Overview
- Learn to interpret Bias and Variance in a given model.
- Mitä eroa on Biasin ja Varianssin välillä?
- Miten saavutetaan Biasin ja Varianssin Tradeoff koneoppimisen työnkulun avulla
Esittely
Puhutaan säästä. Sataa vain, jos on hieman kosteaa, eikä sada, jos on tuulista, kuumaa tai pakkasta. Miten tässä tapauksessa kouluttaisit ennustemallin ja varmistaisit, ettei sään ennustamisessa tapahdu virheitä? Voit sanoa, että valittavana on monia oppimisalgoritmeja. Ne eroavat toisistaan monin tavoin, mutta suuri ero on siinä, mitä odotamme ja mitä malli ennustaa. Se on käsite Bias and Variance Tradeoff.
Tavallisesti Bias and Variance Tradeoff opetetaan tiheiden matemaattisten kaavojen avulla. Tässä artikkelissa olen kuitenkin pyrkinyt selittämään Bias ja Variance mahdollisimman yksinkertaisesti!
Keskityn pyöräyttämään sinut läpi prosessin, jossa ymmärrät ongelmanasettelun ja varmistat, että valitset parhaan mallin, jossa Bias- ja Variance-virheet ovat minimaalisia.
Tätä varten olen ottanut käyttööni suositun Pima-intiaaneja koskevan diabeteksen aineiston. Aineisto koostuu Pima-intiaaniperimää edustavien aikuisten naispotilaiden diagnostisista mittauksista. Tässä tietokokonaisuudessa keskitymme ”Outcome”-muuttujaan – joka ilmaisee, onko potilaalla diabetes vai ei. Ilmeisesti kyseessä on binäärinen luokitusongelma, ja aiomme sukeltaa suoraan siihen ja oppia, miten sitä käsitellään.
Jos olet kiinnostunut tästä ja datatieteen käsitteistä ja haluat oppia käytännössä tutustu kurssiimme- Johdatus datatieteeseen
Sisällysluettelo
- Koneellisen oppimismallin arviointi
- Ongelman asettelu ja ensisijaiset askeleet
- Mitä on harha?
- Mitä on varianssi?
- Bias-Variance Tradeoff
Koneoppimismallin arviointi
Koneoppimismallin ensisijainen tavoite on oppia annetusta datasta ja tuottaa ennusteita oppimisprosessin aikana havaittujen mallien perusteella. Tehtävämme ei kuitenkaan pääty tähän. Meidän on jatkuvasti tehtävä parannuksia malleihin sen perusteella, millaisia tuloksia se tuottaa. Määritämme myös mallin suorituskyvyn käyttämällä mittareita, kuten tarkkuus, keskimääräinen neliövirhe (MSE), F1-tulos jne., ja pyrimme parantamaan näitä mittareita. Tämä voi usein olla hankalaa, kun meidän on säilytettävä mallin joustavuus tinkimättä sen oikeellisuudesta.
Valvotun koneoppimisen malli pyrkii kouluttamaan itsensä syötemuuttujilla (X) siten, että ennustetut arvot (Y) ovat mahdollisimman lähellä todellisia arvoja. Tämä todellisten arvojen ja ennustettujen arvojen välinen ero on virhe, ja sitä käytetään mallin arviointiin. Minkä tahansa valvotun koneoppimisalgoritmin virhe koostuu kolmesta osasta:
- Bias-virhe
- Varianssivirhe
- Kohina
Vaikka kohina on redusoimatonta virhettä, jota emme voi eliminoida, kaksi muuta i.eli Bias ja Variance ovat redusoituvia virheitä, joita voimme yrittää minimoida mahdollisimman paljon.
Seuraavissa kappaleissa käsittelemme Bias-virhettä, Variance-virhettä ja Bias-Variance tradeoffia, jotka auttavat meitä parhaan mallin valinnassa. Ja mikä jännittävintä, käsittelemme joitakin tekniikoita näiden virheiden käsittelemiseksi esimerkkitietokannan avulla.
