
Zanim rozpocząłem tę podróż, próbując nauczyć się informatyki, były pewne terminy i zwroty, które sprawiały, że chciałem uciec w przeciwnym kierunku.
Ale zamiast uciekać, udawałem, że je znam, przytakując w rozmowach, udając, że wiem, do czego ktoś się odnosi, mimo że prawda była taka, że nie miałem pojęcia i właściwie przestałem słuchać całkowicie, gdy usłyszałem ten super przerażający termin z dziedziny informatyki. W trakcie tej serii, udało mi się pokryć wiele gruntu i wiele z tych terminów faktycznie stały się całe mnóstwo mniej przerażające!
Jest jeden duży, choć, że unikałem przez jakiś czas. Do tej pory, ilekroć słyszałem ten termin, czułem się sparaliżowany. Pojawiał się on w luźnych rozmowach na spotkaniach, a czasem na konferencjach. Za każdym razem, myślę o maszynach wirujących i komputerach wypluwających ciągi kodu, które są nie do rozszyfrowania, z wyjątkiem tego, że wszyscy inni wokół mnie mogą faktycznie je rozszyfrować, więc to właściwie tylko ja, który nie wie, co się dzieje (whoops jak to się stało?!).
Prawdopodobnie nie jestem jedynym, który czuł się w ten sposób. Ale, przypuszczam, że powinienem ci powiedzieć, czym właściwie jest ten termin, prawda? Cóż, przygotuj się, ponieważ mam na myśli zawsze nieuchwytne i pozornie mylące abstrakcyjne drzewo składniowe, w skrócie AST. Po wielu latach bycia onieśmielonym, jestem podekscytowany, że w końcu przestałem się bać tego terminu i naprawdę rozumiem, czym on jest.
Czas zmierzyć się z korzeniem abstrakcyjnego drzewa składniowego – i podnieść poziom naszej gry w parsowanie!
Każde dobre zadanie zaczyna się od solidnych podstaw, a nasza misja zdemistyfikowania tej struktury powinna zacząć się dokładnie w ten sam sposób: od definicji, oczywiście!
Abstrakcyjne drzewo składniowe (zwykle określane jako AST) to tak naprawdę nic innego jak uproszczona, skondensowana wersja drzewa parsowania. W kontekście projektowania kompilatorów, termin „AST” jest używany zamiennie z drzewem składni.

Często myślimy o drzewach składniowych (i o tym, jak są one konstruowane) w porównaniu do ich odpowiedników w postaci drzew parseków, które są nam już całkiem dobrze znane. Wiemy, że drzewa parse są drzewiastymi strukturami danych, które zawierają strukturę gramatyczną naszego kodu; innymi słowy, zawierają wszystkie informacje składniowe, które pojawiają się w „zdaniu” kodu i pochodzą bezpośrednio z gramatyki samego języka programowania.
Abstrakcyjne drzewo składniowe, z drugiej strony, ignoruje znaczną ilość informacji składniowych, które w przeciwnym razie zawierałoby drzewo parse.
W przeciwieństwie do tego, AST zawiera tylko informacje związane z analizą tekstu źródłowego i pomija wszelkie inne dodatkowe treści, które są używane podczas parsowania tekstu.
To rozróżnienie zaczyna mieć dużo więcej sensu, jeśli skupimy się na „abstrakcyjności” AST.
Przypominamy, że drzewo parsekcyjne jest ilustrowaną, obrazową wersją struktury gramatycznej zdania. Innymi słowy, możemy powiedzieć, że drzewo parseków reprezentuje dokładnie to, jak wygląda wyrażenie, zdanie lub tekst. Jest to w zasadzie bezpośrednie tłumaczenie samego tekstu; bierzemy zdanie i zamieniamy każdy jego mały fragment – od interpunkcji, przez wyrażenia, po tokeny – w drzewiastą strukturę danych. Ujawnia to konkretną składnię tekstu, dlatego też jest również określane jako konkretne drzewo składniowe, lub CST. Używamy terminu konkretne, aby opisać tę strukturę, ponieważ jest to gramatyczna kopia naszego kodu, token po tokenie, w formacie drzewa.
Ale co sprawia, że coś jest konkretne w porównaniu z abstrakcyjnym? Cóż, abstrakcyjne drzewo składniowe nie pokazuje nam dokładnie, jak wygląda wyrażenie, w sposób, w jaki robi to drzewo parse.

