Reinforcement Learning(RL) jest jednym z najgorętszych tematów badawczych w dziedzinie nowoczesnej sztucznej inteligencji, a jego popularność tylko rośnie. Przyjrzyjmy się 5 przydatnym rzeczom, które trzeba wiedzieć, aby rozpocząć pracę z RL.
Reinforcement Learning(RL) to rodzaj techniki uczenia maszynowego, która umożliwia agentowi uczenie się w interaktywnym środowisku metodą prób i błędów, wykorzystując informacje zwrotne z jego własnych działań i doświadczeń.
Chociaż zarówno uczenie nadzorowane, jak i wzmacniające wykorzystuje mapowanie między danymi wejściowymi i wyjściowymi, w przeciwieństwie do uczenia nadzorowanego, w którym informacja zwrotna dostarczana agentowi jest prawidłowym zestawem czynności do wykonania zadania, uczenie wzmacniające wykorzystuje nagrody i kary jako sygnały dla pozytywnych i negatywnych zachowań.
W porównaniu z uczeniem nienadzorowanym, uczenie wzmacniające różni się pod względem celów. Podczas gdy celem w uczeniu bez nadzoru jest znalezienie podobieństw i różnic między punktami danych, w przypadku uczenia wzmacniającego celem jest znalezienie odpowiedniego modelu działania, który maksymalizowałby całkowitą skumulowaną nagrodę agenta. Poniższy rysunek ilustruje pętlę sprzężenia zwrotnego akcja-nagroda w generycznym modelu RL.

Jak sformułować podstawowy problem Reinforcement Learning?
Kilka kluczowych pojęć, które opisują podstawowe elementy problemu RL to:
- Środowisko – Świat fizyczny, w którym działa agent
- Stan – Aktualna sytuacja agenta
- Nagroda – Informacja zwrotna od środowiska
- Polityka – Metoda mapowania stanu agenta na akcje
- Wartość – Przyszła nagroda, którą agent otrzymałby podejmując akcję w danym stanie
Problem RL można najlepiej wyjaśnić za pomocą gier. Weźmy grę PacMan, w której celem agenta (PacMan) jest zjedzenie jedzenia w siatce, unikając jednocześnie duchów na swojej drodze. W tym przypadku, świat siatki jest interaktywnym środowiskiem dla agenta, w którym działa. Agent otrzymuje nagrodę za zjedzenie jedzenia i karę, jeśli zostanie zabity przez ducha (przegrywa grę). Stany są lokalizacją agenta w świecie siatki, a całkowita skumulowana nagroda to wygrana agenta w grze.

W celu zbudowania optymalnej polityki, agent staje przed dylematem eksploracji nowych stanów przy jednoczesnej maksymalizacji swojej całkowitej nagrody. Nazywa się to kompromisem Eksploracja vs Eksploatacja. Aby zrównoważyć oba te czynniki, najlepsza ogólna strategia może wymagać krótkoterminowych poświęceń. Dlatego agent powinien zebrać wystarczająco dużo informacji, aby podjąć najlepszą decyzję w przyszłości.
Markow Decision Processes(MDPs) są matematycznymi ramami do opisu środowiska w RL i prawie wszystkie problemy RL mogą być sformułowane przy użyciu MDPs. MDP składa się ze zbioru skończonych stanów środowiska S, zbioru możliwych działań A(s) w każdym stanie, funkcji nagrody o rzeczywistej wartości R(s) i modelu przejścia P(s’, s | a). Jednakże, w rzeczywistych środowiskach jest bardziej prawdopodobne, że nie ma żadnej wcześniejszej wiedzy o dynamice środowiska. W takich przypadkach przydają się wolne od modelu metody RL.
Q-learning jest powszechnie stosowanym wolnym od modelu podejściem, które może być użyte do budowy samogrającego agenta PacMan. Obraca się ono wokół pojęcia aktualizacji wartości Q, które oznaczają wartość wykonania akcji a w stanie s. Poniższa reguła aktualizacji wartości stanowi rdzeń algorytmu uczenia Q.

