Szyfrowanie danych w stanie spoczynku jest koniecznością dla każdej nowoczesnej firmy internetowej. Wiele firm jednak nie szyfruje swoich dysków, ponieważ obawia się potencjalnego spadku wydajności spowodowanego narzutem szyfrowania.
Szyfrowanie danych w stanie spoczynku ma kluczowe znaczenie dla Cloudflare, które posiada ponad 200 centrów danych na całym świecie. W tym poście zbadamy wydajność szyfrowania dysków w systemie Linux i wyjaśnimy, jak sprawiliśmy, że jest ono co najmniej dwa razy szybsze dla nas samych i naszych klientów!
Szyfrowanie danych w stanie spoczynku
Jeśli chodzi o szyfrowanie danych w stanie spoczynku, istnieje kilka sposobów, w jakie można je zaimplementować w nowoczesnym systemie operacyjnym (OS). Dostępne techniki są ściśle sprzężone z typowym stosem pamięci masowej systemu operacyjnego. Uproszczoną wersję stosu pamięci masowej i rozwiązań szyfrowania można znaleźć na poniższym diagramie:
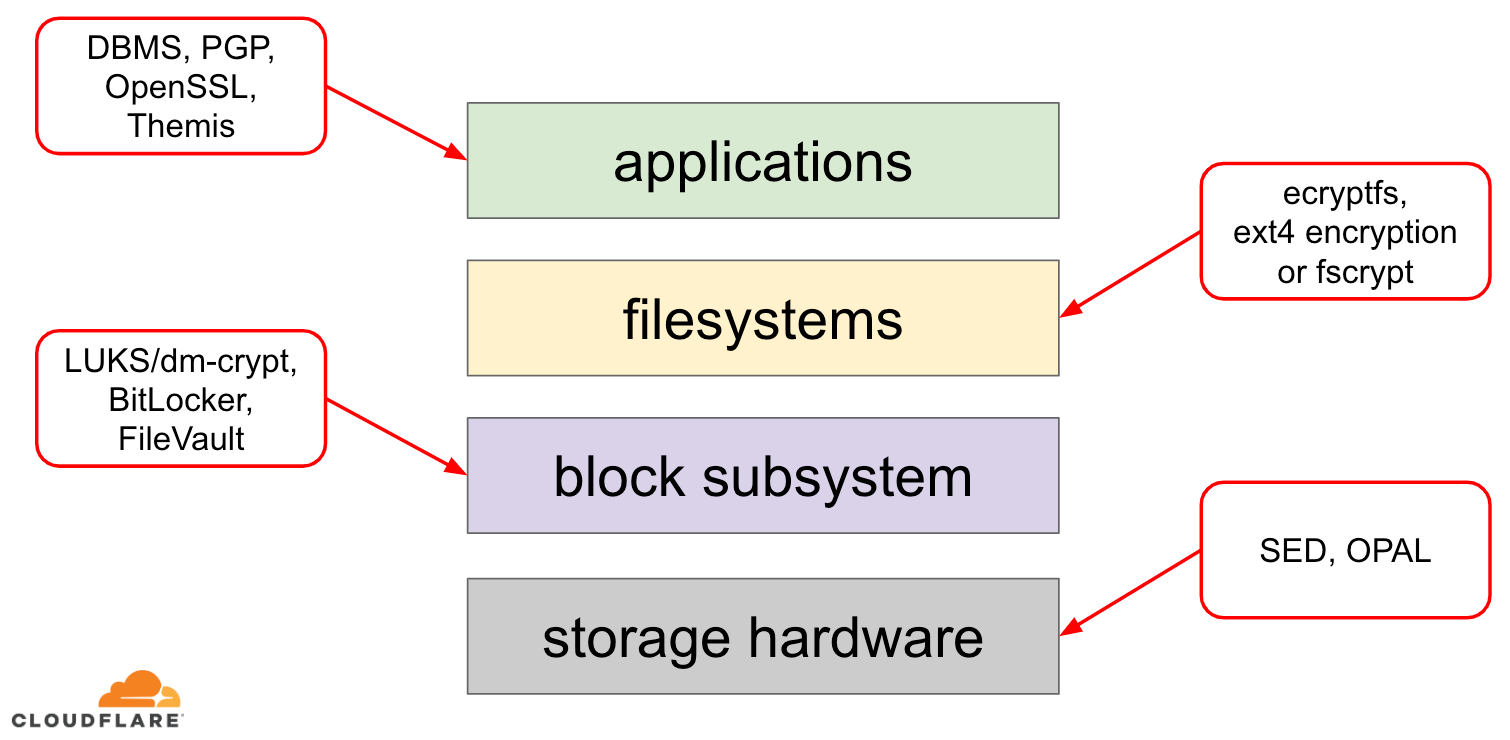
Na szczycie stosu znajdują się aplikacje, które odczytują i zapisują dane w plikach (lub strumieniach). System plików w jądrze systemu operacyjnego śledzi, które bloki bazowego urządzenia blokowego należą do których plików i tłumaczy te odczyty i zapisy plików na odczyty i zapisy bloków, jednak specyfika sprzętowa bazowego urządzenia pamięci masowej jest abstrahowana od systemu plików. Wreszcie podsystem blokowy faktycznie przekazuje odczyty i zapisy bloków do bazowego sprzętu za pomocą odpowiednich sterowników urządzeń.
Koncepcja stosu pamięci masowej jest w rzeczywistości podobna do dobrze znanego sieciowego modelu OSI, w którym każda warstwa ma bardziej wysokopoziomowy widok informacji, a szczegóły implementacji niższych warstw są abstrahowane od warstw wyższych. I podobnie jak w modelu OSI, można stosować szyfrowanie w różnych warstwach (pomyśl o TLS vs IPsec lub VPN).
Dla danych w spoczynku możemy stosować szyfrowanie albo w warstwach blokowych (sprzętowo lub programowo), albo na poziomie plików (bezpośrednio w aplikacjach lub w systemie plików).
