By: Derek Colley | Päivitetty: Coley Colley: 2014-01-29 | Comments (5) | Related: 2014-01-29 | Comments (5) | Related: Järjestelmä
Obgelma
Haluat hakea satunnaisotoksen SQL Server -kyselyn tulosjoukosta. Ehkä etsit edustavaa otosta suuresta asiakastietokannasta; ehkä etsit joitakin keskiarvoja tai käsitystä siitä, millaisia tietoja sinulla on hallussasi. SELECT TOP N ei ole aina ihanteellinen, koska tietojen poikkeamia esiintyy usein tietokokonaisuuksien alussa ja lopussa, varsinkin kun ne on järjestetty aakkosjärjestykseen tai jonkin skalaariarvon mukaan. Samoin olet saattanut käyttää TABLESAMPLEa, mutta sillä on rajoituksia erityisesti pienten tai vinoutuneiden tietokokonaisuuksien kohdalla. Ehkäpä esimiehesi on pyytänyt sinulta satunnaisotantaa 100 asiakkaan nimistä ja sijainneista, tai olet osallistumassa tilintarkastukseen ja sinun on haettava satunnaisotos analysoitavaksi. Miten suorittaisit tämän tehtävän? Tutustu tähän vinkkiin saadaksesi lisätietoja.
Ratkaisu
Tässä vinkissä näytetään, miten voit käyttää TABLESAMPLE-ohjelmaa T-SQL:ssä pseudosattumanvaraisten datanäytteiden hakemiseen, ja puhutaan TABLESAMPLE-ohjelman sisäisistä ominaisuuksista ja siitä, missä tilanteissa se ei sovellu. Siinä esitellään myös vaihtoehtoinen menetelmä – matemaattinen menetelmä, jossa käytetään NEWID()-ohjelmaa yhdistettynä CHECKSUM- ja bitwise-operaattoriin, jonka Microsoft on todennut TABLESAMPLE TechNet-artikkelissa. Puhumme hieman tilastollisesta otannasta yleensä (satunnaisen, systemaattisen ja ositetun otannan erot) esimerkkien avulla, ja tarkastelemme esimerkkinä SQL:n tilastojen otantaa ja vaihtoehtoja, joilla voimme ohittaa tämän otannan. Kun olet lukenut vihjeen, sinulla pitäisi olla käsitys otannan eduista verrattuna TOP N:n kaltaisten menetelmien käyttöön ja osaat soveltaa ainakin yhtä menetelmää tämän saavuttamiseksi SQL Serverissä.
Setup
Tässä vihjeessä käytän tietosarjaa, joka sisältää identtisen INT-sarakkeen (satunnaisuuden asteen määrittämiseksi rivejä valittaessa) ja muita sarakkeita, jotka on täytetty erilaisilla, eri tietotyyppejä sisältävillä, näennäisesti satunnaisiksi luokitelluilla tiedoilla, jotta voidaan (epämääräisesti) simuloida todellista dataa taulukossa. Voit määrittää tämän alla olevan T-SQL-koodin avulla. Sen suorittamiseen pitäisi kulua vain muutama minuutti, ja se on testattu SQL Server 2012 Developer Edition -versiolla.
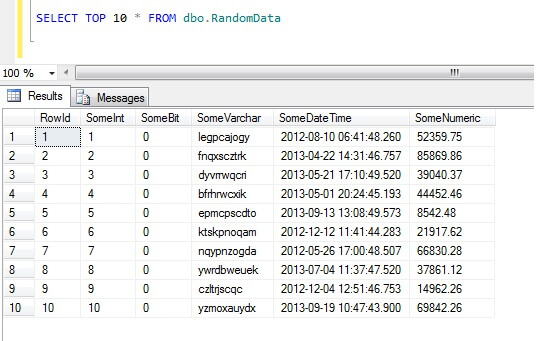
Valitsemalla 10 ylintä tietoriviä saadaan tämä tulos (vain jotta saat käsityksen tietojen muodosta).Sivuhuomautuksena mainittakoon, että tämä on yleinen koodinpätkä, jonka loin luodakseni satunnaista epäsäännöllistä dataa aina, kun tarvitsen sitä – voit vapaasti ottaa sen ja laajentaa/ryöstää sitä sydämesi kyllyydestä!
