
Jeśli chcesz nauczyć się więcej w Pythonie, weź udział w darmowym kursie DataCamp’s Intro to Python for Data Science.
Wszyscy widzieliście zbiory danych. Czasami są one małe, ale często są one ogromnie duże w rozmiarze. Bardzo dużym wyzwaniem staje się przetwarzanie zbiorów danych, które są bardzo duże, przynajmniej na tyle znaczące, aby spowodować wąskie gardło przetwarzania.
Co więc sprawia, że te zbiory danych są tak duże? Cóż, są to cechy. Im większa liczba cech, tym większe będą zbiory danych. Cóż, nie zawsze. Można znaleźć zbiory danych, w których liczba cech jest bardzo duża, ale nie zawierają one aż tylu instancji. Ale to nie jest punkt dyskusji tutaj. Tak więc, możesz się zastanawiać z komputerem klasy commodity w ręku, jak przetwarzać tego typu zbiory danych bez owijania w bawełnę.
Często, w wysokowymiarowym zbiorze danych, pozostają pewne całkowicie nieistotne, nieistotne i nieistotne cechy. Zauważono, że wkład tego typu cech jest często mniejszy w kierunku modelowania predykcyjnego w porównaniu do cech krytycznych. Mogą one mieć również zerowy wkład. Cechy te powodują szereg problemów, które z kolei uniemożliwiają proces skutecznego modelowania predykcyjnego –
- Niepotrzebna alokacja zasobów dla tych cech.
- Cechy te działają jak szum, dla którego model uczenia maszynowego może działać strasznie słabo.
- Model maszynowy zajmuje więcej czasu, aby uzyskać przeszkolenie.
Więc, jakie jest rozwiązanie tutaj? Najbardziej ekonomicznym rozwiązaniem jest Selekcja Cech.
Elekcja Cech jest procesem wyboru najbardziej znaczących cech z danego zbioru danych. W wielu przypadkach, Selekcja Cech może również zwiększyć wydajność modelu uczenia maszynowego.
Brzmi interesująco prawda?
Masz nieformalne wprowadzenie do Selekcji Cech i jej znaczenia w świecie Data Science i uczenia maszynowego. W tym poście zamierzasz omówić:
- Wprowadzenie do selekcji cech i zrozumienie jej znaczenia
- Różnica między selekcją cech a redukcją wymiarowości
- Różne typy metod selekcji cech
- Implementacja różnych metod selekcji cech za pomocą scikit-…learn
Wprowadzenie do selekcji cech
Delekcja cech jest również znana jako selekcja zmiennych lub selekcja atrybutów.
Essentially, it is the process of selecting the most important/relevant. Cechy w zbiorze danych.
Zrozumienie znaczenia selekcji cech
Ważność selekcji cech można najlepiej rozpoznać, gdy mamy do czynienia ze zbiorem danych, który zawiera ogromną liczbę cech. Ten typ zbioru danych jest często określany jako wysokowymiarowy zbiór danych. Teraz, z wysoką wymiarowością, przychodzi wiele problemów, takich jak – wysoka wymiarowość znacznie zwiększy czas szkolenia modelu uczenia maszynowego, może sprawić, że model będzie bardzo skomplikowany, co z kolei może prowadzić do nadmiernego dopasowania.
Często w wysokowymiarowym zbiorze cech, pozostaje kilka cech, które są redundantne, co oznacza, że te cechy są niczym innym jak rozszerzeniem innych istotnych cech. Te nadmiarowe cechy nie przyczyniają się skutecznie do szkolenia modelu, jak również. Tak więc, wyraźnie istnieje potrzeba wyodrębnienia najważniejszych i najbardziej istotnych cech dla zbioru danych w celu uzyskania najbardziej efektywnej wydajności modelowania predykcyjnego.
„Cel wyboru zmiennych jest potrójny: poprawa wydajności predykcji predyktorów, zapewnienie szybszych i bardziej opłacalnych predyktorów oraz zapewnienie lepszego zrozumienia procesu leżącego u podstaw, który wygenerował dane.”
