Von: Derek Colley | Updated: 2014-01-29 | Comments (5) | Related: Weitere > Funktionen – System
Problem
Sie möchten eine Zufallsstichprobe aus einer SQL Server-Abfrageergebnismenge abrufen. Vielleicht suchen Sie nach einer repräsentativen Stichprobe von Daten aus einer großen Kundendatenbank; vielleicht suchen Sie nach einigen Durchschnittswerten oder nach einer Vorstellung von der Art der Daten, die Sie besitzen. SELECT TOP N ist nicht immer ideal, da Datenausreißer oft am Anfang und am Ende von Datensätzen auftreten, besonders wenn sie alphabetisch oder nach einem skalaren Wert geordnet sind. Ebenso haben Sie vielleicht TABLESAMPLE verwendet, aber das hat seine Grenzen, besonders bei kleinen oder schiefen Datensätzen. Vielleicht hat Ihr Chef Sie um eine Zufallsauswahl von 100 Kundennamen und -orten gebeten; oder Sie nehmen an einer Prüfung teil und müssen eine Zufallsstichprobe von Daten für die Analyse abrufen. Wie würden Sie diese Aufgabe bewältigen? In diesem Tipp erfahren Sie mehr.
Lösung
Dieser Tipp zeigt Ihnen, wie Sie TABLESAMPLE in T-SQL verwenden, um Pseudo-Zufallsstichproben abzurufen, und erläutert die Interna von TABLESAMPLE und wo es nicht geeignet ist. Außerdem wird eine alternative Methode vorgestellt – eine mathematische Methode unter Verwendung von NEWID() in Verbindung mit CHECKSUM und einem bitweisen Operator, die von Microsoft im TABLESAMPLE TechNet-Artikel beschrieben wird. Wir werden ein wenig über statistische Stichproben im Allgemeinen sprechen (die Unterschiede zwischen zufälligen, systematischen und geschichteten Stichproben) und uns ansehen, wie SQL-Statistiken als Beispiel für Stichproben verwendet werden und welche Optionen wir verwenden können, um diese Stichproben außer Kraft zu setzen. Nach der Lektüre dieses Tipps sollten Sie die Vorteile des Samplings gegenüber Methoden wie TOP N kennen und wissen, wie Sie mindestens eine Methode anwenden können, um dies in SQL Server zu erreichen.
Setup
Für diesen Tipp verwende ich einen Datensatz mit einer Identitäts-INT-Spalte (um den Grad der Zufälligkeit bei der Auswahl von Zeilen festzulegen) und anderen Spalten, die mit Pseudozufallsdaten verschiedener Datentypen gefüllt sind, um (vage) echte Daten in einer Tabelle zu simulieren. Sie können den unten stehenden T-SQL-Code verwenden, um dies einzurichten. Die Ausführung sollte nur ein paar Minuten dauern und wurde auf SQL Server 2012 Developer Edition getestet.
Wenn Sie die obersten 10 Datenzeilen auswählen, erhalten Sie dieses Ergebnis (nur um Ihnen einen Eindruck von der Form der Daten zu vermitteln).Nebenbei bemerkt ist dies ein allgemeiner Code, den ich erstellt habe, um Zufallsdaten zu generieren, wann immer ich sie brauchte – Sie können ihn nach Herzenslust erweitern und plündern!
