
Si vous voulez en apprendre davantage en Python, suivez le cours gratuit Intro to Python for Data Science de DataCamp.
Vous avez tous vu des ensembles de données. Parfois, ils sont petits, mais souvent, ils sont d’une taille énorme. Il devient très difficile de traiter les ensembles de données qui sont très grands, du moins assez importants pour causer un goulot d’étranglement de traitement.
Alors, qu’est-ce qui rend ces ensembles de données si grands ? Eh bien, ce sont les caractéristiques. Plus le nombre de caractéristiques est important, plus les ensembles de données seront grands. Enfin, pas toujours. Vous trouverez des jeux de données où le nombre de caractéristiques est très élevé, mais qui ne contiennent pas autant d’instances. Mais ce n’est pas le sujet de la discussion ici. Alors, vous pouvez vous demander, avec un ordinateur de commodité en main, comment traiter ce type de jeux de données sans tourner autour du pot.
Souvent, dans un jeu de données à haute dimension, il reste des caractéristiques totalement non pertinentes, insignifiantes et sans importance. Il a été constaté que la contribution de ces types de caractéristiques est souvent moindre vers la modélisation prédictive par rapport aux caractéristiques critiques. Leur contribution peut même être nulle. Ces caractéristiques causent un certain nombre de problèmes qui, à leur tour, empêchent le processus de modélisation prédictive efficace –
- Allocation inutile de ressources pour ces caractéristiques.
- Ces caractéristiques agissent comme un bruit pour lequel le modèle d’apprentissage machine peut avoir des performances terriblement faibles.
- Le modèle machine prend plus de temps pour être formé.
Alors, quelle est la solution ici ? La solution la plus économique est la sélection de caractéristiques.
La sélection de caractéristiques est le processus de sélection des caractéristiques les plus significatives d’un ensemble de données donné. Dans de nombreux cas, la sélection de caractéristiques peut également améliorer les performances d’un modèle d’apprentissage automatique.
Son intérêt n’est-ce pas ?
Vous avez eu une introduction informelle à la sélection de caractéristiques et à son importance dans le monde de la science des données et de l’apprentissage automatique. Dans ce post, vous allez couvrir :
- Introduction à la sélection de caractéristiques et compréhension de son importance
- Différence entre la sélection de caractéristiques et la réduction de la dimensionnalité
- Différents types de méthodes de sélection de caractéristiques
- Implémentation de différentes méthodes de sélection de caractéristiques avec scikit-…learn
Introduction à la sélection de caractéristiques
La sélection de caractéristiques est également connue sous le nom de sélection de variables ou de sélection d’attributs.
Essentiellement, c’est le processus de sélection des plus importantes/pertinentes. Caractéristiques d’un ensemble de données.
Comprendre l’importance de la sélection des caractéristiques
L’importance de la sélection des caractéristiques peut être mieux reconnue lorsque vous traitez avec un ensemble de données qui contient un grand nombre de caractéristiques. Ce type de jeu de données est souvent appelé jeu de données à haute dimension. Maintenant, avec cette haute dimensionnalité, vient un grand nombre de problèmes tels que – cette haute dimensionnalité augmentera considérablement le temps d’apprentissage de votre modèle d’apprentissage automatique, il peut rendre votre modèle très compliqué qui à son tour peut conduire à Overfitting.
Souvent dans un ensemble de caractéristiques de haute dimension, il reste plusieurs caractéristiques qui sont redondantes signifiant que ces caractéristiques ne sont rien d’autre que des extensions des autres caractéristiques essentielles. Ces caractéristiques redondantes ne contribuent pas non plus efficacement à l’apprentissage du modèle. Donc, clairement, il est nécessaire d’extraire les caractéristiques les plus importantes et les plus pertinentes pour un ensemble de données afin d’obtenir la performance de modélisation prédictive la plus efficace.
« L’objectif de la sélection des variables est triple : améliorer la performance de prédiction des prédicteurs, fournir des prédicteurs plus rapides et plus rentables, et fournir une meilleure compréhension du processus sous-jacent qui a généré les données. »
-Une introduction à la sélection de variables et de caractéristiques
Maintenant, comprenons la différence entre la réduction de la dimensionnalité et la sélection de caractéristiques.
