Overview
- Naucz się interpretować Bias i Variance w danym modelu.
- Jaka jest różnica pomiędzy Bias i Variance?
- Jak osiągnąć Bias i Variance Tradeoff używając Machine Learning workflow
Wprowadzenie
Porozmawiajmy o pogodzie. Pada tylko wtedy, gdy jest trochę wilgotno i nie pada, gdy jest wietrznie, gorąco lub mroźno. W tym przypadku, jak wyszkoliłbyś model predykcyjny i zapewniłbyś, że nie ma błędów w prognozowaniu pogody? Można powiedzieć, że istnieje wiele algorytmów uczenia się do wyboru. Są one różne pod wieloma względami, ale istnieje zasadnicza różnica w tym, czego oczekujemy i co przewiduje model. To jest koncepcja Bias and Variance Tradeoff.
Zwykle, Bias and Variance Tradeoff jest nauczany poprzez gęste formuły matematyczne. Ale w tym artykule starałem się wyjaśnić Bias i Variance tak prosto, jak to tylko możliwe!
Moim celem będzie przeprowadzenie Cię przez proces zrozumienia stwierdzenia problemu i zapewnienie, że wybierzesz najlepszy model, w którym błędy Bias i Variance są minimalne.
W tym celu podjąłem popularny zestaw danych Pima Indians Diabetes. Zestaw danych składa się z pomiarów diagnostycznych dorosłych pacjentek z rdzennych Indian Pima Heritage. W przypadku tego zbioru danych skupimy się na zmiennej „Wynik” – która wskazuje, czy pacjent ma cukrzycę, czy nie. Najwyraźniej jest to problem klasyfikacji binarnej i mamy zamiar zanurzyć się w nim i dowiedzieć się, jak to zrobić.
Jeśli jesteś zainteresowany tym i koncepcjami nauki o danych i chcesz się uczyć praktycznie, odnieś się do naszego kursu – Wprowadzenie do nauki o danych
Spis treści
- Ocena modelu uczenia maszynowego
- Problem i podstawowe kroki
- Co to jest Bias?
- Co to jest wariancja?
- Bias-Variance Tradeoff
Evaluating your Machine Learning Model
Podstawowym celem modelu uczenia maszynowego jest uczenie się na podstawie danych i generowanie przewidywań na podstawie wzorca zaobserwowanego podczas procesu uczenia. Jednak nasze zadanie nie kończy się na tym. Musimy na bieżąco wprowadzać poprawki do modelu, bazując na tym, jakie wyniki generuje. Określamy również wydajność modelu używając metryk takich jak Accuracy, Mean Squared Error(MSE), F1-Score, itp. i staramy się poprawić te metryki. To często może być trudne, gdy musimy zachować elastyczność modelu bez narażania na szwank jego poprawności.
Nadzorowany model uczenia maszynowego ma na celu wyszkolenie się na zmiennych wejściowych (X) w taki sposób, że przewidywane wartości (Y) są tak blisko rzeczywistych wartości, jak to możliwe. Różnica pomiędzy wartościami rzeczywistymi a przewidywanymi to błąd i jest on używany do oceny modelu. Błąd dla każdego nadzorowanego algorytmu uczenia maszynowego składa się z 3 części:
- Błąd skośności
- Błąd wariancji
- Szum
Podczas gdy szum jest nieredukowalnym błędem, którego nie możemy wyeliminować, dwa pozostałe tj.tj. błąd systematyczny i wariancja są redukowalnymi błędami, które możemy próbować zminimalizować tak bardzo, jak to tylko możliwe.
W kolejnych sekcjach omówimy błąd systematyczny, błąd wariancji i kompromis błąd systematyczny-wariancja, które pomogą nam w najlepszym wyborze modelu. I co jest ekscytujące, będziemy obejmować niektóre techniki radzenia sobie z tymi błędami przy użyciu przykładowego zestawu danych.