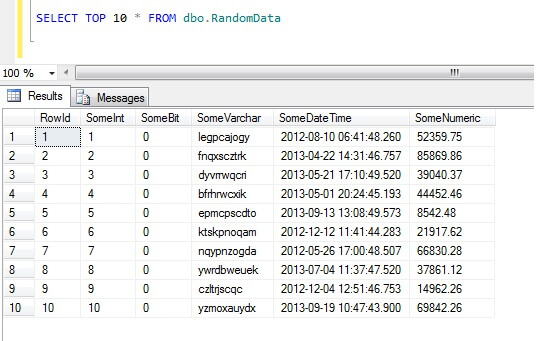
Wie man in SQL Server keine Datenproben nimmt
Nun, da wir unsere Datenproben haben, lassen Sie uns über die schlechtesten Möglichkeiten nachdenken, eine Probe zu erhalten. In der AdventureWorks-Datenbank gibt es eine Tabelle namens Person.Address. Nehmen wir als Beispiel die 10 besten Ergebnisse, in keiner bestimmten Reihenfolge:
SELECT TOP 10 * FROM Person.Address
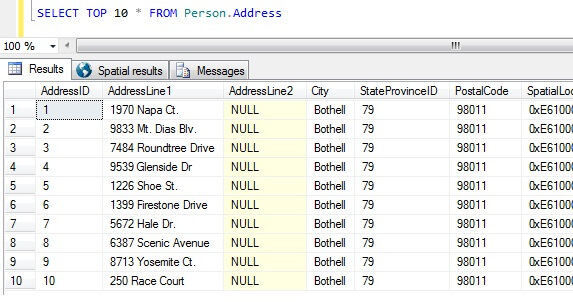
Aus dieser Stichprobe allein können wir erkennen, dass alle zurückgegebenen Personen in Bothell wohnen und die Postleitzahl 98011 haben. Dies liegt daran, dass die Ergebnisse nicht in einer bestimmten Reihenfolge zurückgegeben werden sollten, sondern tatsächlich in der Reihenfolge der Spalte AddressID. Beachten Sie, dass dieses Verhalten insbesondere für Heap-Daten NICHT garantiert ist – siehe dieses Zitat aus BOL:
„Normalerweise werden die Daten zunächst in der Reihenfolge gespeichert, in der die Zeilen in die Tabelle eingefügt werden, aber die Datenbank-Engine kann die Daten im Heap verschieben, um die Zeilen effizient zu speichern; daher kann die Reihenfolge der Daten nicht vorhergesagt werden. Um die Reihenfolge der von einem Heap zurückgegebenen Zeilen zu garantieren, müssen Sie die ORDER BY-Klausel verwenden.“
http://technet.microsoft.com/en-us/library/hh213609.aspx
Anhand dieser Ergebnismenge könnte eine Person, die nicht über die Art der Tabelle informiert ist, zu dem Schluss kommen, dass alle ihre Kunden in Bothell leben.
Typen von Datenstichproben in SQL Server
Das obige ist eindeutig falsch, also brauchen wir eine bessere Art der Stichprobe. Wie wäre es, in regelmäßigen Abständen eine Stichprobe in der Tabelle zu nehmen?
Dies sollte 47 Zeilen ergeben:
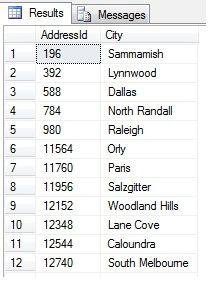
So weit, so gut. Wir haben in regelmäßigen Abständen eine Zeile aus unserem Datensatz entnommen und einen statistischen Querschnitt zurückgegeben – oder doch nicht? Nicht unbedingt. Vergessen Sie nicht, dass die Reihenfolge nicht garantiert ist. Wir könnten ein oder zwei Schlussfolgerungen über diese Daten ziehen. Zur Veranschaulichung wollen wir sie aggregieren. Führen Sie den obigen Codeschnipsel erneut aus, ändern Sie aber den letzten SELECT-Block wie folgt ab:
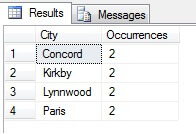
Sie sehen in meinem Beispiel, dass ich aus einer Gesamtzahl von mehr als 19.000 Zeilen in der Tabelle Person.Address eine Stichprobe von etwa 1/4 % der Zeilen gezogen habe, und daher kann ich zu dem Schluss kommen, dass (in meinem Beispiel) Concord, Kirkby, Lynnwood und Paris die meisten Einwohner haben und darüber hinaus gleichmäßig bevölkert sind. Korrekt? Unsinn, natürlich:
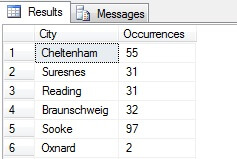
Wie Sie sehen, gehörte keiner meiner vier Orte tatsächlich zu den vier einwohnerstärksten, wie diese Tabelle zeigt. Nicht nur war die Stichprobe zu klein, sondern ich habe diese winzige Stichprobe aggregiert und versucht, daraus eine Schlussfolgerung zu ziehen. Das bedeutet, dass meine Ergebnisse statistisch nicht signifikant sind – der Nachweis der statistischen Signifikanz ist eine der größten Beweislasten bei der Präsentation statistischer Zusammenfassungen (oder sollte es zumindest sein) und ein großer Nachteil vieler beliebter Infografiken und marketinggesteuerter Datendiagramme.
