L’apprentissage par renforcement(RL) est l’un des sujets de recherche les plus chauds dans le domaine de l’intelligence artificielle moderne et sa popularité ne fait que croître. Examinons 5 choses utiles que l’on doit savoir pour commencer avec le RL.
L’apprentissage par renforcement(RL) est un type de technique d’apprentissage automatique qui permet à un agent d’apprendre dans un environnement interactif par essais et erreurs en utilisant le retour d’information de ses propres actions et expériences.
Bien que l’apprentissage supervisé et l’apprentissage par renforcement utilisent tous deux la cartographie entre l’entrée et la sortie, contrairement à l’apprentissage supervisé où la rétroaction fournie à l’agent est un ensemble correct d’actions pour effectuer une tâche, l’apprentissage par renforcement utilise des récompenses et des punitions comme signaux pour un comportement positif et négatif.
Par rapport à l’apprentissage non supervisé, l’apprentissage par renforcement est différent en termes d’objectifs. Alors que le but de l’apprentissage non supervisé est de trouver des similitudes et des différences entre les points de données, dans le cas de l’apprentissage par renforcement, le but est de trouver un modèle d’action approprié qui maximiserait la récompense cumulative totale de l’agent. La figure ci-dessous illustre la boucle de rétroaction action-récompense d’un modèle RL générique.

Comment formuler un problème de base d’apprentissage par renforcement ?
Certains termes clés qui décrivent les éléments de base d’un problème d’apprentissage par renforcement sont :
- Environnement – Monde physique dans lequel l’agent opère
- État – Situation actuelle de l’agent
- Récompense – Rétroaction de l’environnement
- Politique – Méthode pour mettre en correspondance l’état de l’agent et les actions
- Valeur – Récompense future qu’un agent recevrait en prenant une action dans un état particulier
Un problème d’apprentissage par renforcement peut être mieux expliqué par des jeux. Prenons le jeu de PacMan où le but de l’agent(PacMan) est de manger la nourriture dans la grille tout en évitant les fantômes sur son chemin. Dans ce cas, le monde de la grille est l’environnement interactif de l’agent où il agit. L’agent reçoit une récompense s’il mange de la nourriture et une punition s’il est tué par un fantôme (il perd le jeu). Les états sont l’emplacement de l’agent dans le monde de la grille et la récompense cumulative totale est l’agent qui gagne le jeu.

Pour construire une politique optimale, l’agent est confronté au dilemme d’explorer de nouveaux états tout en maximisant sa récompense globale en même temps. C’est ce qu’on appelle le compromis Exploration vs Exploitation. Pour équilibrer les deux, la meilleure stratégie globale peut impliquer des sacrifices à court terme. Par conséquent, l’agent doit collecter suffisamment d’informations pour prendre la meilleure décision globale dans le futur.
Les processus de décision de Markov(MDP) sont des cadres mathématiques pour décrire un environnement en RL et presque tous les problèmes de RL peuvent être formulés en utilisant des MDP. Un MDP consiste en un ensemble d’états d’environnement finis S, un ensemble d’actions possibles A(s) dans chaque état, une fonction de récompense à valeur réelle R(s) et un modèle de transition P(s’, s | a). Cependant, les environnements du monde réel sont plus susceptibles de ne pas avoir de connaissance préalable de la dynamique de l’environnement. Les méthodes RL sans modèle sont pratiques dans de tels cas.
L’apprentissage Q est une approche sans modèle couramment utilisée qui peut être utilisée pour construire un agent PacMan auto-joueur. Elle tourne autour de la notion de mise à jour des valeurs Q qui désigne la valeur de l’exécution de l’action a dans l’état s. La règle suivante de mise à jour des valeurs est le cœur de l’algorithme de Q-learning.

