Il y a beaucoup de grands avantages qui sont offerts en virtualisant votre infrastructure et en exécutant des ressources virtuelles pour servir des charges de travail critiques pour l’entreprise. Dans le cas de VMware vSphere, il offre de nombreuses fonctionnalités et capacités notables qui fournissent une haute disponibilité dans l’environnement ainsi qu’une planification automatisée des charges de travail pour assurer l’utilisation la plus efficace du matériel et des ressources dans votre environnement vSphere.
Dans ce post, nous allons parler de deux des principales fonctionnalités de niveau cluster de vSphere dans l’entreprise – vSphere HA et DRS. Vous avez très probablement vu ces deux éléments référencés avec l’exécution de vSphere dans l’entreprise.
Qu’est-ce que vSphere HA et DRS ? Que font-ils ?
Comment bénéficier de l’exécution des deux dans votre environnement vSphere ?
Regardons une introduction de base à HA et DRS dans VMware vSphere et voyons comment ils se comparent et les avantages de leur utilisation.
MVMware vSphere Clusters
L’un des avantages évidents et des meilleures pratiques lors de l’utilisation de VMware vSphere pour exécuter des charges de travail critiques pour l’entreprise est d’exécuter un vSphere Cluster.
Qu’est-ce qu’un cluster vSphere ?
Un cluster vSphere est une configuration de plus d’un serveur VMware ESXi agrégé ensemble comme un pool de ressources contribuées au cluster vSphere. Les ressources telles que le calcul CPU, la mémoire et, dans le cas du stockage défini par logiciel comme vSAN, le stockage, sont apportées par chaque hôte ESXi.
Pourquoi est-il important d’exécuter vos charges de travail critiques pour l’entreprise au-dessus d’un cluster vSphere ?
Lorsque vous pensez aux avantages fournis par l’exécution d’un hyperviseur, cela permet à plus d’un serveur de fonctionner au-dessus d’un seul ensemble de matériel physique. La virtualisation des charges de travail de cette manière offre de nombreux avantages en termes d’efficacité, par ordre de grandeur, par rapport à l’exécution d’un seul serveur sur un seul ensemble de matériel physique.
Cependant, cela peut également devenir le talon d’Achille d’une solution virtualisée, car l’impact d’une panne matérielle peut affecter beaucoup plus de services et d’applications critiques pour l’entreprise. Vous pouvez imaginer que si vous n’avez qu’un seul hôte ESXi VMware exécutant de nombreuses VM, l’impact de la perte de cet unique hôte ESXi serait immense.
C’est là que l’exécution de plusieurs hôtes ESXi VMware dans un cluster vSphere brille vraiment.
Cependant, vous pouvez vous demander comment la simple exécution de plusieurs hôtes dans un cluster améliore votre haute disponibilité ? Comment un hôte dans le vSphere Cluster » sait » si un autre hôte est tombé en panne ? Existe-t-il un mécanisme spécial utilisé pour gérer la haute disponibilité des charges de travail exécutées sur un cluster vSphere ? Oui, il y en a un. Voyons voir.
Qu’est-ce que HA dans VMware ?
VMware a réalisé la nécessité d’avoir un mécanisme pour être en mesure de fournir une protection contre un hôte ESXi défaillant dans le cluster vSphere. Avec ce besoin, la haute disponibilité (HA) de VMware est née.
VMware vSphere HA offre les avantages suivants :
VMware vSphere HA est rentable et permet de redémarrer automatiquement les VM et les hôtes vSphere lorsqu’il y a une panne de serveur ou une défaillance du système d’exploitation détectée dans l’environnement vSphere
Surveille tous les hôtes VMware vSphere & VM dans le cluster vSphere
Donne une haute disponibilité à la plupart des applications exécutées dans les machines virtuelles, quels que soient le système d’exploitation et les applications.
La beauté de la solution vSphere HA de VMware qui est mise en œuvre via le cluster VMware est la simplicité pour laquelle elle peut être configurée. En quelques clics à travers une interface pilotée par un assistant, la haute disponibilité peut être configurée. Comment cela se compare-t-il aux technologies traditionnelles de » clustering » ?
Comparaison de Windows Server Failover Clustering
Windows Server Failover Clustering (WSFC) est devenu la technologie de clustering à laquelle la plupart pensent lorsqu’ils ont en tête une technologie de clustering. Le problème constaté avec WSFC est qu’il faut beaucoup d’expertise spécialisée pour exécuter correctement les services WSFC, surtout lorsqu’il s’agit de mises à niveau, de correctifs et de tâches opérationnelles générales.