Raczej, abstrakcyjne drzewo składniowe pokazuje nam „ważne” kawałki – rzeczy, na których nam naprawdę zależy, które nadają znaczenie naszemu kodowi „zdanie” samo w sobie. Drzewa składniowe pokazują nam istotne kawałki wyrażenia, lub wyabstrahowaną składnię naszego tekstu źródłowego. Stąd, w porównaniu z konkretnymi drzewami składni, struktury te są abstrakcyjną reprezentacją naszego kodu (i pod pewnymi względami mniej dokładną), i właśnie stąd wzięła się ich nazwa.
Teraz, gdy rozumiemy różnicę pomiędzy tymi dwoma strukturami danych i różnymi sposobami, na jakie mogą one reprezentować nasz kod, warto zadać pytanie: gdzie abstrakcyjne drzewo składni pasuje do kompilatora? Najpierw przypomnijmy sobie wszystko, co wiemy o procesie kompilacji, jaki znamy do tej pory.

Powiedzmy, że mamy super krótki i słodki tekst źródłowy, który wygląda tak: 5 + (1 x 12).
Przypomnimy sobie, że pierwszą rzeczą, która dzieje się w procesie kompilacji, jest skanowanie tekstu, zadanie wykonywane przez skaner, w wyniku którego tekst jest rozbijany na jego najmniejsze możliwe części, które nazywamy leksemami. Ta część będzie niezależna od języka, a my skończymy z rozebraną wersją naszego tekstu źródłowego.
Następnie, te właśnie leksemy są przekazywane do lexera/tokenizatora, który zamienia te małe reprezentacje naszego tekstu źródłowego w tokeny, które będą specyficzne dla naszego języka. Nasze tokeny będą wyglądały mniej więcej tak: . Wspólny wysiłek skanera i tokenizera składa się na analizę leksykalną kompilacji.
Następnie, gdy nasze dane wejściowe zostały tokenizowane, ich wynik jest przekazywany do naszego parsera, który następnie bierze tekst źródłowy i buduje z niego drzewo parsowania. Poniższa ilustracja pokazuje, jak wygląda nasz tokenizowany kod w formacie drzewa parsekcyjnego.
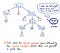
Praca polegająca na przekształcaniu tokenów w drzewo parsekcyjne jest również nazywana parsowaniem i jest znana jako faza analizy składni. Faza analizy składni zależy bezpośrednio od fazy analizy leksykalnej; dlatego analiza leksykalna musi być zawsze na pierwszym miejscu w procesie kompilacji, ponieważ parser naszego kompilatora może wykonać swoją pracę tylko wtedy, gdy tokenizer wykona swoją pracę!
Możemy myśleć o częściach kompilatora jak o dobrych przyjaciołach, którzy wszyscy zależą od siebie nawzajem, aby upewnić się, że nasz kod jest poprawnie przekształcony z tekstu lub pliku w drzewo parsowania.
Ale wracając do naszego pierwotnego pytania: gdzie abstrakcyjne drzewo składniowe pasuje do tej grupy przyjaciół? Cóż, aby odpowiedzieć na to pytanie, należy zrozumieć potrzebę istnienia AST w pierwszej kolejności.
Kondensacja jednego drzewa w drugie
Dobrze, więc teraz mamy dwa drzewa, które musimy trzymać prosto w naszych głowach. Mieliśmy już drzewo parse, a tu jeszcze jedna struktura danych do nauczenia się! I najwyraźniej, ta struktura danych AST jest tylko uproszczonym drzewem parseków. Więc, po co nam to? Jaki jest tego cel?
Przyjrzyjrzyjmy się naszemu drzewu parseków, dobrze?
Wiemy już, że drzewa parseków reprezentują nasz program w jego najbardziej wyraźnych częściach; w rzeczy samej, to dlatego skaner i tokenizer mają tak ważne zadania rozbijania naszego wyrażenia na jego najmniejsze części!
Co to właściwie znaczy reprezentować program w jego najbardziej wyraźnych częściach?
Jak się okazuje, czasami wszystkie odrębne części programu nie są dla nas aż tak użyteczne przez cały czas.
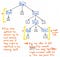
