Tietojen salaus levossa on nykyaikaisen internet-yrityksen ehdoton edellytys. Monet yritykset eivät kuitenkaan salaa levyjään, koska ne pelkäävät salauksen yleiskustannusten mahdollisesti aiheuttamaa suorituskyvyn heikkenemistä.
Levossa olevan datan salaaminen on elintärkeää Cloudflarelle, jolla on yli 200 datakeskusta eri puolilla maailmaa. Tässä postauksessa tutkimme levyn salauksen suorituskykyä Linuxissa ja selitämme, miten saimme sen ainakin kaksi kertaa nopeammaksi itsellemme ja asiakkaillemme!
Levossa olevan datan salaaminen
Levossa olevan datan salaamisessa on useita tapoja, joilla se voidaan toteuttaa nykyaikaisessa käyttöjärjestelmässä (OS). Käytettävissä olevat tekniikat ovat tiukasti sidoksissa käyttöjärjestelmän tyypilliseen tallennuspinoon. Yksinkertaistettu versio tallennuspinosta ja salausratkaisuista löytyy alla olevasta kaaviosta:
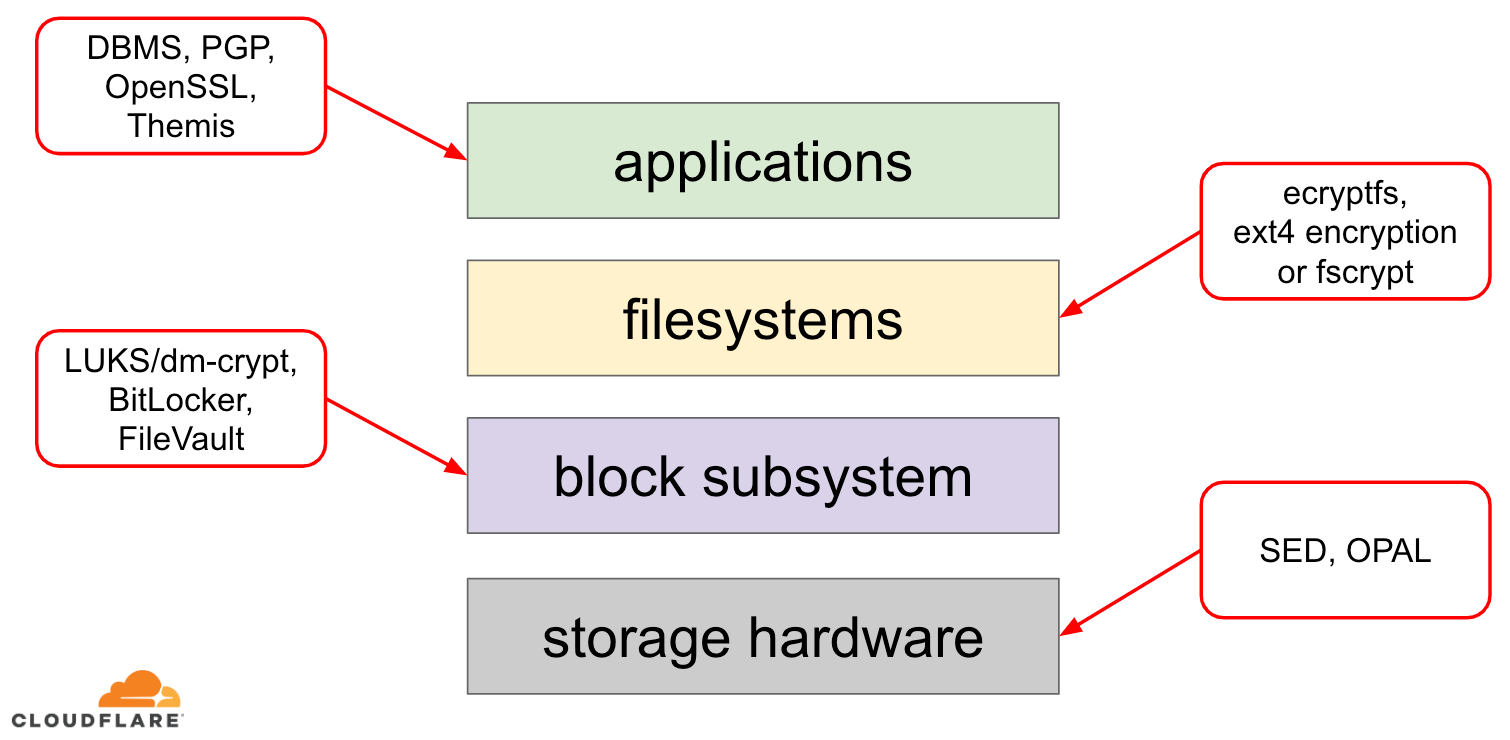
Pinon yläosassa ovat sovellukset, jotka lukevat ja kirjoittavat dataa tiedostoina (tai streameina). Käyttöjärjestelmän ytimen tiedostojärjestelmä pitää kirjaa siitä, mitkä taustalla olevan lohkolaitteen lohkot kuuluvat mihinkin tiedostoihin, ja kääntää nämä tiedostojen luku- ja kirjoitustapahtumat lohkojen luku- ja kirjoitustapahtumiksi, mutta taustalla olevan tallennuslaitteen laitteistokohtaiset erityispiirteet on abstrahoitu pois tiedostojärjestelmästä. Lopuksi lohkoalijärjestelmä siirtää lohkojen luku- ja kirjoitustoiminnot taustalla olevalle laitteistolle asianmukaisten laiteajurien avulla.
Tallennuspinon käsite on itse asiassa samankaltainen kuin tunnettu verkon OSI-malli, jossa kullakin kerroksella on korkeamman tason näkemys tiedoista ja alempien kerrosten toteutuksen yksityiskohdat on abstrahoitu ylemmiltä kerroksilta. Samoin kuin OSI-mallissa salausta voidaan soveltaa eri kerroksissa (ajattele TLS vs. IPsec tai VPN).
Levossa olevaan dataan voidaan soveltaa salausta joko lohkokerroksissa (joko laitteistossa tai ohjelmistossa) tai tiedostotasolla (joko suoraan sovelluksissa tai tiedostojärjestelmässä).
