Viimeisin päivitetty 18.8.2020
Tietoaineistoissa voi olla puuttuvia arvoja, ja tämä voi aiheuttaa ongelmia monille koneoppimisalgoritmeille.
Niinpä on hyvä käytäntö tunnistaa ja korvata puuttuvat arvot jokaisesta sarakkeestasi syöttöaineistossasi ennen ennustustehtävän mallintamista. Tätä kutsutaan puuttuvien tietojen imputoinniksi tai lyhyesti imputoinniksi.
Suosittu lähestymistapa tietojen imputoinnissa on laskea tilastollinen arvo kullekin sarakkeelle (esimerkiksi keskiarvo) ja korvata kaikki kyseisen sarakkeen puuttuvat arvot tilastollisella arvolla. Se on suosittu lähestymistapa, koska tilasto on helppo laskea harjoitusaineiston avulla ja koska se johtaa usein hyvään suorituskykyyn.
Tässä opetusohjelmassa tutustut siihen, miten tilastollisia imputointistrategioita käytetään puuttuvien tietojen imputointiin koneoppimisessa.
Tämän opetusohjelman suoritettuasi osaat:
- Puuttuvat arvot tulee merkitä NaN-arvoilla, ja ne voidaan korvata tilastollisilla mittayksiköillä sarakkeen arvojen laskemiseksi.
- Miten ladataan CSV-arvo, jossa on puuttuvia arvoja, ja merkitään puuttuvat arvot NaN-arvoilla ja raportoidaan puuttuvien arvojen määrä ja prosenttiosuus kustakin sarakkeesta.
- Miten imputoidaan puuttuvat arvot tilastollisilla mittareilla datan valmistelumenetelmänä arvioitaessa malleja ja sovitettaessa lopullista mallia ennusteiden laatimiseksi uusille tiedoille.
Käynnistä projektisi uudella kirjallani Data Preparation for Machine Learning, joka sisältää vaiheittaiset opetusohjelmat ja Python-lähdekooditiedostot kaikille esimerkeille.
Aloitetaan.
- Päivitetty kesäkuu/2020: Muutettu esimerkkien ennustamiseen käytettävää saraketta.

Statistical Imputation for Missing Values in Machine Learning
Kuva: Bernal Saborio, jotkin oikeudet pidätetään.
Oppikirjan yleiskatsaus
Tämä opetusohjelma on jaettu kolmeen osaan; ne ovat:
- Statistical Imputation
- Horse Colic Dataset
- Statistical Imputation With SimpleImputer
- SimpleImputer Data Transform
- SimpleImputer and Model Evaluation
- Erojen imputoitujen tilastojen vertailu
- SimpleImputer-muunnos ennustetta tehtäessä
Statistinen imputointi
Aineistossa voi olla puuttuvia arvoja.
Nämä ovat tietorivejä, joissa yksi tai useampi arvo tai sarake kyseisellä rivillä ei ole. Arvot voivat puuttua kokonaan tai ne voidaan merkitä erityisellä merkillä tai arvolla, kuten kysymysmerkillä ”?”.
Nämä arvot voidaan ilmaista monella tavalla. Olen nähnyt niiden näkyvän muun muassa tyhjänä , tyhjänä merkkijonona , eksplisiittisenä merkkijonona NULL tai määrittelemättömänä tai N/A tai NaN ja numerona 0 . Riippumatta siitä, miten ne esiintyvät aineistossasi, kun tiedät, mitä odottaa, ja tarkistat, että tiedot vastaavat odotuksia, vähennät ongelmia, kun alat käyttää tietoja.
– Sivu 10, Bad Data Handbook, 2012.
Arvot voivat puuttua monista syistä, jotka ovat usein ongelmakenttäkohtaisia, ja niihin voi sisältyä syitä, kuten vioittuneet mittaukset tai tietojen saavuttamattomuus.
