By: Derek Colley | Updated: 2014-01-29 | Komentarze (5) | Powiązane: More > Functions – System
Problem
Chcesz pobrać losową próbkę ze zbioru wyników zapytania SQL Server. Być może szukasz reprezentatywnej próbki danych z dużej bazy danych klientów; być może szukasz średnich lub pomysłu na typ danych, które przechowujesz. SELECT TOP N nie zawsze jest idealnym rozwiązaniem, ponieważ dane odstające często pojawiają się na początku i końcu zbiorów danych, zwłaszcza gdy są uporządkowane alfabetycznie lub według jakiejś wartości skalarnej. Podobnie mogłeś użyć TABLESAMPLE, ale ma on ograniczenia, szczególnie w przypadku małych lub skośnych zestawów danych. Być może Twój szef poprosił Cię o losowy wybór 100 nazw i lokalizacji klientów lub bierzesz udział w audycie i musisz pobrać losową próbkę danych do analizy. Jak wykonałbyś to zadanie? Sprawdź ten poradnik, aby dowiedzieć się więcej.
Rozwiązanie
Ten poradnik pokaże Ci, jak używać TABLESAMPLE w T-SQL, aby pobrać pseudolosowe próbki danych, a także omówi wnętrze TABLESAMPLE i sytuacje, w których nie jest ono odpowiednie. Pokażemy również alternatywną metodę – metodę matematyczną wykorzystującą NEWID() w połączeniu z CHECKSUM i operatorem bitowym, na którą zwrócił uwagę Microsoft w artykule TABLESAMPLE TechNet. Porozmawiamy trochę o próbkowaniu statystycznym w ogóle (różnice pomiędzy losowym, systematycznym i warstwowym) z przykładami, i przyjrzymy się jak próbkowane są statystyki SQL jako przykład, i opcje, których możemy użyć, aby nadpisać to próbkowanie. Po przeczytaniu tej porady powinieneś docenić korzyści płynące z próbkowania w porównaniu z metodami takimi jak TOP N i wiedzieć, jak zastosować przynajmniej jedną metodę, aby to osiągnąć w SQL Server.
Setup
W tej poradzie będę używał zestawu danych zawierającego kolumnę tożsamości INT (aby ustalić stopień losowości podczas wybierania wierszy) i inne kolumny wypełnione pseudolosowymi danymi różnych typów danych, aby (niejasno) symulować prawdziwe dane w tabeli. Możesz użyć poniższego kodu T-SQL, aby to skonfigurować. Jego uruchomienie powinno zająć tylko kilka minut i jest on testowany na SQL Server 2012 Developer Edition.
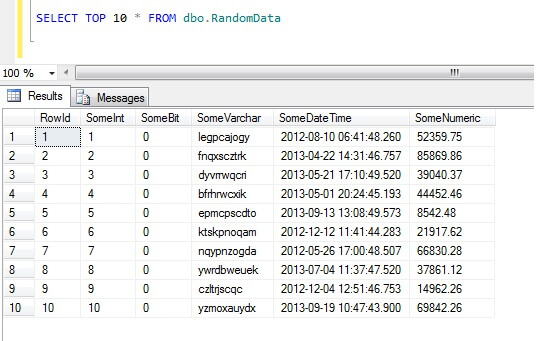
Wybranie 10 pierwszych wierszy danych daje taki wynik (tylko po to, aby dać Ci wyobrażenie o kształcie danych).Na marginesie, jest to ogólny fragment kodu, który stworzyłem, aby generować random-ishdata, kiedy tylko tego potrzebowałem – nie krępuj się go używać i rozszerzać/przeinaczać do woli!