Szyfrowanie blokowe vs szyfrowanie plików
Generalnie, im wyżej w stosie stosujemy szyfrowanie, tym większą mamy elastyczność. W przypadku szyfrowania na poziomie aplikacji opiekunowie aplikacji mogą zastosować dowolny kod szyfrujący do konkretnych danych, których potrzebują. Wadą tego podejścia jest to, że tak naprawdę muszą go zaimplementować sami, a szyfrowanie ogólnie nie jest zbyt przyjazne dla programistów: trzeba znać tajniki konkretnego algorytmu kryptograficznego, odpowiednio generować klucze, nonces, IVs itd. Dodatkowo, szyfrowanie na poziomie aplikacji nie wykorzystuje buforowania na poziomie systemu operacyjnego, a w szczególności buforowania stron w systemie Linux: za każdym razem, gdy aplikacja potrzebuje użyć danych, musi albo ponownie je odszyfrować, marnując cykle procesora, albo zaimplementować własny odszyfrowany „bufor”, co wprowadza więcej złożoności do kodu.
Szyfrowanie na poziomie systemu plików sprawia, że szyfrowanie danych jest przezroczyste dla aplikacji, ponieważ system plików sam szyfruje dane przed przekazaniem ich do podsystemu blokowego, więc pliki są szyfrowane niezależnie od tego, czy aplikacja ma wsparcie kryptograficzne, czy nie. Ponadto, systemy plików mogą być skonfigurowane tak, aby szyfrować tylko konkretny katalog lub mieć różne klucze dla różnych plików. Ta elastyczność jest jednak związana z kosztem bardziej złożonej konfiguracji. Szyfrowanie systemu plików jest również uważane za mniej bezpieczne niż szyfrowanie urządzeń blokowych, ponieważ szyfrowana jest tylko zawartość plików. Pliki mają również powiązane metadane, takie jak rozmiar pliku, liczba plików, układ drzewa katalogów itp., które są nadal widoczne dla potencjalnego przeciwnika.
Szyfrowanie w warstwie bloków (często określane jako szyfrowanie dysku lub szyfrowanie całego dysku) również czyni szyfrowanie danych przezroczystym dla aplikacji, a nawet całych systemów plików. W przeciwieństwie do szyfrowania na poziomie systemu plików, szyfruje ono wszystkie dane na dysku, w tym metadane pliku, a nawet wolną przestrzeń. Jest ono jednak mniej elastyczne – można zaszyfrować cały dysk tylko jednym kluczem, więc nie ma możliwości konfiguracji per katalog, per plik lub per użytkownik. Z punktu widzenia kryptografii, nie wszystkie algorytmy kryptograficzne mogą być użyte, ponieważ warstwa blokowa nie ma już wysokopoziomowego wglądu w dane, więc musi przetwarzać każdy blok niezależnie. Większość popularnych algorytmów wymaga pewnego rodzaju łańcuchowania bloków, aby były bezpieczne, więc nie mają zastosowania do szyfrowania dysków. Zamiast tego, specjalne tryby zostały opracowane tylko dla tego konkretnego przypadku użycia.
Więc którą warstwę wybrać? Jak zawsze, to zależy… Szyfrowanie na poziomie aplikacji i systemu plików jest zwykle preferowanym wyborem dla systemów klienckich ze względu na elastyczność. Na przykład, każdy użytkownik komputera stacjonarnego z wieloma użytkownikami może chcieć zaszyfrować swój katalog domowy własnym kluczem, a niektóre współdzielone katalogi pozostawić niezaszyfrowane. Natomiast w systemach serwerowych, zarządzanych przez firmy SaaS/PaaS/IaaS (w tym Cloudflare), preferowanym wyborem jest prostota konfiguracji i bezpieczeństwo – przy włączonym pełnym szyfrowaniu dysku wszelkie dane z dowolnej aplikacji są automatycznie szyfrowane bez żadnych wyjątków ani nadpisywania. Uważamy, że wszystkie dane muszą być chronione bez sortowania ich na „ważne” i „nieważne”, więc selektywna elastyczność, którą zapewniają wyższe warstwy, nie jest potrzebna.
Szyfrowanie dysków sprzętowe vs programowe
Szyfrując dane w warstwie bloków, można to zrobić bezpośrednio w sprzęcie pamięci masowej, jeśli sprzęt to obsługuje. Zwykle daje to lepszą wydajność odczytu/zapisu i zużywa mniej zasobów hosta. Jednakże, ponieważ większość firmware’u sprzętowego jest prawnie zastrzeżona, nie poświęca się mu tak wiele uwagi i nie jest on poddawany przeglądowi przez społeczność zajmującą się bezpieczeństwem. W przeszłości prowadziło to do błędów w niektórych implementacjach sprzętowego szyfrowania dysków, które czyniły cały model zabezpieczeń bezużytecznym. Microsoft, na przykład, zaczął preferować szyfrowanie dysków oparte na oprogramowaniu od tego czasu.
Nie chcieliśmy narażać naszych danych i danych naszych klientów na ryzyko korzystania z potencjalnie niezabezpieczonych rozwiązań i mocno wierzymy w open-source. Dlatego polegamy tylko na programowym szyfrowaniu dysków w jądrze Linuksa, które jest otwarte i zostało sprawdzone przez wielu specjalistów od bezpieczeństwa na całym świecie.
Wydajność szyfrowania dysków w Linuksie
Dążymy nie tylko do oszczędzania kosztów pasma dla naszych klientów, ale do dostarczania treści do użytkowników Internetu tak szybko jak to możliwe.
W pewnym momencie zauważyliśmy, że nasze dyski nie były tak szybkie jak byśmy chcieli. Pewne profilowanie, jak również szybki test A/B wskazały na szyfrowanie dysków w Linuksie. Ponieważ nie szyfrowanie danych (nawet jeśli ma to być publiczna pamięć podręczna Internetu) nie jest trwałą opcją, zdecydowaliśmy się przyjrzeć bliżej wydajności szyfrowania dysków w Linuksie.