Häviöitä voi esiintyä useista syistä, kuten mittauslaitteiden toimintahäiriöistä, koejärjestelyjen muutoksista tiedonkeruun aikana ja useiden samankaltaisten mutta ei identtisten tietokokonaisuuksien kokoamisesta.
– Page 63, Data Mining: Practical Machine Learning Tools and Techniques, 2016.
Useimmat koneoppimisalgoritmit edellyttävät numeerisia syöttöarvoja ja arvoa jokaiselle datasetin riville ja sarakkeelle. Sinänsä puuttuvat arvot voivat aiheuttaa ongelmia koneoppimisalgoritmeille.
Sen vuoksi on yleistä tunnistaa puuttuvat arvot tietokokonaisuudesta ja korvata ne numeerisella arvolla. Tätä kutsutaan tietojen imputoinniksi tai puuttuvien tietojen imputoinniksi.
Yksi yksinkertaiseksi ja suosituksi lähestymistavaksi tietojen imputointiin kuuluu tilastollisten menetelmien käyttäminen sarakkeen arvon estimoinnissa niiden arvojen perusteella, jotka ovat olemassa, ja sitten sarakkeen kaikkien puuttuvien arvojen korvaaminen lasketulla tilastolla.
Se on yksinkertainen, koska tilastot ovat nopeita laskea, ja se on suosittu, koska se osoittautuu usein hyvin tehokkaaksi.
Yleisiä laskettavia tilastoja ovat:
- Sarakkeen keskiarvo.
- Sarakkeen mediaaniarvo.
- Sarakkeen moodiarvo.
- Vakioarvo.
Nyt kun olemme perehtyneet puuttuvien arvojen imputointiin käytettäviin tilastollisiin menetelmiin, tarkastellaanpa aineistoa, jossa on puuttuvia arvoja.
Tahdotko päästä alkuun datan esikäsittelyssä?
Kirjoita itsellesi maksuton 7-päiväinen sähköpostitse lähetettävä pikakurssini nyt (esimerkkikoodin kanssa).
Klikkaa ilmoittautuaksesi ja saat myös ilmaisen PDF-kirjaversion kurssista.
Lataa ILMAINEN minikurssisi
Hevoskoliikkitietokanta
Hevoskoliikkitietokanta kuvaa koliikkia sairastaneiden hevosten lääketieteellisiä ominaisuuksia ja sitä, jäivätkö ne eloon vai kuolivatko ne.
Tietokannassa on 300 riviä ja 26 tulomuuttujaa, joilla on yksi lähtömuuttuja. Kyseessä on binääriluokitusennustustehtävä, jossa ennustetaan 1, jos hevonen eli, ja 2, jos hevonen kuoli.
Tässä tietokokonaisuudessa on monia kenttiä, jotka voisimme valita ennustettavaksi. Tässä tapauksessa ennustamme, oliko ongelma kirurginen vai ei (sarakeindeksi 23), joten kyseessä on binäärinen luokittelutehtävä.
Tietoaineistossa on lukuisia puuttuvia arvoja monissa sarakkeissa, joissa kukin puuttuva arvo on merkitty kysymysmerkkihahmolla (”?”).
Alhaalla on esimerkki tietokokonaisuuden riveistä, joihin on merkitty puuttuvat arvot.
|
1
2
3
4
5
|
2,1,530101,38.50,66,28,3,3,?,2,5,4,4,?,?,?,3,5,45.00,8.40,?,?,2,2,11300,00000,00000,2
1,1,534817,39.2,88,20,?,?,4,1,3,4,2,?,?,?,4,2,50,85,2,2,3,2,02208,00000,00000,2
2,1,530334,38.30,40,24,1,1,3,1,3,3,1,?,?,?,1,1,33.00,6.70,?,?,1,2,00000,00000,00000,1
1,9,5290409,39.10,164,84,4,1,6,2,2,4,4,1,2,5.00,3,?,48.00,7.20,3,5.30,2,1,02208,00000,00000,1
…
|
Tietoaineistosta saat lisätietoja täältä:
- Horse Colic Dataset
- Horse Colic Dataset Description
Tietoaineistoa ei tarvitse ladata, koska lataamme sen automaattisesti työstetyissä esimerkeissä.
