Overview
- Apprendre à interpréter le Bias et la Variance dans un modèle donné.
- Quelle est la différence entre le biais et la variance ?
- Comment réaliser le compromis biais et variance en utilisant le workflow de Machine Learning
Introduction
Parlons du temps. Il ne pleut que si c’est un peu humide et ne pleut pas s’il y a du vent, de la chaleur ou du gel. Dans ce cas, comment former un modèle prédictif et s’assurer qu’il n’y a pas d’erreurs dans la prévision de la météo ? Vous direz peut-être qu’il existe de nombreux algorithmes d’apprentissage parmi lesquels choisir. Ils sont distincts à bien des égards, mais il existe une différence majeure entre ce que nous attendons et ce que le modèle prédit. C’est le concept de compromis de biais et de variance.
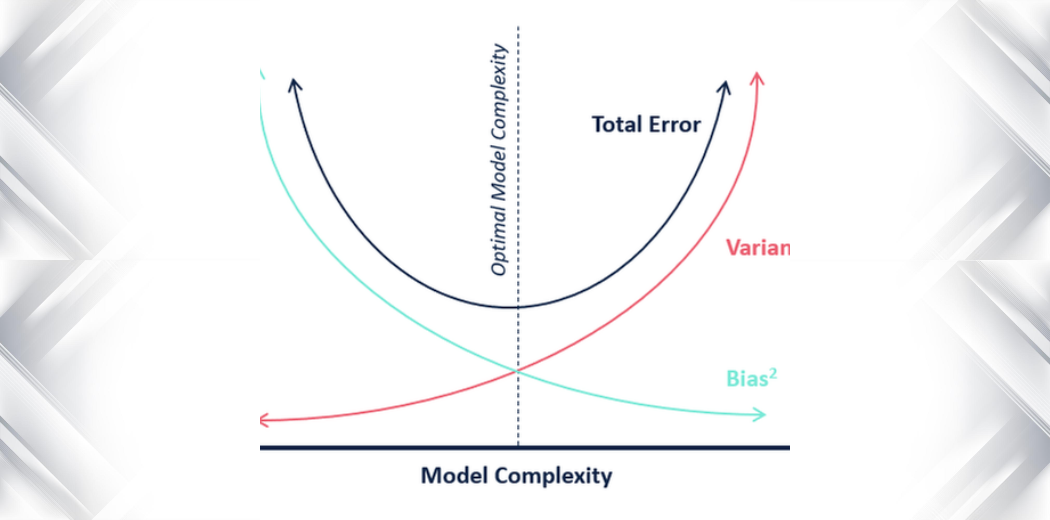
En général, le compromis de biais et de variance est enseigné par des formules mathématiques denses. Mais dans cet article, j’ai tenté d’expliquer le biais et la variance aussi simplement que possible !
Mon objectif sera de vous faire tourner à travers le processus de compréhension de l’énoncé du problème et de s’assurer que vous choisissez le meilleur modèle où les erreurs de biais et de variance sont minimales.
Pour cela, j’ai repris le populaire ensemble de données sur le diabète des Indiens Pima. Ce jeu de données est constitué de mesures diagnostiques de patientes adultes de l’héritage amérindien Pima. Pour cet ensemble de données, nous allons nous concentrer sur la variable « Outcome » – qui indique si le patient est diabétique ou non. De toute évidence, il s’agit d’un problème de classification binaire et nous allons plonger directement dedans et apprendre comment s’y prendre.
Si vous êtes intéressé par ce concept et celui de la science des données et que vous voulez apprendre de manière pratique, référez-vous à notre cours- Introduction à la science des données
Table des matières
- Évaluer un modèle d’apprentissage automatique
- Énoncé du problème et étapes primaires
- Qu’est-ce que le biais ?
- Qu’est-ce que la variance ?
- Compromis biais-variance
Évaluation de votre modèle d’apprentissage automatique
L’objectif principal du modèle d’apprentissage automatique est d’apprendre à partir des données données données et de générer des prédictions basées sur le modèle observé pendant le processus d’apprentissage. Cependant, notre tâche ne s’arrête pas là. Nous devons continuellement apporter des améliorations aux modèles, en fonction du type de résultats qu’ils génèrent. Nous quantifions également les performances du modèle à l’aide de mesures telles que la précision, l’erreur quadratique moyenne (EQM), le score F1, etc. et nous essayons d’améliorer ces mesures. Cela peut souvent devenir délicat lorsque nous devons maintenir la flexibilité du modèle sans compromettre son exactitude.