Miten ei oteta näytteitä SQL Serverissä
Nyt meillä on datanäytteemme, mietitäänpä, mitkä ovat huonoimmat tavat saada näyte. AdventureWorks-tietokannassa on taulukko nimeltä Person.Address. Otetaan näyte ottamalla 10 parasta tulosta ilman erityistä järjestystä:
SELECT TOP 10 * FROM Person.Address
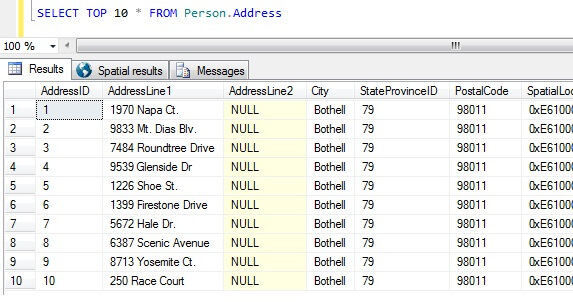
Voidaan pelkästään tämän näytteen perusteella todeta, että kaikki palautetut henkilöt asuvat Bothellissa ja jakavat postinumeron 98011. Tämä johtuu siitä, että tulokset määritettiin palautettaviksi ilman tiettyä järjestystä, mutta ne palautettiinkin AddressID-sarakkeen mukaisessa järjestyksessä. Huomaa, että tämä ei ole taattua käyttäytymistä erityisesti kasan tiedoille – katso tämä lainaus BOL:sta:
”Yleensä tiedot tallennetaan aluksi siinä järjestyksessä, jossa rivit lisätään taulukkoon, mutta tietokantamoottori voi siirtää tietoja kasassa tallentaakseen rivejä tehokkaasti, joten tietojen järjestystä ei voida ennustaa. Jos haluat taata kasasta palautettavien rivien järjestyksen, sinun on käytettävä ORDER BY -lauseketta.”
http://technet.microsoft.com/en-us/library/hh213609.aspx
Tämän tulosjoukon perusteella taulukon luonteesta tietämätön henkilö saattaisi päätellä, että kaikki heidän asiakkaansa asuvat Bothellissa.
Datanäytteenottotyypit SQL Serverissä
Ylläoleva väite on selvästi väärä, joten tarvitsemme paremman näytteenottotavan. Miten olisi, jos ottaisimme näytteen säännöllisin väliajoin koko taulukosta?
Tämän pitäisi palauttaa 47 riviä:
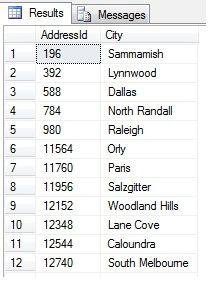
Niin pitkälle, niin hyvä. Olemme ottaneet rivejä säännöllisin väliajoin koko aineistostamme ja palauttaneet tilastollisen poikkileikkauksen – vai olemmeko? Ei välttämättä. Älä unohda, että järjestys ei ole taattu. Voimme tehdä tästä datasta yhden tai kaksi johtopäätöstä. Yhdistetään se havainnollistamiseksi. Suorita yllä oleva koodinpätkä uudelleen, mutta muuta viimeinen SELECT-lohko seuraavasti:
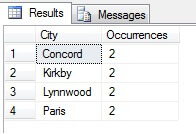
Voit nähdä esimerkissäni, että Person.Address-taulukon yli 19 000 rivin kokonaislukumäärästä olen poiminut otoksen noin 1/4 prosentista riveistä, ja siksi voin päätellä, että (esimerkissäni) Concordissa, Kirkbyssa, Lynnwoodissa ja Parisissa on eniten asukkaita ja että ne ovat lisäksi yhtä tiheästi asutut. Pitääkö se paikkansa? Hölynpölyä tietenkin:
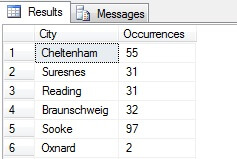
Kuten näet, yksikään näistä neljästä ei oikeastaan ollut neljän parhaan asuinpaikan joukossa tämän taulukon perusteella. Paitsi että otosdata oli liian pieni, aggregoin tämän pienen otoksen ja yritin tehdä siitä johtopäätöksiä. Tämä tarkoittaa, että tulosjoukkoni on tilastollisesti merkityksetön – tilastollisen merkitsevyyden todistaminen on yksi tärkeimmistä todistustaakoista, kun esitetään tilastollisia yhteenvetoja (tai sen pitäisi olla), ja se on monien suosittujen infografiikoiden ja markkinointijohtoisten datakaavioiden suuri kaato.
