Białka zakotwiczone w GPI są dziwnym człowiekiem na zewnątrz. We wstępie do biologii komórki uczono nas, że istnieje pięć typów białek błonowych, nazwanych w następujący sposób: Typ I, Typ II, Typ III, Typ IV i zakotwiczone w GPI. Dlaczego mamy tę dziwną klasę białek połączonych z łańcuchem cukrowo-tłuszczowym? Co one robią? Czy możemy uzyskać jakiś wgląd w moje interesujące białko – PrP – dowiadując się więcej o tej klasie białek, której jest członkiem?
Sonia i ja oraz nasz kolega z zespołu, Andrew, czytaliśmy na ten temat i piszę ten wpis na blogu, aby podzielić się tym, czego się dowiedzieliśmy.
czytanie
Zaczęliśmy od przeczytania kilku recenzji. Głównie dotyczyły one struktury i biogenezy samej kotwicy GPI, o której wiadomo już bardzo dużo.
Kotwica ta, której pełna nazwa to glikozylofosfatydyloinozytol, nie jest monolitem: to ogólny opis cząsteczki, której szczegóły mogą się różnić. Ogólnie rzecz biorąc, zaczynając od ω (ostatniej potranslacyjnej reszty) białka, mamy etanoloaminę, potem fosforan, potem kilka cukrów, a następnie fosfolipid. Główny szkielet cukrowy jest konserwowany, ale łańcuchy boczne odgałęziające się od niego mogą się różnić, a grupa przewodnia fosfolipidu i kwasy tłuszczowe również mogą się różnić. Kotwica GPI PrP została scharakteryzowana w , ale nawet wtedy nie jest monolitem – zidentyfikowano co najmniej sześć różnych struktur różniących się składem łańcucha bocznego cukru.
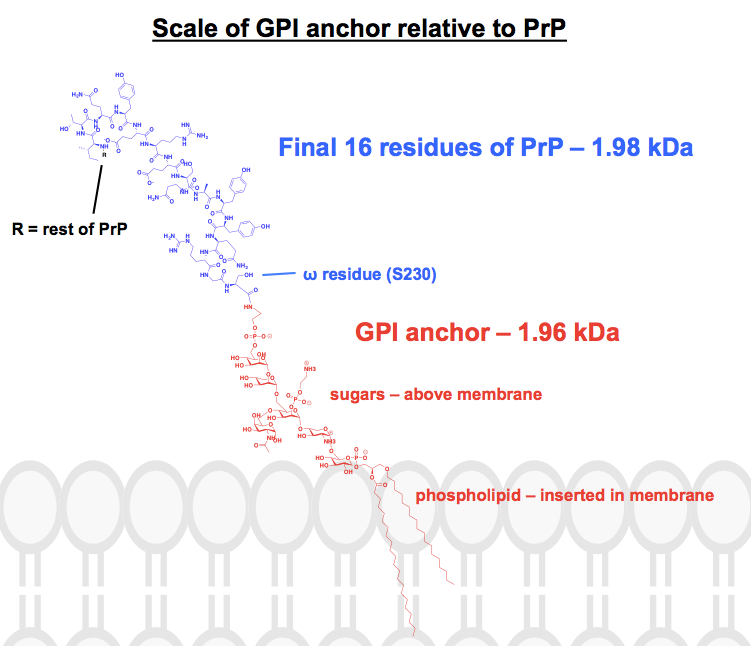
Każda struktura chemiczna, którą znalazłem kotwicy GPI ma co najmniej kilka części skróconych lub podsumowanych, a białko jest zwykle po prostu pokazane jako obraz. Chciałem się zorientować, jak te kotwice wyglądają chemicznie, w kontekście dołączonych do nich białek, więc postanowiłem narysować kompletną strukturę w ChemDraw. Pracując na podstawie Rysunku 1 – najbardziej zbliżonego do kompletnej struktury szkieletowej, jaką udało mi się znaleźć – dodałem szczegóły jednej z kotwic GPI PrP z górnego panelu Rysunku 6. Masa molekularna wynosiła 1,958 Da, więc dla kontekstu dodałem końcowe 16 reszt HuPrP23-230, które ważą porównywalnie, 1,979 Da. Jest to około 8% sekwencji PrP zmodyfikowanej post-translacyjnie. Nie jestem pewien, czy mam każde wiązanie w porządku, ale oto co wymyśliłem:
W wielu przypadkach gen ma wiele izoform, z jednym produktem splicingowym dającym początek białku zakotwiczonemu w GPI, podczas gdy inne dają początek formom wydzielanym lub transmembranowym. Przykłady obejmują NCAM1, który ma trzy główne izoformy, z których jedna jest zakotwiczona w GPI, a dwie pozostałe są transmembranowe, oraz ACHE (kodujący acetylocholinoesterazę), którego forma zakotwiczona w GPI jest najwyraźniej obecna tylko w czerwonych krwinkach (NCBI