Esittely
Jos analysoit aineistojasi käyttämällä moninkertaista regressiota ja jokin riippumattomista muuttujista on mitattu nimellis- tai ordinaaliasteikolla, sinun on tiedettävä, miten luodaan dummy-muuttujia ja miten tulkitaan niiden tuloksia. Tämä johtuu siitä, että nominaalisia ja ordinaalisia riippumattomia muuttujia, jotka tunnetaan laajemmin kategorisina riippumattomina muuttujina, ei voida suoraan syöttää moninkertaiseen regressioanalyysiin. Sen sijaan ne on muunnettava dummy-muuttujiksi. Poikkeuksena ovat ordinaaliset riippumattomat muuttujat, jotka syötetään moninkertaiseen regressioanalyysiin jatkuvina riippumattomina muuttujina, joita ei tarvitse muuntaa dummy-muuttujiksi. Siksi tässä oppaassa näytämme, miten luodaan dummy-muuttujia, kun sinulla on kategorisia riippumattomia muuttujia.
Aluksi esitämme esimerkin, jonka avulla näytämme, miten luodaan dummy-muuttujia SPSS Statisticsissa, ennen kuin selitämme, miten asetat aineistosi SPSS Statisticsin Variable View (Muuttujanäkymä) ja Data View (Tiedonäkymä) -ikkunoissa niin, että voit luoda dummy-muuttujia. Jos dummy-muuttujien käyttö ei ole sinulle tuttua, suosittelemme, että luet sen jälkeen joitakin dummy-muuttujien ja dummy-koodauksen perusperiaatteita, mukaan lukien: (a) analyysissä luotavien dummy-muuttujien määrästä ja b) dummy-muuttujien ja dummy-koodauksen luomisesta. Seuraavassa Proseduuri-osassa esitellään SPSS Statisticsin yksinkertainen, kolmivaiheinen Create Dummy Variables -proseduuri, jota voidaan käyttää dummy-muuttujien luomiseen. Lopuksi selitämme SPSS Statisticsin tulosteen Create Dummy Variables -proseduurin suorittamisen jälkeen, mukaan lukien sen, miten dummy-muuttujasi asetetaan nyt SPSS Statisticsin Variable View- ja Data View -ikkunoihin.
Huomautus: Jos huomaat, että tässä oppaassa esitetyt proseduurit eivät kata haluamasi tyyppisiä dummy-muuttujia, ota yhteyttä meihin. Voimme ehkä lisätä sivustolle toisen oppaan avuksi.
SPSS Statistics
Tässä oppaassa käytetty esimerkki
Tässä oppaassa käytämme esimerkkinä kymmentä triathlonistia, joita pyydettiin valitsemaan suosikkilajinsa kolmesta lajista, joita he harrastavat triathlonia suorittaessaan: uinti, pyöräily ja juoksu. Heidän vastauksensa kirjattiin nimelliseen riippumattomaan muuttujaan favourite_sport, jossa on kolme luokkaa: ”uinti”, ”pyöräily” ja ”juoksu”. Tämä nimellinen riippumaton muuttuja favorite_sport oli tarkoitus sisällyttää moninkertaiseen regressioanalyysiin, jossa oli myös useita jatkuvia riippumattomia muuttujia. Koska tämä riippumaton muuttuja oli kategorinen (eli nominaaliset muuttujat ja ordinaaliset muuttujat voidaan laajasti luokitella kategorisiksi muuttujiksi), oli luotava dummy-muuttujia, ennen kuin se voitiin syöttää moninkertaiseen regressioanalyysiin.
Tärkeää: Huomaa, että favourite_sport on nominaalinen muuttuja, mutta voit luoda dummy-muuttujia myös ordinaaliselle muuttujalle. Lisäksi dummy-muuttujien luomisprosessi on sama riippumatta siitä, onko kyseessä ordinaali- vai nominaalimuuttuja, lukuun ottamatta yhtä pientä muutosta, joka sinun on tehtävä aineiston määrityksessä ja joka selitetään jäljempänä.
Huomautus 1: Kategorisen riippumattoman muuttujan ”luokkia” kutsutaan myös ”ryhmiksi” tai ”tasoiksi”, mutta termi ”tasot” varataan yleensä luokkia varten, joilla on järjestysjärjestys (esim. ordinaalisella riippumattomalla muuttujalla ”kuntoilutaso” voisi olla kolme tasoa: ”alhainen”, ”kohtalainen” ja ”korkea”). Näitä kolmea termiä – ”luokat”, ”ryhmät” ja ”tasot” – voidaan kuitenkin käyttää vaihdellen. Tässä oppaassa viittaamme niihin kategorioina, mutta voit halutessasi viitata niihin ryhminä tai tasoina.
Huomautus 2: Termiä ”tekijät” käytetään toisinaan ”kategoristen riippumattomien muuttujien” (eli riippumattomien muuttujien, jotka ovat ”ordinaalisia” tai ”nominaalisia”) sijasta. Näitä kahta termiä – ”kategoriset riippumattomat muuttujat” ja ”tekijät” – voidaan kuitenkin käyttää vaihdellen. Tässä oppaassa viittaamme niihin kategorisina riippumattomina muuttujina, ja näet myös SPSS Statisticsin viittaavan niihin riippumattomina muuttujina eikä tekijöinä moninkertaisessa regressiomenettelyssä. Voit kuitenkin halutessasi viitata niihin tekijöinä.
SPSS Statistics
Aineiston määrittäminen SPSS Statisticsissa
Luodessasi dummy-muuttujia aloitat yhden kategorisen riippumattoman muuttujan (esim. suosikki_urheilu) avulla. Tämän kategorisen riippumattoman muuttujan määrittämistä varten SPSS Statisticsissa on Variable View (Muuttujanäkymä), jossa määrittelet analysoitavan muuttujan tyypit, ja Data View (Tiedonäkymä), johon syötät tämän muuttujan tiedot. Tässä jaksossa näytetään ensin, miten kategorinen riippumaton muuttuja määritetään SPSS Statisticsin Variable View -ikkunassa, ennen kuin näytetään, miten tiedot syötetään Data View -ikkunaan. Teemme tämän käyttämällä kategorista riippumatonta muuttujaamme favourite_sport, jossa on kolme luokkaa: ”uinti”, ”pyöräily” ja ”juoksu”.
The Variable View in SPSS Statistics
Yhden kategorisen riippumattoman muuttujan (esim, favourite_sport), Variable View -ikkunasi näyttää alla olevan kaltaiselta:
Huomautus: Pääset Variable View -ikkunaan SPSS Statistics -ohjelmistossa napsauttamalla ![]() -välilehteä SPSS Statistics -ohjelmiston vasemmassa alakulmassa.
-välilehteä SPSS Statistics -ohjelmiston vasemmassa alakulmassa.
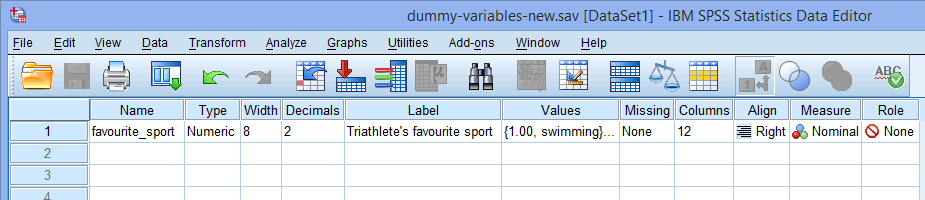
Published with written permission from SPSS Statistics, IBM Corporation.
Kategorisen riippumattoman muuttujasi nimi on kirjoitettava ![]() -sarakkeen alla olevaan soluun (esim, ”favourite_sport” riville
-sarakkeen alla olevaan soluun (esim, ”favourite_sport” riville ![]() edustamaan kategorista riippumatonta muuttujaamme favorite_sport. On olemassa tiettyjä ”laittomia” merkkejä, joita ei voi syöttää
edustamaan kategorista riippumatonta muuttujaamme favorite_sport. On olemassa tiettyjä ”laittomia” merkkejä, joita ei voi syöttää ![]() -soluun. Jos siis saat virheilmoituksen ja haluat, että lisäämme SPSS Statistics -oppaan, jossa selitetään, mitä nämä laittomat merkit ovat, ota meihin yhteyttä.
