Le chiffrement des données au repos est indispensable pour toute société Internet moderne. Cependant, de nombreuses entreprises ne chiffrent pas leurs disques, car elles craignent la pénalité de performance potentielle causée par les frais généraux de chiffrement.
Le chiffrement des données au repos est vital pour Cloudflare avec plus de 200 centres de données à travers le monde. Dans ce post, nous allons étudier les performances du cryptage de disque sur Linux et expliquer comment nous l’avons rendu au moins deux fois plus rapide pour nous et nos clients !
Cryptage des données au repos
Lorsqu’il s’agit de crypter des données au repos, il existe plusieurs façons de le mettre en œuvre sur un système d’exploitation (OS) moderne. Les techniques disponibles sont étroitement couplées à une pile de stockage typique d’un OS. Une version simplifiée de la pile de stockage et des solutions de cryptage se trouve sur le diagramme ci-dessous :
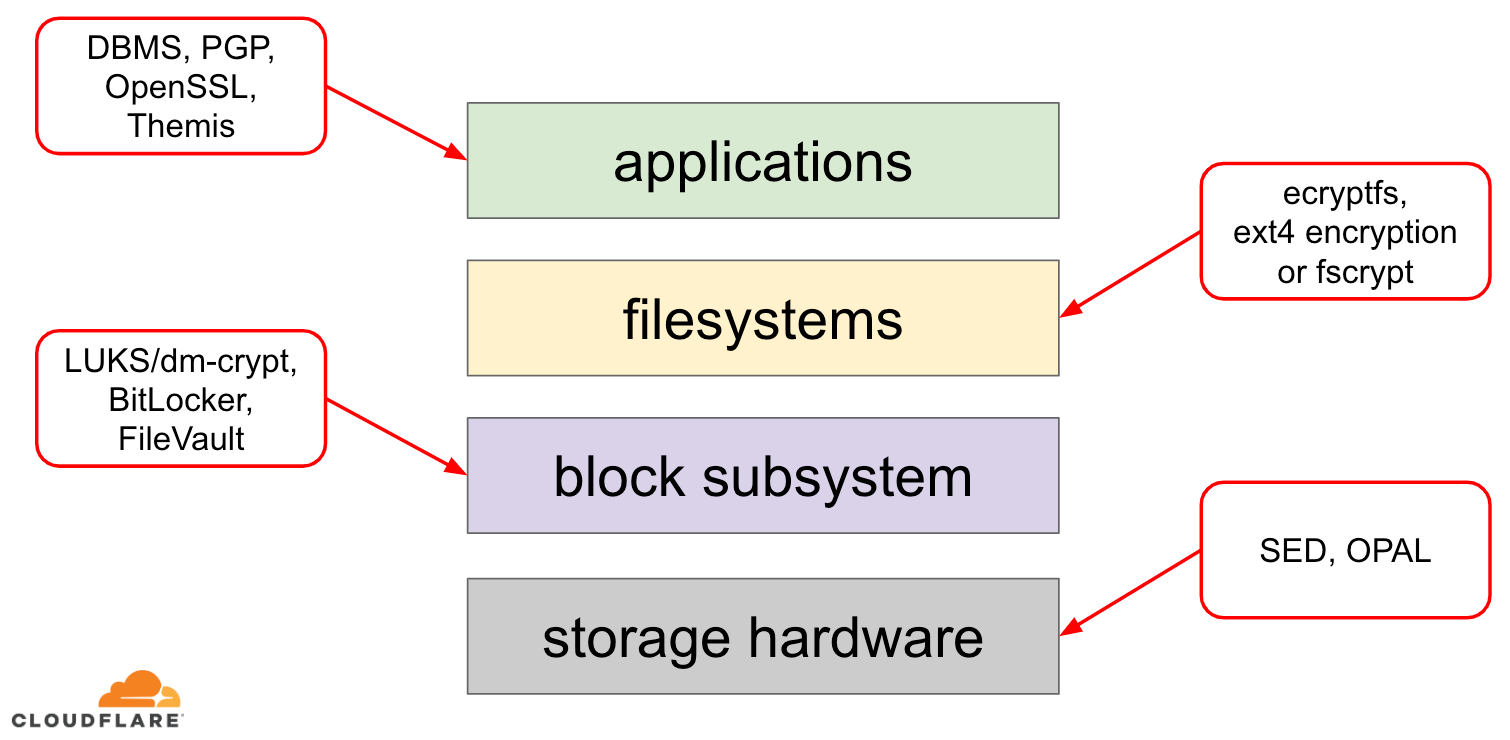
Au sommet de la pile se trouvent les applications, qui lisent et écrivent des données dans des fichiers (ou flux). Le système de fichiers du noyau du système d’exploitation garde la trace de quels blocs du périphérique de bloc sous-jacent appartiennent à quels fichiers et traduit ces lectures et écritures de fichiers en lectures et écritures de blocs, cependant les spécificités matérielles du périphérique de stockage sous-jacent sont abstraites du système de fichiers. Enfin, le sous-système de bloc transmet effectivement les lectures et les écritures de bloc au matériel sous-jacent en utilisant des pilotes de périphérique appropriés.
Le concept de la pile de stockage est en fait similaire au modèle OSI de réseau bien connu, où chaque couche a une vue de plus haut niveau de l’information et les détails de mise en œuvre des couches inférieures sont abstraits des couches supérieures. Et, de manière similaire au modèle OSI, on peut appliquer le cryptage à différentes couches (pensez à TLS vs IPsec ou à un VPN).
Pour les données au repos, nous pouvons appliquer le cryptage soit aux couches de blocs (soit dans le matériel, soit dans le logiciel), soit au niveau des fichiers (soit directement dans les applications, soit dans le système de fichiers).