How Not To Sample Data in SQL Server
Teraz mamy nasze próbki danych, zastanówmy się nad najgorszymi sposobami uzyskania próbki. W bazie danych AdventureWorks istnieje tabela o nazwie Person.Address. Pobierzmy próbkę z 10 najlepszych wyników, w nieszczególnej kolejności:
SELECT TOP 10 * FROM Person.Address
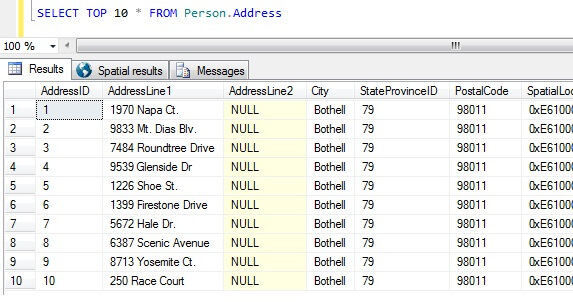
Już na podstawie samej próbki możemy zauważyć, że wszystkie zwrócone osoby mieszkają w Bothell i dzielą kod pocztowy 98011. Dzieje się tak, ponieważ wyniki zostały określone jako zwrócone bez określonej kolejności, ale w rzeczywistości zostały zwrócone w kolejności kolumny AddressID. Zauważ, że to NIE jest gwarantowane zachowanie dla danych sterty w szczególności – zobacz ten cytat z BOL:
„Zazwyczaj dane są początkowo przechowywane w kolejności, w której wiersze są wstawiane do tabeli, ale silnik bazy danych może przenosić dane na stercie, aby przechowywać wiersze wydajnie; więc kolejność danych nie może być przewidziana. Aby zagwarantować kolejność wierszy zwracanych ze sterty, musisz użyć klauzuli ORDER BY.”
http://technet.microsoft.com/en-us/library/hh213609.aspx
Pobierając ten zestaw wyników, osoba niezorientowana w naturze tabeli może dojść do wniosku, że wszyscy jej klienci mieszkają w Bothell.
Typy próbkowania danych w SQL Server
Powyższe jest wyraźnie fałszywe, więc potrzebujemy lepszego sposobu próbkowania. Co powiesz na pobieranie próbki w regularnych odstępach czasu w całej tabeli?
To powinno zwrócić 47 wierszy:
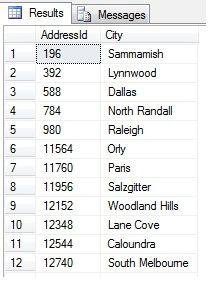
Jak dotąd, tak dobrze. Wzięliśmy wiersz w regularnych odstępach czasu w całym naszym zestawie danych i zwróciliśmy statystyczny przekrój – czy tak? Niekoniecznie. Nie zapominajmy, że kolejność nie jest gwarantowana. Możemy wyciągnąć jeden lub dwa wnioski na temat tych danych. Dla ilustracji zsumujmy je. Uruchom ponownie powyższy fragment kodu, ale zmień końcowy blok SELECT w taki sposób:
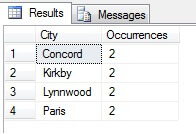
W moim przykładzie widać, że z całkowitej liczby ponad 19 000 wierszy w tabeli Person.Address, pobrałem próbki z około 1/4% wierszy i dlatego mogę stwierdzić, że (w moim przykładzie), Concord, Kirkby, Lynnwood i Paris mają największą liczbę mieszkańców, a ponadto są tak samo zaludnione. Dokładne? Nonsens, oczywiście:
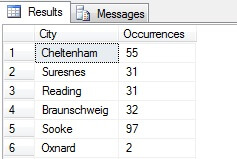
Jak widać, żadna z moich czterech nie była w rzeczywistości w pierwszej czwórce miejsc do życia, jak oceniono w tej tabeli. Nie tylko próbka danych była zbyt mała, ale ja zagregowałem tę maleńką próbkę i próbowałem wyciągnąć z niej wnioski. Oznacza to, że mój zestaw wyników jest statystycznie nieistotny -aversely, udowadnianie istotności statystycznej jest jednym z głównych obciążeń dowodowych przy prezentowaniu podsumowań statystycznych (lub powinno być) i głównym upadkiem wielu popularnych infografik i datagramów prowadzonych przez marketing.