Lohko- vs. tiedostosalaus
Yleisesti mitä ylempänä varastointipinossa sovellamme salausta, sitä enemmän joustavuutta meillä on. Sovellustason salauksen avulla sovelluksen ylläpitäjät voivat soveltaa mitä tahansa haluamaansa salauskoodia mihin tahansa tiettyyn dataan, jota he tarvitsevat. Tämän lähestymistavan huonona puolena on se, että heidän on itse toteutettava se, eikä salaus yleensä ole kovin kehittäjäystävällistä: on tunnettava tietyn salausalgoritmin yksityiskohdat, luotava oikein avaimet, nonces, IV:t jne. Lisäksi sovellustason salaus ei hyödynnä käyttöjärjestelmätason välimuistitietoja eikä varsinkaan Linuxin sivuvälimuistia: joka kerta, kun sovelluksen on käytettävä dataa, sen on joko purettava se uudelleen, mikä tuhlaa suoritinsykliä, tai toteutettava oma purettu ”välimuisti”, mikä lisää koodin monimutkaisuutta.
Tiedostojärjestelmätason salaus tekee datan salauksesta läpinäkyvää sovelluksille, koska tiedostojärjestelmä salaa datan itse ennen kuin se siirretään lohko-alajärjestelmään, joten tiedostot ovat salattuja riippumatta siitä, onko sovelluksessa salausohjelmatuki vai ei. Lisäksi tiedostojärjestelmät voidaan konfiguroida salaamaan vain tietty hakemisto tai käyttää eri avaimia eri tiedostoille. Tämän joustavuuden hintana on kuitenkin monimutkaisempi konfigurointi. Tiedostojärjestelmän salausta pidetään myös vähemmän turvallisena kuin lohkolaitteiden salausta, koska vain tiedostojen sisältö salataan. Tiedostoihin liittyy myös metatietoja, kuten tiedostojen koko, tiedostojen lukumäärä, hakemistopuun rakenne jne., jotka ovat edelleen mahdollisen vastustajan nähtävissä.
Lohkokerroksessa tapahtuva salaus (jota kutsutaan usein levysalaukseksi tai koko levyn salaukseksi) tekee tietojen salauksesta läpinäkyvää myös sovelluksille ja jopa koko tiedostojärjestelmille. Toisin kuin tiedostojärjestelmätason salaus, se salaa kaiken levyllä olevan tiedon, mukaan lukien tiedostojen metatiedot ja jopa vapaan tilan. Se ei kuitenkaan ole yhtä joustava – koko levyn voi salata vain yhdellä avaimella, joten hakemisto-, tiedosto- tai käyttäjäkohtaista konfigurointia ei ole mahdollista tehdä. Salausnäkökulmasta katsottuna kaikkia salausalgoritmeja ei voida käyttää, koska lohkokerroksella ei ole enää korkean tason yleiskuvaa datasta, joten sen on käsiteltävä jokainen lohko itsenäisesti. Useimmat yleiset algoritmit edellyttävät jonkinlaista lohkoketjua ollakseen turvallisia, joten niitä ei voida soveltaa levysalaukseen. Sen sijaan erityisiä tiloja kehitettiin juuri tätä erityistapausta varten.
Minkä kerroksen siis valita? Kuten aina, se riippuu… Sovellus- ja tiedostojärjestelmätason salaus on yleensä suositeltavin valinta asiakasjärjestelmiin joustavuuden vuoksi. Esimerkiksi monikäyttäjätyöpöydän jokainen käyttäjä voi haluta salata kotihakemistonsa omalla avaimellaan ja jättää joitakin jaettuja hakemistoja salaamatta. Sitä vastoin palvelinjärjestelmissä, joita hallinnoivat SaaS/PaaS/IaaS-yritykset (mukaan lukien Cloudflare), ensisijainen valinta on konfiguroinnin yksinkertaisuus ja turvallisuus – kun koko levyn salaus on käytössä, minkä tahansa sovelluksen kaikki tiedot salataan automaattisesti ilman poikkeuksia tai ohituksia. Mielestämme kaikki tiedot on suojattava lajittelematta niitä ”tärkeisiin” vs. ”ei-tärkeisiin” ämpäreihin, joten ylempien kerrosten tarjoamaa valikoivaa joustavuutta ei tarvita.
Kalusto- vs. ohjelmistokiekkosalaus
Tietoja lohkokerroksessa salattaessa on mahdollista tehdä salaus suoraan tallennuslaitteistossa, jos laitteisto tukee sitä. Tämä antaa yleensä paremman luku- ja kirjoitussuorituskyvyn ja kuluttaa vähemmän resursseja isäntäkoneelta. Koska suurin osa laitteiston laiteohjelmistoista on kuitenkin patentoituja, tietoturvayhteisö ei kiinnitä siihen niin paljon huomiota eikä tarkastele sitä yhtä paljon. Aiemmin tämä on johtanut siihen, että joissakin laitteistokiekon salauksen toteutuksissa on ollut puutteita, jotka ovat tehneet koko turvallisuusmallista käyttökelvottoman. Esimerkiksi Microsoft on sittemmin alkanut suosia ohjelmistopohjaista levysalausta.
Me emme halunneet altistaa tietojamme ja asiakkaidemme tietoja riskille käyttää mahdollisesti turvattomia ratkaisuja, ja uskomme vahvasti avoimeen lähdekoodiin. Siksi luotamme vain Linux-ytimen ohjelmistolliseen levysalaukseen, joka on avoin ja jonka monet tietoturva-ammattilaiset ympäri maailmaa ovat tarkastaneet.
Linux-levysalauksen suorituskyky
Tavoitteenamme ei ole ainoastaan säästää kaistanleveyskustannuksia asiakkaillemme, vaan myös toimittaa sisältöä internetin käyttäjille mahdollisimman nopeasti.
Jossain vaiheessa huomasimme, että levymme eivät olleet niin nopeita kuin haluaisimme niiden olevan. Muutama profilointi sekä nopea A/B-testi viittasivat Linux-levyn salaukseen. Koska tietojen salaamatta jättäminen (vaikka niiden pitäisi olla julkista internetin välimuistia) ei ole kestävä vaihtoehto, päätimme tutkia tarkemmin Linux-levyn salauksen suorituskykyä.
