Es gibt viele große Vorteile, die sich aus der Virtualisierung Ihrer Infrastruktur und dem Betrieb virtueller Ressourcen für geschäftskritische Workloads ergeben. Im Fall von VMware vSphere bietet es viele bemerkenswerte Funktionen und Möglichkeiten, die eine hohe Verfügbarkeit in der Umgebung sowie eine automatisierte Workload-Planung ermöglichen, um die effizienteste Nutzung von Hardware und Ressourcen in Ihrer vSphere-Umgebung sicherzustellen.
In diesem Beitrag werden wir über zwei der wichtigsten Funktionen von vSphere auf Clusterebene im Unternehmen sprechen – vSphere HA und DRS. Wahrscheinlich haben Sie beide schon einmal im Zusammenhang mit dem Betrieb von vSphere im Unternehmen gesehen.
Was sind vSphere HA und DRS? Was bewirken sie?
Welchen Nutzen haben Sie, wenn Sie beide in Ihrer vSphere-Umgebung einsetzen?
Werfen wir einen Blick auf eine grundlegende Einführung in HA und DRS in VMware vSphere und sehen wir, wie sie sich vergleichen und welche Vorteile sie bieten.
VMware vSphere Cluster
Einer der offensichtlichen Vorteile und Best Practices bei der Verwendung von VMware vSphere zur Ausführung geschäftskritischer Workloads ist die Ausführung eines vSphere Clusters.
Was ist ein vSphere-Cluster?
Ein vSphere-Cluster ist eine Konfiguration aus mehreren VMware ESXi-Servern, die in einem Pool von Ressourcen zusammengefasst sind, die zum vSphere-Cluster beitragen. Ressourcen wie CPU-Rechenleistung, Arbeitsspeicher und im Falle von softwaredefiniertem Speicher wie vSAN, Speicher, werden von jedem ESXi-Host bereitgestellt.
Warum ist es wichtig, Ihre geschäftskritischen Workloads auf einem vSphere-Cluster auszuführen?
Die Vorteile eines Hypervisors liegen darin, dass mehr als ein Server auf einer einzigen physischen Hardware ausgeführt werden kann. Die Virtualisierung von Arbeitslasten auf diese Weise bietet viele Effizienzvorteile in Größenordnungen im Vergleich zum Betrieb eines einzelnen Servers auf einem einzigen Satz physischer Hardware.
Dies kann jedoch auch zur Achillesferse einer virtualisierten Lösung werden, da die Auswirkungen eines Hardwareausfalls viele weitere geschäftskritische Dienste und Anwendungen betreffen können. Wenn Sie nur einen einzigen VMware ESXi-Host haben, auf dem viele VMs laufen, können Sie sich vorstellen, dass die Auswirkungen eines Ausfalls dieses einzelnen ESXi-Hosts immens wären.
Das ist der Punkt, an dem der Betrieb mehrerer VMware ESXi-Hosts in einem vSphere-Cluster wirklich glänzt.
Sie werden sich jedoch fragen, wie der einfache Betrieb mehrerer Hosts in einem Cluster Ihre Hochverfügbarkeit verbessert. Wie „weiß“ ein Host im vSphere Cluster, ob ein anderer Host ausgefallen ist? Gibt es einen speziellen Mechanismus zur Verwaltung der Hochverfügbarkeit von Workloads, die auf einem vSphere-Cluster ausgeführt werden? Ja, den gibt es. Sehen wir uns das mal an.
Was ist HA in VMware?
VMware erkannte die Notwendigkeit, einen Mechanismus zu haben, der Schutz vor einem ausgefallenen ESXi-Host im vSphere-Cluster bietet. Mit dieser Notwendigkeit wurde VMware High-Availability (HA) geboren.
VMware vSphere HA bietet folgende Vorteile:
VMware vSphere HA ist kostengünstig und ermöglicht einen automatischen Neustart von VMs und vSphere-Hosts, wenn ein Serverausfall oder ein Betriebssystemfehler in der vSphere-Umgebung festgestellt wird
Überwacht alle VMware vSphere-Hosts &VMs im vSphere-Cluster
Bietet Hochverfügbarkeit für die meisten Anwendungen, die in virtuellen Maschinen ausgeführt werden, unabhängig vom Betriebssystem und den Anwendungen.
Das Schöne an der VMware vSphere HA-Lösung, die über den VMware Cluster implementiert wird, ist die Einfachheit, mit der sie konfiguriert werden kann. Mit ein paar Klicks über eine assistentengesteuerte Oberfläche kann Hochverfügbarkeit konfiguriert werden. Wie verhält sich dies im Vergleich zu herkömmlichen „Clustering“-Technologien?
