
Jos haluat oppia lisää Pythonista, osallistu DataCampin maksuttomalle Intro to Python for Data Science -kurssille.
Olette kaikki nähneet datasettejä. Joskus ne ovat pieniä, mutta usein toisinaan ne ovat kooltaan valtavan suuria. Tulee hyvin haastavaksi käsitellä tietokokonaisuuksia, jotka ovat hyvin suuria, ainakin niin merkittäviä, että ne aiheuttavat käsittelyn pullonkaulan.
Miten nämä tietokokonaisuudet ovat näin suuria? No, se johtuu ominaisuuksista. Mitä enemmän piirteitä on, sitä suurempia tietokokonaisuudet ovat. No, ei aina. Löytyy datasettejä, joissa piirteiden määrä on hyvin suuri, mutta ne eivät sisällä niin paljon instansseja. Mutta se ei ole keskustelun aihe tässä. Saatat siis miettiä tavallisella tietokoneella kädessäsi, miten käsitellä tämäntyyppisiä tietokokonaisuuksia hakkaamatta puskista.
Usein korkea-ulotteiseen tietokokonaisuuteen jää joitakin täysin epäolennaisia, merkityksettömiä ja merkityksettömiä piirteitä. On havaittu, että tämäntyyppisten piirteiden osuus ennustavan mallintamisen kannalta on usein pienempi kuin kriittisten piirteiden. Niiden vaikutus voi olla jopa olematon. Nämä piirteet aiheuttavat useita ongelmia, jotka puolestaan estävät tehokkaan ennakoivan mallintamisen –
- Tarpeetonta resurssien kohdentamista näihin piirteisiin.
- Nämä piirteet toimivat kohinana, jonka vuoksi koneoppimismalli voi suoriutua hirvittävän huonosti.
- Koneoppimismallin harjoittelu vie enemmän aikaa.
Mikä on siis ratkaisu tähän? Taloudellisin ratkaisu on Feature Selection.
Feature Selection on prosessi, jossa tietystä tietokokonaisuudesta valitaan merkittävimmät piirteet. Monissa tapauksissa Feature Selection voi parantaa myös koneoppimismallin suorituskykyä.
Asoittuu mielenkiintoiselta, eikö?
Olet saanut epävirallisen johdannon Feature Selectioniin ja sen merkitykseen datatieteen ja koneoppimisen maailmassa. Tässä postauksessa käsitellään:
- Esittely ominaisuuksien valintaan ja sen merkityksen ymmärtäminen
- Ero ominaisuuksien valinnan ja dimensionaalisuuden vähentämisen välillä
- Erilaisia ominaisuuksien valintamenetelmiä
- Erilaisia ominaisuuksien valintamenetelmiä scikit-ohjelmalla
- Erilaisen ominaisuuksien valintamenetelmien toteuttaminen….learn
Esittely ominaisuuksien valintaan
Ominaisuuksien valinta tunnetaan myös nimellä Variable selection tai Attribute selection.
Keskeisesti se on prosessi, jossa valitaan tärkeimmät/relevantit. Features of a dataset.
Ominaisuuksien valinnan merkityksen ymmärtäminen
Ominaisuuksien valinnan merkityksen voi parhaiten tunnistaa, kun kyseessä on tietokokonaisuus, joka sisältää valtavan määrän ominaisuuksia. Tällaista tietokokonaisuutta kutsutaan usein korkea-ulotteiseksi tietokokonaisuudeksi. Korkean ulottuvuuden myötä syntyy paljon ongelmia, kuten – tämä korkea ulottuvuus lisää merkittävästi koneoppimismallin harjoitteluaikaa, se voi tehdä mallista hyvin monimutkaisen, mikä puolestaan voi johtaa ylisovittamiseen.
Usein korkea-ulotteisessa piirrejoukossa on useita piirteitä, jotka ovat redundantteja, mikä tarkoittaa sitä, että nämä piirteet eivät ole mitään muuta kuin muiden olennaisten piirteiden laajennuksia. Nämä tarpeettomat piirteet eivät myöskään vaikuta tehokkaasti mallin koulutukseen. On siis selvää, että on tarpeen poimia aineistosta tärkeimmät ja olennaisimmat piirteet, jotta saadaan tehokkain ennustemallinnustulos.
