naszym zbiorze danych), który ma daną kategorię i wprowadzamy „0” (zero), jeśli nie ma danej kategorii. Po pierwsze, rozważmy zmienną dummy „pływanie”, jak pokazano poniżej:
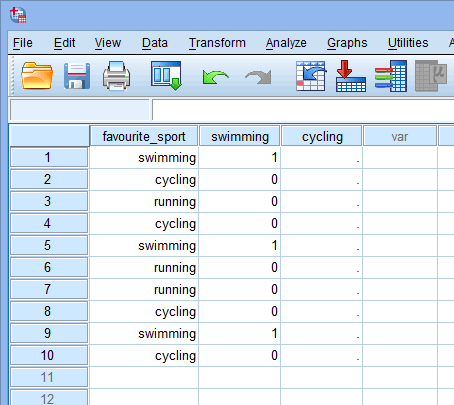
Published za pisemną zgodą SPSS Statistics, IBM Corporation.
Jeśli jeden z triathlonistów stwierdził, że „pływanie” było jego „ulubionym” sportem, wprowadzilibyśmy „1” do komórki pod kolumną zmiennej dummy pływanie (![]() ) dla tego triathlonisty, który stwierdził, że pływanie było jego „ulubionym” sportem. Alternatywnie, jeśli jeden z triathlonistów stwierdził, że „kolarstwo” lub „bieganie” jest jego „ulubionym” sportem, wprowadzimy „0” do komórki w kolumnie zmiennej dummy dla pływania (
) dla tego triathlonisty, który stwierdził, że pływanie było jego „ulubionym” sportem. Alternatywnie, jeśli jeden z triathlonistów stwierdził, że „kolarstwo” lub „bieganie” jest jego „ulubionym” sportem, wprowadzimy „0” do komórki w kolumnie zmiennej dummy dla pływania (![]() ) dla tego triathlonisty, który stwierdził, że pływanie nie jest jego „ulubionym” sportem (tj. oznacza to, że „kolarstwo” lub „bieganie” jest jego ulubionym sportem).
) dla tego triathlonisty, który stwierdził, że pływanie nie jest jego „ulubionym” sportem (tj. oznacza to, że „kolarstwo” lub „bieganie” jest jego ulubionym sportem).
Published with written permission from SPSS Statistics, IBM Corporation.
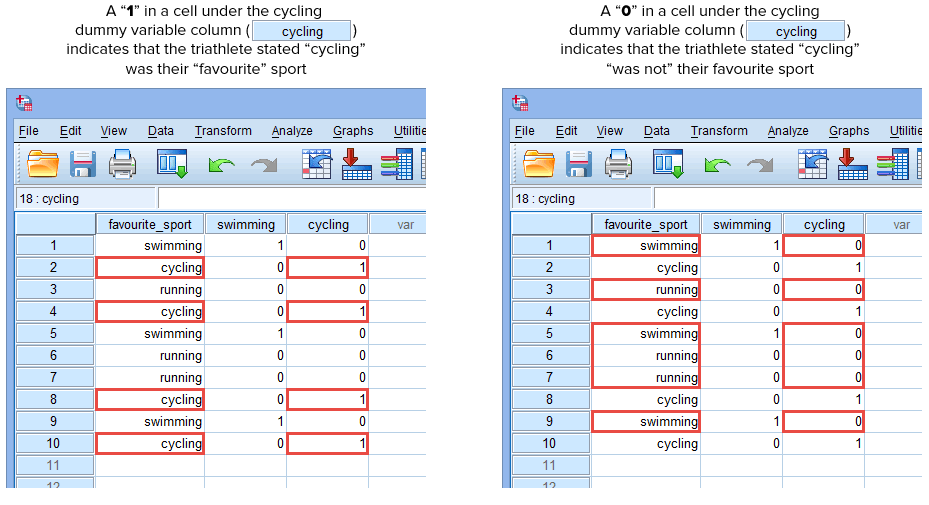
Powtarzamy ten proces dla drugiej zmiennej dummy, „kolarstwo”, jak pokazano poniżej:
Published with written permission from SPSS Statistics, IBM Corporation.
