Posted on August 27, 2015
Rekurrenssia neuroverkkoja
Ihminen ei aloita ajatteluaan tyhjästä joka sekunti. Kun luet tätä esseetä, ymmärrät jokaisen sanan edellisten sanojen ymmärtämisen perusteella. Et heitä kaikkea pois ja aloita ajattelua alusta. Ajatuksillasi on pysyvyyttä.
Traditionaaliset neuroverkot eivät pysty tähän, ja se vaikuttaa suurelta puutteelta. Kuvittele esimerkiksi, että haluat luokitella, millainen tapahtuma tapahtuu elokuvan jokaisessa kohdassa. On epäselvää, miten perinteinen neuroverkko voisi käyttää päättelyään elokuvan aiemmista tapahtumista myöhempiin tapahtumiin.
Rekursiiviset neuroverkot ratkaisevat tämän ongelman. Ne ovat verkkoja, joissa on silmukoita, joiden avulla tieto voi säilyä.

Yllä olevassa kaaviossa neuroverkon lohko \(A\) tarkastelee jotakin syötettä \(x_t\) ja antaa tuloksena arvon \(h_t\). Silmukan avulla tietoa voidaan siirtää verkon yhdestä vaiheesta seuraavaan.
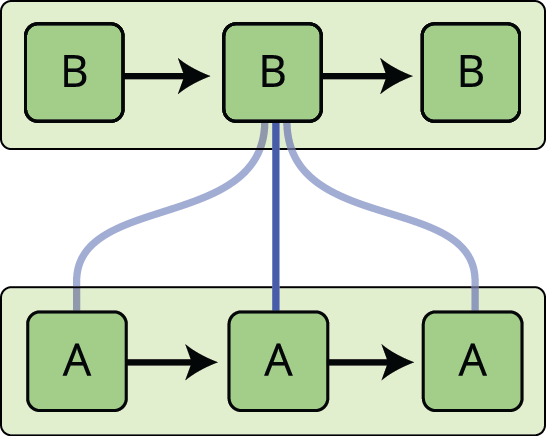
Näiden silmukoiden ansiosta rekursiiviset neuroverkot vaikuttavat jotenkin mystisiltä. Jos kuitenkin miettii hieman tarkemmin, käy ilmi, että ne eivät eroa lainkaan tavallisista neuroverkoista. Rekurrenssia neuroverkkoa voidaan ajatella useina saman verkon kopioina, joista jokainen välittää viestin seuraajalleen. Mieti, mitä tapahtuu, jos rullaamme silmukan auki:

Tämä ketjumainen luonne paljastaa, että rekursiiviset neuroverkot ovat läheisessä yhteydessä sekvensseihin ja luetteloihin. Ne ovat luonnollinen neuroverkkoarkkitehtuuri, jota käytetään tällaiseen dataan.
Ja niitä varmasti käytetäänkin! Viime vuosina RNN:iä on sovellettu uskomattoman menestyksekkäästi monenlaisiin ongelmiin: puheentunnistukseen, kielen mallintamiseen, kääntämiseen, kuvateksteihin… Lista jatkuu. Jätän keskustelun niistä hämmästyttävistä saavutuksista, joita RNN:ien avulla voidaan saavuttaa, Andrej Karpathyn erinomaiseen blogikirjoitukseen The Unreasonable Effectiveness of Recurrent Neural Networks. Mutta ne ovat todella melko hämmästyttäviä.
Tärkeää näissä onnistumisissa on ”LSTM:ien” käyttö, hyvin erikoisenlainen rekursiivinen neuroverkko, joka toimii monissa tehtävissä paljon, paljon paremmin kuin tavallinen versio. Lähes kaikki jännittävät tulokset, jotka perustuvat rekursiivisiin neuroverkkoihin, on saavutettu niillä. Juuri näitä LSTM:iä tutkitaan tässä esseessä.
Pitkän aikavälin riippuvuuksien ongelma
Yksi RNN:ien vetovoimatekijöistä on ajatus siitä, että ne pystyvät yhdistämään aiempaa tietoa nykyiseen tehtävään, kuten esimerkiksi aiempien videokuvien käyttäminen voi auttaa ymmärtämään nykyistä kuvaa. Jos RNN:t pystyisivät tähän, ne olisivat äärimmäisen hyödyllisiä. Mutta pystyvätkö ne siihen? Riippuu siitä.
Joskus meidän on tarkasteltava vain viimeaikaista tietoa nykyisen tehtävän suorittamiseksi. Ajatellaan esimerkiksi kielimallia, joka yrittää ennustaa seuraavaa sanaa edellisten sanojen perusteella. Jos yritämme ennustaa viimeistä sanaa sanassa ”pilvet ovat taivaalla”, emme tarvitse muuta kontekstia – on melko selvää, että seuraava sana on taivas. Tällaisissa tapauksissa, joissa relevantin tiedon ja sen tarvitseman paikan välinen kuilu on pieni, RNN:t voivat oppia käyttämään aiempaa tietoa.