Tutaj znajduje się demonstracja wideo agenta PacMan wykorzystująca głębokie uczenie wzmacniające.
Jakie są niektóre z najczęściej używanych algorytmów Reinforcement Learning?
Q-learning i SARSA (State-Action-Reward-State-Action) to dwa powszechnie używane bezmodelowe algorytmy RL. Różnią się one pod względem strategii eksploracji, podczas gdy ich strategie eksploatacji są podobne. Podczas gdy Q-learning jest metodą off-policy, w której agent uczy się wartości na podstawie akcji a* pochodzącej z innej polityki, SARSA jest metodą on-policy, w której agent uczy się wartości na podstawie swojej bieżącej akcji a pochodzącej z bieżącej polityki. Te dwie metody są proste do wdrożenia, ale brakuje im ogólności, ponieważ nie mają możliwości oszacowania wartości dla niewidzianych stanów.
To może być pokonane przez bardziej zaawansowane algorytmy, takie jak Deep Q-Networks(DQNs), które wykorzystują sieci neuronowe do oszacowania wartości Q. Jednak DQN mogą obsługiwać tylko dyskretne, niskowymiarowe przestrzenie działań.
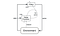
Deep Deterministic Policy Gradient(DDPG) jest bezmodelowym, bezpolitycznym, krytycznym wobec aktora algorytmem, który rozwiązuje ten problem poprzez uczenie się polityk w wielowymiarowych, ciągłych przestrzeniach działań. Poniższy rysunek przedstawia architekturę actor-critic.
Jakie są praktyczne zastosowania Reinforcement Learning?
Ponieważ RL wymaga dużej ilości danych, dlatego ma największe zastosowanie w dziedzinach, w których symulowane dane są łatwo dostępne, takich jak gry, robotyka.
- RL jest dość szeroko stosowane w budowaniu AI do gier komputerowych. AlphaGo Zero jest pierwszym programem komputerowym, który pokonał mistrza świata w starożytnej chińskiej grze Go. Inne to gry na ATARI, Backgammon itp
- W robotyce i automatyce przemysłowej, RL jest wykorzystywany do umożliwienia robotowi stworzenia dla siebie wydajnego adaptacyjnego systemu sterowania, który uczy się na podstawie własnych doświadczeń i zachowań. Praca DeepMind nad Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Policy updates jest dobrym przykładem tego samego. Obejrzyj ten interesujący film demonstracyjny.
Inne zastosowania RL obejmują abstrakcyjne silniki streszczania tekstu, agentów dialogowych (tekst, mowa), które mogą uczyć się od interakcji z użytkownikiem i poprawiać się z czasem, uczenie się optymalnych polityk leczenia w opiece zdrowotnej i agentów opartych na RL do handlu akcjami online.
Jak mogę zacząć z Reinforcement Learning?
Dla zrozumienia podstawowych pojęć RL, można odnieść się do następujących zasobów.
- Reinforcement Learning-An Introduction, książka autorstwa ojca Reinforcement Learning- Richard Sutton i jego doktorant Andrew Barto. Wersja robocza online książki jest dostępna tutaj.
- Materiały dydaktyczne Davida Silvera, w tym wykłady wideo, to świetny kurs wprowadzający do RL.
- Inny techniczny tutorial na temat RL autorstwa Pietera Abbeela i Johna Schulmana (Open AI/ Berkeley AI Research Lab).
Dla rozpoczęcia budowania i testowania agentów RL, pomocne mogą być następujące zasoby.
- Ten blog o tym, jak wytrenować agenta sieci neuronowej ATARI Pong z Policy Gradients z surowych pikseli autorstwa Andreja Karpathy’ego, pomoże Ci uruchomić pierwszego agenta Deep Reinforcement Learning w zaledwie 130 liniach kodu Pythona.
- DeepMind Lab to opensource’owa platforma 3D przypominająca grę stworzona do badań AI opartych na agentach z bogatymi symulowanymi środowiskami.
- Project Malmo to kolejna platforma do eksperymentów AI wspierająca badania podstawowe w AI.
- OpenAI gym to zestaw narzędzi do budowania i porównywania algorytmów uczenia się wzmocnień.