Device mapper ja dm-crypt
Linux toteuttaa läpinäkyvän levyn salauksen dm-crypt-moduulin avulla, ja dm-crypt itsessään on osa device mapperin kernel-kehystä. Lyhyesti sanottuna device mapper mahdollistaa IO-pyyntöjen esi- ja jälkikäsittelyn, kun ne kulkevat tiedostojärjestelmän ja taustalla olevan lohkolaitteen välillä.
dm-crypt salaa erityisesti ”kirjoitus”-IO-pyynnöt, ennen kuin ne lähetetään pinoa alemmas varsinaiseen lohkolaitteeseen, ja purkaa ”luku”-IO-pyynnöt, ennen kuin ne lähetetään ylöspäin tiedostojärjestelmäajurille. Yksinkertaista ja helppoa! Vai onko?
Benchmarking-asetukset
Lukemat tässä postauksessa saatiin suorittamalla tietyt komennot tyhjäkäynnillä olevalla Cloudflare G9 -palvelimella, joka ei ole tuotannossa. Asetelman pitäisi kuitenkin olla helposti toistettavissa millä tahansa nykyaikaisella x86-kannettavalla tietokoneella.
Kaiken tallennuspinon ympärillä tapahtuvan vertailuanalyysin tekeminen on yleensä vaikeaa itse tallennuslaitteiston aiheuttaman kohinan vuoksi. Kaikki levyt eivät ole samanarvoisia, joten tässä postauksessa käytämme nopeinta saatavilla olevaa levyä – eli ei levyjä.
Sen sijaan Linuxissa on mahdollisuus emuloida levy suoraan RAM-muistissa. Koska RAM-muisti on paljon nopeampaa kuin mikään pysyvä tallennusmuisti, sen pitäisi tuoda vain vähän harhaa tuloksiimme.
Seuraavalla komennolla luodaan 4GB:n ramdisk:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Nyt voimme perustaa dm-crypt-instanssin sen päälle mahdollistaen näin levyn salauksen. Ensin meidän on luotava levyn salausavain, ”formatoitava” levy ja määritettävä salasana, jolla vastikään luotu avain avataan.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:Ne, jotka tuntevat LUKS/dm-crypt:n, ovat ehkä huomanneet, että käytimme tässä LUKS:n irrotettua otsikkoa. Normaalisti LUKS tallentaa salasanalla salatun levyn salausavaimen samalle levylle kuin tiedot, mutta koska haluamme verrata luku- ja kirjoitussuorituskykyä salattujen ja salaamattomien laitteiden välillä, saatamme vahingossa korvata salatun avaimen myöhemmin suoritettavan vertailuanalyysin aikana. Salatun avaimen pitäminen erillisessä tiedostossa välttää tämän ongelman tässä postauksessa.
Nyt voimme itse asiassa ”avata” salatun laitteen testausta varten:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0Tässä vaiheessa voimme nyt verrata salatun ja salaamattoman ramdisk-levyn suorituskykyä: jos luemme/kirjoitamme dataa osoitteeseen /dev/ram0, se tallentuu selväkielisenä. Vastaavasti, jos luemme/kirjoitamme dataa /dev/mapper/encrypted-ram0:lle, se puretaan/salataan matkalla dm-crypt:lla ja tallennetaan salatekstinä.
On syytä huomata, että emme luo mitään tiedostojärjestelmää lohkolaitteidemme päälle, jotta vältämme vääristämästä tuloksia tiedostojärjestelmän yleiskustannuksilla.
Läpäisytehon mittaaminen
Tallennuksen testauksessa/benchmarkingissa Flexible I/O tester on tavallinen ratkaisu. Simuloidaan yksinkertaista sekventiaalista luku-/kirjoituskuormitusta 4K-lohkokoolla ramdiskillä ilman salausta:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%Ylläoleva komento pyörii pitkään, joten pysäytämme sen hetken kuluttua. Kuten voimme nähdä tilastoista, pystymme lukemaan ja kirjoittamaan suunnilleen samalla läpimenoteholla noin 1126 MB/s. Toistetaan testi salatun ramdiskin kanssa:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecWhoa, se on pudotus! Saamme nyt vain ~147 MB/s, joka on yli 7 kertaa hitaampi! Ja tämä täysin tyhjäkäynnillä olevalla koneella!
Mahdollisesti salaus on vain hidas
Harkitsimme ensimmäiseksi, että käytämme nopeinta salausmenetelmää. cryptsetup avulla voimme vertailla kaikkia järjestelmässä käytettävissä olevia kryptototeutuksia ja valita niistä parhaan:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/ANäyttää siltä, että aes-xts 256-bittisellä tiedon salausavaimella on tässä nopein. Mutta mitä oikeastaan käytämme salattuun ramdiskiin?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0Käytämme aes-xts 256-bittisellä datan salausavaimella (laske kaikki nollat, jotka on kätevästi peitetty dmsetup-työkalulla – jos haluat nähdä todelliset tavut, lisää yllä olevaan komentoon --showkeys-valinta). Numerot eivät kuitenkaan täsmää: cryptsetup benchmark käskee meitä edellä olemaan luottamatta tuloksiin, koska ”Testit ovat likimääräisiä käyttäen vain muistia (ei tallennuksen IO:ta)”, mutta juuri näin olemme asettaneet kokeilumme käyttäen ramdiskiä. Hieman huonommassa tapauksessa (olettaen, että luemme kaiken datan ja sitten salaamme/purkamme sen peräkkäin ilman rinnakkaisuutta), kun teemme back-of-the-envelope-laskennan, meidän pitäisi saada noin (1126 * 1823) / (1126 + 1823) =~696 MB/s, mikä on silti melko kaukana todellisesta 147 * 2 = 294 MB/s:stä (lukemisten ja kirjoittamisten summa).
dm-crypt performance flags
Lukiessamme cryptsetupin man-sivua huomasimme, että siinä on kaksi optiota, joiden etuliitteenä on --perf- ja jotka todennäköisesti liittyvät suorituskyvyn virittämiseen. Ensimmäinen on --perf-same_cpu_crypt, jolla on melko kryptinen kuvaus:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Siten otamme vaihtoehdon käyttöön
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Huomautus: viimeisimmän man-sivun mukaan on olemassa myös cryptsetup refresh-komento, jolla nämä vaihtoehdot voidaan ottaa käyttöön livenä ilman, että salattua laitetta tarvitsee ”sulkea” ja ”avata” uudelleen. Meidän cryptsetup ei kuitenkaan vielä tukenut sitä.