Vergleich mit Windows Server Failover Clustering
Windows Server Failover Clustering (WSFC) hat sich zu der Clustering-Technologie entwickelt, an die die meisten denken, wenn sie eine Clustering-Technologie im Sinn haben. Das Problem bei WSFC ist, dass es viel Fachwissen erfordert, um WSFC-Dienste korrekt auszuführen, insbesondere wenn es um Upgrades, Patches und allgemeine Betriebsaufgaben geht.
Im Vergleich zu vSphere HA und WSFC ist der betriebliche Aufwand im Vergleich zu WSFC minimal. Es besteht kaum die Möglichkeit, dass HA falsch konfiguriert wird, da es entweder auf einem Cluster aktiviert ist oder nicht. Bei WSFC gibt es viele Überlegungen, die bei der Konfiguration von WSFC angestellt werden müssen, um sowohl Konfigurations- als auch Implementierungsfehler zu vermeiden. Denken Sie an die folgenden Punkte:
- Failover Clustering erfordert Anwendungen, die Clustering unterstützen (SQL usw.)
- Failover Clustering erfordert, dass Quorum korrekt konfiguriert ist
- Nicht von vielen älteren Betriebssystemen und Anwendungen unterstützt
- Erfordert Komplexität von Clusternetzwerknamen, Ressourcen und Netzwerken
Windows Server Failover Clustering wird damit beworben, dass es auf der Anwendungsebene nahezu keine Ausfallzeiten gibt. Wenn man jedoch das Fachwissen hinzurechnet, das für eine ordnungsgemäß funktionierende HA-Lösung zusammen mit der richtigen Implementierung von WSFC erforderlich ist, können die Risiken beginnen, die Vorteile der Verwendung von WSFC für die Hochverfügbarkeit von Anwendungen und Diensten zu überwiegen. Dies gilt insbesondere für die meisten Unternehmen, die nicht unbedingt eine „Null-Ausfallzeit“-Lösung benötigen. Darüber hinaus muss Ihre Anwendung so konzipiert sein, dass sie die Vorteile von WSFC nutzt und ordnungsgemäß mit der WSFC-Technologie funktioniert.
Während vSphere HA bei einem Failover einen Neustart der virtuellen Maschinen auf einem gesunden Host erfordert, muss keine zusätzliche Software in den virtuellen Gastmaschinen installiert werden, es sind keine komplexen Konfigurationen zusätzlicher Clustering-Technologien erforderlich, und Anwendungen oder Betriebssysteme müssen nicht für die Arbeit mit einer bestimmten Clustering-Technologie konzipiert werden.
Legacy-Betriebssysteme und -Anwendungen haben in der Regel nur begrenzte Möglichkeiten, wenn es um unterstützte Technologien zur Bereitstellung von Hochverfügbarkeit geht. Daher gibt es möglicherweise keine nativen Optionen für die Bereitstellung von Failover-Funktionen im Falle von Hardwareausfällen.
Der vSphere HA-Hochverfügbarkeitsmechanismus funktioniert und ist einfach zu implementieren, zu konfigurieren und zu verwalten. Darüber hinaus handelt es sich um eine Technologie, die in Tausenden von VMware-Kundenumgebungen erprobt wurde, so dass sie über eine stabile und lange Geschichte erfolgreicher Implementierungen verfügt.
Allgemeiner Überblick über das Verhalten von vSphere HA
Durch die Nutzung der Vorteile, die den ESXi-Hosts in einem vSphere Cluster zur Verfügung stehen, implementiert vSphere HA in seiner grundlegendsten Form einen Überwachungsmechanismus zwischen den Hosts im vSphere Cluster. Der Überwachungsmechanismus bietet eine Möglichkeit, festzustellen, ob ein Host im vSphere Cluster ausgefallen ist.
In der folgenden Infografik ist bei einem vSphere Cluster mit zwei Knoten ein Ausfall eines der ESXi-Hosts im vSphere Cluster aufgetreten. Der vSphere-Cluster hat vSphere HA auf Clusterebene aktiviert.