Tällainen näytteenotto (jota kutsutaan systemaattiseksi näytteenotoksi) on siis tehokasta, mutta vain tilastollisesti merkitsevän perusjoukon osalta. On olemassa tekijöitä, kuten jaksotus ja suhteellisuus, jotka voivat pilata otoksen – katsotaanpa suhteellisuutta käytännössä ottamalla 10 kaupungin otos Person.Address-taulukosta käyttämällä seuraavaa koodia, joka saa erillisen luettelon kaupungeista Person.Address-taulukosta ja valitsee sitten 10 kaupunkia tuosta luettelosta systemaattista otantaa käyttäen:
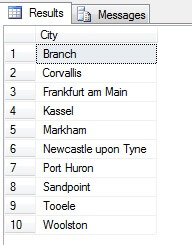
Näyttää hyvältä otokselta, eikö? Verrataan sitä nyt otokseen, joka koostuu EI-erottelevista kaupungeista, jotka on lueteltu nousevassa järjestyksessä eli joka n:nnestä kaupungista, jossa n on rivien kokonaismäärä jaettuna 10:llä. Tässä mittarissa otetaan huomioon otospopulaatio:
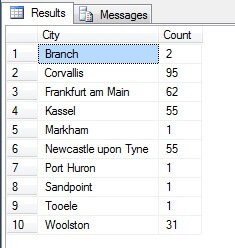
Palautetut tiedot ovat täysin erilaiset – ei sattumasta, vaan edustavan otoksen esittämisestä. Huomaa, että tämä luettelo, johon olen sisällyttänyt kunkin kaupungin lukumäärän lähdetaulukossa hahmotellakseni, kuinka paljon väestöllä on merkitystä tietojen valinnassa, sisältää otoksen neljä eniten asuttua kaupunkia, mikä (jos tarkastellaan järjestettyä ei-erottelevaa luetteloa) on oikeudenmukaisin edustus. Se ei välttämättä ole paras edustus tarpeisiisi, joten ole varovainen valitessasi tilastollista otantamenetelmää.
Muut otantamenetelmät
Ryhmittäinen otanta – tässä otantaan otettava populaatio jaetaan klustereihin eli osajoukkoihin, minkä jälkeen kukin näistä osajoukoista määritetään sattumanvaraisesti, sisällytetäänkö se tulostulosjoukkoon vai ei. Jos se on mukana, jokainen kyseisen osajoukon jäsen palautetaan tulosjoukossa. Katso tästä esimerkki alla olevasta TABLESAMPLEsta.
Disproportionaalinen otanta – tämä on kuin ositettu otanta, jossa osajoukon ryhmien jäsenet valitaan edustamaan koko ryhmää, mutta sen sijaan, että se olisi suhteutettu, kustakin ryhmästä voidaan valita eri määrä jäseniä eri ryhmien edustuksen tasoittamiseksi. Esimerkiksi kun otetaan huomioon edellä olevan kappaleen esimerkin Person.Address-tietueessa olevat kaupungit, ensimmäinen tulosjoukko oli suhteeton, koska siinä ei otettu huomioon väestöä, mutta toinen tulosjoukko oli suhteellinen, koska se edusti Person.Address-taulukon kaupunkimerkintöjen lukumäärää. Tämäntyyppinen otanta on itse asiassa hyödyllinen, jos jokin tietty luokka on aliedustettuna tietokokonaisuudessa eikä suhteellisuus ole tärkeää (esimerkiksi 100 satunnaista asiakasta 100 satunnaisesta kaupungista, jotka on ositettu kaupungin mukaan – osajoukon kaupungit tarvitsisivat normalisointia – voitaisiin käyttää suhteetonta otantaa).