Cryptage de blocs vs cryptage de fichiers
Généralement, plus on applique le cryptage à un niveau élevé de la pile, plus on a de flexibilité. Avec le cryptage au niveau de l’application, les mainteneurs de l’application peuvent appliquer n’importe quel code de cryptage qu’ils veulent à n’importe quelle donnée particulière dont ils ont besoin. L’inconvénient de cette approche est qu’ils doivent l’implémenter eux-mêmes et que le cryptage en général n’est pas très convivial pour les développeurs : il faut connaître les tenants et aboutissants d’un algorithme cryptographique spécifique, générer correctement les clés, les nonces, les IV, etc. En outre, le chiffrement au niveau de l’application ne tire pas parti de la mise en cache au niveau du système d’exploitation et du cache de page Linux en particulier : chaque fois que l’application a besoin d’utiliser les données, elle doit soit les déchiffrer à nouveau, ce qui gaspille des cycles CPU, soit mettre en œuvre son propre « cache » déchiffré, ce qui introduit davantage de complexité dans le code.
Le chiffrement au niveau du système de fichiers rend le chiffrement des données transparent pour les applications, car le système de fichiers lui-même chiffre les données avant de les transmettre au sous-système de blocs, de sorte que les fichiers sont chiffrés indépendamment du fait que l’application dispose d’un support cryptographique ou non. De plus, les systèmes de fichiers peuvent être configurés pour crypter uniquement un répertoire particulier ou avoir des clés différentes pour différents fichiers. Cette souplesse a toutefois pour contrepartie une configuration plus complexe. Le cryptage des systèmes de fichiers est également considéré comme moins sûr que le cryptage des périphériques de bloc, car seul le contenu des fichiers est crypté. Les fichiers ont également des métadonnées associées, comme la taille du fichier, le nombre de fichiers, la disposition de l’arborescence des répertoires, etc. qui restent visibles pour un adversaire potentiel.
Le chiffrement en bas de la couche de blocs (souvent appelé chiffrement du disque ou chiffrement complet du disque) rend également le chiffrement des données transparent pour les applications et même les systèmes de fichiers entiers. Contrairement au cryptage au niveau du système de fichiers, il crypte toutes les données du disque, y compris les métadonnées des fichiers et même l’espace libre. Il est cependant moins flexible – on ne peut chiffrer que l’ensemble du disque avec une seule clé, il n’y a donc pas de configuration par répertoire, par fichier ou par utilisateur. Du point de vue de la cryptographie, tous les algorithmes cryptographiques ne peuvent pas être utilisés car la couche de blocs n’a plus une vue d’ensemble de haut niveau des données, elle doit donc traiter chaque bloc indépendamment. La plupart des algorithmes courants nécessitent une sorte de chaînage de blocs pour être sécurisés, et ne sont donc pas applicables au cryptage de disque. Au lieu de cela, des modes spéciaux ont été développés juste pour ce cas d’utilisation spécifique.
Alors quelle couche choisir ? Comme toujours, cela dépend… Le chiffrement au niveau de l’application et du système de fichiers est généralement le choix préféré pour les systèmes clients en raison de la flexibilité. Par exemple, chaque utilisateur sur un bureau multi-utilisateurs peut vouloir chiffrer son répertoire personnel avec une clé qui lui appartient et laisser certains répertoires partagés non chiffrés. Au contraire, sur les systèmes serveurs, gérés par des sociétés SaaS/PaaS/IaaS (y compris Cloudflare), le choix préféré est la simplicité de configuration et la sécurité – avec le chiffrement complet du disque activé, toutes les données de n’importe quelle application sont automatiquement chiffrées, sans exception ni remplacement. Nous pensons que toutes les données doivent être protégées sans les trier en seaux « importants » vs « pas importants », donc la flexibilité sélective que les couches supérieures fournissent n’est pas nécessaire.
Chiffrement de disque matériel vs logiciel
Lorsque l’on chiffre des données au niveau de la couche bloc, il est possible de le faire directement dans le matériel de stockage, si le matériel le supporte. En procédant ainsi, on obtient généralement de meilleures performances en lecture/écriture et on consomme moins de ressources de l’hôte. Cependant, comme la plupart des microprogrammes matériels sont propriétaires, ils ne reçoivent pas autant d’attention et d’examen de la part de la communauté de la sécurité. Dans le passé, cela a conduit à des failles dans certaines implémentations du chiffrement matériel des disques, qui ont rendu tout le modèle de sécurité inutile. Microsoft, par exemple, a commencé à préférer depuis lors le chiffrement logiciel des disques.
Nous ne voulions pas faire courir le risque à nos données et à celles de nos clients d’utiliser des solutions potentiellement peu sûres et nous croyons fermement à l’open-source. C’est pourquoi nous nous appuyons uniquement sur le chiffrement logiciel des disques dans le noyau Linux, qui est ouvert et a été audité par de nombreux professionnels de la sécurité à travers le monde.
Performances du chiffrement des disques Linux
Nous visons non seulement à économiser les coûts de bande passante pour nos clients, mais aussi à fournir du contenu aux internautes aussi rapidement que possible.
À un moment donné, nous avons remarqué que nos disques n’étaient pas aussi rapides que nous le souhaiterions. Un certain profilage ainsi qu’un rapide test A/B ont pointé vers le cryptage des disques Linux. Parce que ne pas crypter les données (même si elles sont censées être un cache Internet public) n’est pas une option durable, nous avons décidé d’examiner de plus près les performances de cryptage de disque de Linux.
