Introduction
Si vous analysez vos données à l’aide d’une régression multiple et que l’une de vos variables indépendantes a été mesurée sur une échelle nominale ou ordinale, vous devez savoir comment créer des variables fictives et interpréter leurs résultats. En effet, les variables indépendantes nominales et ordinales, plus largement connues sous le nom de variables indépendantes catégorielles, ne peuvent pas être directement saisies dans une analyse de régression multiple. Au lieu de cela, elles doivent être converties en variables nominales. L’exception est constituée par les variables indépendantes ordinales qui sont saisies dans une régression multiple en tant que variables indépendantes continues, qui n’ont pas besoin d’être converties en variables fictives. Par conséquent, dans ce guide, nous vous montrons comment créer des variables fictives lorsque vous avez des variables indépendantes catégorielles.
D’abord, nous présentons l’exemple que nous utilisons pour montrer comment créer des variables fictives dans SPSS Statistics, avant d’expliquer comment configurer vos données dans les fenêtres Vue des variables et Vue des données de SPSS Statistics afin que vous puissiez créer des variables fictives. Si vous n’êtes pas familier avec l’utilisation des variables fictives, nous vous recommandons de lire certains des principes de base des variables fictives et du codage fictif, notamment : (a) le nombre de variables fictives que vous devez créer dans votre analyse ; et (b) comment créer des variables fictives et un codage fictif. Dans la section Procédure qui suit, nous présentons la procédure simple, en trois étapes, Créer des variables fictives dans SPSS Statistics qui peut être utilisée pour créer des variables fictives. Enfin, nous expliquons la sortie de SPSS Statistics après l’exécution de la procédure Create Dummy Variables, y compris la façon dont vos variables fictives seront maintenant configurées dans les fenêtres Variable View et Data View de SPSS Statistics.
Note : Si vous trouvez que les procédures de ce guide ne couvrent pas le type de variables fictives que vous voulez créer, veuillez nous contacter. Nous pourrons peut-être ajouter un autre guide sur le site pour vous aider.
SPSS Statistics
Exemple utilisé dans ce guide
Dans ce guide, nous utiliserons l’exemple de 10 triathlètes à qui l’on a demandé de sélectionner leur sport préféré parmi les trois sports qu’ils pratiquent lors d’un triathlon : la natation, le vélo et la course à pied. Leurs réponses ont été enregistrées dans la variable nominale indépendante, favourite_sport, qui comporte trois catégories : « natation », « cyclisme » et « course à pied ». Cette variable nominale indépendante, favourite_sport, devait être incluse dans une analyse de régression multiple qui comportait également un certain nombre de variables indépendantes continues. Puisque cette variable indépendante était catégorique (c’est-à-dire que les variables nominales et les variables ordinales peuvent être classées de manière générale comme des variables catégoriques), des variables fictives devaient être créées avant qu’elle puisse être entrée dans l’analyse de régression multiple.
Important : remarquez que le sport favori est une variable nominale, mais vous pouvez également créer des variables fictives pour une variable ordinale. En outre, le processus de création de variables fictives est le même, que vous ayez une variable ordinale ou nominale, à l’exception d’un petit changement que vous devez effectuer lors de la configuration de vos données, qui est expliqué ci-dessous.
Note 1 : Les » catégories » d’une variable indépendante catégorielle sont également appelées » groupes » ou » niveaux « , mais le terme » niveaux » est généralement réservé aux catégories qui ont un ordre (par exemple, la variable indépendante ordinale, » niveau de forme physique « , pourrait avoir trois niveaux : « faible », « modéré » et « élevé »). Toutefois, ces trois termes – « catégories », « groupes » et « niveaux » – peuvent être utilisés de manière interchangeable. Dans ce guide, nous les appellerons catégories, mais vous pourriez les appeler groupes ou niveaux si vous préférez.
Note 2 : Le terme « facteurs » est parfois utilisé à la place de « variables indépendantes catégorielles » (c’est-à-dire des variables indépendantes qui sont « ordinales » ou « nominales »). Cependant, ces deux termes – « variables indépendantes catégorielles » et « facteurs » – peuvent être utilisés de manière interchangeable. Dans ce guide, nous les appellerons variables indépendantes catégorielles et vous verrez également SPSS Statistics les désigner comme variables indépendantes plutôt que comme facteurs dans sa procédure de régression multiple. Cependant, vous pouvez vous y référer en tant que facteurs si vous préférez.
SPSS Statistics
Configuration de vos données dans SPSS Statistics
Lorsque vous créez des variables fictives, vous commencerez par une seule variable indépendante catégorielle (par exemple, sport_favori). Pour configurer cette variable indépendante catégorielle, SPSS Statistics dispose d’une vue Variable où vous définissez les types de variables que vous analysez et d’une vue Données où vous saisissez vos données pour cette variable. Dans cette section, nous vous montrons d’abord comment configurer une variable indépendante catégorielle dans la fenêtre Variable View de SPSS Statistics, avant de vous montrer comment saisir vos données dans la fenêtre Data View. Nous utilisons pour cela notre variable indépendante catégorielle, favourite_sport, qui comporte trois catégories : « natation », « vélo » et « course à pied ».
La vue Variable dans SPSS Statistics
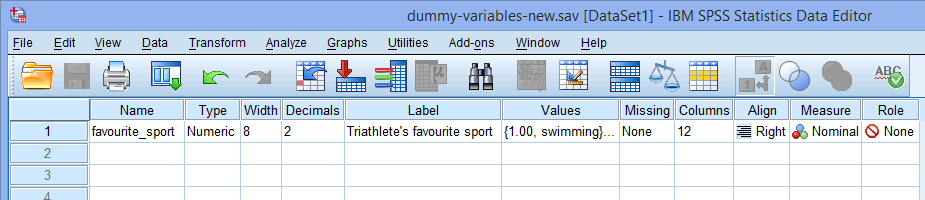
Pour une seule variable indépendante catégorielle (par ex, favourite_sport), votre fenêtre de vue des variables ressemblera à celle ci-dessous :
Note : vous pouvez accéder à la fenêtre de vue des variables dans SPSS Statistics en cliquant sur l’onglet ![]() dans le coin inférieur gauche du logiciel SPSS Statistics.
dans le coin inférieur gauche du logiciel SPSS Statistics.
Publié avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
Le nom de votre variable indépendante catégorielle doit être saisi dans la cellule sous la colonne ![]() (par ex, » favourite_sport » dans la ligne
(par ex, » favourite_sport » dans la ligne ![]() pour représenter notre variable indépendante catégorielle, favourite_sport. Il existe certains caractères « illégaux » qui ne peuvent pas être saisis dans la cellule
pour représenter notre variable indépendante catégorielle, favourite_sport. Il existe certains caractères « illégaux » qui ne peuvent pas être saisis dans la cellule ![]() . Par conséquent, si vous obtenez un message d’erreur et que vous souhaitez que nous ajoutions un guide SPSS Statistics pour expliquer ce que sont ces caractères illégaux, veuillez nous contacter.
