
Ennen kuin aloitin tämän matkan yrittäessäni oppia tietotekniikkaa, oli tiettyjä termejä ja lauseita, jotka saivat minut juoksemaan toiseen suuntaan.
Mutta pakenemisen sijaan teeskentelin tietäväni ne, nyökyttelin mukana keskusteluissa ja teeskentelin tietäväni, mihin joku viittasi, vaikka totuus oli, ettei minulla ollut aavistustakaan ja että olin itse asiassa lakannut kuuntelemasta lainkaan, kun olin kuullut Tuon superpelottavan tietotekniikkatermin™. Tämän sarjan aikana olen onnistunut käsittelemään paljon asioita, ja monet näistä termeistä ovat itse asiassa muuttuneet paljon vähemmän pelottaviksi!
On kuitenkin yksi iso termi, jota olen vältellyt jo jonkin aikaa. Tähän asti aina kun olin kuullut tämän termin, tunsin itseni halvaantuneeksi. Se on tullut esille satunnaisissa keskusteluissa tapaamisissa ja joskus konferenssipuheissa. Joka ikinen kerta ajattelen koneiden pyörivän ja tietokoneiden sylkevän koodisarjoja, jotka ovat käsittämättömiä, paitsi että kaikki muut ympärilläni osaavat itse asiassa tulkita ne, joten oikeastaan vain minä en tiedä, mitä on tekeillä (hups, miten tämä tapahtui?!).
En ehkä ole ainoa, joka on tuntenut näin. Mutta kai minun pitäisi kertoa, mikä tämä termi oikeastaan on? No, valmistautukaa, sillä viittaan aina vaikeasti hahmotettavaan ja hämmentävältä vaikuttavaan abstraktiin syntaksipuuhun, tai lyhyesti AST:hen. Monien vuosien pelottelun jälkeen olen innoissani siitä, että voin vihdoin lakata pelkäämästä tätä termiä ja todella ymmärtää, mitä ihmettä se on.
On aika kohdata abstraktin syntaksipuun juuret päin naamaa – ja nostaa jäsennyspelimme tasoa!
Jokainen hyvä etsintä alkaa vankalla perustalla, ja tehtävämme tämän rakenteen demystifioimiseksi pitäisi aloittaa täsmälleen samalla tavalla: tietenkin määritelmällä!
Abstrakti syntaksipuu (jota yleensä kutsutaan vain AST:ksi) ei oikeastaan ole mitään muuta kuin yksinkertaistettu, tiivistetty versio jäsennyspuusta. Kääntäjäsuunnittelun yhteydessä termiä ”AST” käytetään vaihdellen syntaksipuun kanssa.

Me ajattelemme usein syntaksipuita (ja sitä, miten ne rakennetaan) verrattaessa niitä niiden jäsennyspuiden vastineisiin, jotka ovat meille jo melko tuttuja. Tiedämme, että jäsennyspuut ovat puurakenteisia tietorakenteita, jotka sisältävät koodimme kieliopillisen rakenteen; toisin sanoen ne sisältävät kaiken sen syntaktisen informaation, joka esiintyy koodin ”lauseessa”, ja se on johdettu suoraan itse ohjelmointikielen kieliopista.
Abstrakti syntaksipuu taas jättää huomiotta merkittävän osan syntaktisesta informaatiosta, jonka jäsennyspuu muuten sisältäisi.
AST sen sijaan sisältää vain lähdetekstin analysointiin liittyvää tietoa, ja ohittaa kaiken muun ylimääräisen sisällön, jota käytetään tekstiä jäsennettäessä.
Tämä ero alkaa olla paljon järkevämpi, jos keskitymme AST:n ”abstraktisuuteen”.
Muistutetaan, että jäsennyspuu on havainnollistettu, kuvallinen versio lauseen kieliopillisesta rakenteesta. Toisin sanoen voimme sanoa, että jäsennyspuu edustaa täsmälleen sitä, miltä lauseke, lause tai teksti näyttää. Se on periaatteessa suora käännös itse tekstistä; otamme lauseen ja muutamme sen jokaisen pienen palan – välimerkeistä lausekkeisiin ja merkkeihin – puurakenteeksi. Se paljastaa tekstin konkreettisen syntaksin, minkä vuoksi sitä kutsutaan myös konkreettiseksi syntaksipuuksi eli CST:ksi. Käytämme termiä konkreettinen kuvaamaan tätä rakennetta, koska se on kieliopillinen kopio koodistamme merkki merkiltä puumuodossa.