-Wprowadzenie do selekcji zmiennych i cech
Zrozummy teraz różnicę między redukcją wymiarowości a selekcją cech.
Czasami selekcja cech jest mylona z redukcją wymiarowości. Ale one są różne. Selekcja cech różni się od redukcji wymiarowości. Obie metody mają tendencję do zmniejszania liczby atrybutów w zbiorze danych, ale metoda redukcji wymiarowości robi to poprzez tworzenie nowych kombinacji atrybutów (czasami znane jako transformacja cech), podczas gdy metody selekcji cech obejmują i wykluczają atrybuty obecne w danych bez ich zmiany.
Kilka przykładów metod redukcji wymiarowości to Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis, etc.
Pozwól mi podsumować znaczenie selekcji cech dla Ciebie:
- To pozwala algorytmowi uczenia maszynowego trenować szybciej.
- Zmniejsza złożoność modelu i ułatwia jego interpretację.
- Poprawia dokładność modelu, jeśli zostanie wybrany odpowiedni podzbiór.
- Zmniejsza Overfitting.
W następnej sekcji przestudiujemy różne typy ogólnych metod selekcji cech – metody filtrujące, metody opakowujące i metody osadzone.
Metody filtrujące
Następujący obraz najlepiej opisuje metody selekcji cech oparte na filtrach:

Źródło obrazu: Analytics Vidhya
Metoda filtrów opiera się na ogólnej unikalności danych, które mają być oceniane i wybrać podzbiór cech, nie uwzględniając żadnego algorytmu wydobywczego. Metoda filtra wykorzystuje dokładne kryterium oceny, które obejmuje odległość, informację, zależność i spójność. Metoda filtrów wykorzystuje główne kryteria techniki rankingowej i wykorzystuje metodę porządkowania rang do wyboru zmiennych. Powodem stosowania metody rankingowej jest prostota, produkcja doskonałych i istotnych cech. Metoda rankingowa odfiltrowuje nieistotne cechy przed rozpoczęciem procesu klasyfikacji.
Metody filtracyjne są ogólnie stosowane jako etap wstępnego przetwarzania danych. Wybór cech jest niezależny od jakiegokolwiek algorytmu uczenia maszynowego. Cechy nadają rangę na podstawie statystycznej punktacji, która ma tendencję do określania korelacji cech ze zmienną wynikową. Korelacja jest pojęciem silnie kontekstowym i różni się w zależności od pracy. Możesz odnieść się do poniższej tabeli w celu zdefiniowania współczynników korelacji dla różnych typów danych (w tym przypadku ciągłych i kategorycznych).

Źródło obrazu: Analytics Vidhya
Przykłady niektórych metod filtrujących obejmują test Chi-kwadrat, zysk informacji i wyniki współczynnika korelacji.
Następnie zobaczysz metody Wrapper.
Metody wrapper
Podobnie jak w przypadku metod filtrujących, pozwól, że podam ci ten sam rodzaj info-grafiki, która pomoże ci lepiej zrozumieć metody wrapper:
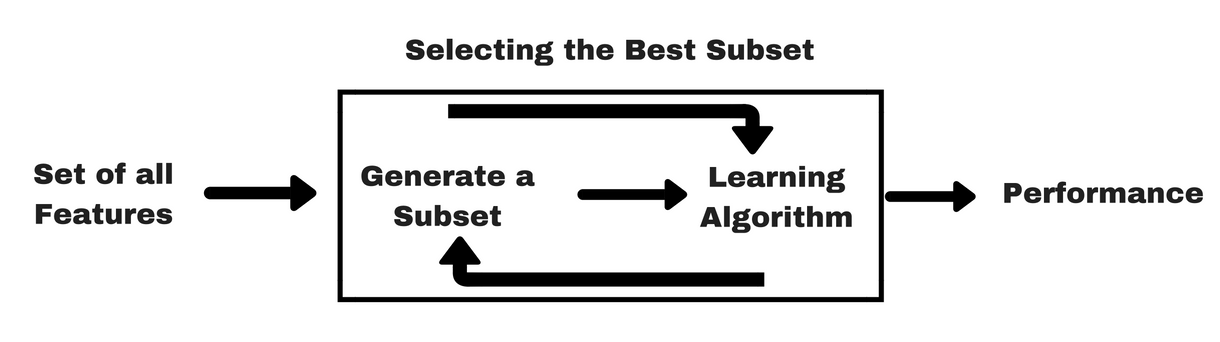
Źródło obrazu: Analytics Vidhya
Jak widać na powyższym obrazie, metoda wrapper potrzebuje jednego algorytmu uczenia maszynowego i wykorzystuje jego wydajność jako kryterium oceny. Metoda ta wyszukuje cechę, która jest najlepiej dopasowana do algorytmu uczenia maszynowego i ma na celu poprawę wydajności wydobycia. Aby ocenić cechy, dokładność predykcyjna używana do zadań klasyfikacji i dobroć klastra jest oceniana przy użyciu klasteryzacji.