Puuttuvien arvojen merkitseminen NaN-arvolla (not a number) ladatussa datasetissa Pythonilla on paras käytäntö.
Voidaan ladata dataset käyttäen read_csv() Pandas-funktiota ja määrittää ”na_values” lataamaan arvot ’?
Kun data on kerran ladattu, voimme tarkastaa ladatun datan vahvistaaksemme, että ”?” -arvot on merkitty NaN:ksi.
|
1
2
3
1 2
3
|
…
# tee yhteenveto ensimmäisistä riveistä
print(dataframe.head())
|
Voidaan sitten luetella kukin sarake ja ilmoittaa niiden rivien lukumäärä, joissa sarakkeen arvot puuttuvat.
|
1
2
3
4
5
6
7
|
…
# Yhteenveto puuttuvia arvoja sisältävien rivien määrästä kunkin sarakkeen osalta
for i in range(dataframe.shape):
# laske puuttuvia arvoja sisältävien rivien määrä
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(’> %d, Puuttuvat arvot: %d (%.1f%%%)’ % (i, n_miss, perc))
|
Tämä yhteenvetona alla on täydellinen esimerkki tietokokonaisuuden lataamisesta ja yhteenvedosta.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# tiivistää hevoskoliikkitietokannan
from pandas import read_csv
# load dataset
url = ’https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# tiivistää ensimmäiset rivit
print(dataframe.head())
# tee yhteenveto niiden rivien määrästä, joissa on puuttuvia arvoja kunkin sarakkeen osalta
for i in range(dataframe.shape):
# laske puuttuvia arvoja sisältävien rivien määrä
n_miss = dataframe].isnull().sum()
perc = n_miss / dataframe.shape * 100
print(’> %d, Puuttuvat arvot: %d (%.1f%%%)’ % (i, n_miss, perc))
|
Esimerkin suorittaminen lataa ensin tietokokonaisuuden ja tekee yhteenvedon viidestä ensimmäisestä rivistä.
Voidaan nähdä, että puuttuvat arvot, jotka oli merkitty ”?”-merkillä, on korvattu NaN-arvoilla.
Seuraavaksi näemme luettelon kaikista tietokokonaisuuden sarakkeista sekä puuttuvien arvojen lukumäärän ja prosenttiosuuden.
Näemme, että joissakin sarakkeissa (esim. sarakeindeksit 1 ja 2) ei ole yhtään puuttuvaa arvoa ja toisissa sarakkeissa (esim. sarakeindeksit 15 ja 21) on paljon tai jopa suurin osa puuttuvista arvoista.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
> 0, Puuttuu: 1 (0.3%)
> 1, Missing:
> 2, Puuttuu: 0 (0.0%)
> 3, Puuttuu: 60 (20.0%)
> 4, Puuttuu:
> 5, Puuttuu: 58 (19.3%)
> 6, Puuttuu: 56 (18.7%)
> 7, Puuttuu: 69 (23.0%)
> 8, Puuttuu: 47 (15.7%)
> 9, Puuttuu: 32 (10.7%)
> 10, Puuttuu: 55 (18.3%)
> 11, Puuttuu: 44 (14.7%)
> 12, Puuttuu: 56 (18.7%)
> 13, Puuttuu: 104 (34.7%)
> 14, Puuttuu: 106 (35.3%)
> 15, Puuttuu: 247 (82.3%)
> 16, Puuttuu: 102 (34.0%)
> 17, Puuttuu: 118 (39.3%)
> 18, Puuttuu: (9,7 %)
> 19, Puuttuu: (11,0 %)
> 20, Puuttuu: 165 (55.0%)
> 21, Puuttuu: 198 (66.0%)
> 22, Puuttuu:
> 23, Puuttuu: 0 (0.0%)
> 24, Puuttuu: 0 (0.0%)
> 25, Puuttuu: 0 (0.0%)
> 26, Missing: 0 (0.0%)
> 27, Missing: 0 (0.0%)
|
Nyt kun olemme tutustuneet hevoskoliikkiaineistoon, jossa on puuttuvia arvoja, tarkastellaan, miten voimme käyttää tilastollista imputointia.
