Le poids moléculaire est l’un des aspects les plus centraux des propriétés des polymères. Bien sûr, toutes les molécules ont des poids moléculaires qui leur sont propres. Il peut sembler évident que la masse moléculaire est une propriété essentielle de tout composé moléculaire. Dans le cas des polymères, la masse moléculaire revêt une importance accrue. En effet, un polymère est une grosse molécule composée d’unités répétitives, mais combien d’unités répétitives ? Trente ? Un millier ? Un million ? N’importe laquelle de ces possibilités pourrait encore être considérée comme représentative du même matériau, mais leurs poids moléculaires seraient très différents, tout comme leurs propriétés.
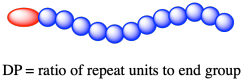
Cette variation introduit certains aspects uniques du poids moléculaire des polymères. Comme les polymères sont assemblés à partir de molécules plus petites, la longueur (et par conséquent la masse moléculaire) d’une chaîne polymère dépend du nombre de monomères qui ont été enchaînés dans le polymère. Le nombre de monomères enchaînés dans une chaîne polymère moyenne dans un matériau est appelé le degré de polymérisation (DP).

Notez ce point clé : il s’agit juste d’une moyenne. Dans un matériau donné, il y aura des chaînes qui ont ajouté plus de monomères et d’autres qui en ont ajouté moins. Pourquoi cette différence ? Tout d’abord, la croissance des polymères est un processus dynamique. Il faut que les monomères s’assemblent et réagissent. Que se passe-t-il si un monomère commence à réagir, formant une chaîne en croissance, avant que les autres ne commencent ? Grâce à son avance, cette chaîne deviendra plus longue que les autres. Et si quelque chose se passe mal avec l’une des chaînes en croissance, et qu’elle ne peut plus ajouter de nouveaux monomères ? Cette chaîne a connu une mort précoce, et elle ne deviendra jamais aussi longue que les autres.
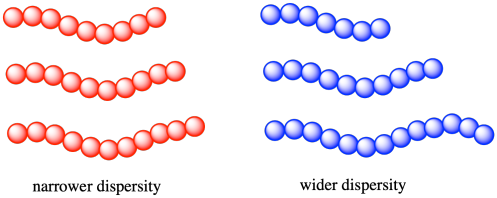
En conséquence, lorsque nous parlons de la masse moléculaire d’un polymère, nous parlons toujours d’une valeur moyenne. Certaines chaînes du matériau seront plus longues (et plus lourdes) et certaines chaînes du matériau seront plus courtes (et plus légères). Comme pour tout groupe de mesures, il est utile de connaître la distribution réelle des valeurs individuelles. En chimie des polymères, la largeur de la distribution des masses moléculaires est décrite par la dispersité (Ð, également appelée, dans les textes plus anciens, la polydispersité ou l’indice de polydispersité, PDI). La dispersité d’un échantillon de polymère est souvent comprise entre 1 et 2 (bien qu’elle puisse être encore supérieure à 2). Plus elle est proche de 1, plus la distribution est étroite. Autrement dit, une dispersité de 1,0 signifierait que toutes les chaînes d’un échantillon sont exactement de la même longueur, avec le même poids moléculaire.
L’idée originale de la dispersité était basée sur des méthodes alternatives de mesure du poids moléculaire (ou de la longueur de la chaîne) d’un échantillon de polymère. Un ensemble de méthodes a donné quelque chose appelé le poids moléculaire moyen en nombre (symbole Mn). Ces méthodes prennent essentiellement le poids d’un échantillon, comptent les molécules dans un échantillon, et trouvent donc le poids moyen de chaque molécule dans cet échantillon. Un exemple classique de cette approche est une expérience sur les propriétés colligatives, comme la dépression du point de congélation. Vous savez que les impuretés présentes dans un liquide ont tendance à perturber les interactions intermoléculaires et à abaisser le point de congélation du liquide. Vous savez également que la quantité d’abaissement du point de congélation dépend du nombre de molécules ou d’ions qui sont dissous. Par conséquent, si vous pesez un échantillon de polymère, que vous le dissolvez dans un solvant et que vous mesurez le point de congélation, vous pourriez calculer le nombre de molécules dissoutes et par conséquent arriver à Mn.
