Istnieje wiele wspaniałych zalet, które są oferowane przez wirtualizację infrastruktury i uruchomienie wirtualnych zasobów do obsługi krytycznych obciążeń biznesowych. W przypadku VMware vSphere, zapewnia on wiele godnych uwagi funkcji i możliwości, które zapewniają wysoką dostępność w środowisku, jak również zautomatyzowane planowanie obciążenia, aby zapewnić najbardziej efektywne wykorzystanie sprzętu i zasobów w środowisku vSphere.
W tym poście, będziemy mówić o dwóch podstawowych funkcji na poziomie klastra vSphere w przedsiębiorstwie – vSphere HA i DRS. Najprawdopodobniej spotkałeś się z odniesieniami do obu tych funkcji przy okazji uruchamiania vSphere w przedsiębiorstwie.
Co to jest vSphere HA i DRS? Do czego służą?
Jakie korzyści można odnieść, uruchamiając oba w swoim środowisku vSphere?
Przyjrzyjrzyjmy się podstawowemu wprowadzeniu do HA i DRS w VMware vSphere i zobaczmy, jak je porównać i jakie korzyści płyną z ich użycia.
VMware vSphere Clusters
Jedną z oczywistych zalet i najlepszych praktyk przy wykorzystaniu VMware vSphere do uruchomienia krytycznych obciążeń biznesowych jest uruchomienie klastra vSphere Cluster.
Co to jest klaster vSphere?
Klaster vSphere to konfiguracja więcej niż jednego serwera VMware ESXi połączonego razem jako pula zasobów wniesionych do klastra vSphere. Zasoby takie jak procesor, pamięć, a w przypadku pamięci masowej definiowanej programowo, takiej jak vSAN, pamięć masowa, są wnoszone przez każdego hosta ESXi.
Dlaczego uruchamianie krytycznych obciążeń biznesowych na szczycie klastra vSphere jest ważne?
Kiedy myślisz o korzyściach płynących z uruchomienia hiperwizora, pozwala on na uruchomienie więcej niż jednego serwera na jednym zestawie sprzętu fizycznego. Wirtualizacja obciążeń w ten sposób zapewnia wiele korzyści wydajności w rzędach wielkości w porównaniu do uruchamiania pojedynczego serwera na pojedynczym zestawie sprzętu fizycznego.
Jednakże może to również stać się piętą achillesową zwirtualizowanego rozwiązania, ponieważ wpływ awarii sprzętu może mieć wpływ na wiele innych usług i aplikacji krytycznych dla biznesu. Można sobie wyobrazić, że jeśli masz tylko jednego hosta VMware ESXi z wieloma maszynami wirtualnymi, wpływ utraty tego pojedynczego hosta ESXi byłby ogromny.
To jest miejsce, gdzie uruchomienie wielu hostów VMware ESXi w klastrze vSphere naprawdę błyszczy.
Jednakże, możesz zadać sobie pytanie, jak po prostu uruchomienie wielu hostów w klastrze zwiększa Twoją wysoką dostępność? W jaki sposób host w klastrze vSphere „wie”, że inny host zawiódł? Czy istnieje jakiś specjalny mechanizm, który jest wykorzystywany do zarządzania wysoką dostępnością obciążeń uruchomionych na klastrze vSphere? Tak, istnieje. Zobaczmy.
Czym jest HA w VMware?
VMware zdało sobie sprawę z potrzeby posiadania mechanizmu, który byłby w stanie zapewnić ochronę przed uszkodzonym hostem ESXi w klastrze vSphere. Z tą potrzebą narodziła się VMware High-Availability (HA).
VMware vSphere HA zapewnia następujące korzyści:
VMware vSphere HA jest efektywny kosztowo i umożliwia automatyczne ponowne uruchamianie maszyn wirtualnych i hostów vSphere w przypadku awarii serwera lub systemu operacyjnego wykrytego w środowisku vSphere
Monitoruje wszystkie hosty VMware vSphere &maszyny wirtualne w klastrze vSphere
Zapewnia wysoką dostępność większości aplikacji działających w maszynach wirtualnych niezależnie od systemu operacyjnego i aplikacji.
Piękno rozwiązania VMware’s vSphere HA, które jest wdrażane poprzez VMware Cluster, polega na prostocie, z jaką można je skonfigurować. Wystarczy kilka kliknięć w interfejsie opartym na kreatorach, aby skonfigurować wysoką dostępność. Jak to się ma do tradycyjnych technologii „klastrowania”?
Windows Server Failover Clustering Comparison
Windows Server Failover Clustering (WSFC) stał się technologią klastrowania, o której większość myśli, gdy ma na myśli technologię klastrowania. Problem z WSFC polega na tym, że do poprawnego działania usług WSFC potrzebna jest duża wiedza specjalistyczna, zwłaszcza jeśli chodzi o aktualizacje, poprawki i ogólne zadania operacyjne.