-soluun. Jos siis saat virheilmoituksen ja haluat, että lisäämme SPSS Statistics -oppaan, jossa selitetään, mitä nämä laittomat merkit ovat, ota meihin yhteyttä.
Huomautus: Oman selkeytensä vuoksi voit myös antaa muuttujillesi merkinnän sarakkeeseen ![]() . Esimerkiksi merkintä, jonka annoimme sarakkeelle ”favourite_sport”, oli ”Triathlete’s favourite sport”.
. Esimerkiksi merkintä, jonka annoimme sarakkeelle ”favourite_sport”, oli ”Triathlete’s favourite sport”.
Sarakkeen ![]() alla olevan solun tulisi sisältää tiedot kategorisen riippumattoman muuttujasi kategorioista (esim. ”uinti”, ”pyöräily” ja ”juoksu” sarakkeelle favorite_sport. Jos haluat syöttää nämä tiedot, napsauta riippumattoman muuttujasi
alla olevan solun tulisi sisältää tiedot kategorisen riippumattoman muuttujasi kategorioista (esim. ”uinti”, ”pyöräily” ja ”juoksu” sarakkeelle favorite_sport. Jos haluat syöttää nämä tiedot, napsauta riippumattoman muuttujasi ![]() -sarakkeen alla olevaa solua. Soluun ilmestyy
-sarakkeen alla olevaa solua. Soluun ilmestyy ![]() -painike. Napsauta tätä painiketta ja Value Labels -valintaikkuna tulee näkyviin. Sinun on nyt annettava jokaiselle riippumattoman muuttujasi luokalle ”arvo”, jonka kirjoitat Value: -kenttään (esim. ”1”), sekä ”nimike”, jonka kirjoitat Label: -kenttään (esim. ”uinti”). Klikkaamalla
-painike. Napsauta tätä painiketta ja Value Labels -valintaikkuna tulee näkyviin. Sinun on nyt annettava jokaiselle riippumattoman muuttujasi luokalle ”arvo”, jonka kirjoitat Value: -kenttään (esim. ”1”), sekä ”nimike”, jonka kirjoitat Label: -kenttään (esim. ”uinti”). Klikkaamalla ![]() -painiketta koodaus ilmestyy päälaatikkoon (esim. ”1.00=”uinti” suosikki_urheilulle). Kategorisen riippumattoman muuttujamme asetukset näkyvät alla olevassa Value Labels -valintaikkunassa:
-painiketta koodaus ilmestyy päälaatikkoon (esim. ”1.00=”uinti” suosikki_urheilulle). Kategorisen riippumattoman muuttujamme asetukset näkyvät alla olevassa Value Labels -valintaikkunassa:
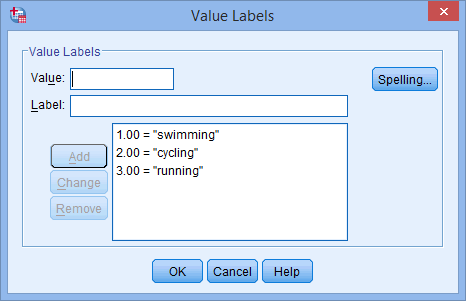
Published with written permission from SPSS Statistics, IBM Corporation.
Sarakkeen ![]() alapuolella olevassa solussa pitäisi näkyä
alapuolella olevassa solussa pitäisi näkyä ![]() , jos käytössäsi on nimellinen riippumaton muuttuja (esim, favorite_sport, kuten esimerkissämme) tai
, jos käytössäsi on nimellinen riippumaton muuttuja (esim, favorite_sport, kuten esimerkissämme) tai ![]() , jos sinulla on ordinaalinen riippumaton muuttuja (esim. kuvittele ordinaalinen muuttuja, kuten ”Body Mass Index” (BMI), BMI), jolla on neljä tasoa: ”alipainoinen”, ”terve/normaalipainoinen”, ”ylipainoinen” ja ”lihava”). Lopuksi sarakkeen
, jos sinulla on ordinaalinen riippumaton muuttuja (esim. kuvittele ordinaalinen muuttuja, kuten ”Body Mass Index” (BMI), BMI), jolla on neljä tasoa: ”alipainoinen”, ”terve/normaalipainoinen”, ”ylipainoinen” ja ”lihava”). Lopuksi sarakkeen ![]() alla olevan solun pitäisi näyttää
alla olevan solun pitäisi näyttää ![]() .
.
Huomautus: Ehdotamme, että sarakkeen ![]() alla oleva solu muutetaan
alla oleva solu muutetaan ![]() :stä
:stä ![]() :ksi, mutta tätä muutosta ei tarvitse tehdä. Suosittelemme sitä, koska SPSS Statisticsissa on tiettyjä analyysejä, joissa
:ksi, mutta tätä muutosta ei tarvitse tehdä. Suosittelemme sitä, koska SPSS Statisticsissa on tiettyjä analyysejä, joissa ![]() -asetus johtaa siihen, että muuttujasi siirretään automaattisesti käyttämiesi valintaikkunoiden tiettyihin kenttiin. Koska et ehkä halua siirtää näitä muuttujia, ehdotamme, että muutat
-asetus johtaa siihen, että muuttujasi siirretään automaattisesti käyttämiesi valintaikkunoiden tiettyihin kenttiin. Koska et ehkä halua siirtää näitä muuttujia, ehdotamme, että muutat ![]() -asetuksen
-asetuksen ![]() :ksi, jotta näin ei tapahdu automaattisesti.
:ksi, jotta näin ei tapahdu automaattisesti.
Olet nyt onnistuneesti syöttänyt Variable View -ikkunaan kaikki SPSS Statisticsin tarvitsemat tiedot kategorisesta riippumattomasta muuttujasta. Seuraavassa osiossa näytämme, miten syötät tietosi Data View -ikkunaan.
The Data View in SPSS Statistics
Pohjautuen kategorisen riippumattoman muuttujasi tiedostoasetuksiin edellä Variable View -ikkunassa, Data View -ikkunan näkymä näyttää seuraavalta:
Huomautus: Pääset Data View -ikkunaan SPSS Statistics -ohjelmistossa napsauttamalla SPSS Statistics -ohjelmiston vasemmassa alareunan ![]() -välilehteä.
-välilehteä.
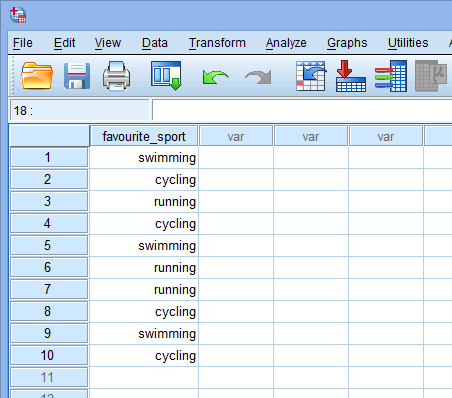
Published with written permission from SPSS Statistics, IBM Corporation.
Kategorinen riippumaton muuttujasi näkyy ensimmäisessä sarakkeessa, koska syötimme muuttujan tässä järjestyksessä Variable View -ikkunaan. Esimerkissämme 10 triathlonistin vastaukset esitetään ![]() -sarakkeessa. Nyt sinun on vain syötettävä tietosi tämän ensimmäisen sarakkeen alla oleviin soluihin. Muista, että jokainen rivi edustaa yhtä tapausta (esim. tapaus voi olla yksi osallistuja). Esimerkkimme rivillä
-sarakkeessa. Nyt sinun on vain syötettävä tietosi tämän ensimmäisen sarakkeen alla oleviin soluihin. Muista, että jokainen rivi edustaa yhtä tapausta (esim. tapaus voi olla yksi osallistuja). Esimerkkimme rivillä ![]() ensimmäinen tapaus edustaa siis triathlonistia, jonka lempilaji on ”uinti”. Koska nämä solut ovat aluksi tyhjiä, sinun on napsautettava soluihin syöttääksesi tiedot. Huomaat, että kun napsautat
ensimmäinen tapaus edustaa siis triathlonistia, jonka lempilaji on ”uinti”. Koska nämä solut ovat aluksi tyhjiä, sinun on napsautettava soluihin syöttääksesi tiedot. Huomaat, että kun napsautat ![]() -sarakkeen alla oleviin soluihin, SPSS Statistics antaa sinulle avattavan vaihtoehdon, jossa luokkasi ovat jo valmiiksi täytettyinä.