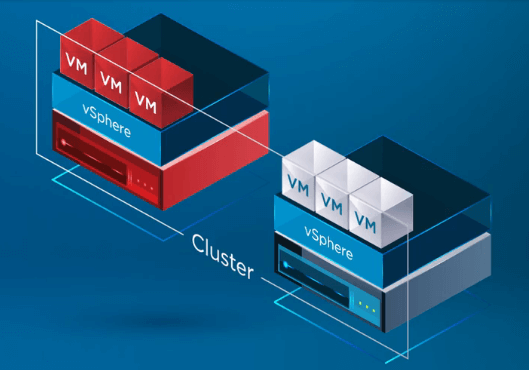
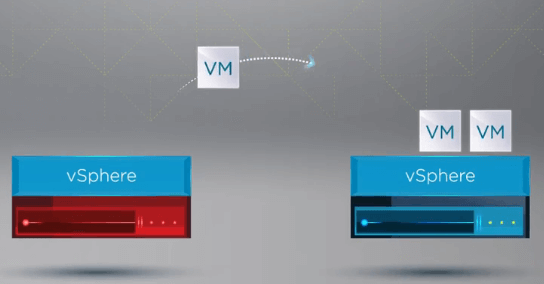
Nachdem vSphere HA erkannt hat, dass ein Host im vSphere Cluster ausgefallen ist, verschiebt der HA-Prozess die Registrierung von VMs vom ausgefallenen Host auf einen gesunden Host.
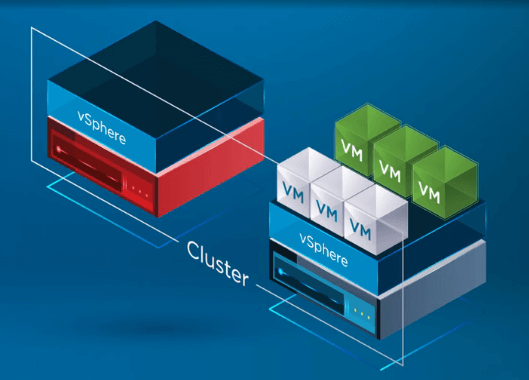
Nachdem die VMs auf einem gesunden Host registriert wurden, startet vSphere HA alle VMs des ausgefallenen Hosts auf einem gesunden ESXi-Host im Cluster neu, auf dem die VMs neu registriert wurden. Die einzige Ausfallzeit entsteht durch den Neustart der VMs auf einem gesunden Host im vSphere-Cluster.
VSphere HA Technischer Überblick
Voraussetzungen für vSphere HA
Sie fragen sich vielleicht, welche Grundvoraussetzungen erforderlich sind, damit vSphere HA funktioniert. Braucht man einfach einen VMware Cluster, um HA zu aktivieren? Im Gegensatz zu Windows Server Failover Clustering gibt es nur wenige Voraussetzungen, die erfüllt sein müssen, damit HA funktioniert.
Voraussetzungen:
- Mindestens zwei ESXi-Hosts
- Mindestens 4 GB Arbeitsspeicher auf jedem Host konfiguriert
- vCenter Server
- vSphere Standardlizenz
- Gemeinsamer Speicher für VMs
- Pingfähiges Gateway oder ein anderer zuverlässiger Netzwerkknoten
Wenn Sie feststellen, Es ist keine Quorum-Komponente erforderlich, keine komplexe Netzwerkbenennung und keine anderen speziellen Cluster-Ressourcen, die vorhanden sein müssen.
Weiterlesen: So konfigurieren Sie einen vSphere High Availability Cluster
VMware vSphere HA Master vs. untergeordnete Hosts
Wenn Sie vSphere HA in einem Cluster aktivieren, wird ein bestimmter Host im vSphere Cluster als Master von vSphere HA bestimmt. Die übrigen ESXi-Hosts im vSphere-Cluster werden in der vSphere HA-Konfiguration als untergeordnete Hosts konfiguriert.
Welche Rolle spielt der vSphere HA ESXi-Host, der als Master bestimmt ist? Der vSphere HA-Masterknoten:
- Überwacht den Status der untergeordneten Slave-Hosts – Wenn der untergeordnete Host ausfällt oder nicht erreichbar ist, identifiziert der Master-Host, welche VMs neu gestartet werden müssen
- Überwacht den Energiestatus aller geschützten VMs. Wenn eine VM ausfällt, sorgt der vSphere HA-Masterknoten dafür, dass die VM neu gestartet wird. Der vSphere HA-Master entscheidet, wo der VM-Neustart stattfindet (welcher ESXi-Host).
- Überwacht alle Cluster-Hosts und VMs, die durch vSphere HA geschützt sind
- Ist als Vermittler zwischen dem vSphere Cluster und vCenter Server bestimmt. Der HA-Master meldet den Cluster-Zustand an vCenter und bietet die Verwaltungsschnittstelle zum Cluster für vCenter Server
- Kann selbst VMs ausführen und den Status von VMs überwachen
- Speichert geschützte VMs in Cluster-Datenspeichern
vSphere HA Untergeordnete Hosts:
- Betreibt virtuelle Maschinen lokal
- Überwacht die Laufzeitzustände der VMs im vSphere-Cluster
- Meldet Zustandsaktualisierungen an den vSphere HA-Master
Master-Host-Wahl und Master-Ausfall
Wie wird der vSphere HA-Master-Host ausgewählt? Wenn vSphere HA für einen Cluster aktiviert ist, nehmen alle aktiven Hosts (kein Wartungsmodus usw.) an der Wahl des Master-Hosts teil. Wenn der gewählte Master-Host ausfällt, findet eine neue Wahl statt, bei der ein neuer Master-HA-Host gewählt wird, der diese Rolle übernimmt.
