Last Updated on August 18, 2020
Zestawy danych mogą mieć brakujące wartości, a to może powodować problemy dla wielu algorytmów uczenia maszynowego.
Jako takie, dobrą praktyką jest zidentyfikowanie i zastąpienie brakujących wartości dla każdej kolumny w danych wejściowych przed modelowaniem zadania predykcji. Nazywa się to imputacją brakujących danych, lub w skrócie imputacją.
Popularnym podejściem do imputacji danych jest obliczenie wartości statystycznej dla każdej kolumny (takiej jak średnia) i zastąpienie wszystkich brakujących wartości dla tej kolumny statystyką. Jest to popularne podejście, ponieważ statystyka jest łatwa do obliczenia przy użyciu zbioru danych treningowych i ponieważ często skutkuje dobrą wydajnością.
W tym samouczku dowiesz się, jak używać strategii imputacji statystycznej dla brakujących danych w uczeniu maszynowym.
Po ukończeniu tego samouczka będziesz wiedział:
- Brakujące wartości muszą być oznaczone wartościami NaN i mogą być zastąpione miarami statystycznymi w celu obliczenia kolumny wartości.
- Jak wczytać wartość CSV z brakującymi wartościami i oznaczyć brakujące wartości wartościami NaN oraz zgłosić liczbę i procent brakujących wartości dla każdej kolumny.
- Jak imputować brakujące wartości za pomocą statystyk jako metodę przygotowania danych podczas oceny modeli oraz podczas dopasowywania ostatecznego modelu w celu tworzenia prognoz na nowych danych.
Zacznij swój projekt z moją nową książką Data Preparation for Machine Learning, zawierającą samouczki krok po kroku oraz pliki kodu źródłowego Pythona dla wszystkich przykładów.
Zacznijmy.
- Zaktualizowano Jun/2020: Zmieniona kolumna używana do predykcji w przykładach.

Statistical Imputation for Missing Values in Machine Learning
Photo by Bernal Saborio, some rights reserved.
Przegląd samouczka
Ten samouczek jest podzielony na trzy części; są to:
- Statistical Imputation
- Horse Colic Dataset
- Statistical Imputation With SimpleImputer
- SimpleImputer Data Transform
- SimpleImputer and Model Evaluation
- Comparing Different Imputed Statistics
- SimpleImputer Transform When Making a Prediction
.
Imputacja statystyczna
Zbiór danych może mieć brakujące wartości.
Są to wiersze danych, w których jedna lub więcej wartości lub kolumn w tym wierszu nie występuje. Wartości te mogą być całkowicie brakujące lub mogą być oznaczone specjalnym znakiem lub wartością, taką jak znak zapytania „?”.
Wartości te mogą być wyrażone na wiele sposobów. Widziałem je jako nic, pusty ciąg, wyraźny ciąg NULL lub undefined lub N/A lub NaN, a także liczbę 0, między innymi. Bez względu na to, jak pojawiają się w zbiorze danych, wiedza o tym, czego się spodziewać i sprawdzenie, czy dane odpowiadają tym oczekiwaniom, zmniejszy problemy, gdy zaczniesz używać danych.
– Strona 10, Bad Data Handbook, 2012.
Wartości może brakować z wielu powodów, często specyficznych dla domeny problemu, i może obejmować powody takie jak uszkodzone pomiary lub niedostępność danych.
Mogą one wystąpić z wielu powodów, takich jak nieprawidłowe działanie sprzętu pomiarowego, zmiany w projekcie eksperymentu podczas zbierania danych oraz zestawianie kilku podobnych, ale nie identycznych zbiorów danych.
– Strona 63, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
Większość algorytmów uczenia maszynowego wymaga numerycznych wartości wejściowych oraz obecności wartości dla każdego wiersza i kolumny w zbiorze danych. Jako takie, brakujące wartości mogą powodować problemy dla algorytmów uczenia maszynowego.
Jako takie, powszechne jest identyfikowanie brakujących wartości w zbiorze danych i zastępowanie ich wartością numeryczną. Nazywa się to imputacją danych lub imputacją brakujących danych.