Więc, próbkowanie w ten sposób (zwane próbkowaniem systematycznym) jest skuteczne, ale tylko dla statystycznie istotnej populacji. Istnieją czynniki, takie jak okresowość i proporcja, które mogą zrujnować próbkę – zobaczmy proporcję w akcji, biorąc próbkę 10 miast z tabeli Person.Address, używając następującego kodu, który pobiera odrębną listę miast z tabeli Person.Address, a następnie wybiera 10 miast z tej listy za pomocą systematycznego próbkowania:
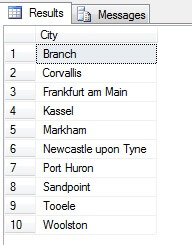
Wygląda jak dobra próbka, prawda? Teraz skontrastujmy to z próbką NIEODRÓŻNIONYCH miast wymienionych w porządku rosnącym, tj. co n-tego miasta, gdzie n jest całkowitą liczbą wierszy podzieloną przez 10. Ta miara bierze pod uwagę populację próbki:
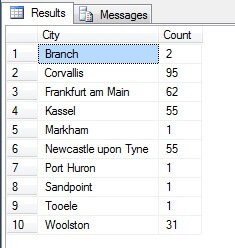
Zwrócone dane są zupełnie inne – nie przez przypadek, ale przez prezentację reprezentatywnej próbki. Zauważ, że ta lista, na której zawarłem liczebność każdego miasta w tabeli źródłowej, aby pokazać, jak bardzo populacja odgrywa rolę w wyborze danych, obejmuje cztery najbardziej zaludnione miasta w próbie, która (jeśli weźmiesz pod uwagę uporządkowaną listę non-distinct) jest najuczciwszą reprezentacją. Niekoniecznie jest to najlepsza reprezentacja dla twoich potrzeb, więc bądź ostrożny przy wyborze statystycznej metody próbkowania.
Inne metody próbkowania
Próbkowanie klastrów – jest to sytuacja, w której populacja, która ma być próbkowana jest podzielona na klastry lub podzbiory, a następnie każdy z tych podzbiorów jest losowo określony do włączenia lub nie do wyjściowego zestawu wyników. Jeśli są uwzględnione, to każdy członek tego podzbioru jest zwracany w zestawie wyników. Zobacz TABLESAMPLE poniżej dla przykładu tego.
Disproportional Sampling – to jest jak próbkowanie warstwowe, gdzie członkowie grup podzbiorów są wybierani w celu reprezentowania całej grupy, ale zamiast być w proporcji, mogą być różne liczby członków z każdej grupy wybranych w celu wyrównania reprezentacji z każdej grupy. Tzn. biorąc pod uwagę miasta w Person.Address w przykładzie z powyższej sekcji, pierwszy zestaw wyników był nieproporcjonalny, ponieważ nie brał pod uwagę populacji, ale drugi zestaw wyników był proporcjonalny, ponieważ reprezentował liczbę wpisów miast w tabeli Person.Address. Ten rodzaj próbkowania jest w rzeczywistości użyteczny, jeśli określona kategoria jest niedostatecznie reprezentowana w zbiorze danych, a proporcja nie jest ważna (na przykład 100 losowych klientów ze 100 losowych miast rozwarstwionych według miasta – miasta w podzbiorze wymagałyby normalizacji – można użyć próbkowania nieproporcjonalnego).