Kontrastując vSphere HA z WSFC, narzut operacyjny jest minimalny w porównaniu z WSFC. Istnieje niewielka szansa, że HA może być skonfigurowany niepoprawnie, ponieważ jest on albo włączony na klastrze, albo nie. W przypadku WSFC istnieje wiele czynników, które należy wziąć pod uwagę podczas konfiguracji WSFC, aby uniknąć błędów zarówno w konfiguracji jak i implementacji. Pomyśl o następujących kwestiach:
- Klastrowanie awaryjne wymaga aplikacji obsługujących klastrowanie (SQL, itp.)
- Klastrowanie awaryjne wymaga prawidłowego skonfigurowania quorum
- Nie jest obsługiwane przez wiele starszych systemów operacyjnych i aplikacji
- Wymaga złożoności nazw sieci klastra, zasobów i sieci
Windows Server Failover Clustering jest reklamowany jako zapewniający niemal zerowy czas przestoju na poziomie aplikacji. Jednak gdy dodamy do tego wiedzę wymaganą do prawidłowego funkcjonowania rozwiązania HA, wraz z właściwym wdrożeniem WSFC, ryzyko może zacząć przewyższać korzyści płynące z wykorzystania WSFC do zapewnienia wysokiej dostępności aplikacji i usług. Jest to szczególnie prawdziwe w przypadku większości organizacji, które mogą nie potrzebować rozwiązania „zero przestojów”. Ponadto aplikacja musi być zaprojektowana tak, aby wykorzystać WSFC i prawidłowo współpracować z technologią WSFC.
Chociaż vSphere HA wymaga ponownego uruchomienia maszyn wirtualnych na zdrowym hoście w przypadku awarii, nie wymaga instalacji dodatkowego oprogramowania wewnątrz maszyn wirtualnych gości, nie wymaga złożonych konfiguracji dodatkowych technologii klastrowania, a aplikacje lub systemy operacyjne nie muszą być zaprojektowane do pracy z określoną technologią klastrowania.
Legendarne systemy operacyjne i aplikacje generalnie mają ograniczone możliwości, jeśli chodzi o obsługiwane technologie zapewniające wysoką dostępność. Tak więc, dosłownie może nie być żadnych natywnych opcji, aby zapewnić funkcjonalność failover w przypadku awarii sprzętu.
Mechanizm wysokiej dostępności vSphere HA działa i jest prosty do wdrożenia, skonfigurowania i zarządzania. Dodatkowo, jest to technologia, która została dobrze przetestowana w tysiącach środowisk klientów VMware, dzięki czemu ma stabilną i długą historię udanych wdrożeń.
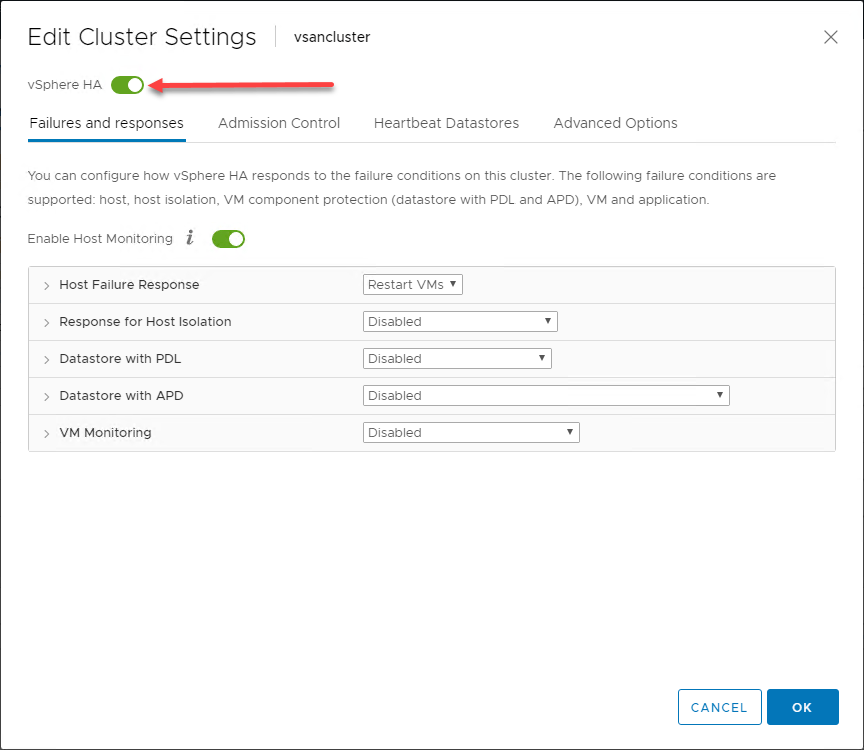
Ogólny przegląd zachowania vSphere HA
Wykorzystując korzyści zapewniane hostom ESXi w klastrze vSphere, w swojej najbardziej podstawowej formie, vSphere HA implementuje mechanizm monitorowania pomiędzy hostami w klastrze vSphere. Mechanizm monitorowania zapewnia sposób na określenie, czy któryś z hostów w klastrze vSphere uległ awarii.