”Muuttujien valinnalla on kolme tavoitetta: ennusteiden ennustustuloksen parantaminen, nopeampien ja kustannustehokkaampien ennusteiden tarjoaminen ja paremman ymmärryksen saaminen taustalla olevasta prosessista, joka on tuottanut aineiston.”
– Johdatus muuttujien ja ominaisuuksien valintaan
Ymmärretään nyt, mitä eroa on dimensioiden pienentämisellä ja ominaisuuksien valinnalla.
Joskus ominaisuuksien valinta sekoitetaan dimensioiden pienentämiseen. Ne ovat kuitenkin erilaisia. Ominaisuuksien valinta on eri asia kuin dimensioiden pienentäminen. Molemmat menetelmät pyrkivät vähentämään aineistossa olevien attribuuttien määrää, mutta dimensioiden pienentämismenetelmä tekee sen luomalla uusia attribuuttikombinaatioita (tunnetaan joskus nimellä ominaisuuksien muunnos), kun taas ominaisuuksien valintamenetelmät sisältävät ja sulkevat pois aineistossa olevia attribuutteja muuttamatta niitä.
Joitakin esimerkkejä dimensioiden pienentämismenetelmistä ovat pääkomponenttianalyysi, singulaariarvojen hajotus, lineaarinen diskriminaatioanalyysi jne.
Sallikaa minun tiivistää ominaisuuksien valinnan merkitys teille:
- Sen avulla koneoppimisalgoritmi voidaan kouluttaa nopeammin.
- Se vähentää mallin monimutkaisuutta ja tekee siitä helpommin tulkittavissa olevan.
- Se parantaa mallin tarkkuutta, jos valitaan oikea osajoukko.
- Se vähentää ylisovittamista.
Seuraavassa osiossa tutkitaan erityyppisiä yleisiä ominaisuuksien valintamenetelmiä – suodatinmenetelmiä, kääremenetelmiä ja upotettuja menetelmiä.
Suodatinmenetelmät
Oheinen kuva kuvaa parhaiten suodattimiin perustuvia ominaisuuksien valintamenetelmiä:

Kuvan lähde: Analytics Vidhya
Suodatinmenetelmä luottaa arvioitavan datan yleiseen ainutlaatuisuuteen ja poimii piirteiden osajoukon, eikä sisällä mitään louhintaalgoritmia. Suodatusmenetelmä käyttää tarkkaa arviointikriteeristöä, joka sisältää etäisyyden, informaation, riippuvuuden ja johdonmukaisuuden. Suodatinmenetelmässä käytetään tärkeysjärjestystekniikan pääkriteerejä ja muuttujien valinnassa käytetään järjestysjärjestysmenetelmää. Syy ranking-menetelmän käyttämiseen on yksinkertaisuus, erinomaisten ja merkityksellisten piirteiden tuottaminen. Ranking-menetelmä suodattaa epäolennaiset piirteet pois ennen luokitusprosessin aloittamista.
Suodatinmenetelmiä käytetään yleensä tietojen esikäsittelyvaiheena. Ominaisuuksien valinta on riippumaton mistä tahansa koneoppimisalgoritmista. Ominaisuudet asetetaan paremmuusjärjestykseen tilastollisten pisteiden perusteella, jotka pyrkivät määrittämään ominaisuuksien korrelaation tulosmuuttujan kanssa. Korrelaatio on vahvasti kontekstisidonnainen termi, ja se vaihtelee työstä toiseen. Voit tutustua seuraavaan taulukkoon, jossa määritellään korrelaatiokertoimet erityyppisille tiedoille (tässä tapauksessa jatkuville ja kategorisille).

Kuvan lähde: Analytics Vidhya
Esimerkkejä joistakin suodatinmenetelmistä ovat esimerkiksi Khiin neliö -testi, informaatiovoitto ja korrelaatiokertoimen pisteet.
Seuraavaksi näet Wrapper-menetelmät.