-sarakkeen alla oleviin soluihin, SPSS Statistics antaa sinulle avattavan vaihtoehdon, jossa luokkasi ovat jo valmiiksi täytettyinä.
Nyt kun olet määrittänyt tietosi SPSS Statisticsin Variable View (Muuttujanäkymä) ja Data View (Tiedonäkymä) -ikkunoissa, suosittelemme lukemaan seuraavan jakson: Understanding dummy variables and dummy coding, jossa selitetään dummy-muuttujien ja dummy-koodauksen perusperiaatteet. Jos olet kuitenkin jo perehtynyt dummy-muuttujien ja dummy-koodauksen perusteisiin, voit ohittaa tämän jakson ja siirtyä suoraan Proseduuri-osioon, jossa esitellään SPSS Statisticsin Create Dummy Variables -proseduuri, jota käytetään dummy-muuttujien luomiseen.
SPSS Statistics
Dummy-muuttujien ja dummy-koodauksen ymmärtäminen
Kuten mainitsimme johdannossa, jos analysoit aineistojasi käyttämällä moninkertaista regressiota ja jokin riippumattomista muuttujistasi mitattiin nimellis- tai ordinaaliasteikolla, sinun on tiedettävä, miten dummy-muuttujia luodaan ja miten niiden tuloksia tulkitaan. Tämä johtuu siitä, että kategorisia riippumattomia muuttujia (eli nominaalisia ja ordinaalisia riippumattomia muuttujia) ei voi syöttää suoraan moninkertaiseen regressioon. Sen sijaan ne on muunnettava dummy-muuttujiksi. Poikkeuksena ovat ordinaaliset riippumattomat muuttujat, jotka syötetään moninkertaiseen regressioon jatkuvina riippumattomina muuttujina, joita ei tarvitse muuntaa dummy-muuttujiksi. Jäljempänä olevissa jaksoissa selitetään: (
Luotavien dummy-muuttujien määrä
Luotavien dummy-muuttujien määrä riippuu siitä, kuinka monta luokkaa kategorisella riippumattomalla muuttujalla on. Yleissääntönä on, että luot yhden dummy-muuttujan vähemmän kuin kategorisessa riippumattomassa muuttujassasi on luokkia. Jos sinulla on esimerkiksi kategorinen riippumaton muuttuja, jossa on kolme luokkaa (esim. favorite_sport, jossa on seuraavat kolme luokkaa: ”uinti”, ”pyöräily” ja ”juoksu”), luot kaksi tyhjää muuttujaa ja valitset yhden luokan toimimaan viitekategoriana (esim. ”uinti” ja ”pyöräily” muuttuvat tyhjiksi muuttujiksi ja ”juoksusta” tulee viitekategoria). Selitämme lisää viitekategorioista seuraavan taulukon jälkeen, jossa on joitakin esimerkkejä kategorisista riippumattomista muuttujista ja luotavien dummy-muuttujien määrästä:
| Kategorisen riippumattoman muuttujan nimi | Muuttujan tyyppi | Luokkien määrä | Luokkien lukumäärä | Luokkien lukumäärä. dummy-muuttujat | |||
|---|---|---|---|---|---|---|---|
| 1 | Sukupuoli | Nominaalinen | Kaksi (Miehet & Naiset) |
Yksi=Miehet ”Naiset” on viiteryhmä |
|||
| 2 | Height | Ordinal | Two (Under 180cm & 180cm and above) |
One=Under 180cm ”180cm ja yli” on viiteryhmä |
|||
| 3 | Etnisyys | Nimellinen | Kolme (Afroamerikkalainen, Caucasian & Hispanic) |
Two=African American & Caucasian ”Hispanic” on viitekategoria |
|||
| 4 | Physical activity level | Ordinal | Three (Low, Kohtalainen & Korkea) |
Kaksi=Alhainen & Kohtalainen ”Korkea” on viitekategoria |
|||
| 5 | Ammatti | Nominaalinen | Neljä (Kirurg, Lääkäri, Sairaanhoitaja & Terapeutti) |
Kolme=Kirurgi, Lääkäri & Sairaanhoitaja ”Terapeutti” on viitekategoria |
|||
| 6 | Yksilöntaso | Ordinaali | Neljä (Täysin samaa mieltä, samaa mieltä, Eri mieltä, Täysin eri mieltä) |
Kolme=Täysin samaa mieltä, Samaa mieltä & Eri mieltä ”Täysin eri mieltä” on viitekategoria |
|||
| 7 | Ainealue | Nominaalinen | Viisi (Liiketaloustiede, Psykologia, Biologiset tieteet, Insinööritieteet & Oikeustiede) |
Neljä=Kauppatieteet, Psykologia, Biologiset tieteet & Insinööritieteet ”Oikeustiede” on viiteluokka |
|||
| 8 | Aika | Ordinaali | Viisi (Alle 18, 19-30, 31-40, 41-50, 51-60) |
Four=Under 18, 19-30, 31-40 & 41-50 ”51-60” on viiteryhmä |
|||
| Taulukko: Esimerkkejä kategorisista riippumattomista muuttujista ja niitä vastaavista dummy-muuttujista | |||||||
Kuten yllä olevasta taulukosta käy ilmi, sinun tarvitsee luoda vain yksi dummy-muuttuja vähemmän kuin kategorisen riippumattoman muuttujasi luokkien määrä. Tämä johtuu siitä, että sinun tarvitsee (ja kannattaa) siirtää tämä määrä dummy-muuttujia moninkertaiseen regressioon vain silloin, kun sinulla on kategorinen riippumaton muuttuja. On kuitenkin hyviä syitä luoda dummy-muuttuja kategorisen riippumattoman muuttujan jokaista luokkaa varten: (a) se on joustavampaa ja (b) se mahdollistaa useiden vertailujen tekemisen (ks. huomautus jäljempänä). Toisin sanoen, jos kategorisessa riippumattomassa muuttujassasi on kolme luokkaa, sinun pitäisi luoda kolme dummy-muuttujaa, ei vain kahta.
SpSS Statisticsin versiossa 22 ja uudemmissa versioissa oleva Create Dummy Variables -proseduuri luo onneksi automaattisesti dummy-muuttujan kategorisen riippumattoman muuttujan jokaiselle luokalle. Tämä ei kuitenkaan päde SPSS Statisticsin versiossa 21 tai sitä aikaisemmissa versioissa käytetyssä Recode into Different Variables -menettelyssä. Siksi normaalitilanteessa olet luonut SPSS Statisticsissa seuraavan asetelman riippuen siitä, onko käytössäsi versio 21 tai aikaisempi vai versio 22 ja uudempi:
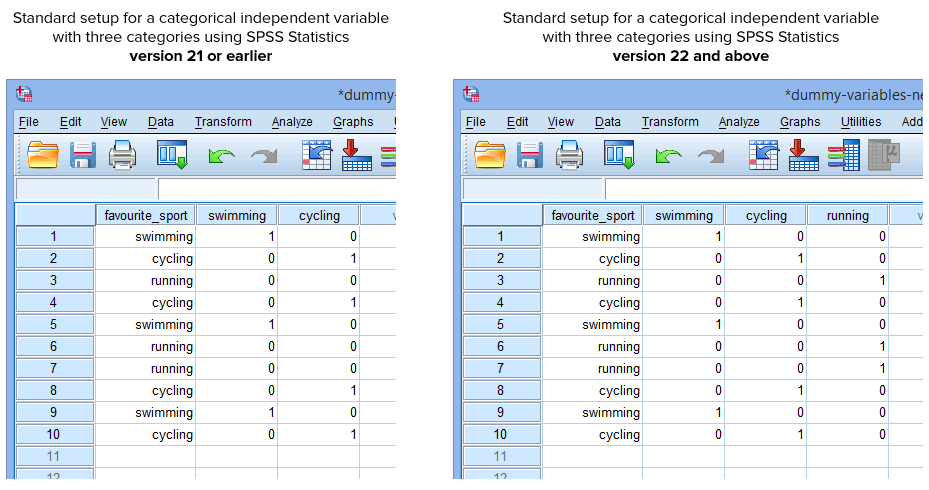
Published with written permission from SPSS Statistics, IBM Corporation.
