Infrastruktuurin virtualisoinnista ja virtuaalisten resurssien käyttämisestä liiketoimintakriittisten työkuormien palvelemiseen on monia suuria etuja. VMware vSphere tarjoaa monia merkittäviä ominaisuuksia ja ominaisuuksia, jotka mahdollistavat korkean käytettävyyden ympäristössä sekä automatisoidun työmäärän ajoituksen, jolla varmistetaan laitteiston ja resurssien mahdollisimman tehokas käyttö vSphere-ympäristössäsi.
Tässä postauksessa käsittelemme kahta vSpheren keskeistä klusteritason ominaisuutta yrityksissä – vSphere HA:ta ja DRS:ää. Olet todennäköisesti nähnyt molempiin näistä viitattavan yhdessä vSphere-järjestelmän käyttämisen kanssa yrityksessä.
Mikä on vSphere HA ja DRS? Mitä ne tekevät?
Miten hyödyt molempien käyttämisestä vSphere-ympäristössäsi?
Katsotaanpa VMware vSphere -palvelun HA:n ja DRS:n perusesittelyä ja katsotaan, miten niitä verrataan toisiinsa ja mitä hyötyä niiden käytöstä on.
VMware vSphere Clusters
Yksi ilmeisistä eduista ja parhaista käytännöistä, kun VMware vSphereä hyödynnetään liiketoimintakriittisten työtehtävien suorittamiseen, on vSphere Clusterin käyttäminen.
Mikä on vSphere-klusteri?
VSphere-klusteri on konfiguraatio, joka koostuu useammasta kuin yhdestä VMware ESXi -palvelimesta, jotka on koottu yhteen resurssipooliksi, joka edistää vSphere-klusteria. Kukin ESXi-isäntä osallistuu resursseihin, kuten suorittimen laskentaan, muistiin ja ohjelmistomääritellyn tallennuksen, kuten vSANin, tapauksessa tallennukseen.
Miksi liiketoimintakriittisten työtehtävien suorittaminen vSphere-klusterin päällä on tärkeää?
Kun ajatellaan hypervisorin suorittamisen tarjoamia etuja, se mahdollistaa useamman kuin yhden palvelimen suorittamisen yhden fyysisen laitteiston päällä. Työkuormien virtualisointi tällä tavoin tarjoaa monia tehokkuushyötyjä suuruusluokkaa verrattuna yhden palvelimen ajamiseen yhdellä fyysisellä laitteistokokonaisuudella.
Tästä voi kuitenkin tulla myös virtualisoidun ratkaisun akilleenkantapää, sillä laitteistovian vaikutus voi vaikuttaa moniin useampiin liiketoiminnan kannalta kriittisiin palveluihin ja sovelluksiin. Voit kuvitella, että jos käytössäsi on vain yksi VMware ESXi-isäntä, joka käyttää monia VM:iä, tuon yhden ESXi-isännän menettämisen vaikutus olisi valtava.
Tässä tilanteessa useiden VMware ESXi-isäntien käyttäminen vSphere-klusterissa todella loistaa.
Voit kuitenkin kysyä itseltäsi, miten pelkkä useiden isäntien käyttäminen klusterissa parantaa korkean käytettävyyden tasoa? Miten vSphere-klusterissa oleva isäntä ”tietää”, jos toinen isäntä on vikaantunut? Onko olemassa jokin erityinen mekanismi, jolla huolehditaan vSphere-klusterissa suoritettavien työtehtävien korkean käytettävyyden hallinnasta? Kyllä, on olemassa. Katsotaanpa.
Mitä HA on VMwaressa?
VMware oivalsi, että tarvitaan mekanismi, joka suojaa vSphere Clusterissa olevaa ESXi-isäntää vikaantumiselta. Tämän tarpeen myötä syntyi VMware High-Availability (HA).
VMware vSphere HA tarjoaa seuraavat edut:
VMware vSphere HA on kustannustehokas ja mahdollistaa VM:ien ja vSphere-isäntien automaattisen uudelleenkäynnistyksen, kun vSphere-ympäristössä havaitaan palvelimen tai käyttöjärjestelmän vikaantuminen
Valvoo kaikkia vSphere-klusterissa olevia VMware vSphere -isäntiä &VM:ien korkeaa käytettävyyttä useimpiin virtuaalikoneissa käynnissä oleviin sovelluksiin käyttöjärjestelmästä ja sovelluksista riippumatta.
