GPI-ankkuroituneet proteiinit ovat outoja. Solubiologian johdantokurssilla meille opetettiin, että kalvoproteiineja on viittä eri tyyppiä, jotka on nimetty seuraavasti: Tyyppi I, tyyppi II, tyyppi III, tyyppi IV ja GPI-ankkuroituneet. Miksi meillä on tämä outo luokka proteiineja, jotka on yhdistetty sokeri- ja rasvaketjuun? Mitä ne tekevät? Voimmeko saada tietoa kiinnostukseni kohteena olevasta proteiinista – PrP:stä – oppimalla lisää tästä proteiinien luokasta, johon se kuuluu?
Sonia ja minä sekä tiimikaverimme Andrew ja olemme lukeneet aiheesta, ja kirjoitan tämän blogikirjoituksen kertoakseni osan siitä, mitä olemme oppineet.
Lukeminen
Aloitimme lukemalla muutaman katsauksen . Nämä käsittelivät enimmäkseen itse GPI-ankkurin rakennetta ja biogeneesiä, josta tiedetään hämmästyttävän paljon.
Tämä ankkuri, jonka koko nimi on glykosyylifosfatidylinositoli, ei ole monoliitti: se on yleinen kuvaus molekyylistä, jonka yksityiskohdat voivat vaihdella. Yleisesti ottaen proteiinin ω-jäännöksestä (viimeinen translaation jälkeinen jäännös) alkaen on etanoliamiinia, sitten fosfaattia, sitten joitakin sokereita, sitten fosfolipidiä. Keskeinen sokerirunko on säilynyt, mutta siitä haarautuvat sivuketjut voivat vaihdella, ja myös fosfolipidin pääryhmä ja rasvahapot voivat vaihdella. PrP:n GPI-ankkuri karakterisoitiin vuonna , mutta silloinkin se ei ole monoliitti – he tunnistivat ainakin kuusi erilaista rakennetta, jotka eroavat toisistaan sokerin sivuketjujen koostumuksen suhteen.
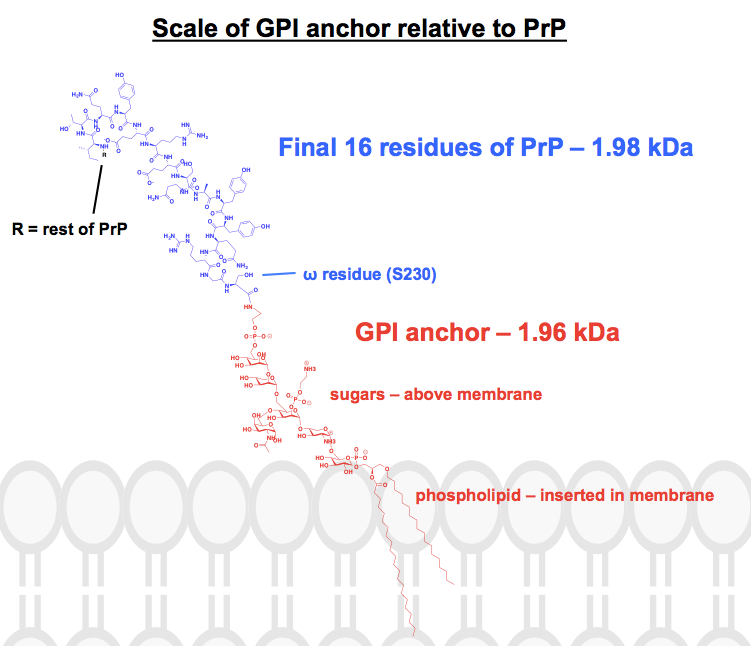
Jokaiseen löytämääni kemialliseen rakenteeseen GPI-ankkureista on ainakin joitakin osia lyhennetty tai tiivistetty, ja proteiini on yleensä esitetty vain kuvana. Halusin saada käsityksen siitä, miltä nämä ankkurit todella näyttävät kemiallisesti, niihin kiinnittyneiden proteiinien yhteydessä, joten ryhdyin itse asiassa piirtämään yhden täydellisen rakenteen ChemDraw-ohjelmalla. Lähtökohtana oli kuva 1, joka oli lähimpänä täydellistä luurankorakennetta, jonka löysin, ja lisäsin yhden PrP:n GPI-ankkurin yksityiskohdat kuvan 6 yläpaneelista. Molekyylipainoksi tuli 1 958 Da, joten kontekstin vuoksi piirsin mukaan HuPrP23-230:n viimeiset 16 jäännöstä, jotka painavat verrattain paljon, 1 979 Da. Tämä on noin 8 % PrP:n translaation jälkeen muunnetusta sekvenssistä. En ole varma, että sain kaikki sidokset oikein, mutta tässä on, mitä sain aikaan:
Monissa tapauksissa geenillä on useita isomuotoja, joista yksi liitostuote synnyttää GPI-ankkuroituneen proteiinin, kun taas toiset synnyttävät erittyvän tai transmembraanisen muodon. Esimerkkejä ovat NCAM1, jolla on kolme pääisoformia, joista yksi on GPI-ankkuroitunut ja kaksi muuta transmembraanista , ja ACHE (joka koodaa asetyylikoliiniesteraasia), jonka GPI-ankkuroitunutta muotoa esiintyy ilmeisesti vain punasoluissa (NCBI Genes). Kiehtovin tarina liittyy hiiren Ly6a-geeniin, joka geneettisen polymorfismin ansiosta on GPI-ankkuroitunut joissakin hiirikannoissa ja toisissa ei. Vain GPI-ankkuroituneessa muodossaan se toimii reseptorina AAV PHP.eB -virusvektorille (tällä vektorilla saavutetaan hämmästyttävän tehokas imeytyminen aivojen hermosoluihin geeniterapiaa varten, mutta valitettavasti se on vain hiiren geeni – meillä ihmisillä ei edes ole Ly6a:ta).
Paljon tiedetään siitä, miten GPI-ankkurit syntetisoituvat ja kiinnittyvät proteiineihin , ja reitillä on mukana >20 proteiinia, joista useimmat alkavat etuliitteellä ”PIG” ja joita koodaavat geenit, kuten PIGA, PIGK ja niin edelleen – katso kaavio kuvasta 2. Suurin osa biosynteesistä tapahtuu siten, että ankkuri on asetettu kalvoon ER:ssä mutta ei ole kiinnittynyt mihinkään proteiiniin. Itse asiassa ensimmäiset vaiheet tapahtuvat membraanin sytosolisella lehdellä, ja vasta myöhemmin ankkuri kääntyy lumenin puolelle (ER:n sisälle). Viimeisessä vaiheessa GPI-transamidaasi, joka on ainakin viidestä proteiinista koostuva kompleksi, pilkkoo GPI-signaalin pois proteiinin C-päätteestä ja kiinnittää GPI-ankkurin proteiinin niin sanottuun ω-jäännökseen (joka on viimeinen jäännös translaatiomuutoksen jälkeisessä sekvenssissä). Tämän jälkeen GPI-ankkuri kypsyy edelleen, kun proteiini siirtyy ulos ER:stä kohti solun pintaa.
Sienissä on useita pienimolekyylisiä GPI:n biosynteesin estäjiä, joista joitakin on yritetty kehittää sienilääkkeiksi, mutta käsittääkseni ainoa tunnettu nisäkässoluissa esiintyvä GPI:n biosynteesin estäjä on mannosamiini, mannoosianalogi, joka ei ole kemialliselta kannalta yhteensopiva GPI:iin sisällyttämisen kanssa.
Etsin ja etsin sekvenssilogoa siitä, minkä aminohapposekvenssimotiivin GPI-transamidaasi tunnistaa, mutta en löytänyt. Ilmeisesti sekvenssimotiivi on melko väljä , ja ilmeisesti GPI-signaalit eivät ole edes homologisia , eli ne eivät ole kehittyneet yhteisestä esi-isä-sekvenssistä, vaan pikemminkin kehittyneet konvergenssissa, sikäli kuin konvergenssia edes on. Paras kuvaus, jonka olen pystynyt löytämään, on, että (lukemalla N-C-loppupäästä proteiinin loppuun asti) tarvitaan 1) noin 11 jäämää jäsentymätöntä linkkeriä, 2) muutama jäämä, joissa on pieniä sivuketjuja, mukaan lukien ω-jäännös, joka voi olla joko S, N, D, G, A tai C, 3) 5-10 polaarista aminohappoa sisältävä spacer, ja lopuksi 4) 15-20 hydrofobista aminohappoa. PrP noudattaa löyhästi tätä mallia. Julkaistujen rakenteiden mukaan alfakierre 3 päättyy jäämään Q223, jolloin ”jäsentymättömäksi linkkeriksi” jää vain AYYQR (joka on hieman lyhyempi kuin vaaditut 11 jäämää). Pienten sivuketjujen alue olisi GS|SM (jossa putki tarkoittaa transamidaasin leikkauskohtaa), polaarinen alue olisi VLFSSPP ja hydrofobinen C-pääte olisi VILLISFLIFLIVG.