En comparant vSphere HA avec WSFC, les frais généraux opérationnels sont minimes par rapport à WSFC. Il y a peu de chance que la configuration soit incorrecte car elle est activée sur un cluster ou non. Avec le WSFC, de nombreuses considérations doivent être prises en compte lors de la configuration du WSFC pour éviter les erreurs de configuration et de mise en œuvre. Pensez à ce qui suit :
- Le clustering de basculement nécessite des applications qui prennent en charge le clustering (SQL, etc)
- Le clustering de basculement nécessite que le quorum soit configuré correctement
- Non pris en charge par de nombreux systèmes d’exploitation et applications hérités
- Requiert la complexité des noms de réseau de cluster, des ressources et de la mise en réseau
Windows Server Failover Clustering est annoncé pour fournir un temps d’arrêt quasi nul au niveau de l’application. Cependant, lorsque vous ajoutez l’expertise requise pour une solution HA fonctionnant correctement, ainsi que la mise en œuvre correcte de WSFC, les risques peuvent commencer à dépasser les avantages de l’utilisation de WSFC pour la haute disponibilité des applications et des services. Cela est particulièrement vrai pour la plupart des organisations qui n’ont pas vraiment besoin d’une solution « zéro temps d’arrêt ». En outre, votre application doit être conçue pour profiter du WSFC et fonctionner correctement avec la technologie WSFC.
Bien que vSphere HA nécessite un redémarrage des machines virtuelles sur un hôte sain lorsqu’un basculement se produit, il ne nécessite aucune installation de logiciel supplémentaire à l’intérieur des machines virtuelles invitées, aucune configuration complexe de technologies de clustering supplémentaires, et les applications ou les OS n’ont pas à être conçus pour fonctionner avec une technologie de clustering particulière.
Les systèmes d’exploitation et les applications hérités ont généralement des capacités limitées en ce qui concerne les technologies prises en charge pour fournir une haute disponibilité. Ainsi, il peut littéralement n’y avoir aucune option native pour fournir une fonctionnalité de basculement dans le cas de défaillances matérielles.
Le mécanisme de haute disponibilité vSphere HA fonctionne et est simple à mettre en œuvre, à configurer et à gérer. De plus, il s’agit d’une technologie bien testée dans des milliers d’environnements de clients VMware, elle a donc un historique stable et long de déploiements réussis.
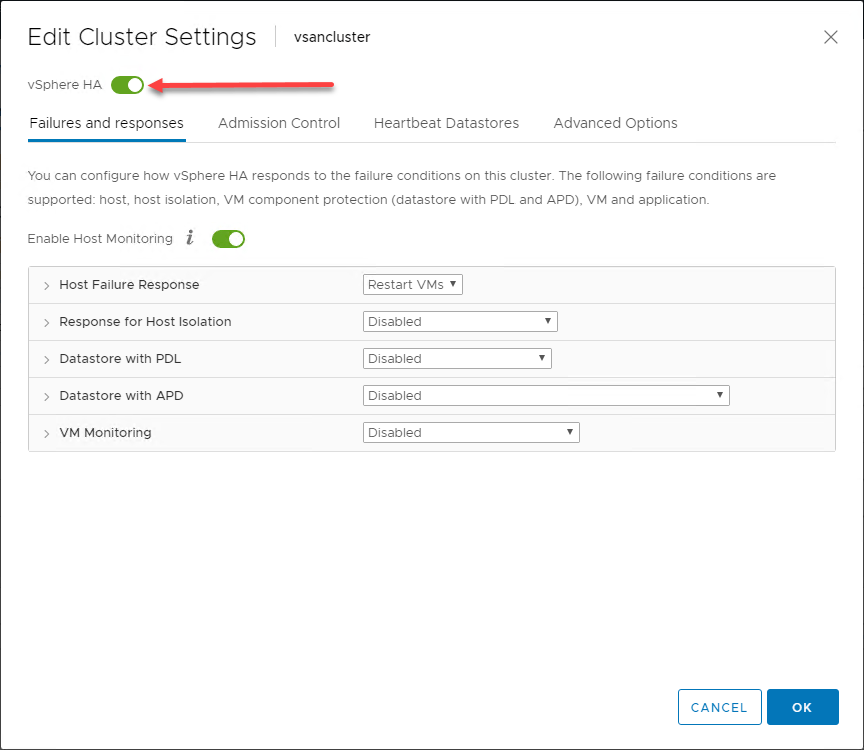
Présentation générale du comportement de vSphere HA
En utilisant les avantages fournis aux hôtes ESXi dans un cluster vSphere, dans sa forme la plus basique, vSphere HA met en œuvre un mécanisme de surveillance entre les hôtes du cluster vSphere. Le mécanisme de surveillance fournit un moyen de déterminer si un hôte du vSphere Cluster est tombé en panne.