SQL Serverin satunnaistettu aineisto taulukkonäytteellä
SQL Serverin mukana tulee avuliaasti menetelmä, jonka avulla voidaan tehdä näytteenotto datasta. Katsotaanpa sitä toiminnassa. Käytä seuraavaa koodia palauttaaksesi noin 100 riviä (jos se palauttaa 0 riviä, suorita uudestaan – selitän hetken kuluttua) aiemmin määrittelemämme dbo.RandomData -datan tietoja.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
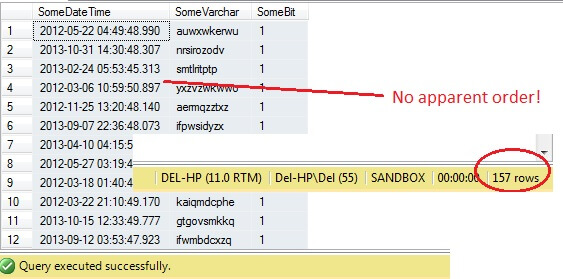
Niinhän se menee hyvin? Hetkinen – emme näe Id-saraketta. Otetaan tämä mukaan ja suoritetaan uudelleen:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
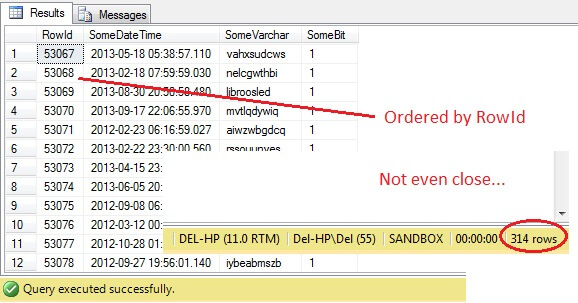
Voi voi – TABLESAMPLE on valinnut siivun datasta, mutta se ei ole sattumanvarainen – RowId osoittaa selvästi rajatun siivun, jolla on minimi- ja maksimiarvo. Lisäksi se ei ole myöskään palauttanut tasan 100 riviä. Mitä on tekeillä?
TABLESAMPLE käyttää implisiittistä SYSTEM-modifikaattoria. Tämä modifioija, joka on oletusarvoisesti päällä ja ANSI-SQL-määritys eli ei valinnainen, ottaa jokaisen 8KB:n sivun, jolla taulukko sijaitsee, ja päättää, sisällytetäänkö tuotettuun näytteeseen kaikki kyseisellä sivulla olevat rivit, jotka ovat kyseisessä taulukossa, prosenttiluvun tai syötetyn N ROWSin perusteella. Näin ollen taulukon, joka sijaitsee monilla sivuilla eli jossa on suuria tietorivejä, pitäisi palauttaa satunnaisempi otos, koska otoksessa on enemmän sivuja. Se ei onnistu meidän esimerkkimme kaltaisessa tapauksessa, jossa tiedot ovat skalaarisia ja pieniä ja sijaitsevat vain muutamalla sivulla – jos jotkin sivut eivät pääse leikkaukseen, tämä voi vääristää tulostettua otosta merkittävästi. Tämä on TABLESAMPLE-ohjelman huono puoli – se ei toimi hyvin ”pienille” tiedoille eikä se ota huomioon tietojen jakautumista sivuille. Tietojen sijoittelu sivuilla on siis viime kädessä vastuussa tämän metodin palauttamasta otoksesta.
Kuulostaako tämä tutulta? Kyseessä on pohjimmiltaan klusterinäytteenotto, jossa kaikki valittujen ryhmien (klustereiden) jäsenet (rivit) ovat edustettuina tulosjoukossa.
Testataan sitä suurella taulukolla, jotta korostetaan käänteistä skaalautumattomuutta. Tunnistetaan ensin AdventureWorks-tietokannan suurin taulukko. Käytämme tähän vakioraporttia – napsauta SSMS:n avulla hiiren kakkospainikkeella AdventureWorks2012-tietokantaa ja valitse Raportit -> Vakioraportit -> Levynkäyttö suurimpien taulukoiden mukaan. Järjestä tiedot (KB) napsauttamalla sarakeotsikkoa (saatat haluta tehdä tämän kahdesti, jotta järjestys olisi laskeva). Näet alla olevan raportin.