Device mapper et dm-crypt
Linux met en œuvre un cryptage de disque transparent via un module dm-crypt et dm-crypt lui-même fait partie du cadre du noyau device mapper. En un mot, le mappeur de périphériques permet de pré/post-traiter les demandes d’E/S lorsqu’elles voyagent entre le système de fichiers et le périphérique de bloc sous-jacent.
dm-crypt en particulier chiffre les demandes d’E/S « d’écriture » avant de les envoyer plus bas dans la pile vers le périphérique de bloc réel et déchiffre les demandes d’E/S « de lecture » avant de les envoyer vers le haut au pilote du système de fichiers. Simple et facile ! Ou l’est-il ?
Configuration du benchmarking
Pour mémoire, les chiffres de ce post ont été obtenus en exécutant les commandes spécifiées sur un serveur Cloudflare G9 inactif hors production. Cependant, la configuration devrait être facilement reproductible sur n’importe quel ordinateur portable x86 moderne.
Généralement, l’évaluation comparative de tout ce qui entoure une pile de stockage est difficile en raison du bruit introduit par le matériel de stockage lui-même. Tous les disques ne sont pas créés égaux, donc pour les besoins de ce post, nous utiliserons les disques les plus rapides disponibles là-bas – c’est-à-dire aucun disque.
A la place, Linux a une option pour émuler un disque directement dans la RAM. Comme la RAM est beaucoup plus rapide que n’importe quel stockage persistant, cela devrait introduire peu de biais dans nos résultats.
La commande suivante crée un ramdisk de 4 Go :
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Maintenant, nous pouvons mettre en place une instance dm-crypt au-dessus de celui-ci permettant ainsi le chiffrement du disque. Tout d’abord, nous devons générer la clé de chiffrement du disque, « formater » le disque et spécifier un mot de passe pour déverrouiller la clé nouvellement générée.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:Ceux qui sont familiers avec LUKS/dm-crypt ont pu remarquer que nous avons utilisé un en-tête détaché LUKS ici. Normalement, LUKS stocke la clé de chiffrement de disque chiffrée par mot de passe sur le même disque que les données, mais puisque nous voulons comparer les performances de lecture/écriture entre les périphériques chiffrés et non chiffrés, nous pourrions accidentellement écraser la clé chiffrée lors de notre benchmarking ultérieur. Garder la clé cryptée dans un fichier séparé évite ce problème pour les besoins de ce post.
Maintenant, nous pouvons réellement « déverrouiller » le périphérique crypté pour nos tests :
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0À ce stade, nous pouvons maintenant comparer les performances du ramdisk crypté par rapport au ramdisk non crypté : si nous lisons/écrivons des données sur /dev/ram0, elles seront stockées en texte clair. De même, si nous lisons/écrivons des données sur /dev/mapper/encrypted-ram0, elles seront décryptées/encryptées en chemin par dm-crypt et stockées en texte chiffré.
Il convient de noter que nous ne créons pas de système de fichiers au-dessus de nos périphériques de bloc pour éviter de biaiser les résultats avec une surcharge de système de fichiers.
Mesurer le débit
Lorsqu’il s’agit de tester/benchmarker le stockage, Flexible I/O tester est la solution habituelle. Simulons une simple charge séquentielle de lecture/écriture avec une taille de bloc de 4K sur le ramdisk sans cryptage:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%La commande ci-dessus s’exécutera pendant un long moment, donc nous l’arrêtons juste après un moment. Comme nous pouvons le voir dans les statistiques, nous sommes capables de lire et d’écrire à peu près avec le même débit autour de 1126 MB/s. Répétons le test avec le ramdisk crypté:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecWhoa, c’est une chute ! Nous obtenons seulement ~147 MB/s maintenant, ce qui est plus de 7 fois plus lent ! Et ceci sur une machine totalement inactive !
Peut-être que la crypto est juste lente
La première chose que nous avons considérée est de nous assurer que nous utilisons la crypto la plus rapide. cryptsetup nous permet de comparer toutes les implémentations de crypto disponibles sur le système pour sélectionner la meilleure:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/AIl semble que aes-xts avec une clé de chiffrement des données de 256 bits soit la plus rapide ici. Mais laquelle utilisons-nous réellement pour notre ramdisk crypté ?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0Nous utilisons effectivement aes-xts avec une clé de cryptage de données de 256 bits (comptez tous les zéros commodément masqués par l’outil dmsetup – si vous voulez voir les octets réels, ajoutez l’option --showkeys à la commande ci-dessus). Les chiffres ne s’additionnent cependant pas : cryptsetup benchmark nous dit ci-dessus de ne pas nous fier aux résultats, car « Les tests sont approximatifs en utilisant uniquement la mémoire (pas d’IO de stockage) », mais c’est exactement la façon dont nous avons configuré notre expérience en utilisant le ramdisk. Dans un cas un peu plus défavorable (en supposant que nous lisons toutes les données et que nous les cryptons/décryptons séquentiellement sans parallélisme) en faisant un calcul à rebours, nous devrions obtenir environ (1126 * 1823) / (1126 + 1823) =~696 MB/s, ce qui est encore assez loin des 147 * 2 = 294 MB/s réels (total pour les lectures et les écritures).
dm-crypt performance flags
En lisant la page de manuel de cryptsetup, nous avons remarqué qu’il a deux options préfixées par --perf-, qui sont probablement liées au réglage des performances. La première est --perf-same_cpu_crypt avec une description plutôt cryptique:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Donc nous activons l’option
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Note : selon la dernière page de manuel, il y a aussi une commande cryptsetup refresh, qui peut être utilisée pour activer ces options en direct sans avoir à « fermer » et « rouvrir » le périphérique crypté. Notre cryptsetup ne le supportait cependant pas encore.