Kilka typowych przykładów metod opakowujących to selekcja cech w przód, eliminacja cech w tył, rekurencyjna eliminacja cech itp.
- Selekcja w przód: Procedura rozpoczyna się od pustego zbioru cech . Wyznaczana jest najlepsza z oryginalnych cech i dodawana do zredukowanego zbioru. W każdej kolejnej iteracji do zbioru dodawana jest najlepsza z pozostałych oryginalnych cech.
- Eliminacja wsteczna: Procedura rozpoczyna się z pełnym zbiorem atrybutów. Na każdym kroku usuwa najgorszy atrybut pozostający w zbiorze.
- Kombinacja selekcji w przód i eliminacji wstecznej: Metody krokowej selekcji w przód i eliminacji wstecznej mogą być połączone tak, że na każdym kroku procedura wybiera najlepszy atrybut i usuwa najgorszy spośród pozostałych atrybutów.
- Rekursywna eliminacja cech: Rekursywna eliminacja cech wykonuje zachłanne wyszukiwanie w celu znalezienia najlepiej działającego podzbioru cech. Tworzy iteracyjnie modele i określa najlepszą lub najgorszą cechę w każdej iteracji. Konstruuje kolejne modele z pozostawionymi cechami, aż wszystkie cechy zostaną zbadane. Następnie szereguje cechy na podstawie kolejności ich eliminacji. W najgorszym przypadku, jeśli zbiór danych zawiera N liczbę cech, RFE wykona zachłanne wyszukiwanie 2N kombinacji cech.
Dobrze!
Teraz przestudiujmy metody wbudowane.
Metody wbudowane
Metody wbudowane są iteracyjne w takim sensie, że zajmują się każdą iteracją procesu szkolenia modelu i starannie wyodrębniają te cechy, które wnoszą najwięcej do szkolenia dla danej iteracji. Metody regularyzacji są najczęściej używanymi metodami wbudowanymi, które penalizują cechę biorąc pod uwagę próg współczynnika.
Dlatego metody regularyzacji są również nazywane metodami penalizacji, które wprowadzają dodatkowe ograniczenia do optymalizacji algorytmu predykcyjnego (takiego jak algorytm regresji), które skłaniają model w kierunku niższej złożoności (mniej współczynników).
Przykładami algorytmów regularyzacji są LASSO, Elastic Net, Ridge Regression, itp.
Różnica pomiędzy filtrem a metodami opakowującymi
Cóż, czasami może być mylące rozróżnienie pomiędzy metodami filtrującymi i opakowującymi pod względem ich funkcjonalności. Przyjrzyjmy się, w jakich punktach różnią się one od siebie.
- Metody filtrowania nie zawierają modelu uczenia maszynowego w celu określenia, czy dana cecha jest dobra czy zła, podczas gdy metody zawijania używają modelu uczenia maszynowego i trenują daną cechę, aby zdecydować, czy jest ona istotna, czy nie.