Proste i popularne podejście do imputacji danych polega na użyciu metod statystycznych do oszacowania wartości dla kolumny z tych wartości, które są obecne, a następnie zastąpienie wszystkich brakujących wartości w kolumnie obliczoną statystyką.
Jest to proste, ponieważ statystyka jest szybka do obliczenia, a jest popularna, ponieważ często okazuje się bardzo skuteczna.
Często obliczane statystyki obejmują:
- Wartość średnią kolumny.
- Wartość mediany kolumny.
- Wartość trybu kolumny.
- Wartość stałą.
Teraz, gdy znamy już statystyczne metody imputacji brakujących wartości, przyjrzyjmy się zbiorowi danych z brakującymi wartościami.
Want to Get Started With Data Preparation?
Take my free 7-day email crash course now (with sample code).
Kliknij, aby się zapisać, a także otrzymać darmowy PDF Ebook w wersji kursu.
Download Your FREE Mini-Course
Horse Colic Dataset
Zbiór danych dotyczących kolki u koni opisuje charakterystykę medyczną koni z kolką oraz to, czy żyły, czy padły.
Zestaw zawiera 300 wierszy i 26 zmiennych wejściowych z jedną zmienną wyjściową. Jest to zadanie przewidywania klasyfikacji binarnej, które polega na przewidywaniu 1, jeśli koń żył i 2, jeśli koń umarł.
Jest wiele pól, które możemy wybrać do przewidywania w tym zbiorze danych. W tym przypadku będziemy przewidywać, czy problem był chirurgiczny czy nie (indeks kolumny 23), co sprawia, że jest to problem klasyfikacji binarnej.
Zbiór danych ma liczne brakujące wartości dla wielu kolumn, gdzie każda brakująca wartość jest oznaczona znakiem zapytania („?”).
Poniżej podano przykład wierszy ze zbioru danych z zaznaczonymi brakującymi wartościami.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Możesz dowiedzieć się więcej o zbiorze danych tutaj:
- Horse Colic Dataset
- Horse Colic Dataset Description
Nie ma potrzeby pobierania zbioru danych, ponieważ pobierzemy go automatycznie w działających przykładach.
Naznaczanie brakujących wartości wartością NaN (not a number) w załadowanym zbiorze danych przy użyciu Pythona jest najlepszą praktyką.
Możemy załadować zbiór danych przy użyciu funkcji read_csv() Pandas i określić „na_values”, aby załadować wartości ’?’ jako brakujące, oznaczone wartością NaN.
|
1
2
3
4
|
…
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
|
Po załadowaniu możemy przejrzeć załadowane dane, aby potwierdzić, że „?” są oznaczone jako NaN.
|
1
2
3
|
….
# podsumuj kilka pierwszych wierszy
print(dataframe.head())
|
Możemy następnie wyliczyć każdą kolumnę i zgłosić liczbę wierszy z brakującymi wartościami dla kolumny.
|
1
2
3
4
5
6
7
|
…
# podsumuj liczbę wierszy z brakującymi wartościami dla każdej kolumny
for i in range(dataframe.shape):
# policz liczbę wierszy z brakującymi wartościami
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(’> %d, Brakujące: %d (%.1f%%)’ % (i, n_miss, perc))
|
Wiążąc to razem, pełny przykład ładowania i podsumowywania zbioru danych znajduje się poniżej.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# summarize the horse colic dataset
from pandas import read_csv
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# podsumuj kilka pierwszych wierszy
print(dataframe.head())
# podsumuj liczbę wierszy z brakującymi wartościami dla każdej kolumny
for i in range(dataframe.shape):
# policz liczbę wierszy z brakującymi wartościami
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(’> %d, Missing: %d (%.1f%%)’ % (i, n_miss, perc))
|
Wykonanie przykładu najpierw ładuje zbiór danych i podsumowuje pięć pierwszych wierszy.
Widzimy, że brakujące wartości, które były oznaczone znakiem „?”, zostały zastąpione wartościami NaN.