Problem Statement and Primary Steps
Jak wyjaśniono wcześniej, podjęliśmy zestaw danych Pima Indians Diabetes i utworzyliśmy problem klasyfikacji na nim. Zacznijmy od sprawdzenia zbioru danych i obserwacji rodzaju danych, z którymi mamy do czynienia. Zrobimy to poprzez zaimportowanie niezbędnych bibliotek:
Teraz załadujemy dane do ramki danych i będziemy obserwować niektóre wiersze, aby uzyskać wgląd w dane.
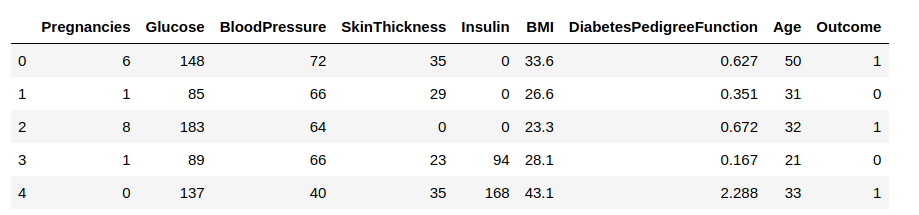
Musimy przewidzieć kolumnę 'Outcome’. Oddzielmy ją i przypiszmy do zmiennej docelowej „y”. Pozostała część ramki danych będzie zbiorem zmiennych wejściowych X.
Teraz przeskalujmy zmienne predykcyjne, a następnie oddzielmy dane treningowe i testowe.
Ponieważ wyniki są klasyfikowane w postaci binarnej, użyjemy najprostszego klasyfikatora K-najbliższych sąsiadów (Knn), aby sklasyfikować, czy pacjent ma cukrzycę, czy nie.
Jak jednak zdecydujemy o wartości 'k’?
- Może powinniśmy użyć k = 1, aby uzyskać bardzo dobre wyniki na naszych danych treningowych? To może zadziałać, ale nie możemy zagwarantować, że model będzie działał tak samo dobrze na naszych danych testowych, ponieważ może stać się zbyt specyficzny
- A może użyjemy wysokiej wartości k, powiedzmy k = 100, tak abyśmy mogli rozważyć dużą liczbę najbliższych punktów, aby uwzględnić również punkty odległe? Jednakże, ten rodzaj modelu będzie zbyt ogólny i nie możemy być pewni, czy rozważył on wszystkie możliwe cechy przyczyniające się prawidłowo.
Przyjmijmy kilka możliwych wartości k i dopasujmy model na danych treningowych dla wszystkich tych wartości. Obliczymy również wynik szkolenia i wynik testowania dla wszystkich tych wartości.
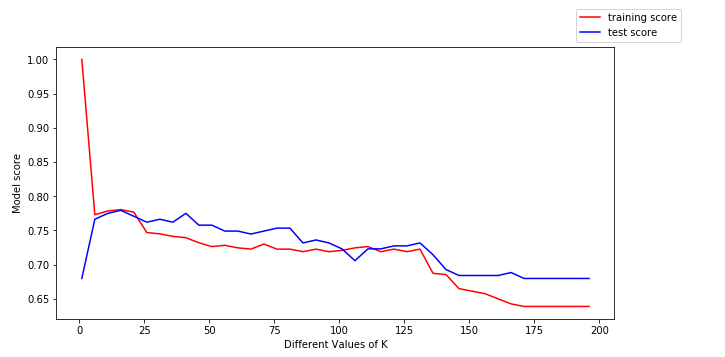
Aby wyciągnąć z tego więcej wniosków, wykreślmy dane szkoleniowe (na czerwono) i dane testowe (na niebiesko).
Aby obliczyć wyniki dla konkretnej wartości k,
![]()
Możemy wyciągnąć następujące wnioski z powyższego wykresu:
- Dla niskich wartości k, wynik szkolenia jest wysoki, podczas gdy wynik testowania jest niski
- Jak wartość k wzrasta, wynik testowania zaczyna rosnąć, a wynik szkolenia zaczyna maleć.
- Jednakże, przy pewnej wartości k, zarówno wynik szkolenia jak i wynik testowania są do siebie zbliżone.
To jest miejsce, w którym Bias i Wariancja wchodzą do obrazu.