Huomautus: Kuten edellä mainittiin, dummy-muuttujan luominen kategorisen riippumattoman muuttujan jokaiselle luokalle on hyödyllistä kahdesta syystä: (a) se on joustavampi ja (b) se mahdollistaa useiden vertailujen tekemisen. Seuraavassa käsitellään lyhyesti näitä etuja:
Se on joustavampaa:
Kun olet luonut dummy-muuttujan kategorisen riippumattoman muuttujasi jokaiselle luokalle, voit sitten pitää mitä tahansa luokkaa vertailuluokkana. Esimerkissämme pidimme ”juoksu”-luokkaa viitekategoriana, mikä tarkoittaa, että olisimme siirtäneet ”uinnin” ja ”pyöräilyn” moninkertaiseen regressioyhtälöön. Jos kuitenkin myöhemmin muuttaisimme mieliämme viitekategorian valinnasta, meidän olisi suoritettava dummy-muuttujamenettely uudelleen (paitsi jos käytössäsi on SPSS Statisticsin versio 22 tai uudempi). Oletetaan esimerkiksi, että haluaisimme nyt pitää ”pyöräily”-luokkaa vertailuluokkana. Voisimme nyt siirtää ”uinti” ja ”juoksu” dummy-muuttujat moninkertaiseen regressioyhtälöön, koska meillä on myös ”juoksu” dummy-muuttuja.
Se mahdollistaa useiden vertailujen tekemisen:
Dummy-muuttujan kerroin edustaa sen luokan, jota kyseinen dummy-muuttuja edustaa, ja viitekategorian välistä eroa. Esimerkiksi kun viitekategoriana on ”juoksu”, ”uinti”-dummy-muuttujan kerroin edustaa riippuvan muuttujan eroa ”uinti”- ja ”juoksu”-luokkien välillä. Tätä menetelmää käytettäessä kaikki luokkien yhdistelmät eivät ole mahdollisia. Tämä ongelma voidaan ratkaista käyttämällä eri vertailuluokkia. Tämä on mahdollista, jos kategorisen muuttujan kaikilla kategorioilla on dummy-muuttuja.
Miten luodaan dummy-muuttujia ja dummy-koodausta
Dummy-muuttujien menestyksekkääseen asettamiseen moninkertaisessa regressiossa on kaksi vaihetta: (1) Luo dummy-muuttujat, jotka edustavat kategorisen riippumattoman muuttujasi luokkia; ja (2) syötä näihin dummy-muuttujiin arvot – joita kutsutaan dummy-koodaukseksi – edustamaan kategorisen riippumattoman muuttujan luokkia. Selitämme tämän prosessin jäljempänä edellä esitetyn esimerkin avulla.
Esittely: Selitys: Dummy-muuttujat ovat yksinkertaisesti uusia muuttujia, jotka toimivat ”sijoituspaikkoina” tiettyä koodausjärjestelmää varten. Ne eivät sinänsä sisällä mitään tietoja. Sen sijaan näihin dummy-muuttujiin on lisättävä tietoja/arvoja, jotta ne voivat täyttää tarkoituksensa eli edustaa kategorisen riippumattoman muuttujasi luokkia. On olemassa monia erityyppisiä koodausjärjestelmiä, jotka määräävät dummy-muuttujiin syötettävät arvot, mutta me käytämme hyvin yleistä koodausjärjestelmää, jota kutsutaan dummy-koodaukseksi tai vaihtoehtoisesti indikaattorikoodaukseksi (HUOM, älkää menkö sekaisin, koska dummy-muuttujat ja dummy-koodaus eivät ole sama asia). Dummy-koodaus toimii siten, että kukin dummy-muuttuja käyttää kategorisen riippumattoman muuttujan tiettyä luokkaa lukuun ottamatta referenssiluokkaa, jonka selitämme jäljempänä.
Aloitetaan tarkastelemalla esimerkkimme kategorista riippumatonta muuttujaa, suosikki_urheilu, jolla on kolme luokkaa: ”uinti”, ”pyöräily” ja ”juoksu”. Koska kategorioita on kolme, tarvitaan kaksi dummy-muuttujaa, jotka edustavat kahta kategoriaa, ja vertailukategoria, joka edustaa kolmatta kategoriaa.
Huomautus: Muista yllä olevasta keskustelusta, että moninkertainen regressio edellyttää, että siirrät yhden dummy-muuttujan vähemmän kuin kategorisen riippumattoman muuttujasi kategorioiden määrä (eli esimerkissämme kaksi). Voit kuitenkin luoda dummy-muuttujan kategorisen riippumattoman muuttujan jokaiselle luokalle joustavuuden lisäämiseksi ja moninkertaisten vertailujen tekemisen mahdollistamiseksi. Jäljempänä olevassa keskustelussa korostamme kuitenkin vain sitä, mitä moninkertainen regressio edellyttää; eli luodaan yksi dummy-muuttuja vähemmän kuin kategorisen riippumattoman muuttujasi luokkien lukumäärä, ja kategoria, jota ei suoraan edusteta, tulee ”vertailuluokaksi”.
Esimerkiksi dummy-muuttuja nro 1 edustaa ”uinti”-luokkaa ja dummy-muuttuja nro 2 edustaa ”pyöräily”-luokkaa. Tällöin ei jää yhtään dummy-muuttujaa luokkaa ”juoksu” varten. Tämä ”puuttuva” luokka on vertailuluokka, eikä sitä tarvita. Lisäksi on täysin teidän päätettävissänne, mitä luokkaa haluatte käyttää vertailuluokkana. Olisimme yhtä hyvin voineet valita vertailuluokaksi luokan ”uinti” kuin luokan ”juoksu”. Ainoa syy, miksi emme tehneet niin, on se, että SPSS Statistics käyttää oletusarvoisesti viimeistä luokkaa, jonka olet koodannut kategorisen riippumattoman muuttujasi Variable View -näkymässä referenssiluokaksi (ks. huomautus alla).