Mutta on myös tapauksia, joissa tarvitsemme enemmän kontekstia. Ajatellaanpa, että yritetään ennustaa viimeinen sana tekstissä ”Kasvoin Ranskassa… Puhun sujuvasti ranskaa”. Viimeaikaiset tiedot viittaavat siihen, että seuraava sana on todennäköisesti jonkin kielen nimi, mutta jos haluamme rajata, mikä kieli on kyseessä, tarvitsemme kontekstia Ranskasta kauempaa. On täysin mahdollista, että relevantin tiedon ja sen kohdan, jossa sitä tarvitaan, välinen kuilu kasvaa hyvin suureksi.
Valitettavasti tuon kuilun kasvaessa RNN:t eivät enää kykene oppimaan tiedon yhdistämistä.

Teoriassa RNN:t pystyvät täysin käsittelemään tällaisia ”pitkän aikavälin riippuvuuksia”. Ihminen voisi huolella valita niille parametrit tämänkaltaisten leluongelmien ratkaisemiseksi. Valitettavasti käytännössä RNN:t eivät näytä kykenevän oppimaan niitä. Ongelmaa tutkivat perusteellisesti Hochreiter (1991) ja Bengio, et al. (1994), jotka löysivät joitakin melko perustavanlaatuisia syitä siihen, miksi se voi olla vaikeaa.
Onneksi LSTM-verkoilla ei ole tätä ongelmaa! Ne esitteli Hochreiter & Schmidhuber (1997), ja monet ovat jalostaneet ja popularisoineet niitä seuraavissa töissä.1 Ne toimivat valtavan hyvin monenlaisissa ongelmissa, ja niitä käytetään nykyään laajalti.
LSTM:t on nimenomaisesti suunniteltu välttämään pitkän aikavälin riippuvuusongelmaa. Tiedon muistaminen pitkiksi ajoiksi on käytännössä niiden oletuskäyttäytyminen, ei jotain, mitä ne ponnistelevat oppiakseen!
Kaikki rekursiiviset neuroverkot ovat muodoltaan toistuvien hermoverkkomoduulien ketju. Tavallisissa RNN:ssä tällä toistuvalla moduulilla on hyvin yksinkertainen rakenne, kuten yksi tanh-kerros.

LSTM:ssä on myös tämä ketjumaisen rakenteen kaltainen rakenne, mutta toistuvalla moduulilla on erilainen rakenne. Sen sijaan, että neuroverkon kerroksia olisi vain yksi, niitä on neljä, ja ne ovat vuorovaikutuksessa keskenään aivan erityisellä tavalla.

Ei kannata murehtia yksityiskohtia siitä, mitä tapahtuu. Käymme LSTM-kaavion läpi vaihe vaiheelta myöhemmin. Yritetään nyt vain totutella käyttämäämme merkintätapaan.

Yllä olevassa kaaviossa jokainen viiva kuljettaa kokonaista vektoria, yhden solmun ulostulosta muiden solmujen sisääntuloihin. Vaaleanpunaiset ympyrät edustavat pistemäisiä operaatioita, kuten vektorin yhteenlaskua, kun taas keltaiset laatikot ovat opittuja neuroverkon kerroksia. Rivien yhdistyminen tarkoittaa ketjuttamista, kun taas haarautuva rivi tarkoittaa, että sen sisältö kopioidaan ja kopiot menevät eri paikkoihin.
LSTM:ien ydinajatus
LSTM:ien avain on solutila, vaakasuora viiva, joka kulkee kaavion yläreunan läpi.
Solutila on ikään kuin liukuhihna. Se kulkee suoraan koko ketjua pitkin, ja siinä on vain pieniä lineaarisia vuorovaikutuksia. On hyvin helppoa, että informaatio vain virtaa sitä pitkin muuttumattomana.

LSTM:llä on kyky poistaa tai lisätä informaatiota solutilaan, jota säädellään huolellisesti rakenteilla, joita kutsutaan porteiksi (gates).
Portit (gates) ovat keino päästää informaatiota valinnaisesti läpi. Ne koostuvat sigmoidisesta neuroverkkokerroksesta ja pistemäisestä kertolaskuoperaatiosta.