Genes). Najbardziej fascynująca jest tu historia mysiego genu Ly6a, który dzięki polimorfizmowi genetycznemu w niektórych szczepach myszy jest zakotwiczony w GPI, a w innych nie. Tylko w formie zakotwiczonej w GPI działa on jako receptor dla wektora wirusowego AAV PHP.eB . (Wektor ten osiąga zadziwiająco wydajne wchłanianie do neuronów mózgu w terapii genowej, ale niestety jest to tylko gen mysi – my, ludzie, nie mamy nawet Ly6a).
Wiele wiadomo o tym, jak kotwice GPI są syntetyzowane i przyłączane do białek, z >20 białkami zaangażowanymi w tę ścieżkę, z których większość zaczyna się od przedrostka „PIG” i jest kodowana przez geny takie jak PIGA, PIGK i tak dalej – patrz rysunek 2 dla diagramu. Większość biosyntezy odbywa się z kotwicą umieszczoną w błonie w ER, ale nie związaną z żadnym białkiem. W rzeczywistości kilka pierwszych etapów zachodzi na cytozolowym listku błony, a dopiero później kotwica przesuwa się na stronę lumenalną (do wnętrza ER). W ostatnim etapie transamidaza GPI, kompleks składający się z co najmniej pięciu białek, rozszczepia sygnał GPI na C-końcu białka i przyłącza kotwicę GPI do tzw. reszty ω białka (ostatniej reszty w sekwencji zmodyfikowanej potranslacyjnie). Następnie dochodzi do dalszego dojrzewania kotwicy GPI, ponieważ białko migruje z ER w kierunku powierzchni komórki.
Istnieje szereg drobnocząsteczkowych inhibitorów biosyntezy GPI w grzybach, z których niektórzy próbowali rozwijać jako leki przeciwgrzybicze , ale o ile mogłem powiedzieć, jedynym znanym inhibitorem biosyntezy GPI w komórkach ssaków jest mannoamina, analog mannozy, który jest chemicznie niezgodny z włączeniem do GPI .
Spojrzałem i poszukałem logo sekwencji, jaki motyw sekwencji aminokwasowej GPI transamidazy rozpoznaje, ale nie znalazłem żadnego. Najwyraźniej motyw sekwencji jest dość luźny i najwyraźniej sygnały GPI nie są nawet homologiczne, co oznacza, że nie wyewoluowały ze wspólnej sekwencji przodka, ale raczej ewoluowały zbieżnie, w stopniu, w jakim istnieje nawet jakakolwiek zbieżność. Najlepszy opis, jaki udało mi się znaleźć jest taki, że (czytając od N do C-końca białka) potrzeba 1) około 11 reszt nieuporządkowanego łącznika, 2) kilku reszt z małymi łańcuchami bocznymi, w tym resztę ω, która może być S, N, D, G, A lub C, 3) odstęp 5-10 polarnych aminokwasów, i wreszcie 4) 15-20 hydrofobowych aminokwasów. PrP luźno podąża za tym motywem. Zgodnie z opublikowanymi strukturami, helisa alfa 3 kończy się na reszcie Q223, co pozostawia „niestrukturalny łącznik” jako AYYQR (nieco krótszy niż zalecane 11 reszt). Region „małego łańcucha bocznego” to GS|SM (z rurką oznaczającą miejsce cięcia transamidazy), region polarny to VLFSSPP, a hydrofobowy terminus C to VILLISFLIFLIVG.