Mapper urządzeń i dm-crypt
Linux implementuje przezroczyste szyfrowanie dysków poprzez moduł dm-crypt i dm-cryptsam jest częścią frameworka jądra mapowania urządzeń. W skrócie, device mapper pozwala na wstępne/późniejsze przetwarzanie żądań IO, gdy podróżują one pomiędzy systemem plików a bazowym urządzeniem blokowym.
dm-cryptw szczególności szyfruje żądania IO „zapisu” przed wysłaniem ich dalej w dół stosu do rzeczywistego urządzenia blokowego i deszyfruje żądania IO „odczytu” przed wysłaniem ich w górę do sterownika systemu plików. Proste i łatwe! A może jest?
Ustawienie testowe
Dla przypomnienia, liczby w tym poście zostały uzyskane przez uruchomienie określonych poleceń na bezczynnym serwerze Cloudflare G9 poza produkcją. Jednak konfiguracja powinna być łatwa do odtworzenia na każdym nowoczesnym laptopie x86.
Generalnie, benchmarkowanie czegokolwiek wokół stosu pamięci masowej jest trudne z powodu szumu wprowadzanego przez sam sprzęt pamięci masowej. Nie wszystkie dyski są sobie równe, więc dla celów tego postu użyjemy najszybszych dostępnych dysków – czyli żadnych dysków.
Zamiast tego Linux posiada opcję emulacji dysku bezpośrednio w pamięci RAM. Ponieważ RAM jest znacznie szybszy niż jakakolwiek pamięć trwała, nie powinno to mieć większego wpływu na nasze wyniki.
Następująca komenda tworzy ramdysk o pojemności 4GB:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Teraz możemy utworzyć na nim instancję dm-crypt umożliwiając w ten sposób szyfrowanie dysku. Po pierwsze, musimy wygenerować klucz szyfrowania dysku, „sformatować” dysk i określić hasło, aby odblokować nowo wygenerowany klucz.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase: Ci, którzy są zaznajomieni z LUKS/dm-crypt mogli zauważyć, że użyliśmy tutaj nagłówka LUKS detached. Normalnie LUKS przechowuje zaszyfrowany hasłem klucz szyfrowania dysku na tym samym dysku co dane, ale ponieważ chcemy porównać wydajność odczytu/zapisu pomiędzy urządzeniami zaszyfrowanymi i niezaszyfrowanymi, możemy przypadkowo nadpisać zaszyfrowany klucz podczas późniejszego benchmarkingu. Przechowywanie zaszyfrowanego klucza w osobnym pliku pozwala uniknąć tego problemu dla celów tego postu.
Teraz możemy faktycznie „odblokować” zaszyfrowane urządzenie do naszych testów:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0W tym momencie możemy teraz porównać wydajność zaszyfrowanego i niezaszyfrowanego ramdysku: jeśli będziemy odczytywać/zapisywać dane do /dev/ram0, będą one przechowywane w plaintext. Podobnie, jeśli odczytujemy/zapisujemy dane do /dev/mapper/encrypted-ram0, zostaną one odszyfrowane/zaszyfrowane po drodze przez dm-crypt i zapisane w szyfrogramie.
Warto zauważyć, że nie tworzymy żadnego systemu plików na wierzchu naszych urządzeń blokowych, aby uniknąć zniekształcenia wyników przez narzut systemu plików.
Pomiar przepustowości
Jeśli chodzi o testowanie pamięci masowej/benchmarking Flexible I/O tester jest zwykle stosowanym rozwiązaniem. Zasymulujmy proste sekwencyjne obciążenie odczytem/zapisem z rozmiarem bloku 4K na ramdysku bez szyfrowania:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%Powyższe polecenie będzie działać przez długi czas, więc po prostu zatrzymamy je po chwili. Jak widzimy na statystykach, jesteśmy w stanie czytać i pisać mniej więcej z taką samą przepustowością w okolicach 1126 MB/s. Powtórzmy test z zaszyfrowanym ramdiskiem:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecWhoa, to jest spadek! Otrzymujemy teraz tylko ~147 MB/s, co jest ponad 7 razy wolniejsze! I to na całkowicie bezczynnej maszynie!
Możliwe, że kryptowaluta jest po prostu wolna
Pierwszą rzeczą, jaką wzięliśmy pod uwagę, jest zapewnienie, że używamy najszybszej kryptowaluty. cryptsetup pozwala nam porównać wszystkie dostępne implementacje kryptowalut w systemie, aby wybrać najlepszą z nich:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/AWygląda na to, że aes-xts z 256-bitowym kluczem szyfrowania danych jest tutaj najszybszy. Ale którego z nich tak naprawdę używamy dla naszego zaszyfrowanego ramdysku?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0Wykorzystujemy aes-xts z 256-bitowym kluczem szyfrowania danych (policz wszystkie zera wygodnie zamaskowane przez narzędzie dmsetup – jeśli chcesz zobaczyć rzeczywiste bajty, dodaj opcję --showkeys do powyższego polecenia). Liczby te jednak nie sumują się: cryptsetup benchmark mówi nam powyżej, żeby nie polegać na wynikach, ponieważ „Tests are approximate using memory only (no storage IO)”, ale dokładnie tak skonfigurowaliśmy nasz eksperyment z użyciem ramdysku. W nieco gorszym przypadku (zakładając, że czytamy wszystkie dane, a następnie szyfrujemy/deszyfrujemy je sekwencyjnie bez żadnej równoległości) wykonując back-of-the-envelope calculation powinniśmy uzyskać około (1126 * 1823) / (1126 + 1823) =~696 MB/s, co jest wciąż dość daleko od rzeczywistego 147 * 2 = 294 MB/s (suma dla odczytów i zapisów).
dm-crypt performance flags
Podczas czytania strony man cryptsetup zauważyliśmy, że posiada ona dwie opcje poprzedzone --perf-, które prawdopodobnie są związane z dostrajaniem wydajności. Pierwsza z nich to --perf-same_cpu_crypt z dość tajemniczym opisem:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Więc włączamy opcję
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Uwaga: zgodnie z najnowszą stroną man istnieje również polecenie cryptsetup refresh, które może być użyte do włączenia tych opcji na żywo bez konieczności „zamykania” i „ponownego otwierania” urządzenia szyfrowanego. Nasze cryptsetup jednak jeszcze tego nie obsługiwało.