Przyjrzyjmy się przedstawionej tu ilustracji, która reprezentuje nasze oryginalne wyrażenie, 5 + (1 x 12), w formacie drzewa parsekcyjnego. Jeśli przyjrzymy się temu drzewu krytycznym okiem, zobaczymy, że istnieje kilka przypadków, w których jeden węzeł ma dokładnie jedno dziecko. Węzły te są również nazywane węzłami pojedynczego następcy, ponieważ mają tylko jeden węzeł potomny wynikający z nich (lub jeden „następca”).
W przypadku naszego przykładu drzewa parsekcyjnego, węzły pojedynczego następcy mają węzeł nadrzędny Expression, lub Exp, które mają pojedynczego następcę o pewnej wartości, takiej jak 5, 1, lub 12. Jednakże, węzły nadrzędne Exp nie dodają do nas nic wartościowego, prawda? Widzimy, że zawierają one węzły potomne tokenów/terminali, ale tak naprawdę nie obchodzi nas węzeł nadrzędny „wyrażenie”; wszystko, co naprawdę chcemy wiedzieć, to jakie jest to wyrażenie?
Węzeł nadrzędny nie daje nam żadnych dodatkowych informacji po sparsowaniu naszego drzewa. Zamiast tego, to co nas naprawdę interesuje, to węzeł z pojedynczym dzieckiem i pojedynczym następnikiem. W rzeczywistości jest to węzeł, który daje nam ważne informacje, część, która jest dla nas istotna: liczbę i wartość! Biorąc pod uwagę fakt, że te węzły nadrzędne są dla nas zbędne, staje się oczywiste, że to drzewo parsekcyjne jest w pewnym sensie nieczytelne.
Wszystkie te węzły pojedynczego następnika są dla nas zbędne i w ogóle nam nie pomagają. Więc pozbądźmy się ich!
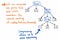
Jeśli skompresujemy węzły pojedynczego następcy w naszym drzewie parseków, w końcu otrzymamy bardziej skompresowaną wersję tej samej dokładnej struktury. Patrząc na powyższą ilustrację, zobaczymy, że wciąż zachowujemy dokładnie takie samo zagnieżdżenie jak poprzednio, a nasze węzły/tokeny/terminale wciąż pojawiają się we właściwym miejscu w drzewie. Ale, udało nam się je trochę odchudzić.
I możemy również przyciąć trochę więcej naszego drzewa. Na przykład, jeśli spojrzymy na nasze drzewo parsowania w obecnej postaci, zobaczymy, że istnieje w nim struktura lustrzana. Podwyrażenie (1 x 12) jest zagnieżdżone wewnątrz nawiasów (), które same w sobie są tokenami.
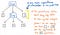
Jednakże te nawiasy tak naprawdę nie pomagają nam, gdy już mamy nasze drzewo. Wiemy już, że 1 i 12 są argumentami, które zostaną przekazane do operacji mnożenia x, więc nawiasy nie mówią nam zbyt wiele w tym momencie. W rzeczywistości, moglibyśmy skompresować nasze drzewo parseków jeszcze bardziej i pozbyć się tych zbędnych węzłów liści.
Kiedy skompresujemy i uprościmy nasze drzewo parseków i pozbędziemy się zbędnego „kurzu” składniowego, otrzymamy strukturę, która w tym momencie wygląda wyraźnie inaczej. Ta struktura jest w rzeczywistości naszym nowym i wyczekiwanym przyjacielem: abstrakcyjnym drzewem składni.

Powyższy obrazek ilustruje dokładnie to samo wyrażenie, co nasze drzewo parseków: 5 + (1 x 12). Różnica polega na tym, że AST abstrahuje od konkretnej składni tego wyrażenia. Nie widzimy więcej nawiasów () w tym drzewie, ponieważ nie są one potrzebne. Podobnie, nie widzimy nie-terminali takich jak Exp, ponieważ już zorientowaliśmy się czym jest „wyrażenie” i jesteśmy w stanie wyciągnąć wartość, która naprawdę ma dla nas znaczenie – na przykład liczbę 5.
To jest właśnie czynnik odróżniający AST od CST. Wiemy, że abstrakcyjne drzewo składniowe ignoruje znaczną część informacji składniowej, którą zawiera drzewo parsowania i pomija „dodatkową zawartość”, która jest używana podczas parsowania. Ale teraz możemy dokładnie zobaczyć, jak to się dzieje!