Dans l’infographie ci-dessous, un vSphere Cluster à deux nœuds a connu une défaillance de l’un des hôtes ESXi du vSphere Cluster. Le vSphere Cluster a vSphere HA activé au niveau du cluster.
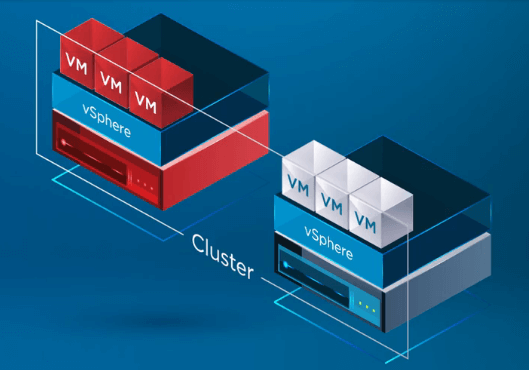
Après que vSphere HA ait reconnu qu’un hôte du vSphere Cluster est défaillant, le processus HA déplace l’enregistrement des VM de l’hôte défaillant vers un hôte sain.
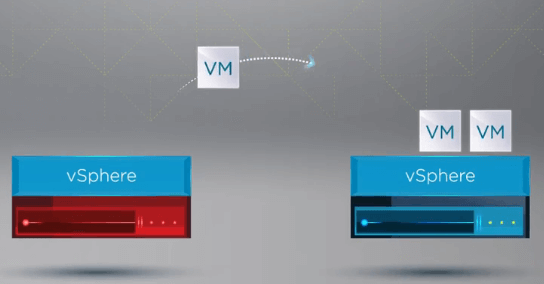
Après l’enregistrement des VM sur un hôte sain, vSphere HA redémarre toutes les VM de l’hôte défaillant sur un hôte ESXi sain du cluster où les VM ont été réenregistrées. Le seul temps d’arrêt subi est celui du redémarrage des VM sur un hôte sain dans le cluster vSphere.
VSphere HA Technical Overview
Prérequis pour vSphere HA
Vous pouvez vous demander quels prérequis sous-jacents peuvent être nécessaires pour que vSphere HA fonctionne. Faut-il simplement disposer d’un cluster VMware pour activer HA ? Contrairement à Windows Server Failover Clustering, il n’y a que quelques conditions requises pour que HA fonctionne.
Requêtes :
- Au moins deux hôtes ESXi
- Au moins 4 Go de mémoire configurés sur chaque hôte
- vCenter Server
- LicencevSphere Standard
- Stockage partagé pour les VM
- Passerelle pingable ou autre nœud de réseau fiable
Si vous remarquez , aucun composant de quorum n’est requis, aucun nommage réseau complexe n’est impliqué, et aucune autre ressource de cluster spéciale ne doit être en place.
Lire la suite : Comment configurer un cluster à haute disponibilité vSphere
VMware vSphere HA maître vs hôtes subordonnés
Lorsque vous activez vSphere HA sur un cluster, un hôte particulier du cluster vSphere est désigné comme maître de vSphere HA. Les autres hôtes ESXi du vSphere Cluster sont configurés comme subordonnés dans la configuration de vSphere HA.
Quel rôle joue l’hôte ESXi de vSphere HA qui est désigné comme maître ? Le nœud maître vSphere HA :
- Surveille l’état des hôtes subordonnés esclaves – Si l’hôte subordonné échoue ou est inaccessible, l’hôte maître identifie les VM qui doivent être redémarrées
- Surveille l’état d’alimentation de toutes les VM qui sont protégées. Si une VM échoue, le nœud maître vSphere HA s’assure que la VM est redémarrée. Le maître vSphere HA décide de l’endroit où le redémarrage de la VM a lieu (quel hôte ESXi).