Weryfikacja, czy opcja została rzeczywiście włączona:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptTak, teraz widzimy same_cpu_crypt na wyjściu, czyli to, co chcieliśmy. Przeprowadźmy ponownie benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, teraz jest ~136 MB/s, co jest nieco gorsze niż poprzednio, więc nie jest dobrze. A co z drugą opcją --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Może jesteśmy tu w „pewnej sytuacji”, więc wypróbujmy ją:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusA teraz benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, który jest nieco lepszy, ale nadal nie jest dobry…
Pytanie społeczności
Będąc zdesperowanymi postanowiliśmy poszukać wsparcia w Internecie i opublikowaliśmy nasze odkrycia na liście mailingowej dm-crypt, ale odpowiedź jaką otrzymaliśmy nie była zbyt zachęcająca:
Jeśli te liczby Ci przeszkadzają, to wynika to z braku zrozumienia po Twojej stronie. Prawdopodobnie nie jesteście świadomi, że szyfrowanie jest operacją o dużym ciężarze…
Postanowiliśmy przeprowadzić naukowe badania na ten temat wpisując „is encryption expensive” w Google Search i jednym z czołowych wyników, który faktycznie zawiera sensowne pomiary, jest… nasz własny post o kosztach szyfrowania, ale w kontekście TLS! Jest to fascynująca lektura sama w sobie, ale sedno jest takie: nowoczesne kryptowaluty na nowoczesnym sprzęcie są bardzo tanie, nawet w skali Cloudflare (wykonywanie milionów zaszyfrowanych żądań HTTP na sekundę). W rzeczywistości jest to tak tanie, że Cloudflare był pierwszym dostawcą, który zaoferował darmowe SSL/TLS dla każdego.
Grzebanie w kodzie źródłowym
Próbując użyć niestandardowych opcji dm-crypt opisanych powyżej, byliśmy ciekawi, dlaczego w ogóle istnieją i o co chodzi z tym „odciążaniem”. Pierwotnie spodziewaliśmy się, że dm-crypt będzie prostym „proxy”, które po prostu szyfruje/deszyfruje dane podczas ich przepływu przez stos. Okazuje się, że dm-crypt robi coś więcej niż tylko szyfrowanie buforów pamięci, a (uproszczony) diagram ścieżki IO traverse jest przedstawiony poniżej:

Kiedy system plików wydaje żądanie zapisu, dm-crypt nie przetwarza go od razu – zamiast tego umieszcza je w kolejce roboczej o nazwie „kcryptd”. W skrócie, kolejka robocza jądra po prostu planuje pewną pracę (w tym przypadku szyfrowanie) do wykonania w późniejszym czasie, kiedy jest to wygodniejsze. Kiedy „czas” nadejdzie, dm-crypt wysyła żądanie do Linux Crypto API w celu faktycznego szyfrowania. Jednakże, współczesny Linux Crypto API jest również asynchroniczny, więc w zależności od tego, jakiej konkretnie implementacji użyje twój system, najprawdopodobniej żądanie nie zostanie przetworzone natychmiast, lecz ponownie ustawione w kolejce na „późniejszy czas”. Kiedy Linux Crypto API w końcu wykona szyfrowanie, dm-crypt może spróbować posortować oczekujące żądania zapisu poprzez umieszczenie każdego żądania w czerwono-czarnym drzewie. Następnie oddzielny wątek jądra ponownie w „późniejszym czasie” faktycznie bierze wszystkie żądania IO w drzewie i wysyła je w dół stosu.
Teraz żądania odczytu: tym razem musimy najpierw uzyskać zaszyfrowane dane ze sprzętu, ale dm-crypt nie pyta po prostu o sterownik dla danych, ale ustawia żądanie w kolejce do innej kolejki roboczej o nazwie „kcryptd_io”. W pewnym momencie później, gdy faktycznie mamy zaszyfrowane dane, planujemy je do odszyfrowania używając znanej już kolejki „kcryptd”. „kcryptd” wyśle żądanie do Linux Crypto API, które może odszyfrować dane również asynchronicznie.
Aby być sprawiedliwym, żądanie nie zawsze przechodzi przez wszystkie te kolejki, ale ważną częścią tutaj jest to, że żądania zapisu mogą być ustawione w kolejce do 4 razy w dm-crypt, a żądania odczytu do 3 razy. W tym momencie zastanawialiśmy się, czy całe to dodatkowe kolejkowanie może powodować jakieś problemy z wydajnością. Na przykład, istnieje ładna prezentacja od Google na temat związku pomiędzy kolejkowaniem a opóźnieniami ogona. Jednym z kluczowych wniosków z prezentacji jest:
Ważna część opóźnień ogona jest spowodowana efektami kolejkowania
Więc, dlaczego są tam te wszystkie kolejki i czy możemy je usunąć?
Archeologia Git
Nikt nie pisze bardziej złożonego kodu dla zabawy, zwłaszcza dla jądra systemu operacyjnego. Więc wszystkie te kolejki musiały zostać tam umieszczone z jakiegoś powodu. Na szczęście źródła jądra Linuksa są zarządzane przez git, więc możemy spróbować prześledzić zmiany i decyzje wokół nich.
Kolejka robocza „kcryptd” była w źródłach od początku dostępnej historii z następującym komentarzem:
Potrzebna, ponieważ byłoby bardzo nierozsądne wykonywać deszyfrowanie w kontekście przerwania, więc biosy powracające z żądań odczytu są tutaj kolejkowane.
Więc to było tylko dla odczytów, ale nawet wtedy – dlaczego obchodzi nas czy jest to kontekst przerwania czy nie, skoro Linux Crypto API prawdopodobnie i tak użyje dedykowanego wątku/kolejki do szyfrowania? Cóż, w 2005 Crypto API nie było asynchroniczne, więc to miało sens.
