Dernière mise à jour le 18 août 2020
Les ensembles de données peuvent avoir des valeurs manquantes, et cela peut causer des problèmes pour de nombreux algorithmes d’apprentissage automatique.
Comme tel, c’est une bonne pratique d’identifier et de remplacer les valeurs manquantes pour chaque colonne dans vos données d’entrée avant de modéliser votre tâche de prédiction. C’est ce qu’on appelle l’imputation des données manquantes, ou imputation pour faire court.
Une approche populaire pour l’imputation des données consiste à calculer une valeur statistique pour chaque colonne (telle qu’une moyenne) et à remplacer toutes les valeurs manquantes pour cette colonne par la statistique. C’est une approche populaire parce que la statistique est facile à calculer en utilisant l’ensemble de données d’entraînement et parce qu’elle donne souvent de bonnes performances.
Dans ce tutoriel, vous découvrirez comment utiliser les stratégies d’imputation statistique pour les données manquantes dans l’apprentissage automatique.
Après avoir terminé ce tutoriel, vous saurez :
- Les valeurs manquantes doivent être marquées avec des valeurs NaN et peuvent être remplacées par des mesures statistiques pour calculer la colonne de valeurs.
- Comment charger une valeur CSV avec des valeurs manquantes et marquer les valeurs manquantes avec des valeurs NaN et rapporter le nombre et le pourcentage de valeurs manquantes pour chaque colonne.
- Comment imputer les valeurs manquantes avec des statistiques comme méthode de préparation des données lors de l’évaluation des modèles et lors de l’ajustement d’un modèle final pour faire des prédictions sur de nouvelles données.
Démarrez votre projet avec mon nouveau livre Data Preparation for Machine Learning, comprenant des tutoriels étape par étape et les fichiers de code source Python pour tous les exemples.
Démarrons.
- Mise à jour Jun/2020 : Changement de la colonne utilisée pour la prédiction dans les exemples.

Imputation statistique pour les valeurs manquantes en apprentissage automatique
Photo de Bernal Saborio, certains droits réservés.
Vue d’ensemble du tutoriel
Ce tutoriel est divisé en trois parties ; ce sont :
- Imputation statistique
- Ensemble de données sur les coliques de chevaux
- Imputation statistique avec SimpleImputer
- Transformation des données par SimpleImputer
- SimpleImputer et évaluation du modèle
- Comparaison de différentes statistiques imputées
- Transformation de SimpleImputer lors d’une prédiction
.
Imputation statistique
Un ensemble de données peut avoir des valeurs manquantes.
Ce sont des lignes de données où une ou plusieurs valeurs ou colonnes de cette ligne ne sont pas présentes. Les valeurs peuvent manquer complètement ou être marquées d’un caractère ou d’une valeur spéciale, comme un point d’interrogation » ? ».
Ces valeurs peuvent être exprimées de plusieurs façons. Je les ai vues apparaître comme rien du tout , une chaîne vide , la chaîne explicite NULL ou indéfinie ou N/A ou NaN, et le nombre 0, entre autres. Peu importe comment ils apparaissent dans votre ensemble de données, savoir à quoi s’attendre et vérifier que les données correspondent à cette attente réduira les problèmes lorsque vous commencerez à utiliser les données.
– Page 10, Bad Data Handbook, 2012.
Les valeurs pourraient être manquantes pour de nombreuses raisons, souvent spécifiques au domaine du problème, et pourraient inclure des raisons telles que des mesures corrompues ou l’indisponibilité des données.
Elles peuvent se produire pour un certain nombre de raisons, telles qu’un dysfonctionnement de l’équipement de mesure, des changements dans la conception expérimentale pendant la collecte des données, et le collationnement de plusieurs ensembles de données similaires mais non identiques.
– Page 63, Data Mining : Practical Machine Learning Tools and Techniques, 2016.
La plupart des algorithmes d’apprentissage automatique nécessitent des valeurs d’entrée numériques, et une valeur doit être présente pour chaque ligne et chaque colonne dans un ensemble de données. À ce titre, les valeurs manquantes peuvent poser des problèmes aux algorithmes d’apprentissage automatique.
