Il est crucial de comprendre les bases de la gestion des schémas pour construire et maintenir une base de données PostgreSQL efficace. Dans cet article, nous allons examiner la façon traditionnelle de gérer un schéma Postgres et une nouvelle façon plus efficace de le faire visuellement, sans avoir à écrire la moindre ligne de code.
Qu’est-ce qu’un schéma PostgreSQL ?
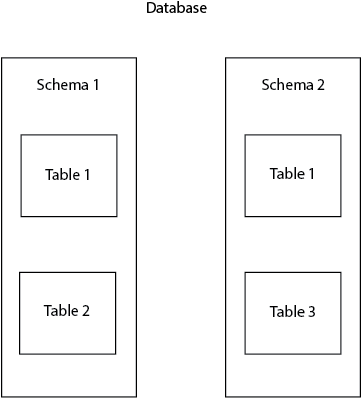
D’abord, pour poser les bases de l’article, mettons au clair une certaine terminologie. Dans Postgres, le schéma est également appelé espace de noms. L’espace de noms peut être associé à un nom de famille. Il est utilisé pour identifier et différencier certains objets de la base de données (tables, vues, colonnes, etc.). Il n’est pas permis de créer deux tables portant le même nom dans un même schéma, mais vous pouvez le faire dans deux schémas différents. Par exemple, nous pouvons avoir deux tables toutes deux nommées table1 présentes dans les schémas public et postgres.
Pourquoi utiliser des schémas ?
Les schémas sont très utiles pour organiser les objets de la base de données en groupes logiques et éviter les collisions de noms. En plus de cela, les schémas sont souvent utilisés pour permettre à différents utilisateurs de travailler avec la base de données sans interférer les uns avec les autres. Un exemple courant est lorsque chaque utilisateur de la base de données travaille sur son propre schéma, sans interférer avec les autres utilisateurs et en évitant les conflits.
La manière classique de gérer les schémas PostgreSQL
Toutes les requêtes ci-dessous seront exécutées depuis l’intérieur du shell PostgreSQL.
Création d’un schéma
Lorsque vous créez une nouvelle base de données dans Postgres, le schéma par défaut est public. Un nouveau schéma peut être créé en exécutant la requête suivante :
CREATE SCHEMA schema_1;
Avant d’y ajouter quelques tables, Je vais expliquer deux concepts importants : les noms qualifiés et non qualifiés.
-
Un nom qualifié est le nom du schéma et le nom de la table séparés par un point. Cela va spécifier le schéma dans lequel nous voulons créer notre table :
.
xxxxxxxxxx
CREATE TABLE schema_name.table_name (...);
-
Un nom non qualifié consiste uniquement en un nom de table. Cela créera la table dans la base de données sélectionnée qui est publique par défaut. Cela peut être modifié via le search_path, mais nous le détaillerons plus tard. Un exemple de nom non qualifié est :
.
xxxxxxxxxx
CREATE TABLE table_name (...);
Les colonnes des tables seront définies à l’intérieur des parenthèses des requêtes ci-dessus (…).
Pour créer une nouvelle table dans notre nouveau schéma, nous allons exécuter :
.
xxxxxxxxxx
CREATE TABLE schema_1.persons (name text, age int);
Pour abandonner le schéma, nous avons deux possibilités. Si le schéma est vide (ne contient aucune table, vue ou autre objet), nous pouvons exécuter :
.
xxxxxxxxxx
DROP SCHEMA schema_1;
Si le schéma contient des objets de base de données, nous insérerons la commande en cascade :
.
xxxxxxxxxx
DROP SCHEMA schema_1 CASCADE;
En PostgreSQL, il est également possible de créer un schéma appartenant à un autre utilisateur avec :
xxxxxxxxxx
CREATE SCHEMA schema_name AUTHORIZATION username;
Search Path
Lorsqu’on exécute une commande avec un nom non qualifié, Postgres suit un chemin de recherche pour déterminer les schémas à utiliser. Par défaut, le chemin de recherche est défini sur le schéma public. Pour le visualiser, exécutez :
.