VMware vSphere HA Cluster-Fehlertypen
In einem vSphere HA-aktivierten Cluster gibt es drei Arten von Fehlern, die ein vSphere HA-Failover-Ereignis auslösen können. Diese Host-Fehlertypen sind:
- Ausfall – Ein Ausfall ist intuitiv das, was Sie denken. Ein Host funktioniert aufgrund von Hardware- oder anderen Problemen nicht mehr.
- Isolierung – Die Isolierung eines Hosts erfolgt im Allgemeinen aufgrund eines Netzwerkereignisses, das einen bestimmten Host von den anderen Hosts im vSphere HA-Cluster isoliert.
- Partitionierung – Ein Partitionsereignis ist dadurch gekennzeichnet, dass ein untergeordneter Host die Netzwerkkonnektivität zum Master-Host des vSphere HA-Clusters verliert.
Heartbeating, Fehlererkennung und Fehleraktionen
Wie stellt der Master-Knoten fest, ob ein bestimmter Host ausgefallen ist?
Es gibt verschiedene Mechanismen, die der Masterknoten verwendet, um festzustellen, ob ein Host ausgefallen ist:
- Der Masterknoten tauscht jede Sekunde Netzwerk-Heartbeats mit den anderen Hosts im Cluster aus.
- Nachdem der Netzwerk-Heartbeat fehlgeschlagen ist, prüft der Master-Host die Host-Lebensfähigkeit.
- Die Host-Lebensfähigkeitsprüfung ermittelt, ob der untergeordnete Host Heartbeats mit einem der Datenspeicher austauscht. Dann sendet er ICMP-Pings an seine Management-IP-Adressen
- Wenn eine direkte Kommunikation mit dem HA-Agenten eines untergeordneten Hosts vom Master-Host aus nicht möglich ist und die ICMP-Pings an die Management-Adresse fehlschlagen, wird der Host als ausgefallen betrachtet und die VMs werden auf einem anderen Host neu gestartet.
- Wenn festgestellt wird, dass der untergeordnete Host Heartbeats mit dem Datenspeicher austauscht, geht der Master-Host davon aus, dass sich der Host in einer Netzwerkpartition befindet oder vom Netzwerk isoliert ist. In diesem Fall überwacht der Master-Host einfach den Host und die VMs
- Die Netzwerkisolierung ist der Fall, in dem ein untergeordneter Host zwar läuft, aber von einem HA-Management-Agenten im Management-Netzwerk nicht mehr gesehen werden kann. Wenn ein Host diesen Datenverkehr nicht mehr sieht, versucht er, die Adressen der Clusterisolierung anzupingen. Wenn dieser Ping fehlschlägt, erklärt der Host, dass er vom Netzwerk isoliert ist
- In diesem Fall überwacht der Master-Knoten die VMs, die auf dem isolierten Host laufen. Wenn die VMs auf dem isolierten Host ausfallen, startet der Masterknoten die VMs auf einem anderen Host neu
Datastore Heartbeating
Wie bereits erwähnt, ist eine der Metriken, die zur Ermittlung der Fehlererkennung verwendet werden, das Datastore Heartbeating. Was ist das genau? VMware vCenter wählt eine bevorzugte Gruppe von Datenspeichern für das Heartbeating aus. Anschließend erstellt vSphere HA ein Verzeichnis im Stammverzeichnis jedes Datenspeichers, das sowohl für das Datastore-Heartbeating als auch für die Aktualisierung der Liste der geschützten VMs verwendet wird. Dieses Verzeichnis trägt den Namen .vSphere-HA.
Es gibt einen wichtigen Hinweis zu vSAN-Datenspeichern. Ein vSAN-Datenspeicher kann nicht für das Datastore Heartbeating verwendet werden. Wenn Sie nur einen vSAN-Datenspeicher zur Verfügung haben, können keine Heartbeat-Datenspeicher verwendet werden.
- VM- und Anwendungsüberwachung
Eine weitere äußerst leistungsstarke Funktion von vSphere HA ist die Möglichkeit, einzelne virtuelle Maschinen über VMware Tools zu überwachen und virtuelle Maschinen neu zu starten, die nicht auf VMware Tools-Heartbeats reagieren. Die Anwendungsüberwachung kann eine VM neu starten, wenn die Heartbeats für eine laufende Anwendung nicht empfangen werden.
