Les protéines à ancrage GPI font figure d’intrus. En introduction à la biologie cellulaire, on nous a appris qu’il existait cinq types de protéines membranaires, nommées comme suit : Type I, Type II, Type III, Type IV, et GPI-anchored. Pourquoi avons-nous cette étrange classe de protéines fusionnées à une chaîne de sucre et de graisse ? Quel est leur rôle ? Pouvons-nous obtenir des informations sur la protéine qui m’intéresse – la PrP – en en apprenant davantage sur cette classe de protéines dont elle est membre ?
Sonia et moi, ainsi que notre coéquipier Andrew et avons fait quelques lectures sur ce sujet et j’écris ce billet de blog pour partager une partie de ce que nous avons appris.
Lecture
Nous avons commencé par lire quelques revues . Celles-ci couvraient principalement la structure et la biogénèse de l’ancre GPI elle-même, sur laquelle on sait une quantité étonnante de choses.
Cette ancre, dont le nom complet est glycosylphosphatidylinositol, n’est pas un monolithe : c’est une description générale d’une molécule dont les détails peuvent varier. En général, en partant du résidu ω (dernier résidu présent de façon post-traductionnelle) de la protéine, on a de l’éthanolamine, puis un phosphate, puis des sucres, puis un phospholipide. Le squelette de sucre central est conservé, mais les chaînes latérales qui se ramifient à partir de celui-ci peuvent varier, et le groupe de tête du phosholipide et les acides gras peuvent également varier. L’ancre GPI de la PrP a été caractérisée en , mais même là, ce n’est pas un monolithe – ils ont identifié au moins six structures différentes qui diffèrent dans la composition de la chaîne latérale de sucre.
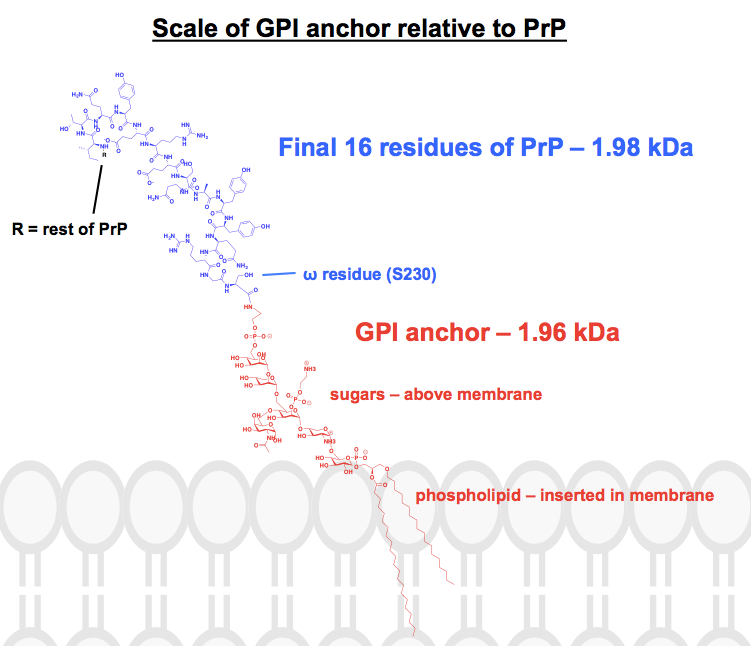
Toutes les structures chimiques que j’ai trouvées des ancres GPI ont au moins certaines parties abrégées ou résumées, et la protéine est généralement juste montrée comme une image. Je voulais avoir une idée de ce à quoi ressemblent réellement ces ancres sur le plan chimique, dans le contexte de leurs protéines attachées, et j’ai donc entrepris de dessiner une structure complète dans ChemDraw. À partir de la figure 1, la plus proche d’une structure squelettique complète que j’ai pu trouver, j’ai ajouté les détails de l’un des ancrages GPI de la PrP dans le panneau supérieur de la figure 6. Le poids moléculaire était de 1 958 Da, donc pour le contexte, j’ai ajouté les 16 derniers résidus de HuPrP23-230, qui pèsent comparativement 1 979 Da. Cela représente environ 8 % de la séquence de la PrP modifiée de manière post-traductionnelle. Je ne suis pas certain d’avoir bien saisi toutes les liaisons, mais voici ce que j’ai trouvé :
Dans de nombreux cas, un gène possède plusieurs isoformes, un produit d’épissage donnant naissance à une protéine à ancrage GPI tandis que d’autres donnent naissance à des formes sécrétées ou transmembranaires. C’est le cas de NCAM1, qui a trois isoformes principales, dont l’une est ancrée dans le GPI et les deux autres sont transmembranaires, et de ACHE (codant pour l’acétylcholinestérase), dont la forme ancrée dans le GPI ne se trouve apparemment que sur les globules rouges (NCBI Genes). L’histoire la plus fascinante ici est celle du gène Ly6a de la souris qui, grâce à un polymorphisme génétique, est ancré à la GPI dans certaines souches de souris et pas dans d’autres. Ce n’est que sous sa forme ancrée GPI qu’il agit comme récepteur pour le vecteur viral AAV PHP.eB . (Ce vecteur atteint une absorption étonnamment efficace dans les neurones du cerveau pour la thérapie génique , mais malheureusement, c’est un gène de souris seulement – nous, les humains, n’avons même pas Ly6a).