SQL Server Random Data with TABLESAMPLE
SQL Server posiada pomocną metodę próbkowania danych. Zobaczmy ją w akcji. Użyj poniższego kodu, aby zwrócić około 100 wierszy (jeśli zwróci 0 wierszy, uruchom ponownie – wyjaśnię to za chwilę) danych z dbo.RandomData, które zdefiniowaliśmy wcześniej.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
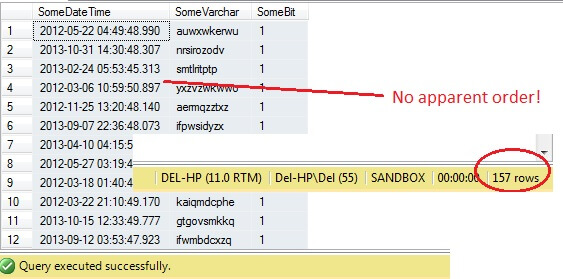
Jak dotąd, tak dobrze, prawda? Chwila – nie widzimy kolumny Id. Włączmy ją i uruchommy ponownie:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
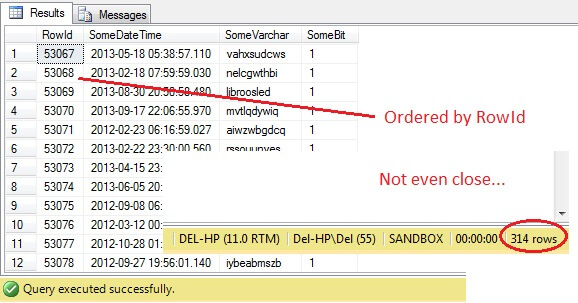
Ojejku – TABLESAMPLE wybrał wycinek danych, ale nie jest on przypadkowy – kolumna RowId pokazuje wyraźnie zaznaczony wycinek z wartością minimalną i maksymalną. Co więcej, nie zwrócił on również dokładnie 100 wierszy. Co się dzieje?
TABLESAMPLE używa implikowanego modyfikatora SYSTEM. Modyfikator ten, domyślnie włączony i zgodny ze specyfikacją ANSI-SQL, tzn. nie jest opcjonalny, bierze pod uwagę każdą stronę 8KB, na której znajduje się tabela i decyduje, czy uwzględnić wszystkie wiersze na tej stronie, które znajdują się w tej tabeli, w wyprodukowanej próbce, w oparciu o procent lub N ROWS przekazane. W związku z tym, tabela, która znajduje się na wielu stronach, tj. ma duże wiersze danych, powinna zwrócić bardziej zrandomizowaną próbkę, ponieważ będzie więcej stron w próbce. To zawodzi dla przykładu takiego jak nasz, gdzie dane są skalarne i małe i rezydują na kilku stronach – jeśli jakakolwiek liczba stron nie przejdzie do cięcia, może to znacznie zniekształcić próbkę wyjściową. To jest właśnie wada TABLESAMPLE – nie działa dobrze dla „małych” danych i nie bierze pod uwagę rozmieszczenia danych na stronach. Tak więc rozmieszczenie danych na stronach jest ostatecznie odpowiedzialne za próbkę zwracaną przez tę metodę.
Czy to brzmi znajomo? Jest to zasadniczo próbkowanie klastrowe, w którym wszyscy członkowie (wiersze) w wybranych grupach (klastrach) są reprezentowani w zestawie wyników.
Testujmy to na dużej tabeli, aby podkreślić punkt odwrotnej nieskalowalności. Najpierw zidentyfikujmy największą tabelę w bazie danych AdventureWorks. Użyjemy do tego standardowego raportu – używając SSMS, kliknij prawym przyciskiem myszy na bazę AdventureWorks2012, przejdź do Raporty ->Raporty standardowe ->Użycie dysku przez największe tabele. Uporządkuj według danych (KB) klikając na nagłówek kolumny (możesz chcieć zrobić to dwa razy dla porządku malejącego). Zobaczysz poniższy raport.