Sigmoidinen kerros tuottaa nollan ja yhden välisiä lukuja, jotka kuvaavat, kuinka paljon kutakin komponenttia pitäisi päästää läpi. Arvo nolla tarkoittaa ”älä päästä mitään läpi”, kun taas arvo yksi tarkoittaa ”päästä kaikki läpi!”
LSTM:ssä on kolme tällaista porttia, jotka suojaavat ja kontrolloivat solun tilaa.
Vaihe vaiheelta LSTM:n läpikäynti
Ensimmäinen vaihe LSTM:ssämme on päättää, mitä tietoa heitämme pois solun tilasta. Tämän päätöksen tekee sigmoidikerros, jota kutsutaan nimellä ”forget gate layer”. Se tarkastelee \(h_{t-1}\) ja \(x_t\) ja tulostaa \(0\) ja \(1\) välisen luvun jokaiselle solutilan \(C_{t-1}\) luvulle. \(1\) edustaa ”pidä tämä kokonaan”, kun taas \(0\) edustaa ”hankkiudu tästä kokonaan eroon.”
Palaamme takaisin esimerkkiin, jossa kielimalli yrittää ennustaa seuraavan sanan kaikkien edellisten sanojen perusteella. Tällaisessa ongelmassa solun tila saattaa sisältää nykyisen subjektin sukupuolen, jotta voidaan käyttää oikeita pronomineja. Kun näemme uuden subjektin, haluamme unohtaa vanhan subjektin sukupuolen.

Seuraavaksi päätämme, mitä uutta tietoa tallennamme solutilaan. Tässä on kaksi osaa. Ensinnäkin sigmoidikerros nimeltä ”input gate layer” päättää, mitä arvoja päivitämme. Seuraavaksi tanh-kerros luo vektorin uusista ehdokasarvoista, \(\tilde{C}_t\), jotka voidaan lisätä tilaan. Seuraavassa vaiheessa yhdistämme nämä kaksi luodaksemme päivityksen tilaan.
Kielimallimme esimerkissä haluaisimme lisätä solun tilaan uuden subjektin sukupuolen vanhan unohtamamme sukupuolen tilalle.

Nyt on aika päivittää vanha solun tila, \(C_{t-1}\), uudeksi solun tilaksi \(C_t\). Edellisissä vaiheissa on jo päätetty, mitä tehdään, meidän täytyy vain todella tehdä se.
Kerrotaan vanha tila \(f_t\):llä unohtaen asiat, jotka päätimme aiemmin unohtaa. Sitten lisäämme \(i_t*\tilde{C}_t\). Tämä on uudet ehdokasarvot skaalattuna sen mukaan, kuinka paljon päätimme päivittää kutakin tilan arvoa.
Kielimallin tapauksessa tässä vaiheessa itse asiassa pudotamme tiedon vanhan koehenkilön sukupuolesta ja lisäämme uuden tiedon, kuten päätimme edellisissä vaiheissa.

Viimeiseksi meidän on päätettävä, mitä aiomme tulostaa. Tämä tuloste perustuu solumme tilaan, mutta se on suodatettu versio. Ensin ajetaan sigmoidikerros, joka päättää, mitä osia solutilasta tulostetaan. Sitten laitamme solun tilan \(\tanh\):n läpi (työntääksemme arvot \(-1\):n ja \(1\):n välille) ja kerromme sen sigmoidiportin ulostulolla, jotta saamme tulostettua vain ne osat, jotka päätimme tulostettavaksi.
Kielimallin esimerkissä, koska se näki äsken subjektin, se saattaa haluta tulostaa tietoa, joka on relevanttia verbin kannalta, siltä varalta, että se on tulossa seuraavaksi. Se voisi esimerkiksi tulostaa, onko subjekti yksikössä vai monikossa, jotta tietäisimme, mihin muotoon verbi pitäisi konjugoida, jos se seuraa seuraavaksi.

Variantteja pitkästä lyhytkestoisesta muistista
Mitä olen tähän mennessä kuvannut, on melko normaali LSTM. Mutta kaikki LSTM:t eivät ole samanlaisia kuin edellä kuvatut. Itse asiassa näyttää siltä, että lähes jokaisessa LSTM:ää käsittelevässä artikkelissa käytetään hieman erilaista versiota. Erot ovat pieniä, mutta on syytä mainita joitakin niistä.
Eräs suosittu LSTM-muunnos, jonka Gers & Schmidhuber (2000) esitteli, on ”kurkistusreikäyhteyksien” lisääminen. Tämä tarkoittaa sitä, että annamme porttikerrosten katsoa solun tilaa.

Yllä olevassa kaaviossa lisätään kurkistusaukkoja kaikkiin portteihin, mutta monissa papereissa annetaan joitakin kurkistusaukkoja ja toisia ei.
Toinen variaatio on käyttää kytkettyjä unohdus- ja tuloportteja. Sen sijaan, että erikseen päätettäisiin, mitä unohdetaan ja mihin lisätään uutta tietoa, tehdään nämä päätökset yhdessä. Unohdamme vain silloin, kun aiomme syöttää jotain sen tilalle. Syötämme tilaan uusia arvoja vain silloin, kun unohdamme jotain vanhempaa.

