Par : Derek Colley | Mis à jour : 2014-01-29 | Commentaires (5) | Connexe : Plus de > Fonctions – Système
Problème
Vous cherchez à récupérer un échantillon aléatoire à partir d’un ensemble de résultats de requête SQL Server. Peut-être cherchez-vous un échantillon représentatif des données d’une grande base de données clients ; peut-être cherchez-vous quelques moyennes, ou une idée du type de données que vous détenez. SELECT TOP N n’est pas toujours idéal, car les données aberrantes apparaissent souvent au début et à la fin des ensembles de données, surtout lorsqu’elles sont classées par ordre alphabétique ou par une valeur scalaire. De même, vous avez peut-être utilisé TABLESAMPLE, mais il présente des limites, notamment avec les ensembles de données de petite taille ou asymétriques. Votre patron vous a peut-être demandé une sélection aléatoire de 100 noms et emplacements de clients ; ou bien vous participez à un audit et devez récupérer un échantillon aléatoire de données pour l’analyser. Comment allez-vous accomplir cette tâche ? Consultez cette astuce pour en savoir plus.
Solution
Cette astuce vous montrera comment utiliser TABLESAMPLE en T-SQL pour récupérer des échantillons de données pseudo-aléatoires, et parlera des internes de TABLESAMPLE et des cas où il n’est pas approprié. Il vous montrera également une méthode alternative – une méthode mathématique utilisant NEWID() couplée à CHECKSUM et un opérateur bitwise, notée par Microsoft dans l’article TechNet de TABLESAMPLE. Nous parlerons un peu de l’échantillonnage statistique en général (les différences entre aléatoire, systématique et stratifié) à l’aide d’exemples, et nous examinerons comment les statistiques SQL sont échantillonnées à titre d’exemple, ainsi que les options que nous pouvons utiliser pour remplacer cet échantillonnage. Après avoir lu cette astuce, vous devriez avoir une appréciation des avantages de l’échantillonnage par rapport à l’utilisation de méthodes comme TOP N et savoir comment appliquer au moins une méthode pour y parvenir dans SQL Server.
Setup
Pour cette astuce, je vais utiliser un ensemble de données contenant une colonne INT d’identité (pour établir le degré de hasard lors de la sélection des lignes) et d’autres colonnes remplies de données pseudo-aléatoires de différents types de données, pour simuler (vaguement) des données réelles dans une table. Vous pouvez utiliser le code T-SQL ci-dessous pour configurer ce système. Son exécution ne devrait prendre que quelques minutes et il est testé sur SQL Server 2012 Developer Edition.
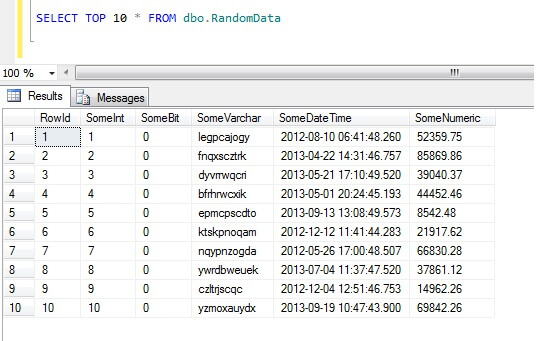
Sélectionner les 10 premières lignes de données donne ce résultat (juste pour vous donner une idée de la forme des données).En passant, il s’agit d’un morceau de code général que j’ai créé pour générer des données aléatoires chaque fois que j’en avais besoin – n’hésitez pas à le prendre et à l’augmenter/piller à votre guise !