- Metody filtrowania są znacznie szybsze w porównaniu z metodami zawijania, ponieważ nie obejmują one szkolenia modeli. Z drugiej strony, metody opakowujące są kosztowne obliczeniowo, a w przypadku masywnych zbiorów danych metody opakowujące nie są najbardziej efektywną metodą selekcji cech do rozważenia.
- Metody filtracyjne mogą nie znaleźć najlepszego podzbioru cech w sytuacjach, gdy nie ma wystarczającej ilości danych do modelowania statystycznej korelacji cech, ale metody opakowujące mogą zawsze zapewnić najlepszy podzbiór cech ze względu na ich wyczerpujący charakter.
- Używanie cech z metod opakowujących w ostatecznym modelu uczenia maszynowego może prowadzić do przepasowania, ponieważ metody opakowujące już trenują modele uczenia maszynowego z cechami i wpływa to na prawdziwą moc uczenia. Ale cechy z metod filtrujących nie prowadzą do przepasowania w większości przypadków
Do tej pory przestudiowałeś znaczenie selekcji cech, zrozumiałeś jej różnicę z redukcją wymiarowości. Omówiłeś również różne rodzaje metod selekcji cech. Jak do tej pory, tak dobrze!
Teraz, zobaczmy kilka pułapek, w które możesz wpaść podczas wykonywania selekcji cech:
Ważne rozważania
Może już zrozumiałeś wartość selekcji cech w potoku uczenia maszynowego i rodzaj usług, które zapewnia, jeśli jest zintegrowana. Ale bardzo ważne jest, aby zrozumieć, gdzie dokładnie powinieneś zintegrować selekcję cech w swoim potoku uczenia maszynowego.
Prosto mówiąc, powinieneś włączyć krok selekcji cech przed podaniem danych do modelu w celu szkolenia, zwłaszcza gdy używasz metod szacowania dokładności, takich jak walidacja krzyżowa. Zapewnia to, że selekcja cech jest wykonywana na złożeniu danych tuż przed wytrenowaniem modelu. Ale jeśli wykonasz selekcję cech najpierw, aby przygotować swoje dane, a następnie wykonasz selekcję modelu i trening na wybranych cechach, to będzie to błąd.
Jeśli wykonasz selekcję cech na wszystkich danych, a następnie walidację krzyżową, to dane testowe w każdym złożeniu procedury walidacji krzyżowej były również używane do wyboru cech, a to ma tendencję do uprzedzania wydajności twojego modelu uczenia maszynowego.
Dość teorii! Przejdźmy teraz od razu do kodowania.
Studium przypadku w Pythonie
Do tego studium przypadku użyjesz zbioru danych Pima Indians Diabetes. Opis zbioru danych można znaleźć tutaj.
Zbiór danych odpowiada zadaniom klasyfikacji, w których musisz przewidzieć, czy dana osoba ma cukrzycę na podstawie 8 cech.
W zbiorze danych znajduje się w sumie 768 obserwacji. Twoim pierwszym zadaniem jest załadowanie zbioru danych, abyś mógł kontynuować. Ale zanim to nastąpi, zaimportujmy niezbędne zależności, których będziemy potrzebować. Możesz zaimportować pozostałe w miarę postępu prac.
import pandas as pdimport numpy as npTeraz, gdy zależności są zaimportowane, załadujmy zbiór danych Indian Pima do obiektu Dataframe za pomocą biblioteki Pandas.
data = pd.read_csv("diabetes.csv")Zbiór danych został pomyślnie załadowany do danych obiektu Dataframe. Przyjrzyjmy się teraz danym.
data.head()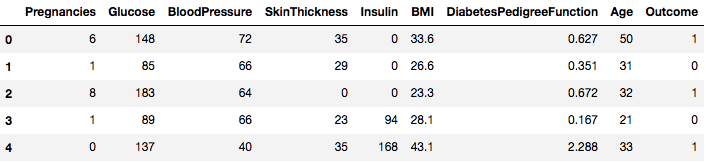
Więc widać 8 różnych cech oznaczonych jako wyniki 1 i 0, gdzie 1 oznacza, że obserwacja ma cukrzycę, a 0 oznacza, że obserwacja nie ma cukrzycy. Wiadomo, że zbiór danych zawiera brakujące wartości. W szczególności, brakuje obserwacji dla niektórych kolumn, które są oznaczone jako wartość zerowa. Można to wywnioskować na podstawie definicji tych kolumn, a niepraktyczne jest, aby wartość zerowa była nieważna dla tych pomiarów, np, zero dla wskaźnika masy ciała lub ciśnienia krwi jest nieważne.