Parfois, la sélection de caractéristiques est confondue avec la réduction de la dimensionnalité. Mais ils sont différents. La sélection de caractéristiques est différente de la réduction de la dimensionnalité. Les deux méthodes tendent à réduire le nombre d’attributs dans l’ensemble de données, mais une méthode de réduction de la dimensionnalité le fait en créant de nouvelles combinaisons d’attributs (parfois appelée transformation des caractéristiques), alors que les méthodes de sélection des caractéristiques incluent et excluent les attributs présents dans les données sans les modifier.
Certains exemples de méthodes de réduction de la dimensionnalité sont l’analyse en composantes principales, la décomposition en valeurs singulières, l’analyse discriminante linéaire, etc.
Laissez-moi vous résumer l’importance de la sélection de caractéristiques :
- Elle permet à l’algorithme d’apprentissage automatique de s’entraîner plus rapidement.
- Elle réduit la complexité d’un modèle et le rend plus facile à interpréter.
- Elle améliore la précision d’un modèle si le bon sous-ensemble est choisi.
- Elle réduit l’Overfitting.
Dans la section suivante, vous étudierez les différents types de méthodes générales de sélection de caractéristiques – les méthodes de filtre, les méthodes de wrapper et les méthodes intégrées.
Méthodes de filtre
L’image suivante décrit le mieux les méthodes de sélection de caractéristiques basées sur le filtre:

Source de l’image : Analytics Vidhya
La méthode du filtre s’appuie sur l’unicité générale des données à évaluer et choisit un sous-ensemble de caractéristiques, sans inclure aucun algorithme de minage. La méthode du filtre utilise le critère d’évaluation exact qui comprend la distance, l’information, la dépendance et la cohérence. La méthode de filtrage utilise les principaux critères de la technique de classement et utilise la méthode de classement pour la sélection des variables. La raison de l’utilisation de la méthode de classement est la simplicité, la production de caractéristiques excellentes et pertinentes. La méthode de classement va filtrer les caractéristiques non pertinentes avant le début du processus de classification.
Les méthodes de filtrage sont généralement utilisées comme une étape de prétraitement des données. La sélection des caractéristiques est indépendante de tout algorithme d’apprentissage automatique. Les caractéristiques donnent un rang sur la base de scores statistiques qui tendent à déterminer la corrélation des caractéristiques avec la variable de résultat. La corrélation est un terme fortement contextuel, qui varie d’un travail à l’autre. Vous pouvez vous référer au tableau suivant pour définir les coefficients de corrélation pour différents types de données (dans ce cas, continues et catégorielles).

Source de l’image : Analytics Vidhya
Certains exemples de certaines méthodes de filtrage incluent le test du Khi-deux, le gain d’information et les scores de coefficient de corrélation.
Puis, vous verrez les méthodes de wrapper.
Méthodes wrapper
Comme les méthodes de filtrage, laissez-moi vous donner un même type d’info-graphique qui vous aidera à mieux comprendre les méthodes wrapper :
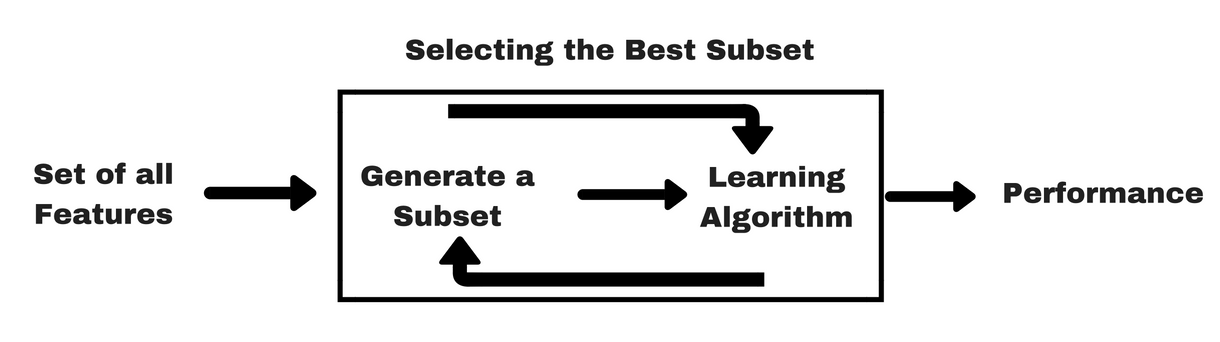
Source de l’image : Analytics Vidhya
Comme vous pouvez le voir dans l’image ci-dessus, une méthode wrapper a besoin d’un algorithme d’apprentissage automatique et utilise ses performances comme critères d’évaluation. Cette méthode recherche une caractéristique qui est la mieux adaptée à l’algorithme d’apprentissage automatique et vise à améliorer les performances d’extraction. Pour évaluer les caractéristiques, la précision prédictive utilisée pour les tâches de classification et la bonté du cluster est évaluée en utilisant le clustering.