Comment ne pas échantillonner les données dans SQL Server
Maintenant que nous avons nos échantillons de données, réfléchissons aux pires façons d’obtenir un échantillon. Dans la base de données AdventureWorks, il existe une table appelée Personne.Adresse. Échantillonnons en prenant les 10 premiers résultats, sans ordre particulier :
SELECT TOP 10 * FROM Person.Address
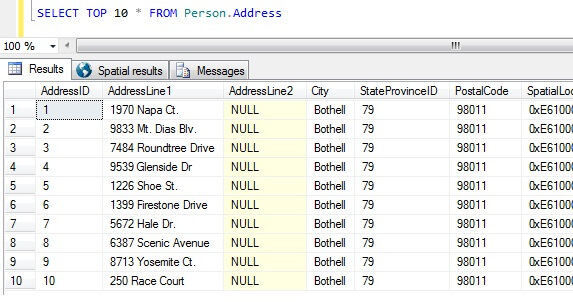
En partant de ce seul échantillon, nous pouvons voir que toutes les personnes retournées vivent à Bothell, et partagent le code postal 98011. Ceci est dû au fait que les résultats ont été spécifiés pour être retournés dans aucun ordre particulier, mais ont en fait été retournés dans l’ordre de la colonne AddressID. Notez que ce n’est PAS un comportement garanti pour les données du tas en particulier – voir cette citation de BOL:
« Habituellement, les données sont initialement stockées dans l’ordre dans lequel est les lignes sont insérées dans la table, mais le moteur de base de données peut déplacer les données dans le tas pour stocker les lignes efficacement ; ainsi, l’ordre des données ne peut être prédit. Pour garantir l’ordre des lignes retournées à partir d’un tas, vous devez utiliser la clause ORDER BY. »
http://technet.microsoft.com/en-us/library/hh213609.aspx
En prenant cet ensemble de résultats, une personne non informée de la nature de la table pourrait conclure que tous leurs clients vivent à Bothell.
Types d’échantillonnage de données dans SQL Server
Ce qui précède est clairement faux, nous avons donc besoin d’une meilleure façon d’échantillonner. Que diriez-vous de prendre un échantillon à intervalles réguliers dans toute la table ?
Cela devrait retourner 47 lignes :
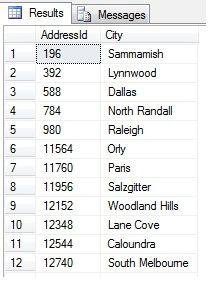
Pour l’instant, tout va bien. Nous avons pris une ligne à intervalles réguliers dans notre ensemble de données et nous avons retourné une section transversale statistique – ou l’avons-nous fait ? Pas nécessairement. N’oubliez pas que l’ordre n’est pas garanti. Nous pourrions tirer une ou deux conclusions de ces données. Agrégeons-les pour les illustrer. Exécutez à nouveau l’extrait de code ci-dessus, mais modifiez le bloc SELECT final comme suit :
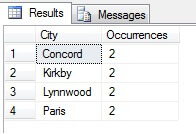
Vous pouvez voir dans mon exemple que sur un total de plus de 19 000 lignes dans la table Person.Address, j’ai échantillonné environ 1/4 % des lignes et que je peux donc conclure que (dans mon exemple), Concord, Kirkby, Lynnwood et Paris ont le plus grand nombre de résidents et sont en outre également peuplés. Exactement ? Absurde, bien sûr :
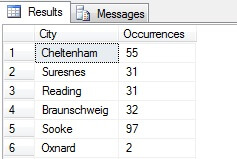
Comme vous pouvez le constater, aucun de mes quatre endroits ne figurait réellement parmi les quatre meilleurs endroits pour vivre, selon ce tableau. Non seulement l’échantillon de données était trop petit, mais j’ai agrégé ce minuscule échantillon et essayé d’en tirer une conclusion. Cela signifie que mon ensemble de résultats est statistiquement non significatif -avarement, prouver la signification statistique est l’une des principales charges de la preuve lors de la présentation de résumés statistiques (ou devrait l’être) et l’un des principaux écueils de nombreuses infographies populaires et de datagrammes dirigés par le marketing.