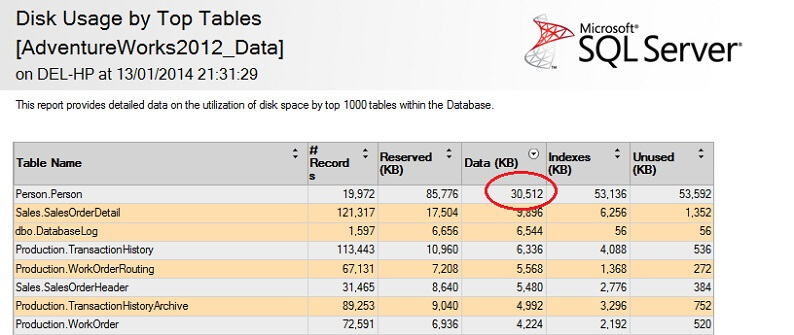
Określiłem interesującą liczbę – tabela Person. Tabela Person zajmuje 30,5MB danych i jest największą (pod względem danych, a nie liczby rekordów) tabelą. Spróbujmy więc pobrać próbkę z tej tabeli:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
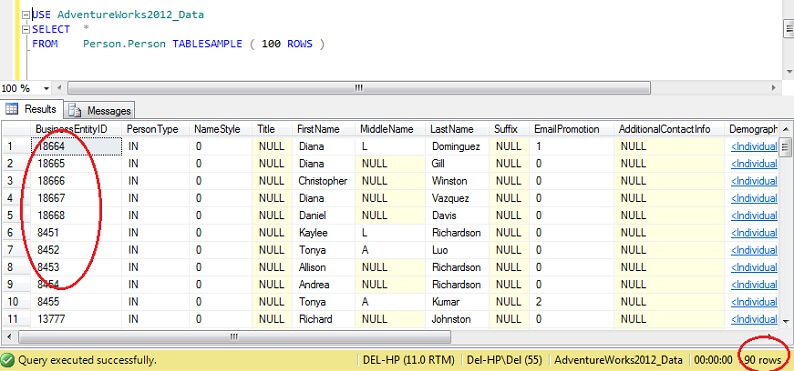
Widać, że jesteśmy znacznie bliżej 100 wierszy, ale co najważniejsze, nie wydaje się, aby było dużo klastrowania na kluczu głównym (chociaż jest trochę, ponieważ jest więcej niż 1 wiersz na stronę).
W konsekwencji, TABLESAMPLE jest dobry dla dużych danych i staje się katastrofalnie gorszy im mniejszy zbiór danych. Nie jest to dobre dla nas, gdy próbkujemy z danych warstwowych lub klastrowanych, gdzie pobieramy wiele próbek z małych grup lub podzbiorów danych, a następnie je agregujemy. Przyjrzyjmy się zatem alternatywnej metodzie.
Losowe dane SQL Server z ORDER BY NEWID()
Tutaj cytat z BOL o uzyskaniu prawdziwie losowej próbki:
„Jeśli naprawdę chcesz uzyskać losową próbkę poszczególnych wierszy, zmodyfikuj zapytanie, aby odfiltrować wiersze losowo, zamiast używać TABLESAMPLE. Na przykład, poniższe zapytanie wykorzystuje funkcję NEWID do zwrócenia około jednego procenta wierszy tabeli Sales.SalesOrderDetail:
Jak to działa? Rozdzielmy klauzulę WHERE i wyjaśnijmy ją.
Funkcja CHECKSUM oblicza sumę kontrolną dla elementów na liście. Można się spierać, czy SalesOrderID jest w ogóle wymagany, ponieważ NEWID() jest funkcją, która zwraca nowy losowy identyfikator GUID, więc pomnożenie losowej liczby przez stałą powinno w każdym przypadku dać wynik losowy.Rzeczywiście, wykluczenie SalesOrderID wydaje się nie robić różnicy. Jeśli jesteś zapalonym statystykiem i możesz uzasadnić włączenie tego, proszę użyj sekcji komentarzy poniżej i daj mi znać, dlaczego się mylę!