. Par conséquent, si vous obtenez un message d’erreur et que vous souhaitez que nous ajoutions un guide SPSS Statistics pour expliquer ce que sont ces caractères illégaux, veuillez nous contacter.
Note : pour votre propre clarté, vous pouvez également fournir une étiquette pour vos variables dans la colonne ![]() . Par exemple, l’étiquette que nous avons entrée pour « sport_favori » était « Sport préféré du triathlète ».
. Par exemple, l’étiquette que nous avons entrée pour « sport_favori » était « Sport préféré du triathlète ».
La cellule sous la colonne ![]() doit contenir les informations sur les catégories de votre variable indépendante catégorielle (par exemple, « natation », « cyclisme » et « course à pied » pour sport_favori. Pour saisir ces informations, cliquez dans la cellule sous la colonne
doit contenir les informations sur les catégories de votre variable indépendante catégorielle (par exemple, « natation », « cyclisme » et « course à pied » pour sport_favori. Pour saisir ces informations, cliquez dans la cellule sous la colonne ![]() pour votre variable indépendante. Le bouton
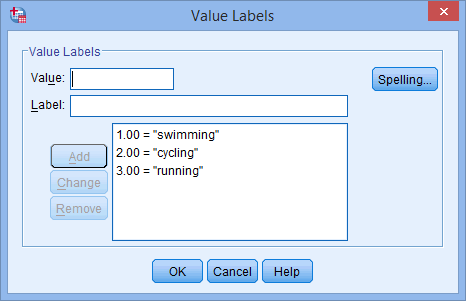
pour votre variable indépendante. Le bouton ![]() apparaîtra dans la cellule. Cliquez sur ce bouton et la boîte de dialogue Value Labels apparaîtra. Vous devez maintenant donner à chaque catégorie de votre variable indépendante une « valeur », que vous saisissez dans la case Valeur : (par exemple, « 1 »), ainsi qu’une « étiquette », que vous saisissez dans la case Étiquette : (par exemple, « natation »). En cliquant sur le bouton
apparaîtra dans la cellule. Cliquez sur ce bouton et la boîte de dialogue Value Labels apparaîtra. Vous devez maintenant donner à chaque catégorie de votre variable indépendante une « valeur », que vous saisissez dans la case Valeur : (par exemple, « 1 »), ainsi qu’une « étiquette », que vous saisissez dans la case Étiquette : (par exemple, « natation »). En cliquant sur le bouton ![]() , le codage apparaîtra dans la boîte principale (par exemple, « 1.00= »natation » pour le sport préféré). La configuration de notre variable indépendante catégorielle est présentée dans la boîte de dialogue Étiquettes de valeur ci-dessous :
, le codage apparaîtra dans la boîte principale (par exemple, « 1.00= »natation » pour le sport préféré). La configuration de notre variable indépendante catégorielle est présentée dans la boîte de dialogue Étiquettes de valeur ci-dessous :
Publié avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
La cellule sous la colonne ![]() devrait afficher
devrait afficher ![]() si vous avez une variable indépendante nominale (par ex, sport_favori, comme dans notre exemple) ou
si vous avez une variable indépendante nominale (par ex, sport_favori, comme dans notre exemple) ou ![]() si vous avez une variable indépendante ordinale (imaginez une variable ordinale telle que « Indice de masse corporelle » (IMC), IMC), qui comporte quatre niveaux : » insuffisance pondérale « , » poids sain/normal « , » surpoids » et » obésité « ). Enfin, la cellule sous la colonne
si vous avez une variable indépendante ordinale (imaginez une variable ordinale telle que « Indice de masse corporelle » (IMC), IMC), qui comporte quatre niveaux : » insuffisance pondérale « , » poids sain/normal « , » surpoids » et » obésité « ). Enfin, la cellule sous la colonne ![]() devrait indiquer
devrait indiquer ![]() .
.
Note : Nous suggérons de changer la cellule sous la colonne ![]() de
de ![]() à
à ![]() , mais vous n’êtes pas obligé de faire ce changement. Nous vous suggérons de le faire car il y a certaines analyses dans SPSS Statistics où le paramètre
, mais vous n’êtes pas obligé de faire ce changement. Nous vous suggérons de le faire car il y a certaines analyses dans SPSS Statistics où le paramètre ![]() entraîne le transfert automatique de vos variables dans certains champs des boîtes de dialogue que vous utilisez. Comme il se peut que vous ne souhaitiez pas transférer ces variables, nous vous suggérons de changer le paramètre
entraîne le transfert automatique de vos variables dans certains champs des boîtes de dialogue que vous utilisez. Comme il se peut que vous ne souhaitiez pas transférer ces variables, nous vous suggérons de changer le paramètre ![]() en
en ![]() afin que cela ne se produise pas automatiquement.
afin que cela ne se produise pas automatiquement.
Vous avez maintenant saisi avec succès toutes les informations que SPSS Statistics a besoin de connaître sur votre variable indépendante catégorielle dans la fenêtre Variable View. Dans la section suivante, nous vous montrons comment saisir vos données dans la fenêtre Vue des données.
La vue des données dans SPSS Statistics
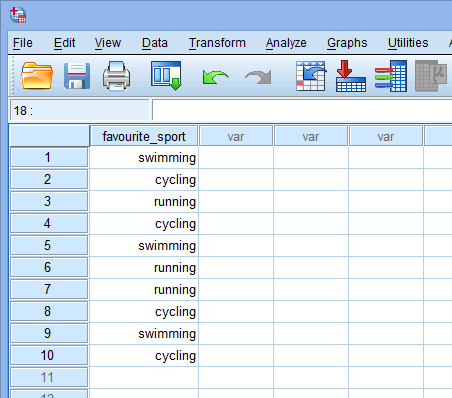
Sur la base de la configuration du fichier pour votre variable indépendante catégorielle dans la fenêtre Vue des variables ci-dessus, la fenêtre Vue des données se présente comme suit :
Note : Vous pouvez accéder à la fenêtre Vue des données dans SPSS Statistics en cliquant sur l’onglet ![]() dans le coin inférieur gauche du logiciel SPSS Statistics.
dans le coin inférieur gauche du logiciel SPSS Statistics.
Publié avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
Votre variable indépendante catégorielle sera affichée dans la première colonne puisque c’est l’ordre dans lequel nous avons entré la variable dans la fenêtre Vue des variables. Dans notre exemple, les réponses des 10 triathlètes sont présentées sous la colonne ![]() . Maintenant, il vous suffit de saisir vos données dans les cellules de cette première colonne. N’oubliez pas que chaque ligne représente un cas (par exemple, un cas pourrait être un seul participant). Ainsi, dans la ligne
. Maintenant, il vous suffit de saisir vos données dans les cellules de cette première colonne. N’oubliez pas que chaque ligne représente un cas (par exemple, un cas pourrait être un seul participant). Ainsi, dans la ligne ![]() de notre exemple, le premier cas représentait un triathlète dont le sport préféré était la « natation ». Comme ces cellules seront initialement vides, vous devez cliquer dans les cellules pour saisir vos données. Vous remarquerez que lorsque vous cliquez dans les cellules de la colonne
de notre exemple, le premier cas représentait un triathlète dont le sport préféré était la « natation ». Comme ces cellules seront initialement vides, vous devez cliquer dans les cellules pour saisir vos données. Vous remarquerez que lorsque vous cliquez dans les cellules de la colonne ![]() , SPSS Statistics vous proposera une option de liste déroulante avec vos catégories déjà remplies.