Vmware Clusterin kautta toteutetun VMware vSphere HA -ratkaisun kauneus on sen konfiguroinnin yksinkertaisuus. Korkean käytettävyyden määrittäminen onnistuu muutamalla klikkauksella ohjatun käyttöliittymän kautta. Miten tämä vertautuu perinteisiin ”klusterointitekniikoihin”?
Windows Server Failover Clusteringin vertailu
Windows Server Failover Clusteringista (WSFC) on tullut se klusterointitekniikka, joka useimmille tulee mieleen, kun he ajattelevat klusterointitekniikkaa. WSFC:n ongelmana nähdään se, että WSFC-palveluiden oikeaoppinen käyttö vaatii paljon erikoisosaamista, erityisesti päivitysten, korjausten ja yleisten käyttötehtävien osalta.
Vertailtaessa vSphere HA:ta WSFC:hen, operatiivinen yleiskustannus on WSFC:hen verrattuna minimaalinen. On pieni mahdollisuus, että HA voidaan konfiguroida väärin, koska se on joko käytössä klusterissa tai ei. WSFC:n kanssa WSFC:tä konfiguroitaessa on otettava huomioon monia seikkoja, jotta vältetään sekä konfigurointi- että käyttöönottovirheet. Mieti seuraavia asioita:
- Failover-klusterointi edellyttää sovelluksia, jotka tukevat klusterointia (SQL jne.)
- Failover-klusterointi edellyttää, että quorum on konfiguroitu oikein
- Monet vanhat käyttöjärjestelmät ja sovellukset eivät tue
- Tarvitsee klusterin verkkonimien, -resurssien ja -verkkokäytön monimutkaisuutta
Windows Serverin vikasietoisen klusteroinnin (Windows Server Failover Clustering) mainostetaan tarjoavan sovellustasolla melkeinpä nolla-ajan. Kun kuitenkin lisätään kunnolla toimivan HA-ratkaisun edellyttämä asiantuntemus sekä WSFC:n asianmukainen toteutus, riskit voivat alkaa olla suuremmat kuin hyödyt, joita WSFC:n käyttäminen sovellusten ja palveluiden korkeaan käytettävyyteen tuo mukanaan. Tämä pätee erityisesti useimpiin organisaatioihin, jotka eivät välttämättä tarvitse ”nollakatkosratkaisua”. Lisäksi sovellus on suunniteltava niin, että se pystyy hyödyntämään WSFC:tä ja toimimaan oikein WSFC-tekniikan kanssa.
Vaikka vSphere HA edellyttää virtuaalikoneiden uudelleenkäynnistämistä terveellä isännällä, kun vikaantuminen tapahtuu, se ei vaadi lisäohjelmistojen asentamista vierasvirtuaalikoneiden sisälle, ei monimutkaisia lisäklusterointitekniikoiden konfigurointeja eikä sovelluksia tai käyttöjärjestelmiä tarvitse suunnitella niin, että ne toimisivat tietyn klusterointitekniikan kanssa.
Legendaarisilla käyttöjärjestelmillä ja sovelluksilla on yleensä rajalliset kyvyt, kun on kyse tuetuista tekniikoista korkean käytettävyyden tarjoamiseksi. Niinpä kirjaimellisesti ei välttämättä ole natiiveja vaihtoehtoja vikatoimintojen tarjoamiseksi laitteistovikojen yhteydessä.
VSphere HA:n korkean käytettävyyden mekanismi toimii, ja se on helppo toteuttaa, määrittää ja hallita. Lisäksi tämä tekniikka on testattu hyvin tuhansissa VMware-asiakasympäristöissä, joten sillä on vakaa ja pitkä historia onnistuneista käyttöönotoista.
Yleistä yleiskatsausta vSphere HA:n käyttäytymisestä
Käyttämällä vSphere-klusterissa oleville ESXi-isännille tarjottuja etuja vSphere HA toteuttaa vSphere-klusterin isäntien välisen valvontamekanismin yksinkertaisimmillaan. Valvontamekanismi tarjoaa keinon määrittää, onko jokin vSphere-klusterin isäntä vikaantunut.
Oheisessa infograafissa kahden solmun vSphere-klusterissa on tapahtunut vika yhdessä vSphere-klusterin ESXi-isännässä. vSphere-klusterissa on vSphere HA käytössä klusteritasolla.