Jotkut GPI:n biosynteesi- ja kiinnittymisreitin proteiineista ovat hyvin tärkeitä, ja on kuvattu useita vakavia GPI-ankkurin puutteesta johtuvia sairauksia ja oireyhtymiä, jotka johtuvat bialleleista toimintakyvyttömyydestä tai ilmeisesti hypomorfisista missense-mutaatioista sellaisissa geeneissä kuin PIGO, PIGV, PIGW, PGAP2 ja PGAP3 .
Sonia löysi muutaman vuoden takaisen erinomaisen artikkelin, jossa he tekivät mutageeniseulan haploidisissa ihmissoluissa kahden GPI-ankkuroituneen proteiinin biogeneesiin tarvittavien geenien tunnistamiseksi: PrP ja CD59 . He käyttivät toistuvaa solujen FACS-lajittelua solupinnan PrP:n ja CD59:n perusteella tunnistaakseen solut, joissa näiden proteiinien pintatasot olivat dramaattisesti alentuneet, ja sen jälkeen he tekivät sekvensointia nähdäkseen, mitkä geenien tyrmäysgeenit olivat rikastuneet näissä soluissa verrattuna kantaväestöön. Kuten arvata saattaa, suurin osa PIG-geeneistä löytyi molempien proteiinien osalta (kuva 4), mutta kaikki osumat eivät olleet päällekkäisiä, mikä on hieman yllättävää, varsinkin kun ainakin RNA-tasolla PrP ja CD59 ovat kaksi proteiinia, joilla on samankaltaisimmat ekspressioprofiilit eri kudoksissa (ks. lämpökartta tämän viestin alaosassa). Joukko GPI-ankkurin sivuketjujen modifiointiin osallistuvia entsyymejä löytyi vain CD59:n osalta, mikä viittaa siihen, että CD59, mutta ei PrP, tarvitsee näitä monimutkaisia sivuketjuja kypsyäkseen ja päästäkseen solun pinnalle. Samaan aikaan Sec62 ja Sec63 löytyivät vain PrP:lle – nämä ovat proteiineja, jotka osallistuvat jotenkin yhteistranslationaaliseen translokaatioon ER:ään, mutta ilmeisesti niitä tarvitaan PrP:lle mutta ei CD59:lle eikä CD55:lle tai CD109:lle, kahdelle muulle tarkastellulle kontrolliproteiinille. Tämä on kiehtova uusi luku vastauksessa kysymykseeni ”onko PrP:n ilmentymisessä jotakin erityistä?”, jossa etsin PrP:n biogeneesistä jotakin ainutlaatuista, johon voitaisiin mahdollisesti kohdistaa pieni molekyyli. Tietenkään se, että nämä proteiinit eivät olleet tärkeitä kolmelle muulle kontrolliproteiinille, ei tarkoita, etteivätkö ne olisi tärkeitä – eräässä tutkimuksessa havaittiin, että Sec62:ta tarvittiin monien pienten proteiinien eritykseen , ja SEC62-geeni on ihmispopulaatiossa täysin köyhdytetty toimintakyvyttömyysvarianttien osalta, mikä riittää viitteeksi siitä, että se on haploinsuffisienssi. SEC63 vaikuttaa vähemmän rajoitetulta, vaikka se voi tarkoittaa vain sitä, että se toimii resessiivisesti.
Kään edellä mainituista ei vastaa kysymykseen siitä, miksi GPI-ankkuroituneita proteiineja on olemassa. Vanhalta solubiologian kurssiltani jäi muuten pois eräs yksityiskohta: on itse asiassa olemassa kuudes luokka kalvoproteiineja, joita kutsutaan häntään ankkuroituneiksi (TA) proteiineiksi , joilla on vain hydrofobinen C-pääte, joka työntyy kalvoon, mutta ei ulotu ulos toisella puolella. Miksi kaikki nämä GPI-ankkuroituneet proteiinit eivät voisi olla vain TA-proteiineja? Miksi solut kehittivät niin monimutkaisen reitin syntetisoidakseen sen sijaan sokeri-rasva-ankkurin, ja miksi ne kehittivät sen niin varhaisessa vaiheessa – GPI-ankkureita on kaikkialla eukaryooteissa, mukaan lukien monissa ihmisiin tarttuvissa yksisoluisissa taudinaiheuttajissa.