Mutta mikä tekee jostakin konkreettisen verrattuna abstraktiin? No, abstrakti syntaksipuu ei näytä meille tarkalleen, miltä lauseke näyttää, niin kuin jäsennyspuu näyttää.

Pikemminkin abstrakti syntaksipuu näyttää meille ”tärkeät” osat – asiat, joista me todella välitämme, jotka antavat merkityksen koodimme ”lausekkeelle” itselleen. Syntaksipuut näyttävät meille lausekkeen merkittävät osat tai lähdetekstimme abstrahoidun syntaksin. Verrattuna konkreettisiin syntaksipuihin nämä rakenteet ovat siis abstrakteja esityksiä koodistamme (ja tietyllä tavalla vähemmän tarkkoja), mistä ne ovat saaneet nimensä.
Nyt kun ymmärrämme näiden kahden tietorakenteen välisen eron ja eri tavat, joilla ne voivat esittää koodimme, on syytä kysyä: miten abstrakti syntaksipuu sopii kääntäjään? Muistutetaan ensin kaikesta siitä, mitä tähän mennessä tiedämme kääntämisprosessista.

Esitettäköön, että käytössämme on superlyhyt ja supernopea lähdeteksti, joka näyttää tältä: 5 + (1 x 12).
Palautetaan mieleen, että kääntämisprosessissa tapahtuu ensimmäisenä tekstin skannaaminen, skannerin suorittama työ, jonka tuloksena teksti pilkotaan pienimpiin mahdollisiin osiinsa, joita kutsutaan lekseemeiksi. Tämä osa on kielestä riippumaton, ja saamme lopputuloksena lähdetekstimme riisutun version.
Seuraavaksi nämä lekseemit siirretään lekserille/tokenisaattorille, joka muuttaa nämä lähdetekstimme pienet esitykset tokeneiksi, jotka ovat kielellemme ominaisia. Merkkimme näyttävät jotakuinkin tältä: . Skannerin ja tokenisaattorin yhteinen ponnistus muodostaa kääntämisen leksikaalisen analyysin.
Kun syötteemme on tokenisoitu, sen tuloksena syntyneet tokenit siirretään jäsentäjälle, joka sitten ottaa lähdetekstin ja rakentaa siitä jäsennyspuun. Alla olevassa kuvassa on esimerkki siitä, miltä tokenisoitu koodimme näyttää jäsennyspuun muodossa.
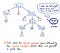
Työtä, jossa tokenit muutetaan jäsennyspuuksi, sanotaan myös jäsentelyksi (parsimiseksi), ja se tunnetaan nimellä syntaksianalyysivaihe. Syntaksianalyysivaihe on suoraan riippuvainen leksikaalisen analyysin vaiheesta; näin ollen leksikaalisen analyysin on aina oltava kääntämisprosessissa ensimmäisenä, koska kääntäjämme jäsentäjä voi tehdä työnsä vasta sitten, kun tokenizer on tehnyt työnsä!
Voisimme ajatella kääntäjän osia hyvinä ystävinä, jotka kaikki ovat riippuvaisia toisistaan varmistaakseen, että koodimme muuttuu oikein tekstistä tai tiedostosta jäsennyspuuksi.
Mutta takaisin alkuperäiseen kysymykseemme: miten abstrakti syntaksipuu sopii tähän ystäväjoukkoon? No, jotta voimme vastata tuohon kysymykseen, auttaa ymmärtämään AST:n tarpeen ylipäätään.
Yksi puun tiivistäminen toiseksi
Okei, nyt meillä on siis kaksi puuta, jotka meidän on pidettävä suorassa päässämme. Meillä oli jo jäsentelypuu, ja kuinka tässä on vielä toinenkin tietorakenne opeteltavana! Ja ilmeisesti tämä AST-tietorakenne on vain yksinkertaistettu jäsennyspuu. Miksi me siis tarvitsemme sitä? Mitä järkeä siinä edes on?
Katsotaanpa sitten meidän jäsennyspuuhamme?