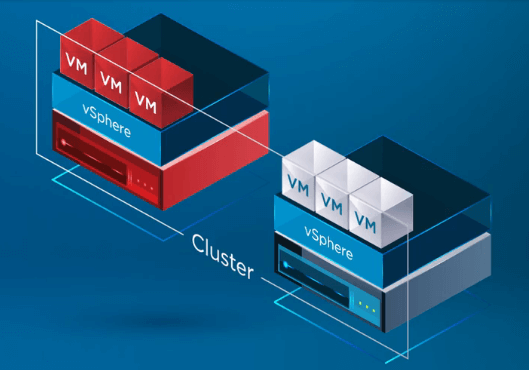
Kun vSphere HA tunnistaa, että vSphere-klusterin yksi isäntä on vikaantunut, HA-prosessi siirtää VM:ien rekisteröinnin vikaantuneelta isännältä terveelle isännälle.
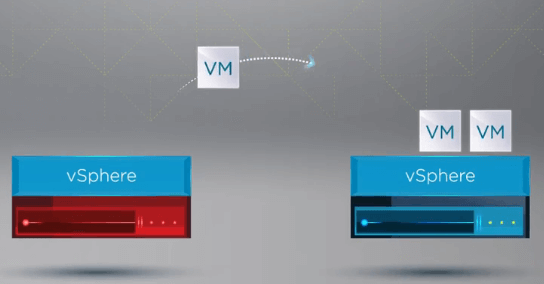
Kun VM:t on rekisteröity terveelle isännälle, vSphere HA käynnistää uudelleen kaikki epäonnistuneen isännän VM:t klusterin terveellä ESXi-isännällä, jossa VM:t rekisteröitiin uudelleen. Ainoa seisokkiaika aiheutuu VM:ien uudelleenkäynnistämisestä vSphere-klusterin terveellä isännällä.
VSphere HA Technical Overview
VSphere HA:n edellytykset
Mahdat miettiä, mitä taustalla olevia edellytyksiä vSphere HA:n toimiminen saattaa edellyttää. Tarvitaanko HA:n käyttöönottoon yksinkertaisesti VMware-klusteri? Toisin kuin Windows Server Failover Clusteringissa, HA:n toimimiseksi on oltava vain muutama vaatimus.
VAatimukset:
- Vähintään kaksi ESXi-isäntää
- Jokaiseen isäntään määritetty vähintään 4 Gt muistia
- vCenter-palvelin
- vSphere Standard -lisenssi
- Jakautettu tallennustila VM:eille
- Pingattavissa oleva yhdyskäytävä tai jokin muu luotettava verkon solmupiste
Huom, ei tarvita quorum-komponenttia, ei monimutkaista verkon nimeämistä eikä muita erityisiä klusterin resursseja, joiden pitäisi olla paikallaan.
Lue lisää: vSphere High Availability -klusterin määrittäminen
VMware vSphere HA Master vs. alisteiset isännät
Kun otat vSphere HA:n käyttöön klusterissa, tietty vSphere-klusterin isäntä nimetään vSphere HA:n masteriksi. Muut vSphere-klusterin ESXi-isännät määritetään vSphere HA -määrityksessä alisteisiksi.
Mitä roolia masteriksi määritetyllä vSphere HA:n ESXi-isännällä on? vSphere HA:n master-solmu:
- Valvoo orjina toimivien alisteisten isäntien tilaa – Jos alisteinen isäntä vikaantuu tai on tavoittamattomissa, master-isäntä tunnistaa, mitkä VM:t on käynnistettävä uudelleen
- Valvoo kaikkien suojattujen VM:ien virransyöttötilaa. Jos VM vikaantuu, master vSphere HA -solmu varmistaa, että VM käynnistetään uudelleen. vSphere HA master päättää, missä VM:n uudelleenkäynnistys tapahtuu (mikä ESXi-isäntä).
- Pitää kirjaa kaikista klusterin isännistä ja VM:istä, jotka on suojattu vSphere HA:lla
- On nimetty välittäjäksi vSphere-klusterin ja vCenter Serverin välillä. HA-master raportoi klusterin tilan vCenterille ja tarjoaa hallintaliittymän klusteriin vCenter Serverille
- Voi itse ajaa VM:iä ja seurata VM:ien tilaa
- Säilyttää suojattuja VM:iä klusterin tietovarastoissa
vSphere HA:n alaiset isännät:
- Käynnistää virtuaalikoneita paikallisesti
- Valvoo vSphere-klusterin VM:ien ajonaikaisia tiloja
- Raportoi tilapäivitykset vSphere HA:n pääkonehallinta-asemalle
Pääkonehallinta-aseman valinta ja pääkonehallinta-aseman vikaantuminen
Kuinka vSphere HA:n pääkonehallinta-asemalle valitaan? Kun vSphere HA on käytössä klusterissa, kaikki aktiiviset isännät (ei ylläpitotilaa jne.) osallistuvat master-isännän valintaan. Jos valittu master-isäntä vikaantuu, suoritetaan uusi valinta, jossa valitaan uusi HA-master-isäntä täyttämään kyseinen rooli.