Obgelman asettelu ja ensisijaiset vaiheet
Kuten aiemmin selitettiin, olemme ottaneet käyttöön Pima-intiaanien diabetestietokannan ja muodostaneet siitä luokitusongelman. Aloitetaan mittaamalla tietokokonaisuus ja havainnoimalla, millaisen datan kanssa olemme tekemisissä. Teemme tämän tuomalla tarvittavat kirjastot:
Lataamme nyt datan datakehykseen ja havainnoimme joitakin rivejä saadaksemme tietoa datasta.
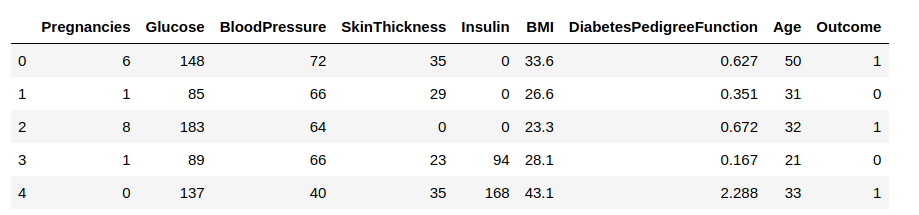
Meidän on ennustettava saraketta ’Outcome’. Erotetaan se ja osoitetaan se kohdemuuttujalle ’y’. Loput datakehikosta on tulomuuttujien joukko X.
Skaalataan nyt ennustemuuttujat ja erotetaan sitten koulutus- ja testausdata.
Koska tulokset luokitellaan binäärimuodossa, käytämme yksinkertaisinta K-nearest neighbor -luokittelijaa(Knn) luokittelemaan, onko potilaalla diabetes vai ei.
Miten päätämme kuitenkin ’k’-arvon?
- Mahdollisesti meidän pitäisi käyttää k = 1, jotta saisimme erittäin hyviä tuloksia harjoitusaineistostamme? Se saattaa toimia, mutta emme voi taata, että malli toimii yhtä hyvin testidatassamme, koska siitä voi tulla liian spesifinen
- Miten olisi, jos käyttäisimme suurta k:n arvoa, vaikkapa k = 100, jotta voimme ottaa huomioon suuren määrän lähimpiä pisteitä, jotta voimme ottaa huomioon myös kaukana olevat pisteet? Tällaisesta mallista tulee kuitenkin liian yleinen, emmekä voi olla varmoja, onko se ottanut kaikki mahdolliset vaikuttavat piirteet oikein huomioon.
Voidaan ottaa muutamia mahdollisia k:n arvoja ja sovittaa malli harjoitusaineistoon kaikille näille arvoille. Lasketaan myös koulutuspisteet ja testauspisteet kaikille näille arvoille.
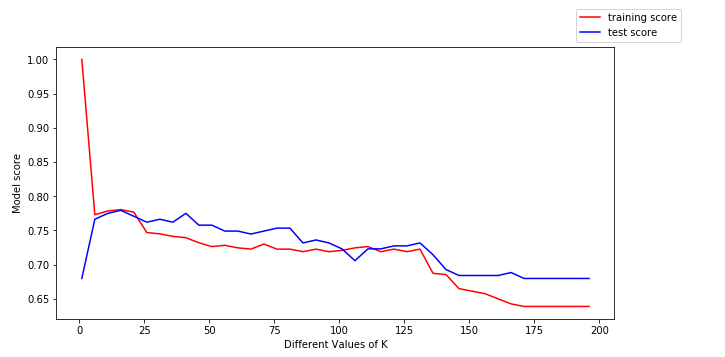
Jotta saamme tästä lisää tietoa, piirretään koulutusdata (punaisella) ja testausdata (sinisellä).
Lasketaan pisteet tietylle k:n arvolle,
![]()
Voidaan tehdä seuraavat johtopäätökset yllä olevasta kuvaajasta:
- Matalilla k:n arvoilla harjoittelun pistemäärä on korkea, kun taas testauksen pistemäärä on matala,
- Kun k:n arvo kasvaa, testauksen pistemäärä alkaa nousta ja harjoittelun pistemäärä laskea.
- Jossain k:n arvossa kuitenkin sekä harjoittelupistemäärä että testauspistemäärä ovat lähellä toisiaan.
Tässä kohtaa harha ja varianssi tulevat kuvaan mukaan.