Wrapper-menetelmät
Kuten suodatinmenetelmät, annan sinulle samanlaisen infograafin, joka auttaa sinua ymmärtämään wrapper-menetelmiä paremmin:
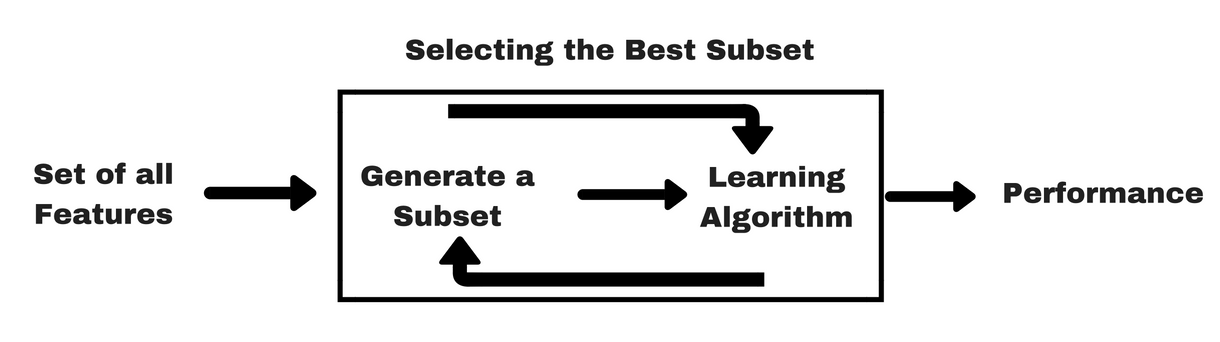
Kuvan lähde: Analytics Vidhya
Kuten yllä olevasta kuvasta näkyy, wrapper-menetelmä tarvitsee yhden koneoppimisalgoritmin ja käyttää sen suorituskykyä arviointikriteerinä. Tämä menetelmä etsii ominaisuuden, joka sopii parhaiten koneoppimisalgoritmille, ja pyrkii parantamaan louhinnan suorituskykyä. Ominaisuuksien arvioimiseksi käytetään luokittelutehtävissä käytettävää ennustetarkkuutta ja klusteroinnin avulla arvioidaan klusterin hyvyyttä.
Tyypillisiä esimerkkejä käärintämenetelmistä ovat mm. eteenpäin suuntautuva ominaisuuksien valinta (forward feature selection), taaksepäin suuntautuva ominaisuuksien eliminointi (backward feature elimination), rekursiivinen ominaisuuksien eliminointi (recursive feature elimination) jne.
- Eteenpäin suuntautuva valinta: Menettely aloitetaan tyhjällä piirrejoukolla . Alkuperäisistä piirteistä määritetään paras ja lisätään supistettuun joukkoon. Jokaisessa seuraavassa iteraatiossa joukkoon lisätään jäljelle jäävistä alkuperäisistä ominaisuuksista paras.
- Taaksepäin eliminointi: Menettely aloitetaan täydestä attribuuttijoukosta. Jokaisessa vaiheessa se poistaa joukosta jäljellä olevan huonoimman attribuutin.
- Eteenpäin valinnan ja taaksepäin eliminoinnin yhdistelmä: Vaiheittainen eteenpäin valinta ja taaksepäin eliminointi voidaan yhdistää siten, että jokaisessa vaiheessa menettely valitsee parhaan attribuutin ja poistaa huonoimman jäljellä olevista attribuuteista.
- Rekursiivinen ominaisuuksien eliminointi: Rekursiivinen ominaisuuksien eliminointi suorittaa ahneen haun löytääkseen parhaiten toimivan ominaisuuksien osajoukon. Se luo iteratiivisesti malleja ja määrittää parhaan tai huonoimman suorituskyvyn omaavan ominaisuuden kussakin iteraatiossa. Se rakentaa seuraavat mallit jäljellä olevilla ominaisuuksilla, kunnes kaikki ominaisuudet on tutkittu. Sen jälkeen se asettaa piirteet paremmuusjärjestykseen niiden poistamisjärjestyksen perusteella. Pahimmassa tapauksessa, jos tietokokonaisuus sisältää N-määrän piirteitä, RFE tekee ahneen haun 2N piirreyhdistelmälle.