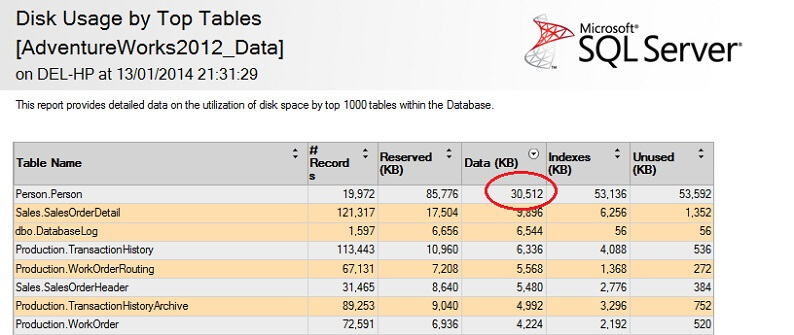
Olen ympyröinyt mielenkiintoisen luvun – Henkilö. Person-taulu kuluttaa 30,5 Mt dataa ja on suurin (datan, ei tietueiden määrän mukaan) taulukko. Kokeillaan sen sijaan ottaa näyte tästä taulusta:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
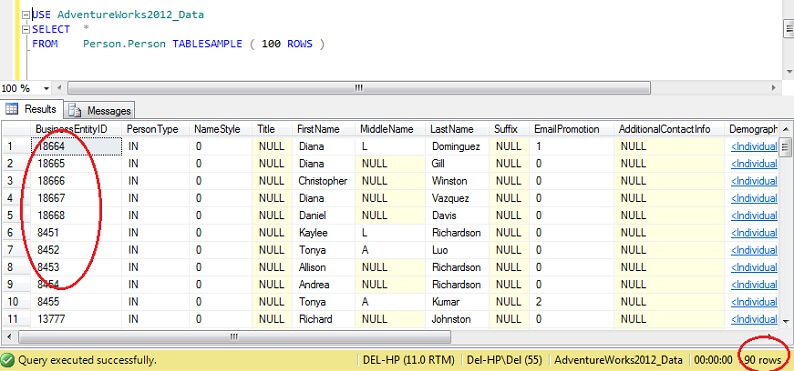
Voit nähdä, että olemme paljon lähempänä sataa riviä, mutta ratkaisevaa on se, että primääriavaimella ei näytä olevan juurikaan klusteroitumista (vaikkakin jonkin verran, koska rivejä on useampi kuin yksi per sivu).
Siten TABLESAMPLE on hyvä suurille tiedoille, ja se huononee katastrofaalisesti sitä huonommin, mitä pienempi tietokokonaisuus on. Tämä ei ole hyväksi, kun otamme näytteitä ositetusta datasta tai klusteroidusta datasta, jossa otamme monia näytteitä pienistä ryhmistä tai datan osajoukoista ja sitten aggregoimme ne. Katsotaan sitten vaihtoehtoista menetelmää.
SQL Serverin satunnaisotanta ORDER BY NEWID()
Tässä on lainaus BOL:sta aidosti satunnaisotannan saamisesta:
”Jos todella haluat satunnaisotannan yksittäisistä riveistä, muokkaa kyselyäsi niin, että suodatat rivejä satunnaisesti, sen sijaan että käyttäisit TAULUKKOOTTA. Esimerkiksi seuraavassa kyselyssä käytetään NEWID-funktiota palauttamaan noin yksi prosentti Sales.SalesOrderDetail-taulun riveistä:
Miten tämä toimii? Jaetaan WHERE-lauseke ja selitetään se.
CHECKSUM-funktio laskee tarkistussumman luettelon kohtien yli. Voidaan kiistellä siitä, tarvitaanko SalesOrderID-tunnusta edes, koska NEWID() on funktio, joka palauttaa uuden satunnaisen GUID-tunnuksen, joten satunnaisluvun kertomisen vakiolla pitäisi joka tapauksessa johtaa satunnaislukuun.Itse asiassa SalesOrderID-tunnuksen pois jättämisellä ei näytä olevan mitään merkitystä. Jos olet innokas tilastotieteilijä ja voit perustella tämän sisällyttämisen, käytä alla olevaa kommenttikenttää ja kerro minulle, miksi olen väärässä!
Funktio CHECKSUM palauttaa VARBINARYn. Suorittamalla bittimääräinen AND-operaatio 0x7fffffffff:n kanssa, joka vastaa (11111111111…) binäärissä, saadaan desimaaliarvo, joka on käytännössä esitys satunnaisesta 0:n ja 1:n merkkijonosta. Jakaminen kertoimella 0x7fffffffff käytännössä normalisoi tämän desimaaliluvun luvuksi, joka on välillä 0 ja 1. Sitten päätettäessä, onko kukin rivi syytä sisällyttää lopulliseen tulosjoukkoon, käytetään kynnysarvoa 1/x (tässä tapauksessa 0.01), jossa x on prosenttiosuus datasta, joka haetaan näytteeksi.