Varmennetaan, onko optio todella otettu käyttöön:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptKyllä, näemme nyt same_cpu_crypt tulosteessa, mitä halusimme. Suoritetaan vertailuarvo uudelleen:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, nyt se on ~136 MB/s, mikä on hieman huonompi kuin aiemmin, joten ei hyvä. Entäpä toinen vaihtoehto --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Mahdollisesti olemme tässä ”jonkinlaisessa tilanteessa”, joten kokeillaan sitä:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusJa nyt vertailuarvo:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, joka on hiukan parempi, mutta ei silti hyvä…
Kysyimme yhteisöltä
Ollessamme epätoivoisia päätimme hakea tukea internetistä ja lähetimme havaintomme dm-crypt-postituslistalle, mutta saamamme reaktio ei ollut kovin rohkaiseva:
Jos luvut häiritsevät sinua, niin tämä johtuu ymmärryksen puutteesta sinun puoleltasi. Et luultavasti ole tietoinen siitä, että salaus on raskas operaatio…
Päätimme tehdä tieteellisen tutkimuksen aiheesta kirjoittamalla Google-hakuun ”is encryption expensive”, ja yksi kärkituloksista, joka oikeasti sisältää mielekkäitä mittaustuloksia, on… oma postauksemme salauskustannuksista, mutta TLS:n kontekstissa! Tämä on kiehtovaa luettavaa sinänsä, mutta ydin on seuraava: nykyaikainen salaus nykyaikaisella laitteistolla on erittäin halpaa jopa Cloudflaren mittakaavassa (miljoonia salattuja HTTP-pyyntöjä sekunnissa). Itse asiassa se on niin halpaa, että Cloudflare oli ensimmäinen palveluntarjoaja, joka tarjosi ilmaisen SSL/TLS:n kaikille.
Lähdekoodin tutkiminen
Kun yritimme käyttää edellä kuvattuja mukautettuja dm-crypt -vaihtoehtoja, olimme uteliaita siitä, miksi ne ylipäätään ovat olemassa ja mistä tuossa ”offloadingissa” on kyse. Alunperin odotimme dm-crypt:n olevan yksinkertainen ”proxy”, joka vain salaa/purkaa dataa sen kulkiessa pinon läpi. Kävi ilmi, että dm-crypt tekee muutakin kuin vain salaa muistipuskureita, ja alla on esitetty (yksinkertaistettu) IO-kulkupolun kaavio:

Kun tiedostojärjestelmä lähettää kirjoituspyynnön, dm-crypt ei käsittele sitä heti – sen sijaan se laittaa sen työjonoon nimeltä ”kcryptd”. Lyhyesti sanottuna ytimen työjono vain aikatauluttaa jonkin työn (tässä tapauksessa salauksen) suoritettavaksi myöhemmin, kun se on sopivampaa. Kun ”aika” koittaa, dm-crypt lähettää pyynnön Linux Crypto API:lle varsinaista salausta varten. Nykyaikainen Linux Crypto API on kuitenkin myös asynkroninen, joten riippuen siitä, mitä toteutusta järjestelmäsi käyttää, pyyntöä ei todennäköisesti käsitellä heti, vaan se asetetaan uudelleen jonoon ”myöhempää aikaa” varten. Kun Linux Crypto API lopulta suorittaa salauksen, dm-crypt voi yrittää lajitella vireillä olevat kirjoituspyynnöt laittamalla jokaisen pyynnön puna-mustaan puuhun. Sitten erillinen ytimen säie taas ”joskus myöhemmin” todella ottaa kaikki IO-pyynnöt puusta ja lähettää ne alaspäin pinossa.
Nyt lukupyynnöt: tällä kertaa meidän on saatava salattu data ensin laitteistosta, mutta dm-crypt ei vain kysy ajurilta dataa, vaan jonottaa pyynnön eri työjonoon nimeltä ”kcryptd_io”. Jossain vaiheessa myöhemmin, kun meillä todella on salattua dataa, ajoitamme sen purettavaksi käyttäen nyt tuttua ”kcryptd”-työjonoa. ”kcryptd” lähettää pyynnön Linux Crypto API:lle, joka voi purkaa datan myös asynkronisesti.
Ollaksemme reiluja pyyntö ei aina kulje kaikkien näiden jonojen läpi, mutta tärkeää tässä on se, että kirjoituspyynnöt voidaan asettaa jonoon jopa neljä kertaa dm-crypt ja lukupyynnöt jopa kolme kertaa. Tässä vaiheessa mietimme, voiko tämä ylimääräinen jonotus aiheuttaa suorituskykyongelmia. Googlella on esimerkiksi hieno esitys jonottamisen ja jälkiviiveen välisestä suhteesta. Yksi esityksen tärkeimmistä poiminnoista on:
Merkittävä osa häntäviiveistä johtuu jonotusvaikutuksista
Miksi sitten kaikki nämä jonot ovat olemassa ja voimmeko poistaa ne?
Git-arkeologiaa
Kukaan ei kirjoita monimutkaisempaa koodia huvikseen, varsinkaan käyttöjärjestelmän ytimelle. Joten kaikki nämä jonot on täytynyt laittaa sinne jostain syystä. Onneksi Linux-ytimen lähdekoodia hallinnoi git, joten voimme yrittää jäljittää muutoksia ja niiden ympärillä tehtyjä päätöksiä.
Työjono ”kcryptd” oli lähdekoodissa saatavilla olevan historian alusta lähtien seuraavalla kommentilla:
Tarvitaan, koska olisi hyvin epäviisasta tehdä salauksen purku keskeytyskontekstissa, joten lukupyynnöistä palaavat biosit asetetaan tänne jonoon.
Se oli siis vain lukukontekstia varten, mutta silloinkin – miksi välitämme siitä, onko se keskeytyskontekstissa vai ei, jos Linux Crypto API käyttää todennäköisesti joka tapauksessa omaa säiettä/jonoa salaukseen? No, vuonna 2005 Crypto API ei ollut asynkroninen, joten tämä oli täysin järkevää.