Ce n’est pas si facile en pratique ; les dépressions du point de congélation sont très petites. On ne les utilise plus très souvent. Un exemple très courant du type de mesure largement utilisé pour déterminer Mn aujourd’hui est l’analyse de groupe final. Dans l’analyse des groupes terminaux, nous utilisons des mesures de RMN 1H pour déterminer le rapport entre un proton spécifique dans les unités de répétition et un proton spécifique dans le groupe terminal. Rappelez-vous, le groupe terminal peut être quelque chose comme l’initiateur, qui n’est ajouté au premier monomère que pour lancer la polymérisation. À la fin de la polymérisation, il se trouve toujours à l’extrémité de la chaîne polymère, il s’agit donc d’un groupe terminal. Il n’y en a qu’un par chaîne, alors qu’il y a beaucoup de monomères enchaînés dans le polymère, donc le rapport entre ces monomères enchaînés et le groupe terminal nous indique la longueur de la chaîne.
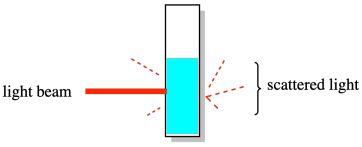
L’autre ensemble de méthodes sur lesquelles la dispersité était basée donnait quelque chose appelé la masse moléculaire moyenne en poids (symbole Mw). L’exemple classique était une expérience de diffusion de la lumière. Dans cette expérience, une solution de polymère était exposée à un faisceau de lumière et la lumière diffusée résultante — provenant de l’échantillon dans différentes directions — était analysée pour déterminer la taille des chaînes de polymère dans la solution. Les résultats ont été plus fortement influencés par les plus grosses molécules en solution. Par conséquent, cette mesure du poids moléculaire était toujours plus élevée que les mesures basées sur le comptage de chaque molécule.
Le rapport résultant, Ð = Mw / Mn, est devenu connu sous le nom d’indice de polydispersité ou, plus récemment, de dispersité. Comme Mw était toujours plus fortement influencé par les chaînes plus longues, il était un peu plus grand que Mn et, par conséquent, la dispersité était toujours supérieure à 1,0.
De nos jours, tant la masse moléculaire que la dispersité sont le plus souvent mesurées par chromatographie par perméation de gel (CPG), synonyme de chromatographie d’exclusion de taille (SEC). Cette méthode est une technique de chromatographie liquide à haute performance (HPLC). Le solvant contenant un échantillon de polymère est pompé à travers une colonne chromatographique spécialisée capable de séparer les molécules en fonction de leurs différences de taille. Lorsque l’échantillon sort de la colonne, il est détecté et enregistré. Le plus souvent, la présence de l’échantillon dans le solvant sortant de la colonne entraîne une légère modification de l’indice de réfraction. Un graphique de l’indice de réfraction en fonction du temps présente un enregistrement de la quantité d’échantillon sortant de la colonne à un moment donné. Comme la colonne a séparé les molécules en fonction de leur taille, l’axe du temps correspond indirectement à la longueur de chaîne de la masse moléculaire.
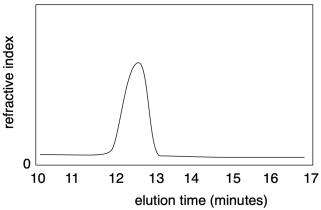
Comment la colonne peut-elle séparer les molécules en fonction de leur taille ? La colonne est garnie d’un matériau poreux, généralement des billes de polymère insolubles. La taille des pores varie. Ces pores sont cruciaux pour la séparation car les molécules qui s’écoulent à travers la colonne peuvent s’attarder dans les pores. Les petites molécules peuvent être retardées dans n’importe lequel des pores du matériau, tandis que les grandes molécules ne seront retardées que dans les plus grands pores. Par conséquent, un temps d’élution plus long correspond à un poids moléculaire plus faible.

Si vous injectiez une série de polymères différents dans une CPG, chacun ayant une distribution de poids moléculaire différente, vous observeriez que chacun élue à un temps différent. De plus, chaque pic peut être plus large ou plus étroit, en fonction de la dispersité de cet échantillon particulier.