Die Stichprobenziehung auf diese Weise (systematische Stichprobenziehung genannt) ist also effektiv, aber nur für eine statistisch signifikante Population. Es gibt Faktoren wie Periodizität und Proportion, die eine Stichprobe ruinieren können – sehen wir uns die Proportion in Aktion an, indem wir eine Stichprobe von 10 Städten aus der Tabelle „Person.Address“ nehmen, indem wir den folgenden Code verwenden, der eine eindeutige Liste von Städten aus der Tabelle „Person.Address“ abruft und dann 10 Städte aus dieser Liste unter Verwendung einer systematischen Stichprobe auswählt:
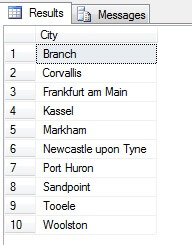
Sieht nach einer guten Stichprobe aus, oder? Vergleichen wir sie nun mit einer Stichprobe von NICHT unterscheidbaren Städten, die in aufsteigender Reihenfolge aufgelistet sind, d. h. jede n-te Stadt, wobei n die Gesamtzahl der Zeilen geteilt durch 10 ist. Dieses Maß berücksichtigt die Grundgesamtheit der Stichprobe:
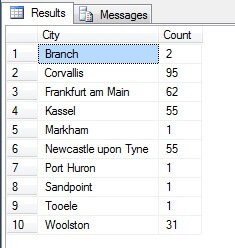
Die zurückgegebenen Daten sind völlig anders – nicht zufällig, sondern weil es sich um eine repräsentative Stichprobe handelt. Beachten Sie, dass diese Liste, in der ich die Zählungen der einzelnen Städte in der Quelltabelle aufgeführt habe, um zu verdeutlichen, wie sehr die Bevölkerung bei der Datenauswahl eine Rolle spielt, die vier bevölkerungsreichsten Städte der Stichprobe enthält, was (wenn man eine geordnete, nicht differenzierte Liste betrachtet) die gerechteste Darstellung ist. Es ist nicht unbedingt die beste Repräsentation für Ihre Bedürfnisse, also seien Sie vorsichtig bei der Wahl Ihrer statistischen Stichprobenmethode.
Andere Stichprobenmethoden
Cluster-Stichproben – hier wird die zu beprobende Grundgesamtheit in Cluster oder Teilmengen unterteilt, dann wird jede dieser Teilmengen nach dem Zufallsprinzip bestimmt, ob sie in die Ergebnismenge aufgenommen wird oder nicht. Wenn sie enthalten sind, wird jedes Mitglied dieser Teilmenge in die Ergebnismenge aufgenommen.
Disproportionale Stichprobenziehung – dies ist wie eine geschichtete Stichprobenziehung, bei der Mitglieder von Untergruppen ausgewählt werden, um die gesamte Gruppe zu repräsentieren, aber anstatt proportional zu sein, kann eine unterschiedliche Anzahl von Mitgliedern aus jeder Gruppe ausgewählt werden, um die Repräsentation aus jeder Gruppe zu gleichen. D.h. angesichts der Städte in Person.Address in dem Beispiel aus dem obigen Abschnitt war die erste Ergebnismenge unverhältnismäßig, da sie die Bevölkerung nicht berücksichtigte, aber die zweite Ergebnismenge war verhältnismäßig, da sie die Anzahl der Städteeinträge in der Tabelle Person.Address repräsentierte. Diese Art der Stichprobenziehung ist in der Tat nützlich, wenn eine bestimmte Kategorie im Datensatz unterrepräsentiert ist und die Proportion nicht wichtig ist (z. B. 100 zufällige Kunden aus 100 zufälligen Städten, die nach Städten geschichtet sind – die Städte in der Teilmenge müssten normalisiert werden – es könnte eine disproportionale Stichprobenziehung verwendet werden).
SQL Server Zufallsdaten mit TABLESAMPLE
SQL Server verfügt über eine hilfreiche Methode zur Stichprobenziehung von Daten. Schauen wir uns das in Aktion an. Verwenden Sie den folgenden Code, um etwa 100 Zeilen (wenn er 0 Zeilen zurückgibt, führen Sie ihn erneut aus – ich erkläre es gleich) von Daten aus dbo.RandomData zurückzugeben, die wir zuvor definiert haben.