On en sait beaucoup sur la façon dont les ancres GPI sont synthétisées et attachées aux protéines , avec >20 protéines impliquées dans la voie, dont la plupart commencent par le préfixe « PIG » et sont codées par des gènes tels que PIGA, PIGK, et ainsi de suite – voir la figure 2 pour un diagramme. La majeure partie de la biosynthèse a lieu alors que l’ancre est insérée dans la membrane du RE mais n’est attachée à aucune protéine. En fait, les premières étapes ont lieu sur le feuillet cytosolique de la membrane, et ce n’est que plus tard que l’ancre bascule du côté de la lumière (à l’intérieur du RE). L’étape finale est celle où la GPI transamidase, un complexe composé d’au moins cinq protéines, clive le signal GPI de l’extrémité C de la protéine et fixe l’ancre GPI au résidu ω de la protéine (le dernier résidu de la séquence modifiée post-traductionnelle). Il y a ensuite une maturation supplémentaire de l’ancre GPI alors que la protéine migre hors du RE vers la surface cellulaire.
Il existe un certain nombre de petites molécules inhibitrices de la biosynthèse de la GPI chez les champignons, dont certaines personnes ont essayé de développer en tant que médicaments antifongiques , mais pour autant que je sache, le seul inhibiteur connu de la biosynthèse de la GPI dans les cellules de mammifères est la mannosamine, un analogue du mannose qui est chimiquement incompatible avec l’incorporation dans la GPI .
J’ai cherché et cherché un logo de séquence de quel motif de séquence d’acides aminés la GPI transamidase reconnaît, mais je n’en ai trouvé aucun. Apparemment, le motif de séquence est assez lâche , et apparemment les signaux GPI ne sont même pas homologues , ce qui signifie qu’ils n’ont pas évolué à partir d’une séquence ancestrale commune, mais ont plutôt évolué de manière convergente, dans la mesure où il y a même une convergence. La meilleure description que j’ai pu trouver est la suivante (en lisant de N à C-terminal jusqu’à la fin de la protéine) : 1) environ 11 résidus d’un lieur non structuré, 2) quelques résidus avec de petites chaînes latérales, y compris un résidu ω qui peut être soit S, N, D, G, A ou C, 3) un espaceur de 5 à 10 acides aminés polaires, et enfin 4) 15 à 20 acides aminés hydrophobes. La PrP suit vaguement ce motif. D’après les structures publiées, l’hélice alpha 3 se termine au résidu Q223, ce qui laisse le « lieur non structuré » comme étant juste AYYQR (un peu plus court que les 11 résidus prescrits). La région de la » petite chaîne latérale » serait GS|SM (le tuyau désignant le site de coupe de la transamidase), la région polaire serait VLFSSPP, et l’extrémité C hydrophobe serait VILLISFLIFLIVG.
Certaines des protéines de la voie de biosynthèse et de fixation de la GPI sont très importantes, et un certain nombre de maladies graves et de syndromes de déficience de l’ancre GPI ont été décrits, en raison de la perte de fonction bialélique ou de mutations missense apparemment hypomorphes dans des gènes comme PIGO, PIGV, PIGW, PGAP2 et PGAP3 .