Ale dla tego samouczka, będziesz bezpośrednio używał wstępnie przetworzonej wersji zbioru danych.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Załadowałeś dane do obiektu DataFrame o nazwie dataframe teraz.
Zamieńmy obiekt DataFrame na tablicę NumPy, aby osiągnąć szybsze obliczenia. Ponadto posegregujmy dane na osobne zmienne, aby cechy i etykiety były oddzielone.
array = dataframe.valuesX = arrayY = arrayWspaniale! Przygotowałeś swoje dane.
Po pierwsze, zaimplementujesz test statystyczny Chi-Squared dla cech nieujemnych, aby wybrać 4 najlepsze cechy ze zbioru danych. Widziałeś już, że test Chi-Squared należy do klasy metod filtrujących. Jeśli ktoś jest ciekawy, jak poznać wnętrze Chi-Squared, ten filmik robi doskonałą robotę.
Biblioteka scikit-learn dostarcza klasę SelectKBest, która może być użyta z zestawem różnych testów statystycznych do wybrania określonej liczby cech, w tym przypadku jest to Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Zaimportowałeś biblioteki, aby uruchomić eksperymenty. Teraz zobaczmy je w akcji.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Interpretacja:
Możesz zobaczyć wyniki dla każdego atrybutu i 4 wybrane atrybuty (te z najwyższymi wynikami): plas, test, masa i wiek. Ta punktacja pomoże Ci w określeniu najlepszych cech do treningu modelu.
P.S.: Pierwszy rząd oznacza nazwy cech. W celu wstępnego przetworzenia zbioru danych, nazwy zostały zakodowane numerycznie.
Następnie zaimplementujemy metodę Recursive Feature Elimination, która jest typem metody selekcji cech wrapper.
Recursive Feature Elimination (lub RFE) działa poprzez rekurencyjne usuwanie atrybutów i budowanie modelu na tych atrybutach, które pozostały.
Używa dokładności modelu, aby określić, które atrybuty (i kombinacje atrybutów) w największym stopniu przyczyniają się do przewidywania atrybutu docelowego.
Możesz dowiedzieć się więcej o klasie RFE w dokumentacji scikit-learn.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionUżyjesz RFE z klasyfikatorem Logistic Regression, aby wybrać 3 najlepsze cechy. Wybór algorytmu nie ma zbyt dużego znaczenia, o ile jest on umiejętny i spójny.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Widzisz, że RFE wybrał 3 najlepsze cechy jako preg, mass i pedi.
Są one oznaczone jako True w tablicy wsparcia i oznaczone wyborem „1” w tablicy rankingu. To z kolei wskazuje na siłę tych cech.
Następnie użyjesz regresji Ridge, która jest w zasadzie techniką regularyzacji i wbudowaną techniką wyboru cech, jak również.
Ten artykuł daje doskonałe wyjaśnienie na temat regresji Ridge. Pamiętaj, aby to sprawdzić.
# First things firstfrom sklearn.linear_model import RidgeNastępnie użyjesz regresji Ridge do określenia współczynnika R2.
Sprawdź również oficjalną dokumentację scikit-learn na temat regresji Ridge.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)Aby lepiej zrozumieć wyniki regresji Ridge, zaimplementujesz małą funkcję pomocniczą, która pomoże ci wydrukować wyniki w lepszy sposób, abyś mógł je łatwo zinterpretować.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)Następnie przekażemy współczynniki modelu Ridge do tej małej funkcji i zobaczymy, co się stanie.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Możemy zauważyć wszystkie współczynniki dołączone do zmiennych charakterystycznych. To znowu pomoże Ci wybrać najbardziej istotne cechy. Poniżej znajduje się kilka punktów, o których należy pamiętać podczas stosowania regresji Ridge:
- Jest ona również znana jako L2-Regularyzacja.