Certains exemples typiques de méthodes wrapper sont la sélection de caractéristiques en avant, l’élimination de caractéristiques en arrière, l’élimination de caractéristiques récursive, etc.
- Sélection en avant : La procédure commence avec un ensemble vide de caractéristiques . La meilleure des caractéristiques originales est déterminée et ajoutée à l’ensemble réduit. A chaque itération suivante, le meilleur des attributs originaux restants est ajouté à l’ensemble.
- Elimination à rebours : La procédure commence avec l’ensemble complet d’attributs. A chaque étape, elle élimine le pire attribut restant dans l’ensemble.
- Combinaison de la sélection en avant et de l’élimination en arrière : Les méthodes de sélection avant et d’élimination arrière par étapes peuvent être combinées de sorte que, à chaque étape, la procédure sélectionne le meilleur attribut et élimine le pire parmi les attributs restants.
- Élimination récursive de caractéristiques : L’élimination récursive des caractéristiques effectue une recherche avide pour trouver le sous-ensemble de caractéristiques le plus performant. Elle crée itérativement des modèles et détermine la caractéristique la plus performante ou la moins performante à chaque itération. Il construit les modèles suivants avec les caractéristiques restantes jusqu’à ce que toutes les caractéristiques soient explorées. Il classe ensuite les caractéristiques en fonction de l’ordre de leur élimination. Dans le pire des cas, si un jeu de données contient N nombre de caractéristiques, RFE fera une recherche avide de 2N combinaisons de caractéristiques.
Bien joué!
Maintenant, étudions les méthodes embarquées.
Méthodes embarquées
Les méthodes embarquées sont itératives dans un sens qui prend en charge chaque itération du processus de formation du modèle et extrait soigneusement les caractéristiques qui contribuent le plus à la formation pour une itération particulière. Les méthodes de régularisation sont les méthodes intégrées les plus couramment utilisées qui pénalisent une caractéristique étant donné un seuil de coefficient.
C’est pourquoi les méthodes de régularisation sont également appelées méthodes de pénalisation qui introduisent des contraintes supplémentaires dans l’optimisation d’un algorithme prédictif (tel qu’un algorithme de régression) qui biaisent le modèle vers une plus faible complexité (moins de coefficients).
Les exemples d’algorithmes de régularisation sont le LASSO, Elastic Net, Ridge Regression, etc.
Différence entre les méthodes de filtre et de wrapper
Bien, il peut parfois être déroutant de différencier les méthodes de filtre et les méthodes de wrapper en termes de fonctionnalités. Jetons un coup d’œil aux points sur lesquels elles diffèrent les unes des autres.
- Les méthodes de filtrage n’intègrent pas de modèle d’apprentissage automatique afin de déterminer si une caractéristique est bonne ou mauvaise alors que les méthodes de wrapper utilisent un modèle d’apprentissage automatique et l’entraînent la caractéristique pour décider si elle est essentielle ou non.
- Les méthodes de filtrage sont beaucoup plus rapides par rapport aux méthodes de wrapper car elles n’impliquent pas l’entraînement des modèles. D’autre part, les méthodes wrapper sont coûteuses en calcul, et dans le cas de jeux de données massifs, les méthodes wrapper ne sont pas la méthode de sélection de caractéristiques la plus efficace à considérer.
