
Avant que je ne commence ce voyage pour essayer d’apprendre l’informatique, il y avait certains termes et phrases qui me donnaient envie de courir dans l’autre direction.
Mais au lieu de courir, je feignais de les connaître, en hochant la tête dans les conversations, en prétendant que je savais à quoi quelqu’un faisait référence, même si la vérité était que je n’en avais aucune idée et que j’avais en fait complètement arrêté d’écouter quand j’entendais ce terme informatique super effrayant™. Tout au long de cette série, j’ai réussi à couvrir beaucoup de terrain et beaucoup de ces termes sont en fait devenus beaucoup moins effrayants !
Il y en a un gros, cependant, que j’ai évité pendant un certain temps. Jusqu’à présent, chaque fois que j’avais entendu ce terme, je me sentais paralysé. Il est apparu dans des conversations informelles lors de rencontres et parfois lors de conférences. À chaque fois, je pense à des machines qui tournent et à des ordinateurs qui crachent des chaînes de code indéchiffrables, sauf que tout le monde autour de moi peut en fait les déchiffrer, donc c’est en fait juste moi qui ne sait pas ce qui se passe (oups comment c’est arrivé ? !).
Peut-être que je ne suis pas le seul à avoir ressenti cela. Mais, je suppose que je devrais vous dire ce qu’est réellement ce terme, non ? Eh bien, préparez-vous, car je fais référence au toujours insaisissable et apparemment déroutant arbre de syntaxe abstraite, ou AST pour faire court. Après de nombreuses années d’intimidation, je suis excité de finalement cesser d’avoir peur de ce terme et de vraiment comprendre ce que c’est sur terre.
Il est temps d’affronter la racine de l’arbre syntaxique abstrait de front – et de mettre à niveau notre jeu d’analyse syntaxique !
Toute bonne quête commence par une base solide, et notre mission de démystification de cette structure devrait commencer exactement de la même manière : par une définition, bien sûr !
Un arbre syntaxique abstrait (généralement simplement appelé AST) n’est en réalité rien de plus qu’une version simplifiée et condensée d’un arbre d’analyse syntaxique. Dans le contexte de la conception de compilateurs, le terme « AST » est utilisé de manière interchangeable avec l’arbre syntaxique.

Nous pensons souvent aux arbres syntaxiques (et à la façon dont ils sont construits) par rapport à leurs homologues arbres parse, avec lesquels nous sommes déjà assez familiers. Nous savons que les arbres d’analyse sont des structures de données arborescentes qui contiennent la structure grammaticale de notre code ; en d’autres termes, ils contiennent toutes les informations syntaxiques qui apparaissent dans une « phrase » de code, et sont directement dérivées de la grammaire du langage de programmation lui-même.
Un arbre syntaxique abstrait, d’autre part, ignore une quantité importante d’informations syntaxiques qu’un arbre d’analyse contiendrait autrement.
A l’inverse, un AST ne contient que les informations liées à l’analyse du texte source, et ignore tout autre contenu supplémentaire utilisé lors de l’analyse du texte.
Cette distinction commence à avoir beaucoup plus de sens si nous nous concentrons sur le « caractère abstrait » d’un AST.
Nous nous souviendrons qu’un arbre d’analyse est une version illustrée, picturale, de la structure grammaticale d’une phrase. En d’autres termes, nous pouvons dire qu’un arbre d’analyse représente exactement ce à quoi ressemble une expression, une phrase ou un texte. Il s’agit en fait d’une traduction directe du texte lui-même ; nous prenons la phrase et en transformons chaque petit morceau – de la ponctuation aux expressions en passant par les tokens – en une structure de données arborescente. Il révèle la syntaxe concrète d’un texte, c’est pourquoi il est également appelé arbre syntaxique concret, ou CST. Nous utilisons le terme concret pour décrire cette structure parce que c’est une copie grammaticale de notre code, token par token, sous forme d’arbre.
Mais qu’est-ce qui rend quelque chose concret par rapport à l’abstrait ? Eh bien, un arbre syntaxique abstrait ne nous montre pas exactement à quoi ressemble une expression, comme le fait un arbre d’analyse.