- Suit tous les hôtes du cluster et les VM qui sont protégés par vSphere HA
- Est désigné comme médiateur entre le cluster vSphere et vCenter Server. Le maître HA rapporte la santé du cluster à vCenter et fournit l’interface de gestion du cluster pour vCenter Server
- Peut exécuter les VM elles-mêmes et surveiller l’état des VM
- Stocke les VM protégées dans les datastores du cluster
hôtes subordonnés vSphere HA :
- Exécuter des machines virtuelles localement
- Surveiller les états d’exécution des VM dans le cluster vSphere
- Reporter les mises à jour d’état au maître vSphere HA
Élection de l’hôte maître et défaillance du maître
Comment l’hôte maître vSphere HA est-il sélectionné ? Lorsque vSphere HA est activé pour un cluster, tous les hôtes actifs (pas de mode de maintenance, etc) participent à l’élection de l’hôte maître. Si l’hôte maître élu échoue, une nouvelle élection a lieu où un nouvel hôte maître HA est élu pour remplir ce rôle.
Types de défaillance de cluster vSphere HA deVMware
Dans un cluster activé par vSphere HA, il existe trois types de défaillances qui peuvent se produire pour déclencher un événement de basculement vSphere HA. Ces types de défaillance d’hôte sont :
- Défaillance – Une défaillance est intuitivement ce que vous pensez. Un hôte a cessé de fonctionner sous une forme ou une autre en raison de problèmes matériels ou autres.
- Isolation – L’isolation d’un hôte se produit généralement en raison d’un événement réseau qui isole un hôte particulier des autres hôtes du cluster vSphere HA.
- Partition – Un événement de partition est caractérisé par la perte de connectivité réseau d’un hôte subordonné à l’hôte maître du cluster vSphere HA.
Battement de cœur, détection des défaillances et actions de défaillance
Comment le nœud maître détermine-t-il s’il y a une défaillance d’un hôte particulier ?
Il existe plusieurs mécanismes différents que le nœud maître utilise pour déterminer si un hôte est défaillant :
- Le nœud maître échange des heartbeats réseau avec les autres hôtes du cluster toutes les secondes.
- Après l’échec du heartbeat réseau, l’hôte maître vérifie le contrôle de la vivacité de l’hôte.
- Le contrôle de la vivacité de l’hôte détermine si l’hôte subordonné échange des heartbeats avec l’un des datastores. Ensuite, il envoie des pings ICMP à ses adresses IP de gestion
- Si la communication directe avec l’agent HA d’un hôte subordonné depuis l’hôte maître n’est pas possible et que les pings ICMP à l’adresse de gestion échouent, l’hôte est considéré comme défaillant et les VM sont redémarrées sur un hôte différent.
- S’il s’avère que l’hôte subordonné échange des battements de cœur avec le datastore, l’hôte maître suppose que l’hôte est dans une partition réseau ou est isolé du réseau. Dans ce cas, le maître surveille simplement l’hôte et les VM
- L’isolement du réseau est l’événement où un hôte subordonné est en cours d’exécution, mais ne peut plus être vu du point de vue de l’agent de gestion HA sur le réseau de gestion. Si un hôte cesse de voir ce trafic, il tente d’envoyer un ping aux adresses d’isolement du cluster. Si ce ping échoue, l’hôte déclare qu’il est isolé du réseau
- Dans ce cas, le nœud maître surveille les VM qui s’exécutent sur l’hôte isolé. Si les VM s’éteignent sur l’hôte isolé, le nœud maître redémarre les VM sur un autre hôte
Datastore Heartbeating
Comme mentionné ci-dessus, l’une des métriques utilisées pour déterminer la détection des défaillances est datastore heartbeating. Qu’est-ce que c’est exactement ? VMware vCenter sélectionne un ensemble préféré de datastores pour le heartbeating. Ensuite, vSphere HA crée un répertoire à la racine de chaque datastore qui est utilisé à la fois pour le battement de cœur du datastore et pour la mise à jour de la liste des VM protégées. Ce répertoire est nommé .vSphere-HA.
Il y a une note importante à retenir concernant les datastores vSAN. Un datastore vSAN ne peut pas être utilisé pour le battement de cœur du datastore. Si vous n’avez qu’un datastore vSAN disponible, aucun datastore de battement de cœur ne peut être utilisé.
- Surveillance des VM et des applications
Une autre fonctionnalité extrêmement puissante de vSphere HA est la possibilité de surveiller des machines virtuelles individuelles via VMware Tools et de redémarrer toute machine virtuelle qui ne répond pas aux battements de cœur VMware Tools. La surveillance des applications peut redémarrer une VM si les battements de cœur d’une application en cours d’exécution ne sont pas reçus.