Me tiedämme jo, että jäsennyspuut esittävät ohjelmamme sen selvimmin erottuvat osat; tämän vuoksi skannerilla ja tokenizerilla onkin niin tärkeä tehtävä hajottaa lausekkeemme sen pienimpiin osiin!
Mitä tarkoittaa oikeastaan ohjelman esittäminen sen selvimmin erottuvien osien mukaan?
Kuten käy ilmi, joskus kaikki ohjelman erottuvat osat eivät itse asiassa ole meille aina kovin hyödyllisiä.
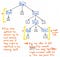
Katsotaanpa tässä esitettyä kuvaa, joka esittää alkuperäisen lausekkeemme 5 + (1 x 12) parse tree tree -muodossa. Jos tarkastelemme tätä puuta kriittisellä silmällä, huomaamme, että on muutamia tapauksia, joissa yhdellä solmulla on täsmälleen yksi lapsi, joita kutsutaan myös yhden seuraajan solmuiksi, koska niillä on vain yksi niistä lähtevä lapsisolmu (tai yksi ”seuraaja”).
Parsintapuuesimerkkimme tapauksessa single-successor-solmuilla on vanhempana solmu Expression tai Exp, joilla on yksi ainoa seuraaja, jolla on jokin arvo, kuten 5, 1 tai 12. Tässä Exp-vanhempisolmut eivät kuitenkaan varsinaisesti lisää mitään arvokasta meille, vai mitä? Näemme, että ne sisältävät token/terminal-lapsensolmuja, mutta emme oikeastaan välitä ”lausekkeen” vanhemmista solmuista; haluamme vain tietää, mikä on lauseke?
Vanhemmat solmut eivät anna meille mitään lisätietoa, kun olemme jäsentäneet puumme. Sen sijaan olemme oikeastaan huolissamme yhdestä ainoasta lapsi- ja seuraajasolmusta. Se on nimittäin se solmu, joka antaa meille tärkeän tiedon, sen osan, joka on meille merkityksellinen: itse numeron ja arvon! Kun otetaan huomioon, että nämä vanhemmat solmut ovat meille tavallaan tarpeettomia, käy selväksi, että tämä jäsennyspuu on eräänlainen verbaalinen.
Kaikki nämä single-successor-solmut ovat meille melko turhia, eivätkä ne auta meitä lainkaan. Hankkiudutaan siis eroon niistä!
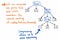
Jos paketoimme jäsennyspuussamme olevat single-successor-solmut yhteen, saamme lopputulokseksi täsmälleen samanlaisen rakenteen tiivistetyemmän version. Kun tarkastelemme yllä olevaa kuvaa, huomaamme, että säilytämme edelleen täsmälleen saman sisäkkäisyyden kuin aiemmin, ja solmumme/tunnuksemme/terminaalit esiintyvät edelleen oikeassa paikassa puun sisällä. Mutta olemme onnistuneet keventämään sitä hieman.
Ja voimme myös karsia puustamme hieman lisää. Jos esimerkiksi tarkastelemme jäsentelypuuta sellaisena kuin se on tällä hetkellä, huomaamme, että siinä on peilirakenne. Ali-ilmaus (1 x 12) on sisäkkäin suluissa (), jotka ovat merkkejä itsessään.
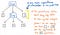
Näistä sulkeista ei kuitenkaan ole mitään hyötyä sen jälkeen, kun puumme on jo kasassa. Tiedämme jo, että 1 ja 12 ovat argumentteja, jotka välitetään kertolaskuoperaatiolle x, joten sulkeet eivät kerro meille tässä vaiheessa kovinkaan paljon. Itse asiassa voisimme tiivistää jäsennyspuumme vielä enemmän ja päästä eroon näistä turhista lehtisolmuista.
Kun tiivistämme ja yksinkertaistamme jäsennyspuumme ja pääsemme eroon turhasta syntaktisesta ”pölystä”, saamme lopulta rakenteen, joka näyttää tässä vaiheessa näkyvästi erilaiselta. Tuo rakenne on itse asiassa uusi ja odotettu ystävämme: abstrakti syntaksipuu.