Na poniższej infografice widać, że w klastrze vSphere z dwoma węzłami nastąpiła awaria jednego z hostów ESXi w klastrze vSphere. Klaster vSphere ma włączoną funkcję vSphere HA na poziomie klastra.
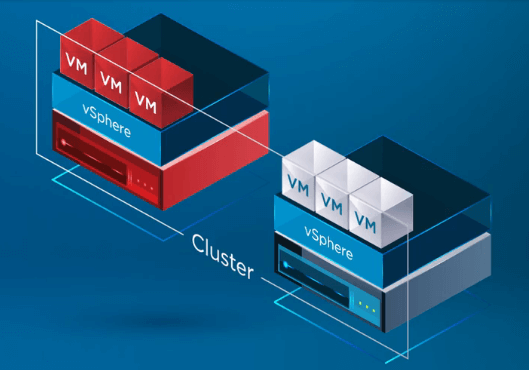
Po tym jak vSphere HA rozpozna, że host w klastrze vSphere uległ awarii, proces HA przenosi rejestrację maszyn wirtualnych z uszkodzonego hosta na zdrowego hosta.
Po zarejestrowaniu maszyn wirtualnych na zdrowym hoście, vSphere HA uruchamia ponownie wszystkie maszyny wirtualne z uszkodzonego hosta na zdrowym hoście ESXi w klastrze, w którym maszyny wirtualne zostały ponownie zarejestrowane. Jedyny przestój związany jest z ponownym uruchomieniem maszyn wirtualnych na zdrowym hoście w klastrze vSphere.
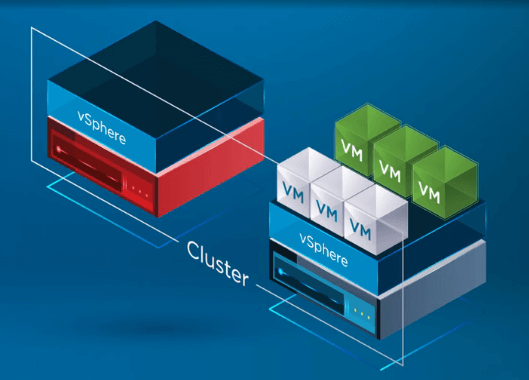
VSphere HA Technical Overview
Prerequisites for vSphere HA
Można się zastanawiać, jakie podstawowe warunki wstępne mogą być wymagane, aby vSphere HA działało. Czy po prostu potrzebujesz klastra VMware, aby włączyć HA? W przeciwieństwie do Windows Server Failover Clustering, istnieje tylko kilka wymagań, które muszą być spełnione, aby HA działał.
Wymagania:
- Co najmniej dwa hosty ESXi
- Co najmniej 4 GB pamięci skonfigurowane na każdym hoście
- vCenter Server
- vSphere Standard License
- Współdzielona pamięć masowa dla maszyn wirtualnych
- Pingowalna brama lub inny niezawodny węzeł sieci
Jeśli zauważysz, że, nie jest wymagany komponent quorum, nie ma złożonego nazewnictwa sieciowego i nie ma innych specjalnych zasobów klastra, które muszą być na miejscu.
Czytaj dalej: How to configure a vSphere High Availability Cluster
VMware vSphere HA Master vs Subordinate Hosts
Gdy włączysz vSphere HA na klastrze, określony host w klastrze vSphere jest wyznaczony jako master vSphere HA. Pozostałe hosty ESXi w klastrze vSphere są skonfigurowane jako podrzędne w konfiguracji vSphere HA.
Jaką rolę pełni host ESXi vSphere HA, który jest wyznaczony jako master? Węzeł główny vSphere HA:
- Monitoruje stan hostów podrzędnych slave – Jeśli host podrzędny ulegnie awarii lub jest nieosiągalny, host główny identyfikuje, które maszyny wirtualne wymagają ponownego uruchomienia
- Monitoruje stan zasilania wszystkich maszyn wirtualnych, które są chronione. Jeśli maszyna wirtualna ulegnie awarii, główny węzeł vSphere HA zapewnia ponowne uruchomienie tej maszyny. Główny węzeł vSphere HA decyduje, gdzie następuje ponowne uruchomienie maszyny wirtualnej (który host ESXi).