, SPSS Statistics vous proposera une option de liste déroulante avec vos catégories déjà remplies.
Maintenant que vous avez configuré vos données dans les fenêtres Vue des variables et Vue des données de SPSS Statistics, nous vous recommandons de lire la section suivante : Comprendre les variables fictives et le codage fictif, où nous expliquons les principes de base des variables fictives et du codage fictif. Cependant, si vous connaissez déjà les principes fondamentaux des variables fictives et du codage fictif, vous pouvez sauter cette section et passer directement à la section Procédure où nous exposons la procédure Créer des variables fictives dans SPSS Statistics qui est utilisée pour créer des variables fictives.
SPSS Statistics
Comprendre les variables fictives et le codage fictif
Comme nous l’avons mentionné dans l’introduction, si vous analysez vos données à l’aide de la régression multiple et que l’une de vos variables indépendantes a été mesurée sur une échelle nominale ou ordinale, vous devez savoir comment créer des variables fictives et interpréter leurs résultats. En effet, les variables indépendantes catégorielles (c’est-à-dire les variables indépendantes nominales et ordinales) ne peuvent pas être saisies directement dans une régression multiple. Au lieu de cela, elles doivent être converties en variables fictives. L’exception est constituée par les variables indépendantes ordinales qui sont entrées dans une régression multiple en tant que variables indépendantes continues, qui n’ont pas besoin d’être converties en variables fictives. Dans les sections ci-dessous, nous expliquons : (a) le nombre de variables fictives que vous devez créer ; et (b) comment créer des variables fictives et un codage fictif.
Le nombre de variables fictives que vous devez créer
Le nombre de variables fictives que vous devez créer dépendra du nombre de catégories de votre variable indépendante catégorielle. En règle générale, vous créerez une variable fictive de moins que le nombre de catégories de votre variable indépendante catégorielle. Par exemple, si vous avez une variable indépendante catégorielle avec trois catégories (par exemple, sport_favori, avec les trois catégories suivantes : « natation », « cyclisme » et « course à pied »), vous allez créer deux variables fictives et sélectionner une catégorie qui servira de catégorie de référence (par exemple, « natation » et « cyclisme » deviennent des variables fictives et « course à pied » devient la catégorie de référence). Nous expliquons plus en détail les catégories de référence après le tableau suivant, qui fournit quelques exemples de variables indépendantes catégorielles et le nombre de variables fictives qui doivent être créées :
| Nom de la variable indépendante catégorielle | Type de variable | Nombre de catégories | Nombre de variables fictives | ||||
|---|---|---|---|---|---|---|---|
| 1 | Gender | Nominal | Two (Males & Females) |
One=Males « Females » est la catégorie de référence |
|||
| 2 | Heure | Ordinale | Deux (Moins de 180cm & 180cm et plus) |
Un=Moins de 180cm « 180cm et plus » est la catégorie de référence |
|||
| 3 | Ethnicité | Nominale | Trois (Afro-américain, Caucasien & Hispanique) |
Deux=Africain Américain & Caucasien « Hispanique » est la catégorie de référence |
|||
| 4 | Niveau d’activité physique | Ordinal | Trois (Faible, Modéré & Élevé) |
Deux=faible & Modéré « Élevé » est la catégorie de référence |
|||
| 5 | Profession | Nominale | Quatre (Chirurgien, Médecin, Infirmier & Thérapeute) |
Trois=Chirurgien, Médecin & Infirmier « Thérapeute » est la catégorie de référence |
|||
| 6 | Niveau d’accord | Ordinal | Quatre (Tout à fait d’accord, D’accord, Pas d’accord, Pas du tout d’accord) |
Trois=Très d’accord, D’accord & Pas d’accord « Pas du tout d’accord » est la catégorie de référence |
|||
| 7 | Sujet | Nominal | Cinq (Études commerciales, Psychologie, Sciences biologiques, Ingénierie & Droit) |
Quatre=Études commerciales, Psychologie, Sciences biologiques & Ingénierie « Droit » est la catégorie de référence |
|||
| 8 | Age | Ordinal | Cinq (Moins de 18 ans, 19-30, 31-40, 41-50, 51-60) |
Quatre=Moins de 18 ans, 19-30, 31-40 & 41-50 « 51-60 » est la catégorie de référence |
|||
| Tableau : Exemples de variables indépendantes catégorielles et de leurs variables fictives respectives | |||||||
Comme le montre le tableau ci-dessus, vous n’avez besoin de créer qu’une variable fictive de moins que le nombre de catégories de votre variable indépendante catégorielle. En effet, vous ne devez (et ne devriez) transférer ce nombre de variables fictives dans une régression multiple que lorsque vous avez une variable indépendante catégorielle. Cependant, il existe de bonnes raisons de créer une variable fictive pour chaque catégorie de la variable indépendante catégorielle : (a) c’est plus flexible et (b) cela permet d’effectuer des comparaisons multiples (voir la note ci-dessous). En d’autres termes, si votre variable indépendante catégorielle comporte trois catégories, vous devez créer trois variables fictives, et pas seulement deux.
Par chance, la procédure Créer des variables fictives de SPSS Statistics version 22 et supérieure crée automatiquement une variable fictive pour chaque catégorie de votre variable indépendante catégorielle. Cependant, ce n’est pas le cas pour la procédure Recoder en différentes variables dans SPSS Statistics version 21 ou antérieure. Par conséquent, dans des circonstances normales, vous aurez créé la configuration suivante dans SPSS Statistics, selon que vous avez la version 21 ou antérieure ou la version 22 et supérieure :
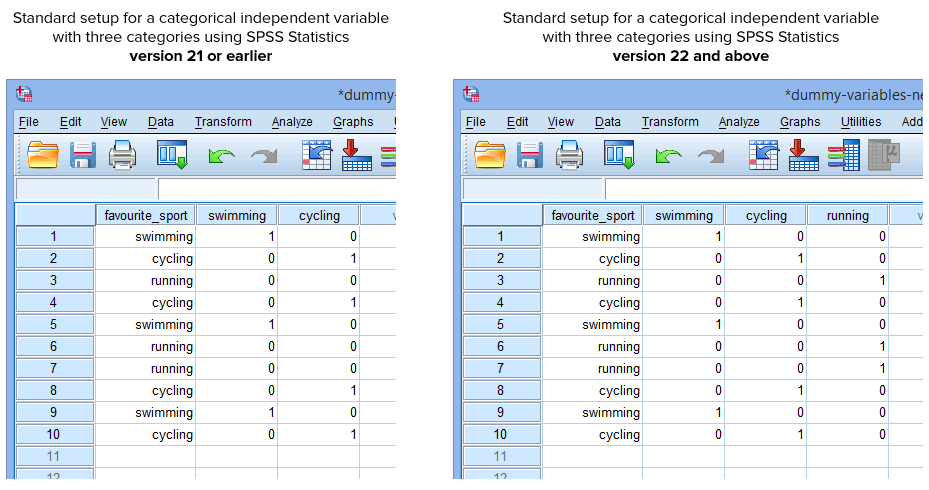
Publiée avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
Note : Comme mentionné ci-dessus, la création d’une variable muette pour chaque catégorie de la variable indépendante catégorielle est bénéfique pour deux raisons : (a) elle est plus flexible et (b) elle permet d’effectuer des comparaisons multiples. Nous abordons brièvement ces avantages ci-dessous :
C’est plus flexible :
Lorsque vous avez créé une variable muette pour chaque catégorie de votre variable indépendante catégorielle, vous pouvez alors considérer n’importe quelle catégorie comme une catégorie de référence. Dans notre exemple, nous avons considéré la catégorie » course à pied » comme la catégorie de référence, ce qui signifie que nous aurions transféré » natation » et » cyclisme » dans l’équation de régression multiple. Toutefois, si nous changions d’avis par la suite sur notre choix de catégorie de référence, nous devrions exécuter à nouveau la procédure de variable muette (à moins que vous ne disposiez de SPSS Statistics version 22 ou supérieure). Par exemple, supposons que nous voulions maintenant considérer la catégorie « cyclisme » comme la catégorie de référence. Nous pourrions maintenant transférer les variables fictives « natation » et « course à pied » dans l’équation de régression multiple parce que nous avons également la variable fictive « course à pied ».
