Vahvistusoppiminen (RL) on yksi nykyaikaisen tekoälyn kuumimmista tutkimusaiheista, ja sen suosio vain kasvaa. Katsotaanpa 5 hyödyllistä asiaa, jotka täytyy tietää, jotta pääsee alkuun RL:n parissa.
Vahvistusoppiminen(RL) on eräänlainen koneoppimistekniikka, jonka avulla agentti voi oppia vuorovaikutteisessa ympäristössä kokeilemalla ja erehtymällä käyttäen palautetta omista toimistaan ja kokemuksistaan.
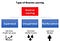
Kaikki sekä valvottu oppiminen että vahvistusoppiminen käyttävät tulon ja tuotoksen välistä kartoitusta, mutta toisin kuin valvotussa oppimisessa, jossa agentille annettavana palautteena ovat oikeat toimintakokonaisuudet tehtävän suorittamiseksi, vahvistusoppimisessa käytetään positiivisen ja negatiivisen käyttäytymisen signaaleina palkkioita ja rangaistuksia.
Valvomattomaan oppimiseen verrattuna vahvistusoppiminen eroaa tavoitteiltaan. Kun valvomattomassa oppimisessa tavoitteena on löytää datapisteiden välisiä yhtäläisyyksiä ja eroja, vahvistusoppimisen tapauksessa tavoitteena on löytää sopiva toimintamalli, joka maksimoi agentin kumulatiivisen kokonaispalkkion. Alla oleva kuva havainnollistaa geneerisen RL-mallin toiminta-palkkio-palautesilmukkaa.

Miten muotoillaan perustavanlaatuinen vahvistusoppimisen ongelma?
Joitakin keskeisiä termejä, jotka kuvaavat RL-ongelman peruselementtejä, ovat:
- Ympäristö – Fyysinen maailma, jossa agentti toimii
- Tila – Agentin tämänhetkinen tilanne
- Palkkio – Ympäristöstä saatava palaute
- Politiikka – Menetelmä, jolla agentin tila kartoitetaan toiminnoiksi
- Arvo – Tulevaisuuden palkkio, jonka agentti saisi ryhtymällä tiettyyn toimintoon tietyssä tilassa
RL-problematiikka selittyy parhaiten pelien kautta. Otetaan vaikka PacMan-peli, jossa agentin(PacMan) tavoitteena on syödä ruudukossa oleva ruoka välttäen samalla matkalla olevia haamuja. Tässä tapauksessa ruudukkomaailma on agentin interaktiivinen ympäristö, jossa se toimii. Agentti saa palkkion ruoan syömisestä ja rangaistuksen, jos aave tappaa sen (se häviää pelin). Tilat ovat agentin sijainti ruudukkomaailmassa ja kumulatiivinen kokonaispalkkio on agentin voitto pelissä.

Optimaalisen toimintapolitiikan rakentamiseksi agentti joutuu dilemman eteen, jossa se joutuu tutkailemaan uusia tiloja ja maksimoimaan samalla kokonaispalkintonsa. Tätä kutsutaan nimellä Exploration vs Exploitation trade-off. Molempien tasapainottamiseksi paras kokonaisstrategia voi edellyttää lyhyen aikavälin uhrauksia. Siksi agentin tulisi kerätä riittävästi tietoa tehdäkseen parhaan kokonaispäätöksen tulevaisuudessa.
Markovin päätösprosessit (MDP) ovat matemaattisia kehyksiä ympäristön kuvaamiseen RL:ssä, ja lähes kaikki RL-ongelmat voidaan muotoilla MDP:n avulla. MDP koostuu joukosta äärellisiä ympäristön tiloja S, joukosta mahdollisia toimia A(s) kussakin tilassa, reaaliarvoisesta palkitsemisfunktiosta R(s) ja siirtymämallista P(s’, s | a). Todellisissa ympäristöissä on kuitenkin todennäköisempää, että ympäristön dynamiikasta ei ole ennakkotietoa. Mallittomat RL-menetelmät ovat käteviä tällaisissa tapauksissa.
Q-oppiminen on yleisesti käytetty malliton lähestymistapa, jota voidaan käyttää itseään pelaavan PacMan-agentin rakentamiseen. Se pyörii Q-arvojen päivittämisen käsitteen ympärillä, joka tarkoittaa toiminnan a suorittamisen arvoa tilassa s. Seuraava arvojen päivityssääntö on Q-oppimisen algoritmin ydin.