W 2006 roku dm-crypt zaczęło używać kolejki roboczej „kcryptd” nie tylko do szyfrowania, ale do składania żądań IO:
Ta poprawka jest zaprojektowana, aby pomóc dm-crypt dostosować się do nowych ograniczeń nałożonych przez następującą poprawkę w -mm: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Wygląda na to, że celem nie było dodanie większej współbieżności, ale raczej zredukowanie użycia stosu jądra, co znowu ma sens, jako że jądro ma wspólny stos dla całego kodu, więc jest to dość ograniczony zasób. Warto jednak zauważyć, że stos jądra Linuksa został rozszerzony w 2014 roku dla platform x86, więc może to już nie być problem.
Pierwsza wersja kolejki roboczej „kcryptd_io” została dodana w 2007 roku z zamiarem uniknięcia:
starania spowodowanego wieloma żądaniami oczekującymi na alokację pamięci…
Przetwarzanie żądań było wąskim gardłem na pojedynczej kolejce roboczej tutaj, więc rozwiązaniem było dodanie kolejnej. To ma sens.
Na pewno nie jesteśmy pierwszymi, którzy doświadczają spadku wydajności z powodu rozległego kolejkowania: w 2011 roku wprowadzono zmianę, aby warunkowo odwrócić niektóre z kolejkowania dla żądań odczytu:
Jeśli jest wystarczająco dużo pamięci, kod może bezpośrednio przesłać bio zamiast kolejkować tę operację w osobnym wątku.
Niestety, w tym czasie komunikaty commit jądra Linux nie były tak dosłowne jak dzisiaj, więc nie ma dostępnych danych dotyczących wydajności.
W 2015 roku dm-crypt zaczął sortować zapisy w oddzielnym wątku „dmcrypt_write” przed wysłaniem ich w dół stosu:
Na maszynie wieloprocesorowej żądania szyfrowania kończą się w innej kolejności niż zostały złożone. W związku z tym żądania zapisu byłyby składane w innej kolejności i mogłoby to spowodować poważne pogorszenie wydajności.
To ma sens, ponieważ sekwencyjny dostęp do dysku był znacznie szybszy niż losowy, a dm-crypt łamał ten wzorzec. Ale dotyczy to głównie dysków wirujących, które wciąż były dominujące w 2015 roku. Może nie być tak ważne w przypadku nowoczesnych szybkich dysków SSD (w tym NVME SSD).
Inna część komunikatu commit jest warta wspomnienia:
…w szczególności umożliwia schedulery IO, takie jak CFQ, do sortowania bardziej efektywnie…
Wspomina o korzyściach z wydajności dla schedulera CFQ IO, ale schedulery Linuksa poprawiły się od tego czasu do tego stopnia, że scheduler CFQ został usunięty z jądra w 2018 roku.
Ten sam zestaw poprawek zastępuje listę sortowania drzewem czerwono-czarnym:
W teorii sortowanie powinno być wykonywane przez bazowy scheduler dyskowy, jednak w praktyce scheduler dyskowy tylko akceptuje i sortuje skończoną liczbę żądań. Aby umożliwić sortowanie wszystkich żądań, dm-crypt musi zaimplementować swoje własne sortowanie.
Nadmiar związany z sortowaniem opartym na rbtree jest uważany za nieistotny, więc nie jest używany warunkowo.
Wszystko to ma sens, ale byłoby miło mieć jakieś dane pomocnicze.
Interesująco, w tym samym zestawie poprawek widzimy wprowadzenie naszej znanej opcji „submit_from_crypt_cpus”:
Istnieją pewne sytuacje, w których odciążenie zapisu biosu z wątków szyfrujących do pojedynczego wątku znacznie pogarsza wydajność
Ogółem widzimy, że każda zmiana była rozsądna i potrzebna, jednak od tamtego czasu wszystko się zmieniło:
- hardware stał się szybszy i mądrzejszy
- przywrócono alokację zasobów w Linuksie
- przeprowadzono rearchitekturę sprzężonych podsystemów Linuksa
I wiele z powyższych wyborów projektowych może nie mieć zastosowania do współczesnego Linuksa.
„Czyszczenie”
Bazując na powyższych badaniach zdecydowaliśmy się spróbować usunąć wszystkie dodatkowe kolejki i zachowania asynchroniczne i przywrócić dm-crypt do jego pierwotnego celu: po prostu szyfrowanie/deszyfrowanie żądań IO, gdy przez nie przechodzą. Jednak ze względu na stabilność i dalsze benchmarki, nie usunęliśmy faktycznego kodu, ale raczej dodaliśmy kolejną opcję dm-crypt, która omija wszystkie kolejki/wątki, jeśli jest włączona. Flaga ta pozwala nam na przełączanie się pomiędzy obecnym i nowym zachowaniem w czasie działania pod pełnym obciążeniem produkcyjnym, dzięki czemu możemy łatwo przywrócić nasze zmiany, jeśli zauważymy jakiekolwiek efekty uboczne. Powstałą łatkę można znaleźć w repozytorium Cloudflare GitHub Linux.