Hyvä riittää!
Katsotaan nyt sulautettuja metodeja.
Sulautetut metodit
Sulautetut metodit ovat iteratiivisia siten, että se huolehtii mallin kouluttamisprosessin jokaisesta iteraatioprosessin jaksosta, ja se poimii huolella ne piirteet, jotka edistävät eniten koulutusta tietyllä toistolla. Säännöstelymenetelmät ovat yleisimmin käytettyjä upotettuja menetelmiä, jotka rankaisevat ominaisuutta, jolle on annettu kertoimen kynnysarvo.
Säännöstelymenetelmiä kutsutaan siksi myös rangaistusmenetelmiksi, jotka tuovat ennakoivan algoritmin (kuten regressioalgoritmin) optimointiin lisärajoituksia, jotka vinouttavat mallia kohti pienempää monimutkaisuutta (vähemmän kertoimia).
Esimerkkejä regularisointialgoritmeista ovat LASSO, Elastic Net, Ridge Regression jne.
Suodatin- ja käärintämenetelmien ero
No, suodatinmenetelmien ja käärintämenetelmien erottaminen toisistaan niiden toiminnallisuuksien suhteen saattaa joskus hämmentää. Katsotaanpa, missä kohdin ne eroavat toisistaan.
- Suodatinmenetelmissä ei käytetä koneoppimismallia sen määrittämiseksi, onko ominaisuus hyvä vai huono, kun taas wrapper-menetelmissä käytetään koneoppimismallia ja koulutetaan se ominaisuuteen päättääkseen, onko se olennainen vai ei.
- Suodatinmenetelmät ovat paljon nopeampia verrattuna wrapper-menetelmiin, koska niissä ei tarvitse kouluttaa malleja. Toisaalta wrapper-menetelmät ovat laskennallisesti kalliita, ja massiivisten tietokokonaisuuksien tapauksessa wrapper-menetelmät eivät ole tehokkain harkittava ominaisuuksien valintamenetelmä.
- Suodatinmenetelmät saattavat epäonnistua parhaan ominaisuuksien osajoukon löytämisessä tilanteissa, joissa ei ole riittävästi dataa ominaisuuksien tilastollisen korrelaation mallintamiseen, mutta wrapper-menetelmät voivat aina tarjota parhaan ominaisuuksien osajoukon niiden tyhjentävän luonteen vuoksi.
- Wrapper-menetelmien piirteiden käyttäminen lopullisessa koneoppimismallissa voi johtaa ylisovittamiseen, koska wrapper-menetelmät jo kouluttavat koneoppimismalleja piirteiden avulla ja se vaikuttaa oppimisen todelliseen tehoon. Mutta suodatinmenetelmistä peräisin olevat piirteet eivät useimmissa tapauksissa johda ylisovittamiseen
Viime aikoina olet tutkinut piirteiden valinnan tärkeyttä, ymmärtänyt sen eron dimensioiden pienentämiseen. Olet myös käsitellyt erityyppisiä ominaisuuksien valintamenetelmiä. Niin pitkälle, niin hyvin!
Katsotaan nyt joitakin ansoja, joihin saatat joutua suorittaessasi ominaisuuksien valintaa:
Tärkeä huomio
Olet ehkä jo ymmärtänyt ominaisuuksien valinnan arvon koneoppimisputkessa ja sen tarjoamat palvelut, jos se on integroitu. On kuitenkin erittäin tärkeää ymmärtää, missä vaiheessa sinun pitäisi integroida ominaisuuksien valinta koneoppimisputkeen.
Yksinkertaisesti sanottuna sinun pitäisi sisällyttää ominaisuuksien valintavaihe ennen kuin syötät datan malliin harjoittelua varten erityisesti silloin, kun käytät tarkkuuden estimointimenetelmiä, kuten ristiinvalidointia. Näin varmistetaan, että ominaisuuksien valinta suoritetaan datan kertaukselle juuri ennen mallin kouluttamista. Mutta jos suoritat piirteiden valinnan ensin datan valmistelemiseksi ja sitten suoritat mallin valinnan ja harjoittelun valituille piirteille, se olisi virhe.