Niektóre z białek w szlaku biosyntezy i przyłączania GPI są bardzo ważne, a szereg ciężkich chorób i zespołów niedoboru kotwicy GPI zostało opisanych, z powodu biallelicznej utraty funkcji lub najwyraźniej hipomorficznych mutacji missense w genach takich jak PIGO, PIGV, PIGW, PGAP2 i PGAP3 .
Sonia znalazła doskonały papier sprzed kilku lat, w którym przeprowadzili mutagenezę screen w haploidalnych komórkach ludzkich, aby zidentyfikować geny wymagane do biogenezy dwóch białek zakotwiczonych w GPI: PrP i CD59 . Użyli oni powtarzanego sortowania FACS komórek opartego na powierzchni komórkowej PrP i CD59 w celu zidentyfikowania komórek z dramatycznie zmniejszonym poziomem powierzchniowym tych białek, a następnie przeprowadzili sekwencjonowanie, aby zobaczyć, które geny nokautujące zostały wzbogacone w tych komórkach w porównaniu z populacją macierzystą. Jak można się spodziewać, większość genów PIG pojawiła się dla obu białek (Rysunek 4), ale nie wszystkie trafienia pokrywały się, co jest nieco zaskakujące, zwłaszcza że na poziomie RNA, przynajmniej, PrP i CD59 są dwoma białkami o najbardziej podobnych profilach ekspresji w różnych tkankach (zobacz mapę cieplną na dole tego postu). Grupa enzymów zaangażowanych w modyfikację łańcucha bocznego kotwicy GPI pojawiła się tylko dla CD59, co sugeruje, że CD59, ale nie PrP, potrzebuje tych złożonych łańcuchów bocznych, aby dojrzeć i dotrzeć na powierzchnię komórki. Tymczasem Sec62 i Sec63 pojawiły się tylko dla PrP – są to białka w jakiś sposób zaangażowane w ko-translacyjną translokację do ER, ale najwyraźniej są one potrzebne dla PrP, ale nie dla CD59 ani dla CD55 czy CD109, dwóch innych białek kontrolnych, którym się przyjrzano. Jest to fascynujący nowy rozdział w odpowiedzi na moje pytanie: „Czy jest coś wyjątkowego w ekspresji PrP?”, gdzie szukałem czegoś wyjątkowego w biogenezie PrP, co mogłoby być potencjalnie celowane za pomocą małej molekuły. Oczywiście, tylko dlatego, że te białka nie były ważne dla trzech innych białek kontrolnych, nie oznacza, że nie są ważne – jedno z badań wykazało, że Sec62 jest potrzebny do wydzielania wielu małych białek, a gen SEC62 jest całkowicie pozbawiony wariantów utraty funkcji w populacji ludzkiej, wystarczająco, by sugerować haploinsufficiency. SEC63 wydaje się mniej ograniczony, choć może to po prostu oznaczać, że działa recesywnie.
Żadne z powyższych nie odpowiada na pytanie, dlaczego istnieją białka zakotwiczone w GPI. Moja stara klasa biologii komórki pominęła szczegół, przy okazji: istnieje faktycznie szósta klasa białek błonowych, zwanych białkami zakotwiczonymi w ogonie (TA), które po prostu mają hydrofobowy terminus C, który przykleja się do błony, ale nie wystaje po drugiej stronie. Dlaczego wszystkie te zakotwiczone w GPI białka nie mogłyby być po prostu białkami TA? Dlaczego komórki wyewoluowały tak skomplikowaną ścieżkę do syntezy kotwicy cukrowo-tłuszczowej zamiast tego, i dlaczego wyewoluowały ją tak wcześnie w grze – kotwice GPI są obecne w całym eukarioncie, w tym w wielu jednokomórkowych patogenach, które infekują ludzi.