Huomautus: Kuten aiemmin selitettiin kohdassa Data Setup (Aineiston asetukset) ja kuten alla näkyy Value Labels (Arvomerkinnät) -valintaikkunassa, kategorisen riippumattoman muuttujamme kolmas ja viimeinen luokka oli ”juoksu” (ts, 3=”running”).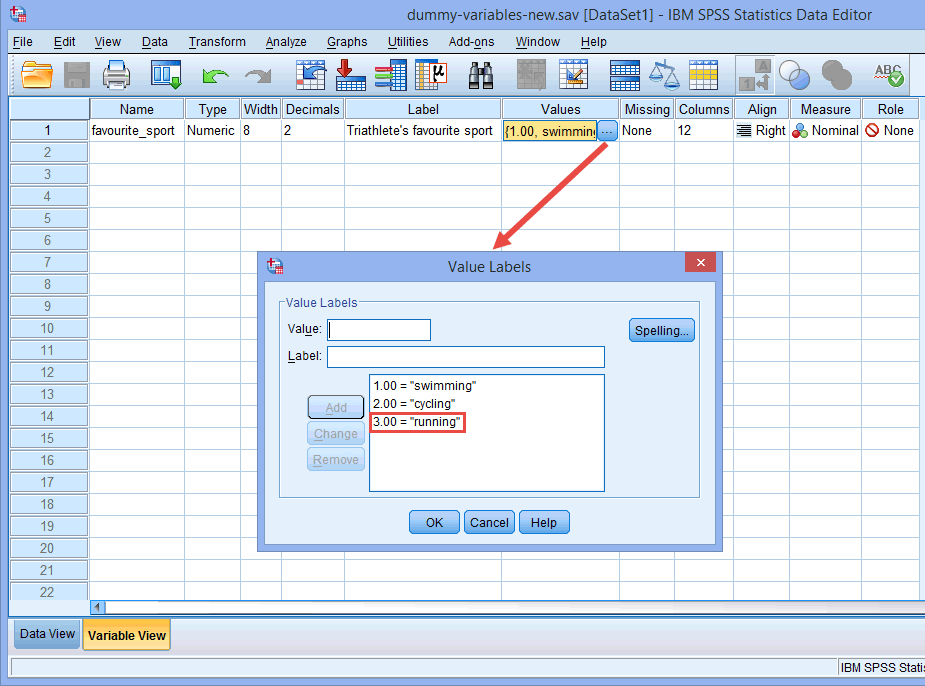
Meille ei ollut mitään teoreettista tai tilastollista syytä tehdä kategoriasta ”running” kolmatta ja viimeistä luokkaa, minkä vuoksi se oli oletusarvoisesti viitekategoria SPSS Statisticsissa. Teimme näin yksinkertaisesti siksi, että kun triathlonistit osallistuvat triathloniin, he ensin uivat, sitten suorittavat pyöräilyn ja lopuksi juoksevat maaliin. Siksi tuntui loogiselta koodata kategorinen riippumaton muuttujamme tällä tavalla. Olisimme kuitenkin voineet koodata sen muotoon 1=pyöräily, 2=juoksu ja 3=uinti; sillä ei olisi ollut mitään merkitystä lukuun ottamatta sitä, että kolmantena ja viimeisenä kategoriana ”uinnista” olisi tullut oletusarvoisesti viitekategoria SPSS Statisticsissa.
Kun luodaan dummy-muuttujia, niille on annettava mielekäs nimi. Koska jokainen dummy-muuttujamme edustaa kategorisen riippumattoman muuttujamme luokkaa, on tapana viitata kuhunkin dummy-muuttujaan sen edustaman luokan nimellä. Siksi olemme kutsuneet valiomuuttujaa nro 1 nimellä ”uinti”, koska se edustaa uintikategoriaa. Vastaavasti olemme kutsuneet dummy-muuttujaa nro 2 ”pyöräilyksi”, koska se edustaa pyöräilyluokkaa. Luomalla nämä kaksi dummy-muuttujaa meillä on kaksi uutta saraketta aineistossamme SPSS Statisticsissa, kuten alla näkyy:
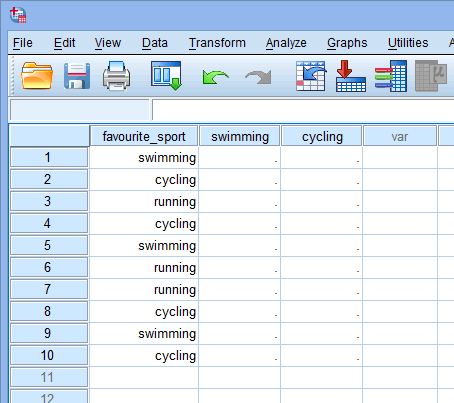
Published with written permission from SPSS Statistics, IBM Corporation.
Nyt kun olemme luoneet kaksi dummy-muuttujaa ja antaneet niille asianmukaiset nimet, meidän on syötettävä arvot näihin muuttujiin niin, että kumpikin dummy-muuttuja tosiaan edustaa omaa luokkaansa kategoriallisesta riippumattomasta muuttujasta. Dummy-koodauksen avulla tämä on hyvin yksinkertaista. Syötät arvon ”1” edustamaan tapausta (esim. aineistossasi olevaa osallistujaa), jolla on kyseinen luokka, ja syötät arvon ”0” (nolla), jos hänellä ei ole kyseistä luokkaa. Tarkastellaan ensin ”uinti” dummy-muuttujaa, kuten alla on esitetty:
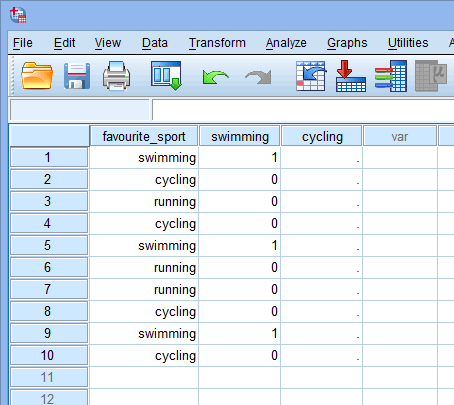
Published with written permission from SPSS Statistics, IBM Corporation.
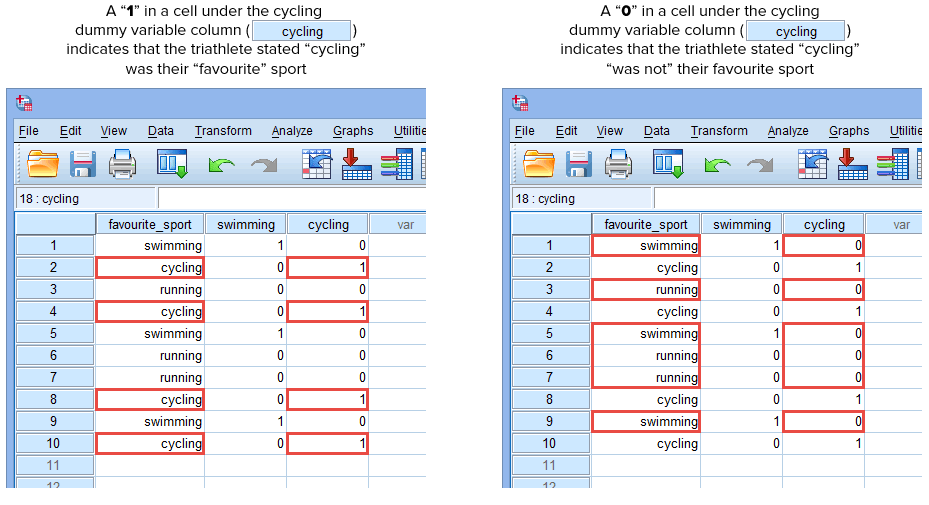
Jos joku triathlonisteista ilmoitti, että ”uinti” oli hänen ”lempilajinsa”, kirjoitamme ”1” soluun uinti-dummy-muuttujan sarakkeen (![]() ) alle, kun kyseessä on se triathlonisti, joka ilmoitti uinnin olevan ”lempilajinsa”. Vaihtoehtoisesti, jos joku triathlonisteista ilmoitti, että ”pyöräily” tai ”juoksu” oli hänen ”lempilajinsa”, kirjoittaisimme ”0” soluun uinnin dummy-muuttujan sarakkeessa (
) alle, kun kyseessä on se triathlonisti, joka ilmoitti uinnin olevan ”lempilajinsa”. Vaihtoehtoisesti, jos joku triathlonisteista ilmoitti, että ”pyöräily” tai ”juoksu” oli hänen ”lempilajinsa”, kirjoittaisimme ”0” soluun uinnin dummy-muuttujan sarakkeessa (![]() ) sille triathlonistille, joka ilmoitti, että uinti ei ollut hänen ”lempilajinsa” (eli tämä tarkoittaa, että joko ”pyöräily” tai ”juoksu” oli kyseisen triathlonistin lempilaji). Tämä on korostettu alla kaikkien 10 triathlonistin osalta:
) sille triathlonistille, joka ilmoitti, että uinti ei ollut hänen ”lempilajinsa” (eli tämä tarkoittaa, että joko ”pyöräily” tai ”juoksu” oli kyseisen triathlonistin lempilaji). Tämä on korostettu alla kaikkien 10 triathlonistin osalta:
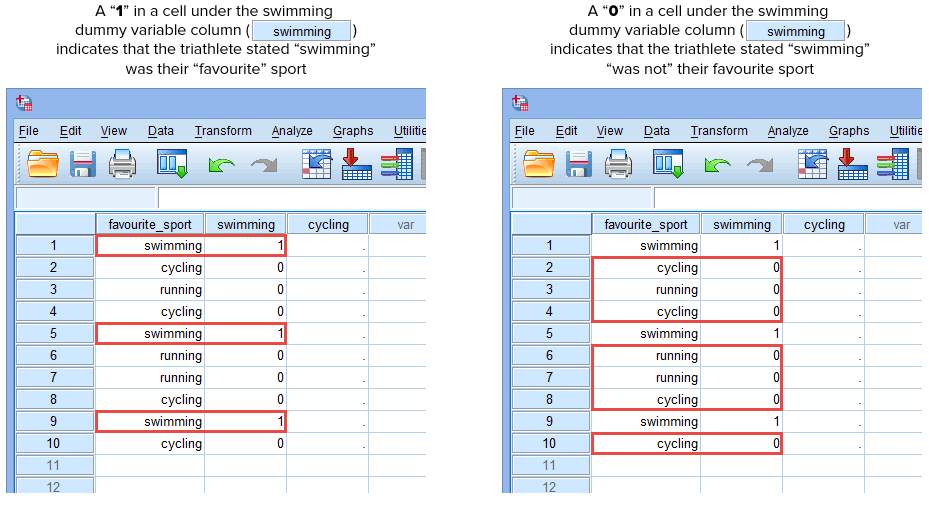
Published with written permission from SPSS Statistics, IBM Corporation.