xxxxxxxxxx
SHOW search_path;
Si rien n’a été changé dans votre base de données, cette requête devrait apporter le résultat suivant :
xxxxxxxxxx
search_path
--------------
"$user",public
Le chemin de recherche peut être modifié pour que le système choisisse automatiquement un autre schéma si vous utilisez un nom non qualifié. Le premier schéma dans le chemin de recherche est appelé schéma courant. Par exemple, je vais définir le schéma_1 comme le schéma courant :
.
xxxxxxxxxx
SET search_path TO schema_1,public;
La requête suivante utilisera un nom non qualifié pour créer une table. Cela la créera automatiquement dans le schéma_1 :
.
xxxxxxxxxx
CREATE TABLE address (city text, street text, number int);
La nouvelle façon : Gérez sans le code !
Il existe une façon plus simple d’effectuer toutes les tâches de gestion des schémas, sans avoir à écrire la moindre ligne de code. En utilisant DbSchema, vous pouvez exécuter toutes les requêtes ci-dessus depuis une interface graphique intuitive, en quelques clics seulement. La connexion à la base de données ne prendra que quelques secondes. Dès le début, vous pouvez sélectionner sur quel schéma travailler.
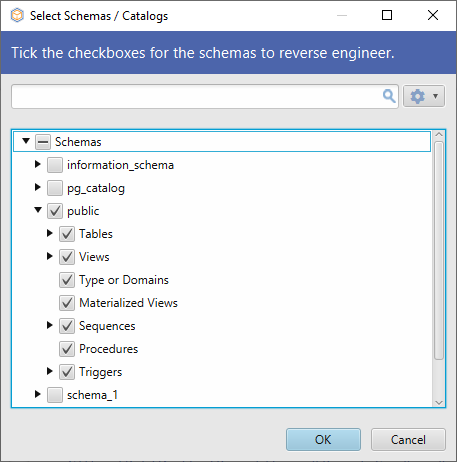
Le ou les schémas sélectionnés seront rétro-ingénierie par DbSchema et montrés dans la mise en page.
Pour créer un nouveau schéma, il suffit de faire un clic droit sur le dossier des schémas dans le menu de gauche et de sélectionner Créer un schéma.
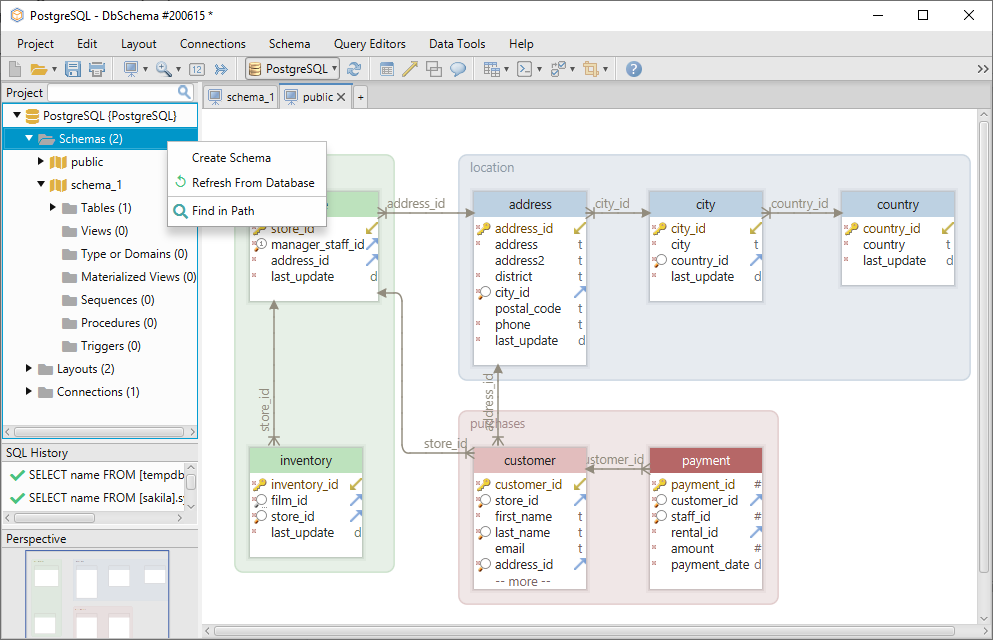
Pour créer une nouvelle table dans le schéma, il suffit de faire un clic droit sur le layout et de sélectionner Créer une table.