Donc, l’échantillonnage de cette manière (appelé échantillonnage systématique) est efficace, mais seulement pour une population statistiquement significative. Il y a des facteurs tels que la périodicité et la proportion qui peuvent ruiner un échantillon – voyons la proportion en action en prenant un échantillon de 10 villes à partir du tableau Person.Address, en utilisant le code suivant, qui obtient une liste distincte de villes à partir du tableau Person.Address, puis sélectionne 10 villes à partir de cette liste en utilisant l’échantillonnage systématique:
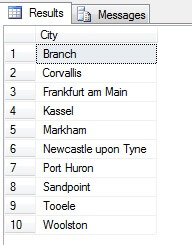
Semble un bon échantillon, non ? Maintenant, comparons-le à un échantillon de villes NON distinctes listées par ordre croissant, c’est-à-dire chaque nième ville, où n est le nombre total de lignes divisé par 10. Cette mesure tient compte de la population de l’échantillon:
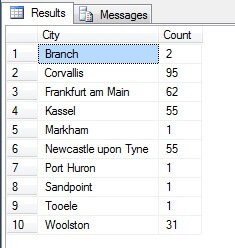
Les données renvoyées sont complètement différentes – non par hasard, mais par la présentation d’un échantillon représentatif. Notez que cette liste, sur laquelle j’ai inclus les comptes de chaque ville dans le tableau source pour souligner à quel point la population joue un rôle dans la sélection des données, comprend les quatre villes les plus peuplées de l’échantillon, ce qui (si vous considérez une liste ordonnée non distincte) est la représentation la plus juste. Ce n’est pas nécessairement la meilleure représentation pour vos besoins, alors soyez prudent lorsque vous choisissez votre méthode d’échantillonnage statistique.
Autres méthodes d’échantillonnage
Échantillonnage en grappes – il s’agit de diviser la population à échantillonner en grappes, ou sous-ensembles, puis de déterminer de façon aléatoire si chacun de ces sous-ensembles sera inclus ou non dans l’ensemble de résultats de sortie. S’il est inclus, chaque membre de ce sous-ensemble est renvoyé dans l’ensemble de résultats. Voir TABLESAMPLE ci-dessous pour un exemple de ceci.
Échantillonnage disproportionnel – c’est comme l’échantillonnage stratifié, où les membres des sous-ensembles sont sélectionnés afin de représenter le groupe entier, mais au lieu d’être en proportion, il peut y avoir différents nombres de membres de chaque groupe sélectionnés pour égaliser la représentation de chaque groupe. Par exemple, étant donné les villes dans Person.Address dans l’exemple de la section ci-dessus, le premier ensemble de résultats était disproportionné car il ne tenait pas compte de la population, mais le deuxième ensemble de résultats était proportionnel car il représentait le nombre d’entrées de villes dans la table Person.Address. Ce type d’échantillonnage est en fait utile si une catégorie particulière est sous-représentée dans l’ensemble de données, et que la proportion n’est pas importante (par exemple, 100 clients aléatoires de 100 villes aléatoires stratifiées par ville – les villes du sous-ensemble auraient besoin d’être normalisées – un échantillonnage disproportionné pourrait être utilisé).