Un modèle d’apprentissage automatique supervisé vise à s’entraîner sur les variables d’entrée(X) de telle sorte que les valeurs prédites(Y) soient aussi proches que possible des valeurs réelles. Cette différence entre les valeurs réelles et les valeurs prédites est l’erreur et elle est utilisée pour évaluer le modèle. L’erreur pour tout algorithme d’apprentissage automatique supervisé comprend 3 parties :
- Erreur de biais
- Erreur de variance
- Le bruit
Alors que le bruit est l’erreur irréductible que nous ne pouvons pas éliminer, les deux autres c’est-à-dire.c’est-à-dire le biais et la variance sont des erreurs réductibles que nous pouvons tenter de minimiser autant que possible.
Dans les sections suivantes, nous couvrirons l’erreur de biais, l’erreur de variance et le compromis biais-variance qui nous aideront à sélectionner le meilleur modèle. Et ce qui est excitant, c’est que nous couvrirons certaines techniques pour traiter ces erreurs en utilisant un jeu de données d’exemple.
Énoncé du problème et étapes primaires
Comme expliqué précédemment, nous avons repris le jeu de données sur le diabète des Indiens Pima et formé un problème de classification sur celui-ci. Commençons par jauger le jeu de données et observer le type de données auquel nous avons affaire. Nous le ferons en important les bibliothèques nécessaires :
Maintenant, nous allons charger les données dans un cadre de données et observer quelques lignes pour avoir un aperçu des données.
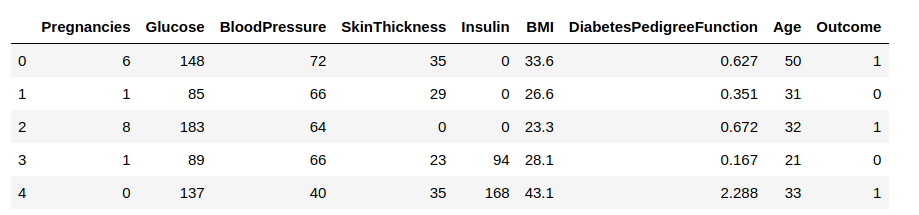
Nous devons prédire la colonne ‘Résultat’. Séparons-la et attribuons-la à une variable cible ‘y’. Le reste du cadre de données sera l’ensemble des variables d’entrée X.
Maintenant, mettons à l’échelle les variables prédicteurs, puis séparons les données de formation et de test.
Puisque les résultats sont classés sous une forme binaire, nous utiliserons le classificateur K plus proche voisin(Knn) le plus simple pour classer si le patient est diabétique ou non.
Mais comment décider de la valeur de ‘k’ ?
- Peut-être devrions-nous utiliser k = 1 afin d’obtenir de très bons résultats sur nos données d’entraînement ? Cela pourrait fonctionner, mais nous ne pouvons pas garantir que le modèle sera tout aussi performant sur nos données de test car il peut devenir trop spécifique
- Que diriez-vous d’utiliser une valeur élevée de k, disons comme k = 100 afin que nous puissions considérer un grand nombre de points les plus proches pour tenir compte également des points éloignés ? Cependant, ce type de modèle sera trop générique et nous ne pourrons pas être sûrs qu’il a considéré correctement toutes les caractéristiques contributives possibles.
Prenons quelques valeurs possibles de k et ajustons le modèle sur les données d’entraînement pour toutes ces valeurs. Nous allons également calculer le score de formation et le score de test pour toutes ces valeurs.
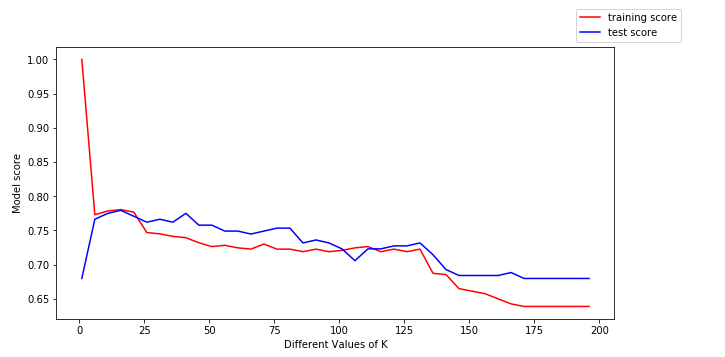
Pour en tirer plus d’enseignements, traçons les données de formation(en rouge) et les données de test(en bleu).
Pour calculer les scores pour une valeur particulière de k,
![]()
Nous pouvons tirer les conclusions suivantes du tracé ci-dessus :
- Pour de faibles valeurs de k, le score de formation est élevé, tandis que le score de test est faible
- A mesure que la valeur de k augmente, le score de test commence à augmenter et le score de formation à diminuer.
- Cependant, à une certaine valeur de k, le score d’entraînement et le score de test sont proches l’un de l’autre.
C’est là que le biais et la variance entrent en jeu.
Qu’est-ce que le biais ?