- Śledzi wszystkie hosty klastra i maszyny wirtualne chronione przez vSphere HA
- Jest wyznaczony jako mediator pomiędzy klastrem vSphere a serwerem vCenter Server. HA master raportuje stan klastra do vCenter i zapewnia interfejs zarządzania klastrem dla vCenter Server
- Może samodzielnie uruchamiać maszyny wirtualne i monitorować ich stan
- Utrzymuje chronione maszyny wirtualne w magazynach danych klastra
vSphere HA Subordinate Hosts:
- Run virtual machines locally
- Monitoruje stany runtime maszyn wirtualnych w klastrze vSphere
- Reportuje aktualizacje stanu do hosta głównego vSphere HA
Master Host Election and Master Failure
Jak wybierany jest host główny vSphere HA? Kiedy vSphere HA jest włączony dla klastra, wszystkie aktywne hosty (bez trybu konserwacji itp.) biorą udział w wyborze hosta głównego. Jeśli wybrany host główny zawiedzie, odbywają się nowe wybory, w których nowy host główny HA jest wybierany do pełnienia tej roli.
Typy awarii klastra VMware vSphere HA
W klastrze z włączoną funkcją vSphere HA istnieją trzy typy awarii, które mogą wywołać zdarzenie przełączenia awaryjnego vSphere HA. Te typy awarii hostów to:
- Awaria – Awaria jest intuicyjnie tym, co myślisz. Host przestał działać w jakiejś formie lub sposób z powodu sprzętu lub innych problemów.
- Izolacja – Izolacja hosta zazwyczaj dzieje się z powodu zdarzenia sieciowego, które izoluje konkretnego hosta od innych hostów w klastrze vSphere HA.
- Podział – Zdarzenie podziału charakteryzuje się tym, że podrzędny host traci łączność sieciową z hostem głównym klastra vSphere HA.
Heartbeating, Failure Detection, and Failure Actions
Jak węzeł główny określa, czy nastąpiła awaria danego hosta?
Istnieje kilka różnych mechanizmów używanych przez węzeł nadrzędny do określenia, czy host uległ awarii:
- Węzeł nadrzędny co sekundę wymienia heartbeaty sieciowe z innymi hostami w klastrze.
- Po nieudanej wymianie heartbeatów sieciowych host nadrzędny sprawdza, czy host podrzędny wymienia heartbeaty z jednym z magazynów danych. Następnie wysyła pingi ICMP do jego adresów IP zarządzania
- Jeśli bezpośrednia komunikacja z agentem HA hosta podrzędnego z hosta głównego nie jest możliwa, a pingi ICMP do adresu zarządzania nie powiodą się, host jest postrzegany jako uszkodzony, a maszyny wirtualne są ponownie uruchamiane na innym hoście.
- Jeśli okaże się, że host podrzędny wymienia bity serca z magazynem danych, host główny zakłada, że host znajduje się w partycji sieciowej lub jest odizolowany od sieci. W takim przypadku host główny po prostu monitoruje hosta i maszyny wirtualne
- Izolacja sieci to zdarzenie, w którym host podrzędny działa, ale nie może być już widziany z perspektywy agenta zarządzania HA w sieci zarządzania. Jeśli host przestaje widzieć ten ruch, próbuje pingować adresy izolacji klastra. Jeśli ten ping się nie powiedzie, host deklaruje, że jest odizolowany od sieci
- W tym przypadku węzeł główny monitoruje maszyny wirtualne, które są uruchomione na odizolowanym hoście. Jeśli maszyny wirtualne wyłączą się na izolowanym hoście, węzeł główny ponownie uruchamia maszyny wirtualne na innym hoście
Datastore Heartbeating
Jak wspomniano powyżej, jedną z metryk używanych do określenia wykrywania awarii jest datastore heartbeating. Co to dokładnie jest? VMware vCenter wybiera preferowany zestaw magazynów danych, które mają być objęte funkcją heartbeating. Następnie vSphere HA tworzy katalog w korzeniu każdego magazynu danych, który jest wykorzystywany zarówno do datastore heartbeating jak i do przechowywania listy chronionych maszyn wirtualnych. Katalog ten nosi nazwę .vSphere-HA.
Jest ważna uwaga dotycząca magazynów danych vSAN, o której należy pamiętać. Magazyn danych vSAN nie może być użyty do datastore heartbeating. Jeśli dostępny jest tylko jeden magazyn danych vSAN, nie można używać żadnych magazynów danych heartbeat.
- Monitorowanie maszyn wirtualnych i aplikacji
Kolejną niezwykle wydajną funkcją vSphere HA jest możliwość monitorowania poszczególnych maszyn wirtualnych za pomocą narzędzi VMware Tools i restartowania wszystkich maszyn wirtualnych, które nie reagują na bicie serca VMware Tools. Application Monitoring może zrestartować maszynę wirtualną, jeśli bity serca dla aplikacji, która jest uruchomiona nie są odbierane.