Większość recenzji nie poświęciła wiele czasu na to pytanie, prawdopodobnie dlatego, że jest to najtrudniejsza rzecz do odpowiedzi. Same białka zakotwiczone w GPI, w stopniu, w jakim znane są ich natywne funkcje, mają ogromny zakres funkcji – są enzymy (takie jak AChE), cząsteczki adhezji komórkowej (takie jak NCAM1), białka regulujące dopełniacz w układzie odpornościowym (CD59) i tak dalej . Najwyraźniej istnieje co najmniej jedno białko zakotwiczone w GPI zaangażowane w utrzymanie mieliny w nerwach obwodowych. Ale co dokładnie mogą robić białka zakotwiczone w GPI, czego nie mogą robić inne białka? Jeden z przeglądów przytacza kilka pomysłów, które zostały zaproponowane. Jednym z nich jest to, że białka zakotwiczone w GPI są dobre w przejściowym dimeryzowaniu. W niektórych badaniach analizowano koncepcję, że homodimeryzacja odgrywa pewną rolę w biologii prionów, choć nie jest jeszcze jasne, jakie znaczenie dla sytuacji in vivo mają stosowane tam systemy modelowe. Innym pomysłem jest to, że ponieważ białka zakotwiczone w GPI mogą być usuwane z powierzchni komórki, na przykład przez enzym konwertujący angiotensynę (ACE), ich lokalizacja może być regulowana w jakiś dynamiczny sposób. Również w tym przypadku wiemy, że PrP może być usuwany, najwyraźniej przez enzym ADAM10 , chociaż jakakolwiek rola w natywnej funkcji PrP nie jest jeszcze jasna. Trzeci pomysł, i być może ten, o którym słyszałem najwięcej, jest taki, że białka zakotwiczone w GPI selektywnie gromadzą się w „tratwach lipidowych”. Jest to być może najbardziej kuszące wyjaśnienie, ponieważ można sobie wyobrazić wszelkiego rodzaju efekty domina, gdzie zwiększona efektywna lokalna koncentracja tych białek pozwala na więcej interakcji, i tak dalej. Ale jeden przegląd wskazał, że zastrzeżeniem jest to, że tratwy lipidowe są nadal bardziej abstrakcyjną ideą niż konkretną rzeczą – podczas gdy są one funkcjonalnie zdefiniowane przez nierozpuszczalność detergentu i większość ludzi opisuje je jako bogate w sfingomielinę i cholesterol, nie ma powszechnie przyjętej definicji tego, co jest, a co nie jest tratwą lipidową, a dowody empiryczne sugerują, że mogą one być znacznie mniejsze i bardziej przejściowe niż większość ludzi myśli.
Z tym czytaniem w ręku, wyruszyłem, aby uzyskać listę tych białek i zrobić kilka analiz na nich, aby zobaczyć, czy mogę uzyskać lepsze wyczucie tego, co oni są jak.
analizy
Uniprot ma listę 173 ludzkich białek zakotwiczonych w GPI. Te zmapowane do 140 symboli genów, które spadły do 135 po uruchomieniu tego skryptu, aby zaktualizować do obecnie zatwierdzonych przez HGNC symboli genów kodujących białka. Ostateczna lista 135 symboli genów jest tutaj.
