GPI-verankerte Proteine sind der Sonderling unter den Proteinen. In der Einführung in die Zellbiologie hat man uns beigebracht, dass es fünf Arten von Membranproteinen gibt, die wie folgt benannt werden: Typ I, Typ II, Typ III, Typ IV und GPI-verankert. Warum gibt es diese seltsame Klasse von Proteinen, die mit einer Zucker- und Fettkette verbunden sind? Was bewirken sie? Können wir Einblicke in das Protein, das mich interessiert – PrP – gewinnen, wenn wir mehr über diese Klasse von Proteinen, zu der es gehört, erfahren?
Sonia und ich und unser Teamkollege Andrew haben einiges zu diesem Thema gelesen, und ich schreibe diesen Blog-Beitrag, um etwas von dem, was wir gelernt haben, mitzuteilen.
Lesen
Zunächst haben wir ein paar Übersichtsarbeiten gelesen. Diese befassten sich hauptsächlich mit der Struktur und Biogenese des GPI-Ankers selbst, über den erstaunlich viel bekannt ist.
Dieser Anker, dessen vollständiger Name Glycosylphosphatidylinositol lautet, ist kein Monolith: Es handelt sich um eine allgemeine Beschreibung eines Moleküls, dessen Details variieren können. Im Allgemeinen hat man, ausgehend vom ω-Rest (letzter posttranslational vorhandener Rest) des Proteins, ein Ethanolamin, dann ein Phosphat, dann einige Zucker und schließlich ein Phospholipid. Das zentrale Zuckergerüst ist konserviert, aber die davon abzweigenden Seitenketten können variieren, und auch die Phosholipid-Kopfgruppe und die Fettsäuren können variieren. Der GPI-Anker von PrP wurde in charakterisiert, aber selbst dann ist er kein Monolith – es wurden mindestens sechs verschiedene Strukturen identifiziert, die sich in der Zusammensetzung der Zuckerseitenketten unterscheiden.
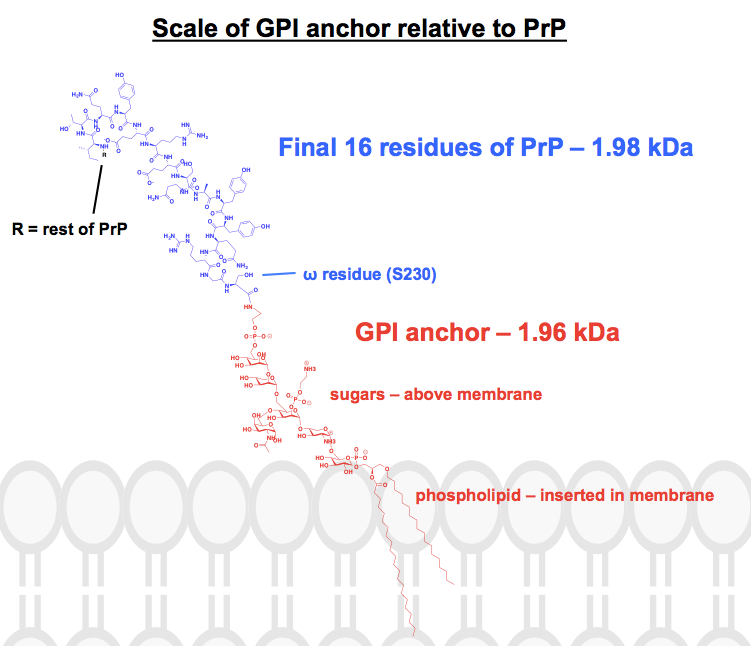
Jede chemische Struktur, die ich von GPI-Ankern gefunden habe, hat zumindest einige Teile abgekürzt oder zusammengefasst, und das Protein ist normalerweise nur als Bild dargestellt. Ich wollte mir ein Bild davon machen, wie diese Anker im Zusammenhang mit den an sie gebundenen Proteinen chemisch aussehen, und habe mich deshalb daran gemacht, eine vollständige Struktur in ChemDraw zu zeichnen. Ausgehend von Abbildung 1 – die einer vollständigen Skelettstruktur am nächsten kommt – fügte ich die Details eines der GPI-Anker von PrP aus dem oberen Feld von Abbildung 6 hinzu. Das Molekulargewicht betrug 1.958 Da, also habe ich zur Veranschaulichung die letzten 16 Reste von HuPrP23-230 eingezeichnet, die ein vergleichbares Gewicht von 1.979 Da haben. Das sind etwa 8 % der posttranslational veränderten Sequenz von PrP. Ich bin mir nicht sicher, ob ich jede Bindung richtig hinbekommen habe, aber hier ist, was ich herausgefunden habe:
In vielen Fällen hat ein Gen mehrere Isoformen, wobei ein Spleißprodukt zu einem GPI-verankerten Protein führt, während andere zu sekretierten oder transmembranen Formen führen. Beispiele hierfür sind NCAM1, das drei Hauptisoformen hat, von denen eine GPI-verankert ist und die anderen beiden transmembranös sind, und ACHE (das für Acetylcholinesterase kodiert), dessen GPI-verankerte Form offenbar nur auf roten Blutkörperchen zu finden ist (NCBI Genes). Die faszinierendste Geschichte ist die des Mausgens Ly6a, das dank eines genetischen Polymorphismus in einigen Mäusestämmen GPI-verankert ist und in anderen nicht. Nur in seiner GPI-verankerten Form fungiert es als Rezeptor für den viralen Vektor AAV PHP.eB . (Dieser Vektor erreicht eine erstaunlich effiziente Aufnahme in Gehirnneuronen für die Gentherapie, aber leider ist es nur ein Mausgen – wir Menschen haben nicht einmal Ly6a).
Es ist viel darüber bekannt, wie GPI-Anker synthetisiert und an Proteine angehängt werden, wobei >20 Proteine an diesem Weg beteiligt sind, von denen die meisten mit dem Präfix „PIG“ beginnen und von Genen wie PIGA, PIGK usw. kodiert werden – siehe Abbildung 2 für ein Diagramm. Der größte Teil der Biosynthese findet statt, wenn der Anker in die Membran im ER eingebaut ist, aber nicht an ein Protein gebunden ist. Tatsächlich finden die ersten Schritte auf dem zytosolischen Blatt der Membran statt, und erst später wechselt der Anker auf die lumenale Seite (innerhalb des ER). Der letzte Schritt besteht darin, dass die GPI-Transamidase, ein Komplex aus mindestens fünf Proteinen, das GPI-Signal vom C-Terminus des Proteins abspaltet und den GPI-Anker an den so genannten ω-Rest des Proteins (den letzten Rest in der posttranslational veränderten Sequenz) bindet. Es findet dann eine weitere Reifung des GPI-Ankers statt, während das Protein aus dem ER in Richtung Zelloberfläche wandert.
Es gibt eine Reihe von niedermolekularen Inhibitoren der GPI-Biosynthese in Pilzen, von denen man versucht hat, einige als Antimykotika zu entwickeln, aber soweit ich sagen kann, ist der einzige bekannte Inhibitor der GPI-Biosynthese in Säugetierzellen Mannosamin, ein Mannose-Analogon, das chemisch nicht mit dem Einbau in GPI kompatibel ist.
Ich habe nach einem Sequenzlogo gesucht, das angibt, welches Aminosäuresequenzmotiv die GPI-Transamidase erkennt, aber keines gefunden. Offensichtlich ist das Sequenzmotiv recht locker, und offenbar sind die GPI-Signale nicht einmal homolog, d.h. sie haben sich nicht aus einer gemeinsamen Vorgängersequenz entwickelt, sondern sind konvergent entstanden, sofern überhaupt eine Konvergenz vorliegt. Die beste Beschreibung, die ich finden konnte, ist, dass man (von N-nach-C-terminal bis zum Ende des Proteins) 1) etwa 11 Reste eines unstrukturierten Linkers, 2) ein paar Reste mit kleinen Seitenketten einschließlich eines ω-Restes, der entweder S, N, D, G, A oder C sein kann, 3) einen Spacer aus 5-10 polaren Aminosäuren und schließlich 4) 15-20 hydrophobe Aminosäuren benötigt. PrP folgt lose diesem Motiv. Nach den veröffentlichten Strukturen endet die Alpha-Helix 3 am Rest Q223, so dass der „unstrukturierte Linker“ nur AYYQR ist (etwas kürzer als die vorgeschriebenen 11 Reste). Der Bereich der „kleinen Seitenkette“ wäre GS|SM (wobei die Pfeife die Transamidase-Schnittstelle bezeichnet), der polare Bereich wäre VLFSSPP und der hydrophobe C-Terminus wäre VILLISFLIFLIVG.