Jeśli jeden z triathlonistów stwierdził, że „kolarstwo” jest jego „ulubionym” sportem, wprowadzimy „1” do komórki w kolumnie zmiennej dummy (![]() ) dla tego triathlonisty, który stwierdził, że kolarstwo jest jego „ulubionym” sportem. Alternatywnie, jeśli jeden z triathlonistów stwierdził, że „pływanie” lub „bieganie” jest jego „ulubionym” sportem, wprowadzamy „0” do komórki w kolumnie
) dla tego triathlonisty, który stwierdził, że kolarstwo jest jego „ulubionym” sportem. Alternatywnie, jeśli jeden z triathlonistów stwierdził, że „pływanie” lub „bieganie” jest jego „ulubionym” sportem, wprowadzamy „0” do komórki w kolumnie ![]() dla tego triathlonisty, który stwierdził, że kolarstwo nie jest jego „ulubionym” sportem (tzn. oznacza to, że „pływanie” lub „bieganie” jest jego ulubionym sportem). Jest to zaznaczone poniżej dla wszystkich 10 triathlonistów:
dla tego triathlonisty, który stwierdził, że kolarstwo nie jest jego „ulubionym” sportem (tzn. oznacza to, że „pływanie” lub „bieganie” jest jego ulubionym sportem). Jest to zaznaczone poniżej dla wszystkich 10 triathlonistów:
Published with written permission from SPSS Statistics, IBM Corporation.
Wprowadzając „1 „s i „0 „s do swoich zmiennych dummy w ten sposób, utworzysz zestaw zmiennych dummy, które możesz wprowadzić do analizy regresji wielorakiej. W sekcji Procedura, która znajduje się poniżej, pokazujemy, jak utworzyć te zmienne dummy za pomocą procedury Utwórz zmienne dummy.
SPSS Statistics
Procedury w SPSS Statistics do tworzenia zmiennych dummy
W SPSS Statistics istnieją dwie procedury do tworzenia zmiennych dummy: procedura Utwórz zmienne dummy i procedura Przekoduj w różne zmienne. W tym przewodniku pokażemy, jak używać procedury Create Dummy Variables, która jest prostą procedurą składającą się z 3 kroków. Jest ona jednak dostępna tylko wtedy, gdy posiadasz SPSS Statistics w wersji 22 lub nowszej, przy czym wersja 26 (i subskrypcyjna wersja SPSS Statistics) jest najnowszą wersją SPSS Statistics. Jeśli nie jesteś pewien, której wersji SPSS Statistics używasz, zobacz nasz przewodnik: Identyfikowanie swojej wersji SPSS Statistics. Jeśli masz SPSS Statistics w wersji 21 lub wcześniejszej lub jesteś zainteresowany dokonywaniem wielokrotnych porównań podczas przeprowadzania analizy regresji wielorakiej, zapoznaj się z poniższą uwagą:
Uwaga: Jeśli masz SPSS Statistics w wersji 21 lub wcześniejszej, nie możesz użyć procedury Create Dummy Variables. Dlatego procedura Recode into Different Variables umożliwia przynajmniej tworzenie zmiennych dummy w SPSS Statistics. Chociaż można również użyć procedury Recode into Different Variables do tworzenia zmiennych dummy, jeśli masz SPSS Statistics w wersji 22 lub nowszej, w tym przewodniku przedstawiliśmy procedurę Create Dummy Variables, ponieważ jest ona dedykowana do tworzenia zmiennych dummy i jest o wiele łatwiejsza i szybsza w użyciu. Na przykład, wymaga tylko 3 kroków, aby utworzyć zmienne dummy dla przykładu użytego w tym przewodniku, w porównaniu do 28 kroków dla tego samego przykładu przy użyciu procedury Recode into Different Variables.