- VM Monitoring – W przypadku VM Monitoring, usługa VM Monitoring wykorzystuje VMware Tools do określenia, czy każda maszyna wirtualna jest uruchomiona poprzez sprawdzenie zarówno heartbeats jak i disk I/O generowanych przez VMware Tools. W przypadku niepowodzenia tych kontroli usługa VM Monitoring określa, że najprawdopodobniej doszło do awarii systemu operacyjnego gościa i maszyna wirtualna jest ponownie uruchamiana. Dodatkowa kontrola operacji wejścia/wyjścia dysku pomaga uniknąć niepotrzebnego resetowania maszyny wirtualnej, jeśli maszyny wirtualne lub aplikacje nadal działają prawidłowo.
Monitorowanie aplikacji – Funkcja monitorowania aplikacji jest włączana poprzez uzyskanie odpowiedniego zestawu SDK od zewnętrznego producenta oprogramowania, który umożliwia skonfigurowanie niestandardowych rytmów serca dla aplikacji, które mają być monitorowane przez proces vSphere HA. Podobnie jak w przypadku procesu monitorowania maszyn wirtualnych, jeśli bicie serca aplikacji przestanie być odbierane, maszyna wirtualna zostanie zresetowana.
Obydwie te funkcje monitorowania mogą być dalej konfigurowane z czułością monitorowania, a także maksymalnym resetem per-VM, aby pomóc uniknąć wielokrotnego resetowania maszyn wirtualnych w przypadku błędów oprogramowania lub błędów fałszywie pozytywnych.
VMware vSphere HA to świetny sposób na zapewnienie, że klaster vSphere zapewnia bardzo odporną wysoką dostępność w celu ochrony przed ogólnymi awariami hostów ESXi w klastrze vSphere.
Co z zapewnieniem efektywnego wykorzystania zasobów w klastrze vSphere? Przyjrzyjmy się kolejnym przepisom dotyczącym klastra vSphere, które pomogą zapewnić efektywne wykorzystanie zasobów i pojemności klastra vSphere.
Czym jest DRS w VMware?
VMware Distributed Resource Scheduler (DRS) to naprawdę potężna funkcja podczas pracy z klastrami vSphere. Zapewnia on harmonogramowanie i równoważenie obciążenia w klastrze vSphere. VMware DRS jest funkcją znajdującą się w vSphere Clusters, która zapewnia, że maszyny wirtualne działające w środowisku vSphere są zaopatrzone w zasoby, których potrzebują do efektywnego i wydajnego działania.
Maszyny wirtualne są zazwyczaj poddawane działaniu DRS już na wczesnym etapie ich życia, ponieważ od pierwszego włączenia w klastrze z obsługą DRS, DRS umieszcza maszyny wirtualne na najlepszym hoście skonfigurowanym tak, aby zapewnić wymagane zasoby dla maszyny wirtualnej zaraz po jej włączeniu. Dodatkowo, DRS stara się utrzymać klastry vSphere w równowadze z perspektywy wykorzystania zasobów.
Nawet jeśli klaster vSphere jest zbalansowany w pewnym momencie, maszyny wirtualne mogą zostać przeniesione lub zmienić się w taki sposób, że nierównowaga zasobów klastra może ponownie wkradać się do środowiska. Kiedy klastry stają się niezbalansowane, może to być szkodliwe dla ogólnej wydajności maszyn wirtualnych działających w klastrze vSphere.
Domyślnie DRS uruchamia się automatycznie na klastrze vSphere co pięć minut, aby określić równowagę klastra vSphere i sprawdzić, czy należy wprowadzić jakiekolwiek zmiany w celu bardziej efektywnego wykorzystania zasobów.
VMware DRS Wymagania
Aby skorzystać z VMware DRS, należy spełnić kilka wymagań, które zapewnią wykorzystanie funkcjonalności Distributed Resource Scheduler. Należą do nich:
- Klaster hostów ESXi
- vCenter Server
- Licencja Enterprise Plus
- vMotion jest wymagana do automatycznego równoważenia obciążenia
Read More: How to Configure a vSphere DRS Cluster
VMware DRS Actions
Gdy VMware DRS uruchamia się na klastrze vSphere co pięć minut, określa, czy w klastrze istnieją jakiekolwiek nierównowagi. Jeśli tak, zostanie wykonane vMotion w celu przeniesienia wyznaczonych maszyn wirtualnych z jednego hosta ESXi do drugiego.
Jak dokładnie DRS określa, czy maszyny wirtualne są lepiej dostosowane do jednego lub drugiego hosta ESXi?