Vuonna 2006 dm-crypt alettiin käyttää ”kcryptd”-työjonoa salauksen lisäksi myös IO-pyyntöjen lähettämiseen:
Tämän korjauksen tarkoituksena on auttaa dm-cryptiä noudattamaan uusia rajoitteita, jotka on asetettu seuraavassa -mm:n korjauksessa: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Näyttää siltä, että tämän tavoitteena ei ollut lisätä rinnakkaisuutta, vaan pikemminkin vähentää ytimen pinon käyttöä, mikä on taas järkevää, koska ytimellä on yhteinen pino kaikelle koodille, joten se on melko rajallinen resurssi. Kannattaa kuitenkin huomata, että Linux-ytimen pinoa on laajennettu vuonna 2014 x86-alustoille, joten tämä ei ehkä ole enää ongelma.
Ensimmäinen versio ”kcryptd_io”-työjonosta lisättiin vuonna 2007 tarkoituksenaan välttää:
nälänhätä, joka aiheutuu siitä, että monet pyynnöt odottavat muistin allokaatiota…
Pyyntöjen käsittely oli pullonkaulana yhdelle työjonolle tässä, joten ratkaisuna oli lisätä toinen. Kuulostaa järkevältä.
Me emme todellakaan ole ensimmäisiä, jotka kokevat suorituskyvyn heikkenemistä laajan jonottamisen takia: vuonna 2011 otettiin käyttöön muutos, joka palautti ehdollisesti osan lukupyyntöjen jonottamisesta:
Jos muistia riittää, koodi voi suoraan lähettää biota sen sijaan, että tämä operaatio asetettaisiin jonoon erilliseen säikeeseen.
Pahaksi onnettomuudeksi tuohon aikaan Linux-ytimen commit-viestit eivät olleet niin sanatarkkoja kuin nykyään, joten suorituskykydataa ei ole saatavilla.
Vuonna 2015 dm-crypt alkoi lajitella kirjoituksia erillisessä ”dmcrypt_write”-säikeessä, ennen kuin ne lähetetään pinoa alaspäin:
Moniprosessorikoneessa salauspyynnöt päättyvät eri järjestyksessä kuin ne lähetettiin. Näin ollen kirjoituspyynnöt lähetettäisiin eri järjestyksessä, ja se voisi aiheuttaa vakavaa suorituskyvyn heikkenemistä.
Se on järkevää, koska sekventiaalinen levykäyttö oli ennen paljon nopeampaa kuin satunnainen, ja dm-crypt rikkoi tämän mallin. Mutta tämä koskee lähinnä pyöriviä levyjä, jotka olivat hallitsevia vielä vuonna 2015. Se ei ehkä ole yhtä tärkeää nykyaikaisilla nopeilla SSD-levyillä (mukaan lukien NVME SSD-levyt).
Toinen osa commit-viestistä on mainitsemisen arvoinen:
…erityisesti se mahdollistaa CFQ:n kaltaisten IO-järjestelijöiden lajittelun tehokkaammin…
Se mainitsee suorituskykyhyötyjä CFQ:n IO-järjestelijän kohdalla, mutta Linux-järjestelijät ovat parantuneet sen jälkeen siinä määrin, että CFQ-järjestelijä poistettiin ytimestä vuonna 2018.
Sama korjaussarja korvaa lajittelulistan punamustalla puulla:
Teoriassa lajittelun pitäisi tapahtua taustalla olevan levynsuunnittelijan toimesta, mutta käytännössä levynsuunnittelija ottaa vastaan ja lajittelee vain rajallisen määrän pyyntöjä. Jotta kaikkien pyyntöjen lajittelu olisi mahdollista, dm-cryptin on toteutettava oma lajittelunsa.
Rbtree-pohjaiseen lajitteluun liittyvää yleiskustannusta pidetään merkityksettömänä, joten sitä ei käytetä ehdollisesti.
Kaikki nämä ovat järkeviä, mutta olisi kiva saada taustatietoja.
Kiinnostavaa kyllä, samassa patchsetissä näemme tutun ”submit_from_crypt_cpus”-vaihtoehtomme käyttöönoton:
On joitain tilanteita, joissa kirjoitusbiosien purkaminen salaussäikeiltä yhdelle säikeelle heikentää suorituskykyä merkittävästi
Kokonaisuutena voimme nähdä, että jokainen muutos oli järkevä ja tarpeellinen, mutta asiat ovat kuitenkin muuttuneet sen jälkeen:
- hardware muuttui nopeammaksi ja älykkäämmäksi
- Linuxin resurssien jakoa tarkistettiin uudelleen
- kytketyt Linuxin osajärjestelmät arkkitehtuuria muutettiin
Ja monet edellä esitetyistä suunnitteluvalinnoista eivät välttämättä ole sovellettavissa nykypäivän Linuxiin.
”siivous”
Yllä olevan tutkimuksen perusteella päätimme yrittää poistaa kaiken ylimääräisen jonottamisen ja asynkronisen käyttäytymisen ja palauttaa dm-crypt sen alkuperäiseen käyttötarkoitukseen: yksinkertaisesti salata/purkata IO-pyynnöt niiden kulkiessa. Vakauden ja jatkuvan vertailuanalyysin vuoksi emme kuitenkaan poistaneet varsinaista koodia, vaan lisäsimme vielä yhden dm-crypt-vaihtoehdon, joka ohittaa kaikki jonot/säikeet, jos se on käytössä. Lipun avulla voimme vaihtaa nykyisen ja uuden käyttäytymisen välillä ajonaikana täydessä tuotantokuormituksessa, joten voimme helposti perua muutoksemme, jos havaitsemme sivuvaikutuksia. Tuloksena syntynyt korjaus löytyy Cloudflaren GitHub Linux-arkistosta.