Dlatego, jeśli masz SPSS Statistics w wersji 21 lub wcześniejszej, nasz rozszerzony przewodnik na temat tworzenia zmiennych dummy w sekcji członków na Laerd Statistics zawiera stronę poświęconą pokazaniu, jak przeprowadzić 28 kroków procedury Recode into Different Variables. Możesz uzyskać dostęp do tego rozszerzonego przewodnika poprzez subskrypcję Laerd Statistics. Alternatywnie można po prostu użyć poniższej procedury Create Dummy Variables.
Aby utworzyć zmienne dummy, gdy posiadasz SPSS Statistics w wersji 22 lub nowszej, wykonaj poniższą trzystopniową procedurę Create Dummy Variables:
- Kliknij Transform > Create Dummy Variables w menu głównym, jak pokazano poniżej:

Published with written permission from SPSS Statistics, IBM Corporation.
Pojawi się okno dialogowe Create Dummy Variables, jak pokazano poniżej:
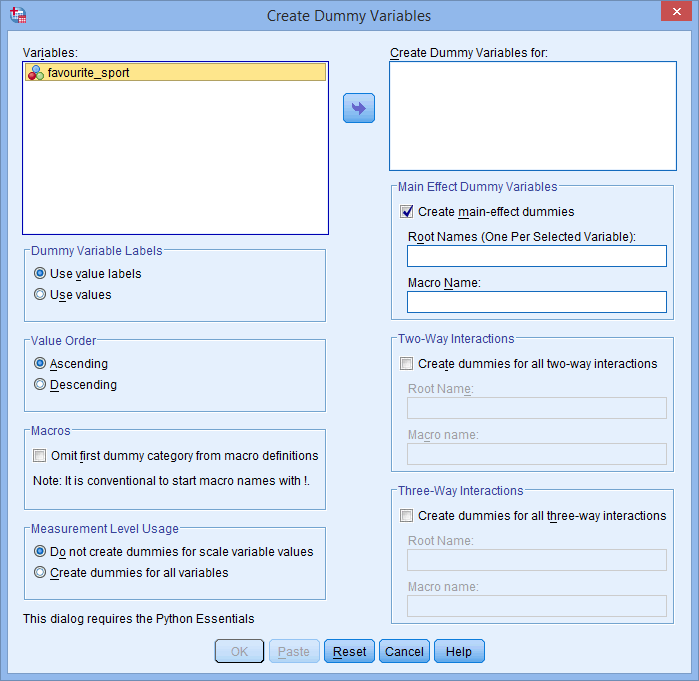
Published with written permission from SPSS Statistics, IBM Corporation.
- Przenieś kategoryczną zmienną niezależną, ulubiony_sport, do okna Create Dummy Variables for: zaznaczając ją (klikając na nią), a następnie klikając przycisk
 . Wprowadź również nazwę „root”, która może reprezentować wszystkie nowe zmienne dummy w polu Root Names (One Per Selected Variable): w obszarze -Main Effect Dummy Variables-. Wprowadziliśmy nazwę root „fs” jako skrót dla naszej kategorycznej zmiennej niezależnej, „favourite_sport”, jak pokazano poniżej:
. Wprowadź również nazwę „root”, która może reprezentować wszystkie nowe zmienne dummy w polu Root Names (One Per Selected Variable): w obszarze -Main Effect Dummy Variables-. Wprowadziliśmy nazwę root „fs” jako skrót dla naszej kategorycznej zmiennej niezależnej, „favourite_sport”, jak pokazano poniżej:
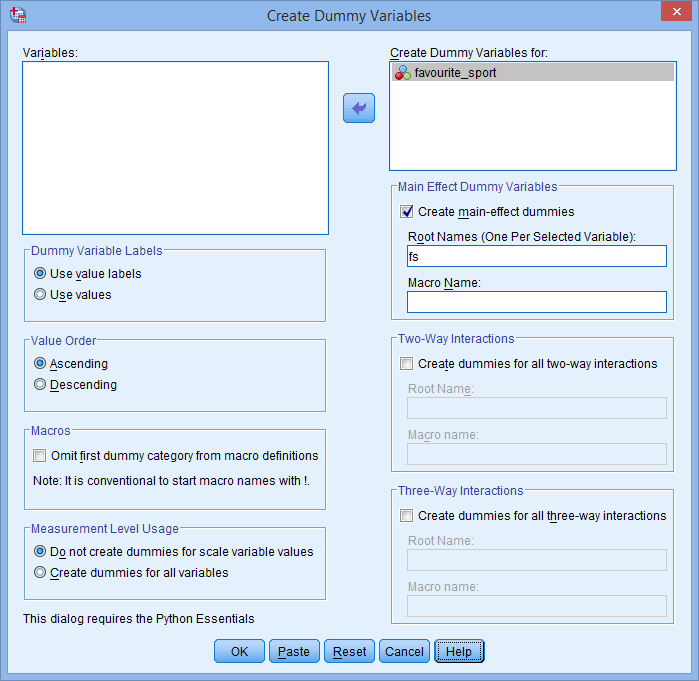
Publikowane za pisemną zgodą SPSS Statistics, IBM Corporation.
Uwaga: SPSS Statistics doda kolejny numer (tj. 1, 2, 3, 4, itd.) na końcu nazwy root, którą wybierzesz do reprezentowania swojej kategorycznej zmiennej niezależnej. Numer kolejny zostanie utworzony dla każdej ze zmiennych dummy, które chcesz utworzyć (np. jeśli masz dwie zmienne dummy, 1 i 2 zostaną dodane na końcu nazwy głównej, ale jeśli masz sześć zmiennych dummy, 1, 2, 3, 4, 5 i 6 zostaną dodane na końcu nazwy głównej). Jest to pokazane dla naszego przykładu w oknie Widok zmiennej poniżej:
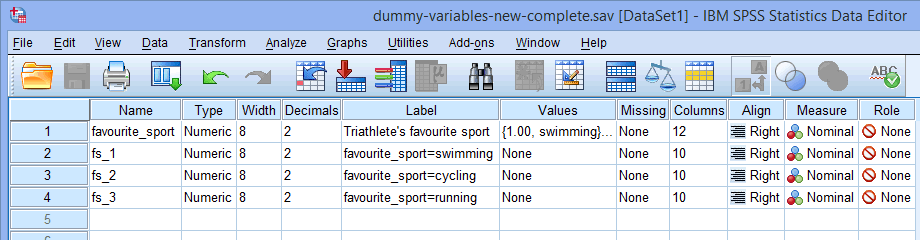
Ponieważ nasza kategoryczna zmienna niezależna, ulubiony_sport, ma trzy kategorie (tj. pływanie, jazda na rowerze i bieganie), procedura Utwórz zmienne dummy tworzy trzy zmienne dummy (tj. jedną dla pływania, jedną dla jazdy na rowerze i jedną dla biegania). Te trzy zmienne dummy są zaznaczone w kolumnie powyżej: „fs_1” (dla pływania), „fs_2” (dla jazdy na rowerze) i „fs_3” (dla biegania). Możesz później zmienić ich nazwy tak, aby miały więcej sensu. Podkreślamy to tylko, abyś wiedział, jak działa pole Root Names (One Per Selected Variable): powyżej.
powyżej: „fs_1” (dla pływania), „fs_2” (dla jazdy na rowerze) i „fs_3” (dla biegania). Możesz później zmienić ich nazwy tak, aby miały więcej sensu. Podkreślamy to tylko, abyś wiedział, jak działa pole Root Names (One Per Selected Variable): powyżej.