À ce titre, il est courant d’identifier les valeurs manquantes dans un ensemble de données et de les remplacer par une valeur numérique. C’est ce qu’on appelle l’imputation des données, ou l’imputation des données manquantes.
Une approche simple et populaire de l’imputation des données consiste à utiliser des méthodes statistiques pour estimer une valeur pour une colonne à partir des valeurs présentes, puis à remplacer toutes les valeurs manquantes de la colonne par la statistique calculée.
Elle est simple car les statistiques sont rapides à calculer et elle est populaire car elle s’avère souvent très efficace.
Les statistiques courantes calculées comprennent :
- La valeur moyenne de la colonne.
- La valeur médiane de la colonne.
- La valeur du mode de la colonne.
- Une valeur constante.
Maintenant que nous sommes familiers avec les méthodes statistiques d’imputation des valeurs manquantes, jetons un coup d’œil à un ensemble de données avec des valeurs manquantes.
Vous voulez vous lancer dans la préparation des données ?
Prenez dès maintenant mon cours intensif gratuit de 7 jours par courriel (avec un exemple de code).
Cliquez pour vous inscrire et obtenir également une version Ebook PDF gratuite du cours.
Téléchargez votre mini-cours GRATUIT
Jeu de données sur les coliques de chevaux
Le jeu de données sur les coliques de chevaux décrit les caractéristiques médicales des chevaux atteints de coliques et s’ils vivent ou meurent.
Il y a 300 lignes et 26 variables d’entrée avec une variable de sortie. Il s’agit d’une tâche de prédiction de classification binaire qui consiste à prédire 1 si le cheval a vécu et 2 si le cheval est mort.
Il existe de nombreux champs que nous pourrions sélectionner pour prédire dans cet ensemble de données. Dans ce cas, nous allons prédire si le problème était chirurgical ou non (indice de colonne 23), ce qui en fait un problème de classification binaire.
Le jeu de données a de nombreuses valeurs manquantes pour beaucoup de colonnes où chaque valeur manquante est marquée par un caractère de point d’interrogation ( » ? « ).
Vous trouverez ci-dessous un exemple de lignes du jeu de données avec des valeurs manquantes marquées.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Vous pouvez en savoir plus sur le jeu de données ici :
- Données sur les coliques de chevaux
- Description du jeu de données sur les coliques de chevaux
Nul besoin de télécharger le jeu de données car nous le téléchargerons automatiquement dans les exemples travaillés.
Marquer les valeurs manquantes avec une valeur NaN (pas un nombre) dans un jeu de données chargé en utilisant Python est une bonne pratique.
Nous pouvons charger le jeu de données en utilisant la fonction Pandas read_csv() et spécifier la valeur « na_values » pour charger les valeurs de ‘ ?’ comme manquantes, marquées par une valeur NaN.
|
1
2
3
4
|
…
# charger le jeu de données
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’ ?’)
|
Une fois chargées, nous pouvons examiner les données chargées pour confirmer que les valeurs » ? » sont marquées comme NaN.
|
1
2
3
|
…
# résumer les premiers rangs
print(dataframe.head()).
|
Nous pouvons ensuite énumérer chaque colonne et rapporter le nombre de lignes avec des valeurs manquantes pour la colonne.
|
1
2
3
4
5
6
7
|
…
# résumer le nombre de lignes avec des valeurs manquantes pour chaque colonne
for i in range(dataframe.shape) :
# compter le nombre de lignes avec des valeurs manquantes
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Missing : %d (%.1f%%)’ % (i, n_miss, perc)).
|
En reliant tout cela, l’exemple complet de chargement et de résumé du jeu de données est énuméré ci-dessous.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# résume le jeu de données sur les coliques de chevaux
from pandas import read_csv
# charge le jeu de données
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# résumer les premières lignes
print(dataframe.head())
# résumer le nombre de lignes avec des valeurs manquantes pour chaque colonne
for i in range(dataframe.shape) :
# compter le nombre de lignes avec des valeurs manquantes
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(‘> %d, Missing : %d (%.1f%%)’ % (i, n_miss, perc)).
|
L’exécution de l’exemple charge d’abord le jeu de données et résume les cinq premières lignes.
Nous pouvons voir que les valeurs manquantes qui étaient marquées par un caractère » ? » ont été remplacées par des valeurs NaN.