Elle permet de faire des comparaisons multiples :
Le coefficient d’une variable fictive représente la différence entre la catégorie que cette variable fictive représente et la catégorie de référence. Par exemple, avec « course à pied » comme catégorie de référence, le coefficient de la variable muette « natation » représente la différence dans la variable dépendante entre les catégories « natation » et « course à pied ». En utilisant cette méthode, toutes les combinaisons de catégories ne seront pas possibles. Ce problème peut être résolu en utilisant différentes catégories de référence. Cela est possible si toutes les catégories de la variable catégorielle ont une variable fictive.
Comment créer des variables fictives et le codage fictif
Il y a deux étapes pour réussir à mettre en place des variables fictives dans une régression multiple : (1) créer des variables fictives qui représentent les catégories de votre variable indépendante catégorielle ; et (2) entrer des valeurs dans ces variables fictives – connues sous le nom de codage fictif – pour représenter les catégories de la variable indépendante catégorielle. Nous expliquons ce processus ci-dessous en utilisant l’exemple que nous avons exposé ci-dessus.
Explication : Les variables fictives sont tout simplement de nouvelles variables qui servent de « placeholders » pour un schéma de codage particulier. Elles ne contiennent pas de données du tout, en soi. Au lieu de cela, des données/valeurs doivent être ajoutées à ces variables fictives pour qu’elles puissent remplir leur fonction de représentation des catégories de votre variable indépendante catégorielle. Il existe de nombreux types de schémas de codage différents qui dictent les valeurs à saisir dans les variables fictives, mais nous utilisons un schéma de codage très courant appelé codage fictif ou, alternativement, codage indicateur (N.B., ne confondez pas car les variables fictives et le codage fictif ne sont pas la même chose). Le codage fictif fonctionne en utilisant chaque variable fictive pour identifier une catégorie spécifique d’une variable indépendante catégorielle, à l’exception d’une catégorie de référence, que nous expliquons ci-dessous.
Commençons par considérer notre exemple de variable indépendante catégorielle, sport_favori, qui comporte trois catégories : « natation », « cyclisme » et « course à pied ». Puisqu’il y a trois catégories, il faut deux variables fictives représentant deux des catégories, et une catégorie de référence représentant la troisième catégorie.
Note : Rappelez-vous de la discussion ci-dessus qu’une régression multiple exige que vous transfériez une variable fictive de moins que le nombre de catégories de votre variable indépendante catégorielle (c’est-à-dire deux dans notre exemple). Cependant, vous pouvez créer une variable muette pour chaque catégorie de la variable indépendante catégorielle afin d’obtenir une plus grande flexibilité et la possibilité de faire des comparaisons multiples. Néanmoins, dans la discussion ci-dessous, nous ne soulignons que ce qui est requis pour une régression multiple, c’est-à-dire la création d’une variable fictive de moins que le nombre de catégories de votre variable indépendante catégorielle, la catégorie qui n’est pas directement représentée devenant la » catégorie de référence « .
Par exemple, que la variable fictive n°1 représente la catégorie » natation » et la variable fictive n°2 la catégorie » cyclisme « . Il ne reste donc aucune variable muette pour la catégorie « course à pied ». Cette catégorie « manquante » est la catégorie de référence et elle n’est pas nécessaire. En outre, c’est à vous de décider quelle catégorie vous voulez utiliser comme catégorie de référence. Nous aurions pu tout aussi bien choisir la catégorie « natation » comme catégorie de référence plutôt que la catégorie « course à pied ». La seule raison pour laquelle nous ne l’avons pas fait est que, par défaut, SPSS Statistics utilise la dernière catégorie que vous avez codée dans la Vue des variables pour votre variable indépendante catégorielle comme catégorie de référence (voir la note ci-dessous).
Note : Comme expliqué dans la section Configuration des données plus haut et comme indiqué ci-dessous dans la boîte de dialogue Étiquettes de valeur, la troisième et dernière catégorie de notre variable indépendante catégorielle était » courir » (c’est-à-dire, 3= »running »).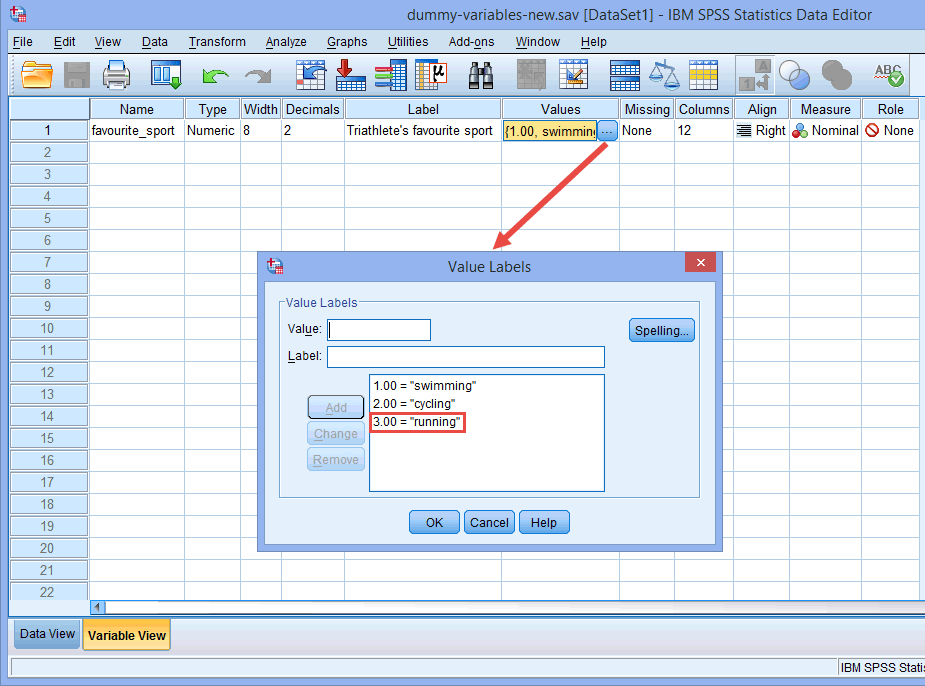
Il n’y avait aucune raison théorique ou statistique pour nous de faire de la catégorie « running » la troisième et dernière catégorie, ce qui en faisait la catégorie de référence dans SPSS Statistics par défaut. Nous avons simplement procédé de cette façon parce que lorsque les triathlètes participent à un triathlon, ils font d’abord la natation, puis entreprennent un cycle, avant de finalement courir jusqu’à la ligne d’arrivée. Par conséquent, il semblait logique de coder notre variable indépendante catégorielle de cette façon. Cependant, nous aurions pu la coder comme suit : 1=cyclisme, 2=course et 3=nage ; cela n’aurait fait aucune différence, à l’exception du fait qu’en tant que troisième et dernière catégorie, la » natation » serait devenue notre catégorie de référence par défaut dans SPSS Statistics.