Synkronous Linux Crypto API
Yllä olevasta kaaviosta muistamme, että kaikkea jonotusta ei ole toteutettu dm-crypt:ssa. Nykyaikainen Linux Crypto API voi olla myös asynkroninen ja tämän kokeilun vuoksi haluamme poistaa jonot myös sieltä. Mitä ”saattaa olla” kuitenkin tarkoittaa? Käyttöjärjestelmässä voi olla erilaisia toteutuksia samasta algoritmista (esimerkiksi laitteistokiihdytetty AES-NI x86-alustoilla ja yleiset C-koodin AES-toteutukset). Oletusarvoisesti järjestelmä valitsee ”parhaan” määritetyn algoritmin prioriteetin perusteella. dm-crypt mahdollistaa tämän käyttäytymisen ohittamisen ja tietyn salaustoteutuksen pyytämisen etuliitteen capi: avulla. Tässä on kuitenkin yksi ongelma. Tarkistetaanpa itse asiassa järjestelmässämme käytettävissä olevat AES-XTS-toteutukset (tämä on levysalakirjoitussalakirjoituksemme, muistatko?):
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64Haluamme eksplisiittisesti valita synkronisen salakirjoitussalakirjoituksen yllä olevasta luettelosta välttyäksemme jonovaikutuksilta säikeissä, mutta ainoat tuetut toteutukset ovat xts(ecb(aes-generic)) (yleinen C-toteutus) ja __xts-aes-aesni (x86-laitteiston kiihdyttämä toteutus). Haluamme ehdottomasti jälkimmäisen, koska se on paljon nopeampi (pyrimme tässä suorituskykyyn), mutta se on epäilyttävästi merkitty sisäiseksi (katso internal: yes). Jos tarkistamme lähdekoodin:
Merkitään salakirjoitus palvelutoteutukseksi, jota voi käyttää vain toinen salakirjoitus, eikä koskaan normaali ytimen krypto-API:n käyttäjä
Tämä salakirjoitus on siis tarkoitettu käytettäväksi vain muussa krypto-API:n wrapper-koodissa, ei sen ulkopuolella. Käytännössä tämä tarkoittaa sitä, että Crypto API:n kutsujan on määriteltävä tämä lippu eksplisiittisesti pyytäessään tiettyä salakirjoitustoteutusta, mutta dm-crypt ei tee sitä, koska se ei suunnittelunsa puolesta ole osa Linuxin Crypto API:ta, vaan ”ulkopuolinen” käyttäjä. Korjaamme jo dm-crypt-moduulin, joten voisimme yhtä hyvin vain lisätä asiaankuuluvan lipun. Erityisesti AES-NI:ssä on kuitenkin toinenkin ongelma: x86 FPU. ”Floating point” sanoitko? Miksi tarvitsemme liukulukumatematiikkaa symmetriseen salaukseen, jossa pitäisi olla kyse vain bittisiirroista ja XOR-operaatioista? Emme tarvitse matematiikkaa, mutta AES-NI-käskyt käyttävät joitakin prosessorin rekistereitä, jotka on varattu FPU:lle. Valitettavasti Linux-ydin ei aina säilytä näitä rekistereitä keskeytyskontekstissa suorituskykysyistä (FPU:n tallentaminen/palauttaminen on kallista). Mutta dm-crypt voi suorittaa koodia keskeytyskontekstissa, joten vaarana on jonkin muun prosessin datan korruptoituminen ja palaamme alkuperäisen koodin ”olisi hyvin epäviisasta tehdä salauksen purku keskeytyskontekstissa” -lausumaan.