VMware vSphere HA:n klusterin vikatyypit
VSphere HA:n käytössä olevassa klusterissa voi tapahtua kolmenlaisia vikoja, jotka laukaisevat vSphere HA:n vikasietotapahtuman. Nämä isännän vikatyypit ovat:
- Vika – Vika on intuitiivisesti sitä, mitä luulet. Isäntä on lakannut toimimasta jossain muodossa tai tavalla laitteisto- tai muiden ongelmien vuoksi.
- Eristäminen – Isännän eristäminen tapahtuu yleensä verkkotapahtuman vuoksi, joka eristää tietyn isännän muista vSphere HA -klusterin isännistä.
- Osastointi – Osastointitapahtumalle on ominaista, että alainen isäntä menettää verkkoyhteyden vSphere HA -klusterin master-isäntään.
Sydänhälytys, vikojen havaitseminen ja vikatoiminnot
Miten master-solmu määrittelee, onko tietyssä isännässä vika?
On olemassa useita eri mekanismeja, joita pääsolmu käyttää määrittääkseen, onko jokin isäntä vikaantunut:
- Sisäsolmu vaihtaa verkon sykeääniä muiden klusterin isäntien kanssa sekunnin välein.
- Verkon sykeäänen epäonnistumisen jälkeen pääsolmu tarkistaa isännän elinvoimaisuuden tarkistuksen.
- Isännän elinvoimaisuuden tarkistuksessa määritetään, vaihtaako alainen isäntä sykeääniä jonkun tietovaraston kanssa. Sen jälkeen se lähettää ICMP-pingejä sen hallinta-IP-osoitteisiin
- Jos suora kommunikointi alisteisen isännän HA-agentin kanssa master-isännältä ei ole mahdollista ja ICMP-pingit hallintaosoitteeseen epäonnistuvat, isäntää pidetään epäonnistuneena ja VM:t käynnistetään uudelleen toisella isännällä.
- Jos havaitaan, että alisteinen isäntä vaihtaa heartbeatteja tietovaraston kanssa, master-isäntä olettaa, että isäntä on verkko-osiossa tai että se on eristetty verkosta. Tällöin master-isäntä yksinkertaisesti valvoo isäntää ja VM:iä
- Verkkoeristäminen on tapahtuma, jossa alisteinen isäntä on käynnissä, mutta sitä ei voida enää nähdä HA-hallinta-agentin näkökulmasta hallintaverkossa. Jos isäntä lakkaa näkemästä tätä liikennettä, se yrittää pingata klusterin eristysosoitteita. Jos tämä pingaus epäonnistuu, isäntä ilmoittaa olevansa eristetty verkosta
- Tällöin pääsolmu valvoo eristetyssä isännässä käynnissä olevia VM:iä. Jos VM:t sammuvat eristetyllä isännällä, master-solmu käynnistää VM:t uudelleen toisella isännällä
Datastore Heartbeating
Kuten edellä mainittiin, yksi vikojen havaitsemiseen käytettävistä metriikoista on datastore Heartbeating. Mitä tämä tarkalleen ottaen on? VMware vCenter valitsee ensisijaisen joukon datatietovarastoja heartbeatingia varten. Sen jälkeen vSphere HA luo jokaisen tietovaraston juuressa olevan hakemiston, jota käytetään sekä tietovarastojen sykkimiseen että suojattujen VM:ien luettelon ylläpitämiseen. Tämän hakemiston nimi on .vSphere-HA.
VSAN-tietovarastoihin liittyen on muistettava yksi tärkeä huomautus. VSAN-tietovarastoa ei voi käyttää datastore heartbeatingiin. Jos käytettävissä on vain yksi vSAN-tietovarasto, heartbeat-tietovarastoja ei voi käyttää.
- VM:n ja sovellusten valvonta
Toinen vSphere HA:n erittäin tehokas ominaisuus on mahdollisuus valvoa yksittäisiä virtuaalikoneita VMware Toolsin kautta ja käynnistää uudelleen kaikki virtuaalikoneet, jotka eivät reagoi VMware Toolsin heartbeatteihin. Sovellusten valvonta voi käynnistää VM:n uudelleen, jos käynnissä olevan sovelluksen sydänääniä ei vastaanoteta.