Funkcja CHECKSUM zwraca VARBINARY. Wykonanie operacji bitowego AND z 0x7fffffff, co jest odpowiednikiem (111111111…) w systemie binarnym, daje wartość dziesiętną, która jest efektywnie reprezentacją losowego ciągu 0 i 1. Dzielenie przez współczynnik 0x7fffffff skutecznie normalizuje tę liczbę dziesiętną do liczby pomiędzy 0 a 1. Następnie, aby zdecydować, czy każdy wiersz zasługuje na włączenie do ostatecznego zestawu wyników, używany jest próg 1/x (w tym przypadku 0.01), gdzie x jest procentem danych do pobrania jako próbka.
Bądź ostrożny, że ta metoda jest formą losowego próbkowania, a nie systematycznego próbkowania, więc prawdopodobnie otrzymasz dane ze wszystkich części danych źródłowych, ale kluczem jest to, że *możesz nie*. Natura losowego pobierania próbek oznacza, że każda zebrana próbka może być tendencyjnie skierowana w stronę jednego segmentu danych, więc aby skorzystać z regresji do średniej (tendencji do losowego wyniku, w tym przypadku), upewnij się, że pobierasz wiele próbek i wybierasz z podzbioru tych próbek, jeśli twoje wyniki wyglądają na skośne. Alternatywą jest pobranie próbek z podzbiorów danych, a następnie zagregowanie ich – jest to inny rodzaj próbkowania, zwany próbkowaniem warstwowym.
Jak statystyki SQL Server są próbkowane?
W SQL Server, automatyczna aktualizacja statystyk kolumn lub statystyk zdefiniowanych przez użytkownika ma miejsce za każdym razem, gdy określony próg wierszy tabeli zostanie zmieniony dla danej tabeli. Dla roku 2012 próg ten jest obliczany jako SQRT(1000 * TR), gdzie TR jest liczbą wierszy tabeli w tabeli. Przed rokiem 2005 zadanie automatycznej aktualizacji statystyk zostanie uruchomione dla każdego (500 wierszy + 20% zmiany) wierszy tabeli. Gdy rozpocznie się proces automatycznej aktualizacji, próbkowanie będzie *zmniejszać liczbę próbkowanych wierszy im większa będzie tabela*, innymi słowy istnieje zależność, która jest podobna do odwrotnej proporcji między procentem próbkowania tabeli a rozmiarem tabeli, ale podąża za zastrzeżonym algorytmem.
Interesujące jest to, że wydaje się to być przeciwieństwem opcji TABLESAMPLE (N PERCENT), gdzie próbkowane wiersze są w normalnej proporcji do liczby wierszy w tabeli. Możemy wyłączyć statystyki automatyczne (należy zachować ostrożność) i aktualizować statystyki ręcznie – uzyskujemy to poprzez użycie NORECOMPUTE w instrukcji UPDATE STATISTICS. Z UPDATE STATISTICS możemy zmienić niektóre opcje – na przykład, możemy wybrać próbkowanie N wierszy lub N procent (podobnie do TABLESAMPLE), wykonać FULLSCAN lub po prostu RESAMPLE używając ostatniego znanego wskaźnika.
Następne kroki
Do dalszego czytania, Joseph Sack jest Microsoft MVP znany ze swojej pracy w analizie statystycznej SQL Server – proszę zobaczyć poniżej kilka linków do jego pracy, wraz z niektórymi odniesieniami do pracy wykorzystanej w tym artykule i do niektórych powiązanych wskazówek z MSSQLTips.com. Dzięki za przeczytanie!
Ostatnia aktualizacja: 2014-01-29


O autorze
 Derek Colley jest pochodzącym z Wielkiej Brytanii DBA i BI Developerem z ponad dziesięcioletnim doświadczeniem w pracy z SQL Server, Oracle i MySQL.
Derek Colley jest pochodzącym z Wielkiej Brytanii DBA i BI Developerem z ponad dziesięcioletnim doświadczeniem w pracy z SQL Server, Oracle i MySQL.Zobacz wszystkie moje wskazówki
- Więcej wskazówek dla programistów baz danych…
.