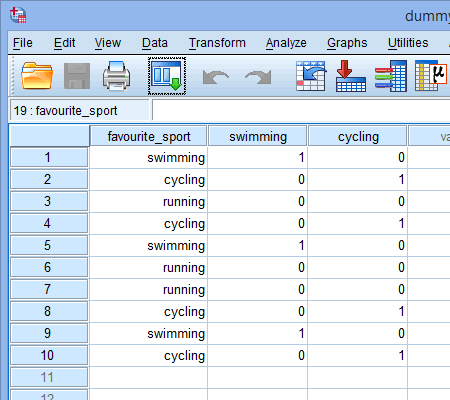
Toistamme tämän prosessin toiselle dummy-muuttujalle, ”pyöräilylle”, kuten alla on esitetty:
Published with written permission from SPSS Statistics, IBM Corporation.
Jos joku triathlonisteista ilmoitti, että ”pyöräily” oli hänen ”lempilajinsa”, kirjoitamme ”1” pyöräilyä koskevan dummy-muuttujan sarakkeen alla olevaan soluun (![]() ) sille triathlonistille, joka ilmoitti pyöräilyn olevan hänen ”lempilajinsa”. Vaihtoehtoisesti, jos joku triathlonisteista ilmoitti, että ”uinti” tai ”juoksu” oli hänen ”lempilajinsa”, merkitsisimme ”0” pyöräilyä koskevan dummy-muuttujan sarakkeen (
) sille triathlonistille, joka ilmoitti pyöräilyn olevan hänen ”lempilajinsa”. Vaihtoehtoisesti, jos joku triathlonisteista ilmoitti, että ”uinti” tai ”juoksu” oli hänen ”lempilajinsa”, merkitsisimme ”0” pyöräilyä koskevan dummy-muuttujan sarakkeen (![]() ) soluun sille triathlonistille, joka ilmoitti, että pyöräily ei ollut hänen ”lempilajinsa” (eli tämä tarkoittaa, että joko ”uinti” tai ”juoksu” oli kyseisen triathlonistin lempilaji). Tämä on korostettu alla kaikkien 10 triathlonistin osalta:
) soluun sille triathlonistille, joka ilmoitti, että pyöräily ei ollut hänen ”lempilajinsa” (eli tämä tarkoittaa, että joko ”uinti” tai ”juoksu” oli kyseisen triathlonistin lempilaji). Tämä on korostettu alla kaikkien 10 triathlonistin osalta:
Julkaistu SPSS Statistics, IBM Corporationin kirjallisella luvalla.
Kirjoittamalla ”1”- ja ”0”-lukuja dummy-muuttujiin tällä tavoin olet luonut joukon dummy-muuttujia, jotka voit syöttää moninkertaiseen regressioanalyysiin. Seuraavassa Proseduurit-osiossa näytämme, miten nämä dummy-muuttujat luodaan Create Dummy Variables -proseduurilla.
SPSS Statistics
Proseduuri SPSS Statisticsissa dummy-muuttujien luomiseksi
SPSS Statisticsissa on kaksi proseduuria dummy-muuttujien luomiseksi: Proseduuri Create Dummy Variables ja Proseduuri Recode into Different Variables. Tässä oppaassa näytämme, miten käytetään Create Dummy Variables -proseduuria, joka on yksinkertainen kolmivaiheinen menettely. Se on kuitenkin käytettävissä vain, jos käytössäsi on SPSS Statisticsin versio 22 tai uudempi, ja versio 26 (ja SPSS Statisticsin tilausversio) on SPSS Statisticsin uusin versio. Jos et ole varma, mitä SPSS Statistics -versiota käytät, katso oppaamme: SPSS Statistics -version tunnistaminen. Jos sinulla on SPSS Statistics -versio 21 tai aikaisempi versio tai olet kiinnostunut moninkertaisten vertailujen tekemisestä suorittaessasi moninkertaista regressioanalyysia, katso alla oleva huomautus:
Huomautus: Jos sinulla on SPSS Statistics -versio 21 tai aikaisempi versio, et voi käyttää Create Dummy Variables -menettelyä. Siksi Recode into Different Variables -proseduuri mahdollistaa ainakin dummy-muuttujien luomisen SPSS Statisticsissa. Vaikka voit myös käyttää Recode into Different Variables -proseduuria dummy-muuttujien luomiseen, jos käytössäsi on SPSS Statisticsin versio 22 tai uudempi, esitämme tässä oppaassa Create Dummy Variables -proseduurin, koska se on tarkoitettu dummy-muuttujien luomiseen ja sitä on paljon helpompi ja nopeampi käyttää. Esimerkiksi tässä oppaassa käytetyn esimerkin dummy-muuttujien luomiseen tarvitaan vain kolme vaihetta verrattuna siihen, että saman esimerkin luomiseen tarvittaisiin 28 vaihetta käyttämällä Recode into Different Variables -menettelyä.
Jos sinulla on siis SPSS Statistics -versio 21 tai sitä aikaisempi versio, Laerd Statistics -osion jäsenten osiossa olevassa laajennetussa oppaassamme dummy-muuttujien luomisesta on sivu, jossa näytetään, miten tämä 28-askeleen pituinen Recode into Different Variables -menettely voidaan suorittaa. Pääset käsiksi tähän laajennettuun oppaaseen tilaamalla Laerd Statisticsin. Vaihtoehtoisesti voit yksinkertaisesti käyttää alla olevaa Create Dummy Variables -menettelyä.
Luo dummy-muuttujat, kun käytössäsi on SPSS Statistics -ohjelman versio 22 tai uudempi, noudattamalla alla olevaa kolmivaiheista Create Dummy Variables -menettelyä:
- Klikkaa Transform > Create Dummy Variables -muodonmuutos -vaihtoehtoa (Transform > Create Dummy Variables -muodonmuutos -vaihtoehto) seuraavassa kuvassa esitetyllä tavalla päävalikossa:

Julkaistu kirjallisella luvalla: SPSS Statistics, IBM Corporation.