Einige der Proteine im GPI-Biosynthese- und Anheftungsweg sind sehr wichtig, und eine Reihe von schweren Krankheiten und Syndromen des GPI-Anker-Mangels sind beschrieben worden, die auf biallelische Funktionsverluste oder offensichtlich hypomorphe Fehlmutationen in Genen wie PIGO, PIGV, PIGW, PGAP2 und PGAP3 zurückzuführen sind.
Sonia fand eine ausgezeichnete Arbeit von vor ein paar Jahren, in der ein Mutagenese-Screening in haploiden menschlichen Zellen durchgeführt wurde, um Gene zu identifizieren, die für die Biogenese von zwei GPI-verankerten Proteinen erforderlich sind: PrP und CD59. Sie verwendeten eine wiederholte FACS-Sortierung von Zellen auf der Grundlage von PrP und CD59 auf der Zelloberfläche, um Zellen mit drastisch reduzierten Oberflächenspiegeln dieser Proteine zu identifizieren, und führten dann eine Sequenzierung durch, um zu sehen, welche Gen-Knockouts in diesen Zellen im Vergleich zur Mutterpopulation angereichert waren. Wie zu erwarten war, wurden die meisten PIG-Gene für beide Proteine gefunden (Abbildung 4), aber nicht alle Treffer überschnitten sich, was etwas überraschend ist, zumal PrP und CD59 zumindest auf RNA-Ebene zwei der Proteine mit den ähnlichsten Expressionsprofilen in verschiedenen Geweben sind (siehe Heatmap am Ende dieses Beitrags). Eine Reihe von Enzymen, die an der Modifikation der GPI-Anker-Seitenkette beteiligt sind, tauchte nur bei CD59 auf, was darauf hindeutet, dass CD59, nicht aber PrP, diese komplexen Seitenketten benötigt, um zu reifen und die Zelloberfläche zu erreichen. Sec62 und Sec63 wurden dagegen nur für PrP gefunden – es handelt sich um Proteine, die irgendwie an der kotranslationalen Translokation in das ER beteiligt sind, aber offenbar werden sie für PrP benötigt, nicht aber für CD59 oder CD55 oder CD109, zwei andere untersuchte Kontrollproteine. Dies ist ein faszinierendes neues Kapitel bei der Beantwortung meiner Frage „Gibt es etwas Besonderes bei der Expression von PrP?“, bei der ich nach etwas Einzigartigem bei der Biogenese von PrP gesucht habe, das möglicherweise mit einem kleinen Molekül angegriffen werden könnte. Natürlich bedeutet die Tatsache, dass diese Proteine für drei andere Kontrollproteine nicht wichtig waren, nicht, dass sie nicht wichtig sind – in einer Studie wurde festgestellt, dass Sec62 für die Sekretion vieler kleiner Proteine benötigt wird, und das SEC62-Gen ist in der menschlichen Bevölkerung durch Loss-of-Function-Varianten völlig verarmt, was auf Haploinsuffizienz schließen lässt. SEC63 scheint weniger eingeschränkt zu sein, obwohl das nur bedeuten könnte, dass es rezessiv wirkt.