Lorsque vous créez des variables fictives, vous devez leur donner un nom significatif. Puisque chacune de nos variables fictives représente une catégorie de notre variable indépendante catégorielle, il est d’usage de désigner chaque variable fictive par le nom de la catégorie qu’elle représente. Par conséquent, nous avons appelé la variable fictive n°1 « natation » car elle représente la catégorie natation. De même, nous avons appelé la variable fictive n°2 « cyclisme » car elle représente la catégorie « cyclisme ». En créant ces deux variables fictives, nous aurons deux nouvelles colonnes dans notre ensemble de données dans SPSS Statistics, comme indiqué ci-dessous :
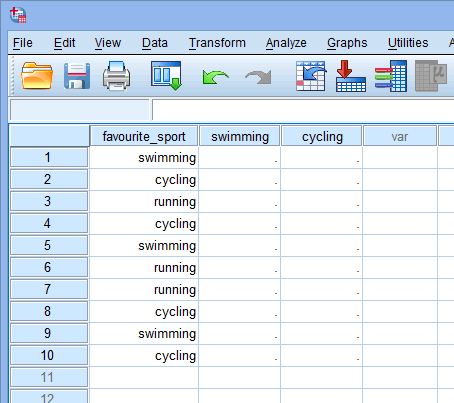
Publié avec la permission écrite de SPSS Statistics, IBM Corporation.
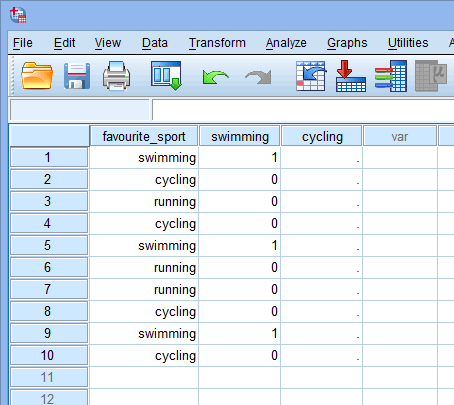
Maintenant que nous avons créé deux variables fictives et que nous leur avons donné des noms appropriés, nous devons entrer des valeurs dans ces variables afin que chaque variable fictive représente réellement sa catégorie de la variable indépendante catégorielle. Avec le codage fictif, c’est très simple. Vous entrez un « 1 » pour représenter tout cas (par exemple, un participant dans votre ensemble de données) qui possède la catégorie et entrez un « 0 » (zéro) s’il ne possède pas la catégorie. Tout d’abord, considérez la variable fictive » natation « , comme indiqué ci-dessous :
Publié avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
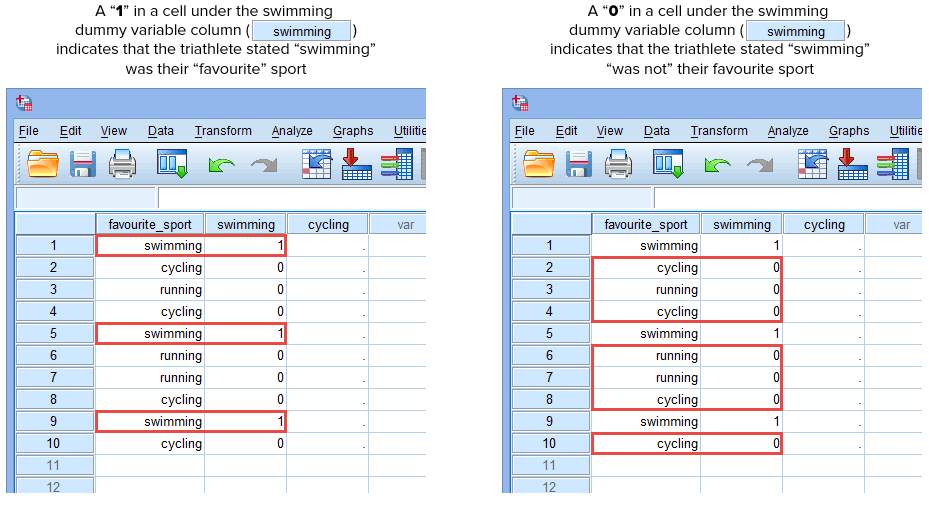
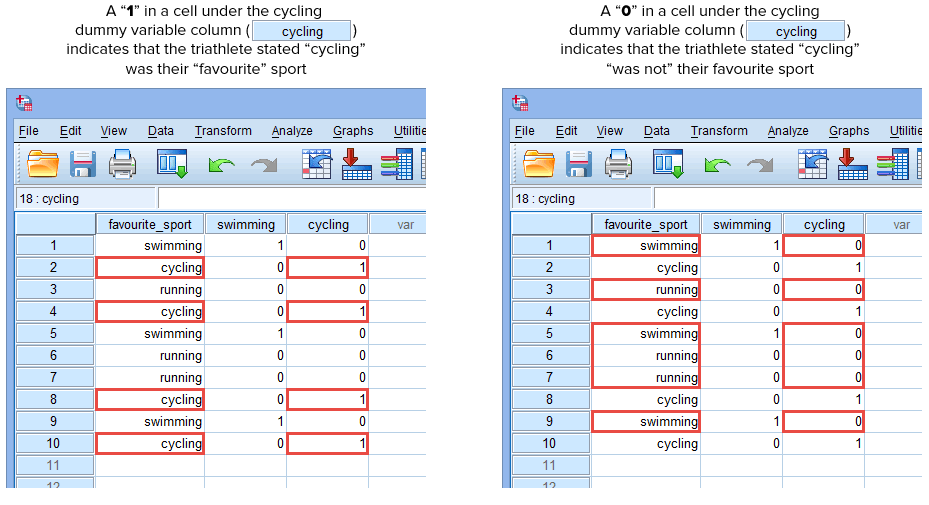
Si l’un des triathlètes a déclaré que la » natation » était son sport » préféré « , nous entrerons un » 1 » dans la cellule sous la colonne de la variable fictive » natation » (![]() ) pour ce triathlète qui a déclaré que la natation était son sport » préféré « . Alternativement, si l’un des triathlètes a déclaré que le « cyclisme » ou la « course à pied » était son sport « préféré », nous entrerons un « 0 » dans la cellule de la colonne de la variable fictive de la natation (
) pour ce triathlète qui a déclaré que la natation était son sport » préféré « . Alternativement, si l’un des triathlètes a déclaré que le « cyclisme » ou la « course à pied » était son sport « préféré », nous entrerons un « 0 » dans la cellule de la colonne de la variable fictive de la natation (![]() ) pour ce triathlète qui a déclaré que la natation n’était « pas » son sport préféré (c’est-à-dire que cela signifie que le « cyclisme » ou la « course à pied » était le sport préféré de ce triathlète). Ceci est mis en évidence ci-dessous pour les 10 triathlètes :
) pour ce triathlète qui a déclaré que la natation n’était « pas » son sport préféré (c’est-à-dire que cela signifie que le « cyclisme » ou la « course à pied » était le sport préféré de ce triathlète). Ceci est mis en évidence ci-dessous pour les 10 triathlètes :
Publié avec la permission écrite de SPSS Statistics, IBM Corporation.