- Les méthodes de filtrage peuvent échouer à trouver le meilleur sous-ensemble de caractéristiques dans les situations où il n’y a pas assez de données pour modéliser la corrélation statistique des caractéristiques, mais les méthodes wrapper peuvent toujours fournir le meilleur sous-ensemble de caractéristiques en raison de leur nature exhaustive.
- L’utilisation des caractéristiques des méthodes wrapper dans votre modèle final d’apprentissage automatique peut conduire à un surajustement, car les méthodes wrapper forment déjà des modèles d’apprentissage automatique avec les caractéristiques et cela affecte la véritable puissance de l’apprentissage. Mais les caractéristiques des méthodes de filtre ne conduiront pas à l’overfitting dans la plupart des cas
Jusqu’à présent, vous avez étudié l’importance de la sélection de caractéristiques, compris sa différence avec la réduction de la dimensionnalité. Vous avez également couvert différents types de méthodes de sélection de caractéristiques. Jusqu’ici, tout va bien !
Maintenant, voyons quelques pièges dans lesquels vous pouvez tomber en effectuant la sélection de caractéristiques :
Considération importante
Vous avez peut-être déjà compris l’intérêt de la sélection de caractéristiques dans un pipeline d’apprentissage automatique et le type de services qu’elle fournit si elle est intégrée. Mais il est très important de comprendre à quel endroit exact vous devez intégrer la sélection de caractéristiques dans votre pipeline d’apprentissage automatique.
Pour parler simplement, vous devez inclure l’étape de sélection de caractéristiques avant de fournir les données au modèle pour l’entraînement, en particulier lorsque vous utilisez des méthodes d’estimation de la précision telles que la validation croisée. Cela garantit que la sélection de caractéristiques est effectuée sur le pli de données juste avant que le modèle ne soit formé. Mais si vous effectuez la sélection des caractéristiques d’abord pour préparer vos données, puis effectuez la sélection du modèle et la formation sur les caractéristiques sélectionnées, alors ce serait une gaffe.
Si vous effectuez la sélection des caractéristiques sur toutes les données et ensuite la validation croisée, alors les données de test dans chaque pli de la procédure de validation croisée ont également été utilisées pour choisir les caractéristiques, et cela a tendance à biaiser les performances de votre modèle d’apprentissage automatique.
Assez de théories ! Passons directement au codage maintenant.
Une étude de cas en Python
Pour cette étude de cas, vous utiliserez le jeu de données Pima Indians Diabetes. La description du jeu de données peut être trouvée ici.
Le jeu de données correspond à des tâches de classification sur lesquelles vous devez prédire si une personne a le diabète en fonction de 8 caractéristiques.
Il y a un total de 768 observations dans le jeu de données. Votre première tâche est de charger le jeu de données afin de pouvoir procéder. Mais avant cela, importons les dépendances nécessaires, dont vous allez avoir besoin. Vous pouvez importer les autres au fur et à mesure.
import pandas as pdimport numpy as npMaintenant que les dépendances sont importées, chargeons le jeu de données Pima Indians dans un objet Dataframe à l’aide de la bibliothèque Pandas.
data = pd.read_csv("diabetes.csv")Le jeu de données est chargé avec succès dans les données de l’objet Dataframe. Maintenant, jetons un coup d’œil aux données.
data.head()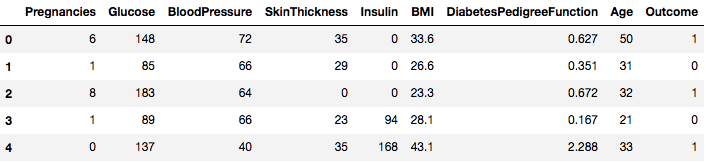
Vous pouvez donc voir 8 caractéristiques différentes étiquetées dans les résultats de 1 et 0 où 1 représente l’observation a le diabète, et 0 dénote l’observation n’a pas le diabète. L’ensemble de données est connu pour avoir des valeurs manquantes. Plus précisément, il y a des observations manquantes pour certaines colonnes qui sont marquées comme une valeur zéro. Vous pouvez déduire cela de la définition de ces colonnes, et il n’est pas pratique d’avoir une valeur zéro est invalide pour ces mesures, par ex, zéro pour l’indice de masse corporelle ou la pression artérielle est invalide.