Statistical Imputation With SimpleImputer
Scikit-learn-koneoppimiskirjastossa on luokka SimpleImputer, joka tukee tilastollista imputointia.
Tässä osiossa tutkitaan, miten SimpleImputer-luokkaa käytetään tehokkaasti.
SimpleImputer-datamuunnos
SimpleImputer on datamuunnos, joka konfiguroidaan ensin kullekin sarakkeelle laskettavan tilastotyypin perusteella, esim.
Sitten imputer sovitetaan datasettiin, jotta voidaan laskea kunkin sarakkeen tilasto.
Fit-imputeria sovelletaan tämän jälkeen datasettiin, jolloin luodaan kopio datasetistä, jossa jokaisen sarakkeen kaikki puuttuvat arvot on korvattu tilastoarvolla.
Voimme havainnollistaa sen käyttöä hevoskoliikkitietokokonaisuuteen ja vahvistaa sen toimivuuden tekemällä yhteenvedon puuttuvien arvojen kokonaismäärästä tietokokonaisuudessa ennen ja jälkeen transformaation.
Kokonaisuudessaan täydellinen esimerkki on lueteltu alla.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# tilastollinen imputaatio. transform for the horse colic dataset
from numpy import isnan
from pandas import read_csv
from sklearn.impute import SimpleImputer
# load dataset
url = ’https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# splittaus input- ja output-elementteihin
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# tulosta puuttuvat yhteensä
print(’Puuttuvat: %d’ % sum(isnan(X).flatten())))
# define imputer
imputer = SimpleImputer(strategy=’mean’)
# fit on the dataset
imputer.fit(X)
# transformoi aineisto
Xtrans = imputer.transform(X)
# tulosta puuttuvien kokonaismäärä
print(’Missing: %d’ % sum(isnan(Xtrans).flatten()))
|
Esimerkin suorittaminen lataa ensin tietokokonaisuuden ja ilmoittaa tietokokonaisuuden puuttuvien arvojen kokonaismääräksi 1605.
Muunnos konfiguroidaan, sovitetaan ja suoritetaan, ja tuloksena syntyvässä uudessa tietokokonaisuudessa ei ole yhtään puuttuvaa arvoa, mikä vahvistaa, että muunnos suoritettiin odotetusti.
Jokainen puuttuva arvo korvattiin sarakkeensa keskiarvolla.
|
1
2
|
Missing: 1605
Missing: 0
|
Yksinkertainen koneoppiminen ja mallien evaluointi
Koneoppimismalleja on hyvä käytäntö evaluoida aineistolla käyttäen k-kertaista ristiinvalidointia.
Jotta tilastollista puuttuvien tietojen imputointia voidaan soveltaa oikein ja välttää tietovuotoa, vaaditaan, että kullekin sarakkeelle lasketut tilastot lasketaan vain harjoitustietokannalle, minkä jälkeen niitä sovelletaan harjoittelu- ja testijoukkoihin kunkin tietokannan kertauksen osalta.
Jos käytämme uudelleennäytteenottoa viritysparametrien arvojen valitsemiseen tai suorituskyvyn estimointiin, imputointi olisi sisällytettävä uudelleennäytteenottoon.
– Page 42, Applied Predictive Modeling, 2013.