- VM-valvonta – VM-valvontapalvelun avulla VM-valvontapalvelu määrittää VMware Toolsin avulla, onko kukin VM käynnissä, tarkistamalla sekä sydämenlyönnit että VMware Toolsin tuottaman levyn I/O:n. Jos nämä tarkistukset epäonnistuvat, VM-valvontapalvelu määrittää todennäköisimmin, että vieras käyttöjärjestelmä on epäonnistunut, ja VM käynnistetään uudelleen. Levyn I/O:n lisätarkistus auttaa välttämään tarpeettomia VM:n uudelleenkäynnistyksiä, jos VM:t tai sovellukset toimivat edelleen moitteettomasti.
Sovellusten valvonta – Sovellusten valvontatoiminto otetaan käyttöön hankkimalla kolmannen osapuolen ohjelmistotoimittajalta asianmukainen SDK, jonka avulla voidaan määrittää räätälöityjä sykäyksiä sovelluksille, joita vSphere HA -prosessi valvoo. Samoin kuin VM:n valvontaprosessi, jos sovellusten sykeäänien vastaanotto lakkaa, VM nollataan.
Kummatkin näistä valvontatoiminnoista voidaan määrittää edelleen valvontaherkkyydellä ja myös VM-kohtaisilla enimmäisasetusten nollauksilla, mikä auttaa välttämään VM:ien nollaamista toistuvasti ohjelmisto- tai väärien positiivisten virheiden vuoksi.
VMware vSphere HA on loistava tapa varmistaa, että vSphere-klusterisi tarjoaa erittäin joustavan korkean käytettävyyden, joka suojaa ESXi-isäntien yleisiä isäntäkokoonpanon vikaantumisia vastaan.
Miten on resurssien tehokkaan käytön varmistamisen laita vSphere-klusterissasi? Tutustutaan seuraavaan vSphere Clusterin varaukseen, joka auttaa varmistamaan vSphere Clusterin resurssien ja kapasiteetin tehokkaan käytön.
Mikä on DRS VMwaressa?
VMware Distributed Resource Scheduler (DRS) on todella tehokas ominaisuus vSphere Clusteria käytettäessä. Se tarjoaa aikataulutuksen ja kuorman tasauksen koko vSphere-klusterissa. VMware DRS on vSphere Clustereista löytyvä ominaisuus, joka varmistaa, että vSphere-ympäristössä suoritettavat virtuaalikoneet saavat käyttöönsä resurssit, joita ne tarvitsevat toimiakseen tehokkaasti ja tuloksellisesti.
VM-tietokoneet ovat yleensä DRS:n piirissä jo varhaisessa vaiheessa, sillä DRS sijoittaa VM-tietokoneet niiden ensimmäisestä käynnistyksestä alkaen DRS:ää tukevassa klusterissa parhaaseen isäntäkoneeseen, joka on konfiguroitu tarjoamaan VM-tietokoneelle sen tarvitsemat resurssit heti, kun se on käynnistetty. Lisäksi DRS pyrkii pitämään vSphere-klusterit tasapainossa resurssien käytön kannalta.
Sitäkin huolimatta, että vSphere-klusteri on tasapainossa tiettynä ajankohtana, VM:iä saatetaan siirtää tai ne voivat muuttua siten, että klusterin resurssien epätasapaino voi hiipiä takaisin ympäristöön. Kun klustereista tulee epätasapainoisia, se voi vaikuttaa haitallisesti vSphere-klusterissa käynnissä olevien virtuaalikoneiden kokonaissuorituskykyyn.
Oletusarvoisesti DRS suoritetaan automaattisesti vSphere-klusterissa viiden minuutin välein vSphere-klusterin tasapainon määrittämiseksi ja sen selvittämiseksi, onko resurssien tehokkaamman käytön varmistamiseksi tehtävä muutoksia.
VMware DRS -vaatimukset
VMware DRS:n hyödyntämiseksi on täytettävä useita vaatimuksia, jotta Distributed Resource Scheduler -toiminnallisuutta voidaan hyödyntää. Näitä ovat:
- ESXi-isäntien klusteri
- vCenter Server
- Enterprise Plus -lisenssi
- vMotion tarvitaan automaattiseen kuormanjakoon
Lue lisää: How to Configure a vSphere DRS Cluster
VMware DRS Actions
Kun VMware DRS suoritetaan vSphere-klusterissa viiden minuutin välein, se määrittää, onko klusterissa epätasapainoa. Jos näin on, suoritetaan vMotion, jolla siirretään nimetyt VM:t yhdeltä ESXi-isännältä toiselle.