Mais pour ce tutoriel, vous utiliserez directement la version prétraitée de l’ensemble de données.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Vous avez chargé les données dans un objet DataFrame appelé dataframe maintenant.
Convertissons l’objet DataFrame en un tableau NumPy pour obtenir un calcul plus rapide. De plus, séparons les données dans des variables distinctes afin que les caractéristiques et les étiquettes soient séparées.
array = dataframe.valuesX = arrayY = arrayMerveilleux ! Vous avez préparé vos données.
D’abord, vous allez mettre en œuvre un test statistique du Khi-deux pour les caractéristiques non négatives afin de sélectionner 4 des meilleures caractéristiques du jeu de données. Vous avez déjà vu que le test du Khi-deux appartient à la classe des méthodes de filtrage. Si quelqu’un est curieux de connaître les internes du Chi-Squared, cette vidéo fait un excellent travail.
La bibliothèque scikit-learn fournit la classe SelectKBest qui peut être utilisée avec une suite de différents tests statistiques pour sélectionner un nombre spécifique de caractéristiques, dans ce cas, c’est le Chi-Squared.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Vous avez importé les bibliothèques pour exécuter les expériences. Maintenant, voyons-les en action.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Interprétation :
Vous pouvez voir les scores pour chaque attribut et les 4 attributs choisis (ceux qui ont les scores les plus élevés) : plas, test, masse et âge. Ces scores vous aideront davantage à déterminer les meilleures caractéristiques pour l’entraînement de votre modèle.
P.S. : La première ligne dénote les noms des caractéristiques. Pour le prétraitement du jeu de données, les noms ont été codés numériquement.
Puis, vous allez mettre en œuvre l’élimination récursive des caractéristiques qui est un type de méthode de sélection des caractéristiques enveloppantes.
L’élimination récursive des caractéristiques (ou RFE) fonctionne en supprimant récursivement des attributs et en construisant un modèle sur les attributs qui restent.
Il utilise la précision du modèle pour identifier quels attributs (et combinaison d’attributs) contribuent le plus à la prédiction de l’attribut cible.
Vous pouvez en savoir plus sur la classe RFE dans la documentation de scikit-learn.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionVous utiliserez RFE avec le classificateur Logistic Regression pour sélectionner les 3 meilleures caractéristiques. Le choix de l’algorithme n’a pas trop d’importance tant qu’il est habile et cohérent.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Vous pouvez voir que RFE a choisi les 3 meilleures caractéristiques comme étant preg, mass, et pedi.
Celles-ci sont marquées True dans le tableau de support et marquées avec un choix « 1 » dans le tableau de classement. Ceci, à son tour, indique la force de ces caractéristiques.
Pour la suite, vous utiliserez la régression de Ridge qui est fondamentalement une technique de régularisation et une technique de sélection de caractéristiques intégrées ainsi.
Cet article vous donne une excellente explication sur la régression de Ridge. Assurez-vous de le consulter.
# First things firstfrom sklearn.linear_model import RidgePuis, vous utiliserez la régression de Ridge pour déterminer le coefficient R2.
Aussi, consultez la documentation officielle de scikit-learn sur la régression de Ridge.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)Afin de mieux comprendre les résultats de la régression de Ridge, vous implémenterez une petite fonction d’aide qui vous aidera à imprimer les résultats dans un meilleur afin que vous puissiez les interpréter facilement.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)Puis, vous passerez les termes de coefficient du modèle de Ridge à cette petite fonction et vous verrez ce qui se passe.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Vous pouvez repérer tous les termes de coefficient annexés aux variables caractéristiques. Cela vous aidera à nouveau à choisir les caractéristiques les plus essentielles. Voici quelques points que vous devez garder à l’esprit lorsque vous appliquez la régression de Ridge :
- Il est également connu sous le nom de L2-Regularisation.