Varoittelen, että tämä menetelmä on pikemminkin satunnaisotantaa kuin systemaattista näytteenottoa, joten olet todennäköisesti saamassa dataa lähdeaineistosi kaikilta osilta, mutta avainsanana tässä on se, että *voi olla myös mahdollista*. Satunnaisotannan luonne tarkoittaa, että mikä tahansa keräämäsi näyte voi olla vinoutunut johonkin aineistosi osaan, joten hyötyäkseen regressiosta keskiarvoon (taipumus kohti satunnaista tulosta tässä tapauksessa) varmista, että otat useita näytteitä ja valitset osajoukon näistä, jos tuloksesi näyttävät vinoutuneilta. Vaihtoehtoisesti voit ottaa näytteitä aineistosi osajoukoista ja yhdistää nämä – tämä on toisenlainen otanta, jota kutsutaan ositelluksi otannaksi.
Miten SQL Serverin tilastoista otetaan näytteitä?
SQL Serverissä sarakkeiden tai käyttäjän määrittelemien tilastojen automaattinen päivitys tapahtuu aina, kun taulukon rivejä muutetaan tietyssä taulukossa tietyn kynnysarvon verran. Vuonna 2012 tämä kynnysarvo lasketaan SQRT(1000 * TR), jossa TR on taulukon rivien määrä taulukossa. Ennen vuotta 2005 automaattinen tilastojen päivitystyö käynnistyi jokaista (500 riviä + 20 prosentin muutos) taulukon riviä kohti. Kun automaattinen päivitysprosessi käynnistyy, näytteenotto *vähentää näytteeksi otettavien rivien määrää, mitä suuremmaksi taulukko kasvaa*, toisin sanoen taulukon näytteenottoprosentin ja taulukon koon välillä on käänteistä suhdetta muistuttava suhde, mutta se noudattaa omaa algoritmia.
Kiinnostavaa on, että tämä näyttää olevan päinvastainen kuin vaihtoehdossa TABLESAMPLE (N PERCENT) (Taulukkonäytteenotto (N-PROSENTTI)-vaihtoehto), jossa näytteeksi otettavien rivien määrä on normaalissa suhteessa taulukon rivien määrään. Voimme poistaa automaattisen tilastoinnin käytöstä (ole varovainen tämän kanssa) ja päivittää tilastot manuaalisesti – tämä onnistuu käyttämällä NORECOMPUTE-käskyä UPDATE STATISTICS -lauseessa. UPDATE STATISTICS -lausekkeella voimme ohittaa joitakin vaihtoehtoja – voimme esimerkiksi valita otoksen N riviä tai N prosenttia (kuten TABLESAMPLE), suorittaa FULLSCAN-mittauksen tai yksinkertaisesti RESAMPLE-mittauksen käyttäen viimeisintä tunnettua määrää.
Seuraavat vaiheet
Lisälukemista varten Joseph Sack on Microsoftin MVP, joka tunnetaan työstään SQL Serverin tilastollisen analyysin parissa – alla on joitakin linkkejä hänen työhönsä sekä viittauksia tässä artikkelissa käytettyihin töihin ja joihinkin aiheeseen liittyviin vinkkeihin MSSQLTips.com-sivustolta. Kiitos lukemisesta!
Viimeisin päivitetty: 2014-01-29


Tietoa kirjoittajasta
 Derek Colley on Isossa-Britanniassa työskentelevä DBA-ohjelmistopäällikkö (DBA) ja BI-kehittäjä (BI Developer), jolla on takanaan yli vuosikymmenen kokemus työskentelystä SQL Serverin, Oraclen ja MySQL-tietokannan kanssa.
Derek Colley on Isossa-Britanniassa työskentelevä DBA-ohjelmistopäällikkö (DBA) ja BI-kehittäjä (BI Developer), jolla on takanaan yli vuosikymmenen kokemus työskentelystä SQL Serverin, Oraclen ja MySQL-tietokannan kanssa.Katso kaikki vinkkini
- Muut tietokantakehittäjän vinkit…