Miten DRS tarkalleen ottaen määrittää, sopivatko virtuaalikoneet paremmin yhdelle vai toiselle ESXi-isännälle?
DRS suorittaa erityisen algoritmin määrittääkseen oikean ESXi-isännän, jossa tietyn VM:n tulisi olla. Kun VM:n virta kytketään päälle, tämä algoritmi ottaa huomioon resurssien jakautumisen koko vSphere-klusterissa sen jälkeen, kun se on varmistanut, ettei rajoituksia rikota, jos tietty VM sijoitetaan tiettyyn ESXi-isäntään.
Lisäksi itse VM:n kysyntä otetaan huomioon, joten VM ei toivottavasti koskaan joudu resurssien puutteeseen, kun se käynnistetään. Mitä VM:n kysyntä sisältää? VM:n kysyntään sisältyy toimintaan tarvittavien resurssien määrä.
- Suorittimen kysyntä lasketaan VM:n tällä hetkellä käyttämän suorittimen määrän perusteella
- Muistin osalta kysyntä lasketaan kaavalla: VM:n muistin tarve = Funktio(Käytetty aktiivinen muisti, Vaihdettu, Jaettu) + 25 % (tyhjäkäytössä oleva kulutettu muisti). Tämä osoittaa, että DRS-muistitasapaino perustuu pääasiassa VM:n aktiiviseen muistinkäyttöön, kun taas pieni osa sen käyttämättömästä muistista otetaan huomioon puskurina mahdollisen työmäärän kasvun varalta.
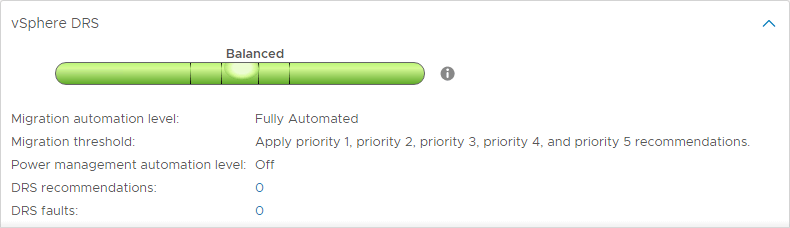
DRS-automaatiotasot
Yksi DRS:n mielenkiintoisista ominaisuuksista on DRS-automaatiotasot. Vaikka DRS jatkaa vSphere-klusterin skannausta ja antaa suosituksia viiden minuutin välein, voit määrittää, pystyykö DRS toteuttamaan suosituksensa automaattisesti vai ehdottaako se vain muutoksia, jotka pitäisi tehdä. DRS:ssä on kolme DRS-automaatiotasoa. Näitä ovat mm:
- Täysin automatisoitu – Täysin automatisoidussa toimintatavassa DRS soveltaa sekä alkusijoitus- että kuormanjakosuosituksia automaattisesti
- Osittain automatisoitu – Osittaisessa automatisoinnissa DRS soveltaa suosituksia vain VM:ien alkusijoitukseen
- Manuaalinen – Manuaalisessa tilassa, sinun on sovellettava suosituksia sekä alustavaan sijoitteluun että kuorman tasapainotussuosituksiin
DRS-siirtymiskynnysarvot
DRS sisältää toisen erittäin hyödyllisen asetuksen, jolla voidaan hallita epätasapainon määrää, jota siedetään ennen DRS-suositusten antamista. DRS-siirtymiskynnyksiä on viisi, ja niillä voidaan hallita siedettävän epätasapainon määrää.
Vaihteluväli on 1 (konservatiivisin) – 5 (aggressiivisin).
Agressiivisemmilla asetuksilla DRS sietää vähemmän epätasapainoa klusterissa. Mitä konservatiivisempi, sitä enemmän DRS sietää epätasapainoa.

VMware DRS:n VM/Host-säännöt
VMware DRS:ää käytettäessä VMware DRS:n avulla voidaan ohjata VM:ien sijoittelua vSphere DRS:ää tukevissa klustereissasi erittäin hyödyllinen ominaisuus. VM/Host-sääntöjen avulla voit käyttää tiettyjä VM:iä tietyissä ESXi-isännissä. Voit ajatella tätä tavallaan affiniteettisääntöinä.