Par contre, un arbre syntaxique abstrait nous montre les bits « importants » – les choses dont nous nous soucions vraiment, qui donnent un sens à notre « phrase » de code elle-même. Les arbres syntaxiques nous montrent les éléments significatifs d’une expression, ou la syntaxe abstraite de notre texte source. Par conséquent, par rapport aux arbres syntaxiques concrets, ces structures sont des représentations abstraites de notre code (et à certains égards, moins exactes), ce qui est exactement la raison pour laquelle elles ont reçu leur nom.
Maintenant que nous comprenons la distinction entre ces deux structures de données et les différentes façons dont elles peuvent représenter notre code, il est utile de poser la question : où un arbre syntaxique abstrait s’intègre dans le compilateur ? Tout d’abord, rappelons tout ce que nous savons sur le processus de compilation tel que nous le connaissons jusqu’à présent.

Disons que nous avons un texte source super court et doux, qui ressemble à ceci : 5 + (1 x 12).
Nous nous souviendrons que la première chose qui se passe dans le processus de compilation est le balayage du texte, un travail effectué par l’analyseur, qui aboutit à la décomposition du texte en ses plus petites parties possibles, qui sont appelées lexèmes. Cette partie sera agnostique au langage, et nous nous retrouverons avec la version dépouillée de notre texte source.
Puis, ces mêmes lexèmes sont transmis au lexeur/tokéniseur, qui transforme ces petites représentations de notre texte source en tokens, qui seront spécifiques à notre langage. Nos tokens ressembleront à quelque chose comme ceci : . L’effort conjoint du scanner et du tokenizer constitue l’analyse lexicale de la compilation.
Puis, une fois que notre entrée a été tokenisée, ses tokens résultants sont transmis à notre parser, qui prend alors le texte source et construit un arbre d’analyse à partir de celui-ci. L’illustration ci-dessous exemplifie ce à quoi ressemble notre code tokénisé, en format d’arbre d’analyse grammaticale.
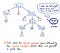
Le travail de transformation des tokens en un arbre d’analyse grammaticale est également appelé analyse syntaxique. La phase d’analyse syntaxique dépend directement de la phase d’analyse lexicale ; ainsi, l’analyse lexicale doit toujours venir en premier dans le processus de compilation, car l’analyseur syntaxique de notre compilateur ne peut faire son travail qu’une fois que le tokenizer fait son travail !
Nous pouvons considérer les parties du compilateur comme de bons amis, qui dépendent tous les uns des autres pour s’assurer que notre code est correctement transformé d’un texte ou d’un fichier en un arbre d’analyse syntaxique.
Mais revenons à notre question initiale : où se situe l’arbre syntaxique abstrait dans ce groupe d’amis ? Eh bien, afin de répondre à cette question, il est utile de comprendre le besoin d’un AST en premier lieu.
Condensation d’un arbre dans un autre
Ok, donc maintenant nous avons deux arbres à garder droit dans nos têtes. Nous avions déjà un arbre d’analyse, et comment il y a encore une autre structure de données à apprendre ! Et apparemment, cette structure de données AST est juste un arbre d’analyse simplifié. Alors, pourquoi en avons-nous besoin ? Quel est même son intérêt ?
Bien, jetons un coup d’œil à notre arbre d’analyse grammaticale, d’accord ?
Nous savons déjà que les arbres d’analyse grammaticale représentent notre programme dans ses parties les plus distinctes ; en effet, c’était la raison pour laquelle l’analyseur et le tokenizer ont des tâches si importantes de décomposer notre expression en ses plus petites parties !
Que signifie réellement représenter un programme par ses parties les plus distinctes ?
Il s’avère que parfois, toutes les parties distinctes d’un programme ne nous sont en fait pas si utiles que ça tout le temps.
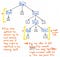