Nous répétons ce processus pour l’autre variable fictive, le » cyclisme « , comme indiqué ci-dessous :
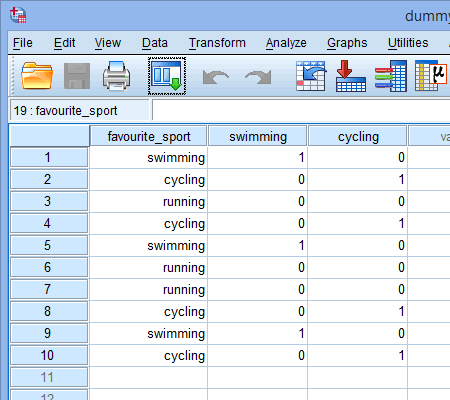
Publié avec la permission écrite de SPSS Statistics, IBM Corporation.
Si l’un des triathlètes a déclaré que le « cyclisme » était son sport « préféré », nous entrerons un « 1 » dans la cellule sous la colonne de la variable fictive « cyclisme » (![]() ) pour ce triathlète qui a déclaré que le cyclisme était son sport « préféré ». Alternativement, si l’un des triathlètes a déclaré que la « natation » ou la « course à pied » était son sport « préféré », nous entrerons un « 0 » dans la cellule de la colonne de la variable muette du cyclisme (
) pour ce triathlète qui a déclaré que le cyclisme était son sport « préféré ». Alternativement, si l’un des triathlètes a déclaré que la « natation » ou la « course à pied » était son sport « préféré », nous entrerons un « 0 » dans la cellule de la colonne de la variable muette du cyclisme (![]() ) pour ce triathlète qui a déclaré que le cyclisme n’était « pas » son sport préféré (c’est-à-dire que cela signifie que la « natation » ou la « course à pied » était le sport préféré de ce triathlète). Ceci est mis en évidence ci-dessous pour les 10 triathlètes :
) pour ce triathlète qui a déclaré que le cyclisme n’était « pas » son sport préféré (c’est-à-dire que cela signifie que la « natation » ou la « course à pied » était le sport préféré de ce triathlète). Ceci est mis en évidence ci-dessous pour les 10 triathlètes :
Publié avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
En entrant des » 1 » et des » 0 » dans vos variables fictives de cette manière, vous aurezcréé un ensemble de variables fictives que vous pourrez entrer dans une analyse de régression multiple. Dans la section Procédure qui suit, nous vous montrons comment créer ces variables fictives à l’aide de la procédure Créer des variables fictives.
SPSS Statistics
Procédure de SPSS Statistics pour créer des variables fictives
Il existe deux procédures dans SPSS Statistics pour créer des variables fictives : la procédure Créer des variables fictives et la procédure Recoder en différentes variables. Dans ce guide, nous vous montrons comment utiliser la procédure Créer des variables fictives, qui est une procédure simple en 3 étapes. Cependant, elle n’est disponible que si vous disposez de SPSS Statistics version 22 ou ultérieure, la version 26 (et la version d’abonnement de SPSS Statistics) étant la dernière version de SPSS Statistics. Si vous n’êtes pas sûr de la version de SPSS Statistics que vous utilisez, consultez notre guide : Identifier votre version de SPSS Statistics. Si vous disposez de SPSS Statistics version 21 ou antérieure ou si vous souhaitez effectuer des comparaisons multiples lors de votre analyse de régression multiple, veuillez consulter la note ci-dessous :
Note : Si vous disposez de SPSS Statistics version 21 ou antérieure, vous ne pouvez pas utiliser la procédure Créer des variables fictives. Par conséquent, la procédure Recoder en différentes variables vous permet au moins de créer des variables fictives dans SPSS Statistics. Bien que vous puissiez également utiliser la procédure Recoder en différentes variables pour créer des variables fictives si vous avez SPSS Statistics version 22 ou ultérieure, nous avons présenté la procédure Créer des variables fictives dans ce guide car elle est dédiée à la création de variables fictives et est beaucoup plus facile et rapide à utiliser. Par exemple, il suffit de 3 étapes pour créer des variables fictives pour l’exemple utilisé dans ce guide, contre 28 étapes pour le même exemple en utilisant la procédure Recoder en différentes variables.
Par conséquent, si vous avez SPSS Statistics version 21 ou antérieure, notre guide amélioré sur la création de variables fictives dans la section des membres sur Laerd Statistics comprend une page dédiée à montrer comment effectuer cette procédure Recoder en différentes variables en 28 étapes. Vous pouvez accéder à ce guide amélioré en vous abonnant à Laerd Statistics. Sinon, vous pouvez simplement utiliser la procédure Créer des variables fictives ci-dessous.
Pour créer des variables fictives lorsque vous disposez de SPSS Statistics version 22 ou ultérieure, suivez la procédure en 3 étapes Créer des variables fictives ci-dessous :
- Cliquez sur Transformer > Créer des variables fictives dans le menu principal, comme indiqué ci-dessous :

Publié avec la permission écrite de SPSS Statistics, IBM Corporation.