Synchroniczne Linux Crypto API
Z powyższego diagramu pamiętamy, że nie wszystkie kolejki są zaimplementowane w dm-crypt. Współczesny Linux Crypto API może być również asynchroniczny i na potrzeby tego eksperymentu chcemy wyeliminować kolejki również tam. Co jednak oznacza „może być”? System operacyjny może zawierać różne implementacje tego samego algorytmu (na przykład, sprzętowo akcelerowany AES-NI na platformach x86 i generyczne implementacje AES w kodzie C). Domyślnie system wybiera „najlepszy” algorytm w oparciu o skonfigurowany priorytet algorytmu. dm-crypt pozwala nadpisać to zachowanie i zażądać konkretnej implementacji szyfru za pomocą prefiksu capi:. Jest jednak jeden problem. Sprawdźmy dostępne w naszym systemie implementacje AES-XTS (to nasz szyfr do szyfrowania dysków, pamiętasz?):
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64 Chcemy jawnie wybrać szyfr synchroniczny z powyższej listy, aby uniknąć efektów kolejkowania w wątkach, ale jedyne dwie obsługiwane implementacje to xts(ecb(aes-generic)) (generyczna implementacja C) i __xts-aes-aesni (implementacja akcelerowana sprzętowo na x86). Zdecydowanie chcemy tę drugą, ponieważ jest znacznie szybsza (celujemy tutaj w wydajność), ale jest podejrzanie oznaczona jako wewnętrzna (patrz internal: yes). Jeśli sprawdzimy kod źródłowy:
Zaznacz szyfr jako implementację usługową, możliwą do użycia tylko przez inny szyfr i nigdy przez zwykłego użytkownika API crypto jądra
Więc szyfr ten ma być używany tylko przez inny kod wrappera w Crypto API, a nie poza nim. W praktyce oznacza to, że wywołujący Crypto API musi jawnie określić tę flagę, gdy żąda konkretnej implementacji szyfru, ale dm-crypt tego nie robi, ponieważ z założenia nie jest częścią Linux Crypto API, a raczej „zewnętrznym” użytkownikiem. My już patchujemy moduł dm-crypt, więc równie dobrze moglibyśmy po prostu dodać odpowiednią flagę. Jednakże, jest jeszcze jeden problem z AES-NI w szczególności: x86 FPU. „Zmiennoprzecinkowe” mówisz? Dlaczego potrzebujemy matematyki zmiennoprzecinkowej do szyfrowania symetrycznego, które powinno polegać tylko na przesunięciach bitowych i operacjach XOR? Nie potrzebujemy matematyki, ale instrukcje AES-NI używają niektórych rejestrów procesora, które są dedykowane dla FPU. Niestety, jądro Linuksa nie zawsze zachowuje te rejestry w kontekście przerwania z powodów wydajnościowych (zapisywanie/przywracanie FPU jest kosztowne). Ale dm-crypt może wykonać kod w kontekście przerwania, więc ryzykujemy uszkodzenie danych innego procesu i wracamy do stwierdzenia „byłoby bardzo nierozsądne wykonywać deszyfrowanie w kontekście przerwania” w oryginalnym kodzie.