En termes les plus simples, le biais est la différence entre la valeur prédite et la valeur attendue. Pour expliquer davantage, le modèle fait certaines hypothèses lorsqu’il s’entraîne sur les données fournies. Lorsqu’il est présenté aux données de test/validation, ces hypothèses ne sont pas toujours correctes.
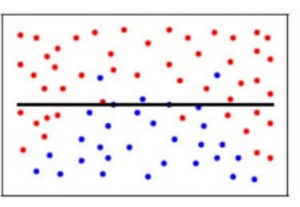
Dans notre modèle, si nous utilisons un grand nombre de plus proches voisins, le modèle peut totalement décider que certains paramètres ne sont pas du tout importants. Par exemple, il peut simplement considérer que le taux de glucose et la pression artérielle décident si le patient est diabétique. Ce modèle ferait des hypothèses très fortes sur le fait que les autres paramètres n’affectent pas le résultat. Vous pouvez également le considérer comme un modèle prédisant une relation simple alors que les points de données indiquent clairement une relation plus complexe :
Mathématiquement, que les variables d’entrée soient X et une variable cible Y. Nous cartographions la relation entre les deux en utilisant une fonction f.
C’est pourquoi,
Y = f(X) + e
Dans ce cas, ‘e’ est l’erreur qui est normalement distribuée. L’objectif de notre modèle f'(x) est de prédire des valeurs aussi proches que possible de f(x). Ici, le biais du modèle est :
Bias = E
Comme je l’ai expliqué plus haut, lorsque le modèle fait les généralisations c’est-à-dire lorsqu’il y a une erreur de biais élevée, il en résulte un modèle très simpliste qui ne prend pas très bien en compte les variations. Comme il n’apprend pas très bien les données d’apprentissage, on parle d’Underfitting.
Qu’est-ce qu’une variance ?
Contrairement au biais, la Variance est lorsque le modèle prend en compte les fluctuations des données c’est-à-dire le bruit également. Donc, que se passe-t-il lorsque notre modèle a une variance élevée ?
Le modèle va quand même considérer la variance comme quelque chose à apprendre. C’est-à-dire que le modèle apprend trop des données d’apprentissage, à tel point que lorsqu’il est confronté à de nouvelles données (de test), il est incapable de prédire avec précision en se basant sur celles-ci.
Mathématiquement, l’erreur de variance du modèle est :
Variance-E^2
Puisque dans le cas d’une variance élevée, le modèle apprend trop des données d’apprentissage, on parle d’overfitting.
Dans le contexte de nos données, si nous utilisons très peu de voisins les plus proches, cela revient à dire que si le nombre de grossesses est supérieur à 3, le taux de glucose est supérieur à 78, la PA diastolique est inférieure à 98, l’épaisseur de la peau est inférieure à 23 mm et ainsi de suite pour chaque caractéristique….. décider que le patient est diabétique. Tous les autres patients qui ne répondent pas aux critères ci-dessus ne sont pas diabétiques. Bien que cela puisse être vrai pour un patient particulier de l’ensemble d’apprentissage, que se passe-t-il si ces paramètres sont des valeurs aberrantes ou ont même été enregistrés de manière incorrecte ? Il est clair qu’un tel modèle pourrait s’avérer très coûteux !
En outre, ce modèle aurait une erreur de variance élevée parce que les prédictions du patient étant diabétique ou non varient grandement avec le type de données de formation que nous lui fournissons. Ainsi, même en changeant le taux de glucose à 75, le modèle prédit que le patient n’est pas diabétique.
Pour faire plus simple, le modèle prédit des relations très complexes entre le résultat et les caractéristiques d’entrée alors qu’une équation quadratique aurait suffi. Voilà à quoi ressemblerait un modèle de classification lorsqu’il y a une erreur de variance élevée/quand il y a un surajustement :
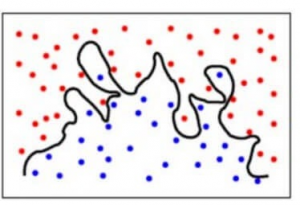
En résumé,
- Un modèle avec une erreur de biais élevée sous-adapte les données et fait des hypothèses très simplistes sur celles-ci
- Un modèle avec une erreur de variance élevée suradapte les données et apprend trop de celles-ci
- Un bon modèle est celui où les erreurs de biais et de variance sont équilibrées
Compromis biais-variance
Comment relions-nous les concepts ci-dessus à notre modèle Knn de tout à l’heure ? Découvrons-le !
Dans notre modèle, disons, pour, k = 1, le point le plus proche du point de données en question sera considéré. Ici, la prédiction pourrait être précise pour ce point de données particulier, donc l’erreur de biais sera moindre.