Teraz, gdy skondensowaliśmy nasze własne drzewo parsowania, będziemy o wiele lepsi w wyłapywaniu niektórych wzorców, które odróżniają AST od CST.
Istnieje kilka sposobów, na które abstrakcyjne drzewo składniowe będzie się wizualnie różnić od drzewa parsekcyjnego:
- An AST nigdy nie będzie zawierać szczegółów składniowych, takich jak przecinki, nawiasy i średniki (oczywiście w zależności od języka).
- An AST będzie mieć zawalone wersje tego, co w przeciwnym razie pojawiłoby się jako węzły z pojedynczym następnikiem; nigdy nie będzie zawierać „łańcuchów” węzłów z pojedynczym dzieckiem.
- Wreszcie, wszelkie tokeny operatorów (takie jak
+,-,xi/) staną się wewnętrznymi (rodzicielskimi) węzłami w drzewie, a nie liśćmi, które kończą się w drzewie parseków.
Wizualnie, AST zawsze będzie wydawać się bardziej zwarta niż drzewo parseków, ponieważ jest to, z definicji, skompresowana wersja drzewa parseków, z mniejszą ilością szczegółów składniowych.
Więc, jeśli AST jest skompresowaną wersją drzewa parseków, to możemy stworzyć abstrakcyjne drzewo składniowe tylko wtedy, gdy mamy rzeczy do zbudowania drzewa parseków na początek!
Właśnie w ten sposób abstrakcyjne drzewo składniowe pasuje do większego procesu kompilacji. AST ma bezpośrednie połączenie z drzewami parse, o których już się dowiedzieliśmy, jednocześnie polegając na lexerze, aby wykonać swoją pracę, zanim AST może zostać kiedykolwiek utworzony.

Abstrakcyjne drzewo składniowe jest tworzone jako końcowy rezultat fazy analizy składniowej. Parser, który jest głównym „bohaterem” podczas analizy składni, może, ale nie zawsze musi wygenerować drzewo parsowania, czyli CST. W zależności od kompilatora i tego, jak został zaprojektowany, parser może bezpośrednio przejść do konstruowania drzewa składni, czyli AST. Ale parser zawsze wygeneruje AST jako wyjście, bez względu na to, czy w międzyczasie utworzy drzewo parsekcyjne, lub ile przejść będzie musiał wykonać, aby to zrobić.
Anatomia AST
Teraz, gdy wiemy, że abstrakcyjne drzewo składniowe jest ważne (ale niekoniecznie przerażające!), możemy zacząć je trochę bardziej rozbierać. Interesujący aspekt tego, jak skonstruowany jest AST, ma związek z węzłami tego drzewa.
Poniższy obrazek przedstawia przykład anatomii pojedynczego węzła w obrębie drzewa składni abstrakcyjnej.
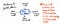
Zauważymy, że ten węzeł jest podobny do innych, które widzieliśmy wcześniej w tym, że zawiera pewne dane (a token i jego value). Jednakże, zawiera on również pewne bardzo specyficzne wskaźniki. Każdy węzeł w AST zawiera odniesienia do swojego następnego węzła rodzeństwa, jak również do swojego pierwszego węzła potomnego.
Na przykład, nasze proste wyrażenie 5 + (1 x 12) może być skonstruowane w formie wizualnej ilustracji AST, jak ta poniżej.

Możemy sobie wyobrazić, że czytanie, przemierzanie, lub „interpretowanie” tego AST może zacząć się od najniższych poziomów drzewa, pracując z powrotem w górę, aby zbudować wartość lub zwrot result na końcu.
Pomocne może być również zobaczenie zakodowanej wersji wyjścia parsera, aby pomóc uzupełnić nasze wizualizacje. Możemy oprzeć się na różnych narzędziach i użyć istniejących parserów, aby zobaczyć szybki przykład tego, jak nasze wyrażenie może wyglądać po przepuszczeniu przez parser. Poniżej znajduje się przykład naszego tekstu źródłowego, 5 + (1 * 12), przepuszczonego przez Esprima, parser ECMAScript, i jego wynikowe abstrakcyjne drzewo składniowe, wraz z listą jego odrębnych tokenów.
W tym formacie, możemy zobaczyć zagnieżdżenie drzewa, jeśli spojrzymy na zagnieżdżone obiekty. Zauważymy, że wartości zawierające 1 i 12 są odpowiednio left i right dziećmi operacji nadrzędnej, *. Zauważymy również, że operacja mnożenia (*) tworzy prawe poddrzewo całego wyrażenia, dlatego jest zagnieżdżona w większym obiekcie BinaryExpression, pod kluczem "right". Podobnie wartość 5 jest pojedynczym "left" dzieckiem większego obiektu BinaryExpression.