Sonia a trouvé un excellent article d’il y a quelques années où ils ont fait un crible de mutagenèse dans des cellules humaines haploïdes pour identifier les gènes nécessaires à la biogenèse de deux protéines à ancrage GPI : PrP et CD59 . Ils ont utilisé un tri FACS répété des cellules sur la base de la PrP et de la CD59 de surface cellulaire afin d’identifier les cellules dont les niveaux de surface de ces protéines sont considérablement réduits, puis ils ont effectué un séquençage pour voir quels gènes knock-out étaient enrichis dans ces cellules par rapport à la population mère. Comme on pouvait s’y attendre, la plupart des gènes PIG sont apparus pour les deux protéines (figure 4), mais tous les résultats ne se chevauchaient pas, ce qui est un peu surprenant, d’autant plus qu’au niveau de l’ARN, au moins, la PrP et la CD59 sont deux des protéines dont les profils d’expression sont les plus similaires dans les tissus (voir la carte thermique au bas de cet article). Une série d’enzymes impliquées dans la modification de la chaîne latérale de l’ancre GPI n’ont été trouvées que pour CD59, ce qui suggère que CD59, mais pas PrP, a besoin de ces chaînes latérales complexes pour mûrir et atteindre la surface cellulaire. Par ailleurs, Sec62 et Sec63 n’ont été trouvées que pour la PrP – il s’agit de protéines impliquées d’une manière ou d’une autre dans la translocation co-traductionnelle dans le RE, mais apparemment, elles sont nécessaires pour la PrP mais pas pour CD59, ni pour CD55 ou CD109, deux autres protéines de contrôle examinées. Il s’agit d’un nouveau chapitre fascinant dans la réponse à ma question « l’expression de la PrP a-t-elle quelque chose de spécial ? », où je cherchais quelque chose d’unique dans la biogenèse de la PrP qui pourrait être potentiellement ciblé par une petite molécule. Bien sûr, le fait que ces protéines ne soient pas importantes pour trois autres protéines de contrôle ne signifie pas qu’elles ne sont pas importantes – une étude a montré que Sec62 était nécessaire à la sécrétion de nombreuses petites protéines, et le gène SEC62 est totalement dépourvu de variants de perte de fonction dans la population humaine, ce qui suffit à suggérer une haplo-insuffisance. SEC63 semble moins contraint, bien que cela puisse simplement signifier qu’il agit de manière récessive.
Aucune des réponses ci-dessus ne permet de savoir pourquoi les protéines à ancrage GPI existent. Mon ancien cours de biologie cellulaire a d’ailleurs omis un détail : il existe en fait une sixième classe de protéines membranaires, appelées protéines ancrées à la queue (TA) , qui ont juste une extrémité C hydrophobe qui s’enfonce dans la membrane mais ne fait pas saillie de l’autre côté. Pourquoi toutes ces protéines à ancrage GPI ne pourraient-elles pas être simplement des protéines TA ? Pourquoi les cellules ont-elles évolué une voie si compliquée pour synthétiser un ancrage sucre-graisse à la place, et pourquoi l’ont-elles évolué si tôt dans le jeu – les ancres GPI sont présentes partout dans les eucaryotes, y compris dans de nombreux pathogènes unicellulaires qui infectent les humains.
La plupart des revues n’ont pas passé beaucoup de temps sur cette question, probablement parce que c’est la chose la plus difficile à répondre. Les protéines à ancrage GPI elles-mêmes, dans la mesure où leurs fonctions natives sont connues, ont un énorme éventail de fonctions – il y a des enzymes (comme l’AChE), des molécules d’adhésion cellulaire (comme NCAM1), des protéines qui régulent le complément dans le système immunitaire (CD59), etc…. Il existe apparemment au moins une protéine ancrée à la GPI qui participe à la maintenance de la myéline dans les nerfs périphériques. Mais que peuvent faire exactement les protéines ancrées à la GPI que les autres protéines ne peuvent pas faire ? Une revue cite quelques idées qui ont été proposées. L’une d’entre elles est que les protéines à ancrage GPI sont douées pour se dimériser de manière transitoire. Certaines études ont exploré l’idée que l’homodimérisation joue un certain rôle dans la biologie des prions, bien que la pertinence des systèmes modèles utilisés pour la situation in vivo ne soit pas encore claire. Une autre idée est que, comme les protéines ancrées aux GPI peuvent être détachées de la surface cellulaire, par exemple par l’enzyme de conversion de l’angiotensine (ACE), leur localisation peut être régulée de manière dynamique. Ici aussi, nous savons que la PrP peut être éliminée, apparemment par l’enzyme ADAM10, bien que son rôle dans la fonction native de la PrP ne soit pas encore clair. Une troisième idée, et peut-être celle dont j’ai le plus entendu parler, est que les protéines à ancrage GPI se rassemblent sélectivement dans des « radeaux lipidiques ». Il s’agit peut-être de l’explication la plus séduisante, car on pourrait imaginer toutes sortes d’effets d’entraînement, où l’augmentation de la concentration locale effective de ces protéines permettrait davantage d’interactions, et ainsi de suite. Mais une revue a souligné qu’une mise en garde est que les radeaux lipidiques sont encore plus une idée abstraite qu’une chose concrète – alors qu’ils sont définis fonctionnellement par l’insolubilité des détergents et que la plupart des gens les décrivent comme étant riches en sphingomyéline et en cholestérol, il n’y a pas de définition universellement acceptée de ce qui est et n’est pas un radeau lipidique, et les preuves empiriques suggèrent qu’ils peuvent être beaucoup plus petits et plus transitoires que la plupart des gens le pensent.