- Surveillance des VM – Avec la surveillance des VM, le service de surveillance des VM utilise VMware Tools pour déterminer si chaque VM est en cours d’exécution en vérifiant à la fois les battements de cœur et les E/S de disque générées par VMware Tools. En cas d’échec de ces vérifications, le service de surveillance de la VM détermine que le système d’exploitation invité a probablement échoué et la VM est redémarrée. La vérification supplémentaire des E/S de disque permet d’éviter toute réinitialisation inutile de la VM si les VM ou les applications fonctionnent encore correctement.
Surveillance des applications – La fonction de surveillance des applications est activée en obtenant le SDK approprié auprès d’un fournisseur de logiciels tiers qui permet de configurer des battements de cœur personnalisés pour les applications à surveiller par le processus vSphere HA. Tout comme le processus de surveillance de la VM, si les battements de cœur des applications cessent d’être reçus, la VM est réinitialisée.
Ces deux fonctions de surveillance peuvent être configurées davantage avec la sensibilité de surveillance et aussi les réinitialisations maximales par VM pour aider à éviter de réinitialiser les VM à plusieurs reprises pour des erreurs logicielles ou des faux positifs.
VMware vSphere HA est un excellent moyen de s’assurer que votre cluster vSphere fournit une haute disponibilité très résiliente pour se protéger contre les défaillances générales des hôtes ESXi dans votre cluster vSphere.
Qu’en est-il de l’assurance d’une utilisation efficace des ressources dans votre cluster vSphere ? Jetons un coup d’œil à la prochaine disposition de vSphere Cluster pour aider à assurer une utilisation efficace des ressources et de la capacité de votre vSphere Cluster.
Qu’est-ce que DRS dans VMware ?
Le Distributed Resource Scheduler (DRS) de VMware est une fonctionnalité vraiment puissante lors de l’exécution de vSphere Clusters. Elle assure l’ordonnancement et l’équilibrage de la charge sur un cluster vSphere. VMware DRS est la fonctionnalité présente dans vSphere Clusters qui garantit que les machines virtuelles exécutées à l’intérieur de votre environnement vSphere reçoivent les ressources dont elles ont besoin pour fonctionner de manière efficace et efficiente.
Les VM sont généralement soumises à DRS très tôt dans leur vie car dès leur première mise sous tension dans un cluster compatible DRS, DRS place les VM sur le meilleur hôte configuré pour fournir les ressources requises à la VM dès sa mise sous tension. En outre, DRS s’efforce de maintenir les clusters vSphere équilibrés du point de vue de l’utilisation des ressources.
Même si un cluster vSphere est équilibré à un certain moment, les VM peuvent être déplacées ou changer de telle manière qu’un déséquilibre des ressources du cluster peut se glisser à nouveau dans l’environnement. Lorsque les clusters sont déséquilibrés, cela peut nuire aux performances globales des machines virtuelles exécutées dans un cluster vSphere.
Par défaut, DRS s’exécute automatiquement sur un cluster vSphere toutes les cinq minutes pour déterminer l’équilibre d’un cluster vSphere et voir si des modifications doivent être apportées pour utiliser plus efficacement les ressources.
Conditions requises pour VMware DRS
Pour profiter de VMware DRS, plusieurs conditions doivent être remplies pour garantir la prise en compte de la fonctionnalité Distributed Resource Scheduler. Celles-ci comprennent :
- Un cluster d’hôtes ESXi
- vCenter Server
- Licence Enterprise Plus
- vMotion est nécessaire pour l’équilibrage automatique de la charge
Lire la suite : Comment configurer un cluster vSphere DRS
Actions de VMware DRS
Lorsque VMware DRS s’exécute sur un cluster vSphere toutes les cinq minutes, il détermine si des déséquilibres existent dans le cluster. Si c’est le cas, une vMotion sera exécutée pour déplacer les VM désignées d’un hôte ESXi à un autre.
Comment exactement DRS détermine-t-il si les machines virtuelles sont mieux adaptées sur un hôte ESXi ou un autre ?
DRS exécute un algorithme spécial pour déterminer le bon hôte ESXi qui doit accueillir une VM particulière. Lorsqu’une VM est mise sous tension, cet algorithme prend en compte la distribution des ressources sur l’ensemble du cluster vSphere après s’être assuré qu’il n’y a pas de violation de contrainte si une VM particulière est placée sur un hôte ESXi particulier.