Puis, nous pouvons voir la liste de toutes les colonnes de l’ensemble de données et le nombre et le pourcentage de valeurs manquantes.
Nous pouvons voir que certaines colonnes (par exemple, les indices de colonne 1 et 2) n’ont aucune valeur manquante et d’autres colonnes (par exemple, les indices de colonne 15 et 21) ont beaucoup ou même une majorité de valeurs manquantes.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Manquant : 1 (0,3%)
> 1, Manquant : 0 (0,0%)
> 2, Manquant : 0 (0.0%)
> 3, Manquant : 60 (20,0%)
> 4, Manquant : 24 (8,0%)
> 5, Manquant : 58 (19,3%)
> 6, Manquant : 56 (18,7%)
> 7, Manquant : 69 (23,0%)
> 8, Manquant : 47 (15,7%)
> 9, Manquant : 32 (10,7%)
> 10, Manquant : 55 (18,3%)
> 11, Manquant : 44 (14,7%)
> 12, Manquant : 56 (18,7%)
> 13, Manquants : 104 (34,7%)
> 14, Manquant : 106 (35,3%)
> 15, Manquants : 247 (82,3%)
> 16, Manquant : 102 (34,0%)
> 17, Manquant : 118 (39,3%)
> 18, Manquant : 29 (9,7%)
> 19, Manquant : 33 (11,0%)
> 20, Manquants : 165 (55,0%)
> 21, Manquant : 198 (66,0%)
> 22, Manquant : 1 (0,3%)
> 23, Manquant : 0 (0.0%)
> 24, Manquant : 0 (0.0%)
> 25, Manquant : 0 (0.0%)
> 26, Manquant : 0 (0.0%)
> 27, Manquant : 0 (0,0%)
|
Maintenant que nous sommes familiers avec l’ensemble de données de coliques de chevaux qui a des valeurs manquantes, regardons comment nous pouvons utiliser l’imputation statistique.
Statistical Imputation With SimpleImputer
La bibliothèque d’apprentissage machine scikit-learn fournit la classe SimpleImputer qui supporte l’imputation statistique.
Dans cette section, nous allons explorer comment utiliser efficacement la classe SimpleImputer.
Transformation de données SimpleImputer
Le SimpleImputer est une transformation de données qui est d’abord configurée en fonction du type de statistique à calculer pour chaque colonne, par ex.ex. moyenne.
|
1
2
3
|
…
# define imputer
imputer = SimpleImputer(strategy=’mean’)
|
L’imputer est ensuite ajusté sur un ensemble de données pour calculer la statistique de chaque colonne.
|
1
2
3
|
…
# fit sur le jeu de données
imputer.fit(X)
|
L’imputer fit est ensuite appliqué à un jeu de données pour créer une copie du jeu de données avec toutes les valeurs manquantes pour chaque colonne remplacées par une valeur statistique.
|
1
2
3
|
…
# transformer l’ensemble de données
Xtrans = imputer.transformer(X)
|
Nous pouvons démontrer son utilisation sur l’ensemble de données de coliques de chevaux et confirmer qu’il fonctionne en résumant le nombre total de valeurs manquantes dans l’ensemble de données avant et après la transformation.
L’exemple complet est répertorié ci-dessous.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# imputation statistique transformation pour le jeu de données sur les coliques du cheval
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
X, y = données, données
# print total missing
print(‘Missing : %d’ % sum(isnan(X).flatten()))
# définir imputer
imputer = SimpleImputer(stratégie=’mean’)
# ajuster sur l’ensemble de données
imputer.fit(X)
# transformer l’ensemble de données
Xtrans = imputer.transform(X)
# imprimer le total des manquants
print(‘Manquant : %d » % sum(isnan(Xtrans).flatten()))
|
L’exécution de l’exemple charge d’abord l’ensemble de données et signale le nombre total de valeurs manquantes dans l’ensemble de données comme étant de 1 605.
La transformation est configurée, ajustée et exécutée et le nouvel ensemble de données résultant n’a aucune valeur manquante, confirmant qu’elle a été exécutée comme nous l’attendions.