Keine der obigen Ausführungen beantwortet die Frage, warum es GPI-verankerte Proteine gibt. In meinem alten Zellbiologiekurs wurde übrigens ein Detail ausgelassen: Es gibt tatsächlich eine sechste Klasse von Membranproteinen, die so genannten schwanzverankerten (TA) Proteine, die nur einen hydrophoben C-Terminus haben, der in die Membran hineinragt, aber auf der anderen Seite nicht herausragt. Warum konnten nicht alle diese GPI-verankerten Proteine einfach TA-Proteine sein? Warum haben die Zellen einen so komplizierten Weg entwickelt, um stattdessen einen Zucker-Fett-Anker zu synthetisieren, und warum haben sie ihn so früh entwickelt – GPI-Anker sind in allen Eukaryonten vorhanden, auch in vielen einzelligen Krankheitserregern, die den Menschen infizieren.
Die meisten Übersichtsarbeiten haben dieser Frage nicht viel Zeit gewidmet, wahrscheinlich weil sie am schwierigsten zu beantworten ist. Die GPI-verankerten Proteine selbst haben, soweit ihre nativen Funktionen bekannt sind, eine große Bandbreite an Funktionen – es gibt Enzyme (wie AChE), Zelladhäsionsmoleküle (wie NCAM1), Proteine, die das Komplement im Immunsystem regulieren (CD59), und so weiter. Offenbar gibt es mindestens ein GPI-verankertes Protein, das an der Erhaltung des Myelins in den peripheren Nerven beteiligt ist. Aber was genau können GPI-verankerte Proteine tun, was andere Proteine nicht können? In einer Übersichtsarbeit werden einige Ideen genannt, die vorgeschlagen wurden. Eine davon ist, dass GPI-verankerte Proteine gut darin sind, vorübergehend zu dimerisieren. In einigen Studien wurde die Idee untersucht, dass die Homodimerisierung in der Prionenbiologie eine Rolle spielt, obwohl die Relevanz der dort verwendeten Modellsysteme für die Situation in vivo noch nicht klar ist. Eine andere Idee ist, dass GPI-verankerte Proteine von der Zelloberfläche abgelöst werden können, zum Beispiel durch Angiotensin-umwandelndes Enzym (ACE), und dass ihre Lokalisierung auf eine dynamische Weise reguliert werden kann. Auch hier wissen wir, dass PrP abgelöst werden kann, und zwar offenbar durch das Enzym ADAM10 , obwohl eine Rolle bei der nativen Funktion von PrP noch nicht klar ist. Eine dritte Idee, von der ich vielleicht am meisten gehört habe, ist, dass sich GPI-verankerte Proteine selektiv in „Lipid Rafts“ ansammeln. Dies ist vielleicht die verlockendste Erklärung, weil man sich alle möglichen Nebeneffekte vorstellen kann, bei denen die erhöhte effektive lokale Konzentration dieser Proteine mehr Interaktionen ermöglicht, und so weiter. In einer Übersichtsarbeit wurde jedoch darauf hingewiesen, dass Lipid Rafts nach wie vor eher eine abstrakte Idee als etwas Konkretes sind. Während sie funktionell durch die Unlöslichkeit von Detergenzien definiert sind und die meisten Menschen sie als reich an Sphingomyelin und Cholesterin beschreiben, gibt es keine allgemein akzeptierte Definition dessen, was ein Lipid Raft ist und was nicht, und die empirischen Beweise deuten darauf hin, dass sie viel kleiner und flüchtiger sind, als die meisten Menschen denken.
Mit dieser Lektüre in der Hand machte ich mich daran, eine Liste dieser Proteine zu erstellen und sie zu analysieren, um zu sehen, ob ich ein besseres Gefühl für ihre Beschaffenheit bekommen kann.
Analysen
Uniprot hat eine Liste von 173 menschlichen GPI-verankerten Proteinen. Diese wurden auf 140 Gensymbole abgebildet, die nach Ausführung dieses Skripts zur Aktualisierung auf die derzeit von HGNC genehmigten Gensymbole für Proteinkodierung auf 135 sanken. Die endgültige Liste mit 135 Gensymbolen finden Sie hier.