En outre, la demande de la VM elle-même est prise en considération afin que la VM ne soit jamais, espérons-le, privée de ressources lorsqu’elle est mise sous tension. Qu’est-ce qui est inclus dans la demande de la VM ? La demande d’une VM comprend la quantité de ressources nécessaires à son fonctionnement.
- Pour la demande de CPU, cela est calculé en fonction de la quantité de CPU que la VM consomme actuellement
- Pour la mémoire, la demande est calculée en fonction de la formule : Demande de mémoire VM = Fonction(Mémoire active utilisée, Swapped, Shared) + 25% (mémoire consommée au ralenti). Cela montre que l’équilibre de la mémoire DRS est basé principalement sur l’utilisation de la mémoire active d’une VM tout en considérant une petite quantité de sa mémoire consommée au ralenti comme un coussin pour toute augmentation de la charge de travail.
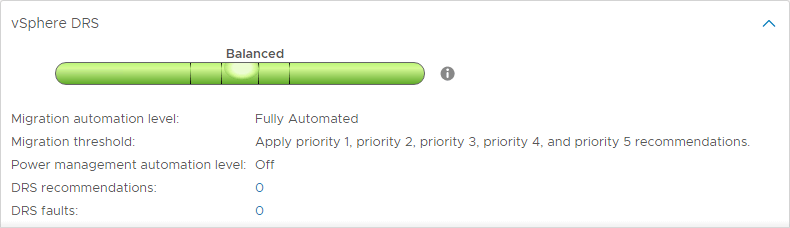
Niveaux d’automatisation de DRS
L’une des caractéristiques intéressantes de DRS est les niveaux d’automatisation de DRS. Alors que DRS continue à analyser le cluster vSphere et à fournir des recommandations toutes les 5 minutes, vous pouvez déterminer si DRS est en mesure d’appliquer ses recommandations automatiquement ou seulement de suggérer les changements à effectuer. DRS dispose de trois niveaux d’automatisation DRS. Il s’agit de :
- Entièrement automatisé – Dans l’approche entièrement automatisée, DRS applique automatiquement les recommandations de placement initial et d’équilibrage de charge
- Partiellement automatisé – Avec l’automatisation partielle, DRS applique les recommandations uniquement pour le placement initial des VM
- Manuel – En mode manuel, vous devez appliquer les recommandations pour le placement initial et les recommandations d’équilibrage de charge
Seuils de migration DRS
DRS inclut un autre paramètre très utile pour contrôler la quantité de déséquilibre qui sera tolérée avant que des recommandations DRS soient faites. Il existe cinq seuils de migration DRS pour contrôler la quantité de déséquilibre tolérée.
La plage va de 1 (le plus conservateur) à 5 (le plus agressif).
Avec des paramètres plus agressifs, DRS tolère moins de déséquilibre dans un cluster. Plus il est conservateur, plus le DRS tolère le déséquilibre.

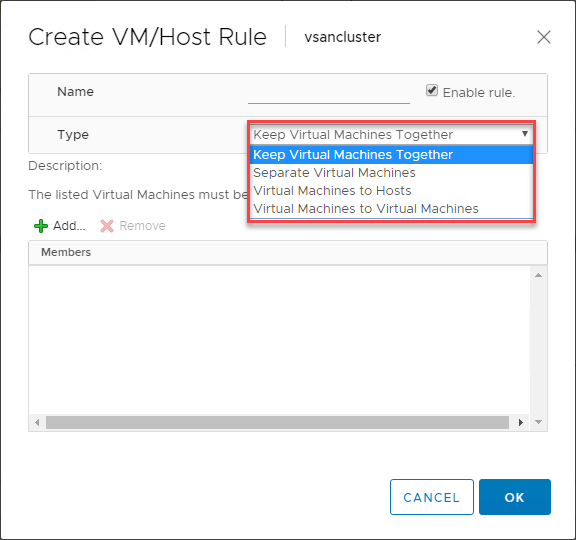
Règles VM/Host de VMware DRS
Il existe une fonctionnalité extrêmement utile que l’on trouve lorsqu’on utilise VMware DRS pour contrôler le placement des VM dans vos clusters compatibles vSphere DRS. Les règles VM/Host vous permettent d’exécuter des VM spécifiques sur un hôte ESXi spécifique. Vous pouvez considérer cela comme des règles d’affinité en quelque sorte.