- Dla skorelowanych cech oznacza to, że mają one tendencję do uzyskiwania podobnych współczynników.
- Cechy posiadające ujemne współczynniki nie przyczyniają się tak bardzo. Ale w bardziej złożonym scenariuszu, gdzie masz do czynienia z wieloma cechami, wtedy ten wynik zdecydowanie pomoże ci w ostatecznym procesie podejmowania decyzji o wyborze cech.
Więc, to kończy sekcję studium przypadku. Metody, które zaimplementowałeś w powyższej sekcji, pomogą ci zrozumieć cechy konkretnego zbioru danych w sposób kompleksowy. Pozwól, że podam ci kilka krytycznych punktów na temat tych technik:
- Wybór cech jest zasadniczo częścią wstępnego przetwarzania danych, które jest uważane za najbardziej czasochłonną część każdego potoku uczenia maszynowego.
- Te techniki pomogą ci podejść do tego w bardziej systematyczny sposób i przyjazny dla uczenia maszynowego. Będziesz w stanie dokładniej interpretować cechy.
Wrap up!
W tym poście poruszyłeś jeden z najlepiej zbadanych tematów statystycznych, czyli selekcję cech. Zapoznałeś się również z jego różnymi wariantami i użyłeś ich do sprawdzenia, które cechy w zbiorze danych są ważne.
Możesz pójść dalej w tym tutorialu, łącząc miarę korelacji z metodą wrapper i zobaczyć, jak ona działa. W trakcie działania, możesz skończyć tworząc swój własny mechanizm selekcji cech. W ten sposób tworzysz podstawy dla swoich małych badań. Naukowcy wykorzystują również różne zasady miękkich obliczeń w celu przeprowadzenia selekcji. Jest to samo w sobie cały obszar studiów i badań. Powinieneś również wypróbować istniejące algorytmy selekcji cech na różnych zestawach danych i wyciągnąć własne wnioski.
Dlaczego te tradycyjne metody selekcji cech nadal się utrzymują?
Tak, to pytanie jest oczywiste. Ponieważ istnieją architektury sieci neuronowych (na przykład CNN), które są całkiem zdolne do wyodrębniania najbardziej znaczących cech z danych, ale to również ma ograniczenie. Używanie CNN do zwykłego tabelarycznego zbioru danych, który nie ma specyficznych właściwości (właściwości, które typowy obraz posiada, takie jak właściwości przejściowe, krawędzie, właściwości pozycyjne, kontury itp.) nie jest najmądrzejszą decyzją do podjęcia. Ponadto, gdy mamy ograniczone dane i zasoby, trening CNN na zwykłych tabelarycznych zbiorach danych może okazać się kompletnym marnotrawstwem. Tak więc, w sytuacjach takich jak ta, metody, które studiowałeś na pewno się przydadzą.
Jeśli chcesz dowiedzieć się więcej na ten temat, skorzystaj z następujących źródeł:
- Feature Selection for Knowledge Discovery and Data Mining
- Subspace, Latent Structure, and Feature Selection: Statistical and Optimization Perspectives Workshop
- Feature Selection: Problem Statement and Uses
- Using genetic algorithms for feature selection in Data Analytics
Poniżej znajdują się referencje, które zostały wykorzystane do napisania tego tutoriala.
- Data Mining: Concepts and Techniques; Jiawei Han Micheline Kamber Jian Pei.
- Wprowadzenie do selekcji cech
- Analytics Vidhya artykuł o selekcji cech
- Hierarchical and Mixed Model – DataCamp course
- Feature Selection For Machine Learning in Python
- Outlier Detection in Stream Data by MachineLearning and Feature Selection Methods
- S. Visalakshi i V. Radha, „A literature review of feature selection techniques and applications: Review of feature selection in data mining,” 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, pp. 1-6.
.