Uniprot bietet keine Informationen darüber, wie ihre Annotationen generiert wurden, obwohl ein erheblicher Anteil an manueller Kuration vorhanden sein muss. Zum Vergleich hat Andrew auch eine Reihe von Arbeiten ausgegraben, in denen PI-PLD oder PI-PLC, zwei Enzyme, die GPI-Anker spalten, verwendet wurden, um GPI-verankerte Proteine empirisch aus Zellen zu isolieren. Die Kombination der Listen aus diesen Veröffentlichungen und die Zuordnung zu den aktuellen Gensymbolen ergaben 107 Gene. Wir überprüften stichprobenartig einige davon. Darunter befanden sich bekannte GPI-verankerte Proteine wie Glypican-1 (GPC1) und das neurale Zelladhäsionsmolekül (NCAM1), von denen berichtet wird, dass sie mit PrP interagieren. Es waren jedoch auch mehrere Gene vorhanden, für die in der Literatur keine GPI-Verankerung bekannt zu sein schien, wie z. B. VDAC3, wobei es sich bei einigen von ihnen einfach um sehr häufig vorkommende Proteine oder um falsch positive Ergebnisse aus anderen Gründen handeln könnte. In der Zwischenzeit gibt es offensichtliche Quellen für falsch negative Ergebnisse: Gene, die in der untersuchten Zelllinie einfach nicht exprimiert wurden oder nicht häufig genug vorkamen, um mit Massenspektrometern erfasst zu werden, und die PrP-Paraloge SPRN und PRND waren nicht in den Listen enthalten. Insgesamt waren 51 Gene in beiden Listen enthalten, eine hochsignifikante Anreicherung (OR = 217, P < 1 × 10-84), was mich darin bestärkt, dass die Annotationen von Uniprot mit den empirischen Daten übereinstimmen. Für weitere Analysen haben wir uns jedoch für die Uniprot-Liste entschieden, da sie empfindlicher und spezifischer zu sein scheint.
Mit dieser Liste wollte ich sehen, wie GPI-verankerte Proteine abschneiden. PrP ist ein einzelnes Exon, kurz (208 Aminosäuren in seiner reifen Form), nicht essentiell und ein weit verbreitetes Protein. Sind diese Merkmale typisch oder untypisch für ein GPI-verankertes Protein?
Es stellte sich heraus, dass GPI-verankerte Proteine in jeder Dimension, die ich untersucht habe, genauso variabel sind wie alle anderen Proteine.
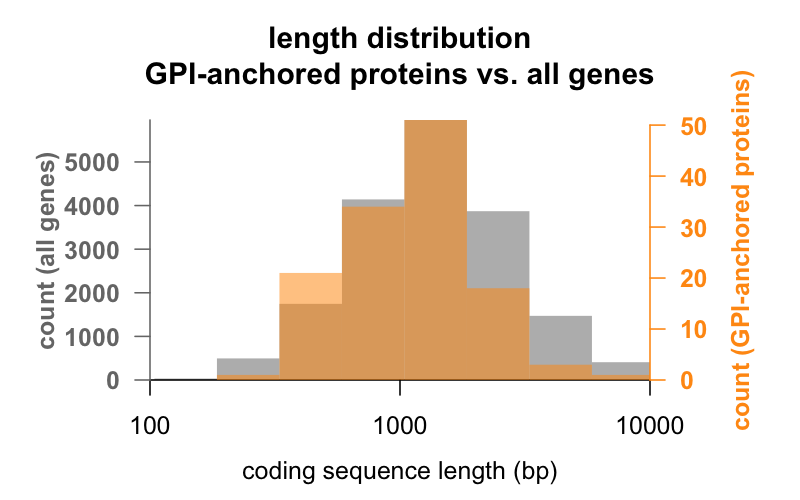
Zunächst die Länge. Unten sind die Histogramme der Länge der kodierenden Sequenz in Basenpaaren für alle Gene und für Gene, die für GPI-verankerte Proteine kodieren, übereinandergelegt. Die Verteilung der GPI-verankerten Proteine ist nur geringfügig nach links verschoben. Das durchschnittliche Gen für GPI-verankerte Proteine hat eine kodierende Sequenzlänge von 1.301 bp, während das durchschnittliche Gen 1.729 bp hat, aber dieser Mittelwertunterschied ist gering im Vergleich zur Variation innerhalb jeder Gruppe. PrP ist mit nur 762 bp kodierender Sequenz definitiv auf der kleinen Seite, obwohl es in keiner der beiden Gruppen ein Ausreißer ist – CD52 ist mit nur 186 Basenpaaren Sequenz und offenbar nur 12 Aminosäuren in seiner reifen Form das kleinste GPI-verankerte Protein.