Useimmissa katsauksissa ei käytetä paljoa aikaa tämän kysymyksen käsittelyyn, luultavasti siksi, että se on vaikein asia vastata. Itse GPI-ankkuroituneilla proteiineilla, sikäli kuin niiden natiivit toiminnot tunnetaan, on valtavasti erilaisia tehtäviä – on entsyymejä (kuten AChE), soluadheesiomolekyylejä (kuten NCAM1), proteiineja, jotka säätelevät komplementtia immuunijärjestelmässä (CD59), ja niin edelleen . Ilmeisesti ainakin yksi GPI-ankkuroitu proteiini osallistuu myeliinin ylläpitoon ääreishermoissa . Mutta mitä GPI-ankkuroituneet proteiinit voivat tehdä, mitä muut proteiinit eivät voi? Eräässä katsauksessa mainitaan muutamia ajatuksia, joita on ehdotettu. Yksi niistä on, että GPI-ankkuroituneet proteiinit ovat hyviä ohimenevässä dimerisaatiossa . Joissakin tutkimuksissa on tutkittu ajatusta, että homodimerisaatiolla on jokin rooli prionien biologiassa, vaikka niissä käytettyjen mallijärjestelmien soveltuvuus in vivo -tilanteeseen ei ole vielä selvää. Toinen ajatus on, että koska GPI-ankkuroituneet proteiinit voivat irrota solun pinnalta esimerkiksi angiotensiinikonvertaasientsyymin (ACE) avulla, niiden lokalisaatiota voidaan säädellä jollakin dynaamisella tavalla. Tässäkin tapauksessa tiedämme, että PrP:tä voidaan irrottaa, ilmeisesti ADAM10 -entsyymin avulla, vaikkakaan sen rooli PrP:n natiivissa toiminnassa ei ole vielä selvillä. Kolmas ajatus, josta olen ehkä kuullut eniten puhuttavan, on se, että GPI-ankkuroituneet proteiinit kerääntyvät valikoivasti ”lipidilauttoihin”. Tämä on ehkä houkuttelevin selitys, koska voitaisiin kuvitella kaikenlaisia kerrannaisvaikutuksia, joissa näiden proteiinien lisääntynyt tehokas paikallinen pitoisuus mahdollistaa enemmän vuorovaikutuksia ja niin edelleen. Eräässä katsauksessa kuitenkin huomautettiin, että varoituksena on se, että lipidilautat ovat edelleen enemmän abstrakti ajatus kuin konkreettinen asia – vaikka ne määritelläänkin toiminnallisesti detergenttien liukenemattomuuden perusteella ja useimmat ihmiset kuvaavat niiden sisältävän runsaasti sfingomyeliiniä ja kolesterolia, ei ole olemassa yleisesti hyväksyttyä määritelmää siitä, mikä on ja mikä ei ole lipidilautta, ja empiiriset todisteet viittaavat siihen, että ne voivat olla paljon pienempiä ja ohimenevämpiä kuin useimmat ihmiset luulevat.
Tämän lukemani perusteella lähdin hankkimaan luetteloa näistä proteiineista ja tekemään niille analyysejä, jotta saisin paremman käsityksen siitä, millaisia ne ovat.
analyysit
Uniprotilla on luettelo 173 ihmisen GPI-ankkuroituneesta proteiinista. Nämä kuvasivat 140 geenisymbolia, jotka putosivat 135:een sen jälkeen, kun tämä skripti ajettiin päivittämään nykyisin HGNC:n hyväksymiin proteiineja koodaaviin geenisymboleihin. Lopullinen 135 geenisymbolin luettelo on tässä.