Avec cette lecture en main, j’ai entrepris d’obtenir une liste de ces protéines et de faire quelques analyses sur elles pour voir si je pouvais avoir une meilleure idée de ce qu’elles sont.
analyses
Uniprot a une liste de 173 protéines humaines ancrées à la GPI. Ceux-ci ont mappé à 140 symboles de gènes, qui ont chuté à 135 après avoir exécuté ce script pour mettre à jour les symboles de gènes codant pour les protéines actuellement approuvés par HGNC. La liste finale de 135 symboles de gènes est ici.
Uniprot n’offre aucune information sur la façon dont leurs annotations ont été générées, bien qu’il doive y avoir un degré significatif de curation manuelle. À titre de comparaison, Andrew a également déniché une série d’articles soignés qui utilisent PI-PLD ou PI-PLC, deux enzymes qui clivent les ancres GPI, pour isoler empiriquement les protéines ancrées GPI des cellules . En combinant les listes de ces articles et en les associant aux symboles génétiques actuels, nous avons obtenu 107 gènes. Nous avons vérifié plusieurs d’entre eux au hasard. Parmi eux se trouvaient des protéines à ancrage GPI bien connues, telles que glypican-1 (GPC1) et la molécule d’adhésion des cellules neurales (NCAM1), qui auraient toutes deux des interactions avec la PrP. Mais plusieurs gènes pour lesquels aucun ancrage GPI ne semblait être connu dans la littérature, comme VDAC3, étaient également présents, certains d’entre eux pouvant simplement être des protéines très abondantes ou des faux positifs pour d’autres raisons. Par ailleurs, il existe des sources évidentes de faux négatifs : les gènes qui n’étaient tout simplement pas exprimés dans la lignée cellulaire étudiée, ou qui n’étaient pas assez abondants pour être détectés par spectrométrie de masse, et les paralogues de la PrP, SPRN et PRND, ne figuraient pas dans les listes. Dans l’ensemble, 51 gènes figuraient dans les deux listes, un enrichissement hautement significatif (OR = 217, P < 1 × 10-84), ce qui contribue à me rassurer sur la cohérence des annotations d’Uniprot avec les données empiriques. Mais pour les analyses ultérieures, nous avons décidé d’utiliser la liste Uniprot car elle semble plus sensible et spécifique.
Avec cette liste, j’ai voulu voir comment les protéines à ancrage GPI se classent. La PrP est une protéine à un seul exon, courte (208 acides aminés dans sa forme mature), non essentielle et largement exprimée. Ces caractéristiques sont-elles typiques ou atypiques pour une protéine à ancrage GPI ?
Il s’avère que les protéines à ancrage GPI sont partout sur la carte, tout aussi variables sur chaque dimension que j’ai examinée que tout autre ensemble de protéines.