Chaque valeur manquante a été remplacée par la valeur moyenne de sa colonne.
|
1
2
|
Manque : 1605
Manque : 0
|
SimpleImputation et évaluation de modèles
C’est une bonne pratique d’évaluer les modèles d’apprentissage automatique sur un ensemble de données en utilisant la validation croisée k-fold.
Pour appliquer correctement l’imputation statistique des données manquantes et éviter les fuites de données, il est nécessaire que les statistiques calculées pour chaque colonne soient calculées sur le jeu de données d’entraînement uniquement, puis appliquées aux jeux d’entraînement et de test pour chaque pli du jeu de données.
Si nous utilisons le rééchantillonnage pour sélectionner les valeurs des paramètres d’accord ou pour estimer les performances, l’imputation doit être incorporée dans le rééchantillonnage.
– Page 42, Applied Predictive Modeling, 2013.
Cela peut être réalisé en créant un pipeline de modélisation où la première étape est l’imputation statistique, puis la deuxième étape est le modèle. Ceci peut être réalisé en utilisant la classe Pipeline.
Par exemple, le Pipeline ci-dessous utilise un SimpleImputer avec une stratégie ‘moyenne’, suivi d’un modèle de forêt aléatoire.
|
1
2
3
4
5
|
…
# define modeling pipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
|
Nous pouvons évaluer l’ensemble de données imputées à la moyenne.imputed dataset et le pipeline de modélisation de la forêt aléatoire pour le jeu de données de coliques de chevaux avec une validation croisée 10 fois répétée.
L’exemple complet est répertorié ci-dessous.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
25
|
# évalue l’imputation de la moyenne et la forêt aléatoire forest pour le jeu de données sur les coliques de chevaux
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# diviser en éléments d’entrée et de sortie
data = dataframe.values
ix = ) if i != 23]
X, y = données, données
# définir le pipeline de modélisation
modèle = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
# définir l’évaluation du modèle
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# évaluer le modèle
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
print(‘Mean Accuracy : %.3f (%.3f)’ % (mean(scores), std(scores)))
|
L’exécution de l’exemple applique correctement l’imputation des données à chaque pli de la procédure de validation croisée.
Note : Vos résultats peuvent varier compte tenu de la nature stochastique de l’algorithme ou de la procédure d’évaluation, ou des différences de précision numérique. Envisagez d’exécuter l’exemple plusieurs fois et comparez le résultat moyen.
Le pipeline est évalué en utilisant trois répétitions de la validation croisée 10 fois et rapporte la précision de classification moyenne sur le jeu de données comme environ 86.3 pour cent, ce qui est un bon score.
|
1
|
Exactitude moyenne : 0,863 (0.054)
|
Comparaison de différentes statistiques imputées
Comment savons-nous que l’utilisation d’une stratégie statistique » moyenne » est bonne ou meilleure pour cet ensemble de données ?
La réponse est que nous ne le savons pas et qu’elle a été choisie arbitrairement.
Nous pouvons concevoir une expérience pour tester chaque stratégie statistique et découvrir celle qui fonctionne le mieux pour cet ensemble de données, en comparant les stratégies moyenne, médiane, mode (le plus fréquent) et constante (0). La précision moyenne de chaque approche peut alors être comparée.
L’exemple complet est repris ci-dessous.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# comparer stratégies d’imputation statistique pour le jeu de données sur les coliques de chevaux
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from matplotlib import pyplot
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’ ?’)
# diviser en éléments d’entrée et de sortie
data = dataframe.values
ix = ) if i != 23]
X, y = données, données
# évaluer chaque stratégie sur le jeu de données
résultats = liste()
stratégies =
for s in stratégies :
# créer le pipeline de modélisation
pipeline = Pipeline(steps=)
# évaluer le modèle
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(pipeline, X, y, scoring=’accuracy’, cv=cv, n_jobs=-1)
# stocker les résultats
results.append(scores)
print(‘>%s %.3f (%.3f)’ % (s, mean(scores), std(scores)))
# tracer les performances du modèle pour la comparaison
pyplot.boxplot(results, labels=strategies, showmeans=True)
pyplot.show()
|
L’exécution de l’exemple évalue chaque stratégie d’imputation statistique sur le jeu de données de coliques de chevaux en utilisant la validation croisée répétée.