Jos suoritat piirteiden valinnan kaikelle datalle ja sen jälkeen suoritat ristiinvalidoinnin, myös ristiinvalidointimenettelyn jokaisessa kertauksessa olevaa testidataa käytettiin piirteiden valintaan, ja tämä on omiaan vinouttamaan koneoppimismallisi suorituskykyä.
Ei riitä teorioita! Mennään nyt suoraan koodauksen pariin.
Tapaustutkimus Pythonilla
Tässä tapaustutkimuksessa käytetään Pima Indians Diabetes -aineistoa. Tietoaineiston kuvaus löytyy täältä.
Tietoaineisto vastaa luokittelutehtävää, jossa sinun pitää ennustaa, onko henkilöllä diabetes 8 ominaisuuden perusteella.
Tietoaineistossa on yhteensä 768 havaintoa. Ensimmäinen tehtäväsi on ladata tietokokonaisuus, jotta voit jatkaa. Mutta ennen sitä tuodaan tarvittavat riippuvuudet, joita tarvitset. Voit tuoda muut sitä mukaa, kun etenet.
import pandas as pdimport numpy as npNyt kun riippuvuudet on tuotu, ladataan Pima Indians -tietokokonaisuus Dataframe-objektiin Pandas-kirjaston avulla.
data = pd.read_csv("diabetes.csv")Tietokokonaisuus on onnistuneesti ladattu Dataframe-objektin tietoihin. Katsotaan nyt dataa.
data.head()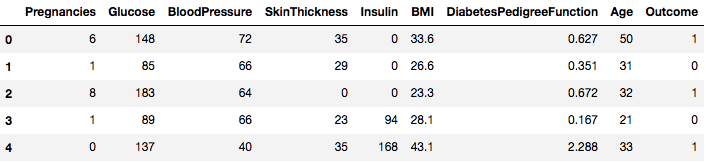
Voidaan siis nähdä 8 erilaista piirrettä, jotka on merkitty tuloksiin 1 ja 0, jossa 1 tarkoittaa, että havainnolla on diabetes, ja 0 tarkoittaa, että havainnolla ei ole diabetesta. Aineistossa tiedetään olevan puuttuvia arvoja. Erityisesti joistakin sarakkeista puuttuu havaintoja, jotka on merkitty nolla-arvoksi. Tämän voi päätellä näiden sarakkeiden määritelmästä, ja on epäkäytännöllistä, että nolla-arvo on virheellinen näille toimenpiteille, esim, nolla painoindeksille tai verenpaineelle on mitätön.
Mutta tässä opetusohjelmassa käytät suoraan esikäsiteltyä versiota datasetistä.
# load dataurl = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"names = dataframe = pd.read_csv(url, names=names)Lastasit nyt datan DataFrame-objektiin nimeltä dataframe.
Muunnetaan DataFrame-objekti NumPy-massamuodoksi nopeamman laskennan saavuttamiseksi. Lisäksi erotetaan data erillisiin muuttujiin, jotta piirteet ja merkinnät erotetaan toisistaan.
array = dataframe.valuesX = arrayY = arrayHienoa! Olet valmistellut datasi.
Aluksi toteutat tilastollisen Khiin neliö -testin ei-negatiivisille piirteille valitaksesi 4 parasta piirrettä aineistosta. Olet jo nähnyt Chi-Squared-testin kuuluvan suodatinmenetelmien luokkaan. Jos joku on utelias tuntemaan Chi-Squaredin sisäiset asiat, tämä video tekee erinomaista työtä.
Scikit-learn-kirjastosta löytyy SelectKBest-luokka, jota voidaan käyttää erilaisten tilastollisten testien kanssa tietyn määrän piirteiden valitsemiseen, tässä tapauksessa Chi-Squaredin.
# Import the necessary libraries firstfrom sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2Itroit kirjastot kokeiden suorittamista varten. Nyt nähdään se toiminnassa.