- Pour les caractéristiques corrélées, cela signifie qu’elles ont tendance à obtenir des coefficients similaires.
- Les caractéristiques ayant des coefficients négatifs ne contribuent pas tant que cela. Mais dans un scénario plus complexe où vous avez affaire à beaucoup de caractéristiques, alors ce score vous aidera certainement dans le processus de décision final de sélection des caractéristiques.
Bien, cela conclut la section des études de cas. Les méthodes que vous avez mises en œuvre dans la section ci-dessus vous aideront à comprendre les caractéristiques d’un ensemble de données particulier d’une manière complète. Laissez-moi vous donner quelques points critiques sur ces techniques :
- La sélection des caractéristiques est essentiellement une partie du prétraitement des données qui est considéré comme la partie la plus longue de tout pipeline d’apprentissage automatique.
- Ces techniques vous aideront à l’aborder d’une manière plus systématique et conviviale pour l’apprentissage automatique. Vous serez en mesure d’interpréter les caractéristiques avec plus de précision.
Wrap up!
Dans ce post, vous avez couvert l’un des sujets statistiques les plus étudiés et les plus recherchés, à savoir la sélection des caractéristiques. Vous vous êtes également familiarisé avec ses différentes variantes et vous les avez utilisées pour voir quelles caractéristiques dans un ensemble de données sont importantes.
Vous pouvez aller plus loin dans ce tutoriel en fusionnant une mesure de corrélation dans la méthode wrapper et voir comment elle se comporte. Dans le cours de l’action, vous pourriez finir par créer votre propre mécanisme de sélection de caractéristiques. C’est ainsi que vous établissez les bases de votre petite recherche. Les chercheurs utilisent également divers principes d’informatique douce afin d’effectuer la sélection. Il s’agit en soi d’un domaine d’étude et de recherche à part entière. Aussi, vous devriez essayer les algorithmes de sélection de caractéristiques existants sur divers ensembles de données et tirer vos propres conclusions.
Pourquoi ces méthodes traditionnelles de sélection de caractéristiques tiennent-elles toujours ?
Oui, cette question est évidente. Parce qu’il existe des architectures de réseaux neuronaux (par exemple les CNN) qui sont tout à fait capables d’extraire les caractéristiques les plus significatives des données, mais cela aussi a une limite. L’utilisation d’un CNN pour un ensemble de données tabulaires ordinaires qui n’ont pas de propriétés spécifiques (les propriétés d’une image typique comme les propriétés de transition, les bords, les propriétés de position, les contours, etc. De plus, lorsque vous disposez de données et de ressources limitées, l’entraînement d’un CNN sur des ensembles de données tabulaires ordinaires peut s’avérer être un véritable gaspillage. Donc, dans des situations comme celle-là, les méthodes que vous avez étudiées seront certainement utiles.
Voici quelques ressources si vous souhaitez creuser davantage sur ce sujet :
- Sélection de caractéristiques pour la découverte de connaissances et l’exploration de données
- Sous-espace, structure latente et sélection de caractéristiques : Atelier sur les perspectives statistiques et d’optimisation
- Sélection de caractéristiques : Énoncé du problème et utilisations
- Utilisation des algorithmes génétiques pour la sélection de caractéristiques dans l’analyse des données
Vous trouverez ci-dessous les références qui ont été utilisées pour rédiger ce tutoriel.
- Data Mining : Concepts et techniques ; Jiawei Han Micheline Kamber Jian Pei.
- Une introduction à la sélection de caractéristiques
- Article d’Analytics Vidhya sur la sélection de caractéristiques
- Modèle hiérarchique et mixte – Cours DataCamp
- Sélection de caractéristiques pour l’apprentissage automatique en Python
- Détection des excentricités dans les données de flux par des méthodes d’apprentissage automatique et de sélection de caractéristiques
- S. Visalakshi et V. Radha, « A literature review of feature selection techniques and applications » : Revue de la sélection de caractéristiques dans la fouille de données », 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, pp. 1-6.
.