Tämä voidaan saavuttaa luomalla mallinnusputki, jossa ensimmäinen vaihe on tilastollinen imputointi ja toinen vaihe on malli. Tämä voidaan saavuttaa käyttämällä Pipeline-luokkaa.
Esimerkiksi alla olevassa Pipeline-luokassa käytetään SimpleImputer-luokkaa, jossa on ’mean’-strategia, jonka jälkeen käytetään satunnaismetsämallia.
|
1
2
3
4
5
|
…
# define modeling pipeline
model = RandomForestClassifier()
imputer = SimpleImputer(strategy=’mean’)
pipeline = Pipeline(steps=)
|
Voidaan evaluoida keskiarvo–imputoitua tietokokonaisuutta ja satunnaismetsämallinnusputkea hevoskoliikkitietokokonaisuudelle toistetulla 10-kertaisella ristiinvalidoinnilla.
Täydellinen esimerkki on lueteltu alla.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
25
25
|
Esimerkin suorittaminen soveltaa oikein tietojen imputointia ristiinvalidointimenettelyn jokaiseen kertaukseen.
Huomautus: Tuloksesi voivat vaihdella algoritmin tai arviointimenettelyn stokastisen luonteen tai numeerisen tarkkuuden erojen vuoksi. Harkitse esimerkin suorittamista muutaman kerran ja vertaa keskimääräistä tulosta.
Putkisto on arvioitu käyttämällä kolmea 10-kertaisen ristiinvalidoinnin toistoa, ja se ilmoittaa keskimääräiseksi luokittelutarkkuudeksi aineistossa noin 86.3 prosenttia, mikä on hyvä tulos.
|
1
|
Keskimääräinen luokitustarkkuus: 0,863 (0.054)
|
Erojen imputoitujen tilastojen vertailu
Miten tiedämme, että ”keskimääräisen” tilastostrategian käyttäminen on hyvä tai paras tähän aineistoon?
Vastaus on, ettemme tiedä ja että se valittiin mielivaltaisesti.
Voidaan suunnitella koe, jossa testataan kutakin tilastollista strategiaa ja selvitetään, mikä toimii parhaiten tälle aineistolle, vertailemalla keskiarvo, mediaani, moodi (yleisin) ja vakio (0) -strategioita. Tämän jälkeen voidaan verrata kunkin lähestymistavan keskimääräistä tarkkuutta.
Kokonaisesimerkki on lueteltu alla.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
Esimerkin suorittaminen arvioi kutakin tilastollista imputointistrategiaa hevosten koliikkiaineistolla käyttäen toistuvaa ristiinvalidointia.
Huomaa: Tuloksesi voivat vaihdella algoritmin tai arviointimenettelyn stokastisen luonteen tai numeerisen tarkkuuden erojen vuoksi. Harkitse esimerkin ajamista muutaman kerran ja vertaa keskimääräistä tulosta.
Kunkin strategian keskimääräinen tarkkuus ilmoitetaan matkan varrella. Tulokset viittaavat siihen, että vakioarvon, esimerkiksi 0, käyttäminen johtaa parhaaseen tulokseen, joka on noin 88,1 prosenttia, mikä on erinomainen tulos.
|
1
2
3
4
|
>keskiarvo 0.860 (0.054)
>median 0.862 (0.065)
>most_frequent 0.872 (0.052)
>constant 0.881 (0.047)
|
Ajon lopussa jokaisesta tulossarjasta luodaan laatikko- ja whisker-kuvaaja (box and whisker plot), jonka avulla voidaan vertailla tulosten jakaumaa.
Voidaan selvästi nähdä, että vakiostrategian tarkkuuspisteiden jakauma on parempi kuin muiden strategioiden.