SQL Server Random Data with TABLESAMPLE
SQL Server est utilement livré avec une méthode d’échantillonnage des données. Voyons-la en action. Utilisez le code suivant pour renvoyer environ 100 lignes (s’il renvoie 0 ligne, réexécutez – je vous expliquerai dans un instant) de données provenant de dbo.RandomData que nous avons défini précédemment.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
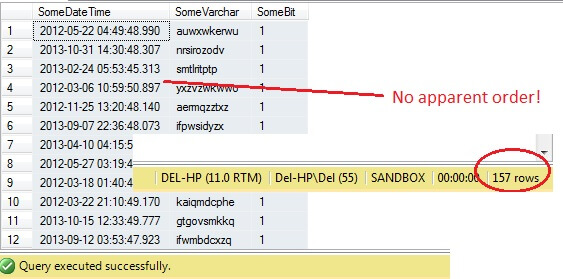
Alors, tout va bien, non ? Attendez – nous ne pouvons pas voir la colonne Id. Incluons-la et réexécutons :
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
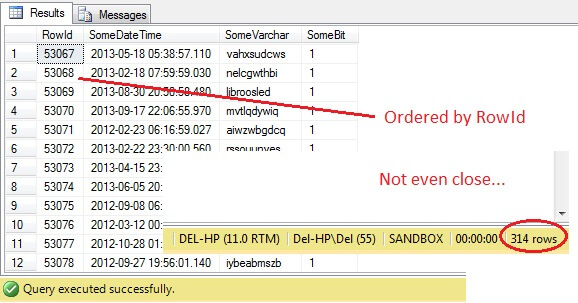
Oh là là – TABLESAMPLE a sélectionné une tranche de données, mais elle n’est pas aléatoire – le RowId montre une tranche clairement délimitée avec une valeur minimale et maximale. Qui plus est, il n’a pas non plus renvoyé exactement 100 lignes. Que se passe-t-il ?
TABLESAMPLE utilise le modificateur implicite SYSTEM. Ce modificateur, activé par défaut et une spécification ANSI-SQL c’est-à-dire non optionnelle, prendra chaque page de 8KB sur laquelle réside la table et décidera d’inclure ou non toutes les lignes de cette page qui sont dans cette table dans l’échantillon produit, en fonction du pourcentage ou de N ROWS transmis. Par conséquent, une table qui réside sur de nombreuses pages, c’est-à-dire qui a de grandes lignes de données, devrait renvoyer un échantillon plus aléatoire puisqu’il y aura plus de pages dans l’échantillon. Cela échoue pour un exemple comme le nôtre, où les données sont scalaires et petites et ne résident que sur quelques pages – si un certain nombre de pages ne sont pas prises en compte, cela peut fausser de manière significative l’échantillon de sortie. C’est l’inconvénient de TABLESAMPLE – il ne fonctionne pas bien pour les « petites » données et il ne tient pas compte de la distribution des données sur les pages. Ainsi, la disposition des données sur les pages est finalement responsable de l’échantillon renvoyé par cette méthode.
Cela vous semble-t-il familier ? Il s’agit essentiellement d’un échantillonnage en grappes, où tous les membres (lignes) des groupes (grappes) sélectionnés sont représentés dans l’ensemble de résultats.
Testons-le sur un grand tableau pour souligner le point de la non évolutivité inverse. Commençons par identifier la plus grande table de la base de données AdventureWorks. Nous utiliserons un rapport standard pour cela – en utilisant SSMS, faites un clic droit sur la base de données AdventureWorks2012, allez à Reports -> Standard Reports -> Disk Usage by Top Tables. Ordonnez par Données(KB) en cliquant sur l’en-tête de la colonne (vous pourriez souhaiter le faire deux fois pour un ordre décroissant). Vous verrez le rapport ci-dessous.