Les règles VM/Host vous permettent de :
- Maintenir les machines virtuelles ensemble
- Séparer les machines virtuelles
- Lier les machines virtuelles à des hôtes spécifiques
- Lier les machines virtuelles à des machines virtuelles
Vous trouverez ci-dessous un exemple de création d’une règle VM/Host pour les machines virtuelles et les hôtes ESXi.
Quel type de cas d’utilisation existe pour ces règles VM/Host ? L’un des cas d’utilisation classiques qui existent est avec les contrôleurs de domaine. En général, si vous exécutez tous vos contrôleurs de domaine dans un environnement virtualisé tel qu’un cluster vSphere, vous voulez vous assurer que vous avez vos machines virtuelles de contrôleur de domaine séparées les unes des autres à l’intérieur du cluster. De cette façon, si un hôte ESXi tombe en panne en même temps qu’un de vos contrôleurs de domaine, vous avez toujours un contrôleur de domaine qui est soumis à une règle de machines virtuelles séparées qui le maintient hors du même hôte qu’un autre DC.
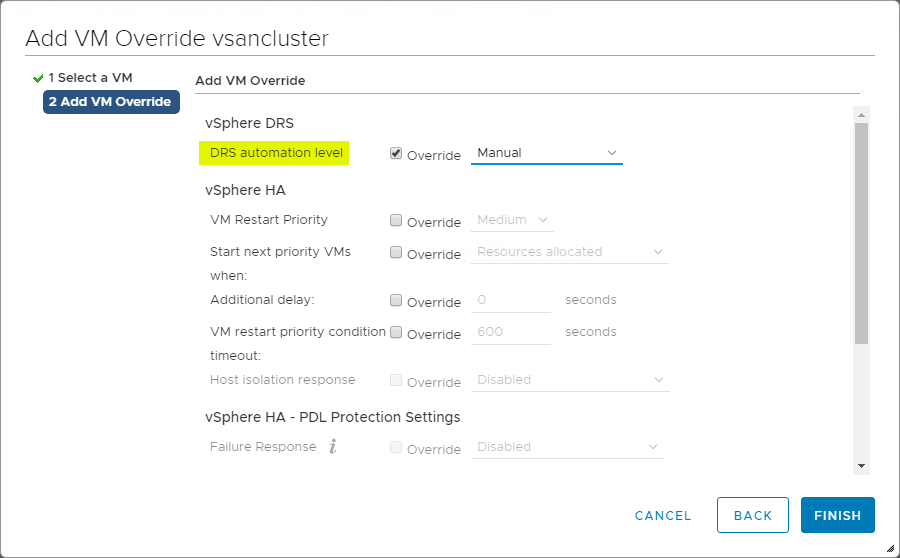
MVM Overrides pour DRS
Le cluster vSphere fournit une grande granularité pour les opérations affectant les VM individuelles à l’intérieur du cluster vSphere. Vous pouvez créer des surcharges de VM pour remplacer les paramètres globaux définis au niveau du cluster pour HA et DRS afin de définir des paramètres plus spécifiques pour chaque VM individuelle.
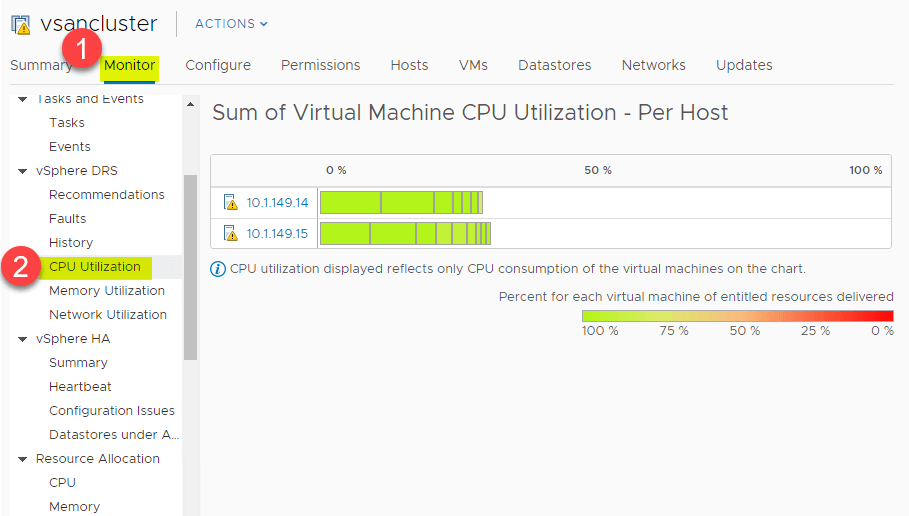
Sommaire de l’utilisation de l’unité centrale et de la mémoire
DRS fournit une grande vue de haut niveau du résumé de l’utilisation des ressources CPU des hôtes ESXi dans le cluster vSphere. Naviguez jusqu’à > Paramètres > Moniteur > vSphere DRS >Utilisation du CPU.