Le schéma peut être déposé en cliquant avec le bouton droit de la souris sur son nom dans le menu de gauche.
Pour ajouter un autre schéma depuis la base de données, choisissez Rafraîchir depuis la base de données.
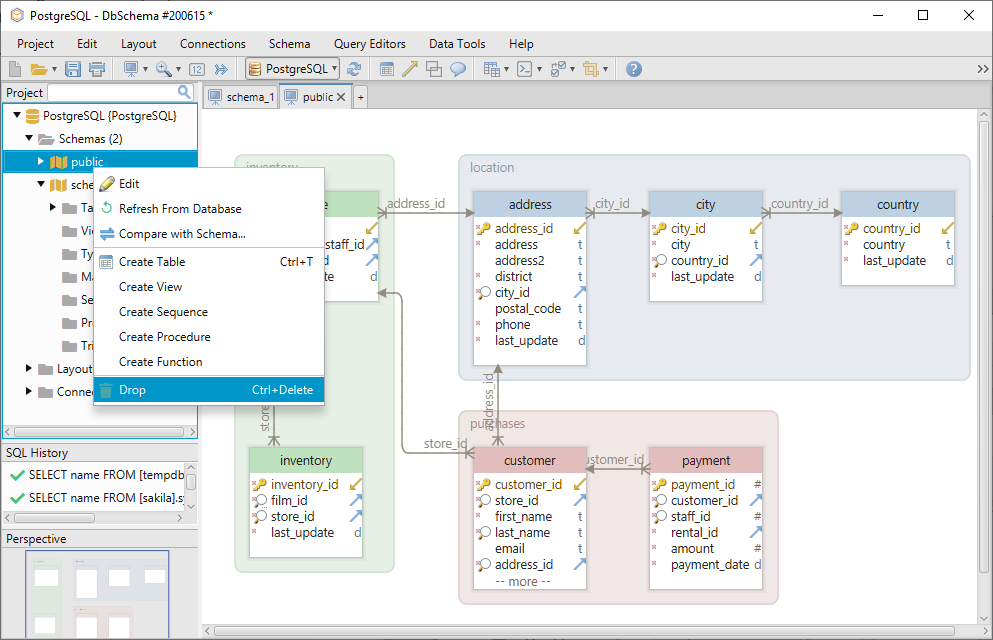
En utilisant DbSchema, vous n’aurez pas besoin d’utiliser la syntaxe show_path car vous pouvez créer les tables directement dans le layout. Un layout peut être comparé à une planche à dessin sur laquelle vous pouvez ajouter les tables et les modifier. Chaque layout est associé à un schéma, donc si vous êtes sur le layout schema_1, les tables y seront automatiquement créées.
Travail hors ligne
DbSchema stocke une image locale du schéma dans un fichier de projet local. Cela signifie que le fichier de projet peut être ouvert sans connectivité à la base de données (hors ligne). En mode hors ligne, vous pouvez effectuer toutes les actions présentées ci-dessus et plus encore, mais sans données. Après la reconnexion à la base de données, vous pouvez comparer le fichier de projet avec la base de données et choisir les actions à conserver ou à abandonner.
La même chose peut être faite entre deux versions différentes du même fichier de projet. Par exemple, si vous travaillez dans une équipe, il se peut qu’il y ait plusieurs schémas (production, test, développement), chacun ayant son propre fichier de projet. Si une modification apparaît dans le développement et que vous souhaitez l’appliquer sur les deux autres schémas, il vous suffit de comparer et de synchroniser les deux fichiers de projet.
Conclusion
La compréhension des concepts énumérés ci-dessus vous aidera à gérer facilement vos schémas PostgreSQL. L’utilisation d’un concepteur visuel tel que DbSchema facilitera encore plus votre travail en vous permettant de tout faire visuellement, sans avoir à écrire une seule ligne de code.