- VM-Überwachung – Bei der VM-Überwachung verwendet der VM-Überwachungsdienst VMware Tools, um festzustellen, ob jede VM ausgeführt wird, indem er sowohl auf Heartbeats als auch auf von VMware Tools generierte Festplatten-E/A prüft. Wenn diese Überprüfungen fehlschlagen, stellt der VM-Überwachungsdienst fest, dass höchstwahrscheinlich das Gastbetriebssystem ausgefallen ist, und die VM wird neu gestartet. Die zusätzliche Festplatten-E/A-Prüfung hilft, unnötige VM-Resets zu vermeiden, wenn VMs oder Anwendungen noch ordnungsgemäß funktionieren.
Anwendungsüberwachung – Die Anwendungsüberwachungsfunktion wird aktiviert, indem das entsprechende SDK von einem Drittanbieter bezogen wird, das die Einrichtung von benutzerdefinierten Heartbeats für die Anwendungen ermöglicht, die vom vSphere HA-Prozess überwacht werden sollen. Ähnlich wie beim VM-Überwachungsprozess wird die VM zurückgesetzt, wenn keine Anwendungs-Heartbeats mehr empfangen werden.
Beide Überwachungsfunktionen können mit einer Überwachungsempfindlichkeit und maximalen Rücksetzungen pro VM konfiguriert werden, um ein wiederholtes Zurücksetzen von VMs aufgrund von Software- oder False-Positive-Fehlern zu vermeiden.
VMware vSphere HA ist eine großartige Möglichkeit, um sicherzustellen, dass Ihr vSphere Cluster eine sehr robuste Hochverfügbarkeit bietet, um vor allgemeinen Hostausfällen von ESXi-Hosts in Ihrem vSphere Cluster zu schützen.
Wie lässt sich die effiziente Nutzung von Ressourcen in Ihrem vSphere Cluster sicherstellen? Werfen wir einen Blick auf die nächste vSphere-Cluster-Bereitstellung, um eine effiziente Nutzung Ihrer vSphere-Cluster-Ressourcen und -Kapazitäten zu gewährleisten.
Was ist DRS in VMware?
VMware Distributed Resource Scheduler (DRS) ist eine wirklich leistungsstarke Funktion beim Betrieb von vSphere-Clustern. Sie sorgt für die Planung und den Lastausgleich in einem vSphere-Cluster. VMware DRS ist die Funktion in vSphere Clustern, die sicherstellt, dass virtuelle Maschinen, die in Ihrer vSphere-Umgebung ausgeführt werden, mit den Ressourcen versorgt werden, die sie für eine effektive und effiziente Ausführung benötigen.
VMs unterliegen in der Regel schon früh DRS, da DRS die VMs ab dem ersten Einschalten in einem DRS-aktivierten Cluster auf dem besten Host platziert, der so konfiguriert ist, dass er die erforderlichen Ressourcen für die VM bereitstellt, sobald sie eingeschaltet wird. Darüber hinaus ist DRS bestrebt, vSphere-Cluster in Bezug auf die Ressourcennutzung ausgeglichen zu halten.
Selbst wenn ein vSphere-Cluster zu einem bestimmten Zeitpunkt ausgeglichen ist, können VMs verschoben werden oder sich so verändern, dass sich ein Ungleichgewicht der Cluster-Ressourcen wieder in die Umgebung einschleichen kann. Wenn Cluster unausgewogen sind, kann sich dies negativ auf die Gesamtleistung der in einem vSphere-Cluster ausgeführten virtuellen Maschinen auswirken.
Standardmäßig wird DRS alle fünf Minuten automatisch auf einem vSphere-Cluster ausgeführt, um das Gleichgewicht eines vSphere-Clusters zu ermitteln und festzustellen, ob Änderungen vorgenommen werden müssen, um die Ressourcen effektiver zu nutzen.
VMware DRS-Anforderungen
Um die Vorteile von VMware DRS nutzen zu können, müssen mehrere Anforderungen erfüllt werden, um die Vorteile der Distributed Resource Scheduler-Funktionalität nutzen zu können. Dazu gehören:
- Ein Cluster von ESXi-Hosts
- vCenter Server
- Enterprise Plus-Lizenz
- vMotion ist für den automatischen Lastausgleich erforderlich
Weiterlesen: So konfigurieren Sie einen vSphere DRS-Cluster
VMware DRS-Aktionen
Wenn VMware DRS alle fünf Minuten auf einem vSphere-Cluster ausgeführt wird, stellt es fest, ob im Cluster ein Ungleichgewicht besteht. Ist dies der Fall, wird eine vMotion durchgeführt, um bestimmte VMs von einem ESXi-Host auf einen anderen zu verschieben.
Wie genau bestimmt DRS, ob virtuelle Maschinen auf einem ESXi-Host besser geeignet sind als auf einem anderen?