Ylläoleva kuva havainnollistaa täsmälleen samanlaista lauseketta kuin jäsentelypuumme: 5 + (1 x 12). Erona on se, että se on abstrahoinut lausekkeen pois konkreettisesta syntaksista. Emme näe enää sulkuja () tässä puussa, koska ne eivät ole tarpeellisia. Samoin emme näe ei-terminaaleja, kuten Exp, koska olemme jo selvittäneet, mikä ”lauseke” on, ja pystymme vetämään esiin meille todella tärkeän arvon – esimerkiksi luvun 5.
Juuri tämä on AST:n ja CST:n erottava tekijä. Tiedämme, että abstrakti syntaksipuu jättää huomiotta merkittävän osan jäsennyspuun sisältämästä syntaktisesta informaatiosta ja ohittaa jäsennyksessä käytettävän ”ylimääräisen sisällön”. Mutta nyt näemme tarkalleen, miten se tapahtuu!

Nyt, kun olemme tiivistäneet oman jäsennyspuumme, pystymme paljon paremmin havaitsemaan joitain malleja, jotka erottavat AST:n CST:stä.
On muutamia tapoja, joilla abstrakti syntaksipuu eroaa visuaalisesti jäsennyspuusta:
- AST ei koskaan sisällä syntaktisia yksityiskohtia, kuten pilkkuja, sulkuja ja puolipisteitä (riippuen tietenkin kielestä).
- AST:ssä on kokoonpainettuja versioita niistä, jotka muutoin näyttäisivät yksittäisiltä peräkkäisiltä solmuilta; siinä ei koskaan ole ”ketjuja” solmuja, joissa on yksi ainoa lapsi.
- Loppujen lopuksi kaikki operaattorimerkit (kuten
+,-,xja/) muuttuvat puun sisäisiksi (vanhemmiksi) solmuiksi eikä lehdiksi, jotka päättyvät jäsennyspuuhun.
Visuaalisesti AST näyttää aina tiiviimmältä kuin jäsennyspuu, koska se on määritelmällisesti tiivistetty versio jäsennyspuusta, jossa on vähemmän syntaktisia yksityiskohtia.
Sitten olisi loogista, että jos AST on kompaktifioitu versio jäsennyspuusta, voimme oikeastaan luoda abstraktin syntaksipuun vain, jos meillä on asiat, joiden avulla voimme aluksi rakentaa jäsennyspuun!
Juuri näin abstrakti syntaksipuu todellakin sopii laajempaan kompilointiprosessiin. AST:llä on suora yhteys jäsennyspuihin, joista olemme jo oppineet, ja samalla se luottaa siihen, että lekseri tekee työnsä ennen kuin AST:tä voidaan koskaan luoda.

Abstrakti syntaksipuu luodaan syntaksianalyysivaiheen lopputuloksena. Jäsennin, joka on etualalla pää ”hahmona” syntaksianalyysin aikana, voi aina tuottaa jäsennyspuun eli CST:n, mutta ei aina. Kääntäjästä ja sen suunnittelutavasta riippuen jäsentäjä voi siirtyä suoraan syntaksipuun eli AST:n rakentamiseen. Mutta jäsentäjä tuottaa aina AST:n tulosteenaan riippumatta siitä, luoko se välissä jäsennyspuun, tai kuinka monta läpikäyntiä se joutuu siihen käyttämään.
AST:n anatomia
Nyt kun tiedämme, että abstrakti syntaksipuu on tärkeä (mutta ei välttämättä pelottava!), voimme ryhtyä paloittelemaan sitä hiukan tarkemmin. Mielenkiintoinen näkökohta AST:n rakentamisessa liittyy tämän puun solmuihin.
Oheinen kuva havainnollistaa yhden solmun anatomiaa abstraktissa syntaksipuussa.
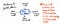
Huomaa, että tämä solmu on samanlainen kuin muut aiemmin näkemämme solmut siinä mielessä, että se sisältää dataa (token ja sen value). Se sisältää kuitenkin myös joitakin hyvin erityisiä osoittimia.
Voidaan kuvitella, että tämän AST:n lukeminen, läpikäyminen tai ”tulkitseminen” voisi alkaa puun alimmilta tasoilta ja edetä ylöspäin rakentaen arvoa tai palautusta result loppuun mennessä.