Co to jest Bias?
W najprostszych słowach, Bias jest różnicą pomiędzy Wartością Przewidywaną a Wartością Oczekiwaną. Aby wyjaśnić dalej, model czyni pewne założenia, kiedy trenuje na dostarczonych danych. Kiedy jest on wprowadzany do danych testowych/walidacyjnych, założenia te nie zawsze mogą być poprawne.
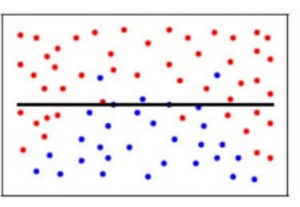
W naszym modelu, jeśli używamy dużej liczby najbliższych sąsiadów, model może całkowicie zdecydować, że niektóre parametry nie są w ogóle ważne. Na przykład, może po prostu uznać, że poziom glukozy i ciśnienie krwi decydują o tym, czy pacjent ma cukrzycę. Model ten przyjąłby bardzo silne założenia, że pozostałe parametry nie mają wpływu na wynik. Można również myśleć o nim jako o modelu przewidującym prostą zależność, gdy punkty danych wyraźnie wskazują na bardziej złożoną zależność:
Matematycznie, niech zmiennymi wejściowymi będą X i zmienna docelowa Y. Mapujemy zależność między nimi za pomocą funkcji f.
Thereforefore,
Y = f(X) + e
Here 'e’ is the error that is normally distributed. Celem naszego modelu f'(x) jest przewidywanie wartości jak najbardziej zbliżonych do f(x). Tutaj błąd systematyczny modelu wynosi:
Bias = E
Jak wyjaśniłem powyżej, gdy model dokonuje uogólnień, tj. gdy występuje wysoki błąd systematyczny, skutkuje to bardzo uproszczonym modelem, który nie uwzględnia dobrze zmian. Ponieważ nie uczy się danych szkoleniowych bardzo dobrze, nazywa się Underfitting.
Co to jest wariancja?
W przeciwieństwie do uprzedzenia, wariancja jest wtedy, gdy model bierze pod uwagę wahania w danych, tj. szum, jak również. Więc, co się stanie, gdy nasz model ma wysoką wariancję?
Model nadal będzie uważał wariancję jako coś, z czego można się uczyć. Oznacza to, że model uczy się zbyt wiele z danych treningowych, tak bardzo, że w konfrontacji z nowymi danymi (testowymi), nie jest w stanie dokładnie przewidzieć na ich podstawie.
Matematycznie, błąd wariancji w modelu jest:
Wariancja-E^2
Ponieważ w przypadku wysokiej wariancji, model uczy się zbyt wiele z danych treningowych, nazywa się to przepełnieniem.
W kontekście naszych danych, jeśli używamy bardzo niewielu najbliższych sąsiadów, to tak jakbyśmy powiedzieli, że jeśli liczba ciąż jest większa niż 3, poziom glukozy jest większy niż 78, rozkurczowe ciśnienie tętnicze jest mniejsze niż 98, grubość skóry jest mniejsza niż 23 mm i tak dalej dla każdej cechy….. zdecyduj, że pacjent ma cukrzycę. Wszyscy inni pacjenci, którzy nie spełniają powyższych kryteriów, nie są diabetykami. Chociaż może to być prawdą dla jednego konkretnego pacjenta w zbiorze treningowym, co jeśli te parametry są wartościami odstającymi lub nawet zostały zapisane nieprawidłowo? Najwyraźniej taki model mógłby okazać się bardzo kosztowny!
Dodatkowo model ten miałby wysoki błąd wariancji, ponieważ przewidywania, czy pacjent jest cukrzykiem, czy nie, różnią się znacznie w zależności od rodzaju danych szkoleniowych, które mu dostarczamy. Tak więc nawet zmiana poziomu glukozy na 75 spowodowałaby, że model przewidywałby, że pacjent nie ma cukrzycy.