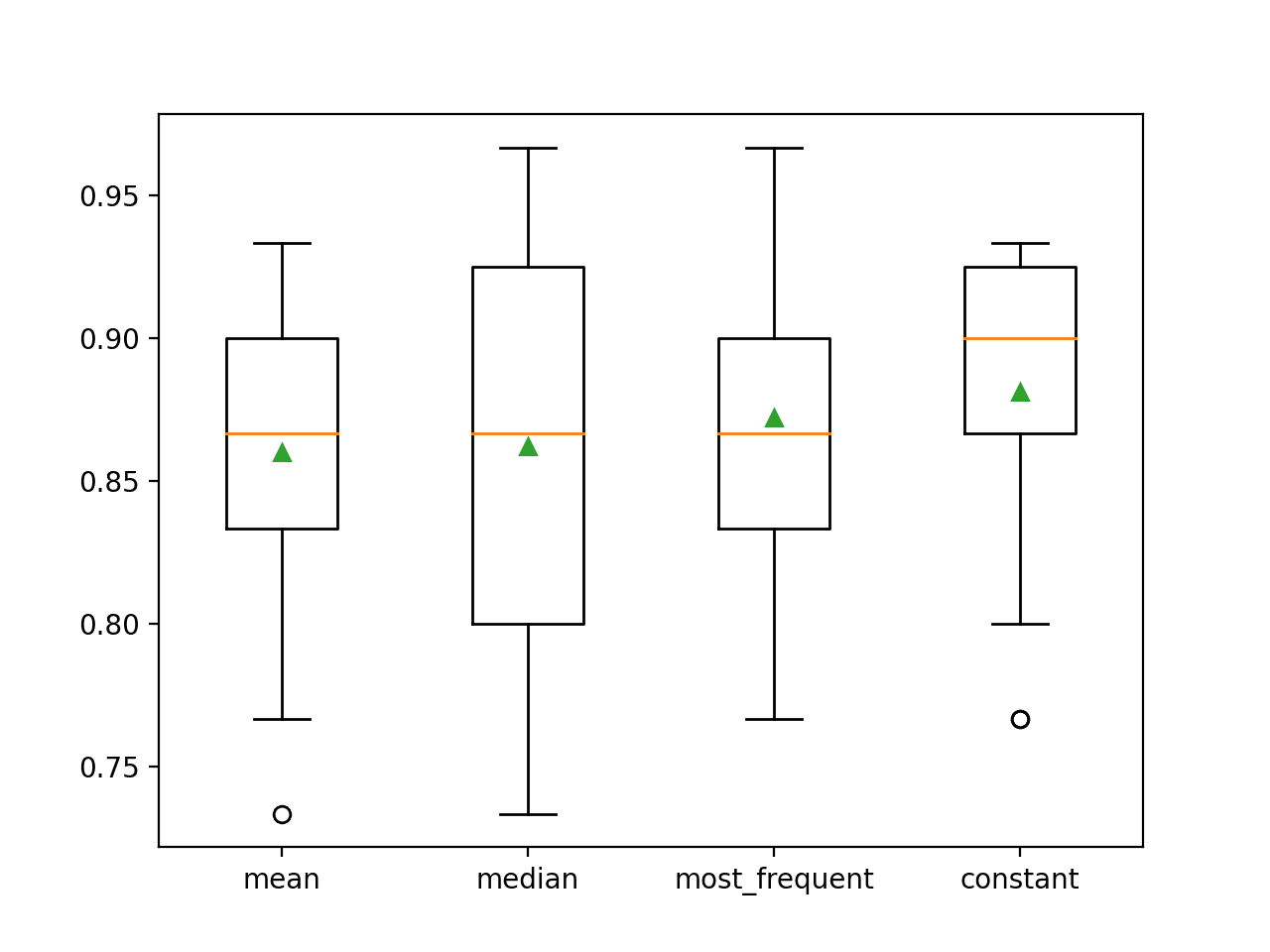
Box and Whisker Plot of Statistical Imputation Strategies Applied to the Horse Colic Dataset
SimpleImputer Transform When Making a Prediction
Haluamme ehkä luoda lopullisen mallinnusputken vakioimputointistrategialla ja satunnaismetsäalgoritmilla, minkä jälkeen teemme ennusteen uusille tiedoille.