Ponadto, nazwa korzenia, którą wpisujesz do pola Root Names (One Per Selected Variable): nie może być taka sama jak nazwa twojej kategorycznej zmiennej niezależnej, jak pokazano poniżej (tj, gdzie wprowadziliśmy nazwę główną „ulubiony_sport”, aby zilustrować, czego nie moglibyśmy nazwać naszą nazwą główną):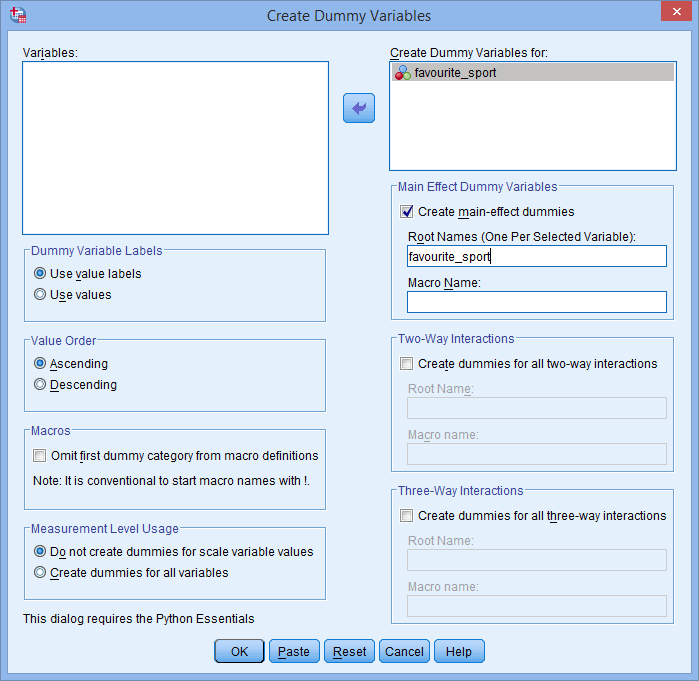
Jeśli nazwa główna, którą wprowadzasz, jest taka sama jak nazwa twojej kategorycznej zmiennej niezależnej, jak pokazano powyżej, po kliknięciu przycisku otrzymasz następujące ostrzeżenie:
otrzymasz następujące ostrzeżenie:
- Kliknij przycisk .
Po wykonaniu powyższej 3-stopniowej procedury tworzenia zmiennej dummy będziesz miał utworzone zmienne dummy dla swojej kategorycznej zmiennej niezależnej. W następnej sekcji podkreśl dane wyjściowe, które są tworzone w Widoku zmiennych i Widoku danych SPSS Statistics po uruchomieniu procedury Utwórz zmienne dummy.
SPSS Statistics
Ustawienia danych wyjściowych i danych w SPSS Statistics po utworzeniu zmiennych dummy
Po utworzeniu zmiennych dummy, SPSS Statistics tworzy następującą tabelę Variable Creation w przeglądarce IBM SPSS Statistics Viewer:
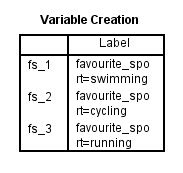
Publikacja opublikowana za pisemną zgodą SPSS Statistics, IBM Corporation.
Tabela Variable Creation potwierdza, że udało się utworzyć zmienne dummy. Powinno być tyle wierszy, ile jest nowych zmiennych dummy. Ponieważ utworzyliśmy trzy zmienne fikcyjne, w tabeli znajdują się trzy wiersze „fs_1”, „fs_2” i „fs_3”, które odzwierciedlają nazwę główną i numerację sekwencyjną wprowadzoną w kroku 2 procedury „Utwórz zmienne fikcyjne” w poprzedniej sekcji. Dla każdej z tych zmiennych dummy w tabeli podana jest etykieta, aby wyjaśnić, którą kategorię kategorycznej zmiennej niezależnej reprezentuje każda zmienna dummy. Na przykład, etykieta „favourite_sport=pływanie” jest podana dla „fs_1”, wskazując, że „fs_1” jest zmienną dummy dla kategorii „pływanie” kategorycznej zmiennej niezależnej, favourite_sport.