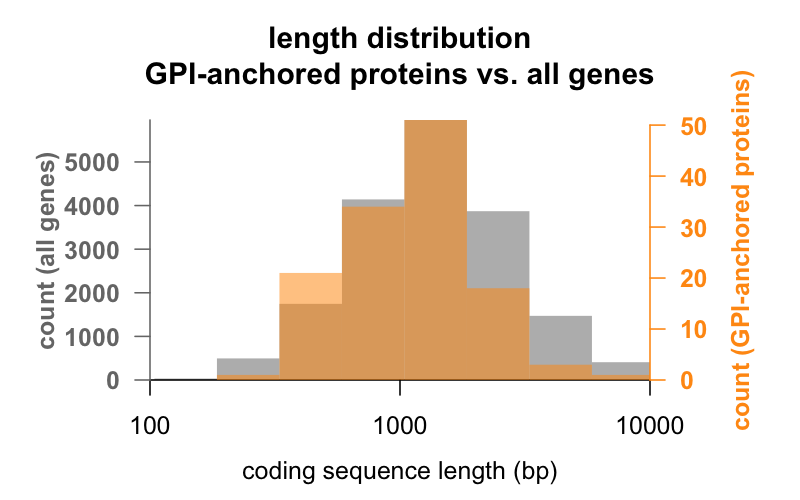
D’abord, la longueur. Ci-dessous, des histogrammes superposés de la longueur de la séquence codante en paires de bases pour tous les gènes, par rapport aux gènes codant pour des protéines ancrées GPI. La distribution des protéines ancrées à la GPI est à peine décalée vers la gauche. Le gène moyen de la protéine ancrée GPI possède 1 301 pb de séquence codante, alors que le gène moyen en possède 1 729, mais cette différence de moyenne est faible par rapport à la variation au sein de chaque groupe. La PrP, avec seulement 762 pb de séquence codante, est définitivement du côté des petites protéines, bien qu’elle ne soit en aucun cas une aberration dans l’un ou l’autre groupe – CD52, avec seulement 186 paires de base de séquence et apparemment seulement 12 acides aminés dans sa forme mature , est la plus petite protéine ancrée par GPI.
Qu’en est-il du nombre d’exons ? Les protéines ancrées GPI ont effectivement un peu moins d’exons en moyenne, par rapport à tous les gènes (moyenne de 7,8 contre 10,1), ce qui est cohérent avec la légère différence de distribution de longueur notée ci-dessus, mais la plupart sont multi-exons. Ici aussi, la PrP est plus petite : il n’y a que six protéines ancrées dans la GPI qui n’ont qu’un seul exon codant, et trois d’entre elles sont la PrP et ses deux paralogues, Sho et Dpl. (Les trois autres gènes sont GAS1, SPACA4, et le fabuleusement nommé OMG).
J’ai ensuite examiné la contrainte de perte de fonction. La contrainte est une mesure de la force de la sélection naturelle à laquelle un gène est soumis, basée sur la façon dont il est appauvri pour, disons, le non-sens, le décalage de cadre, et la variation du site d’épissage dans la population générale par rapport à l’attente basée sur les taux de mutation. Cette mesure n’est pas très interprétable pour les gènes courts, à la fois pour des raisons statistiques (le nombre de mutations attendues est faible pour les gènes courts, il est donc difficile de quantifier l’appauvrissement) et biologiques (les gènes à un seul exon ne sont pas soumis à la désintégration par non-sens, il est donc plus difficile de savoir si les variantes de tronquage de protéines sont réellement des « pertes de fonction » ou non). Mais comme la plupart des protéines ancrées dans la GPI ne sont pas aussi courtes que la PrP, j’ai pensé que cela valait la peine d’y jeter un coup d’œil. Résultat : en moyenne, les protéines ancrées dans le GPI sont légèrement moins contraintes que le gène moyen, ce qui signifie qu’elles présentent une plus grande part de leur quantité attendue de variation de perte de fonction. Le gène moyen présente 47 % de sa variation de perte de fonction, tandis que les protéines ancrées à la GPI en présentent 56 %. Mais comme pour tout ici, il y a une large distribution dans les deux camps. Pour les protéines ancrées à la GPI, vous avez l’ACHE absolument contraint (17 LoFs attendus et aucun observé) à une extrémité et, à l’autre extrémité, plusieurs gènes qui semblent ne subir aucune sélection contre la perte de fonction du tout – CNTN6, CD109, TREH et MSLN sont quelques exemples. PRNP tombe dans ce dernier camp une fois que l’on exclut les résidus ≥145 où les variants de troncature de la protéine provoquent un gain de fonction .