Ratkaisumme edellä mainittuun ongelmaan oli luoda toinen jokseenkin ”älykäs” Crypto API -moduuli. Tämä moduuli on synkroninen eikä se rullaa omaa kryptoaan, vaan on vain salauspyyntöjen ”reititin”:
- jos voimme käyttää FPU:ta (ja siten AES-NI:tä) nykyisessä suorituskontekstissa, ohjaamme salauspyynnön vain eteenpäin nopeampaan, ”sisäiseen”
__xts-aes-aesnitoteutukseen (ja voimme käyttää sitä tässä, koska nyt olemme osa Crypto API:ta) - muussa tapauksessa välitämme salauspyynnön hitaampaan, yleiseen C-pohjaiseen
xts(ecb(aes-generic))-toteutukseen
Kokonaistoteutuksen käyttäminen
Kävellään läpi koko prosessin käyttö yhdessä. Ensimmäinen askel on napata korjaukset ja kääntää ydin uudelleen (tai kääntää vain dm-crypt ja meidän xtsproxy-moduulimme).
Seuraavaksi käynnistetään IO-työkuorma uudelleen erillisessä päätelaitteessa, jotta voimme varmistaa, että voimme konfiguroida ytimen uudelleen ajon aikana kuormituksen alaisena:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Pääterminaalissa varmista, että uusi Crypto API -moduulimme on ladattu ja käytettävissä:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Konfiguroi salattu levy uudelleen käyttämään juuri ladattua moduuliamme ja ota käyttöön korjattu dm-crypt-lippumme (meidän on käytettävä matalan tason dmsetup-työkalua, koska cryptsetup ei ilmeisesti ole tietoinen muutoksistamme):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Me juuri ”latasimme” uuden konfiguraation, mutta jotta se astuisi voimaan, meidän on keskeytettävä/jatkettava salatun laitteen käyttöä:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0Ja nyt tarkkaile tulosta. Voimme palata toiseen päätelaitteeseen, jossa ajetaan fio-tehtävää, ja tarkastella tulostetta, mutta mukavuuden vuoksi tässä on tilannekuva Grafanassa havaitusta luku-/kirjoitusläpimenosta:
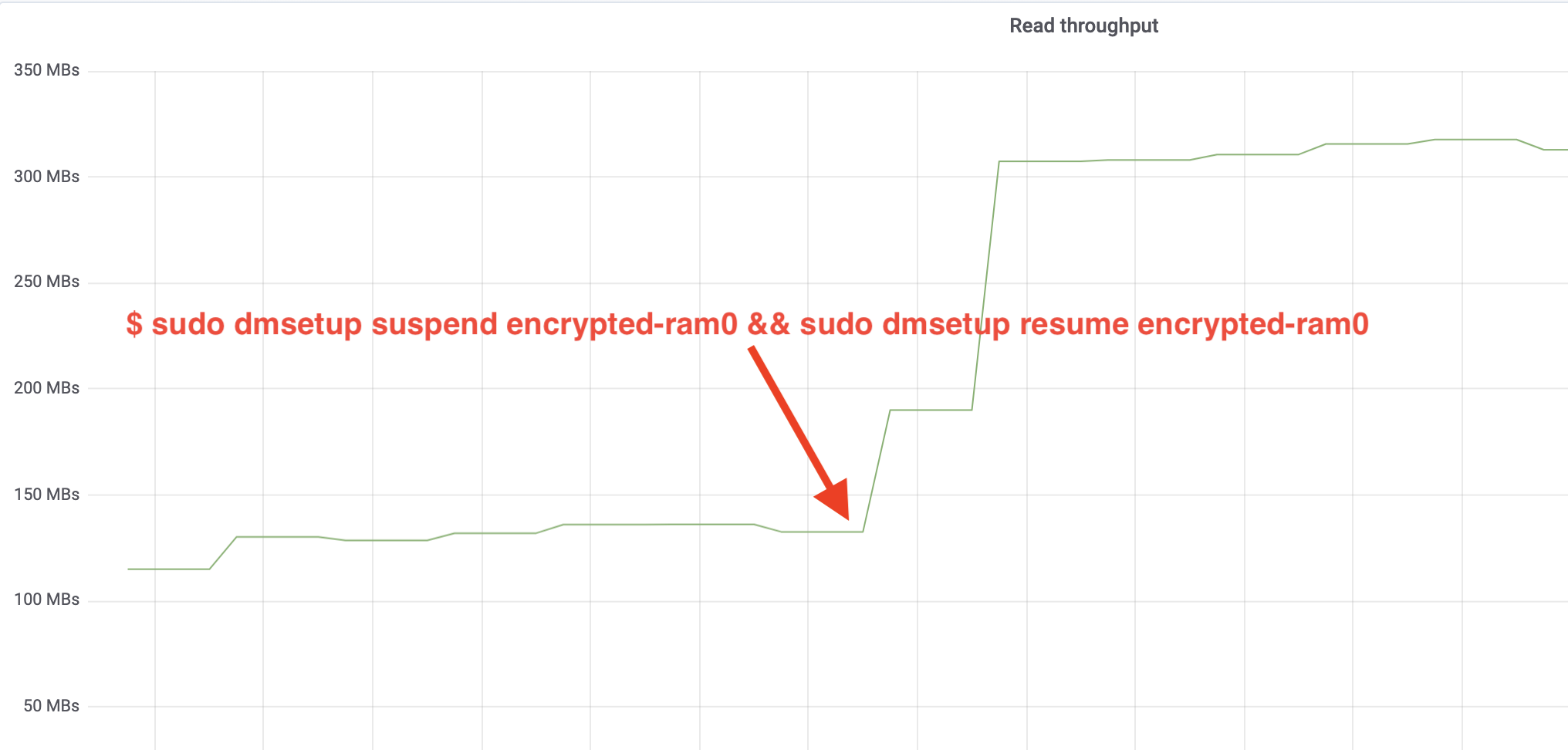
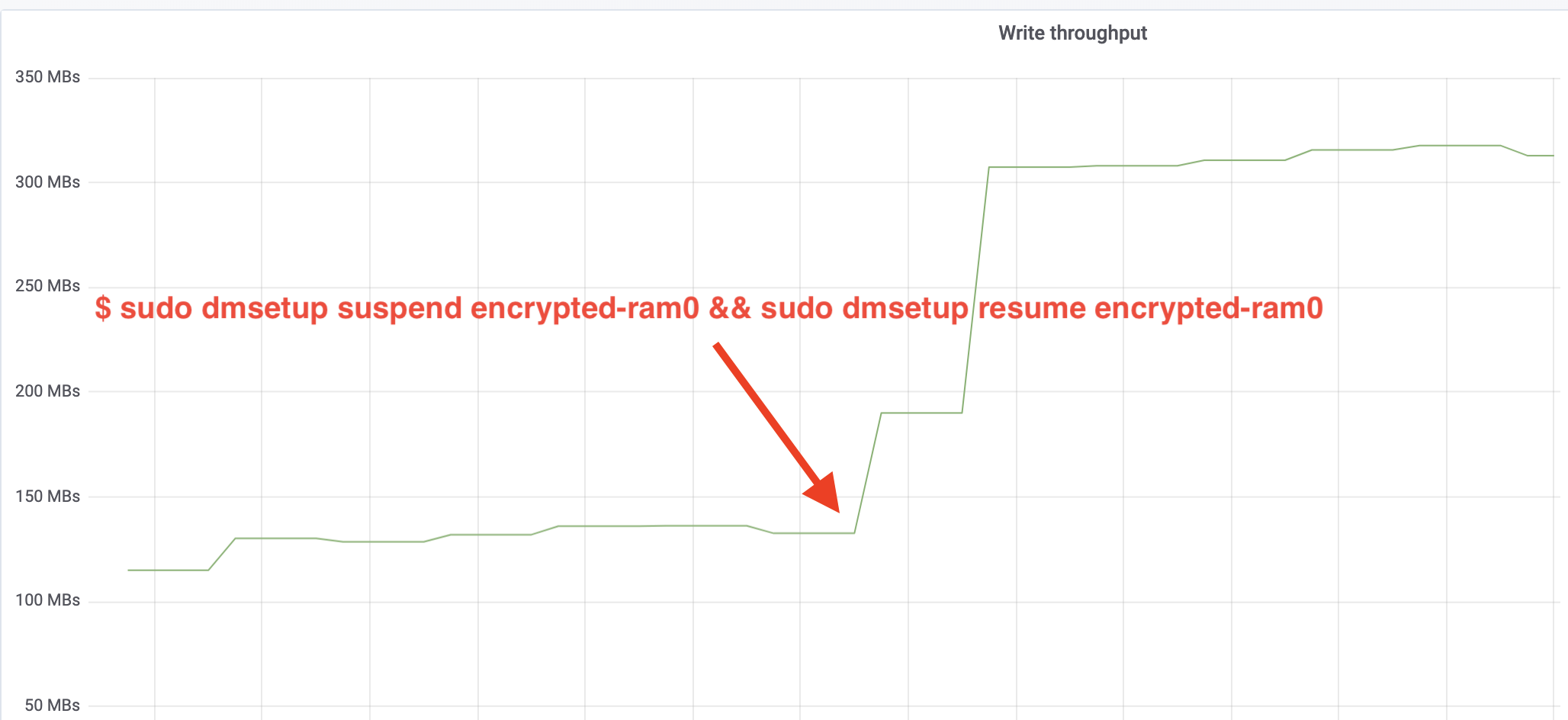
Vau, olemme yli kaksinkertaistaneet läpimenon! Kokonaisläpimenon ollessa ~640 MB/s olemme nyt paljon lähempänä edellä odotettua ~696 MB/s. Entä IO-viive? (iostat-raportointityökalun await-tilasto):
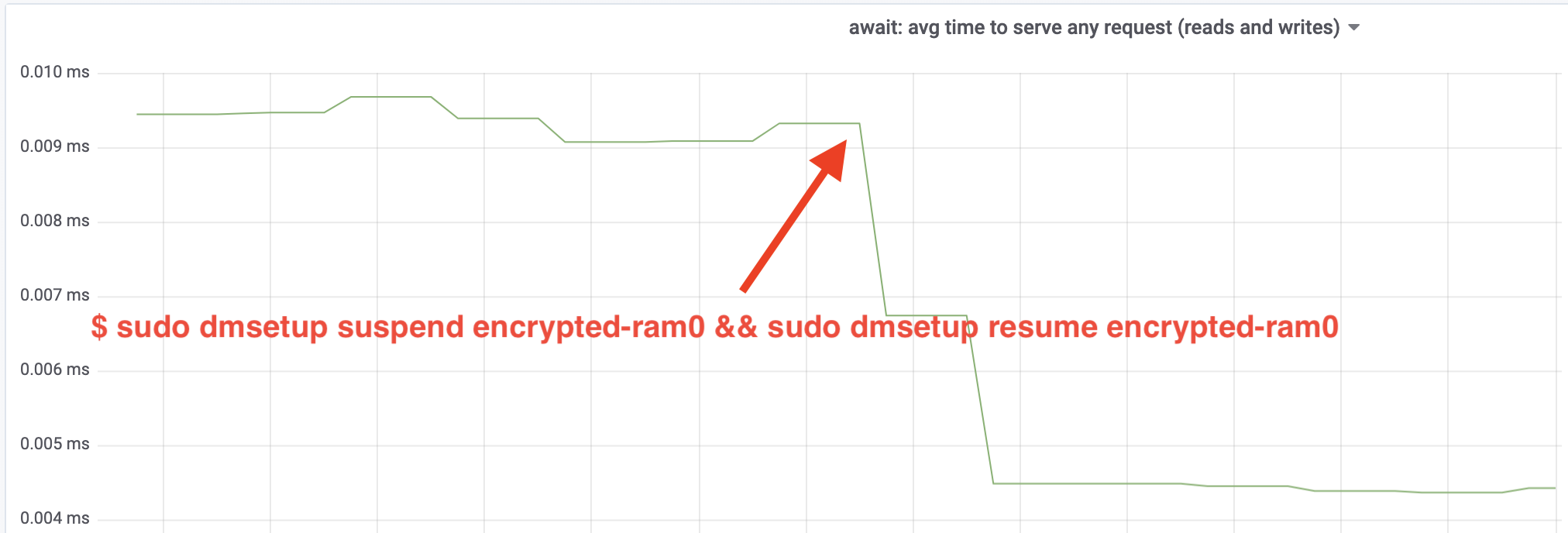
Myös latenssi on puolittunut!
Tuotantoon
Tähän mennessä olemme käyttäneet synteettistä asetusta, josta puuttuu joitakin osia täydestä tuotantopinosta, kuten tiedostojärjestelmiä, todellisia laitteistoja ja ennen kaikkea tuotantotyömäärää. Varmistaaksemme, ettemme optimoi kuvitteellisia asioita, tässä on tilannekuva näiden muutosten tuotannollisesta vaikutuksesta pinomme välimuistitallennusosaan:

Tämä kuvaaja edustaa kolminkertaista vertailua välimuistitallennuksen huonoimman tapauksen vasteajoista (99. prosenttipiste) yhdessä palvelimessamme. Vihreä viiva on peräisin palvelimelta, jossa on salaamattomia levyjä, joita käytämme perustasona. Punainen viiva on palvelimelta, jossa on salattuja levyjä Linuxin oletusarvoisen levysalauksen avulla, ja sininen viiva on palvelimelta, jossa on salattuja levyjä ja meidän optimointimme on käytössä. Kuten näemme, Linux-levyjen salauksen oletustoteutus vaikuttaa merkittävästi välimuistin viiveeseen pahimmassa tapauksessa, kun taas korjattu toteutus ei eroa siitä, että salausta ei käytettäisi lainkaan. Toisin sanoen parannetulla salaustoteutuksella ei ole minkäänlaista vaikutusta välimuistin vastenopeuteen, joten saamme sen käytännössä ilmaiseksi! Se on voitto!
Olemme vasta alussa
Tämä viesti osoittaa, miten arkkitehtuurin tarkistus voi kaksinkertaistaa järjestelmän suorituskyvyn. Vahvistimme myös uudelleen, että nykyaikainen kryptografia ei ole kallista, eikä yleensä ole mitään tekosyytä olla suojaamatta tietojasi.
Aioimme lähettää tämän työn sisällytettäväksi ytimen päälähdepuuhun, mutta todennäköisesti ei nykyisessä muodossaan. Vaikka tulokset näyttävätkin rohkaisevilta, on muistettava, että Linux on erittäin siirrettävä käyttöjärjestelmä: se toimii niin tehokkailla palvelimilla kuin pienillä resurssirajoitteisilla IoT-laitteilla ja monilla muillakin prosessoriarkkitehtuureilla. Nykyinen versio laastareista vain optimoi levyn salauksen tietylle työmäärälle tietyllä arkkitehtuurilla, mutta Linux tarvitsee ratkaisun, joka toimii sujuvasti kaikkialla.
Sen sanottu, jos uskot tapauksesi olevan samanlainen ja haluat hyödyntää suorituskykyparannuksia nyt, voit napata laastarit ja toivottavasti antaa palautetta. Suoritusaikalippu tekee toiminnallisuuden vaihtamisen lennossa helpoksi ja yksinkertaisen A/B-testin voi tehdä nähdäkseen, hyödyttääkö se jotakin tiettyä tapausta tai asetusta. Nämä korjaukset ovat toimineet laajassa verkostossamme, johon kuuluu yli 200 datakeskusta viidellä laitteistosukupolvella, joten niitä voidaan pitää kohtuullisen vakaina. Nauti sekä suorituskyvystä että Cloudflaren turvallisuudesta kaikille!

Päivitys (11. lokakuuta 2020)
Tämän blogin pääkorjaus (hieman päivitetyssä muodossa) on yhdistetty Linux-ytimen päälinjaan, ja se on saatavilla versiosta 5.9 alkaen. Tärkein ero on se, että mainline-versio paljastaa kaksi lippua yhden sijasta, jotka tarjoavat mahdollisuuden ohittaa dm-crypt-työjonot luku- ja kirjoitustapahtumille itsenäisesti. Katso lisätietoja virallisesta dm-crypt-dokumentaatiosta.