Aby to uprościć, model przewiduje bardzo złożone zależności między wynikiem a cechami wejściowymi, podczas gdy wystarczyłoby równanie kwadratowe. Tak wyglądałby model klasyfikacyjny, gdy mamy do czynienia z wysokim błędem wariancji / gdy mamy do czynienia z przepasowaniem:
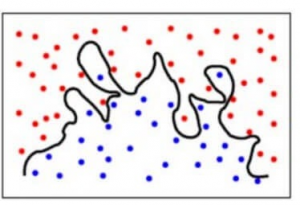
Podsumowując,
- Model z wysokim błędem skośności niedostosowuje danych i przyjmuje na ich temat bardzo uproszczone założenia
- Model z wysokim błędem wariancji nadmiernie dopasowuje dane i uczy się na ich podstawie zbyt wiele
- Dobry model to taki, w którym zarówno błędy skośności, jak i wariancji są zrównoważone
Bias-Variance Tradeoff
Jak odniesiemy powyższe koncepcje do naszego modelu Knn z wcześniejszych rozważań? Dowiedzmy się!
W naszym modelu, powiedzmy, dla, k = 1, punkt najbliższy danemu datapointowi będzie brany pod uwagę. Tutaj przewidywanie może być dokładne dla tego konkretnego punktu danych, więc błąd skośności będzie mniejszy.
Jednakże błąd wariancji będzie wysoki, ponieważ tylko jeden najbliższy punkt jest brany pod uwagę, a to nie uwzględnia innych możliwych punktów. Jak myślisz, do jakiego scenariusza to odpowiada? Tak, myślisz dobrze, oznacza to, że nasz model jest przepasowany.
Z drugiej strony, dla wyższych wartości k, wiele więcej punktów bliższych danemu datapointowi będzie branych pod uwagę. Z drugiej strony, dla wyższych wartości k, model będzie uwzględniał o wiele więcej punktów bliższych danemu punktowi, co spowoduje, że nie będzie w stanie nauczyć się specyfiki ze zbioru treningowego. Jednakże, możemy uwzględnić niższy błąd wariancji dla zbioru testowego, który ma nieznane wartości.
Aby osiągnąć równowagę pomiędzy błędem stronniczości i błędem wariancji, potrzebujemy wartości k takiej, że model ani nie uczy się z szumu (overfit na danych), ani nie robi zbyt daleko idących założeń na danych (underfit na danych). Dla uproszczenia, zrównoważony model wyglądałby następująco:
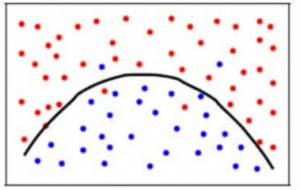
Chociaż niektóre punkty są klasyfikowane niepoprawnie, model ogólnie pasuje do większości punktów danych dokładnie. Równowaga między błędem skośności a błędem wariancji to kompromis między skośnością a wariancją.
Następujący diagram byczego oka lepiej wyjaśnia ten kompromis:
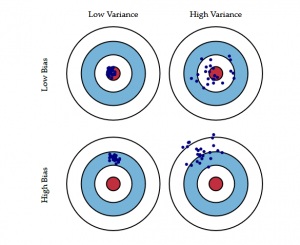
Środek, tj. bycze oko, to wynik modelu, który chcemy osiągnąć, który doskonale przewiduje wszystkie wartości prawidłowo. W miarę oddalania się od byczego oka, nasz model zaczyna dokonywać coraz bardziej błędnych przewidywań.
Model z niską skośnością i wysoką wariancją przewiduje punkty, które ogólnie znajdują się wokół centrum, ale są dość odległe od siebie. Model z wysoką skośnością i niską wariancją jest dość daleko od byka, ale ponieważ wariancja jest niska, przewidywane punkty są bliżej siebie.