Enfin, je me suis demandé où les protéines ancrées par GPI sont exprimées. La PRNP est la plus élevée dans le cerveau mais elle est exprimée partout. Est-ce typique ? J’ai téléchargé le fichier complet de résumé « gene median tpm » de GTEx v7 (15 janvier 2016), où chaque ligne est un gène et chaque colonne est un tissu et les cellules sont des RPKM – lectures RNA-seq par kilobase d’exon par million de lectures mappées. Travailler avec cet ensemble de données a nécessité quelques mises au point. J’ai entendu dire que certains bioinformaticiens considèrent que <1 RPKM est « non exprimé », mais la matrice d’expression est clairsemée – la plupart des gènes ne sont pas fortement exprimés dans la plupart des tissus – de sorte que le bruit en dessous de 1 RPKM peut dominer si vous tracez simplement les RPKM bruts. En même temps, l’expression des gènes doit être considérée sur une échelle logarithmique, car les gènes d’un tissu peuvent varier de <1 RPKM à >10 000 RPKM, donc si vous considérez tout sur une échelle linéaire, les quelques combinaisons gène/tissu très fortement exprimées peuvent également dominer, ce qui fait que la matrice semble encore plus éparse qu’elle ne l’est. J’ai donc pris le log10 de la matrice et j’ai tronqué la distribution à , ainsi, l’échelle violette que j’ai utilisée va de 1 – 10 – 100 – 1 000 – 10 000 RPKM. Ensuite, j’ai fait un sous-ensemble des protéines ancrées GPI d’Uniprot. Pour visualiser tout cela, j’ai réalisé une carte thermique pour la première fois de ma vie. J’ai souvent vu ces cartes dans des articles et elles ne me parlent généralement pas, mais ici mon but était juste d’avoir une idée du modèle d’expression, et après avoir joué un peu, c’est ce qui m’a donné le plus d’informations. Le principe d’une carte thermique est que les lignes et les colonnes sont regroupées de manière à ce que les éléments similaires aillent ensemble. Ainsi, par exemple, toutes les colonnes de tissu cérébral sont alignées consécutivement dans un patch sur l’axe des x, et tous les gènes fortement exprimés par le cerveau sont alignés consécutivement dans un patch sur l’axe des y, de sorte que leur intersection forme un rectangle violet dense qui peut être interprété comme, « il existe un cluster de gènes qui sont principalement exprimés par le cerveau ».
Les lecteurs intéressés peuvent consulter le PDF d’art vectoriel à pleine échelle de la carte thermique, mais pour la rendre plus immédiatement accessible, voici une version annotée à la main appelant les grappes d’intérêt:

La réponse, alors, est non – la plupart des protéines ancrées GPI n’ont pas le même schéma d’expression que PRNP. La PRNP fait partie de la poignée de protéines les plus fortement et les plus largement exprimées, et figure près du sommet de cette carte thermique, avec CD59, LY6E, GPC1 et BST2. La plupart des protéines ancrées à la GPI ont une expression plus faible ou plus restreinte au niveau tissulaire, certaines étant presque uniquement exprimées dans le cerveau et d’autres presque uniquement non exprimées dans le cerveau, et d’autres groupes plus petits appartenant principalement à des tissus spécifiques comme les testicules, comme le paralogue de PrP, PRND, dont le knockout provoque la stérilité masculine .
conclusions
Les protéines à ancrage GPI peuvent avoir à peu près n’importe quelle taille, être exprimées dans à peu près n’importe quel tissu, et apparemment avoir à peu près n’importe quelle fonction, dans la mesure où leurs fonctions sont connues. De nombreuses protéines à ancrage GPI ont des fonctions natives très claires, mais ces fonctions sont diverses et on ne sait pas très bien pourquoi elles nécessitent un ancrage GPI, d’autant plus que beaucoup de ces protéines existent aussi sous des isoformes sans ancrage GPI. En même temps, pour d’autres protéines ancrées à la GPI, y compris la PrP, nous en savons peu sur la fonction native, il est donc difficile de spéculer sur la raison pour laquelle la fonction native nécessite un ancrage à la GPI. Aucune des analyses que j’ai effectuées ou des revues que j’ai lues n’a permis de dégager un principe unificateur quant à la raison de l’existence de ce mécanisme d’ancrage ou à ce qui fait que ces protéines en ont besoin. Il existe un certain nombre d’hypothèses expliquant pourquoi les protéines à ancrage GPI sont uniques, notamment les radeaux lipidiques, les homodimères et l’excrétion. Toutes ces hypothèses peuvent être valables. Mais en fin de compte, la réponse semble peu susceptible d’être un moment eurêka, mais plutôt, comme une grande partie de la biologie, un mélange prosaïque de différentes choses.
Le code R et les fichiers de données brutes pour les analyses de ce post sont ici.