Uniprot ei tarjoa mitään tietoa siitä, miten heidän annotaationsa on luotu, vaikka manuaalista kuratointia on varmasti tehty merkittävässä määrin. Vertailun vuoksi Andrew kaivoi esiin myös sarjan siistejä artikkeleita, joissa käytettiin PI-PLD:tä tai PI-PLC:tä, kahta entsyymiä, jotka pilkkovat GPI-ankkureita, eristämään empiirisesti GPI-ankkuroituja proteiineja soluista . Yhdistämällä luettelot näistä papereista ja kartoittamalla ne nykyisiin geenisymboleihin saatiin 107 geeniä. Tarkistimme satunnaisesti useita näistä. Joukossa oli tunnettuja GPI-ankkuroituneita proteiineja, kuten glypikaani-1 (GPC1) ja hermosolujen adheesiomolekyyli (NCAM1), joilla molemmilla on raportoitu olevan vuorovaikutuksia PrP:n kanssa . Mukana oli kuitenkin myös useita geenejä, joiden GPI-ankkuroitumista ei näyttänyt kirjallisuudessa olevan tiedossa, kuten VDAC3, ja osa näistä voi olla yksinkertaisesti hyvin runsaasti esiintyviä proteiineja tai vääriä positiivisia tuloksia muista syistä. Samaan aikaan on ilmeisiä väärien negatiivisten geenien lähteitä: geenejä, jotka eivät yksinkertaisesti ilmentyneet tutkitussa solulinjassa tai joita ei ollut tarpeeksi runsaasti, jotta niitä olisi voitu havaita massaspektrometrillä, ja PrP:n paralogit SPRN ja PRND eivät olleet luetteloissa. Kaiken kaikkiaan 51 geeniä oli molemmissa luetteloissa, mikä on erittäin merkitsevä rikastuminen (OR = 217, P < 1 × 10-84), mikä auttaa vakuuttamaan minut siitä, että Uniprotin annotaatiot ovat yhdenmukaisia empiiristen tietojen kanssa. Päätimme kuitenkin jatkoanalyyseissä käyttää Uniprotin listaa, koska se vaikuttaa herkemmältä ja spesifisemmältä.
Tämän listan avulla halusin nähdä, miten GPI-ankkuroituneet proteiinit sijoittuvat. PrP on yhden eksonin pituinen, lyhyt (208 aminohappoa kypsässä muodossaan), ei-essentiaalinen, laajalti ekspressoituva proteiini. Ovatko nämä ominaisuudet tyypillisiä vai epätyypillisiä GPI-ankkuroituneelle proteiinille?
Kävi ilmi, että GPI-ankkuroituneita proteiineja on joka puolella karttaa, ja ne ovat yhtä vaihtelevia kaikilla tarkastelemillani ulottuvuuksilla kuin mikä tahansa muukin proteiinijoukko.
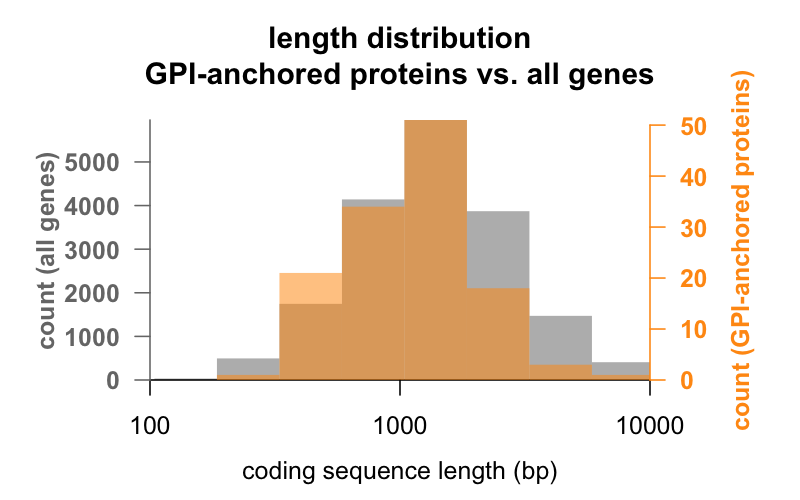
Ensiksi, pituus. Alla on päällekkäiset histogrammit koodaavan sekvenssin pituudesta emäspareina kaikkien geenien ja GPI-ankkuroituja proteiineja koodaavien geenien välillä. GPI-ankkuroituneiden jakauma on juuri ja juuri vasemmalle siirtynyt. GPI-ankkuroituneen proteiinin geenin keskimääräinen koodaussekvenssi on 1 301 bp, kun taas geenin keskiarvo on 1 729 bp, mutta tämä keskiarvojen ero on pieni verrattuna kunkin ryhmän sisäiseen vaihteluun. PrP, jonka koodaava sekvenssi on vain 762 bp, on ehdottomasti pienen puolella, vaikka se ei suinkaan ole poikkeus kummassakaan ryhmässä – CD52, jonka sekvenssi on vain 186 emäsparia ja ilmeisesti vain 12 aminohappoa kypsässä muodossaan , on pienin GPI-ankkuroitunut proteiini.