Regardons l’illustration présentée ici, qui représente notre expression originale, 5 + (1 x 12), sous forme d’arbre parse. Si nous examinons de près cet arbre avec un œil critique, nous verrons qu’il y a quelques cas où un nœud a exactement un enfant, qui sont également appelés nœuds à successeur unique, car ils n’ont qu’un seul nœud enfant qui en découle (ou un « successeur »).
Dans le cas de notre exemple d’arbre d’analyse, les nœuds à successeur unique ont un nœud parent d’un Expression, ou Exp, qui ont un successeur unique d’une certaine valeur, comme 5, 1, ou 12. Cependant, les nœuds parents Exp n’ajoutent pas réellement quelque chose de valeur pour nous, n’est-ce pas ? Nous pouvons voir qu’ils contiennent des nœuds enfants token/terminal, mais nous ne nous soucions pas vraiment du nœud parent » expression » ; tout ce que nous voulons vraiment savoir, c’est quelle est l’expression ?
Le nœud parent ne nous donne aucune information supplémentaire une fois que nous avons analysé notre arbre. Au lieu de cela, ce qui nous préoccupe vraiment, c’est le nœud fils unique, successeur unique. En effet, c’est ce nœud qui nous donne l’information importante, la partie qui est significative pour nous : le nombre et la valeur eux-mêmes ! En considérant le fait que ces nœuds parents sont en quelque sorte inutiles pour nous, il devient évident que cet arbre d’analyse est une sorte de verbe.
Tous ces nœuds à successeur unique sont plutôt superflus pour nous, et ne nous aident pas du tout. Donc, débarrassons-nous d’eux !
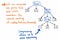
Si nous compressons les nœuds à successeur unique dans notre arbre d’analyse, nous nous retrouverons avec une version plus compressée de la même structure exacte. En regardant l’illustration ci-dessus, nous verrons que nous conservons exactement la même imbrication qu’auparavant, et que nos noeuds/tokens/terminaux apparaissent toujours au bon endroit dans l’arbre. Mais, nous avons réussi à le réduire un peu.
Et nous pouvons aussi réduire un peu plus notre arbre. Par exemple, si nous regardons notre arbre d’analyse tel qu’il est actuellement, nous verrons qu’il y a une structure miroir à l’intérieur. La sous-expression de (1 x 12) est imbriquée dans les parenthèses (), qui sont des tokens à part entière.
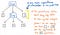
Cependant, ces parenthèses ne nous aident pas vraiment une fois notre arbre en place. Nous savons déjà que 1 et 12 sont des arguments qui seront passés à l’opération de multiplication x, donc les parenthèses ne nous disent pas grand-chose à ce stade. En fait, nous pourrions comprimer notre arbre d’analyse syntaxique encore plus loin et nous débarrasser de ces nœuds feuilles superflus.
Une fois que nous avons comprimé et simplifié notre arbre d’analyse syntaxique et que nous nous sommes débarrassés de la « poussière » syntaxique superflue, nous nous retrouvons avec une structure qui semble visiblement différente à ce stade. Cette structure est, en fait, notre nouvel et très attendu ami : l’arbre syntaxique abstrait.

L’image ci-dessus illustre exactement la même expression que notre arbre d’analyse : 5 + (1 x 12). La différence est qu’il a abstrait l’expression de la syntaxe concrète. Nous ne voyons plus les parenthèses () dans cet arbre, car elles ne sont pas nécessaires. De même, nous ne voyons pas de non-terminaux comme Exp, puisque nous avons déjà compris ce qu’est l' »expression » et que nous sommes capables d’extraire la valeur qui nous importe vraiment – par exemple, le nombre 5.
C’est exactement le facteur de distinction entre un AST et un CST. Nous savons qu’un arbre syntaxique abstrait ignore une quantité significative d’informations syntaxiques qu’un arbre d’analyse contient, et saute le « contenu supplémentaire » qui est utilisé dans l’analyse syntaxique. Mais maintenant, nous pouvons voir exactement comment cela se produit!