Voi myös auttaa näkemään koodatun version jäsentäjän tulosteesta täydentämään visualisointiamme. Voimme nojata erilaisiin työkaluihin ja käyttää valmiita jäsentäjiä nähdäksemme nopean esimerkin siitä, miltä lausekkeemme voisi näyttää, kun se ajetaan jäsentäjän läpi. Alla on esimerkki lähdetekstistämme 5 + (1 * 12), joka on ajettu ECMAScript-parserin Espriman läpi, ja sen tuloksena syntynyt abstrakti syntaksipuu, jonka jälkeen on luettelo sen erillisistä tokeneista.
Tämässä muodossa näemme puun sisäkkäisyyden, jos tarkastelemme sisäkkäisiä objekteja. Huomaamme, että arvot, jotka sisältävät 1 ja 12, ovat vastaavasti left ja right vanhemman operaation * lapsia. Huomaamme myös, että kertolaskuoperaatio (*) muodostaa itse koko lausekkeen oikeanpuoleisen alipuun, minkä vuoksi se on sisäkkäin isomman BinaryExpression-objektin sisällä avaimen "right" alla. Vastaavasti arvo 5 on suuremman BinaryExpression-objektin "left" yksittäinen BinaryExpression-lapsi.

Abstraktin syntaksipuun kiehtovin puoli on kuitenkin se, että vaikka ne ovat niin kompakteja ja puhtaita, niitä ei aina ole helppo yrittää rakentaa tietorakenteeksi. Itse asiassa AST:n rakentaminen voi olla melko monimutkaista riippuen kielestä, jota jäsentäjä käsittelee!
Useimmat jäsentäjät yleensä joko rakentavat jäsennyspuun (CST) ja muuttavat sen sitten AST-muotoon, koska se voi joskus olla helpompaa – vaikka se tarkoittaakin useampia vaiheita ja yleisesti ottaen useampia läpikäyntejä lähdetekstissä. CST:n rakentaminen on itse asiassa melko helppoa, kun jäsentäjä tuntee sen kielen kieliopin, jota se yrittää jäsentää. Sen ei tarvitse tehdä mitään monimutkaista työtä sen selvittämiseksi, onko merkki ”merkittävä” vai ei; sen sijaan se vain ottaa tarkalleen sen, mitä se näkee, tietyssä järjestyksessä, ja sylkee sen kaiken ulos puuksi.
Toisaalta on olemassa joitakin jäsentäjiä, jotka yrittävät tehdä kaiken tämän yksivaiheisena prosessina, hyppäämällä suoraan abstraktin syntaksipuun rakentamiseen.
Suoraan AST:n rakentaminen voi olla hankalaa, koska jäsentäjän on paitsi löydettävä merkit ja esitettävä ne oikein, myös päätettävä, mitkä merkit ovat meille tärkeitä ja mitkä eivät.
Kääntäjäsuunnittelussa AST:llä on lopulta erittäin suuri merkitys useammasta syystä. Kyllä, se voi olla hankala rakentaa (ja luultavasti helppo mokata), mutta lisäksi se on leksikaalisen ja syntaksianalyysivaiheen viimeinen ja lopullinen tulos yhdessä! Leksikaalista ja syntaksianalyysivaihetta kutsutaan usein yhdessä analyysivaiheeksi tai kääntäjän front-endiksi.

Voisimme ajatella, että abstrakti syntaksipuu on kääntäjän front-endin ”lopputyö”. Se on tärkein osa, koska se on viimeinen asia, jonka front-endin on näytettävä itsestään. Tekninen termi tälle on nimeltään välikoodin esitys tai IR, koska siitä tulee tietorakenne, jota kääntäjä viime kädessä käyttää lähdetekstin esittämiseen.
Abstrakti syntaksipuu on yleisin IR:n muoto, mutta myös joskus väärinymmärretyin. Mutta nyt kun ymmärrämme sitä hieman paremmin, voimme alkaa muuttaa käsitystämme tästä pelottavasta rakenteesta! Toivottavasti se on meille nyt hieman vähemmän pelottava.
Resurssit
AST:istä on olemassa paljon resursseja eri kielillä. Tietäminen siitä, mistä aloittaa, voi olla hankalaa, varsinkin jos haluat oppia lisää. Alla on muutamia aloittelijoille sopivia resursseja, jotka syventyvät paljon yksityiskohtaisemmin ilman, että ne ovat liian yliampuvia. Happy asbtracting!
- The AST vs the Parse Tree, Professor Charles N. Fischer
- What’s the difference between parse trees and abstract syntax trees?,