Następnie, przejdź do okna Variable View w SPSS Statistics klikając na zakładkę ![]() . Zostaną dodane trzy zmienne dummy, jak pokazano poniżej (tj. zmienne dummy „fs_1”, „fs_2” i „fs_3” w kolumnie
. Zostaną dodane trzy zmienne dummy, jak pokazano poniżej (tj. zmienne dummy „fs_1”, „fs_2” i „fs_3” w kolumnie ![]() ):
):
Published with written permission from SPSS Statistics, IBM Corporation.
Uwaga: Możesz zmienić nazwy zmiennych dummy w kolumnie ![]() , aby wyraźniej określić, co to jest. Na przykład zmieniliśmy „fs_1” na „pływanie”, „fs_2” na „jazda na rowerze” i „fs_3” na „bieganie”, jak pokazano poniżej:
, aby wyraźniej określić, co to jest. Na przykład zmieniliśmy „fs_1” na „pływanie”, „fs_2” na „jazda na rowerze” i „fs_3” na „bieganie”, jak pokazano poniżej:
Na koniec przejdź do okna Data View w SPSS Statistics, klikając na zakładkę ![]() . Kodowanie dummy jest wyświetlane pod każdą z utworzonych zmiennych dummy. Na przykład, w wierszach pod kolumną „fs_1”, kategoria „pływanie” jest zakodowana jako „1.00”, podczas gdy kategorie „jazda na rowerze” i „bieganie” są zakodowane jako „.00”, jak pokazano poniżej. Jeśli nie jesteś pewien, dlaczego te zmienne dummy są zakodowane w ten sposób, zobacz sekcję: Understanding dummy variables and dummy coding.
. Kodowanie dummy jest wyświetlane pod każdą z utworzonych zmiennych dummy. Na przykład, w wierszach pod kolumną „fs_1”, kategoria „pływanie” jest zakodowana jako „1.00”, podczas gdy kategorie „jazda na rowerze” i „bieganie” są zakodowane jako „.00”, jak pokazano poniżej. Jeśli nie jesteś pewien, dlaczego te zmienne dummy są zakodowane w ten sposób, zobacz sekcję: Understanding dummy variables and dummy coding.
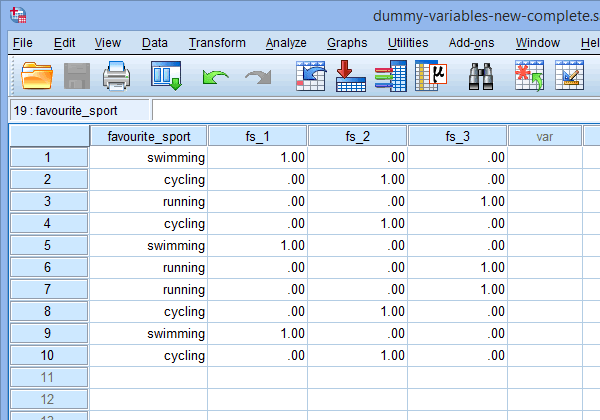
Published with written permission from SPSS Statistics, IBM Corporation.
Uwaga 1: Ze względu na domyślne ustawienia SPSS Statistics, Twoje zmienne dummy będą kodowane „1.00” lub „.00” zamiast odpowiednio „1” lub „0”. Są one identyczne. Jednak często można spotkać kodowanie zmiennych manekinowych zapisane w postaci 1 i 0, a nie zawierające liczby dziesiętne.
Uwaga 2: Jeśli zmieniłeś nazwy zmiennych manekinowych w kolumnie ![]() w oknie Widok zmiennych powyżej, zostaną one również zmienione w kolumnach okna Widok danych, jak pokazano poniżej (np. nagłówek kolumny
w oknie Widok zmiennych powyżej, zostaną one również zmienione w kolumnach okna Widok danych, jak pokazano poniżej (np. nagłówek kolumny ![]() jest teraz zatytułowany
jest teraz zatytułowany ![]() ):
):