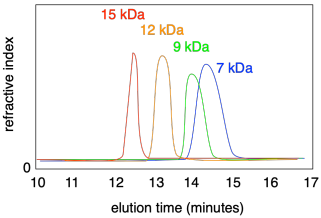
Plus le pic est large en CPG, plus la distribution des masses moléculaires est large ; plus les pics sont étroits, plus les chaînes sont uniformes. Normalement, un logiciel analyse la courbe pour déterminer la dispersité.

Notez que l’axe des x sur un tracé de GPC est le plus souvent étiqueté comme « temps d’élution » et il va normalement de gauche à droite. Cependant, l’axe des x est souvent étiqueté « droit moléculaire » car c’est vraiment la quantité qui nous intéresse. En fait, l’axe est parfois inversé, de sorte que les pics de poids moléculaire plus élevé apparaissent à droite, car il peut sembler plus naturel de le regarder de cette façon. Vous devez regarder attentivement les données pour voir comment elles sont affichées.
Il y a quelques problèmes à se fier à la CPG pour les mesures de masse moléculaire. La principale difficulté est que les polymères en solution ont tendance à s’enrouler en boules, et ces enroulements contiendront des quantités plus ou moins importantes de solvant, selon la force de l’interaction entre le polymère et le solvant. Si le polymère interagit plus fortement avec le solvant, il attirera beaucoup plus de molécules de solvant à l’intérieur de ses bobines. La bobine doit s’agrandir pour faire de la place à ces molécules de solvant internes. S’il n’interagit pas fortement avec le solvant, il restera le plus souvent collé à lui-même, empêchant les molécules de solvant d’entrer. Il existe un large éventail de comportements entre les deux.
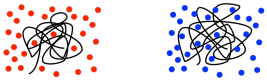
En conséquence, différents polymères peuvent gonfler à des degrés différents dans différents solvants. Cela a de l’importance parce que la CPG utilise vraiment la taille de la bobine du polymère comme un indice de son poids moléculaire, donc la comparaison des traces de CPG de deux types différents de polymères doit être faite avec prudence.
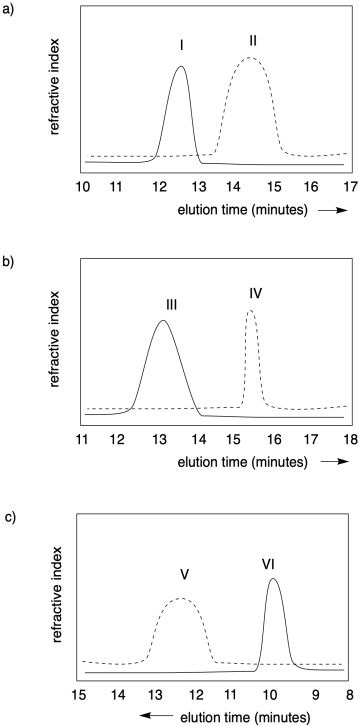
Problème CP1.1.
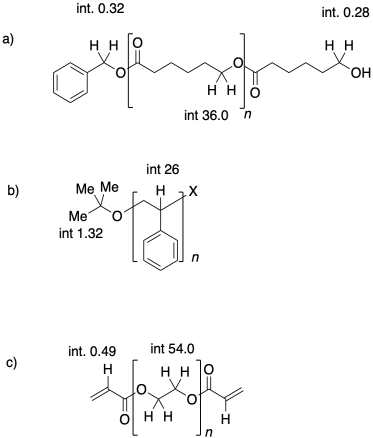
Dans chacun des cas suivants, indiquez quel polymère a le poids moléculaire le plus élevé, et lequel a une dispersité plus étroite
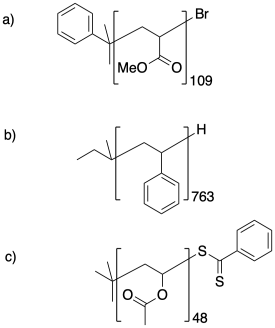
Problème CP1.2.
Calculez le poids moléculaire des échantillons suivants.
Problème CP1.3.
Utilisez l’analyse des groupes terminaux par RMN pour déterminer les degrés de polymérisation des échantillons suivants.
.