Maintenant que nous avons condensé un arbre d’analyse syntaxique de notre propre, nous serons beaucoup plus à même de repérer certains des modèles qui distinguent un AST d’un CST.
Il y a quelques façons dont un arbre syntaxique abstrait différera visuellement d’un arbre parse:
- Un AST ne contiendra jamais de détails syntaxiques, tels que les virgules, les parenthèses et les points-virgules (en fonction, bien sûr, de la langue).
- Un AST aura une version effondrée de ce qui apparaîtrait autrement comme des nœuds à successeur unique ; il ne contiendra jamais de « chaînes » de nœuds avec un seul enfant.
- Enfin, tous les tokens opérateurs (tels que
+,-,x, et/) deviendront des nœuds internes (parents) dans l’arbre, plutôt que les feuilles qui se terminent dans un arbre d’analyse grammaticale.
Visuellement, un AST apparaîtra toujours plus compact qu’un arbre d’analyse grammaticale, puisqu’il est, par définition, une version compressée d’un arbre d’analyse grammaticale, avec moins de détails syntaxiques.
Il serait donc logique que, si un AST est une version comprimée d’un arbre parse, nous ne pouvons vraiment créer un arbre syntaxique abstrait que si nous avons les choses pour construire un arbre parse pour commencer !
C’est, en effet, la façon dont l’arbre syntaxique abstrait s’intègre dans le processus de compilation plus large. Un AST a un lien direct avec les arbres d’analyse syntaxique que nous avons déjà appris, tout en s’appuyant simultanément sur le lexer pour faire son travail avant qu’un AST puisse jamais être créé.

L’arbre syntaxique abstrait est créé comme le résultat final de la phase d’analyse syntaxique. L’analyseur syntaxique, qui est au premier plan comme le « personnage » principal pendant l’analyse syntaxique, peut ou non toujours générer un arbre d’analyse, ou AST. Selon le compilateur lui-même, et la façon dont il a été conçu, l’analyseur syntaxique peut directement passer à la construction d’un arbre syntaxique, ou AST. Mais l’analyseur syntaxique générera toujours un AST comme sortie, peu importe s’il crée un arbre d’analyse entre temps, ou combien de passes il pourrait avoir besoin de prendre pour le faire.
Anatomie d’un AST
Maintenant que nous savons que l’arbre syntaxique abstrait est important (mais pas nécessairement intimidant !), nous pouvons commencer à le disséquer un tout petit peu plus. Un aspect intéressant sur la façon dont l’AST est construit a à voir avec les nœuds de cet arbre.
L’image ci-dessous illustre l’anatomie d’un seul nœud dans un arbre de syntaxe abstraite.
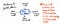
Nous remarquerons que ce nœud est similaire à d’autres que nous avons vus auparavant en ce qu’il contient des données (un token et son value). Cependant, il contient également des pointeurs très spécifiques. Chaque nœud dans une AST contient des références à son prochain nœud frère, ainsi qu’à son premier nœud enfant.
Par exemple, notre expression simple de 5 + (1 x 12) pourrait être construite en une illustration visualisée d’une AST, comme celle ci-dessous.

Nous pouvons imaginer que la lecture, la traversée ou « l’interprétation » de cette AST pourrait commencer par les niveaux inférieurs de l’arbre, en remontant pour construire une valeur ou un retour result par la fin.
Il peut également être utile de voir une version codée de la sortie d’un parseur pour aider à compléter nos visualisations. Nous pouvons nous appuyer sur divers outils et utiliser des analyseurs préexistants pour voir un exemple rapide de ce à quoi notre expression pourrait ressembler lorsqu’elle est exécutée par un analyseur. Voici un exemple de notre texte source, 5 + (1 * 12), exécuté par Esprima, un analyseur ECMAScript, et l’arbre syntaxique abstrait qui en résulte, suivi d’une liste de ses tokens distincts.
Dans ce format, nous pouvons voir l’imbrication de l’arbre si nous regardons les objets imbriqués. Nous remarquerons que les valeurs contenant 1 et 12 sont les left et right enfants, respectivement, d’une opération mère, *. Nous verrons également que l’opération de multiplication (*) constitue le sous-arbre de droite de l’expression entière elle-même, ce qui explique pourquoi elle est imbriquée dans l’objet plus large BinaryExpression, sous la clé "right". De même, la valeur de 5 est le seul "left" enfant de l’objet plus grand BinaryExpression.