Note : Vos résultats peuvent varier compte tenu de la nature stochastique de l’algorithme ou de la procédure d’évaluation, ou des différences de précision numérique. Envisagez d’exécuter l’exemple plusieurs fois et comparez le résultat moyen.
La précision moyenne de chaque stratégie est signalée en cours de route. Les résultats suggèrent que l’utilisation d’une valeur constante, par exemple 0, donne la meilleure performance d’environ 88,1 pour cent, ce qui est un résultat exceptionnel.
|
1
2
3
4
|
>moyenne 0.860 (0,054)
>médiane 0,862 (0.065)
>les plus fréquentes 0,872 (0,052)
>constante 0,881 (0,047)
|
À la fin de l’exécution, un graphique en boîte et moustaches est créé pour chaque ensemble de résultats, permettant de comparer la distribution des résultats.
Nous pouvons clairement voir que la distribution des scores de précision pour la stratégie constante est meilleure que les autres stratégies.
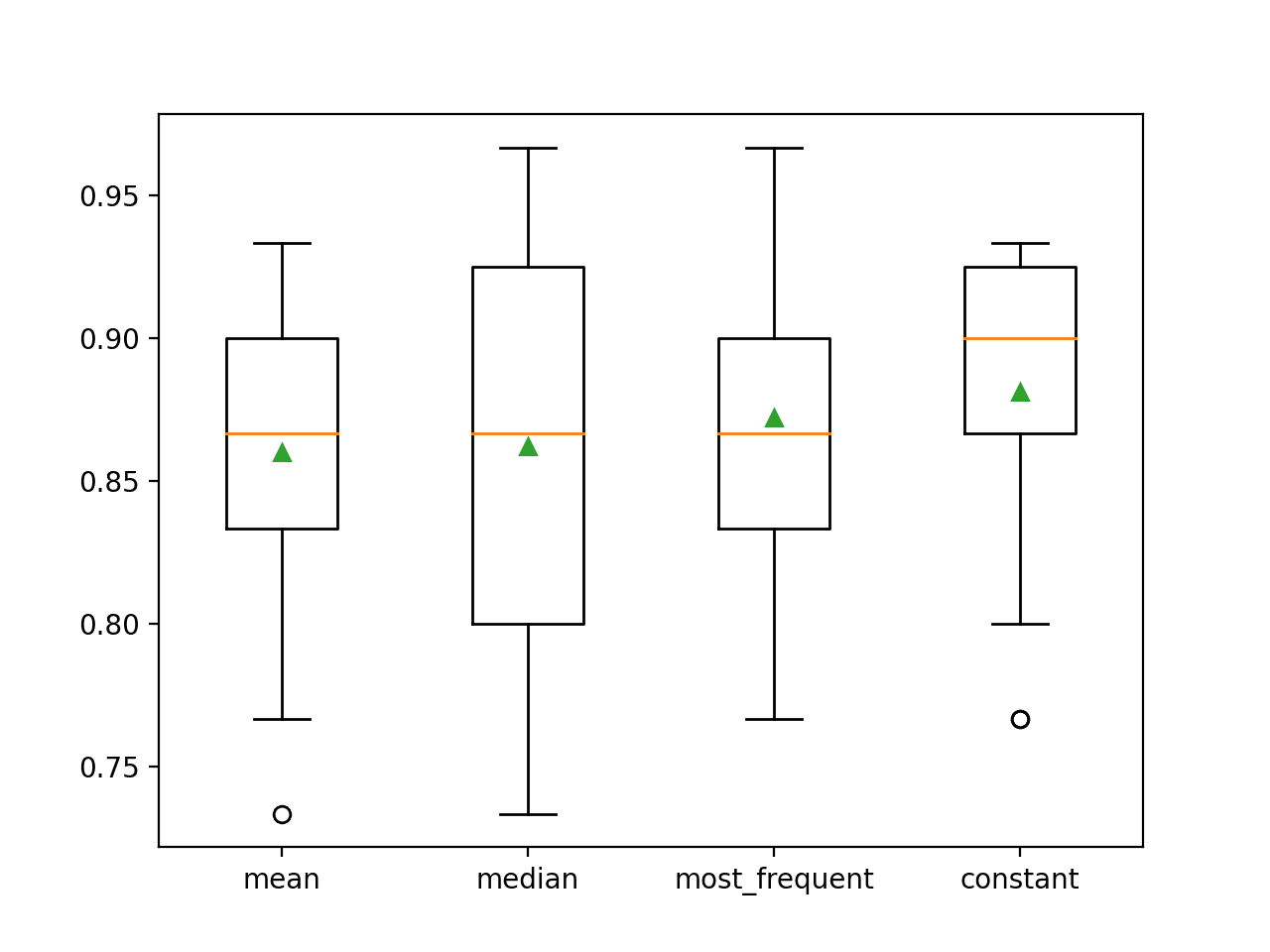
Tracé de boîtes et de moustaches des stratégies d’imputation statistique appliquées au jeu de données sur les coliques de chevaux
Transformation simple de l’ordinateur lors de la réalisation d’une prédiction
Nous pouvons souhaiter créer un pipeline de modélisation final avec la stratégie d’imputation constante et l’algorithme de forêt aléatoire, puis réaliser une prédiction pour les nouvelles données.