VM/Host-sääntöjen avulla voit:
- Virtuaalikoneiden pitäminen yhdessä
- Virtuaalikoneiden erottaminen
- Virtuaalikoneiden sitominen tiettyihin isäntäkoneisiin
- Virtuaalikoneiden sitominen tiettyihin isäntäkoneisiin
Alhaalla on esimerkki virtuaalikoneiden ja ESXi-isäntäkoneiden välisen VM/Host-säännön luomiseen.
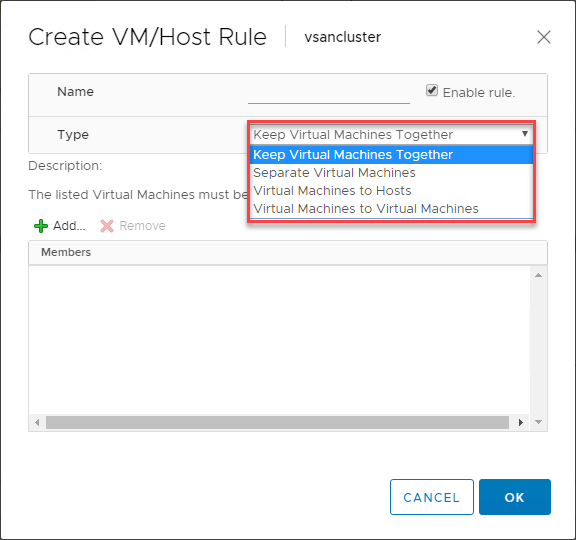
Minkälainen käyttötapaus näille VM/Host-säännöille on olemassa? Yksi klassisista käyttötapauksista, joita on olemassa, on toimialueohjaimien kanssa. Yleisesti ottaen, jos käytät kaikkia toimialueenohjaimiasi virtualisoidussa ympäristössä, kuten vSphere-klusterissa, haluat varmistaa, että toimialueenohjaimen virtuaalikoneet on erotettu toisistaan klusterin sisällä. Tällä tavoin, jos ESXi-isäntä kaatuu yhdessä yhden toimialueohjaimesi kanssa, sinulla on edelleen toimialueohjain, johon sovelletaan Separate Virtual Machines -sääntöä, joka pitää sen poissa samasta isännästä kuin toisen DC:n.
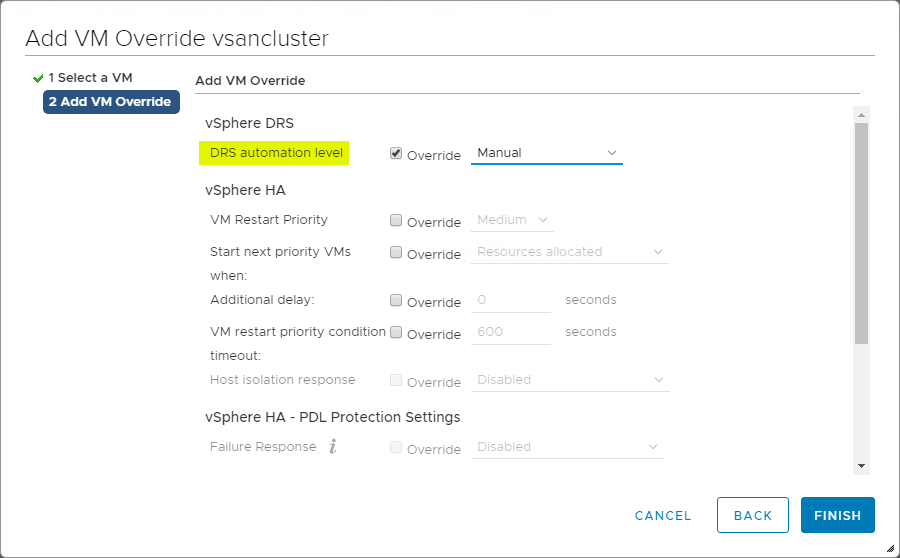
VM Overrides for DRS
VSphere Cluster tarjoaa suuren tarkkuuden toiminnoille, jotka vaikuttavat yksittäisiin VM:iin vSphere Clusterin sisällä. Voit luoda VM Overrides -asetuksia, joilla voit ohittaa klusteritasolla HA:lle ja DRS:lle määritetyt yleiset asetukset ja määrittää tarkemmat asetukset kullekin yksittäiselle VM:lle.