Wie steht es um die Anzahl der Exons? GPI-verankerte Proteine haben im Vergleich zu allen Genen im Durchschnitt etwas weniger Exons (Mittelwert 7,8 gegenüber 10,1), was mit dem oben erwähnten leichten Unterschied in der Längenverteilung übereinstimmt, aber die meisten sind Multi-Exons. Auch hier ist PrP eher klein: Es gibt nur sechs GPI-verankerte Proteine, die nur ein kodierendes Exon haben, und drei davon sind PrP und seine beiden Paraloge, Sho und Dpl. (Die anderen drei Gene sind GAS1, SPACA4 und das fabelhaft benannte OMG).
Als Nächstes habe ich mir den Funktionsverlust-Zwang angesehen. Constraint ist ein Maß für die Stärke der natürlichen Selektion, der ein Gen unterworfen ist, basierend darauf, wie stark es beispielsweise durch Nonsense-, Frameshift- und Spleißstellenvariationen in der allgemeinen Population dezimiert ist, verglichen mit den Erwartungen, die sich aus den Mutationsraten ergeben. Diese Metrik ist bei kurzen Genen nicht sehr aussagekräftig, sowohl aus statistischen Gründen (die Anzahl der erwarteten Mutationen ist bei kurzen Genen gering, so dass es schwierig ist, die Verarmung zu quantifizieren) als auch aus biologischen Gründen (Gene mit nur einem Exon unterliegen nicht dem Nonsense-vermittelten Zerfall, so dass es schwieriger ist, festzustellen, ob Varianten, die das Protein abschneiden, wirklich „funktionslos“ sind oder nicht). Da aber die meisten GPI-verankerten Proteine nicht so kurz sind wie PrP, hielt ich es für sinnvoll, einen Blick darauf zu werfen. Das Ergebnis: Im Durchschnitt sind GPI-verankerte Proteine nur geringfügig weniger eingeschränkt, d. h. sie weisen mehr der erwarteten Menge an Variationen mit Funktionsverlust auf als das durchschnittliche Gen. Das durchschnittliche Gen hat 47 % seiner Funktionsverlust-Variation, während GPI-verankerte Proteine 56 % aufweisen. Aber wie bei allem gibt es auch hier eine breite Streuung in beiden Lagern. Bei GPI-verankerten Proteinen gibt es am einen Ende die absolut eingeschränkte ACHE (17 erwartete LoFs und keine beobachteten) und am anderen Ende mehrere Gene, die anscheinend überhaupt nicht gegen Funktionsverluste selektiert werden – CNTN6, CD109, TREH und MSLN sind einige Beispiele. PRNP fällt in das letztgenannte Lager, wenn man die Reste ≥145 ausschließt, bei denen Varianten, die das Protein abschneiden, einen Funktionsgewinn bewirken.