Cela peut être réalisé en définissant le pipeline et en l’ajustant sur toutes les données disponibles, puis en appelant la fonction predict() en passant les nouvelles données en argument.
Important, la ligne des nouvelles données doit marquer toutes les valeurs manquantes en utilisant la valeur NaN.
|
1
2
3
|
…
# définir de nouvelles données
row =
|
L’exemple complet est repris ci-dessous.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# imputation constante stratégie et prédiction pour le jeu de données de coliques de tuyau
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’ ?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
X, y = données, données
# créer le pipeline de modélisation
pipeline = Pipeline(steps=)
# ajuster le modèle
pipeline.fit(X, y)
# définir de nouvelles données
row =
# faire une prédiction
yhat = pipeline.predict()
# résumer la prédiction
print(‘Classe prédite : %d’ % yhat)
|
L’exécution de l’exemple adapte le pipeline de modélisation sur toutes les données disponibles.
Une nouvelle ligne de données est définie avec les valeurs manquantes marquées par des NaN et une prédiction de classification est effectuée.
|
1
|
Classe prédite : 2
|
Lectures complémentaires
Cette section fournit plus de ressources sur le sujet si vous cherchez à approfondir.
Tutoriels connexes
- Résultats pour les ensembles de données d’apprentissage automatique de classification et de régression standard
- Comment gérer les données manquantes avec Python
Livres
- Manuel des mauvaises données, 2012.
- Data Mining : Outils et techniques pratiques d’apprentissage automatique, 2016.
- Modélisation prédictive appliquée, 2013.
APIs
- Imputation des valeurs manquantes, documentation scikit-learn.
- API sklearn.impute.SimpleImputer.
Dataset
- Dataset de coliques de chevaux
- Dataset de coliques de chevaux Description
Summary
Dans ce tutoriel, vous avez découvert comment utiliser les stratégies d’imputation statistique pour les données manquantes en apprentissage automatique.
Spécifiquement, vous avez appris :
- Les valeurs manquantes doivent être marquées avec des valeurs NaN et peuvent être remplacées par des mesures statistiques pour calculer la colonne de valeurs.
- Comment charger une valeur CSV avec des valeurs manquantes et marquer les valeurs manquantes avec des valeurs NaN et rapporter le nombre et le pourcentage de valeurs manquantes pour chaque colonne.
- Comment imputer les valeurs manquantes avec des statistiques comme méthode de préparation des données lors de l’évaluation des modèles et lors de l’ajustement d’un modèle final pour faire des prédictions sur de nouvelles données.
Avez-vous des questions ?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.
Prenez en main la préparation moderne des données !

Préparez vos données d’apprentissage automatique en quelques minutes
….avec seulement quelques lignes de code python
Découvrez comment dans mon nouvel Ebook:
Préparation des données pour l’apprentissage automatique
Il fournit des tutoriels d’auto-apprentissage avec un code de travail complet sur:
Sélection des caractéristiques, RFE, nettoyage des données, transformations des données, mise à l’échelle, réduction de la dimensionnalité, et bien plus encore…
Amenez les techniques modernes de préparation des données à
vos projets d’apprentissage automatique
Voyez ce qu’il y a dedans
.