Następnie możemy zobaczyć listę wszystkich kolumn w zbiorze danych oraz liczbę i procent brakujących wartości.
Możemy zobaczyć, że niektóre kolumny (np. indeksy kolumn 1 i 2) nie mają żadnych brakujących wartości, a inne kolumny (np. indeksy kolumn 15 i 21) mają wiele lub nawet większość brakujących wartości.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Missing: 1 (0,3%)
> 1, Brakuje: 0 (0.0%)
> 2, Brakujące: 0 (0.0%)
> 3, Brakujące: 60 (20.0%)
> 4, Brakujące: 24 (8,0%)
> 5, Brakujące: 58 (19,3%)
> 6, Brakujące: 56 (18,7%)
> 7, Brakujące: 69 (23,0%)
> 8, Brakujące: 47 (15,7%)
> 9, Brakujące: 32 (10,7%)
> 10, Brakujące: 55 (18,3%)
> 11, Brakujące: 44 (14,7%)
> 12, Brakujące: 56 (18,7%)
> 13, Brakujące: 104 (34,7%)
> 14, Brakujące: 106 (35,3%)
> 15, Brakujących: 247 (82,3%)
> 16, Brakujące: 102 (34,0%)
> 17, Brakujące: 118 (39,3%)
> 18, Brakujące: 29 (9,7%)
> 19, Brakujące: 33 (11.0%)
> 20, Brakujące: 165 (55.0%)
> 21, Brakujące: 198 (66.0%)
> 22, Brakujące: 1 (0,3%)
> 23, Brakujące: 0 (0.0%)
> 24, Brakujące: 0 (0.0%)
> 25, Brakujące: 0 (0.0%)
> 26, Brakujące: 0 (0.0%)
> 27, Brakujące: 0 (0.0%)
|
Teraz, gdy znamy już zbiór danych dotyczących kolki końskiej, który ma brakujące wartości, przyjrzyjmy się, jak możemy użyć imputacji statystycznej.
Statistical Imputation With SimpleImputer
Biblioteka uczenia maszynowego scikit-learn dostarcza klasę SimpleImputer, która obsługuje imputację statystyczną.
W tym rozdziale zbadamy, jak efektywnie używać klasy SimpleImputer.
Przekształcenie danych SimpleImputer
Przekształcenie SimpleImputer jest przekształceniem danych, które jest najpierw konfigurowane w oparciu o typ statystyki do obliczenia dla każdej kolumny, np.np. mean.
|
1
2
3
|
…
# define imputer
imputer = SimpleImputer(strategy=’mean’)
|
Następnie imputer jest dopasowywany na zbiorze danych, aby obliczyć statystykę dla każdej kolumny.
|
1
2
3
|
…
# fit on the dataset
imputer.fit(X)
|
Pasujący imputer jest następnie stosowany do zbioru danych, aby utworzyć kopię zbioru danych ze wszystkimi brakującymi wartościami dla każdej kolumny zastąpionymi wartością statystyczną.
|
1
2
3
|
…
# transform the dataset
Xtrans = imputer.transform(X)
|
Możemy zademonstrować jego użycie na zbiorze danych dotyczących kolki końskiej i potwierdzić, że działa, podsumowując całkowitą liczbę brakujących wartości w zbiorze danych przed i po transformacji.
Pełny przykład znajduje się poniżej.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# imputacja statystyczna transform for the horse colic dataset
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# print total missing
print(’Missing: %d’ % sum(isnan(X).flatten()))
# define imputer
imputer = SimpleImputer(strategy=’mean’)
# fit on the dataset
imputer.fit(X)
# transform the dataset
Xtrans = imputer.transform(X)
# print total missing
print(’Missing: %d’ % sum(isnan(Xtrans).flatten())
|
Wykonanie przykładu najpierw ładuje zbiór danych i zgłasza całkowitą liczbę brakujących wartości w zbiorze danych jako 1 605.