CPU:n ja muistin käyttöasteen yhteenveto
DRS:n avulla saat loistavan ylätason yhteenvedon suorittimen käyttöasteen yhteenvedon ESXi-isäntien suorittimen käyttöasteen resursseista vSphere-ryppään sisällä. Siirry kohtaan > Asetukset > Valvonta > vSphere DRS > CPU-käyttöaste.
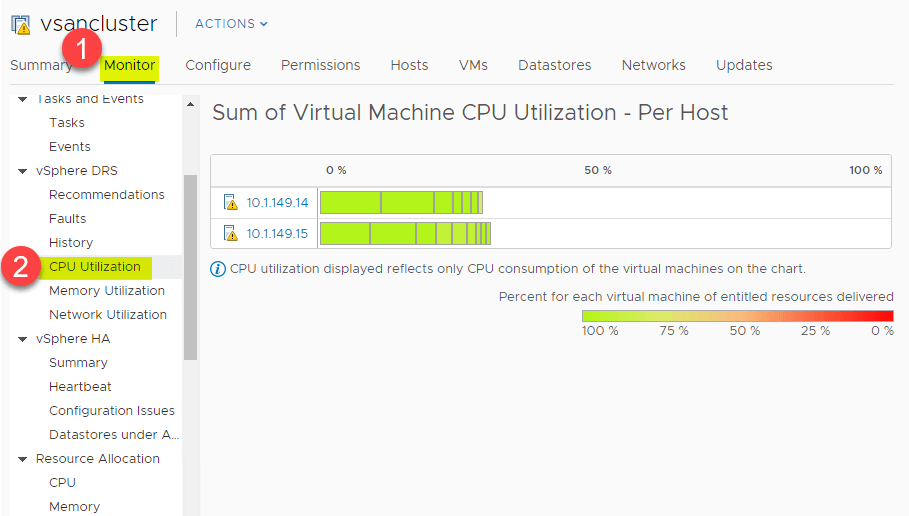
Samaa korkean tason yleiskatsausta voi tarkastella myös muistin kulutuksen osalta. Siirry kohtaan > Asetukset > Valvonta > vSphere DRS > Muistin käyttöaste
Kummankin maailman parhaat puolet
Ovatko VMware vSphere HA ja VMware DRS keskenään kilpailevia teknologioita?
Eivät ne ole. Itse asiassa on erittäin suositeltavaa käyttää sekä vSphere HA:ta että VMware DRS:ää yhdessä, jotta voidaan yhdistää automaattinen vikasietoisuus ja kuormanjako-ominaisuudet ja -toiminnot. Näin saadaan paljon joustavampi ja tasapainoisempi vSphere-ympäristö.
Jos ESXi-isäntä vikaantuu, vSphere HA käynnistää VM:t uudelleen vSphere-klusterin jäljellä olevissa terveissä isännissä. Ensimmäinen prioriteetti on siis tietenkin virtuaalikoneiden resurssien saatavuus. Tämän jälkeen VMware DRS ajaa ja määrittää, onko työtehtäviä suorittavien ESXi-isäntien välillä epätasapainoa, ja antaa suosituksia klusterin epätasapainon korjaamiseksi määritetyn siirtokynnyksen perusteella. Automaatiotason perusteella nämä suositukset toteutetaan joko automaattisesti tai vain suositellaan, jos niitä ei ole täysin automatisoitu.
Loppuajatuksia VMware vSphere HA:sta ja DRS:stä
Sekä VMware vSphere HA:n että DRS:n käyttäminen on erittäin suositeltavaa tuotannossa olevassa vSphere-klusterissa. Molempien tekniikoiden käyttäminen auttaa tekemään työtehtävistäsi korkeasti käytettävissä olevia ja varmistaa, että niillä on jatkuvasti tarvittavat resurssit VM:n CPU/muistivaatimusten perusteella.
Kummankin mekanismin toiminnan ymmärtäminen auttaa sinua vSphere-ylläpitäjänä hyödyntämään molempia tekniikoita parhaalla mahdollisella tavalla ja parhaiden käytäntöjen mukaisesti. Molempien tekniikoiden tuomien etujen lisäksi kumpikin ominaisuus on erittäin helppo ottaa käyttöön ja määrittää. Muutamalla yksinkertaisella napsautuksella vSphere-klustereiden ominaisuuksissa voit nopeasti alkaa hyötyä näistä käytettävissä olevista klusteritason ominaisuuksista.
Seuraa Twitter- ja Facebook-syötteitämme saadaksesi uusia julkaisuja, päivityksiä, oivaltavia viestejä ja paljon muuta.