SELECT SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
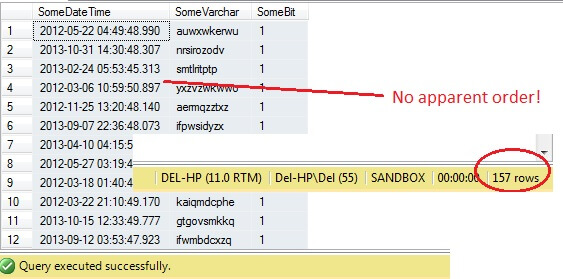
So weit, so gut, oder? Moment mal – wir können die Id-Spalte nicht sehen. Fügen wir dies ein und führen es erneut aus:
SELECT RowId, SomeDateTime, SomeVarchar, SomeBit FROM dbo.RandomData TABLESAMPLE ( 100 ROWS )
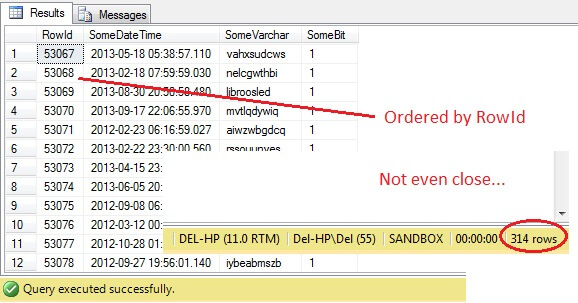
Oh je – TABLESAMPLE hat einen Teil der Daten ausgewählt, aber er ist nicht zufällig – die RowId zeigt einen klar abgegrenzten Teil mit einem Mindest- und einem Höchstwert. Außerdem hat es auch nicht genau 100 Zeilen zurückgegeben. Was ist hier los?
TABLESAMPLE verwendet den impliziten SYSTEM-Modifikator. Dieser Modifikator, der standardmäßig aktiviert ist und eine ANSI-SQL-Spezifikation darstellt, d.h. nicht optional ist, nimmt jede 8KB-Seite, auf der sich die Tabelle befindet, und entscheidet, ob alle Zeilen auf dieser Seite, die sich in dieser Tabelle befinden, in die erzeugte Stichprobe einbezogen werden sollen oder nicht, und zwar auf der Grundlage des Prozentsatzes oder von N ROWS, die eingegeben wurden. Daher sollte eine Tabelle, die sich auf vielen Seiten befindet, d. h. große Datenzeilen hat, eine stärker randomisierte Stichprobe liefern, da mehr Seiten in der Stichprobe enthalten sind. Bei einem Beispiel wie dem unseren, bei dem die Daten skalar und klein sind und sich auf nur wenigen Seiten befinden, schlägt dies fehl – wenn eine beliebige Anzahl von Seiten nicht in die Stichprobe aufgenommen wird, kann dies die ausgegebene Stichprobe erheblich verzerren. Dies ist der Nachteil von TABLESAMPLE – es funktioniert nicht gut bei „kleinen“ Daten und berücksichtigt nicht die Verteilung der Daten auf den Seiten. Die Anordnung der Daten auf den Seiten ist also letztlich für die von dieser Methode zurückgegebene Stichprobe verantwortlich.
Kommt Ihnen das bekannt vor? Es handelt sich im Wesentlichen um ein Cluster-Sampling, bei dem alle Mitglieder (Zeilen) in den ausgewählten Gruppen (Clustern) in der Ergebnismenge vertreten sind.
Lassen Sie uns dies an einer großen Tabelle testen, um den Punkt der umgekehrten Nicht-Skalierbarkeit zu betonen. Lassen Sie uns zunächst die größte Tabelle in der AdventureWorks-Datenbank ermitteln. Dazu verwenden wir einen Standardbericht: Klicken Sie in SSMS mit der rechten Maustaste auf die AdventureWorks2012-Datenbank und gehen Sie zu Berichte -> Standardberichte -> Datenträgernutzung nach Top-Tabellen. Ordnen Sie nach Daten (KB), indem Sie auf die Spaltenüberschrift klicken (für eine absteigende Reihenfolge müssen Sie dies eventuell zweimal tun). Sie sehen dann den folgenden Bericht.