DRS uruchamia specjalny algorytm w celu określenia właściwego hosta ESXi, który powinien pomieścić konkretną maszynę wirtualną. Kiedy maszyna wirtualna jest włączana, algorytm ten bierze pod uwagę dystrybucję zasobów w klastrze vSphere, po czym zapewnia, że nie dojdzie do naruszenia ograniczeń, jeśli dana maszyna wirtualna zostanie umieszczona na konkretnym hoście ESXi.
Dodatkowo, zapotrzebowanie samej maszyny wirtualnej jest brane pod uwagę, dzięki czemu maszyna nigdy nie będzie głodna zasobów, gdy zostanie włączona. Co wchodzi w skład zapotrzebowania maszyny wirtualnej? Zapotrzebowanie maszyny wirtualnej obejmuje ilość zasobów potrzebnych do jej działania.
- W przypadku zapotrzebowania na procesor, jest ono obliczane na podstawie ilości procesora, jaką VM aktualnie zużywa
- W przypadku pamięci, zapotrzebowanie jest obliczane na podstawie wzoru: VM memory demand = Function(Active memory used, Swapped, Shared) + 25% (idle consumed memory). Pokazuje to, że bilans pamięci DRS opiera się głównie na aktywnym wykorzystaniu pamięci przez maszynę wirtualną, przy jednoczesnym uwzględnieniu niewielkiej ilości jej pamięci zużytej w stanie spoczynku jako bufor na wypadek wzrostu obciążenia.
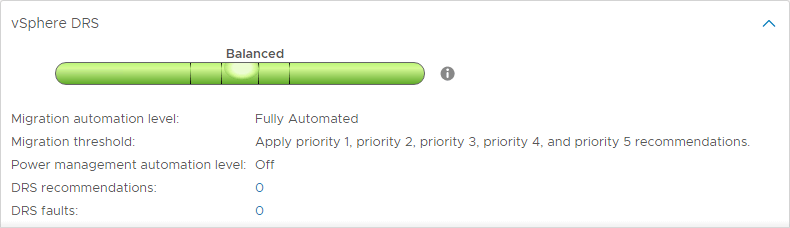
Poziomy automatyzacji DRS
Jedną z interesujących cech DRS są poziomy automatyzacji DRS. Podczas gdy DRS kontynuuje skanowanie klastra vSphere i dostarcza rekomendacje co 5 minut, można określić, czy DRS jest w stanie wykonać swoje rekomendacje automatycznie, czy tylko sugerować zmiany, które powinny być wykonane. DRS ma trzy poziomy automatyzacji DRS. Należą do nich:
- W pełni zautomatyzowany – W podejściu w pełni zautomatyzowanym DRS stosuje automatycznie zarówno zalecenia dotyczące początkowego rozmieszczenia, jak i równoważenia obciążenia
- Częściowo zautomatyzowany – Przy częściowej automatyzacji DRS stosuje zalecenia tylko dla początkowego rozmieszczenia maszyn wirtualnych
- Ręczny – W trybie ręcznym, musisz zastosować zalecenia zarówno dla początkowego rozmieszczenia, jak i dla zaleceń równoważenia obciążenia
DRS Migration Thresholds
DRS zawiera kolejne bardzo przydatne ustawienie do kontrolowania wielkości nierównowagi, która będzie tolerowana przed wydaniem zaleceń DRS. Istnieje pięć progów migracji DRS pozwalających kontrolować tolerowaną wielkość niezbilansowania.
Zakres wynosi od 1 (najbardziej konserwatywny) do 5 (najbardziej agresywny).
Przy bardziej agresywnych ustawieniach DRS toleruje mniejszą nierównowagę w klastrze. Im bardziej konserwatywne, tym bardziej DRS toleruje nierównowagę.

Reguły VM/Host VM/Host Rules
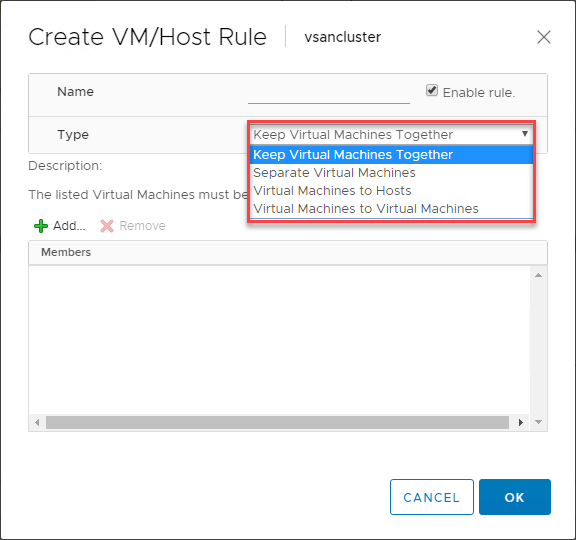
Korzystanie z VMware DRS w celu kontroli rozmieszczenia maszyn wirtualnych w klastrach z obsługą vSphere DRS jest niezwykle użyteczną funkcją. Reguły VM/Host Rules pozwalają na uruchamianie określonych maszyn wirtualnych na określonych hostach ESXi. Można to w pewnym sensie traktować jako reguły pokrewieństwa.