Naszym rozwiązaniem, aby rozwiązać powyższy problem było stworzenie innego nieco „inteligentnego” modułu Crypto API. Ten moduł jest synchroniczny i nie rozwija własnego crypto, ale jest tylko „routerem” żądań szyfrowania:
- jeśli możemy użyć FPU (i tym samym AES-NI) w bieżącym kontekście wykonania, po prostu przekazujemy żądanie szyfrowania do szybszej, „wewnętrznej”
__xts-aes-aesniimplementacji (i możemy jej użyć tutaj, ponieważ teraz jesteśmy częścią Crypto API) - w przeciwnym razie, po prostu przekażemy żądanie szyfrowania do wolniejszej, ogólnej, opartej na C implementacji
xts(ecb(aes-generic))
Używanie całej masy
Przejdźmy przez proces używania tego wszystkiego razem. Pierwszym krokiem jest pobranie łatek i przekompilowanie jądra (lub po prostu skompilowanie dm-crypt i naszych modułów xtsproxy).
Następnie, zrestartujmy nasze obciążenie IO w oddzielnym terminalu, abyśmy mogli upewnić się, że możemy przekonfigurować jądro w trybie runtime pod obciążeniem:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...W głównym terminalu upewnij się, że nasz nowy moduł Crypto API jest załadowany i dostępny:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Reconfigure the encrypted disk to use our newly loaded module and enable our patched dm-crypt flag (we have to use low-level dmsetup tool as cryptsetup obviously is not aware of our modifications):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Właśnie „załadowaliśmy” nową konfigurację, ale żeby zaczęła działać, musimy zawiesić/wznowić pracę urządzenia zaszyfrowanego:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0And now observe the result. Możemy wrócić do drugiego terminala z zadaniem fio i spojrzeć na dane wyjściowe, ale żeby było ładniej, oto zrzut obserwowanej przepustowości odczytu/zapisu w Grafanie:
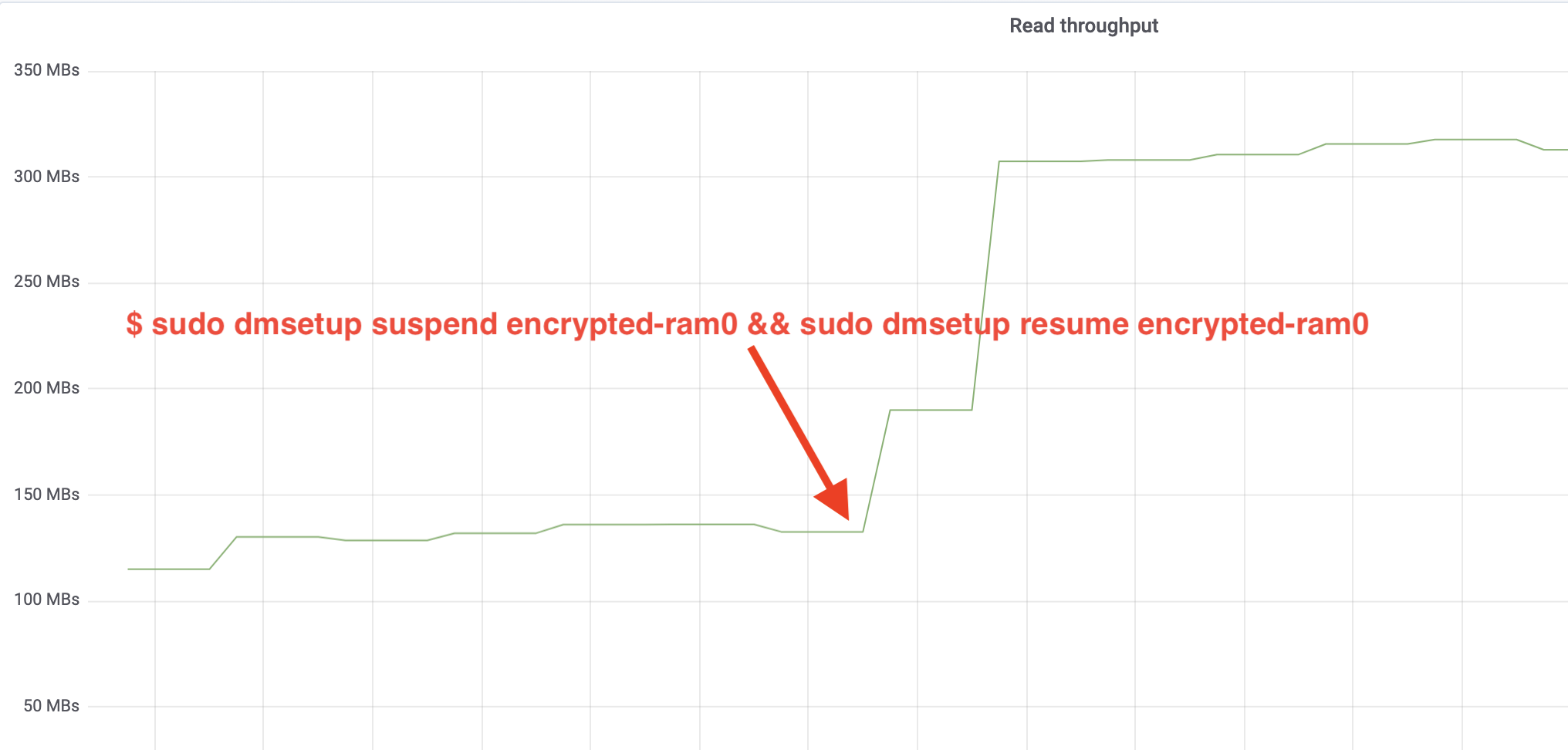
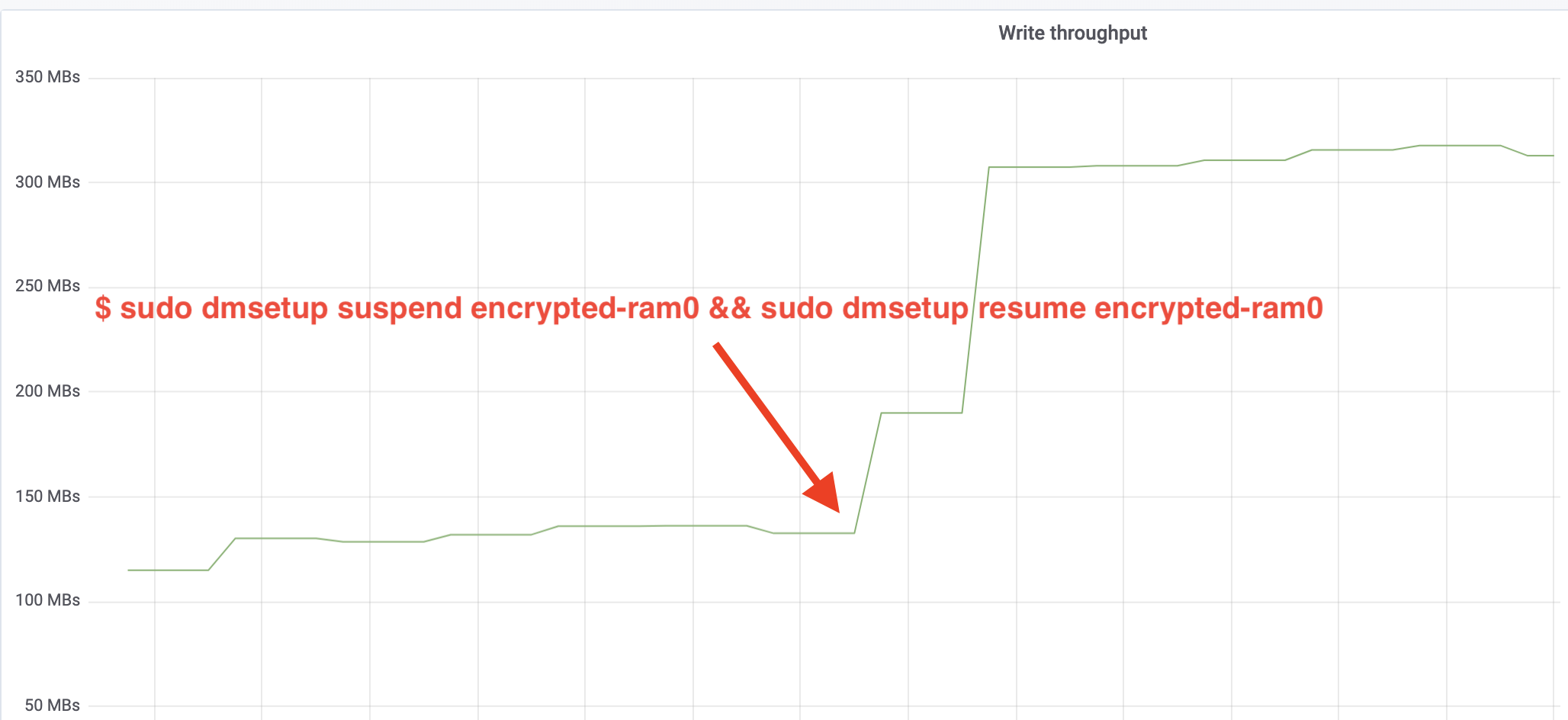
Wow, zwiększyliśmy przepustowość ponad dwukrotnie! Z całkowitą przepustowością ~640 MB/s jesteśmy teraz znacznie bliżej oczekiwanego ~696 MB/s z góry. A co z opóźnieniami IO? (The await statistic from the iostat reporting tool):
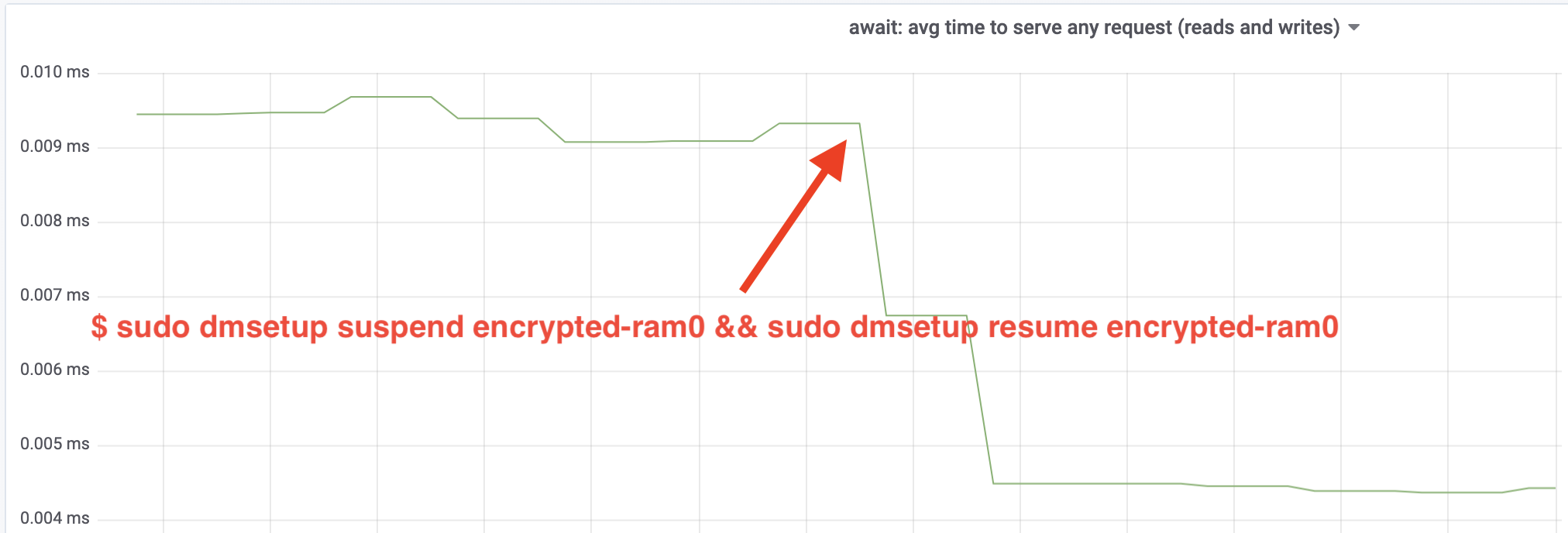
The latency has been cut in half as well!
To production
Do tej pory używaliśmy syntetycznej konfiguracji z niektórymi częściami pełnego stosu produkcyjnego, jak systemy plików, prawdziwy sprzęt i co najważniejsze, obciążenie produkcyjne. Aby upewnić się, że nie optymalizujemy wyimaginowanych rzeczy, oto migawka wpływu produkcyjnego, jaki te zmiany mają na część buforującą naszego stosu:

Ten wykres przedstawia trójstronne porównanie najgorszych czasów odpowiedzi (99. percentyl) dla trafienia w pamięci podręcznej w jednym z naszych serwerów. Zielona linia pochodzi z serwera z niezaszyfrowanymi dyskami, którego będziemy używać jako linii bazowej. Czerwona linia pochodzi z serwera z zaszyfrowanymi dyskami z domyślną implementacją szyfrowania dysków w systemie Linux, a niebieska linia pochodzi z serwera z zaszyfrowanymi dyskami i włączonymi naszymi optymalizacjami. Jak widzimy, domyślna implementacja szyfrowania dysków w systemie Linux ma znaczący wpływ na opóźnienie pamięci podręcznej w najgorszych scenariuszach, podczas gdy poprawiona implementacja jest nie do odróżnienia od nieużywania szyfrowania w ogóle. Innymi słowy, ulepszona implementacja szyfrowania nie ma żadnego wpływu na szybkość odpowiedzi naszej pamięci podręcznej, więc w zasadzie dostajemy ją za darmo! To jest wygrana!
Właśnie zaczynamy
Ten post pokazuje, jak przegląd architektury może podwoić wydajność systemu. Ponadto potwierdziliśmy, że nowoczesna kryptografia nie jest droga i zazwyczaj nie ma wymówki, by nie chronić swoich danych.
Zamierzamy zgłosić tę pracę do włączenia do głównego drzewa źródeł jądra, ale najprawdopodobniej nie w obecnej formie. Chociaż wyniki wyglądają zachęcająco, musimy pamiętać, że Linux jest wysoce przenośnym systemem operacyjnym: działa zarówno na potężnych serwerach, jak i małych, ograniczonych zasobami urządzeniach IoT oraz na wielu innych architekturach procesorów. Obecna wersja poprawek po prostu optymalizuje szyfrowanie dysków pod kątem konkretnego obciążenia na konkretnej architekturze, ale Linux potrzebuje rozwiązania, które będzie działać bezproblemowo wszędzie.
Jeśli uważasz, że twój przypadek jest podobny i chcesz skorzystać z poprawy wydajności już teraz, możesz pobrać poprawki i, miejmy nadzieję, dostarczyć informacje zwrotne. Flaga runtime ułatwia przełączanie funkcjonalności w locie, a prosty test A/B może być przeprowadzony, aby sprawdzić, czy jest to korzystne dla konkretnego przypadku lub konfiguracji. Te poprawki zostały uruchomione w naszej szerokiej sieci ponad 200 centrów danych na pięciu generacjach sprzętu, więc można je zasadnie uznać za stabilne. Ciesz się zarówno wydajnością, jak i bezpieczeństwem z Cloudflare dla wszystkich!

Uaktualnienie (11 października 2020)
Główna poprawka z tego bloga (w nieco zaktualizowanej formie) została włączona do głównego jądra Linuksa i jest dostępna od wersji 5.9. Główną różnicą jest to, że wersja mainline eksponuje dwie flagi zamiast jednej, które zapewniają możliwość ominięcia kolejek roboczych dm-crypt dla odczytu i zapisu niezależnie. Szczegóły można znaleźć w oficjalnej dokumentacji dm-crypt.