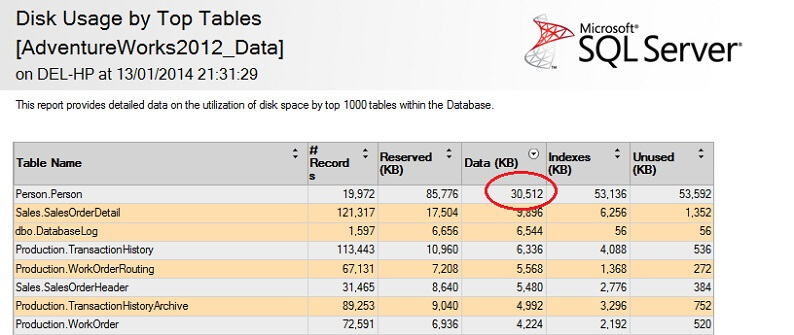
Ich habe die interessante Zahl eingekreist – die Tabelle Person. Person verbraucht 30,5 MB an Daten und ist die größte Tabelle (nach Daten, nicht nach Anzahl der Datensätze). Versuchen wir also, stattdessen eine Stichprobe aus dieser Tabelle zu nehmen:
USE AdventureWorks2012_DataSELECT *FROM Person. Person TABLESAMPLE ( 100 ROWS )
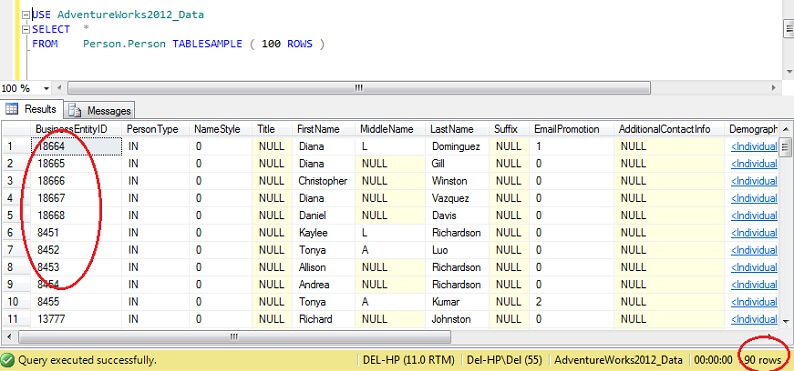
Sie sehen, dass wir viel näher an 100 Zeilen sind, aber entscheidend ist, dass es keine große Clusterbildung beim Primärschlüssel zu geben scheint (obwohl es eine gibt, da es mehr als eine Zeile pro Seite gibt).
Folglich ist TABLESAMPLE gut für große Daten und wird katastrophal schlechter, je kleiner der Datensatz ist. Das ist nicht gut für uns, wenn wir Stichproben aus geschichteten oder geclusterten Daten nehmen, wo wir viele Stichproben aus kleinen Gruppen oder Teilmengen von Daten nehmen und diese dann aggregieren. Schauen wir uns also eine alternative Methode an.
Zufällige SQL Server-Daten mit ORDER BY NEWID()
Hier ist ein Zitat von BOL über das Erhalten einer wirklich zufälligen Stichprobe:
„Wenn Sie wirklich eine zufällige Stichprobe einzelner Zeilen wünschen, ändern Sie Ihre Abfrage, um Zeilen nach dem Zufallsprinzip herauszufiltern, anstatt TABLESAMPLE zu verwenden. Die folgende Abfrage verwendet beispielsweise die Funktion NEWID, um ungefähr ein Prozent der Zeilen der Tabelle Sales.SalesOrderDetail zurückzugeben:
Wie funktioniert das? Lassen Sie uns die WHERE-Klausel aufteilen und erklären.
Die CHECKSUM-Funktion berechnet eine Prüfsumme über die Elemente in der Liste. Man kann sich darüber streiten, ob die SalesOrderID überhaupt erforderlich ist, da NEWID() eine Funktion ist, die eine neue zufällige GUID zurückgibt, so dass die Multiplikation einer Zufallszahl mit einer Konstanten in jedem Fall eine Zufallszahl ergeben sollte.In der Tat scheint das Weglassen der SalesOrderID keinen Unterschied zu machen. Wenn Sie ein eifriger Statistiker sind und die Einbeziehung dieses Parameters begründen können, lassen Sie mich bitte im Kommentarbereich wissen, warum ich falsch liege!