DRS führt einen speziellen Algorithmus aus, um den richtigen ESXi-Host zu bestimmen, der eine bestimmte VM aufnehmen sollte. Wenn eine VM eingeschaltet wird, berücksichtigt dieser Algorithmus die Ressourcenverteilung im vSphere-Cluster, nachdem er sichergestellt hat, dass es keine Einschränkungen gibt, wenn eine bestimmte VM auf einem bestimmten ESXi-Host platziert wird.
Zusätzlich wird der Bedarf der VM selbst berücksichtigt, so dass die VM hoffentlich nie unter Ressourcenmangel leidet, wenn sie angeschaltet wird. Was ist im VM-Bedarf enthalten? Der Bedarf einer VM umfasst die Menge an Ressourcen, die für den Betrieb benötigt werden.
- Für den CPU-Bedarf wird dieser auf der Grundlage der CPU-Menge berechnet, die die VM gegenwärtig verbraucht
- Für den Speicherbedarf wird dieser auf der Grundlage der folgenden Formel berechnet: VM-Speicherbedarf = Funktion (genutzter aktiver Speicher, Swapped, Shared) + 25 % (im Leerlauf verbrauchter Speicher). Dies zeigt, dass die DRS-Speicherbilanz hauptsächlich auf der aktiven Speichernutzung einer VM basiert, während ein kleiner Teil des im Leerlauf verbrauchten Speichers als Puffer für einen Anstieg der Arbeitslast berücksichtigt wird.
DRS-Automatisierungsebenen
Eine der interessanten Funktionen von DRS sind die DRS-Automatisierungsebenen. Während DRS den vSphere-Cluster weiterhin scannt und alle 5 Minuten Empfehlungen ausspricht, können Sie festlegen, ob DRS seine Empfehlungen automatisch umsetzen kann oder nur Änderungen vorschlägt, die vorgenommen werden sollten. DRS verfügt über drei DRS-Automatisierungsstufen. Dazu gehören:
- Vollständig automatisiert – Beim vollständig automatisierten Ansatz wendet DRS sowohl die Empfehlungen für die Erstplatzierung als auch für den Lastausgleich automatisch an
- Teilweise automatisiert – Bei der teilweisen Automatisierung wendet DRS die Empfehlungen nur für die Erstplatzierung von VMs an
- Manuell – Im manuellen Modus, müssen Sie die Empfehlungen sowohl für die Erstplatzierung als auch für den Lastausgleich anwenden
DRS-Migrationsschwellenwerte
DRS enthält eine weitere sehr nützliche Einstellung, um das Ausmaß des Ungleichgewichts zu steuern, das toleriert wird, bevor DRS-Empfehlungen ausgesprochen werden. Es gibt fünf DRS-Migrationsschwellenwerte, mit denen das Ausmaß des tolerierten Ungleichgewichts gesteuert werden kann.
Der Bereich reicht von 1 (am konservativsten) bis 5 (am aggressivsten).
Bei aggressiveren Einstellungen toleriert DRS weniger Ungleichgewicht in einem Cluster. Je konservativer, desto mehr toleriert DRS ein Ungleichgewicht.

VMware DRS VM/Host-Regeln
Es gibt eine äußerst nützliche Funktion, wenn Sie VMware DRS zur Steuerung der Platzierung von VMs in Ihren vSphere DRS-aktivierten Clustern verwenden. Die VM/Host-Regeln ermöglichen es Ihnen, bestimmte VMs auf bestimmten ESXi-Hosts auszuführen. Sie können sich dies in gewisser Weise als Affinitätsregeln vorstellen.
Mit den VM/Host-Regeln können Sie:
- Virtuelle Maschinen zusammenhalten
- Virtuelle Maschinen trennen
- Virtuelle Maschinen an bestimmte Hosts binden
- Virtuelle Maschinen an virtuelle Maschinen binden
Unten sehen Sie ein Beispiel für die Erstellung einer VM/Host-Regel für virtuelle Maschinen und ESXi-Hosts.