Reguły VM/Host pozwalają na:
- Utrzymanie maszyn wirtualnych razem
- Oddzielenie maszyn wirtualnych
- Przywiązanie maszyn wirtualnych do określonych hostów
- Przywiązanie maszyn wirtualnych do maszyn wirtualnych
Poniżej przedstawiono przykład tworzenia reguły VM/Host dla maszyn wirtualnych i hostów ESXi.
Jaki typ przypadku użycia istnieje dla tych reguł VM/Host? Jednym z klasycznych przypadków użycia jest kontroler domeny. Ogólnie rzecz biorąc, jeśli uruchamiasz wszystkie swoje kontrolery domeny w zwirtualizowanym środowisku, takim jak klaster vSphere, chcesz się upewnić, że masz swoje maszyny wirtualne kontrolerów domeny oddzielone od siebie wewnątrz klastra. W ten sposób, jeśli host ESXi ulegnie awarii wraz z jednym z kontrolerów domeny, nadal masz kontroler domeny, który podlega regule Separate Virtual Machines, która utrzymuje go poza tym samym hostem, co inny DC.
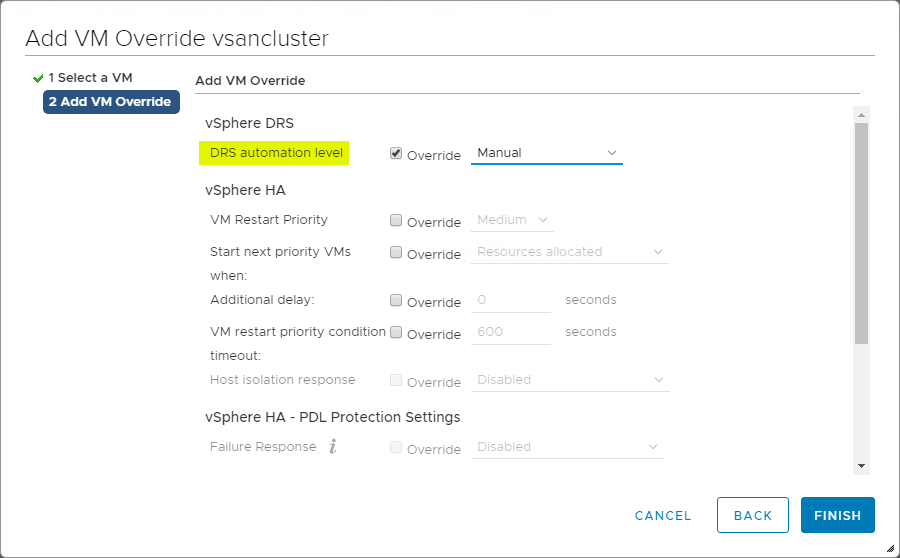
VM Overrides for DRS
Klaster vSphere zapewnia dużą granularność dla operacji wpływających na poszczególne maszyny wirtualne wewnątrz klastra vSphere. Można utworzyć nadpisania VM Overrides, aby zastąpić globalne ustawienia ustawione na poziomie klastra dla HA i DRS w celu zdefiniowania bardziej szczegółowych ustawień dla poszczególnych maszyn wirtualnych.
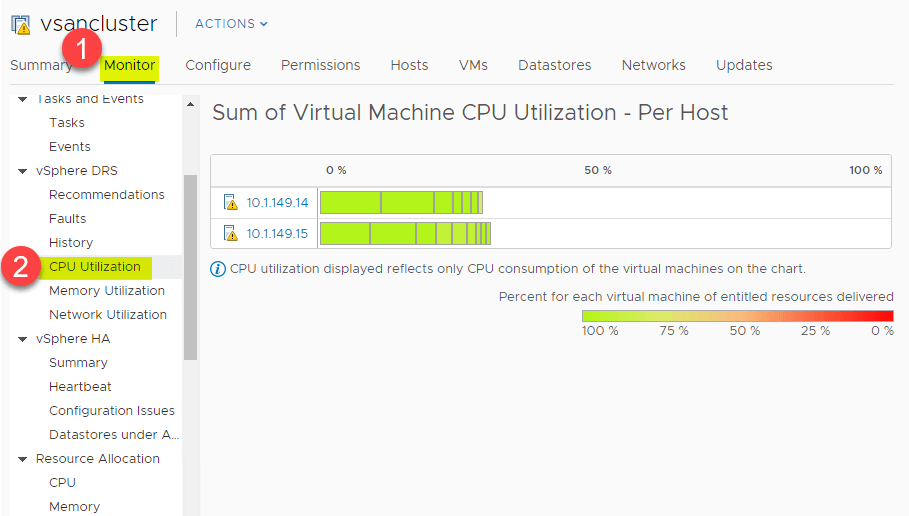
CPU and Memory Utilization Summary
DRS zapewnia doskonały widok wysokiego poziomu podsumowania wykorzystania zasobów CPU hostów ESXi w klastrze vSphere. Przejdź do > Settings > Monitor > vSphere DRS > CPU Utilization.