Uniprot nie oferuje żadnych informacji o tym, jak ich adnotacje zostały wygenerowane, chociaż musi być znaczny stopień ręcznej kurateli. Dla porównania, Andrew wykopał również serię zgrabnych prac, które wykorzystywały PI-PLD lub PI-PLC, dwa enzymy rozszczepiające kotwice GPI, do empirycznej izolacji białek zakotwiczonych w GPI z komórek. Łącząc listy z tych prac i mapując je do aktualnych symboli genów otrzymaliśmy 107 genów. Sprawdziliśmy losowo kilka z nich. Wśród nich były dobrze znane białka zakotwiczone w GPI, takie jak glipikan-1 (GPC1) i cząsteczka adhezji komórek nerwowych (NCAM1), z których oba mają interakcje z PrP. Jednak obecnych było również kilka genów, dla których zakotwiczenie GPI nie wydaje się być znane w literaturze, takich jak VDAC3, z których niektóre mogą być po prostu bardzo obfitymi białkami lub fałszywymi pozytywami z innych powodów. Tymczasem istnieją oczywiste źródła fałszywych negatywów: geny, które po prostu nie ulegały ekspresji w badanej linii komórkowej lub nie były wystarczająco obfite, aby wykryć je za pomocą spektroskopii masowej, a także paralogi PrP – SPRN i PRND nie znalazły się na listach. W sumie 51 genów znalazło się na obu listach, co stanowi bardzo istotne wzbogacenie (OR = 217, P < 1 × 10-84), które upewnia mnie, że anotacje Uniprot są zgodne z danymi empirycznymi. Ale dla dalszych analiz zdecydowaliśmy się iść z listy Uniprot jak to wydaje się bardziej wrażliwe i specyficzne.
Uzbrojony w tej liście, chciałem zobaczyć, jak GPI zakotwiczone białka stosy się. PrP jest pojedynczym eksonem, krótkim (208 aminokwasów w swojej dojrzałej formie), nieistotnym, szeroko eksprymowanym białkiem. Czy te cechy są typowe lub nietypowe dla białek zakotwiczonych w GPI?
Okazuje się, że białka zakotwiczone w GPI są na całej mapie, tak samo zmienne na każdym wymiarze, na który patrzyłem, jak każdy inny zestaw białek są.
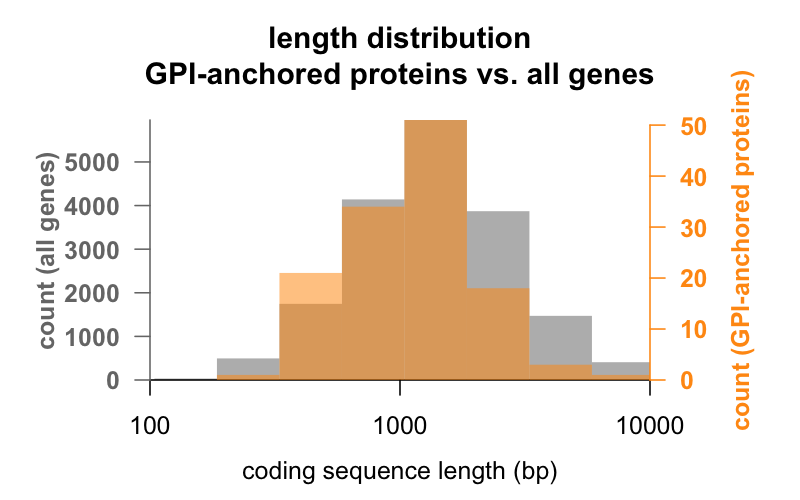
Po pierwsze, długość. Poniżej znajdują się nałożone na siebie histogramy długości sekwencji kodującej w parach zasad dla wszystkich genów, w porównaniu z genami kodującymi białka zakotwiczone w GPI. Rozkład GPI-zakotwiczonych jest ledwie przesunięty w lewo. Przeciętny gen koduj±cy białko zakotwiczone w GPI ma 1 301 bp sekwencji koduj±cej, podczas gdy przeciętny gen ma 1 729, ale ta różnica ¶rednich jest niewielka w porównaniu ze zmienno¶ci± w obrębie każdej grupy. PrP, z zaledwie 762 bp sekwencji kodującej, jest zdecydowanie po stronie małych, choć w żadnym wypadku nie jest wyjątkiem w żadnej z grup – CD52, z zaledwie 186 parami bazowymi sekwencji i najwyraźniej tylko 12 aminokwasami w swojej dojrzałej formie , jest najmniejszym białkiem zakotwiczonym w GPI.
