Co to jest czyszczenie danych?
Czyszczenie danych to proces przygotowywania danych do analizy poprzez usuwanie lub modyfikowanie danych, które są nieprawidłowe, niekompletne, nieistotne, zduplikowane lub niewłaściwie sformatowane.
Dane te zazwyczaj nie są konieczne lub pomocne, jeśli chodzi o analizę danych, ponieważ mogą utrudniać proces lub dostarczać niedokładnych wyników. Istnieje kilka metod czyszczenia danych w zależności od tego, jak są one przechowywane wraz z poszukiwanymi odpowiedziami.
Czyszczenie danych nie polega po prostu na usuwaniu informacji, aby zrobić miejsce dla nowych danych, ale raczej na znalezieniu sposobu na zmaksymalizowanie dokładności zestawu danych bez konieczności usuwania informacji.
Dla jednego, czyszczenie danych obejmuje więcej działań niż usuwanie danych, takich jak naprawianie błędów ortograficznych i składniowych, standaryzacja zestawów danych i poprawianie błędów, takich jak puste pola, brakujące kody i identyfikacja zduplikowanych punktów danych. Czyszczenie danych jest uważane za podstawowy element podstaw nauki o danych, ponieważ odgrywa ważną rolę w procesie analitycznym i odkrywaniu wiarygodnych odpowiedzi.
Co najważniejsze, celem czyszczenia danych jest stworzenie zbiorów danych, które są znormalizowane i jednolite, aby umożliwić narzędziom business intelligence i analityki danych łatwy dostęp i znalezienie odpowiednich danych dla każdego zapytania.
Jak mogę użyć czyszczenia danych?
Niezależnie od rodzaju analizy lub wizualizacji danych, których potrzebujesz, czyszczenie danych jest niezbędnym krokiem do zapewnienia, że generowane odpowiedzi są dokładne. Podczas zbierania danych z wielu strumieni i ręcznego wprowadzania danych przez użytkowników, informacje mogą zawierać błędy, być nieprawidłowo wprowadzone lub mieć luki.
Czyszczenie danych pomaga zapewnić, że informacje zawsze pasują do właściwych pól, ułatwiając jednocześnie narzędziom business intelligence interakcję ze zbiorami danych w celu bardziej efektywnego wyszukiwania informacji. Jednym z najczęstszych przykładów czyszczenia danych jest jego zastosowanie w hurtowniach danych.

Skuteczna hurtownia danych przechowuje różnorodne dane z różnych źródeł i optymalizuje je pod kątem analizy przed wykonaniem jakiegokolwiek modelowania. W tym celu aplikacje hurtowni muszą przebrnąć przez miliony przychodzących punktów danych, aby upewnić się, że są one dokładne, zanim zostaną umieszczone w odpowiedniej bazie danych, tabeli lub innej strukturze.
Organizacje, które zbierają dane bezpośrednio od konsumentów wypełniających ankiety, kwestionariusze i formularze, również szeroko stosują czyszczenie danych. W ich przypadkach obejmuje to sprawdzenie, czy dane zostały wprowadzone do właściwego pola, czy nie zawierają nieprawidłowych znaków i czy nie ma luk w dostarczonych informacjach.
Zobacz to w akcji:
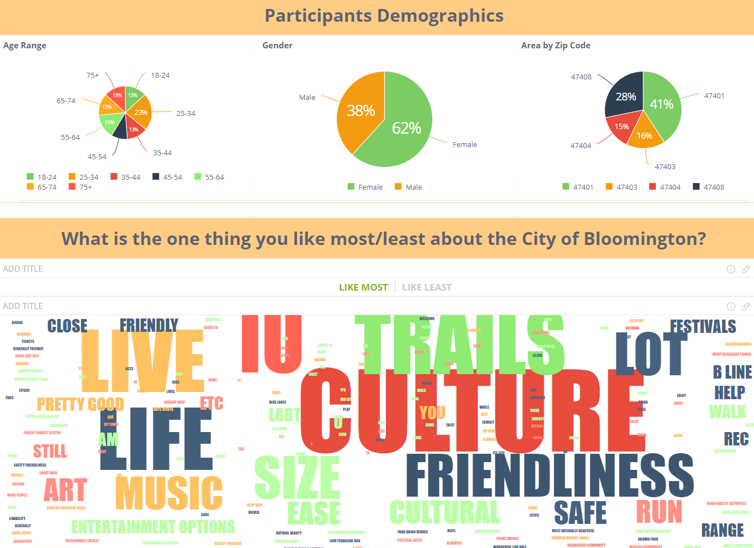 Explore Dashboard
Explore Dashboard