Transformacja jest skonfigurowana, dopasowana i wykonana, a wynikowy nowy zbiór danych nie ma brakujących wartości, potwierdzając, że została wykonana zgodnie z naszymi oczekiwaniami.
Każda brakująca wartość została zastąpiona średnią wartością swojej kolumny.
|
1
2
|
Brakujące: 1605
Brak: 0
|
Ewaluacja modeli i uczenia maszynowego
Dobrą praktyką jest ewaluacja modeli uczenia maszynowego na zbiorze danych przy użyciu k-krotnej walidacji krzyżowej.
Aby poprawnie zastosować statystyczną imputację brakujących danych i uniknąć wycieku danych, wymagane jest, aby statystyki obliczane dla każdej kolumny były obliczane tylko na zbiorze danych treningowych, a następnie stosowane do zestawów treningowych i testowych dla każdego złożenia w zbiorze danych.
Jeśli używamy ponownego próbkowania do wyboru wartości parametrów dostrajania lub do oszacowania wydajności, imputacja powinna być włączona do ponownego próbkowania.
– Strona 42, Applied Predictive Modeling, 2013.
Można to osiągnąć poprzez utworzenie potoku modelowania, w którym pierwszym krokiem jest imputacja statystyczna, a następnie drugim krokiem jest model. Można to osiągnąć za pomocą klasy Pipeline.
Na przykład, poniższy Pipeline używa SimpleImputer ze strategią 'mean’, a następnie modelu random forest.
|
1
2
3
4
5
|
…
# define modeling pipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
|
Możemy ocenić imputowany zestaw danych mean-imputowany zbiór danych i potok modelowania lasu losowego dla zbioru danych o kolce końskiej z powtarzaną 10-krotną walidacją krzyżową.
Pełny przykład znajduje się poniżej.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# evaluate mean imputation and random forest forest for the horse colic dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# podziel na elementy wejściowe i wyjściowe
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# define modeling pipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
# define model evaluation
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate model
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
print(’Mean Accuracy: %.3f (%.3f)” % (mean(scores), std(scores)))
|
Wykonanie przykładu poprawnie stosuje imputację danych do każdego złożenia procedury walidacji krzyżowej.
Uwaga: Twoje wyniki mogą się różnić ze względu na stochastyczny charakter algorytmu lub procedury oceny, lub różnice w precyzji numerycznej. Rozważ uruchomienie przykładu kilka razy i porównaj średni wynik.
Potok jest oceniany przy użyciu trzech powtórzeń 10-krotnej walidacji krzyżowej i zgłasza średnią dokładność klasyfikacji na zbiorze danych jako około 86.3 procent, co jest dobrym wynikiem.
|
1
|
Mean Accuracy: 0.863 (0.054)
|
Porównanie różnych imputowanych statystyk
Skąd wiemy, że użycie „średniej” strategii statystycznej jest dobre lub najlepsze dla tego zbioru danych?
Odpowiedź brzmi, że nie wiemy i że została ona wybrana arbitralnie.
Możemy zaprojektować eksperyment, aby przetestować każdą strategię statystyczną i odkryć, co działa najlepiej dla tego zbioru danych, porównując strategie: średnią, medianę, tryb (najczęstszy) i stałą (0). Średnia dokładność każdego podejścia może być następnie porównana.
Pełny przykład jest wymieniony poniżej.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# porównaj strategie imputacji statystycznej dla zbioru danych o kolce końskiej
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# podziel na elementy wejściowe i wyjściowe
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# oceń każdą ze strategii na zbiorze danych
results = list()
strategies =
for s in strategies:
# create the modeling pipeline
pipeline = Pipeline(steps=)
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
# store results
results.append(scores)
print(’>%s %.3f (%.3f)’ % (s, mean(scores), std(scores))))
#wykreśl wydajność modelu dla porównania
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
|
Running the example evaluates each statistical imputation strategy on the horse colic dataset using repeated cross-validation.
Uwaga: Twoje wyniki mogą się różnić ze względu na stochastyczną naturę algorytmu lub procedury oceny, lub różnice w precyzji numerycznej. Rozważ uruchomienie przykładu kilka razy i porównaj średni wynik.