# Feature extractiontest = SelectKBest(score_func=chi2, k=4)fit = test.fit(X, Y)# Summarize scoresnp.set_printoptions(precision=3)print(fit.scores_)features = fit.transform(X)# Summarize selected featuresprint(features) ]Tulkinta:
Näet kunkin ominaisuuden pisteet ja neljä valittua ominaisuutta (ne, joilla on korkeimmat pisteet): plas, testi, massa ja ikä. Nämä pisteet auttavat sinua edelleen parhaiden ominaisuuksien määrittämisessä mallin harjoittelua varten.
P.S.: Ensimmäinen rivi tarkoittaa ominaisuuksien nimiä. Aineiston esikäsittelyä varten nimet on koodattu numeerisesti.
Seuraavaksi toteutetaan Recursive Feature Elimination, joka on eräänlainen wrapper-ominaisuuksien valintamenetelmä.
Rekursiivinen ominaisuuksien eliminointi eli RFE (Recursive Feature Elimination) toimii poistamalla rekursiivisesti attribuutteja ja rakentamalla malli jäljelle jäävien attribuuttien perusteella.
Se käyttää mallin tarkkuutta tunnistamaan, mitkä attribuutit (ja attribuuttien yhdistelmät) edistävät eniten kohdeattribuutin ennustamista.
Lisätietoa RFE-luokasta saat scikit-learnin dokumentaatiosta.
# Import your necessary dependenciesfrom sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionKäytät RFE:tä Logistic Regression-luokittimen kanssa 3 parhaan ominaisuuden valitsemiseen. Algoritmin valinnalla ei ole suurta merkitystä, kunhan se on taitava ja johdonmukainen.
# Feature extractionmodel = LogisticRegression()rfe = RFE(model, 3)fit = rfe.fit(X, Y)print("Num Features: %s" % (fit.n_features_))print("Selected Features: %s" % (fit.support_))print("Feature Ranking: %s" % (fit.ranking_))Num Features: 3Selected Features: Feature Ranking: Voit nähdä, että RFE valitsi 3 parhaaksi piirteeksi preg, mass ja pedi.
Nämä merkitään True-merkinnällä support-joukkoon ja merkitään valinnalla ”1” ranking-joukkoon. Tämä puolestaan osoittaa näiden piirteiden vahvuuden.
Jatkossa käytetään Ridge-regressiota, joka on pohjimmiltaan regularisointitekniikka ja myös sulautettu piirteiden valintatekniikka.
Tässä artikkelissa annetaan erinomainen selitys Ridge-regressiosta. Muista tutustua siihen.
# First things firstfrom sklearn.linear_model import RidgeJatkossa käytät Ridge-regressiota määrittääksesi kertoimen R2.
Lue myös scikit-learnin virallinen dokumentaatio Ridge-regressiosta.
ridge = Ridge(alpha=1.0)ridge.fit(X,Y)Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None, normalize=False, random_state=None, solver='auto', tol=0.001)Voidaksesi ymmärtää paremmin Ridge-regression tuloksia, toteutat pienen apufunktion, joka auttaa sinua tulostamaan tulokset paremmin niin, että pystyt tulkitsemaan niitä helposti.
# A helper method for pretty-printing the coefficientsdef pretty_print_coefs(coefs, names = None, sort = False): if names == None: names = lst = zip(coefs, names) if sort: lst = sorted(lst, key = lambda x:-np.abs(x)) return " + ".join("%s * %s" % (round(coef, 3), name) for coef, name in lst)Seuraavaksi annat Ridge-mallin kertoimitermejä tälle pienelle funktiolle ja katsot, mitä tapahtuu.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7Voit huomata kaikki kertoimitermeihin liitetyt ominaisuusmuuttujat. Se taas auttaa sinua valitsemaan olennaisimmat piirteet. Alla on joitain seikkoja, jotka kannattaa pitää mielessä Ridge-regressiota sovellettaessa:
- Se tunnetaan myös nimellä L2-regressio.