Hieman dramaattisempi variaatio LSTM:stä on Cho, et al. (2014) esittelemä Gated Recurrent Unit eli GRU. Se yhdistää forget- ja input-portit yhdeksi ”päivitysportiksi”. Se myös yhdistää solun tilan ja piilotetun tilan ja tekee joitakin muita muutoksia. Tuloksena syntyvä malli on yksinkertaisempi kuin tavalliset LSTM-mallit, ja se on kasvattanut suosiotaan.

Nämä ovat vain muutamia merkittävimpiä LSTM-muunnoksia. On paljon muitakin, kuten Yao, et al. (2015) Depth Gated RNNs. On myös jokin täysin erilainen lähestymistapa käsitellä pitkän aikavälin riippuvuuksia, kuten Clockwork RNNs by Koutnik, et al. (2014).
Mikä näistä muunnelmista on paras? Onko eroilla merkitystä? Greff, et al. (2015) tekevät hienon vertailun suosituista vaihtoehdoista ja toteavat, että ne ovat kaikki suunnilleen samanlaisia. Jozefowicz, et al. (2015) testasivat yli kymmentätuhatta RNN-arkkitehtuuria ja löysivät joitakin, jotka toimivat paremmin kuin LSTM:t tietyissä tehtävissä.
Johtopäätökset
Aiemmin mainitsin huomattavia tuloksia, joita ihmiset saavuttavat RNN:ien avulla. Pohjimmiltaan kaikki nämä saavutetaan LSTM:ien avulla. Ne todella toimivat paljon paremmin useimmissa tehtävissä!
Yhtälöinä kirjoitettuna LSTM:t näyttävät melko pelottavilta. Toivottavasti niiden läpikäyminen askel askeleelta tässä esseessä on tehnyt niistä hieman helpommin lähestyttäviä.
LSTM:t olivat iso askel siinä, mitä voimme saavuttaa RNN:ien avulla. On luonnollista miettiä: onko olemassa toista suurta askelta? Yleinen mielipide tutkijoiden keskuudessa on: ”Kyllä! On olemassa seuraava askel ja se on huomio!” Ajatuksena on antaa RNN:n jokaisen askeleen valita tarkasteltava tieto jostain suuremmasta informaatiokokoelmasta. Jos esimerkiksi RNN:n avulla luodaan kuvaa kuvaava kuvateksti, se voi valita kuvan osan, jota se tarkastelee jokaisen tuottamansa sanan kohdalla. Itse asiassa Xu, et al. (2015) tekevät juuri näin – se voisi olla hauska lähtökohta, jos haluat tutkia huomiota! Huomion avulla on saatu useita todella jännittäviä tuloksia, ja näyttää siltä, että kulman takana on paljon lisää…
Huomio ei ole ainoa jännittävä säie RNN-tutkimuksessa. Esimerkiksi Kalchbrennerin, et al. (2015) Grid LSTM:t vaikuttavat erittäin lupaavilta. RNN:iä generatiivisissa malleissa käyttävät työt – kuten Gregor, et al. (2015), Chung, et al. (2015) tai Bayer & Osendorfer (2015) – vaikuttavat myös erittäin mielenkiintoisilta. Viime vuodet ovat olleet jännittävää aikaa rekursiivisille neuroverkoille, ja tulevat vuodet lupaavat olla vain jännittävämpiä!
Kiitokset
Olen kiitollinen monille ihmisille siitä, että he ovat auttaneet minua ymmärtämään LSTM:iä paremmin, kommentoineet visualisointeja ja antaneet palautetta tästä viestistä.
Olen hyvin kiitollinen kollegoilleni Googlessa hyödyllisestä palautteesta, erityisesti Oriol Vinyalsille, Greg Corradolle, Jon Shlensille, Luke Vilnisille ja Ilya Sutskeverille. Olen kiitollinen myös monille muille ystäville ja kollegoille, kuten Dario Amodeille ja Jacob Steinhardtille, jotka ovat käyttäneet aikaa auttaakseen minua. Erityisen kiitollinen olen Kyunghyun Cholle äärimmäisen huomaavaisesta kirjeenvaihdosta kaavioistani.
Ennen tätä viestiä harjoittelin LSTM:ien selittämistä kahdessa seminaarisarjassa, joita opetin neuroverkoista. Kiitos kaikille niihin osallistuneille kärsivällisyydestä minua kohtaan ja palautteesta.
-
Alkuperäisten kirjoittajien lisäksi monet ihmiset vaikuttivat nykyaikaiseen LSTM:ään. Ei-täydellinen luettelo on: Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustino Gomez, Matteo Gagliolo ja Alex Graves.
Muut viestit
Attention and Augmented Recurrent Neural Networks
On Distill
Conv Nets
A Modulaarinen näkökulma
Neuraaliverkot, Manifolds, and Topology