Vérifier si l’option a vraiment été activée:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptOui, nous pouvons maintenant voir same_cpu_crypt dans la sortie, ce qui est ce que nous voulions. Relançons le benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, maintenant c’est ~136 MB/s ce qui est légèrement pire qu’avant, donc pas bon. Qu’en est-il de la deuxième option --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Peut-être que nous sommes dans la « certaine situation » ici, alors essayons-la:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusEt maintenant le benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, ce qui est un peu mieux, mais toujours pas bon…
Demander à la communauté
Etant désespérés, nous avons décidé de chercher du soutien sur Internet et avons posté nos résultats sur la liste de diffusion dm-crypt, mais la réponse que nous avons reçue n’était pas très encourageante:
Si les chiffres vous dérangent, alors c’est un manque de compréhension de votre part. Vous n’êtes probablement pas conscient que le cryptage est une opération lourde…
Nous avons décidé de faire une recherche scientifique sur ce sujet en tapant « le cryptage est-il cher » dans Google Search et l’un des premiers résultats, qui contient effectivement des mesures significatives, est… notre propre post sur le coût du cryptage, mais dans le contexte de TLS ! Il s’agit d’une lecture fascinante en soi, mais l’essentiel est le suivant : le cryptage moderne sur du matériel moderne est très bon marché, même à l’échelle de Cloudflare (qui effectue des millions de requêtes HTTP cryptées par seconde). En fait, c’est tellement bon marché que Cloudflare a été le premier fournisseur à offrir gratuitement SSL/TLS pour tout le monde.
Digging into the source code
En essayant d’utiliser les options dm-crypt personnalisées décrites ci-dessus, nous étions curieux de savoir pourquoi elles existent en premier lieu et ce qu’est ce « délestage ». À l’origine, nous nous attendions à ce que dm-crypt soit un simple « proxy », qui se contente de crypter/décrypter les données lorsqu’elles circulent dans la pile. Il s’avère que dm-crypt fait plus que simplement crypter les tampons de mémoire et un diagramme (simplifié) du chemin de traverse IO est présenté ci-dessous:

Lorsque le système de fichiers émet une demande d’écriture, dm-crypt ne la traite pas immédiatement – au lieu de cela, il la place dans une file de travail nommée « kcryptd ». En un mot, une file d’attente de travail du noyau ne fait que planifier un certain travail (le cryptage dans ce cas) pour qu’il soit exécuté à un moment ultérieur, quand c’est plus pratique. Quand « le moment » arrive, dm-crypt envoie la requête à l’API Crypto de Linux pour le cryptage réel. Cependant, l’API Linux Crypto moderne est également asynchrone, donc selon l’implémentation particulière que votre système utilisera, il est fort probable qu’elle ne sera pas traitée immédiatement, mais remise en file d’attente pour « un moment ultérieur ». Lorsque Linux Crypto API fera finalement le cryptage, dm-crypt peut essayer de trier les demandes d’écriture en attente en mettant chaque demande dans un arbre rouge-noir. Ensuite, un thread de noyau séparé, encore une fois à « un moment ultérieur », prend effectivement toutes les demandes d’E/S dans l’arbre et les envoie vers le bas de la pile.
Maintenant pour les demandes de lecture : cette fois, nous devons d’abord obtenir les données cryptées du matériel, mais dm-crypt ne demande pas simplement le pilote pour les données, mais met la demande en file d’attente dans une file de travail différente nommée « kcryptd_io ». Un peu plus tard, lorsque nous aurons réellement les données cryptées, nous les programmerons pour le décryptage en utilisant la file d’attente « kcryptd » maintenant familière. « kcryptd » enverra la demande à l’API Linux Crypto, qui peut décrypter les données de manière asynchrone également.
Pour être juste, la demande ne traverse pas toujours toutes ces files d’attente, mais la partie importante ici est que les demandes d’écriture peuvent être mises en file d’attente jusqu’à 4 fois dans dm-crypt et les demandes de lecture jusqu’à 3 fois. À ce stade, nous nous demandions si toute cette mise en file d’attente supplémentaire pouvait causer des problèmes de performance. Par exemple, il existe une belle présentation de Google sur la relation entre la mise en file d’attente et la latence de queue. Un élément clé à retenir de la présentation est :
Une quantité significative de latence de queue est due aux effets de file d’attente
Alors, pourquoi toutes ces files d’attente sont là et pouvons-nous les supprimer ?
Archéologie Git
Personne n’écrit de code plus complexe juste pour le plaisir, surtout pour le noyau de l’OS. Donc toutes ces files d’attente doivent avoir été mises là pour une raison. Heureusement, le source du noyau Linux est géré par git, donc nous pouvons essayer de retracer les changements et les décisions autour d’eux.
La file d’attente de travail « kcryptd » était dans le source depuis le début de l’historique disponible avec le commentaire suivant:
Nécessaire parce qu’il serait très imprudent de faire le décryptage dans un contexte d’interruption, donc les bios qui reviennent des demandes de lecture sont mis en file d’attente ici.
C’était donc pour les lectures seulement, mais même dans ce cas – pourquoi se soucier de savoir si c’est un contexte d’interruption ou non, si Linux Crypto API utilisera probablement un thread/une file d’attente dédiée pour le cryptage de toute façon ? Eh bien, en 2005, Crypto API n’était pas asynchrone, donc cela était parfaitement logique.
En 2006, dm-crypt a commencé à utiliser la file d’attente de travail « kcryptd » non seulement pour le cryptage, mais pour soumettre des demandes d’E/S:
Ce patch est conçu pour aider dm-crypt à se conformer aux nouvelles contraintes imposées par le patch suivant dans -mm : md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Il semble que l’objectif ici n’était pas d’ajouter plus de concurrence, mais plutôt de réduire l’utilisation de la pile du noyau, ce qui est de nouveau logique car le noyau a une pile commune à tout le code, c’est donc une ressource assez limitée. Il convient de noter, cependant, que la pile du noyau Linux a été étendue en 2014 pour les plates-formes x86, donc cela pourrait ne plus être un problème.