Voici une démonstration vidéo d’un agent PacMan qui utilise l’apprentissage par renforcement profond.
Quels sont les algorithmes d’apprentissage par renforcement les plus utilisés ?
L’apprentissage Q et SARSA (State-Action-Reward-State-Action) sont deux algorithmes RL sans modèle couramment utilisés. Ils diffèrent en termes de stratégies d’exploration alors que leurs stratégies d’exploitation sont similaires. Alors que Q-learning est une méthode hors politique dans laquelle l’agent apprend la valeur basée sur l’action a* dérivée d’une autre politique, SARSA est une méthode sur politique où il apprend la valeur basée sur son action actuelle a dérivée de sa politique actuelle. Ces deux méthodes sont simples à mettre en œuvre mais manquent de généralité car elles n’ont pas la capacité d’estimer des valeurs pour des états non vus.
Cela peut être surmonté par des algorithmes plus avancés tels que les Deep Q-Networks(DQNs) qui utilisent des réseaux neuronaux pour estimer les valeurs Q. Mais les DQNs ne peuvent gérer que des espaces d’action discrets et de faible dimension.
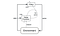
Deep Deterministic Policy Gradient(DDPG) est un algorithme sans modèle, hors politique et critique de l’acteur qui s’attaque à ce problème en apprenant des politiques dans des espaces d’action continus de haute dimension. La figure ci-dessous est une représentation de l’architecture acteur-critique.
Quelles sont les applications pratiques de l’apprentissage par renforcement ?
Puisque, RL nécessite beaucoup de données, il est donc plus applicable dans les domaines où les données simulées sont facilement disponibles comme le jeu, la robotique.
- RL est assez largement utilisé dans la construction d’IA pour jouer à des jeux vidéo. AlphaGo Zero est le premier programme informatique à avoir battu un champion du monde dans l’ancien jeu chinois du Go. D’autres incluent les jeux ATARI, Backgammon ,etc
- Dans la robotique et l’automatisation industrielle, RL est utilisé pour permettre au robot de créer un système de contrôle adaptatif efficace pour lui-même qui apprend de sa propre expérience et de son comportement. Les travaux de DeepMind sur l’apprentissage par renforcement profond pour la manipulation robotique avec mises à jour asynchrones des politiques en sont un bon exemple. Regardez cette vidéo de démonstration intéressante.
D’autres applications de RL comprennent des moteurs de résumé de texte abstractif, des agents de dialogue(texte, parole) qui peuvent apprendre des interactions de l’utilisateur et s’améliorer avec le temps, l’apprentissage de politiques de traitement optimales dans les soins de santé et des agents basés sur RL pour le commerce boursier en ligne.
Comment puis-je commencer avec l’apprentissage par renforcement ?
Pour comprendre les concepts de base de RL, on peut se référer aux ressources suivantes.
- Reinforcement Learning-An Introduction, un livre par le père de l’apprentissage par renforcement- Richard Sutton et son conseiller doctoral Andrew Barto. Une ébauche en ligne du livre est disponible ici.
- Le matériel d’enseignement de David Silver, y compris les conférences vidéo, est un excellent cours d’introduction sur le RL.
- Voici un autre tutoriel technique sur le RL par Pieter Abbeel et John Schulman (Open AI/ Berkeley AI Research Lab).
Pour commencer à construire et tester des agents RL, les ressources suivantes peuvent être utiles.
- Ce blog sur la façon de former un agent ATARI Pong à réseau neuronal avec des gradients de politique à partir de pixels bruts par Andrej Karpathy vous aidera à mettre en place votre premier agent d’apprentissage par renforcement profond en seulement 130 lignes de code Python.
- DeepMind Lab est une plateforme open source de type jeu 3D créée pour la recherche sur l’IA basée sur les agents avec des environnements simulés riches.
- Project Malmo est une autre plateforme d’expérimentation de l’IA pour soutenir la recherche fondamentale en IA.
- OpenAI gym est une boîte à outils pour construire et comparer des algorithmes d’apprentissage par renforcement.