- Korreloituneille piirteille se tarkoittaa, että niillä on taipumus saada samankaltaisia kertoimia.
- Ominaisuus, jolla on negatiivisia kertoimia, ei edistä niin paljon. Mutta monimutkaisemmassa skenaariossa, jossa olet tekemisissä monien piirteiden kanssa, tämä pistemäärä varmasti auttaa sinua lopullisessa piirteiden valintaa koskevassa päätöksentekoprosessissa.
Noh, tähän päättyy tapaustutkimusosio. Edellä olevassa osiossa toteuttamasi menetelmät auttavat sinua ymmärtämään tietyn tietokokonaisuuden piirteitä kattavasti. Annan sinulle joitakin kriittisiä kohtia näistä tekniikoista:
- Ominaisuuksien valinta on olennaisesti osa datan esikäsittelyä, jota pidetään aikaa vievimpänä osana mitä tahansa koneoppimisputkea.
- Nämä tekniikat auttavat sinua lähestymään sitä systemaattisemmin ja koneoppimisystävällisemmin. Pystyt tulkitsemaan piirteitä tarkemmin.
Pakkaus!
Tässä postauksessa käsiteltiin yhtä hyvin tutkittua ja tutkittua tilastollista aihetta, eli piirteiden valintaa. Tutustuit myös sen eri variantteihin ja käytit niitä nähdessäsi, mitkä piirteet tietokokonaisuudessa ovat tärkeitä.
Voit viedä tätä opetusohjelmaa pidemmälle yhdistämällä korrelaatiomittarin wrapper-menetelmään ja katsomalla, miten se toimii. Toiminnan edetessä saatat päätyä luomaan oman ominaisuuksien valintamekanismin. Näin luot pohjan pienelle tutkimuksellesi. Tutkijat käyttävät myös erilaisia soft computing -periaatteita valinnan suorittamiseen. Tämä on itsessään kokonainen tutkimus- ja tutkimusala. Kannattaa myös kokeilla olemassa olevia piirteidenvalinta-algoritmeja erilaisilla tietokokonaisuuksilla ja tehdä omat johtopäätöksesi.
Miksi nämä perinteiset piirteidenvalintamenetelmät pitävät edelleen paikkansa?
Joo, tämä kysymys on ilmeinen. Koska on olemassa neuroverkkoarkkitehtuureja (esimerkiksi CNN), jotka pystyvät varsin hyvin poimimaan datasta merkittävimmät piirteet, mutta siinäkin on rajoituksensa. CNN:n käyttäminen tavalliseen taulukkomuotoiseen aineistoon, jolla ei ole erityisominaisuuksia (ominaisuuksia, joita tyypillisessä kuvassa on, kuten siirtymäominaisuudet, reunat, sijaintiominaisuudet, ääriviivat jne.), ei ole viisain päätös. Kun dataa ja resursseja on rajoitetusti, CNN:n kouluttaminen tavallisiin taulukkomuotoisiin tietokokonaisuuksiin saattaa lisäksi olla täysin turhaa. Joten tällaisissa tilanteissa opiskelemasi menetelmät tulevat varmasti tarpeeseen.
Seuraavassa on joitakin lähteitä, jos haluat kaivaa lisää tästä aiheesta:
- Feature Selection for Knowledge Discovery and Data Mining
- Subspace, Latent Structure, and Feature Selection: Statistical and Optimization Perspectives Workshop
- Feature Selection: Problem statement and Uses
- Using genetic algorithms for feature selection in Data Analytics
Alhaalla ovat viitteet, joita käytettiin tämän ohjeen kirjoittamisessa.
- Data Mining: Concepts and Techniques; Jiawei Han Micheline Kamber Jian Pei.
- An introduction to feature selection
- Analytics Vidhya article on feature selection
- Hierarkkinen ja sekamalli – DataCamp-kurssi
- Feature Selection For Machine Learning in Python
- Outlier Detection in Stream Data by MachineLearning and Feature Selection Methods
- S. Visalakshi ja V. Radha, ”A literature review of feature selection techniques and applications: Review of feature selection in data mining,” 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, 2014, s. 1-6.