Mikä on harha?
Yksinkertaisimmillaan harha on ennustetun arvon ja odotusarvon erotus. Tarkemmin selitän, että malli tekee tiettyjä oletuksia, kun se harjoittelee annettujen tietojen perusteella. Kun se otetaan käyttöön testaus-/validointidatassa, nämä oletukset eivät välttämättä aina pidä paikkaansa.
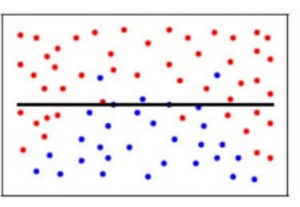
Mallissamme, jos käytämme suurta määrää lähimpiä naapureita, malli voi täysin päättää, että jotkut parametrit eivät ole lainkaan tärkeitä. Se voi esimerkiksi vain katsoa, että Glusoce-taso ja verenpaine ratkaisevat, onko potilaalla diabetes. Tämä malli tekisi hyvin vahvoja oletuksia siitä, että muut parametrit eivät vaikuta lopputulokseen. Voit ajatella sitä myös mallina, joka ennustaa yksinkertaista suhdetta, vaikka datapisteet osoittavat selvästi monimutkaisempaa suhdetta:
Matemaattisesti ajateltuna, olkoon syötemuuttuja X ja kohdemuuttuja Y. Kartoitamme näiden kahden välisen suhteen funktion f avulla.
Siten,
Y = f(X) + e
Tässä ’e’ on normaalisti jakaantunut virhe. Mallimme f'(x) tavoitteena on ennustaa arvoja, jotka ovat mahdollisimman lähellä f(x):tä. Tässä mallin bias on:
Bias = E
Kuten edellä selitin, kun malli tekee yleistyksiä eli kun bias-virhe on suuri, tuloksena on hyvin yksinkertaistettu malli, joka ei huomioi vaihteluita kovin hyvin. Koska se ei opi harjoitusdataa kovin hyvin, sitä kutsutaan alimitoitukseksi.
Mikä on varianssi?
Kontrastina bias-virheeseen varianssi on se, kun malli ottaa huomioon myös datassa olevat vaihtelut eli kohinan. Mitä tapahtuu siis silloin, kun mallillamme on suuri varianssi?
Malli ottaa varianssin silti huomioon asiana, josta voi oppia. Eli malli oppii liikaa harjoitusdatasta, niin paljon, että kun se kohtaa uutta (testaus)dataa, se ei pysty ennustamaan tarkasti sen perusteella.
Matemaattisesti mallin varianssivirhe on:
Varianssi-E^2
Sen vuoksi, että korkean varianssin tapauksessa malli oppii liikaa harjoitusdatasta, sitä kutsutaan ylisovittamiseksi.
Datamme yhteydessä, jos käytämme hyvin vähän lähimpiä naapureita, se on kuin sanoisi, että jos raskauksien määrä on yli 3, glukoositaso on yli 78, diastolinen verenpaine on alle 98, ihon paksuus on alle 23 mm ja niin edelleen jokaisen ominaisuuden kohdalla….. päättää, että potilaalla on diabetes. Kaikki muut potilaat, jotka eivät täytä edellä mainittuja kriteerejä, eivät ole diabeetikkoja. Vaikka tämä voi pitää paikkansa koulutusjoukon yhden tietyn potilaan kohdalla, entä jos nämä parametrit ovat poikkeavia tai ne on jopa kirjattu väärin? On selvää, että tällainen malli voi osoittautua hyvin kalliiksi!
Lisäksi tällä mallilla olisi suuri varianssivirhe, koska ennusteet siitä, onko potilas diabeetikko vai ei, vaihtelevat suuresti sen mukaan, millaista harjoitusdataa annamme sille. Niinpä jopa glukoositason muuttaminen 75:ksi johtaisi siihen, että malli ennustaisi, että potilaalla ei ole diabetesta.