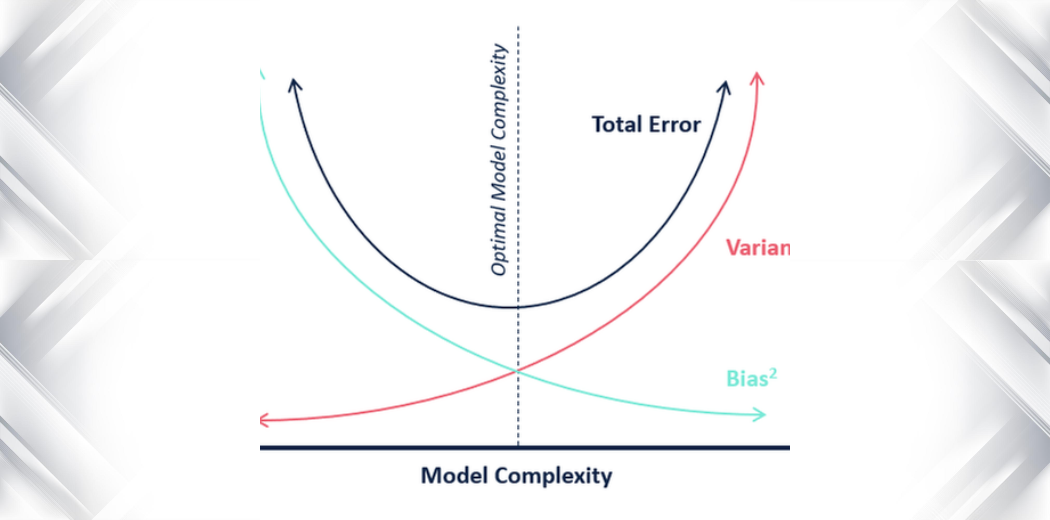
W odniesieniu do złożoności modelu, możemy użyć następującego diagramu, aby zdecydować o optymalnej złożoności naszego modelu.
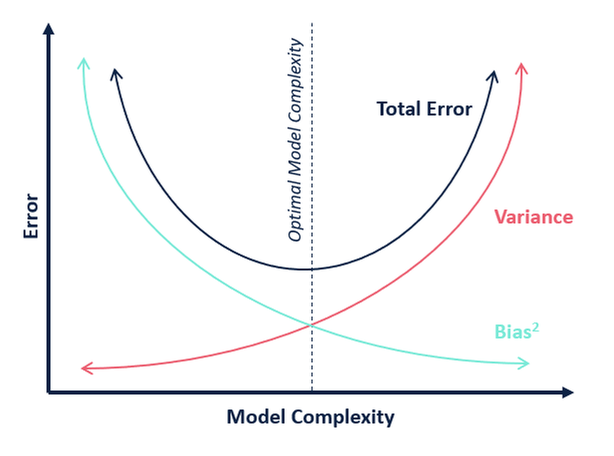
Więc, jak myślisz, jaka jest optymalna wartość dla k?
Z powyższego wyjaśnienia możemy wywnioskować, że k, dla którego
- wynik testowania jest najwyższy, a
- zarówno wynik testowania, jak i wynik szkolenia są do siebie zbliżone
jest optymalną wartością k. Tak więc, nawet jeśli idziemy na kompromis w sprawie niższego wyniku szkolenia, nadal uzyskujemy wysoki wynik dla naszych danych testowych, co jest bardziej kluczowe – dane testowe są przecież danymi nieznanymi.
Zróbmy tabelę dla różnych wartości k, aby dalej to udowodnić:
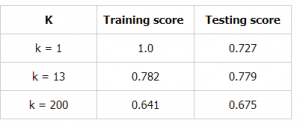
Wniosek
Podsumowując, w tym artykule dowiedzieliśmy się, że idealnym modelem byłby taki, w którym zarówno błąd skośności, jak i błąd wariancji są niskie. Jednak zawsze powinniśmy dążyć do modelu, w którym wynik modelu dla danych szkoleniowych jest jak najbliższy wynikowi modelu dla danych testowych.
Tutaj dowiedzieliśmy się, jak wybrać model, który nie jest zbyt złożony (wysoka wariancja i niska wariancja), co prowadziłoby do przepasowania i nie jest zbyt prosty (wysoka wariancja i niska wariancja), co prowadziłoby do niedopasowania.
Bias i wariancja odgrywają ważną rolę w podejmowaniu decyzji, który model predykcyjny użyć. Mam nadzieję, że ten artykuł wyjaśnił koncepcję dobrze.
.