Entä eksonien lukumäärä? GPI-ankkuroiduissa proteiineissa on keskimäärin hieman vähemmän eksoneja verrattuna kaikkiin geeneihin (keskiarvo 7,8 vs. 10,1), mikä vastaa edellä mainittua pientä pituusjakaumaeroa, mutta useimmat ovat monieksonisia. Tässäkin PrP on pieni: GPI-ankkuroituneita proteiineja, joilla on vain yksi koodaava eksoni, on vain kuusi, ja niistä kolme on PrP ja sen kaksi paralogia, Sho ja Dpl. (Kolme muuta geeniä ovat GAS1, SPACA4 ja upeasti nimetty OMG).
Seuraavaksi tarkastelin toimintakyvyn menetysrajoitteita. Constraint on mitta siitä, kuinka voimakkaan luonnollisen valinnan alaisena geeni on, perustuen siihen, kuinka köyhtynyt se on esimerkiksi nonsense-, frameshift- ja liitospaikkavaihtelun suhteen yleisessä populaatiossa verrattuna mutaatiomäärään perustuvaan odotukseen. Tämä mittari ei ole kovin tulkinnanvarainen lyhyille geeneille sekä tilastollisista syistä (odotettavissa olevien mutaatioiden määrä on pieni lyhyissä geeneissä, joten köyhtymistä on vaikea kvantifioida) että biologisista syistä (yhden eksonin geenit eivät altistu nonsense-välitteiselle hajoamiselle, joten on vaikeampi tietää, ovatko proteiineja lyhentävät variantit oikeasti ”toimintahäviöitä” vai eivät). Mutta koska useimmat GPI-ankkuroituneet proteiinit eivät ole yhtä lyhyitä kuin PrP, ajattelin, että asiaa kannattaa tarkastella. Tulos: GPI-ankkuroituneet proteiinit ovat keskimäärin vain hieman vähemmän rajoittuneita, mikä tarkoittaa, että niissä on enemmän odotettavissa olevaa toimintakyvyttömyyttä aiheuttavaa variaatiota kuin keskimääräisissä geeneissä. Keskimääräisellä geenillä on 47 prosenttia toimintakyvyn heikkenemisen aiheuttamasta vaihtelusta, kun taas GPI-ankkuroituneilla proteiineilla on 56 prosenttia. Mutta kuten kaikessa tässä, molemmissa leireissä on laaja jakauma. GPI-ankkuroituneiden proteiinien osalta toisessa päässä on täysin rajoitettu ACHE (17 LoF:ää odotetaan, mutta yhtään ei ole havaittu), ja toisessa päässä on useita geenejä, jotka eivät näytä olevan lainkaan toimintakyvyn menettämisen vastaisen valinnan alaisina – CNTN6, CD109, TREH ja MSLN ovat muutamia esimerkkejä. PRNP kuuluu jälkimmäiseen leiriin, kun jätetään pois jäännökset ≥145, joissa proteiinia lyhentävät variantit aiheuttavat funktion vahvistumista.