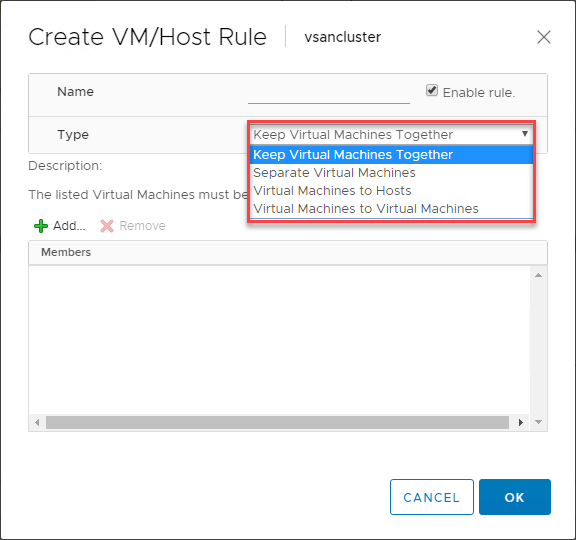
Welche Art von Anwendungsfall gibt es für diese VM/Host-Regeln? Einer der klassischen Anwendungsfälle ist der Einsatz von Domain Controllern. Wenn Sie alle Ihre Domänencontroller in einer virtualisierten Umgebung wie einem vSphere-Cluster ausführen, sollten Sie sicherstellen, dass die virtuellen Maschinen der Domänencontroller innerhalb des Clusters voneinander getrennt sind. Wenn ein ESXi-Host zusammen mit einem Ihrer Domänencontroller ausfällt, haben Sie auf diese Weise immer noch einen Domänencontroller, der einer Regel für getrennte virtuelle Maschinen unterliegt, die ihn vom selben Host wie einen anderen DC fernhält.
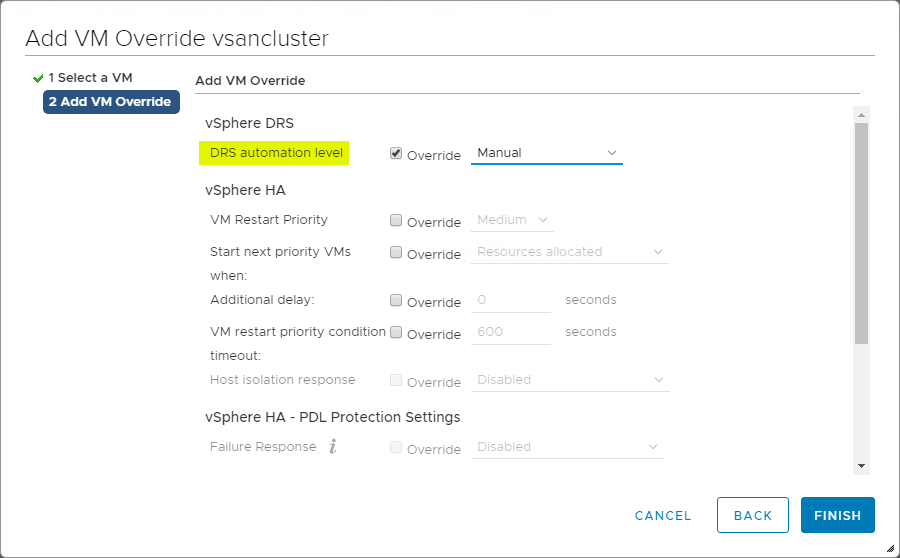
VM-Overrides für DRS
Der vSphere Cluster bietet eine hohe Granularität für Vorgänge, die einzelne VMs innerhalb des vSphere Clusters betreffen. Sie können VM-Overrides erstellen, um globale Einstellungen, die auf Clusterebene für HA und DRS festgelegt wurden, außer Kraft zu setzen und spezifischere Einstellungen für jede einzelne VM zu definieren.
Zusammenfassung der CPU- und Speicherauslastung
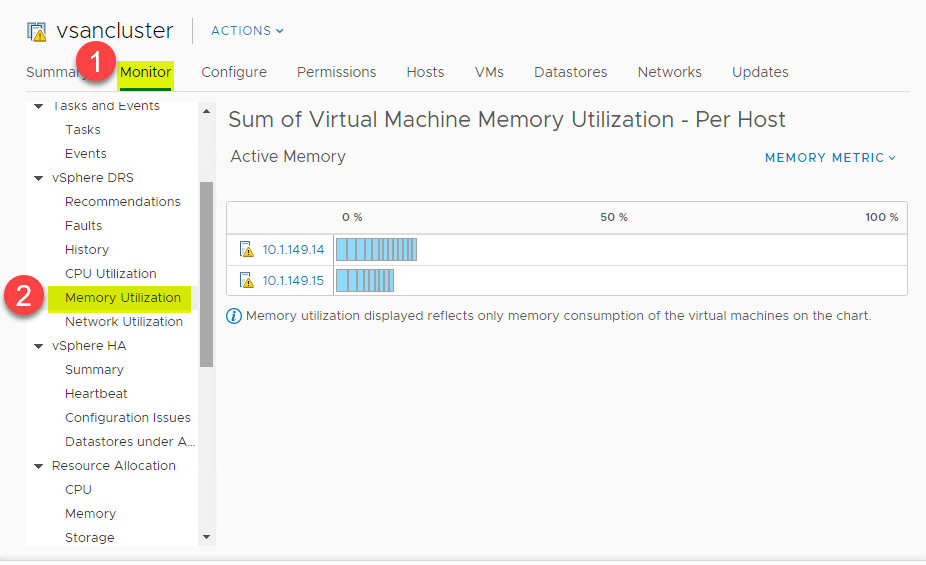
DRS bietet eine hervorragende Übersicht über die CPU-Auslastung der CPU-Ressourcen der ESXi-Hosts im vSphere Cluster. Navigieren Sie zu > Einstellungen > Monitor > vSphere DRS > CPU-Auslastung.