Co z liczbą eksonów? Białka zakotwiczone w GPI mają średnio nieco mniej eksonów w porównaniu do wszystkich genów (średnia 7,8 vs. 10,1), co jest zgodne z niewielką różnicą w rozkładzie długości zauważoną powyżej, ale większość z nich jest wieloeksonowa. Również tutaj PrP jest po stronie małych genów: istnieje tylko sześć białek zakotwiczonych w GPI, które mają tylko 1 kodujący egzon, a trzy z nich to PrP i jego dwa paralogi, Sho i Dpl. (Pozostałe trzy geny to GAS1, SPACA4, i bajecznie nazwany OMG).
Następnie przyjrzałem się ograniczeniu utraty funkcji. Ograniczenie jest miarą tego, jak silna jest naturalna selekcja genu, oparta na tym, jak bardzo jest on uszczuplony dla, powiedzmy, nonsensu, przesunięcia ramki i zmiany miejsca splotu w ogólnej populacji w porównaniu do oczekiwań opartych na wskaźnikach mutacji. Ta metryka nie jest zbyt interpretowalna dla krótkich genów, zarówno z powodów statystycznych (liczba oczekiwanych mutacji jest niska dla krótkich genów, więc trudno jest określić ilościowo zubożenie), jak i biologicznych (geny pojedynczego eksonu nie podlegają nonsensownemu rozpadowi, więc trudniej jest wiedzieć, czy warianty przerywające białko są naprawdę „utratą funkcji”, czy nie). Ale ponieważ większość białek zakotwiczonych w GPI nie jest tak krótka jak PrP, pomyślałem, że warto się temu przyjrzeć. Wynik: średnio, białka zakotwiczone w GPI są nieco mniej ograniczone, co oznacza, że mają więcej oczekiwanej ilości wariantów utraty funkcji, niż przeciętny gen. Przeciętny gen ma 47% swojej zmienności utraty funkcji, a białka zakotwiczone w GPI mają 56%. Ale jak ze wszystkim tutaj, istnieje szeroka dystrybucja w obu obozach. Dla białek zakotwiczonych w GPI, masz absolutnie ograniczone ACHE (17 LoF oczekiwanych i żadnych obserwowanych) na jednym końcu i na drugim końcu, kilka genów, które wydają się być pod żadną selekcją przeciwko utracie funkcji w ogóle – CNTN6, CD109, TREH i MSLN są kilkoma przykładami. PRNP należy do tego ostatniego obozu, gdy wykluczy się reszty ≥145, gdzie warianty rozcinające białko powodują zysk funkcji.