La boîte de dialogue Créer des variables fictives s’affiche, comme illustré ci-dessous :
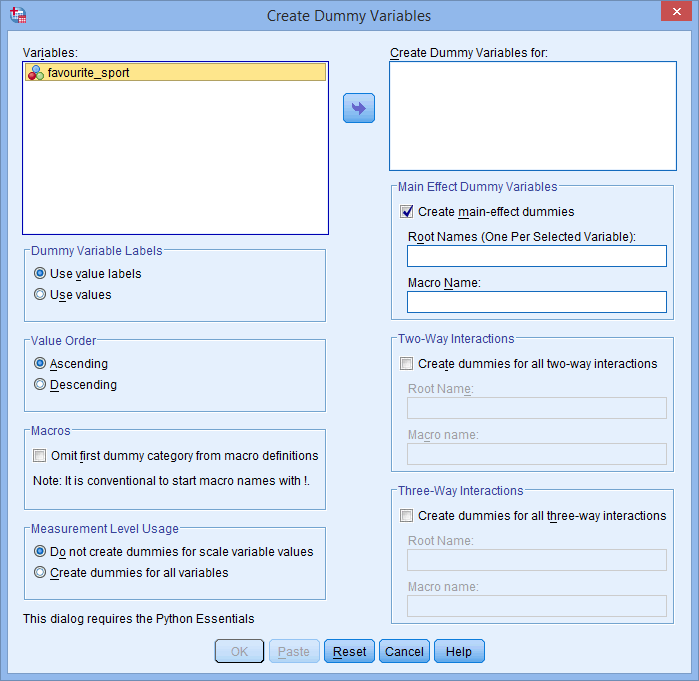
Publié avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
- Transférez la variable indépendante catégorielle, favourite_sport, dans la boîte Créer des variables fictives pour : en la sélectionnant (en cliquant dessus) puis en cliquant sur le bouton
 . Saisissez également un nom « racine » pouvant représenter toutes les nouvelles variables fictives dans la case Noms racine (un par variable sélectionnée) : de la zone -Variables fictives à effet principal-. Nous avons entré le nom racine « fs » comme abréviation de notre variable indépendante catégorielle, « favourite_sport », comme indiqué ci-dessous :
. Saisissez également un nom « racine » pouvant représenter toutes les nouvelles variables fictives dans la case Noms racine (un par variable sélectionnée) : de la zone -Variables fictives à effet principal-. Nous avons entré le nom racine « fs » comme abréviation de notre variable indépendante catégorielle, « favourite_sport », comme indiqué ci-dessous :
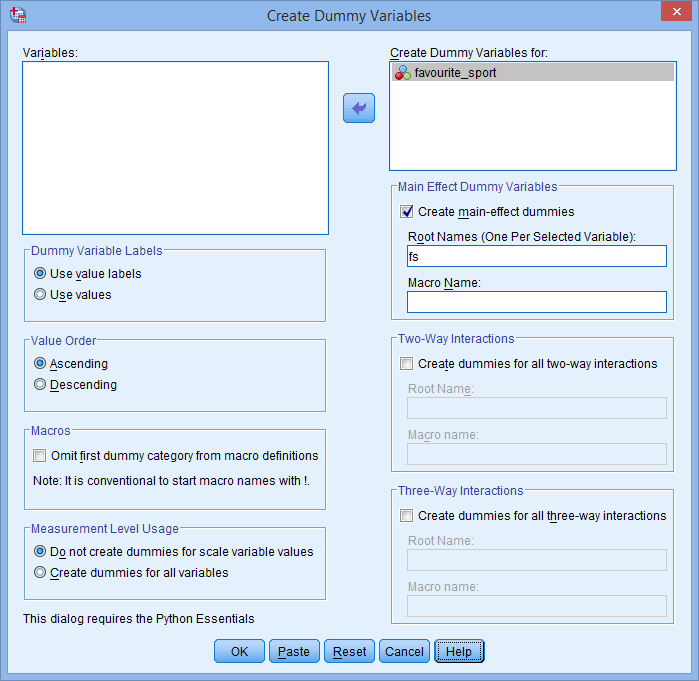
Publié avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
Note : SPSS Statistics ajoutera un numéro séquentiel (c’est-à-dire 1, 2, 3, 4, etc.) à la fin du nom racine que vous choisissez pour représenter votre variable indépendante catégorielle. Un numéro séquentiel sera créé pour chacune des variables fictives que vous souhaitez créer (par exemple, si vous avez deux variables fictives, un 1 et un 2 seront ajoutés à la fin du nom racine, mais si vous avez six variables fictives, un 1, 2, 3, 4, 5 et 6 seront ajoutés à la fin du nom racine). Ceci est illustré pour notre exemple dans la fenêtre Variable View ci-dessous :
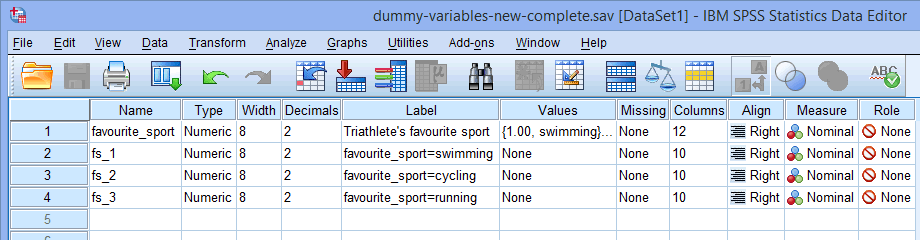
Puisque notre variable indépendante catégorielle, favourite_sport, comportait trois catégories (c’est-à-dire la natation, le cyclisme et la course à pied), la procédure Create Dummy Variables crée trois variables fictives (c’est-à-dire une pour la natation, une pour le cyclisme et une pour la course à pied). Ces trois variables fictives sont mises en évidence dans la colonne ci-dessus : « fs_1 » (pour la natation), « fs_2 » (pour le cyclisme) et « fs_3 » (pour la course à pied). Vous pourrez les renommer plus tard pour qu’ils aient plus de sens. Nous soulignons simplement cela pour que vous sachiez comment fonctionne la case Noms de racine (un par variable sélectionnée) : ci-dessus.
ci-dessus : « fs_1 » (pour la natation), « fs_2 » (pour le cyclisme) et « fs_3 » (pour la course à pied). Vous pourrez les renommer plus tard pour qu’ils aient plus de sens. Nous soulignons simplement cela pour que vous sachiez comment fonctionne la case Noms de racine (un par variable sélectionnée) : ci-dessus.
De plus, le nom de racine que vous entrez dans la case Noms de racine (un par variable sélectionnée) : ne peut pas être le même que le nom de votre variable indépendante catégorielle, comme indiqué ci-dessous (c’est-à-dire , où nous avons entré le nom racine, « favourite_sport », pour illustrer ce que nous ne pourrions pas appeler notre nom racine):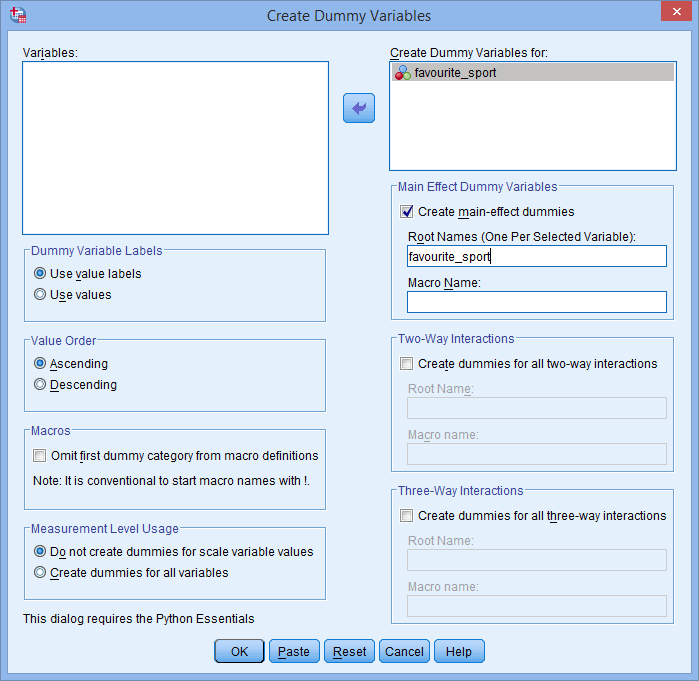
Si le nom racine que vous entrez est le même que le nom de votre variable indépendante catégorielle, comme indiqué ci-dessus, lorsque vous cliquez sur le bouton , vous obtiendrez l’avertissement suivant:
, vous obtiendrez l’avertissement suivant:
- Cliquez sur le bouton .