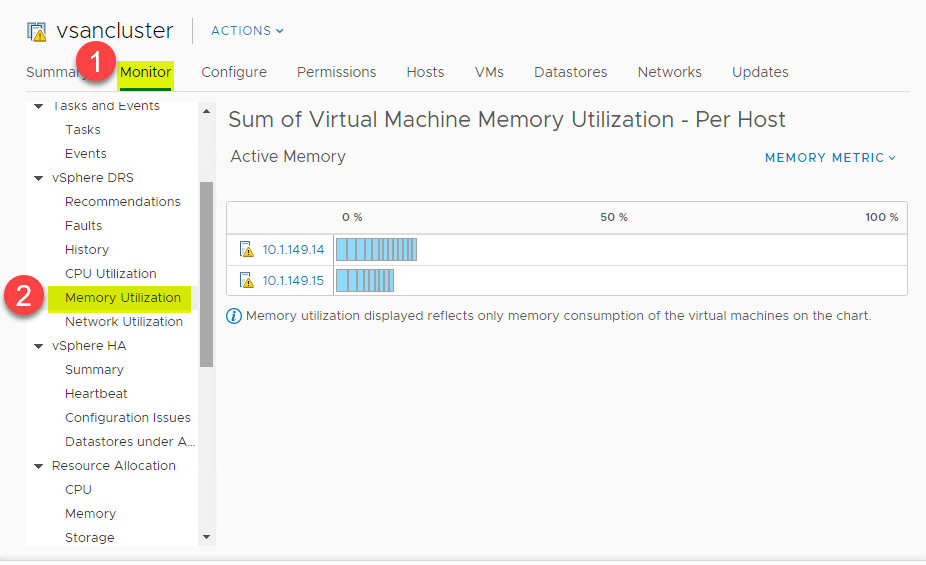
Ten sam wysokopoziomowy przegląd można wyświetlić również dla zużycia pamięci. Navigate to > Settings > Monitor > vSphere DRS > Memory Utilization
The Best of Both Worlds
Is VMware vSphere HA and VMware DRS competing technologies?
Nie, nie są. Wręcz przeciwnie, zaleca się stosowanie zarówno vSphere HA jak i VMware DRS razem, aby połączyć automatyczne przełączanie awaryjne z funkcjami równoważenia obciążenia. Rezultatem jest znacznie bardziej odporne i bardziej zrównoważone środowisko vSphere.
Jeśli wystąpi awaria hosta ESXi, vSphere HA zrestartuje maszyny wirtualne na pozostałych zdrowych hostach w klastrze vSphere. Tak więc, pierwszym priorytetem jest oczywiście dostępność zasobów maszyn wirtualnych. Następnie VMware DRS określi, czy istnieje jakakolwiek nierównowaga pomiędzy hostami ESXi pracującymi z obciążeniami i wyda zalecenia w celu rozwiązania problemu nierównowagi w klastrze w oparciu o skonfigurowany próg migracji. W zależności od poziomu automatyzacji, zalecenia te zostaną automatycznie wykonane lub tylko zalecone, jeśli nie są w pełni zautomatyzowane.
Final Thoughts on VMware vSphere HA and DRS
Running both VMware vSphere HA and DRS are highly recommended in a production vSphere Cluster. Wykorzystanie obu technologii pomaga uczynić obciążenia wysoce dostępnymi i zapewnia im stały dostęp do wymaganych zasobów w oparciu o wymagania CPU/pamięci maszyny wirtualnej.
Zrozumienie działania obu mechanizmów pomaga administratorowi vSphere wykorzystać obie technologie w najlepszy możliwy sposób i w zgodzie z najlepszymi praktykami. Wśród korzyści, jakie niosą ze sobą obie technologie, jest fakt, że każda z nich jest niezwykle łatwa do włączenia i skonfigurowania. Wystarczy kilka prostych kliknięć we właściwościach klastrów vSphere, aby szybko zacząć korzystać z tych dostępnych funkcji na poziomie klastra.
Śledź nasze kanały na Twitterze i Facebooku, aby uzyskać informacje o nowych wydaniach, aktualizacjach, wnikliwych postach i nie tylko.
.