Wreszcie zastanawiałem się, gdzie białka zakotwiczone w GPI są wyrażane. PRNP jest najwyższy w mózgu, ale jest wyrażany wszędzie. Czy to jest typowe? Pobrałem pełny plik podsumowujący GTEx v7 „gene median tpm” (Jan 15, 2016), gdzie każdy wiersz to gen, a każda kolumna to tkanka, a komórki to RPKM – RNA-seq reads per kilobase of exon per million mapped reads. Praca z tym zbiorem danych wymagała trochę finezji. Słyszałem, że niektórzy bioinformatycy uważają <1 RPKM za „niewyrażone”, ale macierz ekspresji jest skąpa – większość genów nie wykazuje wysokiej ekspresji w większości tkanek – więc szum poniżej 1 RPKM może dominować, jeśli po prostu wykreślisz surowe RPKM. Tymczasem ekspresja genów jest czymś, co musisz myśleć o skali logicznej, ponieważ geny w tkance mogą się różnić od <1 RPKM do >10,000 RPKM, więc jeśli rozważasz wszystko w skali liniowej, wtedy kilka naprawdę wysoko wyrażonych kombinacji genów/tkanek może również dominować, sprawiając, że matryca wygląda jeszcze bardziej rozproszona niż jest. Dlatego wziąłem log10 macierzy i obcięłem dystrybucję na , tak więc fioletowa skala, której użyłem, biegnie 1 – 10 – 100 – 1,000 – 10,000 RPKM. Następnie dokonałem podzbioru na białka zakotwiczone w Uniprot GPI. Aby to zwizualizować, po raz pierwszy w życiu zrobiłem mapę cieplną. Często widziałem je w gazetach i zwykle do mnie nie przemawiają, ale tutaj moim celem było po prostu zorientowanie się we wzorcu ekspresji, a po pobawieniu się trochę, to było to, co dało mi największy wgląd. Zasada mapy cieplnej polega na tym, że wiersze i kolumny są pogrupowane tak, że podobne rzeczy idą razem. Tak więc, na przykład, wszystkie kolumny tkanki mózgowej są ułożone kolejno w łatę na osi x, a wszystkie geny o wysokiej ekspresji mózgowej są ułożone kolejno w łatę na osi y, tak że ich przecięcie tworzy gęsty fioletowy prostokąt, który można interpretować jako „istnieje skupisko genów, które są w większości eksprymowane w mózgu”.
Zainteresowani czytelnicy mogą obejrzeć pełnowymiarowy wektorowy plik PDF mapy ciepła, ale aby uczynić ją bardziej dostępną od razu, poniżej znajduje się ręcznie zanotowana wersja określająca klastry zainteresowania:

Odpowiedź brzmi więc: nie – większość białek zakotwiczonych w GPI nie ma takiego samego wzorca ekspresji jak PRNP. PRNP jest jednym z garstki bardziej wysoko i szeroko wyrażonych, znajdując się blisko szczytu tej mapy ciepła, wraz z CD59, LY6E, GPC1 i BST2. Większość białek zakotwiczonych w GPI ma niższą lub bardziej ograniczoną tkankowo ekspresję, z niektórymi prawie wyłącznie wyrażanymi w mózgu i innymi prawie wyłącznie nie wyrażanymi w mózgu, oraz innymi mniejszymi skupiskami należącymi głównie do specyficznych tkanek, takich jak jądra, takich jak paralog PrP – PRND, którego nokaut powoduje męską bezpłodność.
wnioski
Białka zakotwiczone w GPI mogą mieć prawie każdy rozmiar, wyrażać się w prawie każdej tkance i najwyraźniej mieć prawie każdą funkcję, w stopniu, w jakim ich funkcje są znane. Wiele białek zakotwiczonych w GPI ma bardzo wyraźne funkcje natywne, ale te funkcje są zróżnicowane i nie jest jasne, dlaczego wymagają zakotwiczenia w GPI, zwłaszcza że wiele z tych białek istnieje w izoformach nie zakotwiczonych w GPI, jak również. Tymczasem w przypadku innych białek zakotwiczonych w GPI, w tym PrP, niewiele wiemy o funkcji natywnej, więc trudno jest nawet spekulować, dlaczego funkcja natywna wymaga zakotwiczenia w GPI. Żadna z analiz, które przeprowadziłem lub przeglądów, które czytałem nie była w stanie wyciągnąć jednoczącej zasady, dlaczego ten mechanizm zakotwiczenia istnieje lub co sprawia, że te białka go wymagają. Istnieje wiele hipotez, dlaczego białka zakotwiczone w GPI są wyjątkowe, w tym tratwy lipidowe, homodimery i zrzucanie. Wszystkie te hipotezy mogą mieć pewne uzasadnienie. Ale na koniec dnia, odpowiedź wydaje się mało prawdopodobne, aby być moment eureka, ale raczej, jak wiele z biologii, prozaiczna mieszanka różnych rzeczy.
Kod R i surowe pliki danych do analiz w tym poście są tutaj.
.