Yksinkertaistaen malli ennustaa hyvin monimutkaisia suhteita lopputuloksen ja syöttöominaisuuksien välillä, kun kvadraattinen yhtälö olisi riittänyt. Tällaiselta luokittelumalli näyttäisi, kun varianssivirhe on suuri / kun on tapahtunut ylisovittamista:
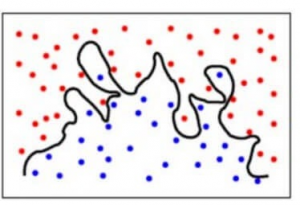
Yhteenvetona,
- Malli, jolla on suuri bias-virhe, alipukeutuu dataan ja tekee siitä hyvin yksinkertaisia oletuksia
- Malli, jolla on suuri varianssivirhe, ylipukeutuu dataan ja oppii siitä liikaa
- Hyvä malli on sellainen, jossa sekä bias- että varianssivirheet ovat tasapainossa
Bias-Variance Tradeoff
Miten suhteutamme edellä mainitut käsitteet aiemmin esiteltyyn Knn-kuvausmalliimme? Otetaan selvää!
Mallissamme, vaikkapa, for, k = 1, tarkastellaan pistettä, joka on lähimpänä kyseistä datapistettä. Tällöin ennuste saattaa olla tarkka kyseisen datapisteen osalta, joten harhavirhe on pienempi.
Mutta varianssivirhe on suuri, koska vain yksi lähin piste otetaan huomioon, eikä tämä ota huomioon muita mahdollisia pisteitä. Mitä skenaariota tämä mielestäsi vastaa? Kyllä, ajattelet oikein, tämä tarkoittaa, että mallimme on ylisovitettu.
Toisaalta suuremmilla k:n arvoilla otetaan huomioon paljon enemmän pisteitä, jotka ovat lähempänä kyseistä datapistettä. Tämä johtaisi suurempaan harhavirheeseen ja alisovittamiseen, koska monet datapistettä lähempänä olevat pisteet otetaan huomioon ja näin se ei voi oppia erityispiirteitä harjoitusjoukosta. Voimme kuitenkin ottaa huomioon pienemmän varianssivirheen testausjoukossa, jossa on tuntemattomia arvoja.
Voidaksemme saavuttaa tasapainon harhavirheen ja varianssivirheen välillä, tarvitsemme sellaisen k:n arvon, että malli ei opi kohinasta (overfit on data) eikä tee laveampia oletuksia datasta (underfit on data). Yksinkertaistaen tasapainoinen malli näyttäisi seuraavalta:
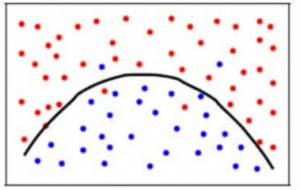
Vaikka jotkin pisteet luokitellaan virheellisesti, malli yleensä sovittaa suurimman osan datapisteistä tarkasti. Bias-virheen ja varianssivirheen välinen tasapaino on Bias-Variance Tradeoff.
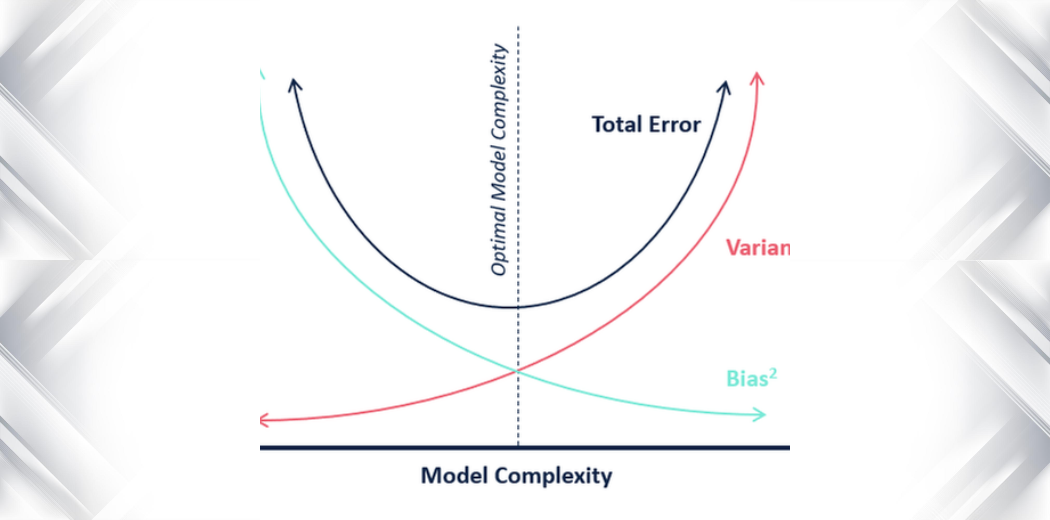
Oheinen häränsilmäkaavio selittää tradeoffin paremmin:
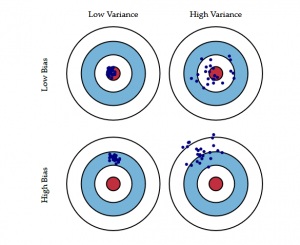
Keskipiste eli häränsilmä on haluamamme mallitulos, joka ennustaa kaikki arvot täydellisesti oikein. Kun siirrymme kauemmas häränsilmästä, mallimme alkaa tehdä yhä enemmän vääriä ennusteita.