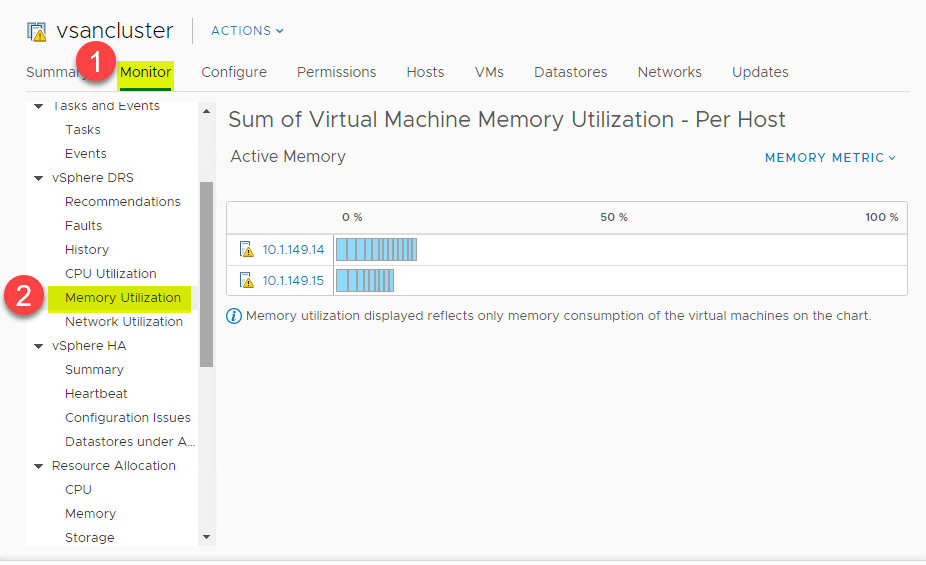
Le même aperçu de haut niveau peut être visualisé pour la consommation de mémoire également. Naviguez vers > Paramètres > Moniteur > vSphere DRS >Utilisation de la mémoire
Le meilleur des deux mondes
Les technologies VMware vSphere HA et VMware DRS sont-elles concurrentes ?
Non, elles ne le sont pas. En fait, il est fortement recommandé d’utiliser à la fois vSphere HA et VMware DRS pour combiner le basculement automatique avec des caractéristiques et des fonctionnalités d’équilibrage de charge. Cela permet d’obtenir un environnement vSphere beaucoup plus résilient et plus équilibré.
En cas de défaillance d’un hôte ESXi, vSphere HA redémarre les VM sur les hôtes sains restants dans un cluster vSphere. La première priorité est donc, bien sûr, la disponibilité des ressources des machines virtuelles. VMware DRS s’exécutera ensuite et déterminera si un déséquilibre existe entre les hôtes ESXi exécutant les charges de travail et fera des recommandations pour résoudre tout déséquilibre dans le cluster en fonction du seuil de migration configuré. En fonction du niveau d’automatisation, ces recommandations seront soit automatiquement mises en œuvre, soit uniquement recommandées si elles ne sont pas entièrement automatisées.
Pensées finales sur VMware vSphere HA et DRS
L’exécution à la fois de VMware vSphere HA et de DRS est fortement recommandée dans un cluster vSphere de production. L’utilisation de ces deux technologies permet de rendre vos charges de travail hautement disponibles et de garantir qu’elles disposent en permanence des ressources nécessaires en fonction des demandes de CPU/mémoire de la VM.
Comprendre le fonctionnement des deux mécanismes vous aide, en tant qu’administrateur vSphere, à exploiter les deux technologies de la meilleure façon possible et en accord avec les meilleures pratiques. Parmi les avantages que les deux technologies apportent, chaque fonctionnalité est extrêmement facile à activer et à configurer. En quelques clics dans les propriétés de vos clusters vSphere, vous pouvez rapidement commencer à bénéficier de ces fonctionnalités disponibles au niveau du cluster.
Suivez nos flux Twitter et Facebook pour les nouvelles versions, les mises à jour, les posts perspicaces et plus encore.