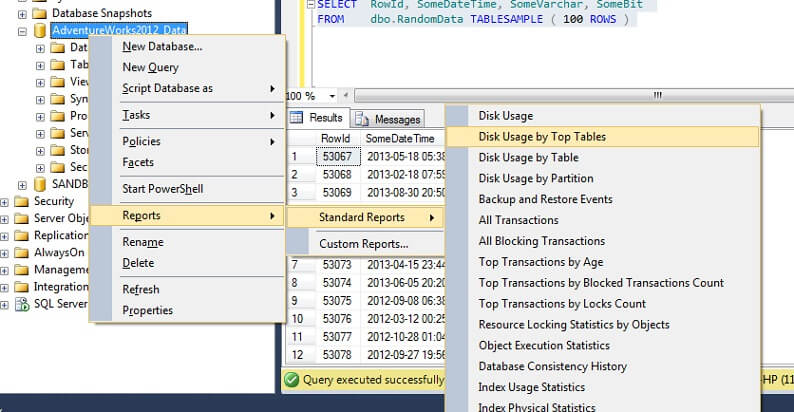
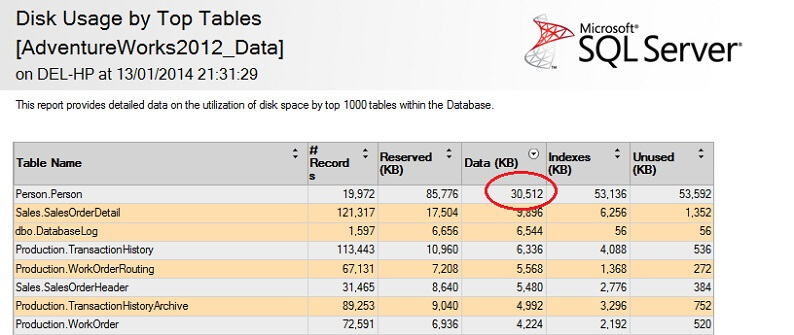
J’ai entouré le chiffre intéressant – la table Person. La table Person consomme 30,5 Mo de données et est la plus grande table (par les données, pas le nombre d’enregistrements). Essayons donc de prendre un échantillon de cette table à la place:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
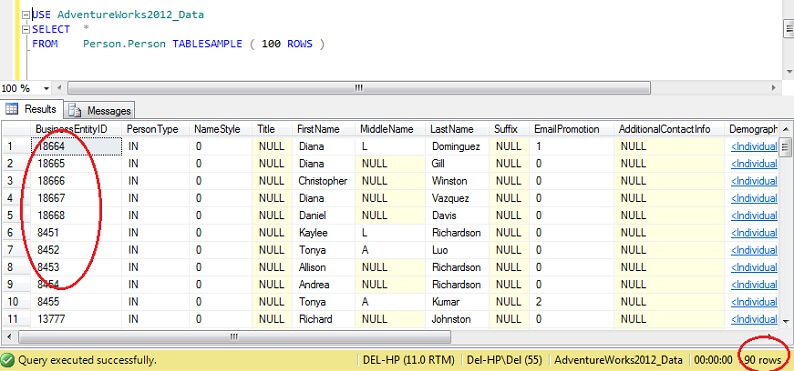
Vous pouvez voir que nous sommes beaucoup plus proches de 100 lignes, mais de manière cruciale, il ne semble pas y avoir beaucoup de regroupement sur la clé primaire (bien qu’il y en ait, car il y a plus d’une ligne par page).
En conséquence, TABLESAMPLE est bon pour les grosses données, et devient catastrophiquement mauvais plus l’ensemble de données est petit. Ce n’est pas bon pour nous lorsque nous échantillonnons à partir de données stratifiées ou de données en grappes, où nous prenons de nombreux échantillons à partir de petits groupes ou sous-ensembles de données puis nous les agrégeons. Examinons une méthode alternative, alors.
Données aléatoires de SQL Server avec ORDER BY NEWID()
Voici une citation de BOL sur l’obtention d’un échantillon vraiment aléatoire :
« Si vous voulez vraiment un échantillon aléatoire de lignes individuelles, modifiez votre requête pour filtrer les lignes de façon aléatoire, au lieu d’utiliser TABLESAMPLE. Par exemple, la requête suivante utilise la fonction NEWID pour renvoyer environ un pour cent des lignes de la table Sales.SalesOrderDetail:
Comment cela fonctionne-t-il ? Divisons la clause WHERE et expliquons-la.
La fonction CHECKSUM calcule une somme de contrôle sur les éléments de la liste. On peut discuter de la question de savoir si SalesOrderID est même nécessaire, puisque NEWID() est une fonction qui renvoie un nouveau GUID aléatoire, donc multiplier un chiffre aléatoire par une constante devrait donner un aléatoire dans tous les cas.En effet, exclure SalesOrderID semble ne faire aucune différence. Si vous êtes un statisticien chevronné et que vous pouvez justifier l’inclusion de cette donnée, veuillez utiliser la section des commentaires ci-dessous et m’indiquer pourquoi j’ai tort !