Une première version de la file d’attente de travail « kcryptd_io » a été ajoutée en 2007 avec l’intention d’éviter :
la famine causée par de nombreuses demandes en attente d’allocation de mémoire…
Le traitement des demandes était un goulot d’étranglement sur une seule file d’attente de travail ici, donc la solution était d’en ajouter une autre. C’est logique.
Nous ne sommes certainement pas les premiers à subir une dégradation des performances à cause d’une mise en file d’attente étendue : en 2011, un changement a été introduit pour inverser conditionnellement une partie de la mise en file d’attente pour les demandes de lecture :
S’il y a suffisamment de mémoire, le code peut directement soumettre la bio au lieu de mettre en file d’attente cette opération dans un thread séparé.
Malheureusement, à cette époque, les messages de commit du noyau Linux n’étaient pas aussi verbeux qu’aujourd’hui, donc il n’y a pas de données de performance disponibles.
En 2015, dm-crypt a commencé à trier les écritures dans un thread « dmcrypt_write » séparé avant de les envoyer en bas de la pile:
Sur une machine multiprocesseur, les demandes de cryptage se terminent dans un ordre différent de celui dans lequel elles ont été soumises. Par conséquent, les demandes d’écriture seraient soumises dans un ordre différent et cela pourrait entraîner une sévère dégradation des performances.
Cela a du sens car l’accès séquentiel au disque était auparavant beaucoup plus rapide que l’accès aléatoire et dm-crypt brisait le schéma. Mais cela s’applique surtout aux disques rotatifs, qui étaient encore dominants en 2015. Il se peut que ce ne soit pas aussi important avec les SSD rapides modernes (y compris les SSD NVME).
Une autre partie du message commit vaut la peine d’être mentionnée :
…en particulier, il permet aux ordonnanceurs d’E/S comme CFQ de trier plus efficacement…
Il mentionne les avantages en termes de performances pour l’ordonnanceur d’E/S CFQ, mais les ordonnanceurs Linux se sont améliorés depuis au point que l’ordonnanceur CFQ a été retiré du noyau en 2018.
Le même patchset remplace la liste de tri par un arbre rouge-noir :
En théorie, le tri devrait être effectué par l’ordonnanceur de disque sous-jacent, cependant, en pratique, l’ordonnanceur de disque n’accepte et ne trie qu’un nombre fini de demandes. Pour permettre le tri de toutes les demandes, dm-crypt doit implémenter son propre tri.
L’overhead associé au tri basé sur rbtree est considéré comme négligeable, il n’est donc pas utilisé de manière conditionnelle.
Tout cela a du sens, mais il serait bien d’avoir des données de soutien.
Intéressant, dans le même patchset, nous voyons l’introduction de notre option familière « submit_from_crypt_cpus »:
Il y a certaines situations où décharger les bios d’écriture des threads de chiffrement à un seul thread dégrade les performances de manière significative
Dans l’ensemble, nous pouvons voir que chaque changement était raisonnable et nécessaire, cependant les choses ont changé depuis :
- le matériel est devenu plus rapide et plus intelligent
- l’allocation des ressources Linux a été revisitée
- les sous-systèmes Linux couplés ont été réarchitecturés
Et beaucoup des choix de conception ci-dessus peuvent ne pas être applicables à Linux moderne.
Le « nettoyage »
Sur la base des recherches ci-dessus, nous avons décidé d’essayer de supprimer toutes les files d’attente supplémentaires et le comportement asynchrone et de revenir dm-crypt à son objectif initial : simplement crypter/décrypter les demandes d’E/S lorsqu’elles passent. Mais pour des raisons de stabilité et de benchmarking ultérieur, nous avons fini par ne pas supprimer le code actuel, mais plutôt par ajouter une autre option dm-crypt, qui contourne toutes les files d’attente/threads, si elle est activée. Ce drapeau nous permet de basculer entre le comportement actuel et le nouveau comportement au moment de l’exécution sous une charge de production complète, de sorte que nous pouvons facilement revenir sur nos modifications si nous constatons des effets secondaires. Le patch résultant peut être trouvé sur le dépôt Cloudflare GitHub Linux.