Najbardziej intrygującym aspektem abstrakcyjnego drzewa składni jest jednak fakt, że mimo iż są one tak zwarte i czyste, nie zawsze są łatwą strukturą danych, którą można spróbować skonstruować. W rzeczywistości, budowanie AST może być dość skomplikowane, w zależności od języka, z którym parser ma do czynienia!
Większość parserów zazwyczaj albo konstruuje drzewo parsowania (CST), a następnie konwertuje je do formatu AST, ponieważ czasami może to być łatwiejsze – nawet jeśli oznacza to więcej kroków i ogólnie mówiąc, więcej przejść przez tekst źródłowy. Budowanie CST jest właściwie całkiem proste, gdy parser zna gramatykę języka, który próbuje przetworzyć. Nie musi wykonywać żadnej skomplikowanej pracy polegającej na ustaleniu, czy token jest „znaczący” czy nie; zamiast tego, po prostu bierze dokładnie to, co widzi, w określonej kolejności i wypluwa to wszystko do drzewa.
Z drugiej strony, są parsery, które spróbują zrobić to wszystko jako proces jednoetapowy, skacząc prosto do konstruowania abstrakcyjnego drzewa składni.
Budowanie AST bezpośrednio może być podchwytliwe, ponieważ parser musi nie tylko znaleźć tokeny i reprezentować je poprawnie, ale także zdecydować, które tokeny mają dla nas znaczenie, a które nie.
W projektowaniu kompilatorów, AST kończy się byciem super ważnym z więcej niż jednego powodu. Tak, może być trudna do skonstruowania (i prawdopodobnie łatwo ją zepsuć), ale także, jest to ostatni i ostateczny rezultat połączonych faz analizy leksykalnej i składniowej! Fazy analizy leksykalnej i składniowej są często wspólnie nazywane fazą analizy lub front-endem kompilatora.

Możemy myśleć o abstrakcyjnym drzewie składni jako o „końcowym projekcie” front-endu kompilatora. Jest to najważniejsza część, ponieważ jest to ostatnia rzecz, którą front-end ma do pokazania dla siebie. Techniczny termin dla tego nazywa się pośrednią reprezentacją kodu lub IR, ponieważ staje się strukturą danych, która jest ostatecznie używana przez kompilator do reprezentowania tekstu źródłowego.
An abstract syntax tree jest najczęstszą formą IR, ale także, czasami najbardziej niezrozumiałą. Ale teraz, gdy rozumiemy to trochę lepiej, możemy zacząć zmieniać nasze postrzeganie tej przerażającej struktury! Mamy nadzieję, że teraz jest ona dla nas trochę mniej przerażająca.
Źródła
Istnieje całe mnóstwo zasobów na temat AST, w różnych językach. Wiedza o tym, od czego zacząć, może być trudna, zwłaszcza jeśli chcesz dowiedzieć się więcej. Poniżej znajduje się kilka przyjaznych dla początkujących zasobów, które zagłębiają się w szczegóły, nie będąc przy tym zbyt przytłaczającymi. Happy asbtracting!
- The AST vs the Parse Tree, Professor Charles N. Fischer
- Jaka jest różnica między drzewami parseków a abstrakcyjnymi drzewami składni? StackOverflow
- Abstract vs. Concrete Syntax Trees, Eli Bendersky
- Abstract Syntax Trees, Profesor Stephen A. Edwards
- Abstract Syntax Trees & Top-Down Parsing, Profesor Konstantinos (Kostis) Sagonas
- Lexical and Syntax Analysis of Programming Languages, Chris Northwood
- AST Explorer, Felix Kling
.