Reinforcement Learning (RL) ist eines der heißesten Forschungsthemen auf dem Gebiet der modernen künstlichen Intelligenz und seine Popularität wächst ständig. Schauen wir uns 5 nützliche Dinge an, die man wissen muss, um mit RL anzufangen.
Reinforcement Learning(RL) ist eine Art von maschineller Lerntechnik, die es einem Agenten ermöglicht, in einer interaktiven Umgebung durch Versuch und Irrtum zu lernen, indem er Rückmeldungen aus seinen eigenen Aktionen und Erfahrungen nutzt.
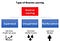
Obgleich sowohl das überwachte als auch das verstärkende Lernen ein Mapping zwischen Input und Output verwenden, werden beim verstärkenden Lernen im Gegensatz zum überwachten Lernen, bei dem die Rückmeldung an den Agenten in der korrekten Ausführung einer Aufgabe besteht, Belohnungen und Bestrafungen als Signale für positives und negatives Verhalten verwendet.
Im Vergleich zum unüberwachten Lernen unterscheidet sich das Verstärkungslernen in Bezug auf die Ziele. Während das Ziel beim unüberwachten Lernen darin besteht, Ähnlichkeiten und Unterschiede zwischen Datenpunkten zu finden, ist es beim Reinforcement Learning das Ziel, ein geeignetes Handlungsmodell zu finden, das die kumulative Gesamtbelohnung des Agenten maximiert. Die folgende Abbildung zeigt die Aktions-Belohnungs-Rückkopplungsschleife eines allgemeinen RL-Modells.

Wie formuliert man ein grundlegendes Reinforcement Learning Problem?
Einige Schlüsselbegriffe, die die grundlegenden Elemente eines RL-Problems beschreiben, sind:
- Umgebung – Physikalische Welt, in der der Agent agiert
- Zustand – Aktuelle Situation des Agenten
- Belohnung – Rückmeldung aus der Umgebung
- Politik – Methode, um den Zustand des Agenten auf Aktionen abzubilden
- Wert – Zukünftige Belohnung, die ein Agent erhalten würde, wenn er eine Aktion in einem bestimmten Zustand durchführt
Ein RL-Problem lässt sich am besten durch Spiele erklären. Nehmen wir das Spiel PacMan, bei dem das Ziel des Agenten (PacMan) ist, das Essen im Gitter zu essen und dabei den Geistern auf seinem Weg auszuweichen. In diesem Fall ist die Gitterwelt die interaktive Umgebung für den Agenten, in der er agiert. Der Agent erhält eine Belohnung für die Nahrungsaufnahme und eine Bestrafung, wenn er von einem Geist getötet wird (er verliert das Spiel). Die Zustände sind die Positionen des Agenten in der Gitterwelt und die kumulative Gesamtbelohnung ist der Gewinn des Spiels durch den Agenten.

Um eine optimale Strategie zu entwickeln, steht der Agent vor dem Dilemma, neue Zustände zu erkunden und gleichzeitig seine Gesamtbelohnung zu maximieren. Dies wird als Kompromiss zwischen Erkundung und Ausbeutung bezeichnet. Um beides auszugleichen, kann die beste Gesamtstrategie kurzfristige Opfer erfordern. Daher sollte der Agent genügend Informationen sammeln, um in der Zukunft die beste Gesamtentscheidung zu treffen.
Markov-Entscheidungsprozesse (MDPs) sind mathematische Rahmen zur Beschreibung einer Umgebung in RL und fast alle RL-Probleme können mit Hilfe von MDPs formuliert werden. Ein MDP besteht aus einer Menge von endlichen Umgebungszuständen S, einer Menge von möglichen Aktionen A(s) in jedem Zustand, einer reellwertigen Belohnungsfunktion R(s) und einem Übergangsmodell P(s‘, s | a). In der realen Welt ist es jedoch wahrscheinlicher, dass keine Vorkenntnisse über die Dynamik der Umgebung vorhanden sind. In solchen Fällen bieten sich modellfreie RL-Methoden an.
Q-Lernen ist ein häufig verwendeter modellfreier Ansatz, der für den Aufbau eines selbstspielenden PacMan-Agenten verwendet werden kann. Es dreht sich um das Konzept der Aktualisierung von Q-Werten, die den Wert der Ausführung von Aktion a im Zustand s bezeichnen. Die folgende Wertaktualisierungsregel ist der Kern des Q-Learning-Algorithmus.