Die CHECKSUM-Funktion gibt einen VARBINÄR zurück. Eine bitweise UND-Verknüpfung mit 0x7fffffff, was (111111111…) im Binärformat entspricht, ergibt einen Dezimalwert, der praktisch eine zufällige Folge von 0en und 1en darstellt. Durch Division durch den Koeffizienten 0x7fffffff wird diese Dezimalzahl auf einen Wert zwischen 0 und 1 normiert. Um dann zu entscheiden, ob jede Zeile in die endgültige Ergebnismenge aufgenommen werden soll, wird ein Schwellenwert von 1/x verwendet (in diesem Fall 0,01), wobei x der Prozentsatz der Daten ist, die als Stichprobe abgerufen werden sollen.
Bitte beachten Sie, dass es sich bei dieser Methode um eine Form der Zufallsstichprobe und nicht um eine systematische Stichprobe handelt, so dass Sie wahrscheinlich Daten aus allen Teilen Ihrer Quelldaten erhalten werden, aber der Schlüssel ist, dass Sie es *möglicherweise* nicht tun. Es liegt in der Natur von Zufallsstichproben, dass jede einzelne Stichprobe, die Sie nehmen, für ein Segment Ihrer Daten voreingenommen sein kann. Um also von der Regression zum Mittelwert (in diesem Fall die Tendenz zu einem zufälligen Ergebnis) zu profitieren, stellen Sie sicher, dass Sie mehrere Stichproben nehmen und aus einer Teilmenge davon auswählen, wenn Ihre Ergebnisse verzerrt aussehen. Alternativ können Sie Stichproben aus Teilmengen Ihrer Daten nehmen und diese dann aggregieren – dies ist eine andere Art der Stichprobenziehung, die als geschichtete Stichprobenziehung bezeichnet wird.
Wie werden SQL Server-Statistiken erfasst?
In SQL Server werden Spalten- oder benutzerdefinierte Statistiken immer dann automatisch aktualisiert, wenn ein festgelegter Schwellenwert von Tabellenzeilen für eine bestimmte Tabelle geändert wird. Für 2012 wird dieser Schwellenwert mit SQRT(1000 * TR) berechnet, wobei TR die Anzahl der Tabellenzeilen in der Tabelle ist. Vor 2005 wurde der Auftrag zur automatischen Aktualisierung der Statistiken bei jeder (500 Zeilen + 20 % Änderung) der Tabellenzeilen ausgelöst. Sobald der automatische Aktualisierungsprozess beginnt, *verringert sich die Anzahl der abgetasteten Zeilen, je größer die Tabelle wird*, d. h. es besteht eine Beziehung, die der umgekehrten Proportion zwischen dem Prozentsatz der Tabellenabtastung und der Größe der Tabelle ähnelt, aber einem proprietären Algorithmus folgt.
Interessanterweise scheint dies das Gegenteil der Option TABLESAMPLE (N PERCENT) zu sein, bei der die Anzahl der abgetasteten Zeilen im normalen Verhältnis zur Anzahl der Zeilen in der Tabelle steht. Wir können die automatischen Statistiken deaktivieren (seien Sie dabei vorsichtig) und die Statistiken manuell aktualisieren – dies wird durch die Verwendung von NORECOMPUTE bei der UPDATE STATISTICS-Anweisung erreicht. Mit UPDATE STATISTICS können wir einige der Optionen außer Kraft setzen – zum Beispiel können wir wählen, ob wir N Zeilen oder N Prozent (ähnlich wie bei TABLESAMPLE) abfragen, einen FULLSCAN durchführen oder einfach RESAMPLE mit der letzten bekannten Rate.
Nächste Schritte
Für weitere Lektüre: Joseph Sack ist ein Microsoft MVP, der für seine Arbeit im Bereich der statistischen Analyse von SQL Server bekannt ist – unten finden Sie einige Links zu seiner Arbeit sowie einige Verweise auf Arbeiten, die für diesen Artikel verwendet wurden, und auf einige verwandte Tipps von MSSQLTips.com. Vielen Dank fürs Lesen!
Letzte Aktualisierung: 2014-01-29


Über den Autor
 Derek Colley ist ein in Großbritannien ansässiger DBA und BI-Entwickler mit mehr als einem Jahrzehnt Erfahrung im Umgang mit SQL Server, Oracle und MySQL.
Derek Colley ist ein in Großbritannien ansässiger DBA und BI-Entwickler mit mehr als einem Jahrzehnt Erfahrung im Umgang mit SQL Server, Oracle und MySQL.Alle meine Tipps ansehen
- Weitere Tipps für Datenbankentwickler…