Schließlich habe ich mich gefragt, wo GPI-verankerte Proteine exprimiert werden. PRNP ist im Gehirn am häufigsten, wird aber überall exprimiert. Ist das typisch? Ich habe die vollständige GTEx v7 „gene median tpm“-Zusammenfassungsdatei (15. Januar 2016) heruntergeladen, bei der jede Zeile ein Gen und jede Spalte ein Gewebe ist und die Zellen RPKMs sind – RNA-seq reads per kilobase of exon per million mapped reads. Die Arbeit mit diesem Datensatz erforderte einige Feinarbeit. Ich habe gehört, dass einige Bioinformatiker <1 RPKM als „nicht exprimiert“ betrachten, aber die Expressionsmatrix ist spärlich – die meisten Gene werden in den meisten Geweben nicht stark exprimiert -, so dass das Rauschen unter 1 RPKM dominieren kann, wenn man nur die rohen RPKMs aufzeichnet. In der Zwischenzeit muss man die Genexpression auf einer logarithmischen Skala betrachten, da die Gene in einem Gewebe von <1 RPKM bis >10.000 RPKM variieren können. Wenn man also alles auf einer linearen Skala betrachtet, können die wenigen wirklich hoch exprimierten Gen/Gewebe-Kombinationen ebenfalls dominieren, was die Matrix noch spärlicher aussehen lässt, als sie ist. Ich habe daher log10 der Matrix genommen und die Verteilung bei abgeschnitten, so dass die von mir verwendete lila Skala 1 – 10 – 100 – 1.000 – 10.000 RPKM umfasst. Dann habe ich die Uniprot-Proteine mit GPI-Verankerung unterteilt. Um dies zu visualisieren, habe ich zum ersten Mal in meinem Leben eine Heatmap erstellt. Ich habe solche Karten schon oft in Veröffentlichungen gesehen und sie sagen mir normalerweise nichts, aber hier ging es mir nur darum, ein Gefühl für das Muster der Expression zu bekommen, und nachdem ich ein bisschen herumgespielt hatte, gab mir das den besten Einblick. Das Prinzip einer Heatmap besteht darin, dass die Zeilen und Spalten so gruppiert werden, dass ähnliche Dinge zusammengehören. So sind beispielsweise alle Spalten des Hirngewebes nacheinander in einem Feld auf der X-Achse angeordnet, und alle Gene, die in hohem Maße im Gehirn exprimiert werden, sind nacheinander in einem Feld auf der Y-Achse angeordnet, so dass ihr Schnittpunkt ein dichtes violettes Rechteck bildet, das so interpretiert werden kann: „Es gibt eine Gruppe von Genen, die hauptsächlich im Gehirn exprimiert werden“.
Interessierte Leser können sich das PDF der Heatmap in voller Größe ansehen, aber um sie leichter zugänglich zu machen, hier eine handnotierte Version, die die interessanten Cluster nennt:

Die Antwort lautet also nein – die meisten GPI-verankerten Proteine haben nicht das gleiche Expressionsmuster wie PRNP. PRNP ist eines der wenigen Proteine, die besonders stark und breit exprimiert werden, und befindet sich zusammen mit CD59, LY6E, GPC1 und BST2 an der Spitze dieser Heatmap. Die meisten GPI-verankerten Proteine weisen eine geringere oder stärker gewebebeschränkte Expression auf, wobei einige fast ausschließlich im Gehirn exprimiert werden und andere fast ausschließlich nicht im Gehirn, und andere kleinere Cluster gehören hauptsächlich zu bestimmten Geweben wie den Hoden, wie z. B. das PrP-Paralog PRND, dessen Knockout männliche Sterilität verursacht.
Schlussfolgerungen
GPI-verankerte Proteine können so gut wie jede Größe haben, in so gut wie jedem Gewebe exprimiert werden und offensichtlich so gut wie jede Funktion haben, soweit ihre Funktionen bekannt sind. Viele GPI-verankerte Proteine haben sehr klare native Funktionen, aber diese Funktionen sind vielfältig und es ist nicht klar, warum sie eine GPI-Verankerung erfordern, zumal viele dieser Proteine auch in nicht-GPI-verankerten Isoformen existieren. Bei anderen GPI-verankerten Proteinen, einschließlich PrP, wissen wir hingegen nur wenig über die native Funktion, so dass es schwierig ist, auch nur zu spekulieren, warum die native Funktion eine GPI-Verankerung erfordert. Keine der Analysen, die ich durchgeführt habe, und keine der Rezensionen, die ich gelesen habe, waren in der Lage, ein einheitliches Prinzip zu formulieren, warum es diesen Verankerungsmechanismus gibt oder warum diese Proteine ihn benötigen. Es gibt eine Reihe von Hypothesen, warum GPI-verankerte Proteine einzigartig sind, darunter Lipid Rafts, Homodimere und Shedding. Alle diese Hypothesen mögen stichhaltig sein. Letztendlich scheint die Antwort jedoch kein Heureka-Moment zu sein, sondern, wie so vieles in der Biologie, eine prosaische Mischung aus verschiedenen Dingen.
R-Code und Rohdaten für die Analysen in diesem Beitrag finden Sie hier.