Tässä on videodemonstraatio PacMan-agentista, joka käyttää syvä vahvistusoppimista.
Mitkä ovat yleisimmin käytettyjä vahvistusoppimisalgoritmeja?
Q-oppiminen ja SARSA (State-Action-Reward-State-Action) ovat kaksi yleisesti käytettyä mallitonta RL-algoritmia. Ne eroavat toisistaan etsintästrategioidensa suhteen, kun taas niiden hyödyntämisstrategiat ovat samankaltaisia. Q-learning on off-policy-menetelmä, jossa agentti oppii arvon, joka perustuu toisesta politiikasta johdettuun toimintaan a*, kun taas SARSA on on-policy-menetelmä, jossa agentti oppii arvon, joka perustuu senhetkiseen toimintaan a, joka on johdettu senhetkisestä politiikasta. Nämä kaksi menetelmää ovat yksinkertaisia toteuttaa, mutta niistä puuttuu yleispätevyys, koska niillä ei ole kykyä arvioida arvoja näkymättömille tiloille.
Tämä voidaan ratkaista kehittyneemmillä algoritmeilla, kuten Deep Q-Networks(DQNs) -menetelmillä, jotka käyttävät hermoverkkoja Q-arvojen estimointiin. DQN:t pystyvät kuitenkin käsittelemään vain diskreettejä, matalaulotteisia toiminta-avaruuksia.
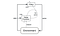
Deep Deterministic Policy Gradient(DDPG) on malliton, politiikan ulkopuolinen, toimijakriittinen algoritmi, joka ratkaisee tämän ongelman oppimalla toimintatapoja korkea-ulotteisissa, jatkuvissa toiminta-avaruuksissa. Alla olevassa kuvassa on esitetty toimijakriittinen arkkitehtuuri.
Mitkä ovat vahvistusoppimisen käytännön sovellukset?
Koska RL vaatii paljon dataa, se soveltuu parhaiten aloilla, joilla simuloitua dataa on helposti saatavilla, kuten pelien pelaamisessa ja robotiikassa.
- RL:ää käytetään melko laajalti tekoälyn rakentamisessa tietokonepelejä varten. AlphaGo Zero on ensimmäinen tietokoneohjelma, joka voitti maailmanmestarin muinaisessa kiinalaisessa Go-pelissä. Muita ovat ATARI-pelit, Backgammon ,jne
- Robotiikassa ja teollisuusautomaatiossa RL:ää käytetään, jotta robotti voi luoda itselleen tehokkaan adaptiivisen ohjausjärjestelmän, joka oppii omasta kokemuksestaan ja käyttäytymisestään. DeepMindin työ Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Policy updates on hyvä esimerkki tästä. Katso tämä mielenkiintoinen esittelyvideo.
Muita RL:n sovelluksia ovat muun muassa abstraktiiviset tekstin tiivistämismoottorit, dialogiagentit (teksti, puhe), jotka voivat oppia käyttäjän vuorovaikutuksesta ja kehittyä ajan mittaan, optimaalisten hoitokäytäntöjen oppiminen terveydenhuollossa ja RL-pohjaiset agentit verkkopörssikauppaa varten.
Miten pääsen alkuun vahvistusoppimisessa?
Vahvistusoppimisen peruskäsitteiden ymmärtämiseksi voi tutustua seuraaviin lähteisiin.
- Reinforcement Learning-An Introduction, vahvistusoppimisen isän Richard Suttonin ja hänen väitöskirjaohjaajansa Andrew Barton kirja. Kirjan verkkoluonnos on saatavilla täältä.
- David Silverin opetusmateriaali videoluentoja myöten on hyvä johdantokurssi RL:stä.
- Tässä on toinen tekninen tutoriaali RL:stä, jonka ovat kirjoittaneet Pieter Abbeel ja John Schulman (Open AI/ Berkeley AI Research Lab).
RL-agenttien rakentamisen ja testaamisen aloittamiseen voivat olla avuksi seuraavat resurssit.
- Tämä Andrej Karpathyn blogi siitä, miten kouluttaa neuroverkon ATARI Pong -agentti Policy Gradientsin avulla raakapikseleistä Andrej Karpathyn tekemä Neural Network ATARI Pong -agentti, auttaa sinua saamaan ensimmäisen Deep Reinforcement Learning -agenttisi pystyyn ja toimimaan vain 130 rivillä Python-koodia.
- DeepMind Lab on avoimen lähdekoodin 3D-pelimäinen alusta, joka on luotu agenttipohjaiseen tekoälytutkimukseen rikkailla simuloitavilla ympäristöillä.
- Project Malmo on toinen tekoälyn kokeilualusta, jolla tuetaan tekoälyn perustutkimusta.
- OpenAI-jumppa on työkalupakki, jonka avulla voi rakentaa ja vertailla vahvistusoppimisalgoritmeja.