Malli, jolla on pieni harha ja suuri varianssi, ennustaa pisteitä, jotka ovat yleensä keskipisteen ympärillä, mutta melko kaukana toisistaan. Malli, jolla on suuri harha ja pieni varianssi, on melko kaukana napakymppisilmästä, mutta koska varianssi on pieni, ennustetut pisteet ovat lähempänä toisiaan.
Mallin monimutkaisuuden suhteen voimme käyttää seuraavaa kaaviota päättäessämme mallimme optimaalisen monimutkaisuuden.
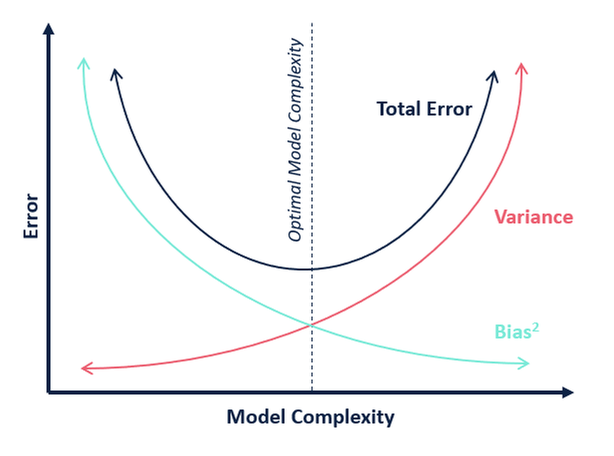
Mikä on mielestäsi k:n optimaalinen arvo?
Yllä olevasta selityksestä voimme päätellä, että k:n optimaalinen arvo on se, jolle
- testauksen pisteet ovat suurimmat ja
- kumpikin testin pisteet ja harjoittelun pisteet ovat lähellä toisiaan
. Vaikka siis tingimme pienemmästä harjoittelupistemäärästä, saamme silti korkean pistemäärän testiaineistolle, mikä on ratkaisevampaa – testiaineisto on loppujen lopuksi tuntematonta dataa.
Tehdäänpä taulukko k:n eri arvoille, jotta voimme todistaa tämän vielä paremmin:
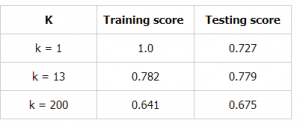
Johtopäätökset
Yhteenvetona voimme todeta, että tässä artikkelissa opimme ideaalisen mallin olevan sellainen, jossa sekä harhavirhe että varianssivirhe ovat pieniä. Meidän tulisi kuitenkin aina pyrkiä malliin, jossa harjoitusaineiston mallipistemäärä on mahdollisimman lähellä testiaineiston mallipistemäärää.
Tässä saimme selville, miten valita malli, joka ei ole liian monimutkainen (korkea varianssi ja matala harha), mikä johtaisi ylisovittamiseen, eikä myöskään liian yksinkertainen (korkea harha ja matala varianssi), mikä johtaisi alisovittamiseen.
Harha- ja harha-arvot (Bias) ja varianssi (Variance) ovat tärkeässä roolissa, kun päätetään, mitä ennustemallia käytetään. Toivottavasti tämä artikkeli selitti käsitteen hyvin.