Lopuksi mietin, missä GPI-ankkuroituneet proteiinit ilmentyvät. PRNP:tä esiintyy eniten aivoissa, mutta sitä ilmentyy kaikkialla. Onko se tyypillistä? Latasin koko GTEx v7:n ”gene median tpm” -yhteenvetotiedoston (15.1.2016), jossa jokainen rivi on geeni ja jokainen sarake on kudos ja solut ovat RPKM-arvoja – RNA-seq-lukemia eksonikiloa kohti miljoonaa kartoitettua lukemaa kohti. Työskentely tämän tietokokonaisuuden kanssa vaati hieman hienosäätöä. Olen kuullut, että jotkut bioinformaatikot pitävät <1 RPKM:ää ”ei-ekspressoituna”, mutta ekspressiomatriisi on harva – useimmat geenit eivät ekspressoidu voimakkaasti useimmissa kudoksissa – joten alle 1 RPKM:n kohina voi olla hallitsevaa, jos vain piirretään raa’at RPKM:t. Samaan aikaan geeniekspressiota on tarkasteltava logaritmisella asteikolla, sillä kudoksen geenit voivat vaihdella <1 RPKM:n ja >10 000 RPKM:n välillä, joten jos kaikkea tarkastellaan lineaarisella asteikolla, muutama todella voimakkaasti ekspressoitunut geeni/kudos-yhdistelmä voi myös dominoida, mikä saa matriisin näyttämään vieläkin harvalukuisemmalta kuin se on. Siksi otin matriisin log10-arvon ja katkaisin jakauman , joten käyttämäni violetti asteikko on 1 – 10 – 100 – 1 000 – 10 000 RPKM. Sitten otin mukaan Uniprotin GPI-ankkuroituja proteiineja. Tämän visualisoimiseksi tein lämpökartan ensimmäistä kertaa elämässäni. Olen nähnyt näitä usein papereissa, eivätkä ne yleensä puhuttele minua, mutta tässä tarkoitukseni oli vain saada käsitys ilmentymismallista, ja kun olin leikkinyt hieman, tämä antoi minulle eniten tietoa. Lämpökartan periaatteena on, että rivit ja sarakkeet ryhmitellään siten, että samanlaiset asiat menevät yhteen. Niinpä esimerkiksi kaikki aivokudoksen sarakkeet ovat peräkkäin x-akselilla ja kaikki voimakkaasti aivoissa ilmentyvät geenit ovat peräkkäin y-akselilla niin, että niiden leikkauspiste muodostaa tiheän violetin suorakulmion, jonka voidaan tulkita tarkoittavan, että ”on olemassa klusteri geenejä, jotka ilmentyvät pääasiassa aivoissa”.
Halukkaat lukijat voivat tarkastella lämpökartan täysimittaista vektoritaiteellista PDF-tiedostoa, mutta jotta se olisi välittömämmin saatavilla, tässä on käsin merkitty versio, jossa kutsutaan esiin kiinnostavat klusterit:

Vastaus on siis ei – useimmilla GPI-ankkuroituneilla proteiineilla ei ole samanlaista ilmentymismallia kuin PRNP:llä on. PRNP on yksi kourallisista voimakkaammin ja laajemmin ilmentyvistä proteiineista, ja se esiintyy lähellä tämän lämpökartan yläosaa yhdessä CD59:n, LY6E:n, GPC1:n ja BST2:n kanssa. Useimmilla GPI-ankkuroituneilla proteiineilla on vähäisempi tai enemmän kudosrajoitettu ilmentyminen, ja jotkin niistä ilmentyvät lähes yksinomaan aivoissa ja toiset eivät ilmenty lähes yksinomaan aivoissa, ja toiset pienemmät ryhmät kuuluvat pääasiassa tiettyihin kudoksiin, kuten kiveksiin, kuten PrP:n paralogi PRND, jonka tyrmääminen aiheuttaa urospuolista steriiliyttä .
johtopäätökset
GPI-ankkuroituneet proteiinit voivat olla melkein minkä kokoisia tahansa, ilmentyä melkein missä tahansa kudoksessa ja niillä voi ilmeisesti olla melkein mikä tahansa tehtävä siinä määrin kuin niiden tehtävät tunnetaan. Monilla GPI-ankkuroituneilla proteiineilla on hyvin selvät natiivit toiminnot, mutta nämä toiminnot ovat moninaisia, eikä ole selvää, miksi ne vaativat GPI-ankkuroitumista, varsinkin kun monet näistä proteiineista ovat olemassa myös muina kuin GPI-ankkuroituneina isomuotoina. Muista GPI-ankkuroituneista proteiineista, kuten PrP:stä, tiedämme aluksi vain vähän natiivista toiminnasta, joten on vaikea edes spekuloida, miksi natiivitoiminta edellyttää GPI-ankkuroitumista. Missään tekemissäni analyyseissä tai lukemissani katsauksissa ei pystytty esittämään yhtenäistä periaatetta siitä, miksi tämä ankkurointimekanismi on olemassa tai mikä saa nämä proteiinit tarvitsemaan sitä. On olemassa useita hypoteeseja siitä, miksi GPI-ankkuroituneet proteiinit ovat ainutlaatuisia, kuten lipidilautat, homodimeerit ja irtoaminen. Kaikki nämä hypoteesit saattavat pitää paikkansa. Loppujen lopuksi vastaus ei kuitenkaan näytä olevan mikään heurekahetki, vaan pikemminkin, kuten niin paljon biologiassa, proosallinen sekoitus erilaisia asioita.
R-koodi ja raakadatatiedostot tämän postauksen analyysejä varten löytyvät täältä.