Hier ist eine Video-Demonstration eines PacMan-Agenten, der Deep Reinforcement Learning verwendet.
Welche sind einige der am häufigsten verwendeten Reinforcement Learning Algorithmen?
Q-Learning und SARSA (State-Action-Reward-State-Action) sind zwei häufig verwendete modellfreie RL-Algorithmen. Sie unterscheiden sich in Bezug auf ihre Explorationsstrategien, während ihre Ausbeutungsstrategien ähnlich sind. Während Q-learning eine Off-Policy-Methode ist, bei der der Agent den Wert auf der Grundlage der Aktion a* lernt, die von einer anderen Policy abgeleitet wurde, ist SARSA eine On-Policy-Methode, bei der er den Wert auf der Grundlage seiner aktuellen Aktion a lernt, die von seiner aktuellen Policy abgeleitet wurde. Diese beiden Methoden sind einfach zu implementieren, aber es mangelt ihnen an Allgemeinheit, da sie nicht in der Lage sind, Werte für ungesehene Zustände zu schätzen.
Dies kann durch fortschrittlichere Algorithmen wie Deep Q-Networks (DQNs) überwunden werden, die neuronale Netze zur Schätzung von Q-Werten verwenden. DQNs können jedoch nur mit diskreten, niedrigdimensionalen Aktionsräumen umgehen.
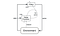
Deep Deterministic Policy Gradient (DDPG) ist ein modellfreier, akteurskritischer Algorithmus, der dieses Problem durch das Lernen von Strategien in hochdimensionalen, kontinuierlichen Aktionsräumen angeht. Die folgende Abbildung zeigt eine Darstellung der akteurskritischen Architektur.
Was sind die praktischen Anwendungen des Reinforcement Learning?
Da RL viele Daten erfordert, ist es am besten in Bereichen anwendbar, in denen simulierte Daten leicht verfügbar sind, wie z. B. in der Spiel- und Robotertechnik.
- RL wird häufig bei der Entwicklung von KI für Computerspiele eingesetzt. AlphaGo Zero ist das erste Computerprogramm, das einen Weltmeister im alten chinesischen Spiel Go besiegt hat. Weitere Beispiele sind ATARI-Spiele, Backgammon usw.
- In der Robotik und der industriellen Automatisierung wird RL eingesetzt, um den Roboter in die Lage zu versetzen, ein effizientes adaptives Steuerungssystem für sich selbst zu entwickeln, das aus seinen eigenen Erfahrungen und seinem Verhalten lernt. Die Arbeit von DeepMind an Deep Reinforcement Learning für Robotermanipulation mit asynchronen Policy-Updates ist ein gutes Beispiel dafür. Sehen Sie sich dieses interessante Demonstrationsvideo an.
Andere Anwendungen von RL umfassen abstrakte Textzusammenfassungsmaschinen, Dialogagenten (Text, Sprache), die aus Benutzerinteraktionen lernen und sich mit der Zeit verbessern können, das Lernen optimaler Behandlungsstrategien im Gesundheitswesen und RL-basierte Agenten für den Online-Aktienhandel.
Wie kann ich mit Reinforcement Learning beginnen?
Um die grundlegenden Konzepte von RL zu verstehen, kann man sich auf die folgenden Ressourcen beziehen.
- Reinforcement Learning-An Introduction, ein Buch vom Vater des Reinforcement Learning – Richard Sutton und seinem Doktorvater Andrew Barto. Ein Online-Entwurf des Buches ist hier verfügbar.
- Das Lehrmaterial von David Silver, einschließlich Videovorlesungen, ist ein großartiger Einführungskurs in RL.
- Hier ist ein weiteres technisches Tutorial über RL von Pieter Abbeel und John Schulman (Open AI/ Berkeley AI Research Lab).
Für den Einstieg in den Aufbau und das Testen von RL-Agenten können die folgenden Ressourcen hilfreich sein.
- Dieser Blog von Andrej Karpathy zeigt, wie man einen ATARI Pong-Agenten mit neuronalen Netzwerken und Policy Gradients aus rohen Pixeln trainiert, und hilft Ihnen, Ihren ersten Deep Reinforcement Learning-Agenten in nur 130 Zeilen Python-Code zum Laufen zu bringen.
- DeepMind Lab ist eine quelloffene, spielähnliche 3D-Plattform für agentenbasierte KI-Forschung mit reichhaltigen simulierten Umgebungen.
- Project Malmo ist eine weitere KI-Experimentierplattform zur Unterstützung der KI-Grundlagenforschung.
- OpenAI Gym ist ein Toolkit zum Erstellen und Vergleichen von Reinforcement Learning-Algorithmen.