Średnia dokładność każdej strategii jest raportowana po drodze. Wyniki sugerują, że użycie stałej wartości, np. 0, daje najlepszy wynik około 88,1 procent, co jest znakomitym rezultatem.
|
1
2
3
4
|
>mean 0.860 (0.054)
>median 0.862 (0.065)
>most_frequent 0.872 (0.052)
>constant 0.881 (0.047)
|
Na końcu przebiegu dla każdego zestawu wyników tworzony jest wykres typu box and whisker, pozwalający na porównanie rozkładu wyników.
Widzimy wyraźnie, że rozkład wyników dokładności dla strategii stałej jest lepszy niż dla pozostałych strategii.
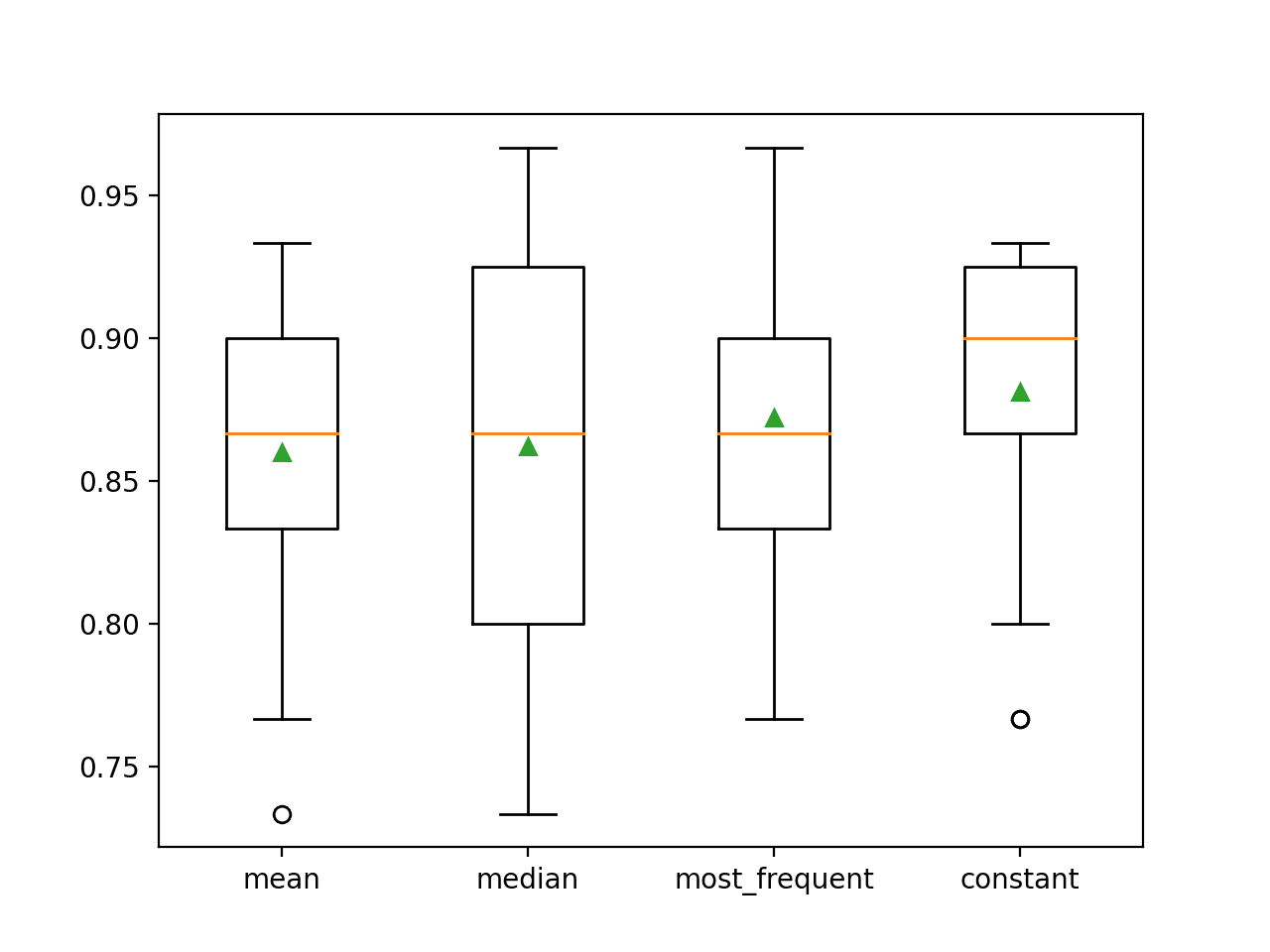
Box and Whisker Plot of Statistical Imputation Strategies Applied to the Horse Colic Dataset
SimpleImputer Transform When Making a Prediction
Możemy chcieć utworzyć ostateczny potok modelowania ze strategią stałej imputacji i algorytmem random forest, a następnie dokonać predykcji dla nowych danych.