Par contre, l’erreur de variance sera élevée puisque seul le point le plus proche est considéré et cela ne tient pas compte des autres points possibles. A quel scénario pensez-vous que cela correspond ? Oui, vous pensez bien, cela signifie que notre modèle est surajusté.
D’autre part, pour des valeurs plus élevées de k, beaucoup plus de points plus proches du point de données en question seront considérés. Cela entraînerait une erreur de biais plus élevée et un sous-ajustement puisque de nombreux points plus proches du point de données sont considérés et qu’il ne peut donc pas apprendre les spécificités de l’ensemble d’apprentissage. Cependant, nous pouvons tenir compte d’une erreur de variance plus faible pour l’ensemble de test qui a des valeurs inconnues.
Pour atteindre un équilibre entre l’erreur de biais et l’erreur de variance, nous avons besoin d’une valeur de k telle que le modèle n’apprenne pas du bruit (surajustement sur les données) ni ne fasse des hypothèses radicales sur les données(sous-ajustement sur les données). Pour rester plus simple, un modèle équilibré ressemblerait à ceci:
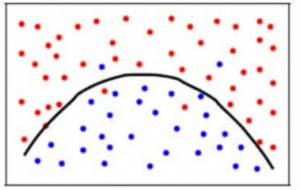
Bien que certains points soient classés de manière incorrecte, le modèle s’adapte généralement à la plupart des points de données de manière précise. L’équilibre entre l’erreur de biais et l’erreur de variance est le compromis biais-variance.
Le diagramme de l’œil de taureau suivant explique mieux le compromis:
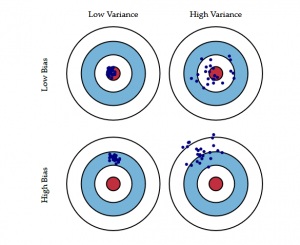
Le centre c’est-à-dire l’œil de taureau est le résultat du modèle que nous voulons atteindre qui prédit parfaitement toutes les valeurs correctement. Au fur et à mesure que nous nous éloignons de l’œil de bœuf, notre modèle commence à faire de plus en plus de prédictions erronées.
Un modèle avec un biais faible et une variance élevée prédit des points qui sont autour du centre en général, mais assez éloignés les uns des autres. Un modèle avec un biais élevé et une faible variance est assez loin de l’œil du taureau, mais comme la variance est faible, les points prédits sont plus proches les uns des autres.
En termes de complexité du modèle, nous pouvons utiliser le diagramme suivant pour décider de la complexité optimale de notre modèle.
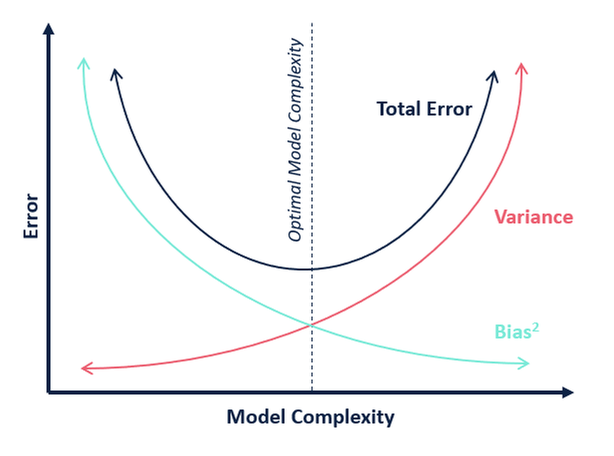
Donc, selon vous, quelle est la valeur optimale de k ?
D’après l’explication ci-dessus, nous pouvons conclure que le k pour lequel
- le score de test est le plus élevé, et
- le score de test et le score d’entraînement sont proches l’un de l’autre
est la valeur optimale de k. Ainsi, même si nous faisons un compromis sur un score d’apprentissage plus faible, nous obtenons toujours un score élevé pour nos données de test, ce qui est plus crucial – les données de test sont après tout des données inconnues.
Faisons un tableau pour différentes valeurs de k afin de prouver davantage ceci :
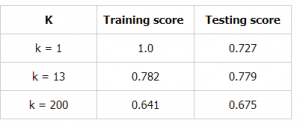
Conclusion
Pour résumer, dans cet article, nous avons appris qu’un modèle idéal serait un modèle où l’erreur de biais et l’erreur de variance sont toutes deux faibles. Cependant, nous devrions toujours viser un modèle où le score du modèle pour les données d’apprentissage est aussi proche que possible du score du modèle pour les données de test.
C’est là que nous avons compris comment choisir un modèle qui n’est pas trop complexe (variance élevée et faible biais), ce qui conduirait à un surajustement et ni trop simple(Biais élevé et faible variance), ce qui conduirait à un sous-ajustement.
Le biais et la variance jouent un rôle important dans le choix du modèle prédictif à utiliser. J’espère que cet article a bien expliqué le concept.