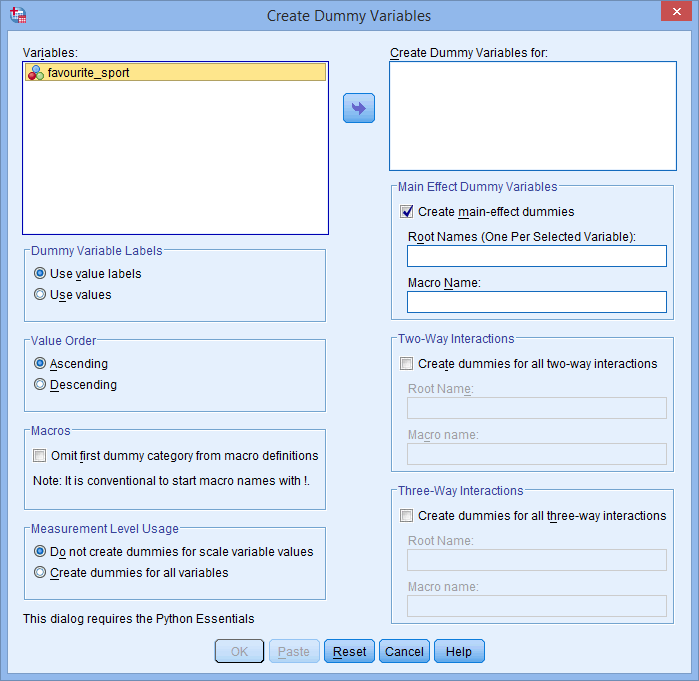
Sinulle avautuu Create Dummy Variables -valintaikkuna alla esitetyllä tavalla:
Published with written permission from SPSS Statistics, IBM Corporation.
- Siirrä kategorinen riippumaton muuttuja favourite_sport Create Dummy Variables for: -valintaikkunaan valitsemalla se (napsauttamalla sitä napsauttamalla sitä) ja napsauttamalla sen jälkeen painiketta
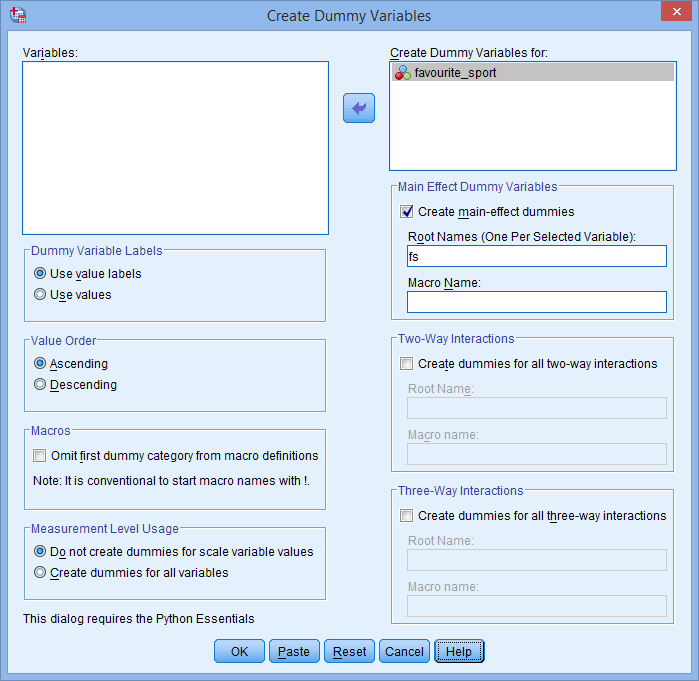
 . Kirjoita myös ”juurinimi”, joka voi edustaa kaikkia uusia dummy-muuttujia Root Names (One Per Selected Variable): (Juurinimet (Yksi per valittu muuttuja):) -ruutuun alueella -Main Effect Dummy Variables-. Syötimme juurinimen ”fs” kategorisen riippumattoman muuttujamme ”favourite_sport” lyhenteeksi, kuten alla näkyy:
. Kirjoita myös ”juurinimi”, joka voi edustaa kaikkia uusia dummy-muuttujia Root Names (One Per Selected Variable): (Juurinimet (Yksi per valittu muuttuja):) -ruutuun alueella -Main Effect Dummy Variables-. Syötimme juurinimen ”fs” kategorisen riippumattoman muuttujamme ”favourite_sport” lyhenteeksi, kuten alla näkyy:
Published with written permission from SPSS Statistics, IBM Corporation.
Huomautus: SPSS Statistics lisää juoksevan numeron (eli 1, 2, 3, 4 jne.) kategorisen riippumattoman muuttujan edustajaksi valitsemasi juurinimen loppuun. Juokseva numero luodaan jokaiselle dummy-muuttujalle, jonka haluat luoda (esim. jos sinulla on kaksi dummy-muuttujaa, juurinimen loppuun lisätään 1 ja 2, mutta jos sinulla on kuusi dummy-muuttujaa, juurinimen loppuun lisätään 1, 2, 3, 4, 5 ja 6). Tämä näkyy esimerkkimme osalta alla olevassa Variable View -ikkunassa:
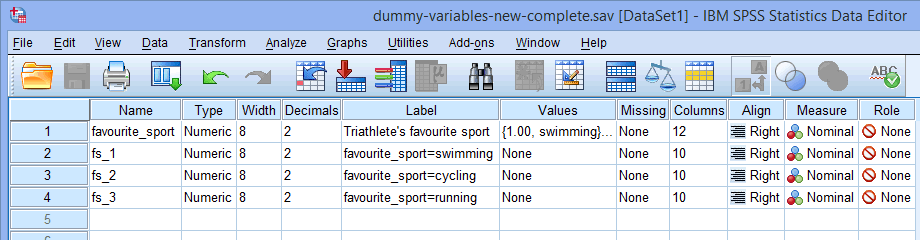
Koska kategorisella riippumattomalla muuttujallamme favourite_sport oli kolme luokkaa (eli uinti, pyöräily ja juoksu), Create Dummy Variables -proseduuri luo kolme dummy-muuttujaa (eli yhden uinnille, yhden pyöräilylle ja yhden juoksulle). Nämä kolme dummy-muuttujaa on korostettu edellä olevassa -sarakkeessa: ”fs_1” (uintia varten), ”fs_2” (pyöräilyä varten) ja ”fs_3” (juoksua varten). Voit nimetä nämä myöhemmin uudelleen niin, että niissä on enemmän järkeä. Korostamme tätä vain siksi, että tiedät, miten yllä oleva Root Names (One Per Selected Variable): -ruutu toimii.
-sarakkeessa: ”fs_1” (uintia varten), ”fs_2” (pyöräilyä varten) ja ”fs_3” (juoksua varten). Voit nimetä nämä myöhemmin uudelleen niin, että niissä on enemmän järkeä. Korostamme tätä vain siksi, että tiedät, miten yllä oleva Root Names (One Per Selected Variable): -ruutu toimii.
Ei myöskään juurinimi, jonka syötät Root Names (One Per Selected Variable): -ruutuun, voi olla sama kuin kategorisen riippumattoman muuttujasi nimi, kuten alla on esitetty (esim, jossa olemme syöttäneet juurinimen ”favorite_sport” havainnollistaaksemme, mitä emme voisi kutsua juurinimeksi):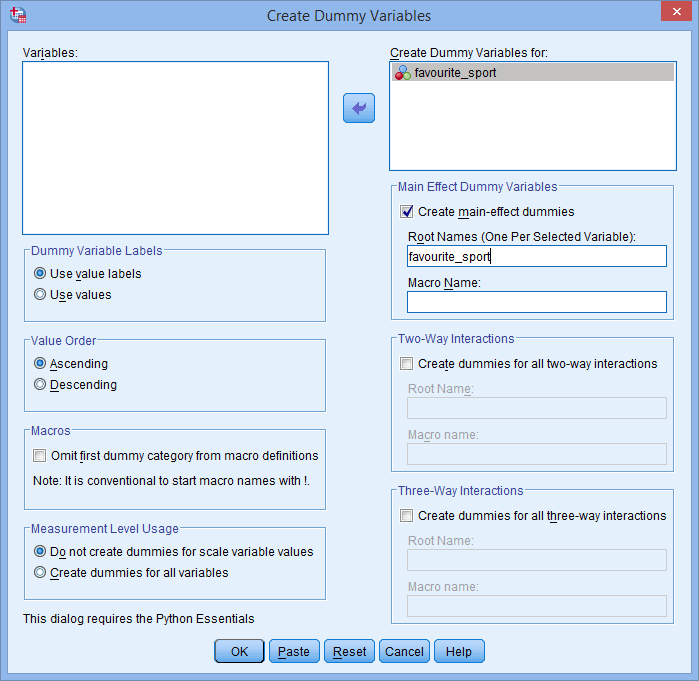
Jos syöttämäsi juurinimi on sama kuin kategorisen riippumattoman muuttujasi nimi, kuten edellä on esitetty, kun napsautat -painiketta, saat seuraavan varoituksen:
-painiketta, saat seuraavan varoituksen:
- Klikkaa -painiketta.