Synchronous Linux Crypto API
D’après le diagramme ci-dessus, nous nous souvenons que toutes les files d’attente ne sont pas implémentées dans dm-crypt. L’API Crypto Linux moderne peut également être asynchrone et, pour les besoins de cette expérience, nous voulons éliminer les files d’attente là aussi. Mais que signifie « peut être » ? Le système d’exploitation peut contenir différentes implémentations du même algorithme (par exemple, AES-NI accéléré par le matériel sur les plates-formes x86 et les implémentations AES génériques en code C). Par défaut, le système choisit la « meilleure » en fonction de la priorité de l’algorithme configuré. dm-crypt permet de surpasser ce comportement et de demander une implémentation de chiffrement particulière en utilisant le préfixe capi:. Cependant, il y a un problème. Vérifions effectivement les implémentations AES-XTS (c’est notre chiffrement de disque, rappelez-vous ?) disponibles sur notre système:
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64Nous voulons explicitement sélectionner un chiffrement synchrone dans la liste ci-dessus pour éviter les effets de file d’attente dans les threads, mais les deux seuls supportés sont xts(ecb(aes-generic)) (l’implémentation C générique) et __xts-aes-aesni (l’implémentation x86 accélérée par le matériel). Nous voulons définitivement cette dernière car elle est beaucoup plus rapide (nous visons la performance ici), mais elle est suspicieusement marquée comme interne (voir internal: yes). Si nous vérifions le code source:
Marquer un chiffrement comme une implémentation de service utilisable uniquement par un autre chiffrement et jamais par un utilisateur normal de l’API crypto du noyau
Donc ce chiffrement est censé être utilisé uniquement par d’autres codes wrappers dans l’API Crypto et pas en dehors. En pratique, cela signifie que l’appelant de l’API Crypto doit spécifier explicitement ce drapeau, lorsqu’il demande une implémentation particulière du chiffrement, mais dm-crypt ne le fait pas, car par conception, il ne fait pas partie de l’API Crypto Linux, plutôt un utilisateur « externe ». Nous patchons déjà le module dm-crypt, donc nous pourrions tout aussi bien ajouter le drapeau correspondant. Cependant, il y a un autre problème avec AES-NI en particulier : x86 FPU. « Virgule flottante », dites-vous ? Pourquoi avons-nous besoin de mathématiques en virgule flottante pour faire du cryptage symétrique qui ne devrait être qu’une question de décalage de bits et d’opérations XOR ? Nous n’avons pas besoin des maths, mais les instructions AES-NI utilisent certains des registres du CPU, qui sont dédiés au FPU. Malheureusement, le noyau Linux ne préserve pas toujours ces registres dans un contexte d’interruption pour des raisons de performance (la sauvegarde/restauration du FPU est coûteuse). Mais dm-crypt peut exécuter du code dans le contexte d’interruption, donc nous risquons de corrompre certaines données d’un autre processus et nous revenons à la déclaration « il serait très imprudent de faire du décryptage dans un contexte d’interruption » dans le code original.