L’aspect le plus intriguant de l’arbre syntaxique abstrait est, cependant, le fait que même s’ils sont si compacts et propres, ils ne sont pas toujours une structure de données facile à essayer et à construire. En fait, la construction d’un AST peut être assez complexe, selon la langue que l’analyseur syntaxique traite!
La plupart des analyseurs syntaxiques vont généralement soit construire un arbre d’analyse (CST) et ensuite le convertir en un format AST, parce que cela peut parfois être plus facile – même si cela signifie plus d’étapes, et généralement parlant, plus de passages à travers le texte source. Construire un CST est en fait assez facile une fois que l’analyseur connaît la grammaire de la langue qu’il essaie d’analyser. Il n’a pas besoin de faire un travail compliqué pour déterminer si un token est « significatif » ou non ; au lieu de cela, il prend exactement ce qu’il voit, dans l’ordre spécifique qu’il le voit, et crache le tout dans un arbre.
D’autre part, il y a certains analyseurs qui vont essayer de faire tout cela comme un processus en une seule étape, sautant directement à la construction d’un arbre syntaxique abstrait.
Construire un AST directement peut être délicat, puisque l’analyseur syntaxique doit non seulement trouver les tokens et les représenter correctement, mais aussi décider quels tokens sont importants pour nous, et lesquels ne le sont pas.
Dans la conception du compilateur, l’AST finit par être super important pour plus d’une raison. Oui, il peut être délicat à construire (et probablement facile à foirer), mais aussi, c’est le dernier et dernier résultat des phases d’analyse lexicale et syntaxique combinées ! Les phases d’analyse lexicale et syntaxique sont souvent appelées conjointement la phase d’analyse, ou le frontal du compilateur.

Nous pouvons penser à l’arbre syntaxique abstrait comme le « projet final » du frontal du compilateur. C’est la partie la plus importante, car c’est la dernière chose que le front-end doit montrer pour lui-même. Le terme technique pour cela est appelé la représentation intermédiaire du code ou la RI, parce qu’elle devient la structure de données qui est finalement utilisée par le compilateur pour représenter un texte source.
Un arbre syntaxique abstrait est la forme la plus commune de la RI, mais aussi, parfois la plus mal comprise. Mais maintenant que nous le comprenons un peu mieux, nous pouvons commencer à changer notre perception de cette structure effrayante ! Espérons qu’elle soit un peu moins intimidante pour nous maintenant.
Ressources
Il existe tout un tas de ressources sur les AST, dans une variété de langues. Savoir où commencer peut être délicat, surtout si vous cherchez à en savoir plus. Ci-dessous, vous trouverez quelques ressources adaptées aux débutants qui plongent dans un tas de détails sans être trop assommantes. Joyeux asbtracting!
- L’AST contre l’arbre d’analyse, Professeur Charles N. Fischer
- Quelle est la différence entre les arbres d’analyse et les arbres de syntaxe abstraite ? StackOverflow
- Arbres syntaxiques abstraits contre arbres syntaxiques concrets, Eli Bendersky
- Arbres syntaxiques abstraits, Professeur Stephen A. Edwards
- Arbres syntaxiques abstraits & Parsing top-down, Professeur Konstantinos (Kostis) Sagonas
- Analyse lexicale et syntaxique des langages de programmation, Chris Northwood
- AST Explorer, Felix Kling
.