Można to osiągnąć poprzez zdefiniowanie potoku i dopasowanie go do wszystkich dostępnych danych, a następnie wywołanie funkcji predict() przekazując nowe dane jako argument.
Ważne jest, że wiersz nowych danych musi oznaczać wszelkie brakujące wartości przy użyciu wartości NaN.
|
1
2
3
|
…
# define new data
row =
|
Pełny przykład znajduje się poniżej.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# stała imputacja strategy and prediction for the hose colic dataset
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# create the modeling pipeline
pipeline = Pipeline(steps=)
# fit the model
pipeline.fit(X, y)
# define new data
row =
# make a prediction
yhat = pipeline.predict()
# podsumuj predykcję
print(’Predicted Class: %d’ % yhat)
|
Running the example fits the modeling pipeline on all available data.
Nowy rząd danych jest definiowany z brakującymi wartościami oznaczonymi jako NaNs i dokonywana jest predykcja klasyfikacji.
|
1
|
Przewidywana klasa: 2
|
Dalsza lektura
Ta sekcja zapewnia więcej zasobów na ten temat, jeśli szukasz pogłębienia.
Related Tutorials
- Results for Standard Classification and Regression Machine Learning Datasets
- How to Handle Missing Data with Python
Książki
- Bad Data Handbook, 2012.
- Data Mining: Practical Machine Learning Tools and Techniques, 2016.
- Applied Predictive Modeling, 2013.
APIs
- Imputation of missing values, scikit-learn Documentation.
- API sklearn.impute.SimpleImputer.
Dataset
- Horse Colic Dataset
- Horse Colic Dataset Opis
Podsumowanie
W tym samouczku dowiedziałeś się jak używać strategii imputacji statystycznej dla brakujących danych w uczeniu maszynowym.
W szczególności, dowiedziałeś się:
- Brakujące wartości muszą być oznaczone wartościami NaN i mogą być zastąpione miarami statystycznymi w celu obliczenia kolumny wartości.
- Jak załadować wartość CSV z brakującymi wartościami i oznaczyć brakujące wartości wartościami NaN i zgłosić liczbę i procent brakujących wartości dla każdej kolumny.
- Jak imputować brakujące wartości za pomocą statystyki jako metody przygotowania danych podczas oceny modeli i podczas dopasowywania ostatecznego modelu w celu dokonania przewidywań na nowych danych.
Czy masz jakieś pytania?
Zadawaj pytania w komentarzach poniżej, a ja postaram się odpowiedzieć.
Get a Handle on Modern Data Preparation!

Prepare Your Machine Learning Data in Minutes
….z zaledwie kilkoma liniami kodu Pythona
Odkryj jak w moim nowym Ebooku:
Przygotowanie Danych do Uczenia Maszynowego
Zawiera on samouczki z pełnym działającym kodem na temat:
Wyboru Funkcji, RFE, Czyszczenia Danych, Transformacji Danych, Skalowania, Redukcji Wymiarów i wiele więcej…
Bring Modern Data Preparation Techniques to
Your Machine Learning Projects
See What’s Inside
.