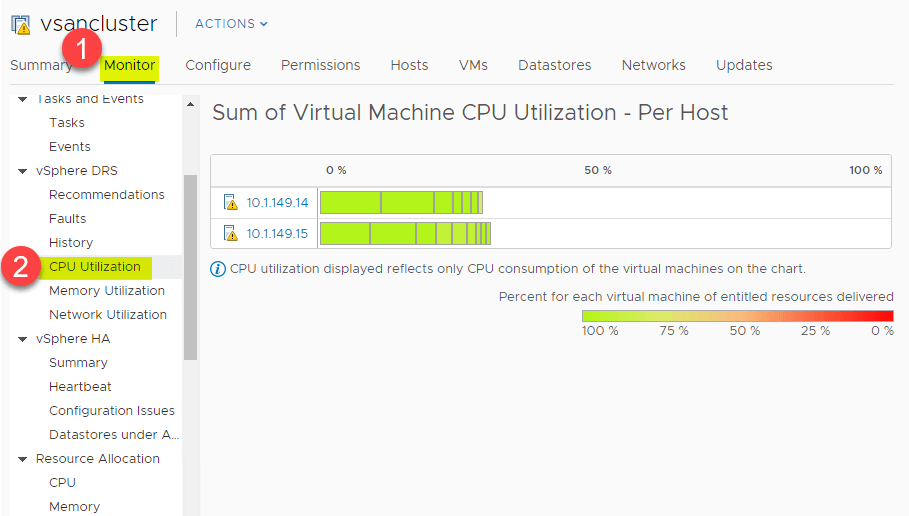
Die gleiche Übersicht auf hoher Ebene kann auch für den Speicherverbrauch angezeigt werden. Navigieren Sie zu > Einstellungen > Monitor > vSphere DRS > Speicherauslastung
Das Beste aus beiden Welten
Sind VMware vSphere HA und VMware DRS konkurrierende Technologien?
Nein, das sind sie nicht. Es wird sogar dringend empfohlen, sowohl vSphere HA als auch VMware DRS zusammen zu verwenden, um automatisches Failover mit Lastausgleichsfunktionen und -funktionen zu kombinieren. Dies führt zu einer wesentlich stabileren und ausgewogeneren vSphere-Umgebung.
Fällt ein ESXi-Host aus, startet vSphere HA die VMs auf den verbleibenden gesunden Hosts in einem vSphere-Cluster neu. Die erste Priorität ist also natürlich die Verfügbarkeit der Ressourcen der virtuellen Maschinen. VMware DRS stellt dann fest, ob ein Ungleichgewicht zwischen den ESXi-Hosts besteht, auf denen die Workloads ausgeführt werden, und gibt Empfehlungen zur Behebung von Ungleichgewichten im Cluster auf der Grundlage des konfigurierten Migrationsschwellenwerts. Je nach Automatisierungsgrad werden diese Empfehlungen entweder automatisch umgesetzt oder nur empfohlen, wenn sie nicht vollständig automatisiert sind.
Abschließende Überlegungen zu VMware vSphere HA und DRS
Der Einsatz von VMware vSphere HA und DRS wird in einem produktiven vSphere-Cluster dringend empfohlen. Die Verwendung beider Technologien trägt dazu bei, Ihre Workloads hochverfügbar zu machen und stellt sicher, dass sie kontinuierlich über die erforderlichen Ressourcen verfügen, die auf den CPU-/Speicheranforderungen der VM basieren.
Wenn Sie verstehen, wie beide Mechanismen funktionieren, können Sie als vSphere-Administrator beide Technologien optimal und in Übereinstimmung mit Best Practices nutzen. Zu den Vorteilen, die beide Technologien mit sich bringen, gehört, dass jede Funktion extrem einfach zu aktivieren und zu konfigurieren ist. Mit ein paar einfachen Klicks in den Eigenschaften Ihrer vSphere-Cluster können Sie schnell von diesen verfügbaren Funktionen auf Clusterebene profitieren.
Folgen Sie unseren Twitter- und Facebook-Feeds für neue Versionen, Updates, aufschlussreiche Beiträge und mehr.