Tämä voidaan saavuttaa määrittelemällä putki ja sovittamalla se kaikkeen käytettävissä olevaan dataan ja kutsumalla sitten predict()-funktiota syöttämällä argumenttina uutta dataa.
Tärkeää on, että uuden datan riville merkitään kaikki puuttuvat arvot käyttämällä NaN-arvoa.
|
1
2
3
|
…
# define new data
row =
|
Täydellinen esimerkki on lueteltu alla.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# vakioimputointi. strategia ja ennustaminen letkukoliikkiaineistolle
from numpy import nan
from pandas import read_csv
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# load dataset
url = ’https://raw.githubusercontent.com/jbrownlee/Datasets/master/horse-colic.csv’
dataframe = read_csv(url, header=None, na_values=’?’)
# split into input and output elements
data = dataframe.values
ix = ) if i != 23]
X, y = data, data
# luo mallinnusputki
pipeline = Pipeline(steps=)
# sovita malli
pipeline.fit(X, y)
# määritä uusi data
row =
# tee ennuste
yhat = pipeline.predict()
# summarize prediction
print(’Predicted Class: %d’ % yhat)
|
Esimerkin ajaminen sovittaa mallinnusputken kaikkeen käytettävissä olevaan dataan.
Määritellään uusi tietorivi, jossa puuttuvat arvot on merkitty NaN:llä, ja tehdään luokitusennuste.
|
1
|
Ennustettu luokka: 2
|
Lisälukemista
Tässä osiossa on lisää resursseja aiheesta, jos haluat syventyä.
Seuraavat opetusohjelmat
- Tulokset tavallisille luokittelu- ja regressiokoneoppimisen aineistoille
- How to Handle Missing Data with Python
Kirjat
- Puutteellisen datan käsikirja, 2012.
- Tiedonlouhinta: Practical Machine Learning Tools and Techniques, 2016.
- Applied Predictive Modeling, 2013.
APIs
- Imputation of missing values, scikit-learn Documentation.
- sklearn.impute.SimpleImputer API.
Dataset
- Horse Colic Dataset
- Horse Colic Dataset Description
Yhteenveto
Tässä opetusohjelmassa tutustuttiin siihen, miten tilastollisia imputointistrategioita käytetään puuttuvien tietojen imputointiin koneoppimisessa.
Kohtaisesti opit:
- Puuttuvat arvot on merkittävä NaN-arvoilla, ja ne voidaan korvata tilastollisilla mittareilla sarakkeen arvojen laskemiseksi.
- Miten ladataan CSV-arvo, jossa on puuttuvia arvoja, ja merkitään puuttuvat arvot NaN-arvoilla sekä raportoidaan puuttuvien arvojen määrä ja prosenttiosuus kunkin sarakkeen osalta.
- Miten puuttuvia arvoja imputoidaan tilastojen avulla tietojen valmistelumenetelmänä arvioitaessa malleja ja sovitettaessa lopullista mallia ennusteiden tekemiseksi uusille tiedoille.
Onko sinulla kysyttävää?
Kysy kysymyksesi alla olevissa kommenteissa, ja teen parhaani vastatakseni.
Ota käsiisi moderni datanvalmistus!

Valmista koneoppimisdatasi muutamassa minuutissa
….vain muutamalla rivillä python-koodia
Löydä miten uudessa Ebookissani:
Data Preparation for Machine Learning
Se tarjoaa itseopiskeluoppaita täydellä toimivalla koodilla:
Feature Selection, RFE, Data Cleaning, Data Transforms, Scaling, Dimensionality Reduction, ja paljon muuta…
Vie nykyaikaiset datanvalmistustekniikat
koneoppimisprojekteihisi
Katso, mitä sisällä on