Notre solution pour répondre à ce qui précède a été de créer un autre module Crypto API quelque peu « intelligent ». Ce module est synchrone et ne roule pas sa propre crypto, mais est juste un « routeur » de demandes de cryptage :
- si nous pouvons utiliser le FPU (et donc AES-NI) dans le contexte d’exécution actuel, nous transmettons simplement la demande de cryptage à l’implémentation
__xts-aes-aesniplus rapide et « interne » (et nous pouvons l’utiliser ici, parce que maintenant nous faisons partie de l’API Crypto) - sinon, nous transmettons simplement la demande de chiffrement à l’implémentation
xts(ecb(aes-generic))plus lente, générique et basée sur le langage C
Utilisation de l’ensemble
Promenons le processus d’utilisation de l’ensemble. La première étape consiste à récupérer les patchs et à recompiler le noyau (ou simplement compiler dm-crypt et nos modules xtsproxy).
Puis, relançons notre charge de travail IO dans un terminal séparé, afin de nous assurer que nous pouvons reconfigurer le noyau à l’exécution sous charge :
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Dans le terminal principal, assurez-vous que notre nouveau module Crypto API est chargé et disponible :
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Reconfigurer le disque crypté pour utiliser notre module nouvellement chargé et activer notre drapeau dm-crypt patché (nous devons utiliser l’outil bas niveau dmsetup car cryptsetup n’est évidemment pas au courant de nos modifications):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Nous venons de « charger » la nouvelle configuration, mais pour qu’elle prenne effet, nous devons suspendre/reprendre le dispositif crypté:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0Et maintenant observer le résultat. Nous pouvons revenir à l’autre terminal exécutant le job fio et regarder la sortie, mais pour rendre les choses plus agréables, voici un instantané du débit de lecture/écriture observé dans Grafana:
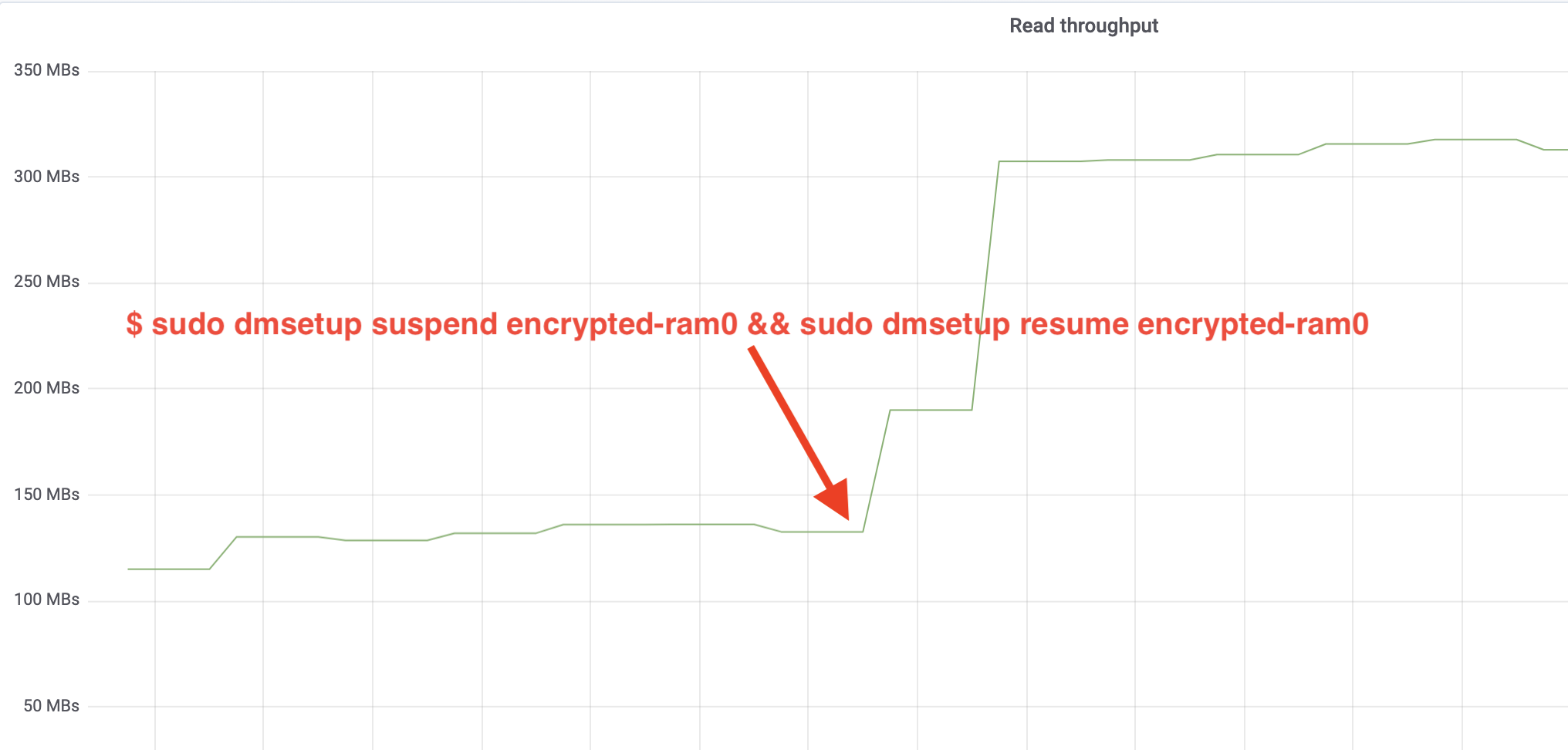
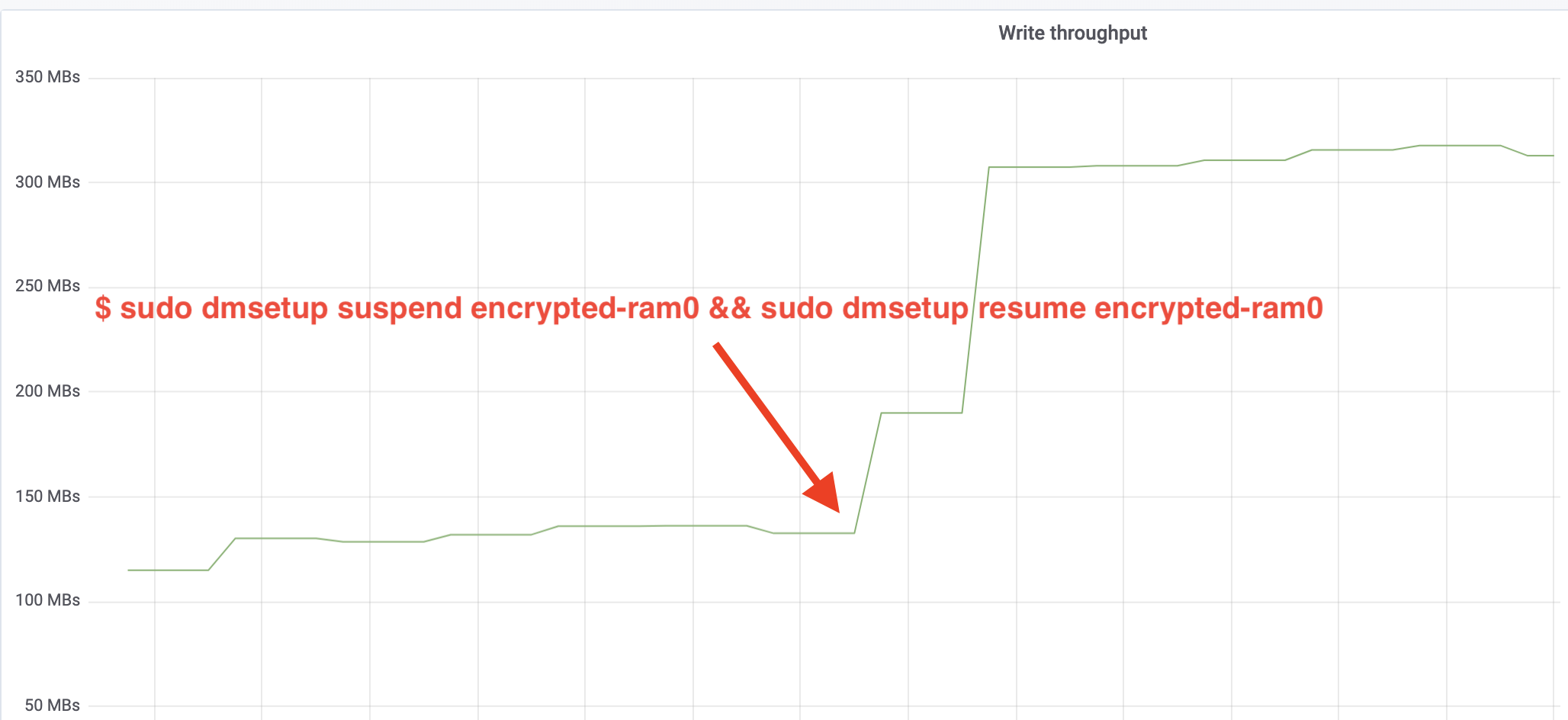
Wow, nous avons plus que doublé le débit ! Avec un débit total de ~640 MB/s, nous sommes maintenant beaucoup plus proches des ~696 MB/s attendus ci-dessus. Qu’en est-il de la latence IO ? (La statistique await de l’outil de reporting iostat):
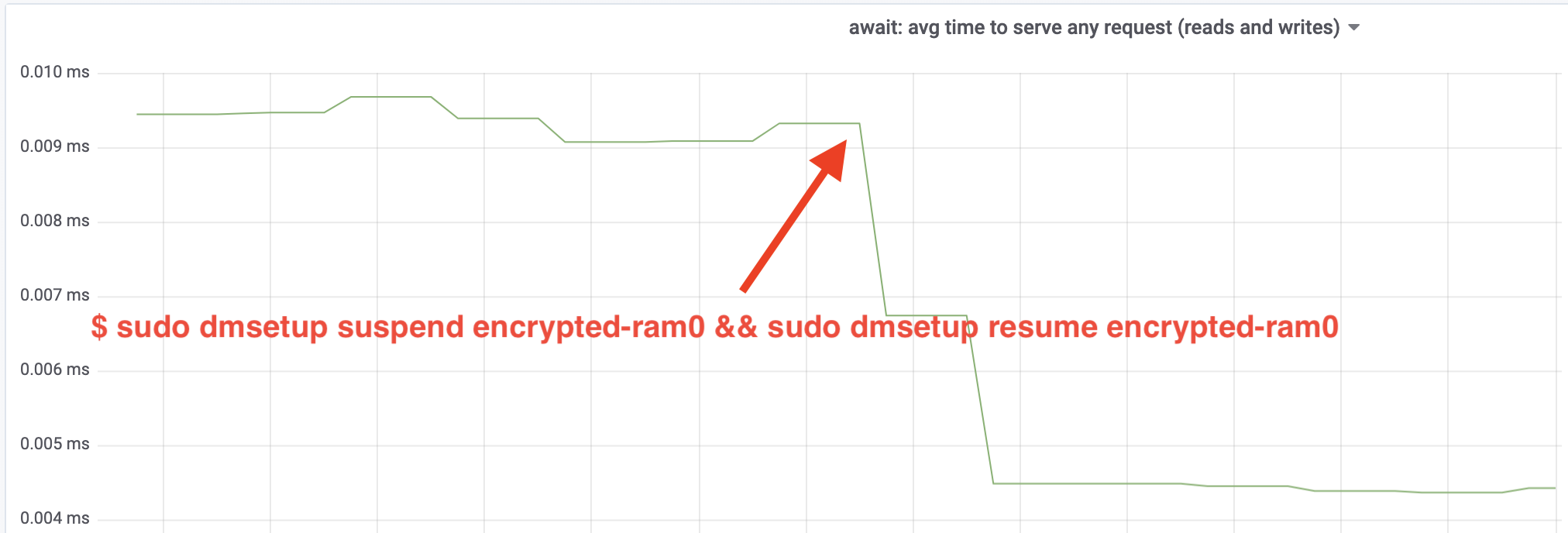
La latence a également été réduite de moitié!
Vers la production
Jusqu’à présent, nous avons utilisé une configuration synthétique avec certaines parties de la pile de production complète manquantes, comme les systèmes de fichiers, le matériel réel et surtout, la charge de travail de production. Pour s’assurer que nous n’optimisons pas des choses imaginaires, voici un instantané de l’impact de production que ces changements apportent à la partie cache de notre pile:

Ce graphique représente une comparaison à trois voies des pires temps de réponse (99e percentile) pour un hit de cache dans l’un de nos serveurs. La ligne verte provient d’un serveur avec des disques non chiffrés, que nous utiliserons comme ligne de base. La ligne rouge est celle d’un serveur avec des disques chiffrés avec l’implémentation par défaut du chiffrement de disque de Linux et la ligne bleue est celle d’un serveur avec des disques chiffrés et nos optimisations activées. Comme nous pouvons le constater, l’implémentation par défaut du chiffrement des disques Linux a un impact significatif sur la latence de notre cache dans les pires scénarios, alors que l’implémentation corrigée est indiscernable de l’absence totale de chiffrement. En d’autres termes, l’implémentation améliorée du chiffrement n’a pas du tout d’impact sur la vitesse de réponse de notre cache, donc nous l’obtenons fondamentalement gratuitement ! C’est une victoire !
Nous ne faisons que commencer
Ce post montre comment une revue d’architecture peut doubler les performances d’un système. Nous avons également reconfirmé que la cryptographie moderne n’est pas coûteuse et qu’il n’y a généralement pas d’excuse pour ne pas protéger vos données.
Nous allons soumettre ce travail pour inclusion dans l’arbre source principal du noyau, mais très probablement pas dans sa forme actuelle. Bien que les résultats semblent encourageants, nous devons nous rappeler que Linux est un système d’exploitation hautement portable : il fonctionne aussi bien sur de puissants serveurs que sur de petits appareils IoT limités en ressources et sur de nombreuses autres architectures de CPU également. La version actuelle des correctifs ne fait qu’optimiser le chiffrement du disque pour une charge de travail particulière sur une architecture particulière, mais Linux a besoin d’une solution qui fonctionne bien partout.
Cela dit, si vous pensez que votre cas est similaire et que vous voulez profiter des améliorations de performance maintenant, vous pouvez saisir les correctifs et, espérons-le, fournir des commentaires. L’indicateur d’exécution permet de basculer facilement la fonctionnalité à la volée et un simple test A/B peut être effectué pour voir si cela profite à un cas particulier ou à une configuration. Ces correctifs ont été exécutés dans notre vaste réseau de plus de 200 centres de données sur cinq générations de matériel, et peuvent donc être raisonnablement considérés comme stables. Profitez à la fois des performances et de la sécurité de Cloudflare pour tous !

Mise à jour (11 octobre 2020)
Le correctif principal de ce blog (sous une forme légèrement mise à jour) a été fusionné dans le noyau Linux mainline et est disponible depuis la version 5.9 et plus. La principale différence est que la version mainline expose deux drapeaux au lieu d’un, qui fournissent la possibilité de contourner les files d’attente de dm-crypt pour les lectures et les écritures indépendamment. Pour plus de détails, voir la documentation officielle de dm-crypt.