Après avoir exécuté la procédure de création de variable fictive en 3 étapes ci-dessus, vous aurez créé des variables fictives pour votre variable indépendante catégorielle. Dans la section suivante, mettez en évidence la sortie qui est créée dans la vue des variables et la vue des données de SPSS Statistics après avoir exécuté cette procédure Créer des variables fictives.
SPSS Statistics
Sortie et configuration des données dans SPSS Statistics après la création de variables fictives
Après avoir créé vos variables fictives, SPSS Statistics produit le tableau de création de variables suivant son IBM SPSS Statistics Viewer:
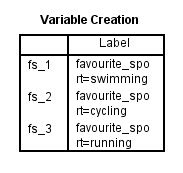
Publié avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
Le tableau de création de variables confirme que vous avez réussi à créer des variables fictives. Il devrait y avoir autant de lignes qu’il y a de nouvelles variables fictives. Puisque nous avons créé trois variables fictives, il y a trois lignes dans le tableau, « fs_1 », « fs_2 » et « fs_3 », qui reflètent le nom de la racine et la numérotation séquentielle entrés à l’étape 2 de la procédure Créer des variables fictives de la section précédente. Pour chacune de ces variables fictives, un libellé est fourni dans le tableau afin de préciser la catégorie de la variable indépendante catégorielle que représente chaque variable fictive. Par exemple, l’étiquette, « favourite_sport=swimming », est fournie pour « fs_1 », indiquant que « fs_1 » est la variable fictive pour la catégorie « natation » de la variable indépendante catégorielle, favourite_sport.
Puis, allez dans la fenêtre Variable View de SPSS Statistics en cliquant sur l’onglet ![]() . Les trois variables fictives auront été ajoutées, comme indiqué ci-dessous (c’est-à-dire les variables fictives, « fs_1 », « fs_2 » et « fs_3 », dans la colonne
. Les trois variables fictives auront été ajoutées, comme indiqué ci-dessous (c’est-à-dire les variables fictives, « fs_1 », « fs_2 » et « fs_3 », dans la colonne ![]() ):
):
Publiée avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
Note : Vous pouvez changer les noms des variables fictives dans la colonne ![]() pour rendre plus clair ce dont il s’agit. Par exemple, nous avons changé « fs_1 » en « natation », « fs_2 » en « cyclisme » et « fs_3 » en « course à pied », comme indiqué ci-dessous :
pour rendre plus clair ce dont il s’agit. Par exemple, nous avons changé « fs_1 » en « natation », « fs_2 » en « cyclisme » et « fs_3 » en « course à pied », comme indiqué ci-dessous :
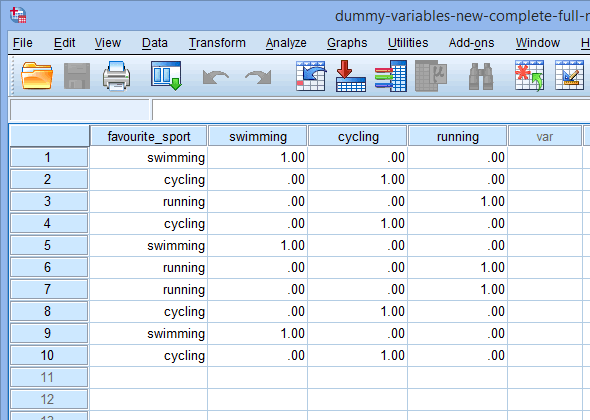
Enfin, allez dans la fenêtre d’affichage des données de SPSS Statistics en cliquant sur l’onglet ![]() . Le codage fictif est indiqué sous chacune des variables fictives qui ont été créées. Par exemple, dans les lignes sous la colonne « fs_1 », la catégorie « natation » est codée « 1.00 », alors que les catégories « cyclisme » et « course à pied » sont codées « .00 », comme indiqué ci-dessous. Si vous n’êtes pas sûr de la raison pour laquelle ces variables fictives sont codées de cette manière, consultez la section : Comprendre les variables fictives et le codage fictif.
. Le codage fictif est indiqué sous chacune des variables fictives qui ont été créées. Par exemple, dans les lignes sous la colonne « fs_1 », la catégorie « natation » est codée « 1.00 », alors que les catégories « cyclisme » et « course à pied » sont codées « .00 », comme indiqué ci-dessous. Si vous n’êtes pas sûr de la raison pour laquelle ces variables fictives sont codées de cette manière, consultez la section : Comprendre les variables fictives et le codage fictif.
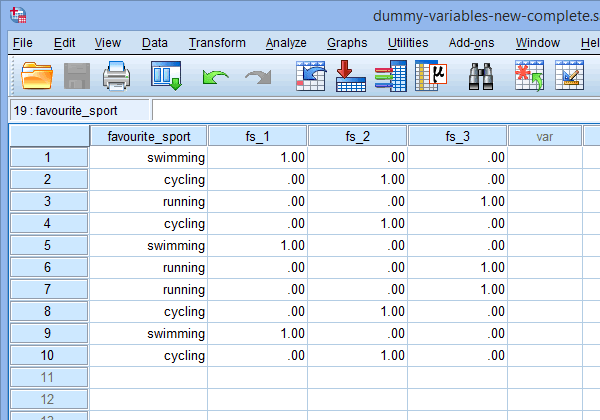
Publié avec l’autorisation écrite de SPSS Statistics, IBM Corporation.
Note 1 : En raison des paramètres par défaut de SPSS Statistics, vos variables fictives seront codées « 1,00 » ou « .00 » au lieu de « 1 » ou « 0 », respectivement. Elles sont identiques. Cependant, vous verrez souvent le codage des variables fictives écrit en termes de 1 et de 0 plutôt que d’inclure des décimales.
Note 2 : Si vous avez modifié les noms des variables fictives dans la colonne ![]() de la fenêtre Vue des variables ci-dessus, ceux-ci auront également été modifiés dans les colonnes de la fenêtre Vue des données, comme indiqué ci-dessous (par exemple, l’en-tête de la colonne
de la fenêtre Vue des variables ci-dessus, ceux-ci auront également été modifiés dans les colonnes de la fenêtre Vue des données, comme indiqué ci-dessous (par exemple, l’en-tête de la colonne ![]() est maintenant intitulé
est maintenant intitulé ![]() ):
):
.