Toteutettuasi edellä esitetyn kolmivaiheisen Create Dummy Variable -menettelyn olet luonut kategoriselle riippumattomalle muuttujallesi dummy-muuttujat. Korosta seuraavassa osiossa tuotos, joka luodaan SPSS Statisticsin Variable Viewer- ja Data Viewer -näkymässä tämän Create Dummy Variables -proseduurin suorittamisen jälkeen.
SPSS Statistics
Output and data setup in SPSS Statistics after creating dummy variables
Luonnettuasi dummy-muuttujasi SPSS Statistics tuottaa seuraavan Variable Creation -taulukon IBM SPSS Statistics Viewer -ohjelmassaan:
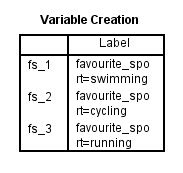
Published with written permission from SPSS Statistics, IBM Corporation.
Muuttujien luonti -taulukko vahvistaa, että olet onnistuneesti luonut dummy-muuttujat. Taulukossa pitäisi olla yhtä monta riviä kuin on uusia dummy-muuttujia. Koska olemme luoneet kolme tyhjää muuttujaa, taulukossa on kolme riviä: ”fs_1”, ”fs_2” ja ”fs_3”, jotka heijastavat edellisessä luvussa esitetyn tyhjien muuttujien luominen -menettelyn vaiheessa 2 syötettyä juurinimeä ja juoksevaa numerointia. Kullekin dummy-muuttujalle annetaan taulukossa merkintä, josta käy selvästi ilmi, mitä kategorisen riippumattoman muuttujan luokkaa kukin dummy-muuttuja edustaa. Esimerkiksi ”fs_1”-muuttujalle annetaan merkintä ”favourite_sport=swimming”, mikä osoittaa, että ”fs_1” on kategorisen riippumattoman muuttujan favourite_sport luokan ”uinti” dummy-muuttuja.
Seuraavaksi siirry SPSS Statisticsin Variable View -ikkunaan napsauttamalla ![]() -välilehteä. Kolme dummy-muuttujaa on lisätty alla esitetyllä tavalla (eli dummy-muuttujat ”fs_1”, ”fs_2” ja ”fs_3” sarakkeessa
-välilehteä. Kolme dummy-muuttujaa on lisätty alla esitetyllä tavalla (eli dummy-muuttujat ”fs_1”, ”fs_2” ja ”fs_3” sarakkeessa ![]() ):
):
Published with written permission from SPSS Statistics, IBM Corporation.
Huomautus: Voit vaihtaa sarakkeessa ![]() olevien dummy-muuttujien nimiä, jos haluat selventää selkeämmin, mitä ne ovat. Olemme esimerkiksi muuttaneet ”fs_1” muotoon ”uinti”, ”fs_2” muotoon ”pyöräily” ja ”fs_3” muotoon ”juoksu”, kuten alla on esitetty:
olevien dummy-muuttujien nimiä, jos haluat selventää selkeämmin, mitä ne ovat. Olemme esimerkiksi muuttaneet ”fs_1” muotoon ”uinti”, ”fs_2” muotoon ”pyöräily” ja ”fs_3” muotoon ”juoksu”, kuten alla on esitetty:
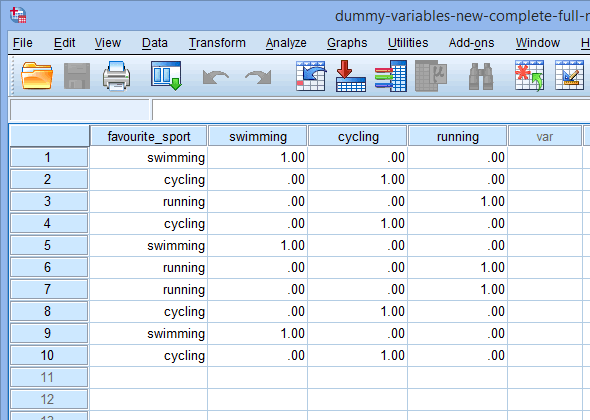
Vaihde lopuksi SPSS Statisticsin Data View -ikkunaan napsauttamalla ![]() -välilehteä. Dummy-koodaus näkyy jokaisen luodun dummy-muuttujan alla. Esimerkiksi sarakkeen ”fs_1” alla olevilla riveillä luokka ”uinti” on koodattu arvolla ”1.00”, kun taas luokat ”pyöräily” ja ”juoksu” on koodattu arvolla ”.00”, kuten alla näkyy. Jos et ole varma, miksi nämä dummy-muuttujat on koodattu tällä tavalla, katso kohta: Understanding dummy variables and dummy coding.
-välilehteä. Dummy-koodaus näkyy jokaisen luodun dummy-muuttujan alla. Esimerkiksi sarakkeen ”fs_1” alla olevilla riveillä luokka ”uinti” on koodattu arvolla ”1.00”, kun taas luokat ”pyöräily” ja ”juoksu” on koodattu arvolla ”.00”, kuten alla näkyy. Jos et ole varma, miksi nämä dummy-muuttujat on koodattu tällä tavalla, katso kohta: Understanding dummy variables and dummy coding.
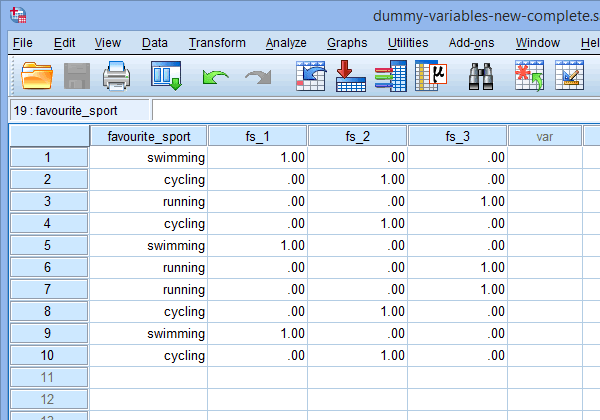
Published with written permission from SPSS Statistics, IBM Corporation.
Huomautus 1: SPSS Statisticsin oletusasetusten vuoksi dummy-muuttujasi koodataan ”1.00” tai ”.00” sen sijaan, että ne olisivat vastaavasti ”1” tai ”0”. Ne ovat identtisiä. Näet kuitenkin usein, että dummy-muuttujien koodaus on kirjoitettu 1:n ja 0:n muodossa sen sijaan, että se sisältäisi desimaaliluvut.
Huomautus 2: Jos olet muuttanut dummy-muuttujien nimiä yllä olevassa Muuttujien näkymä -ikkunan ![]() -sarakkeessa, ne ovat muuttuneet myös Tietojen näkymä -ikkunan sarakkeissa, kuten alla on esitetty (esimerkiksi sarakkeen
-sarakkeessa, ne ovat muuttuneet myös Tietojen näkymä -ikkunan sarakkeissa, kuten alla on esitetty (esimerkiksi sarakkeen ![]() otsikon otsikkona käytetään nyt nimeä
otsikon otsikkona käytetään nyt nimeä ![]() ):
): >
>
Huom.