La fonction CHECKSUM renvoie un VARBINAIRE. En effectuant une opération ET au sens du bit avec 0x7fffffff, qui est l’équivalent de (111111111…) en binaire, on obtient une valeur décimale qui est effectivement une représentation d’une chaîne aléatoire de 0 et de 1. La division par le coefficient 0x7fffff normalise effectivement ce chiffre décimal à un chiffre compris entre 0 et 1. Ensuite, pour décider si chaque ligne mérite d’être incluse dans l’ensemble de résultats final, un seuil de 1/x est utilisé (dans ce cas, 0,01) où x est le pourcentage des données à récupérer comme échantillon.
Sachez que cette méthode est une forme d’échantillonnage aléatoire plutôt qu’un échantillonnage systématique, donc vous êtes susceptible d’obtenir des données de toutes les parties de vos données sources, mais la clé ici est que vous *pourriez ne pas*. La nature de l’échantillonnage aléatoire signifie que tout échantillon que vous recueillez peut être biaisé en faveur d’un segment de vos données, donc afin de bénéficier de la régression vers la moyenne (tendance vers un résultat aléatoire, dans ce cas), assurez-vous de prendre plusieurs échantillons et de sélectionner un sous-ensemble de ceux-ci, si vos résultats semblent biaisés. Vous pouvez également prélever des échantillons dans des sous-ensembles de vos données, puis les agréger – il s’agit d’un autre type d’échantillonnage, appelé échantillonnage stratifié.
Comment les statistiques de SQL Server sont-elles échantillonnées ?
Dans SQL Server, la mise à jour automatique des statistiques de colonnes ou définies par l’utilisateur a lieu chaque fois qu’un seuil défini de lignes de table est modifié pour une table donnée. Pour 2012, ce seuil est calculé à SQRT(1000 * TR) où TR est le nombre de lignes de table dans la table. Avant 2005, le travail statistique de mise à jour automatique se déclenche pour chaque (500 lignes + 20 % de changement) de lignes de table. Une fois que le processus de mise à jour automatique commence, l’échantillonnage *réduit le nombre de lignes échantillonnées au fur et à mesure que la table devient plus grande*, en d’autres termes, il y a une relation qui est similaire à une proportion inverse entre le pourcentage d’échantillonnage de la table et la taille de la table, mais qui suit un algorithme propriétaire.
Intéressant, cela semble être l’opposé de l’option TABLESAMPLE (N PERCENT), où les lignes échantillonnées sont en proportion normale avec le nombre de lignes de la table. Nous pouvons désactiver les statistiques automatiques (faites attention en faisant cela) et mettre à jour les statistiques manuellement – ceci est réalisé en utilisant NORECOMPUTE sur l’instruction UPDATE STATISTICS. Avec UPDATE STATISTICS, nous pouvons remplacer certaines des options – par exemple, nous pouvons choisir d’échantillonner N lignes, ou N pour cent (similaire à TABLESAMPLE), effectuer un FULLSCAN, ou simplement RESAMPLER en utilisant le dernier taux connu.
Prochaines étapes
Pour une lecture plus approfondie, Joseph Sack est un Microsoft MVP connu pour son travail dans l’analyse statistique de SQL Server – veuillez voir ci-dessous pour quelques liens vers son travail, ainsi que quelques références au travail utilisé pour cet article et à quelques conseils connexes de MSSQLTips.com. Merci de votre lecture !
Dernière mise à jour : 2014-01-29


A propos de l’auteur
 Derek Colley est un DBA et un développeur BI basé au Royaume-Uni avec plus d’une décennie d’expérience de travail avec SQL Server, Oracle et MySQL.
Derek Colley est un DBA et un développeur BI basé au Royaume-Uni avec plus d’une décennie d’expérience de travail avec SQL Server, Oracle et MySQL.Voir tous mes conseils
- Plus de conseils pour les développeurs de bases de données…